数据库查询优化实验报告_SQLServer2008
sql server 2008 实验报告

sql server 2008 实验报告SQL Server 2008 实验报告引言:SQL Server 2008 是微软公司开发的一种关系型数据库管理系统(RDBMS),广泛应用于企业级应用程序和大规模数据存储。
本实验报告将探讨 SQL Server 2008 的一些关键特性和使用案例,以及在实验过程中的观察和结果。
一、SQL Server 2008 的特性1. 支持多种数据类型:SQL Server 2008 提供了丰富的数据类型,包括整数、浮点数、日期时间、字符串等。
这些数据类型的灵活性使得开发人员可以更好地满足不同应用程序的需求。
2. 强大的查询和操作功能:SQL Server 2008 提供了强大的查询和操作功能,包括 SELECT、INSERT、UPDATE 和 DELETE 等语句。
这些功能使得开发人员可以轻松地从数据库中检索和修改数据。
3. 支持事务处理:SQL Server 2008 支持事务处理,这意味着在数据库中的一系列操作可以作为一个单独的单元进行处理。
如果在事务处理期间发生错误,可以回滚到事务开始之前的状态,确保数据的完整性。
4. 数据库安全性:SQL Server 2008 提供了多层次的安全性控制,包括用户认证、权限管理和数据加密等。
这些功能可以保护数据库中的敏感信息,防止未经授权的访问。
5. 高可用性和容错性:SQL Server 2008 提供了高可用性和容错性功能,包括数据库镜像、故障转移和备份恢复等。
这些功能可以确保数据库在发生故障时能够快速恢复并保持可用状态。
二、SQL Server 2008 的使用案例1. 企业级应用程序:SQL Server 2008 是一种理想的数据库管理系统,可用于支持企业级应用程序的数据存储和处理。
它可以处理大量的数据,支持高并发访问,并提供了可靠的数据保护和安全性。
2. 数据仓库和商业智能:SQL Server 2008 提供了强大的数据仓库和商业智能功能,可以帮助企业从大量的数据中提取有价值的信息。
数据库实验一 SQL Server 2008环境

实验1 SQL Server 2008 环境1.目的与要求(1) 掌握SQL Server Management Studio 对象资源管理器的使用方法;(2) 掌握SQL Server Management Studio 查询分析器的使用方法;(3) 对数据库及其对象有一个基本了解。
2.实验准备(1) 了解 SQL Server 2008 各种版本安装的软、硬件要求;(2) 了解SQL Server 2008 支持的身份验证模式;(3) 对数据库、表及其其他数据库对象有一个基本了解。
3.实验内容(1) SQL Server 2008的安装。
检查软、硬件配置是否达到SQL Server 2008的安装要求,参照第1章内容安装SQL Server 2008,熟悉SQL Server 2008的安装方法。
(2) 对象资源管理器的使用。
①进入SQL Server Management Studio。
单击“开始”,选择“程序”,选择“SQL Server 2008”,单击“SQL Server Management Studio”,打开“连接到服务器”窗口,如图T1.1所示。
图T1.1 连接到服务器在打开的“连接到服务器”窗口中使用系统默认设置连接服务器,单击“连接”按钮,系统显示“SQL Server Management Studio”窗口。
在SQL Server Management Studio窗口中,左边是对象资源管理器,它以目录树的形式组织对象。
右边是操作界面,如“查询分析器”窗口、“表设计器”窗口等。
②了解系统数据库和数据库的对象。
在SQL Server 2008安装后,系统生成了4个数据库:master、model、msdb和tempdb。
在对象资源管理器中单击“系统数据库”,右边显示4个系统数据库,如图T1.2所示。
选择系统数据库master,观察SQL Server 2008对象资源管理器中数据库对象的组织方式。
实验一-SQL-SERVER-2008入门实验报告

实验一SQL SERVER 2008环境一、实验目的1、了解SQL SERVER 2008的安装过程中的关键问题;2、掌握通过SQL Server Management Studio管理数据库服务器、操作数据库对象的方法;3、掌握数据库的还原与备份操作。
二、实验过程1、启动SQLSERVER服务实验室机器上既安装了SQL Server 2008服务器端工具又安装了客户端工具,在使用客户端工具SQL Server Management Studio连接数据库引擎之前,需要将本地数据库引擎服务启动,启动方法如下:(1)打开配置管理器开始菜单——>所有程序——> Microsoft SQL Server 2008——>配置工具——>SQL Server配置管理器(2)启动SQL Server服务单击左窗格的“SQL Server 服务”选项,在右窗格中就会显示所有的服务,找到“SQL Server(MSSQLSERVER)”服务,在服务上单击右键,选择“启动”,SQL Server数据库引擎服务启动。
