数据结构习题课7
南邮陈慧南版数据结构课后习题答案
}
65
if (p==root) root=root->lchild;
else q->rchild=p->lchild;
37
e=p->element;
25
delete p;
return true;
14
32
}
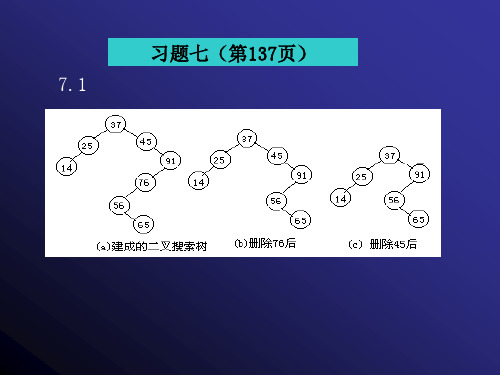
7.8 以下列序列为输入,从空树开始构造AVL搜索树。 (1)A,Z,B,Y,C,X (2)A,V,L,T,R,E,I,S,O,K
int i,j,top=-1; //top为栈顶元素的下标 ENode<T> *p; for(i=0; i<n; i++)
if(!InDegree[i]) {
F
B
A
FB
A
E
E
G
D
C
GD
C
Void LinkedGraph<T>::DFS1(int v,bool visited[],int parent[])
{ Enode *w; visited[v]=true; for(w=g.firstarc; w; w=w->nextarc) if(!visited[w->adjvex]) { DFS1(w->adjvex,visited,parent) parent[w->adjvex]=v; }
{ q.DeQueue(v);
//队首元素出队
for (w=a[v];w;w=w->nextarc)
if (! visited[w->adjvex])
{ cout <<“ “<< w->adjvex;
visited [w->adjvex]=true;
《数据结构》第二版严蔚敏课后习题作业参考答案(1-7章)

第1章4.答案:(1)顺序存储结构顺序存储结构是借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系,通常借助程序设计语言的数组类型来描述。
(2)链式存储结构顺序存储结构要求所有的元素依次存放在一片连续的存储空间中,而链式存储结构,无需占用一整块存储空间。
但为了表示结点之间的关系,需要给每个结点附加指针字段,用于存放后继元素的存储地址。
所以链式存储结构通常借助于程序设计语言的指针类型来描述。
5. 选择题(1)~(6):CCBDDA6.(1)O(1) (2)O(m*n) (3)O(n2)(4)O(log3n) (5)O(n2) (6)O(n)第2章1.选择题(1)~(5):BABAD (6)~(10):BCABD (11)~(15):CDDAC 2.算法设计题(1)将两个递增的有序链表合并为一个递增的有序链表。
要求结果链表仍使用原来两个链表的存储空间, 不另外占用其它的存储空间。
表中不允许有重复的数据。
[题目分析]合并后的新表使用头指针Lc指向,pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点,从第一个结点开始进行比较,当两个链表La和Lb均为到达表尾结点时,依次摘取其中较小者重新链接在Lc表的最后。
如果两个表中的元素相等,只摘取La表中的元素,删除Lb表中的元素,这样确保合并后表中无重复的元素。
当一个表到达表尾结点,为空时,将非空表的剩余元素直接链接在Lc表的最后。
void MergeList(LinkList &La,LinkList &Lb,LinkList &Lc){//合并链表La和Lb,合并后的新表使用头指针Lc指向pa=La->next; pb=Lb->next;//pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点Lc=pc=La; //用La的头结点作为Lc的头结点while(pa && pb){ if(pa->data<pb->data){pc->next=pa; pc=pa; pa=pa->next;}//取较小者La中的元素,将pa链接在pc的后面,pa指针后移else if(pa->data>pb->data) {pc->next=pb; pc=pb; pb=pb->next;}//取较小者Lb中的元素,将pb链接在pc的后面,pb指针后移else //相等时取La中的元素,删除Lb中的元素{pc->next=pa;pc=pa;pa=pa->next;q=pb->next; delete pb ; pb =q;}}pc->next=pa?pa:pb; //插入剩余段delete Lb; //释放Lb的头结点}(5)设计算法将一个带头结点的单链表A分解为两个具有相同结构的链表B、C,其中B表的结点为A表中值小于零的结点,而C表的结点为A表中值大于零的结点(链表A中的元素为非零整数,要求B、C表利用A表的结点)。
