人口预测中线性回归分析简单步骤
人口预测的数学模型与预测方法分析

人口预测的数学模型与预测方法分析人口预测是对未来一定时期内人口数量和结构的变动进行估计和预测的过程。
人口预测在社会经济发展规划、城市规划、教育医疗资源配置等方面具有重要的参考价值。
为了准确预测人口的变动趋势,需要建立合理的数学模型和选择适当的预测方法。
人口预测的数学模型主要包括线性回归模型、指数模型、Logistic模型等。
线性回归模型是一种用来描述两个变量之间线性关系的统计模型,可以用来预测人口随时间的变化。
指数模型假设人口数量按照指数规律增长或减少,适用于人口增长较快的情况。
Logistic模型则适用于人口增长速度放缓后的情况,它是一种描述增长速度逐渐趋近于饱和的模型。
在选择数学模型时,需要综合考虑以下几个因素:人口历史变动趋势、人口自然增长率、人口迁移和流动情况、政策调控等因素。
同时,还需根据实际情况对模型的参数进行合理的设定和修正,以提高预测的准确性。
在预测方法上,常用的有趋势线法、复合增长率法、比较推理法、时间序列分析法和系统动力学方法等。
趋势线法是基于历史数据的发展趋势来进行预测,适用于人口变动趋势比较稳定的情况。
复合增长率法是将历史数据中的增长率按一定规则进行加权平均,再用来推算未来人口的增长率。
比较推理法通过对不同因素的比较和推理,来估计未来人口的变化。
时间序列分析法是根据时间序列数据的历史模式来预测未来的变化趋势。
系统动力学方法则是通过对不同因素的动态关系建立模型,用来探索人口变动的内在机制和规律。
在具体应用时,可以结合不同的数学模型和预测方法,进行多角度的分析和预测。
同时,还需要不断对模型进行修正和优化,以适应不断变化的人口变动趋势和社会经济背景。
此外,还应该注意对预测结果的不确定性进行评估和把握,提供多种可能性的预测结果,为决策者提供科学的参考依据。
线性回归方程解题步骤