2、登录服务器在使用SQL Server Management Studio管理数据库引擎服务器时,需要首先登录到服务器上,第一次登录时需要将登录界面的“服务器名称”选项修改为本地的计算机名。
同时将身份验证方式改为“Windows身份验证”获取本地计算机名:右键点击“我的电脑”——>属性——>“计算机名”标签页3、创建数据库建立名为“Student”的数据库。
4、建立基本表在“Student”数据库下,建立学生表(S)、课程表(C)和学生选课表(SC),其逻辑结构描述,详见表1、表2和表3。
表1 S表加主码后的SC表:外键关系:表2 C表表3 SC表5、录入数据6、修改数据表逻辑结构(1)在课程表中添加一个授课教师列,列名为Tname,类型为varchar(8)此时,关闭这个窗口后,在左边列表重新打开就能看到列表上增加了Tname这一项(2)将学生表中的Brithday属性列删除。
SQL server 2008数据库实验
实验九.视图和索引及数据库关系图
视图操作
创建视图view_s_grade
修改视图只显示分数大于80的人
创建索引
实验十. sql server事务管理
定义一个事务,更改s表的数据
事务处理,一条有误两条都不写入数据库
事务处理
定义一个事务,向表插入一段数据再删除,结果没有删除该数据
向s表插入数据Βιβλιοθήκη 在sc表中删除s13 c10的记录。
实验四.数据库约束实验
利用数据库关系图管理主键。
利用表设计管理主键。
利用T-SQL定义主键。
唯一性约束的设置与删除。
实验五. select数据查询
查询数学系的学生的学号和姓名。
查询每个学生的情况和所选的课程号
查询学了体育的学生的学号和姓名
学了体育的比此课程平均成绩大的学号和成绩
实验十一. Sql server安全管理
创建新的账户和用户
创建登陆账户
创建数据库用户
把查询表s的权限授给login_account_user
删除数据用户
删除登陆账户
实验十二.数据库的备份和恢复
分离数据库
分离数据库
数据库的附加
数据库备份
还原数据库
实验十三.数据的导入导出
数据的导出
数据的导入
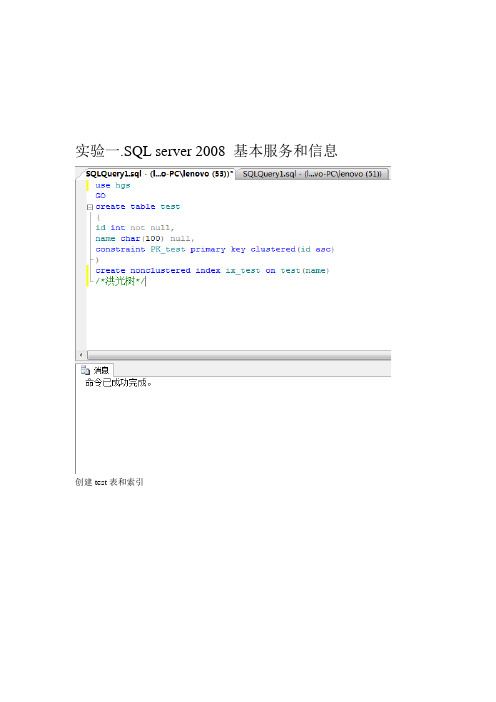
实验一.SQL server 2008基本服务和信息
创建test表和索引
查询test表的信息
查询column的id
查看表分区信息
实验二.数据库的创建和管理
数据库的创建
数据库的创建
修改数据库属性
删除数据库
实验三.数据表的创建和管理
建立Dept-info表
sqlserver实验报告

实验报告:SQL Server一、实验目的本次实验旨在熟悉并掌握SQL Server数据库管理系统,了解其功能特点、操作方法和应用场景。
通过实验,我们希望深入理解数据库的基本概念,掌握SQL Server的基本操作,为后续的数据库学习和应用打下坚实的基础。
二、实验内容1. 了解SQL Server版本和功能特点通过阅读教材、查阅资料,我们了解了SQL Server的不同版本及其功能特点。
目前,SQL Server最新版本是SQL Server 2008,它只能在Windows上运行,操作系统的系统稳定性对数据库十分重要。
2. 安装SQL Server在实验过程中,我们按照教材的指导,成功安装了SQL Server 2008。
安装过程中,我们注意了安装选项的选择,确保安装了必要的组件和工具。
3. 创建和管理数据库在SQL Server中,我们通过对象资源管理器创建了名为“testdb”的数据库。
在创建过程中,我们设置了数据库的名称、文件路径、文件大小等参数。
同时,我们还学习了如何修改数据库的属性,如修改数据库的名称、删除数据库等。
4. 创建和管理表在“testdb”数据库中,我们创建了名为“employees”的表,用于存储员工信息。
在创建表的过程中,我们定义了表的列名、数据类型、约束等属性。
同时,我们还学习了如何修改表的属性,如添加列、删除列等。
5. 查询数据通过查询语句,我们从“employees”表中检索了所有员工的信息。
在查询过程中,我们使用了SELECT语句,并通过WHERE子句对结果进行了筛选。
同时,我们还学习了如何使用聚合函数对数据进行统计和分析。
6. 插入、更新和删除数据在“employees”表中,我们插入了新的员工信息,更新了现有员工的信息,并删除了离职的员工信息。
在插入、更新和删除数据的过程中,我们使用了INSERT、UPDATE和DELETE语句。
同时,我们还学习了如何使用事务来确保数据的完整性和一致性。
sql server 2008 实验报告

sql server 2008 实验报告SQL Server 2008 实验报告引言SQL Server 2008 是微软公司推出的一款关系型数据库管理系统,它具有强大的数据管理和处理能力,被广泛应用于企业和组织的数据管理工作中。
本实验报告将对SQL Server 2008进行实验并进行详细的分析和总结。
实验目的本次实验的目的是通过对SQL Server 2008的实验,掌握其基本的安装、配置和使用方法,了解其在数据管理和处理方面的优势和特点,为日后的数据库管理工作打下基础。
实验内容1. SQL Server 2008的安装和配置首先,我们需要进行SQL Server 2008的安装和配置工作。