《数据结构》第二版严蔚敏课后习题作业参考答案(1-7章)

《数据结构》第二版严蔚敏课后习题作业参考答案(1-7章)【第一章绪论】1. 数据结构是计算机科学中的重要基础知识,它研究的是如何组织和存储数据,以及如何通过高效的算法进行数据的操作和处理。
本章主要介绍了数据结构的基本概念和发展历程。
【第二章线性表】1. 线性表是由一组数据元素组成的数据结构,它的特点是元素之间存在着一对一的线性关系。
本章主要介绍了线性表的顺序存储结构和链式存储结构,以及它们的操作和应用。
【第三章栈与队列】1. 栈是一种特殊的线性表,它的特点是只能在表的一端进行插入和删除操作。
本章主要介绍了栈的顺序存储结构和链式存储结构,以及栈的应用场景。
2. 队列也是一种特殊的线性表,它的特点是只能在表的一端进行插入操作,而在另一端进行删除操作。
本章主要介绍了队列的顺序存储结构和链式存储结构,以及队列的应用场景。
【第四章串】1. 串是由零个或多个字符组成的有限序列,它是一种线性表的特例。
本章主要介绍了串的存储结构和基本操作,以及串的模式匹配算法。
【第五章数组与广义表】1. 数组是一种线性表的顺序存储结构,它的特点是所有元素都具有相同数据类型。
本章主要介绍了一维数组和多维数组的存储结构和基本操作,以及广义表的概念和表示方法。
【第六章树与二叉树】1. 树是一种非线性的数据结构,它的特点是一个节点可以有多个子节点。
本章主要介绍了树的基本概念和属性,以及树的存储结构和遍历算法。
2. 二叉树是一种特殊的树,它的每个节点最多只有两个子节点。
本章主要介绍了二叉树的存储结构和遍历算法,以及一些特殊的二叉树。
【第七章图】1. 图是一种非线性的数据结构,它由顶点集合和边集合组成。
本章主要介绍了图的基本概念和属性,以及图的存储结构和遍历算法。
【总结】1. 数据结构是计算机科学中非常重要的一门基础课程,它关注的是如何高效地组织和存储数据,以及如何通过算法进行数据的操作和处理。
本文对《数据结构》第二版严蔚敏的课后习题作业提供了参考答案,涵盖了第1-7章的内容。
数据结构课后习题答案第七章
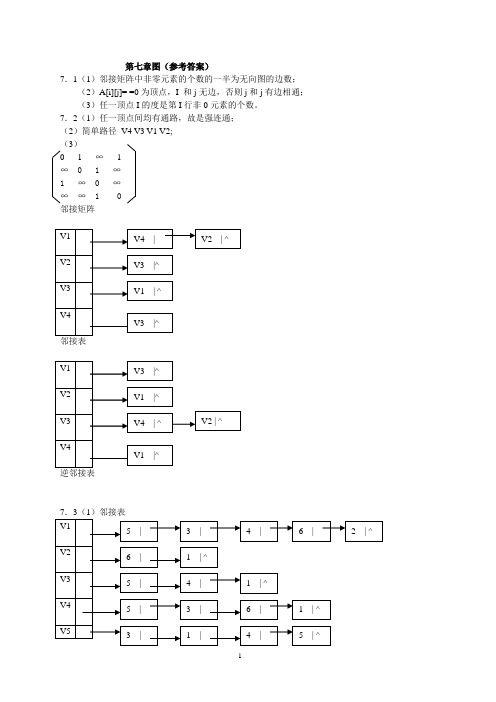
第七章图(参考答案)7.1(1)邻接矩阵中非零元素的个数的一半为无向图的边数;(2)A[i][j]= =0为顶点,I 和j无边,否则j和j有边相通;(3)任一顶点I的度是第I行非0元素的个数。
7.2(1)任一顶点间均有通路,故是强连通;(2)简单路径V4 V3 V1 V2;(3)0 1 ∞ 1∞ 0 1 ∞1 ∞ 0 ∞∞∞ 1 0邻接矩阵邻接表(2)从顶点4开始的DFS序列:V5,V3,V4,V6,V2,V1(3)从顶点4开始的BFS序列:V4,V5,V3,V6,V1,V27.4(1)①adjlisttp g; vtxptr i,j; //全程变量② void dfs(vtxptr x)//从顶点x开始深度优先遍历图g。
在遍历中若发现顶点j,则说明顶点i和j间有路径。
{ visited[x]=1; //置访问标记if (y= =j){ found=1;exit(0);}//有通路,退出else { p=g[x].firstarc;//找x的第一邻接点while (p!=null){ k=p->adjvex;if (!visited[k])dfs(k);p=p->nextarc;//下一邻接点}}③ void connect_DFS (adjlisttp g)//基于图的深度优先遍历策略,本算法判断一邻接表为存储结构的图g种,是否存在顶点i //到顶点j的路径。
设 1<=i ,j<=n,i<>j.{ visited[1..n]=0;found=0;scanf (&i,&j);dfs (i);if (found) printf (” 顶点”,i,”和顶点”,j,”有路径”);else printf (” 顶点”,i,”和顶点”,j,”无路径”);}// void connect_DFS(2)宽度优先遍历全程变量,调用函数与(1)相同,下面仅写宽度优先遍历部分。
大学课程《数据结构》课后习题答案

大学课程《数据结构》课后习题答案第 1 章绪论课后习题讲解1.填空⑴()是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。
【解答】数据元素⑵()是数据的最小单位,()是讨论数据结构时涉及的最小数据单位。
【解答】数据项,数据元素【分析】数据结构指的是数据元素以及数据元素之间的关系。
⑶ 从逻辑关系上讲,数据结构主要分为()、()、()和()。
【解答】集合,线性结构,树结构,图结构⑷ 数据的存储结构主要有()和()两种基本方法,不论哪种存储结构,都要存储两方面的内容:()和()。
【解答】顺序存储结构,链接存储结构,数据元素,数据元素之间的关系⑸ 算法具有五个特性,分别是()、()、()、()、()。
【解答】有零个或多个输入,有一个或多个输出,有穷性,确定性,可行性⑹ 算法的描述方法通常有()、()、()和()四种,其中,()被称为算法语言。
【解答】自然语言,程序设计语言,流程图,伪代码,伪代码⑺在一般情况下,一个算法的时间复杂度是()的函数。
【解答】问题规模⑻ 设待处理问题的规模为n,若一个算法的时间复杂度为一个常数,则表示成数量级的形式为(),若为n*log25n,则表示成数量级的形式为()。
【解答】Ο(1),Ο(nlog2n)【分析】用大O 记号表示算法的时间复杂度,需要将低次幂去掉,将最高次幂的系数去掉。
2.选择题⑴ 顺序存储结构中数据元素之间的逻辑关系是由()表示的,链接存储结构中的数据元素之间的逻辑关系是由()表示的。
A 线性结构B 非线性结构C 存储位置D 指针【解答】C,D【分析】顺序存储结构就是用一维数组存储数据结构中的数据元素,其逻辑关系由存储位置(即元素在数组中的下标)表示;链接存储结构中一个数据元素对应链表中的一个结点,元素之间的逻辑关系由结点中的指针表示。
⑵ 假设有如下遗产继承规则:丈夫和妻子可以相互继承遗产;子女可以继承父亲或母亲的遗产;子女间不能相互继承。
则表示该遗产继承关系的最合适的数据结构应该是()。
数据结构 习题课

算 法
练习5 若已知非空线性链表第一个结点的指针为list, 请 写一个算法, 将该链表中数据域值最小的那个 移到链表的最前端。
list
35 67 18
…
52
10
14
71
…
82
65
q
p
^
list=q;
list
35 67 18
s->link=q->link;
…
52 10 14 71
…
82
65
s
q
^
(删除表中第i元素)
寻找满足条件的元素,即从表中第一个 元素开始到最后那个元素,反复比较相邻的 两个元素是否相同,若相同,删除其中一个, 否则,比较下一对相邻元素。
for(j=i+1; j<n; j++) A[j−1]=A[j]; n--;
(删除表中第i元素)
void DEL( ElemType A[ ], int &n ) { int j, i=0; 比较相邻元素 while(i<n-1) if(A[i]!=A[i+1]) i++; else { for(j=i+1; j<n; j++) A[j−1]=A[j]; n– – ; } } 删除一个元素
list
35 68 59 28
q->link=list;
… q p r r sp qp
r=p; p=p->link;
void REMOVE(LinkList &list ) { 算法 LinkList q=list,s,r; p=list → link; r=list; while (p!=NULL) { if (p→data<q→data) then 寻找值最小结点 { s=r; q=p; } r=p; O (链表长度) p=p→link; // 找到值最小的那个结点 ,地址由q记录 // } if (q!=list) then // 若值最小的结点不是链表最前面那个结点 // { s→link=q→link; q→link=list; list=q ; list s q } } … … 28 39 35 82
数据结构教程李春葆课后答案第7章树和二叉树

教材中练习题及参考答案
1. 有一棵树的括号表示为 A(B,C(E,F(G)),D),回答下面的问题: (1)指出树的根结点。 (2)指出棵树的所有叶子结点。 (3)结点 C 的度是多少? (4)这棵树的度为多少? (5)这棵树的高度是多少? (6)结点 C 的孩子结点是哪些? (7)结点 C 的双亲结点是谁? 答:该树对应的树形表示如图 7.2 所示。 (1)这棵树的根结点是 A。 (2)这棵树的叶子结点是 B、E、G、D。 (3)结点 C 的度是 2。 (4)这棵树的度为 3。 (5)这棵树的高度是 4。 (6)结点 C 的孩子结点是 E、F。 (7)结点 C 的双亲结点是 A。