在安装过程中,需要注意选择合适的安装选项和配置参数,以确保系统能够正常运行并满足实际需求。
2. 数据库的创建和管理接下来,我们将学习如何在SQL Server 2008中创建数据库、表和索引,以及对数据进行增删改查等操作。
这些操作是数据库管理工作中的基本内容,掌握这些操作方法对于日后的实际工作至关重要。
3. 数据备份和恢复数据库的备份和恢复是数据库管理工作中的重要环节,也是保障数据安全的关键。
在本次实验中,我们将学习如何使用SQL Server 2008进行数据备份和恢复操作,以确保数据的安全性和完整性。
实验结果通过本次实验,我们成功完成了SQL Server 2008的安装和配置工作,并学习了数据库的创建和管理、数据备份和恢复等操作方法。
在实验过程中,我们深刻体会到SQL Server 2008在数据管理和处理方面的优势和特点,以及其在实际工作中的重要作用。
结论SQL Server 2008作为一款强大的关系型数据库管理系统,具有优秀的性能和稳定性,广泛应用于企业和组织的数据管理工作中。
通过本次实验,我们对SQL Server 2008有了更深入的了解,掌握了其基本的安装、配置和使用方法,为日后的数据库管理工作打下了坚实的基础。
数据库实训报告(SQL SERVER 2008)
实训目的实训一:VB程序开发1、熟悉vb集成开发环境2、掌握vb启动与退出3、掌握简单应用程序界面设计步骤4、掌握窗体上控件的添加方法和常用控件的简单应用5、掌握几种常用控件的应用计常用属性的方法。
实训二: 菜单设计1、了解菜单的概念和作用2、掌握菜单编辑器的使用方法3、熟悉菜单事件的编程方法。
实训三:创建李亚强0912020107数据库1、掌握数据库的创建与修改方法2、掌握数据库表的创建方法3、学会t-sql 语句创建表、修改表和删除表4、掌握给表之间建立关系。
实训四:查询与视图的建立及应用1、掌握select子句和where子句的用法。
2、掌握视图的创建方法及应用。
3、掌握利用视图来更新基本表。
实训五:程序结构及变量的应用1、掌握程序的基本结构的使用2、掌握系统函数的使用。
3、掌握自定义函数的使用实训六:利用Vb访问SQL SERVER 2008数据库(系统集成)1、掌握如何通过VB来访问SQL SERVER 2008开发的数据库。
实训要求(一)知识要求:1.了解数据库的意义,数据库的要素2.深入理解数据库中表与关系的概念,及其关系3.理解表、查询、视图、索引、存储过程和触发器的概念4.理解安全性管理的作用5.掌握数据库的备份和恢复方法6.掌握数据转换的内容(二)能力要求:1.熟练掌握使用SQL SERVER建立数据库,设计表及其关系;2. 掌握数据库查询的几种方法;3. 会使用视图和索引对数据库进行各种操作;4. 会进行存储过程和触发器的创建和使用并对其进行语句分析;5. 掌握安全性管理方法的内容并会角色用户的创建和使用;6. 掌握数据库的备份三种方式会进行备份和恢复;7.会使用数据转换向导进行数据转换操作。
实训注意事项1、遵守机房纪律,服从辅导教师指挥,爱护实验设备2、注意保存做好的作品3、防止雷同4、设计页面美观大方,无垃圾代码5、不迟到,不早退6、做完后完成实训报告。
实训内容一、VB程序开发二、菜单设计三、创建李亚强0912020107数据库四、查询与视图的建立及应用五、程序结构及变量的应用六、利用Vb访问SQL SERVER 2008数据库(系统集成)实训心得体会经过这一学期的学习,我对SQL SERVER数据库管理系统有了一定的了解。
数据库原理-实验8-查询优化
一、实验目的1.熟悉查询查询处理的过程;2.掌握查询优化的概念,理解查询优化的必要性;3.了解数据库的查询计划;4.掌握查询代价的分析方法,并且能通过配置参数或者修改SQL语句来降低查询代价。
二、实验环境SQL Server 2008三、实验学时2学时四、实验要求1)求选修了00002号课程的学生姓名。
用SQL表达:SELECT Student.SnameFROM Student,SCWHERE Student.Sno=SC.Sno AND o=‘00002’2)三种实现方法:Q1=πSname(σStudent.Sno=SC.Sno∧o='2' (Student×SC))Q2=πSname(σo='2' (Student SC))Q3=πSname(Student σo='2'(SC))3)要求:本实验旨在说明查询优化的必要性,只要求把法一Q1与法二Q2和法三 Q3比较,从而说明查询优化的重要性五、实验内容及步骤(一)实验数据的准备-- 1.创建数据库(事先在D盘新建一个文件夹stu_opti)create database stu_optimizationON( NAME = stu_opti,FILENAME = 'd:\stu_opti\stu_opti.mdf',SIZE = 100,MAXSIZE = 500,FILEGROWTH = 10 )LOG ON( NAME = 'stu_opti_log',FILENAME = 'd:\stu_opti\stu_opti_log.ldf', SIZE = 50MB,MAXSIZE = 250MB,FILEGROWTH = 5MB )GO-- 2. 