12. 假设二叉树中每个结点值为单个字符,采用二叉链存储结构存储。设计一个算法 计算一棵给定二叉树 b 中的所有单分支结点个数。 解:计算一棵二叉树的所有单分支结点个数的递归模型 f(b)如下:
f(b)=0 若 b=NULL
6 f(b)=f(b->lchild)+f(b->rchild)+1 f(b)=f(b->lchild)+f(b->rchild)
表7.1 二叉树bt的一种存储结构 1 lchild data rchild 0 j 0 2 0 h 0 3 2 f 0 4 3 d 9 5 7 b 4 6 5 a 0 7 8 c 0 8 0 e 0 9 10 g 0 10 1 i 0
答:(1)二叉树bt的树形表示如图7.3所示。
a b c e h j f i d g e h j c f i b d g a
对应的算法如下:
void FindMinNode(BTNode *b,char &min) { if (b->data<min) min=b->data; FindMinNode(b->lchild,min); //在左子树中找最小结点值 FindMinNode(b->rchild,min); //在右子树中找最小结点值 } void MinNode(BTNode *b) //输出最小结点值 { if (b!=NULL) { char min=b->data; FindMinNode(b,min); printf("Min=%c\n",min); } }
数据结构课程课后习题集答案解析

《数据结构简明教程》练习题及参考答案练习题11. 单项选择题(1)线性结构中数据元素之间是()关系。
A.一对多B.多对多C.多对一D.一对一答:D(2)数据结构中与所使用的计算机无关的是数据的()结构。
A.存储B.物理C.逻辑D.物理和存储答:C(3)算法分析的目的是()。
A.找出数据结构的合理性B.研究算法中的输入和输出的关系C.分析算法的效率以求改进D.分析算法的易懂性和文档性答:C(4)算法分析的两个主要方面是()。
A.空间复杂性和时间复杂性B.正确性和简明性C.可读性和文档性D.数据复杂性和程序复杂性答:A(5)计算机算法指的是()。
A.计算方法B. 排序方法C.求解问题的有限运算序列D.调度方法答:C(6)计算机算法必须具备输入、输出和()等5个特性。
A.可行性、可移植性和可扩充性B.可行性、确定性和有穷性C.确定性、有穷性和稳定性D.易读性、稳定性和安全性答:B2. 填空题(1)数据结构包括数据的①、数据的②和数据的③这三个方面的内容。
答:①逻辑结构②存储结构③运算(2)数据结构按逻辑结构可分为两大类,它们分别是①和②。
答:①线性结构②非线性结构(3)数据结构被形式地定义为(D,R),其中D是①的有限集合,R是D上的②有限集合。
答:①数据元素②关系数据结构简明教程(4)在线性结构中,第一个结点 ① 前驱结点,其余每个结点有且只有1个前驱结点;最后一个结点 ② 后继结点,其余每个结点有且只有1个后继结点。
答:①没有 ②没有 (5)在树形结构中,树根结点没有 ① 结点,其余每个结点有且只有 ② 个前驱结点;叶子结点没有 ③ 结点,其余每个结点的后继结点数可以是 ④ 。
答:①前驱 ②1 ③后继 ④任意多个(6)在图形结构中,每个结点的前驱结点数和后继结点数可以是( )。
答:任意多个(7)数据的存储结构主要有四种,它们分别是 ① 、 ② 、 ③ 和 ④ 存储结构。
答:①顺序 ②链式 ③索引 ④哈希(8)一个算法的效率可分为 ① 效率和 ② 效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
C++
int h[MAXN]; int n=0; void insert(x) {
h[++n]=x; for(int j=n;j>1;j>>=1)//上浮
if(a[j] > a[j>>1]) swap(a[j], a[j>>1]); }
7-36
文件(R1,R2,…,Rn)是一个堆,1≤i≤n, 请给出一个算法,该算法从(R1,R2,…, Rn)中删除 Ri,使删除后的文件仍然是堆 ,要求算法的时间复杂度为O(log2n) .
参考答案
当 n/2 >=M,才会在辅助堆栈中压入第1个元素 当n/(22)>=M,才会在辅助堆栈中压入第2个元素 ……,依此类推, 当n/(2k)>=M,才会在辅助堆栈中压入第k个元素 则 2k <= n/M. k<=log2(n/M) 因此最多为 floor ( log2(n/M)) 个
1)*(n/2+1)次.每次比较都交换,总交换次数为
(n-1)*n/2 或 (n-1)*3n/2 .
//逆序
(3)最好时间O(n)
最坏时间O(n2)
平均时间O(n2) (书上P201反序对的平均数)
正确性证明:数学归纳法
对元素个数n进行归纳
当n=1是,算法正确
假设当n<=k时,算法能对n个元素的数组进行 排序,则当n=k+1时,进行一趟分划后,轴心元 素R[s]进入了最终排序应在的位置R[i],即R[i] 之前的元素R[s]~R[i-1]都小于等于R[i],R[i]之 后的元素R[i+1]~R[e]都大于等于R[i]。由于 R[s]~R[i-1],R[i+1]~R[e]任意一部分最多为k个 ,按照假设,都能正确排序。因此,该算法能 对全部k+1个元素正确排序。
( j←j-1.
while ② do j←j-1.
if (i≥j) then j←i.
else (Ri ←Rj. i=i+1.
PA3
while Ki<K do i ←i+1. if ③ then Rj ←Ri.)). ④▌
Kj≥K
i<j Rj←R
7-26
分析算法HSort中的堆栈S可能包含的最大元 素个数(表示成M和n的函数)。
比赛树高为k。由2K-1<n<=2k ,即形成的树高为log2n .
,得log2n<=k<log2n+1
7-35
设文件(R1,R2,…,Rn)是一个堆,Rn+1是 任意一个结点。请设计一个算法,该算法把 Rn+1添加到堆(R1,R2,…,Rn)中,并使 (R1,R2,…,Rn,Rn+1)成为一个堆(要求 算法的时间复杂度为O(log2n) ).
7-24
填充如下排序算法中的方框,并证明该算法的 正确性. (实质是一趟快速排序算法)
算法PartA(R,s,e)
//分划文件(Rs,Rs+1,…,Re),且Ks-1=-∞,Ke+1=+∞
PA1[初始化]
i ←s. j ← ① .
K ←Ks. R ←Rs.
e+1
PA2[分划过程]
while i<j do
算法InsertSort(FIRST. FIRST) /*对单链表直接插入排序, FIRST指向表头结点*/
IS1[边界] IF(LINK(FIRST)=NULL OR LINK(LINK(FIRST))=NULL ) THEN RETRUN.