创建学生表create table s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))godrop table sgo-- 3. 为学生表输入数据--输入30000个计科教育学生declare @num intdeclare @n intset @num=30000set @n=1while @n<=@numbegininsert into s(sno,sdept)select '151031'+right('00000'+cast(@n as varchar(5)),5),'计科教育'set @n=@n+1endselect * from s--4. 设置学生性别--(1)设置15000个学生的性别为女性--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 15000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--随机设置个学生的性别为女性update dbo.sset ssex='女'from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--(2)设置其他学生的性别为男性update dbo.sset ssex='男'where ssex is null--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_sselect * from s order by sno--5. 设置学生年龄--(1)为5000个学生设置其年龄为21岁--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这个学生的年龄为21岁update dbo.sset sage=21from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_s--(2)为5000个学生设置其年龄为22岁--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这个学生的年龄为22岁update dbo.sset sage=22from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_s--(3)为5000个学生设置其年龄为23岁--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这个学生的年龄为23岁update dbo.sset sage=23from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_s--(4)为5000个学生设置其年龄为20岁--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这个学生的年龄为20岁update dbo.sset sage=20from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_s--(5)为5000个学生设置其年龄为19岁--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这个学生的年龄为19岁update dbo.sset sage=19from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_s--(6)为5000个学生设置其年龄为18岁--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这个学生的年龄为18岁update dbo.sset sage=18from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_supdate s set sage=21 where sage is nullselect * from s order by sno--6. 设置学生姓名--(1)为5000个学生设置其姓名为李--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这些学生的姓名为李update dbo.sset sname='李'from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_s--(2)为5000个学生设置其姓名为王--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这些学生的姓名为王update dbo.sset sname='王'from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_s--(3)为5000个学生设置其姓名为王--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这些学生的姓名为陈update dbo.sset sname='陈'from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_s--(4)为5000个学生设置其姓名为刘--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这些学生的姓名为刘update dbo.sset sname='刘'from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_s--(5)为5000个学生设置其姓名为张--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这些学生的姓名为张update dbo.sset sname='张'from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_sDROP TABLE #TEMP_s--(6)为5000个学生设置其姓名为邱--创建临时表,其结构与学生表的结构一致 CREATE TABLE #TEMP_s(sno char(11),sname char(10),ssex char(2),sage tinyint,sdept char(10))--从学生表中随机产生行数据插入到临时表中INSERT INTO #TEMP_sSELECT top 5000 sno,sname,ssex,sage,sdept FROM dbo.sORDER BY NEWID()--设置这些学生的姓名为邱update dbo.sset sname='邱'from dbo.s inner join #TEMP_son dbo.s.sno=#TEMP_s.sno--删除临时表TRUNCATE TABLE #TEMP_s DROP TABLE #TEMP_s-- 7. 创建课程表,录入课程create table c(cno char(5),cname varchar(20),cpno char(5),ccredit tinyint)goinsert into dbo.c(cno,cname,cpno,ccredit) values--('00001','计算机导论','',2),--('00002','高级语言程序设计','',2),--('00003','离算数学','',3),--('00004','数据结构','00002',3),--('00005','c#','00002',2),--('00006','面向对象程序设计','00005',2), --('00007','数据库原理','00004',3),--('00008','操作系统','',3),--('00009','计算机组成原理','',3),--('00010','编译原理','',3),--('00011','软件工程','',2),--('00012','数字图像处理','',2),--('00013','程序设计','',2),--('00014','平面动画设计','',2),--('00015','linux操作系统','00008',2),--('00016','数据库新技术','00007',2),--('00017','嵌入式技术','',2),--('00018','算法设计与分析','00004',2), --('00019','nosql','',2),('00020','数据库实用技术','00007',2)select * from c--8. 创建学生成绩表,录入成绩--(1)创建学生成绩表sc create table sc(sno char(11) not null,cno char(5) not null,grade tinyint,primary key(sno,cno))go--(2)录入学号和课程号declare @sno char(11)declare s_cursor cursor local for select sno from dbo.s open s_cursorfetch s_cursor into @snodeclare @s_row int,@n intset @s_row=30000set @n=1while @n<=@s_rowbegininsert dbo.sc(sno,cno)select @sno, cno from dbo.cfetch s_cursor into @snoset @n=@n+1endclose s_cursordeallocate s_cursor--(3)为学生选课表生成成绩--1)创建学生选课表sc12create table sc12(sno char(11),cno char(5),grade int,primary key(sno,cno))go--2)将学生选课表sc中的选课信息插入到学生选课表sc12,并随机生成相应的选课成绩declare @sno char(11),@cno char(5)declare @grdae tinyintdeclare sc_cur cursor for select sno,cno from dbo.scopen sc_curfetch next from sc_cur into @sno,@cnoset @grdae=cast( floor(rand()*50) as int)+50declare @n int,@sc_row intset @n=1set @sc_row=600000while @n<=@sc_rowbegininsert into dbo.sc12(sno,cno,grade)values(@sno,@cno,@grdae)fetch next from sc_cur into @sno,@cnoset @grdae=cast( floor(rand()*50) as int)+50set @n=@n+1endclose sc_curdeallocate sc_cur说明:上面是查询优化数据库的模板程序。