IS2[插入排序] q ← LINK(FIRST). q0 ←LINK(q). WHILE(q<>NULL)( p← LINK(FIRST). p0 ← FIRST. WHILE(KEY(p)<=KEY(q) AND LINK(p)<>q) DO (p0←p.p←LINK(p).). IF(KEY(p) > KEY(q) ) THEN( LINK(q0)←LINK(q).LINK(p0) ←q. LINK(q) ←p. q ←LINK(q0).). ESLE (q0 ←q. q ←LINK(q0).). )▌
(3)与简单选择排序相比,比较次数增加,移 动次数减少。整体上时间效率要低于简单选择 排序,辅助空间要高于简单选择排序。
数据结构习题 第 7 章
吉林大学计算机科学与技术学院 谷方明
第7章作业
247页:每组的第1题是必交的, 即7-2、7-5、7-18、7-24、7-49
7-2、7-3、 7-5、7-8、7-10、 7-18、 7-24、7-26、7-30、7-31、7-35、7-36 7-49、7-50
分析:堆有大根堆和小根堆。教材上用的是大 根堆。
参考答案
算法Insert (R,n,x.R,n) /*在堆中插入元素x,从下往上调整堆*/ U1 [x放入R[n+1]]
n ← n+1. R[n] ←x. U2 [从下往上调整,称上浮]
i←n. WHILE(i>1 AND R[i/2]<R[i]) DO i ← i/2. ▌
参考答案
算法Delete(R,n,i.R,n) /*在堆中删除元素R[i],从上往下调整堆*/ D1 [R[i]与R[n]交换]
R[i] ←R[n]. n ← n-1. D2 [从上往下调整,称下沉]
j←i. WHILE(2*j<=n AND R[2*j]>R[j] OR
2*j+1<=n AND R[2*j+1]>R[j] ) DO( y ←2*j. IF(2*j+1<=n AND R[2*j+1]>R[2*j] ) THEN y ←y+1. R[j]↔ R[y]. j ←y. )▌
参考答案
证明:
当n=2K时,第1轮后剩下n/2=2K-1 ,第二轮后剩下 n/4=2K-2 ,依次类推, 第k轮淘汰赛后就剩下1个选手,
就是最大元素。每一轮淘汰赛都对应比赛树中的一层
,因此当n=2K时,比赛树的最大层数是k,比赛树的
高度是log2n
当n为任意数时,总可以找到一个k,使得2K-
1<n<=2k,只需要k轮淘汰赛就可以最大元素,对应的
7-30
证明:用淘汰赛找n个元素的最大元素正好需 要n–1次元素比较。
参考答案
证明:在淘汰赛中,每进行一场比赛,即进行 依次比较,都恰淘汰1个元素,找到最大元素 需要淘汰n-1个元素,因此需要n-1比较。
7-31
证明:用淘汰赛找 n个元素的最大元素所形成 的树高为log2n .
(1) 给出适用于计数排序的数据表定义。 (2) 对于有n个记录的表,关键词比较次数是多少? (3) 与简单选择排序相比较,这种方法是否更好?为什么?
参考答案
(1) 数据表放在数组R中,元素个数为n ,下标 从0开始(因为小于关键词的个数为c,就放在c 的位置)。
(2) 对于每个记录,扫描待排序的表一趟,即 比较n次。一共n个记录,共需比较n2次。
7-49
填充如下排序算法中的方框,并讨论该算法的 稳定性.
算法C(R,n)
/*比较计数,本算法按关键词K1,K2,…,Kn排序记 录R1,R2,…,Rn . 一维数组COUNT[1 : n]用来记 录各个记录的排序位置*/
count[i] ←1
[C1] FOR i=1 TO n DO ① .
WHILE i<j DO ( WHILE Ki<0 AND i<j DO i←i+1 . WHILE Kj >0 AND i<j DO j←j–1. IF i<j THEN Ri Rj .) ▌
7-8
讨论冒泡排序算法的稳定性。
参考答案
冒泡排序中,每一趟冒泡,相邻的关键词只有 满足(Rj>Rj+1)时才会发生交换,关键词相同 的记录不会发生交换,即相同位置不变,因此 是冒泡排序算法是稳定的。
(1)排序的终止条件是什么?
(2)完成该算法的具体设计. (3)分析该算法的平均运行时间.
算法Sort(X,n) S1[一趟扫描过程中,均没有记录交换则算法终止]
change ← 1. while (change) (change ← 0.
for i ← 1 to n-1 step 2 //奇交换 if (X[i].key>X[i+1].key) ( X[i] X[i+1]. change ← 1.)
即所有记录已经进入最终排序位置。
7-18
奇偶交换排序算法的基本思想描述如下:排序 过程通过对文件x[i](l≤i≤n)的若干次扫描来完 成,第奇数次扫描,对所有下标为奇数的记录 x[i]与其后面的记录x[i+1](l≤ i≤ n–1)相比较, 若x[i].KEY>x[i+1].KEY,则交换x[i]和x[i+1] 的内容;第偶数次扫描,对所有下标为偶数的 记录x[i]与其后面的记录x[i+1](2≤i≤n–1)相比较 ,若x[i].KEY>x[i+1]. KEY,则交换x[i]和 x[i+1]之内容,重复上述过程直到排序完成为 止.
C++
int h[MAXN]; int n=0; void delete(int i) {
h[i]=h[n--]; while(2*i<=n && h[2*i] > h[i] || 2*i+1<=n && h[2*i+1]>h[i] ) int y=2*i;