sql server 2008实验报告
sql server 2008实验报告SQL Server 2008实验报告摘要:本实验报告旨在对SQL Server 2008进行实验研究,探讨其在数据库管理和数据处理方面的性能和功能。
通过对SQL Server 2008的实验操作和性能测试,对其优点和不足进行分析,以期为数据库管理和应用开发提供参考和指导。
1. 实验背景SQL Server 2008是微软公司推出的关系型数据库管理系统,具有强大的数据管理和处理能力,被广泛应用于企业级数据库系统中。
本实验旨在通过对SQL Server 2008的实验操作和性能测试,全面了解其功能和性能特点,为数据库管理和应用开发提供参考和指导。
2. 实验目的通过本次实验,我们旨在:- 了解SQL Server 2008的基本架构和特点- 掌握SQL Server 2008的安装和配置方法- 熟悉SQL Server 2008的数据库管理和维护操作- 测试SQL Server 2008在数据处理和查询性能方面的表现- 分析SQL Server 2008的优缺点和适用场景3. 实验内容本次实验主要包括以下内容:- SQL Server 2008的安装和配置- 数据库的创建和管理- 数据表的设计和维护- SQL查询语句的编写和性能测试- 对SQL Server 2008的功能和性能进行评估分析4. 实验步骤4.1 SQL Server 2008的安装和配置按照官方文档指引,我们完成了SQL Server 2008的安装和配置,包括数据库引擎、分析服务、报表服务等组件的安装和配置。
4.2 数据库的创建和管理我们创建了一个测试数据库,并进行了数据表的设计和管理,包括表的创建、字段的定义、索引的添加等操作。
4.3 数据表的设计和维护我们对数据表进行了设计和维护,包括表结构的修改、数据的导入和导出、数据的备份和恢复等操作。
4.4 SQL查询语句的编写和性能测试我们编写了一系列SQL查询语句,并进行了性能测试,包括查询速度、索引优化、并发处理等方面的测试。
数据库sqlserver实验报告
实验一熟悉常用的 DBMS:SQL SERVER2008、Oracle试验内容及要求:(1)了解不同数据库管理系统及不同版本的相应功能特点目前,商品化的数据库管理系统以关系型数据库为主导产品,技术比较成熟。
面向对象的数据库管理系统虽然技术先进,数据库易于开发、维护,但尚未有成熟的产品。
国际国内的主导关系型数据库管理系统有Oracle、Sybase、INFORMIX和INGRES。
这些产品都支持多平台,如UNIX、VMS、Windows,但支持的程度不一样。
IBM的DB2也是成熟的关系型数据库。
但是,DB2是内嵌于IBM的AS/400系列机中,只支持OS/400操作系统。
1.MySQLMySQL是最受欢迎的开源SQL数据库管理系统,它由MySQL AB开发、发布和支持。
MySQL AB是一家基于MySQL开发人员的商业公司,它是一家使用了一种成功的商业模式来结合开源价值和方法论的第二代开源公司。
MySQL是MySQL AB的注册商标。
MySQL是一个快速的、多线程、多用户和健壮的SQL数据库服务器。
MySQL服务器支持关键任务、重负载生产系统的使用,也可以将它嵌入到一个大配置(mass- deployed)的软件中去。
与其他数据库管理系统相比,MySQL具有以下优势:(1)MySQL是一个关系数据库管理系统。
(2)MySQL是开源的。
(3)MySQL服务器是一个快速的、可靠的和易于使用的数据库服务器。
(4)MySQL服务器工作在客户/服务器或嵌入系统中。
(5)有大量的MySQL软件可以使用。
2.SQL ServerSQL Server是由微软开发的数据库管理系统,是Web上最流行的用于存储数据的数据库,它已广泛用于电子商务、银行、保险、电力等与数据库有关的行业。
目前最新版本是SQL Server2005,它只能在Windows上运行,操作系统的系统稳定性对数据库十分重要。
并行实施和共存模型并不成熟,很难处理日益增多的用户数和数据卷,伸缩性有限。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SQL Server 2008数据查询的优化方法研究摘要随着数据存储需求的日益增长,对关系数据的管理和访问就成为数据库技术必须解决的问题。
本文主要论述关系数据库查询优化技术,并从它的优化技术进行深入探讨,对系统实现做了一定的论述,并进行了部分的程序实现。
关键词:数据库查询系统优化引言SQLServer是是由微软公司开发的基于Windows操作系统的关系型数据库管理系统,它是一个全面的、集成的、端到端的数据解决方案,为企业中的用户提供了一个安全、可靠和高效的平台用于企业数据管理和商业智能应用。
目前,许多中小型企业的数据库应用系统都是用SQLServer作为后台数据库管理系统设计开发的。
设计一个应用系统并不难,但是要想使系统达到最优化的性能并不是一件容易的事。
根据多年的实践,由于初期的数据库中表的记录数比较少,性能不会有太大问题,但数据积累到一定程度,达到数百万甚至上千万条,全面扫描一次往往需要数十分钟,甚至数小时。
20%的代码用去了80%的时间,这是程序设计中的一个著名定律,在数据库应用程序中也同样如此。
如果用比全表扫描更好的查询策略,往往可以使查询时间降为几分钟。
而且我们知道,目前数据库系统应用中,查询操作占了绝大多数,查询优化成为数据库性能优化最为重要的手段之一。
影响查询效率的因素SQLServer处理查询计划的过程是这样的:在做完查询语句的词法、语法检查之后,将语句提交给SQLServer的查询优化器,查询优化器通过检查索引的存在性、有效性和基于列的统计数据来决定如何处理扫描、检索和连接,并生成若干执行计划,然后通过分析执行开销来评估每个执行计划,从中选出开销最小的执行计划,由预编译模块对语句进行处理并生成查询规划,然后在合适的时间提交给系统处理执行,最后将执行结果返回给用户。
所以,SQLServer中影响查询效率的因素主要有以下几种:1.没有索引或者没有用到索引。
索引是数据库中重要的数据结构,使用索引的目的是避免全表扫描,减少磁盘I/O,以加快查询速度。
2.没有创建计算列导致查询不优化。
3.查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)。
4.返回了不必要的行和列。
5.查询语句不好,没有优化。
其中包括:查询条件中操作符使用是否得当;查询条件中的数据类型是否兼容;对多个表查询时,数据表的次序是否合理;多个选择条件查询时,选择条件的次序是否合理;是否合理安排联接选择运算等。
SQLServer数据查询优化方法1、避免使用不兼容的数据类型。
例如float和int、char和varchar、binary和varbinary 是不兼容的。
数据类型的不兼容可能使优化器无法执行一些本来可以进行的优化操作。
例如: select name from employee where salary >60000在这条语句中,如salary字段是money型的,则优化器很难对其进行优化,因为60000是个整型数。
我们应当在编程时将整型转化成为钱币型,而不要等到运行时转化。
2、尽量避免在where子句中对字段进行函数或表达式操作,这将导致引擎放弃使用索引而进行全表扫描。
如:select * from t1 where f1/2=100应改为:select * from t1 where f1=100*2select * from record where substring(card_no,1,4)=‟5378‟应改为:select * from record where card_n o like …5378%‟select member_number, first_name, last_name from memberswhere datediff(yy,datofbirth,getdate()) > 21应改为:select member_number, first_name, last_name from memberswhere dateofbirth < dateadd(yy,-21,getdate())即:任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
3、避免使用!=或<>、is null或is not null、in ,not in等这样的操作符,因为这会使系统无法使用索引,而只能直接搜索表中的数据。
例如:select id from employee where id != b%优化器将无法通过索引来确定将要命中的行数,因此需要搜索该表的所有行。
4、尽量使用数字型字段,一部分开发人员和数据库管理人员喜欢把包含数值信息的字段设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
这是因为引擎在处理查询和连接回逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
5、合理使用exists,not exists子句。
如下所示:1.select sum(t1.c1)from t1 where((select count(*)from t2 where t2.c2=t1.c2>0)2.select sum(t1.c1) from t1where exists(select * from t2 where t2.c2=t1.c2)两者产生相同的结果,但是后者的效率显然要高于前者。
因为后者不会产生大量锁定的表扫描或是索引扫描。
如果你想校验表里是否存在某条纪录,不要用count(*)那样效率很低,而且浪费服务器资源。
可以用exists代替。
如:if (select count(*) from table_name where column_name = xxx)可以写成:if exists (select * from table_name where column_name = xxx)6、尽量避免在索引过的字符数据中,使用非打头字母搜索。
这也使得引擎无法利用索引。
见如下例子:select * from t1 where name like …%l%‟select * from t1 where substing(name,2,1)=‟l‟select * from t1 where name like …l%‟即使name字段建有索引,前两个查询依然无法利用索引完成加快操作,引擎不得不对全表所有数据逐条操作来完成任务。
而第三个查询能够使用索引来加快操作。
7、分利用连接条件,在某种情况下,两个表之间可能不只一个的连接条件,这时在where 子句中将连接条件完整的写上,有可能大大提高查询速度。
例:select sum(a.amount) from account a,card b where a.card_no = b.card_noselect sum(a.amount) from account a,card b where a.card_no = b.card_no and a.account_no=b.account_no第二句将比第一句执行快得多。
8、消除对大型表行数据的顺序存取尽管在所有的检查列上都有索引,但某些形式的where子句强迫优化器使用顺序存取。
如:select * from orders where (customer_num=104 and order_num>1001) ororder_num=1008解决办法可以使用并集来避免顺序存取:select *from orders where customer_num=104 and order_num>1001unionselect *from orders where order_num=1008这样就能利用索引路径处理查询。
9、避免困难的正规表达式like关键字支持通配符匹配,技术上叫正规表达式。
但这种匹配特别耗费时间。
例如:select * from customer where zipcode like “98_ _ _”即使在zipcode字段上建立了索引,在这种情况下也还是采用顺序扫描的方式。
如果把语句改为select *from customer where zipcode >“98000”,在执行查询时就会利用索引来查询,显然会大大提高速度。
10、使用视图加速查询把表的一个子集进行排序并创建视图,有时能加速查询。
它有助于避免多重排序操作,而且在其他方面还能简化优化器的工作。
例如:select ,rcvbles.balance,……other columnsfrom cust,rcvbleswhere cust.customer_id = rcvlbes.customer_idand rcvblls.balance>0and cust.postcode>“98000”order by 如果这个查询要被执行多次而不止一次,可以把所有未付款的客户找出来放在一个视图中,并按客户的名字进行排序:create view dbo.v_cust_rcvlbesasselect ,rcvbles.balance,……other columnsfrom cust,rcvbleswhere cust.customer_id = rcvlbes.customer_idand rcvblls.balance>0order by 然后以下面的方式在视图中查询:select *from v_cust_rcvlbeswhere postcode>“98000”视图中的行要比主表中的行少,而且物理顺序就是所要求的顺序,减少了磁盘i/o,所以查询工作量可以得到大幅减少。
11、能够用between的就不要用inselect * from t1 where id in (10,11,12,13,14)改成:select * from t1 where id between 10 and 14因为in会使系统无法使用索引,而只能直接搜索表中的数据。
12、 distinct的就不用group byselect orderid from details where unitprice > 10 group by orderid可改为:select distinct orderid from details where unitprice > 1013、部分利用索引1.select employeeid, firstname, lastnamefrom nameswhere dept = prod or city = orlando or division = food2.select employeeid, firstname, lastname from names where dept = prod union allselect employeeid, firstname, lastname from names where city = orlando union allselect employeeid, firstname, lastname from names where division = food如果dept 列建有索引则查询2可以部分利用索引,查询1则不能。