线性回归方程解题步骤引言:线性回归是一种常见的统计分析方法,用于建立自变量与因变量之间的关系。
在许多实际问题中,我们需要通过线性回归方程来预测因变量的值。
本文将介绍线性回归方程的解题步骤,帮助读者更好地理解和应用这一方法。
一、收集数据:在开始解决线性回归方程问题之前,我们首先需要收集相关的数据。
这些数据应包含两个变量:自变量和因变量。
自变量是我们希望用来预测因变量的变量,而因变量是我们希望预测的变量。
例如,我们希望通过一个人的年龄来预测其收入,那么年龄就是自变量,收入就是因变量。
二、绘制散点图:收集到数据后,我们需要绘制散点图来观察自变量和因变量之间的关系。
散点图是一种将自变量和因变量的取值用点标出的图表,可以直观地反映二者之间的关系。
通过观察散点图,我们可以初步判断自变量和因变量之间是否存在线性关系。
三、确定最佳拟合直线:在线性回归中,我们希望找到一组参数,使得自变量和因变量之间的线性关系最好地被拟合。
最常用的拟合方法是最小二乘法,即通过最小化误差平方和来确定最佳拟合直线。
误差是指实际观测值与拟合值之间的差异。
通过最小二乘法,我们可以得到最佳拟合直线的参数,也就是线性回归方程的系数。
四、求解线性回归方程:得到最佳拟合直线的参数后,我们就可以得到线性回归方程。
线性回归方程的一般形式为:Y = aX + b,其中Y是因变量,X是自变量,a和b分别是线性回归方程的系数。
我们可以根据最佳拟合直线的参数来确定线性回归方程的具体形式。
五、进行预测:有了线性回归方程后,我们可以通过输入自变量的取值来预测因变量的值。
通过代入自变量的值到线性回归方程中,我们可以得到对应的因变量的预测值。
这样,我们就可以利用线性回归方程进行预测和分析。
六、评估回归模型:在进行线性回归分析后,我们需要对回归模型进行评估,以确定其在实际应用中的有效性和准确性。
常用的评价指标包括残差分析、确定系数(R²)和假设检验等。
残差分析用于检验回归模型是否符合一些基本的假设,如误差项的正态性和方差齐性。
线性回归分析的基本步骤
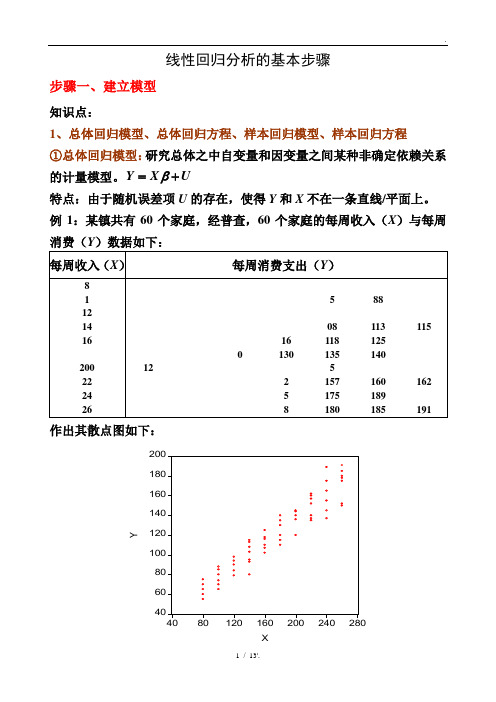
线性回归分析的基本步骤步骤一、建立模型知识点:1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。
Y X U β=+特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。
例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周消费(Y )数据如下:作出其散点图如下:②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。
总体回归方程的求法:以例1的数据为例 由于01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。
如将()()222777100,|77200,|137X E Y X X E Y X ====和代入()01|i i i E Y X X ββ=+可得:01001177100171372000.6ββββββ=+=⎧⎧⇒⎨⎨=+=⎩⎩以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为:③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。
如在例1中,通过抽样考察,我们得到了20个家庭的样本数据:那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型ˆY X e β=+就称为样本回归模型。
④样本回归方程(线):通过样本数据估计出ˆβ,得到样本观测值的拟合值与解释变量之间的关系方程ˆˆY X β=称为样本回归方程。
如下图所示:⑤四者之间的关系:ⅰ:总体回归模型建立在总体数据之上,它描述的是因变量Y 和自变量X 之间的真实的非确定型依赖关系;样本回归模型建立在抽样数据基础之上,它描述的是因变量Y 和自变量X 之间的近似于真实的非确定型依赖关系。
人口增长趋势预测数据分析

人口增长趋势预测数据分析
首先,需要收集历史上的人口数据。
这些数据通常包括每年的人口数量、出生率、死亡率和迁移率等指标。
可以通过查阅历史文献、民政统计年鉴等途径获取这些数据。
接下来,可以利用统计学方法分析这些数据。
常见的方法包括线性回归、指数平滑、时间序列分析等。
线性回归可以用来研究人口数量与时间的关系,从而预测未来的人口数量。
指数平滑则可以通过对历史数据的平滑处理,得到未来人口数量的估计。
时间序列分析结合历史数据和时间的相关性,可以对未来的人口增长进行模型建立和预测。
在进行数据分析时,还需要考虑一些其他因素的影响。
例如,经济发展、社会政策、教育水平等都可能对人口增长有重要的影响。
因此,需要综合考虑这些因素,并在模型中加以考虑。
此外,为了得到更准确的结果,可以采用多种方法进行验证和比较。
例如,可以将数据分为训练集和测试集,使用训练集建立模型,然后用测试集验证模型的预测效果。
还可以使用多个不同的模型进行比较,选择最合适的模型。
最后,通过对人口增长趋势进行数据分析,可以得到未来人口数量的预测结果。
这些预测结果可以提供给政府部门和决策者,以指导人口政策的制定和实施。
需要注意的是,人口增长趋势预测是一个复杂的问题,受到多种因素的影响。
因此,在进行数据分析和预测时,需要慎重考虑,综合利用多种方法和数据,以提供尽可能准确和可靠的结果。
此外,还需要不断更新数据和模型,以应对社会和经济变化对人口增长趋势的影响。
人口预测中线性回归分析简单步骤

人口预测中线性回归分析简单步骤:
一、进行回归分析
SPSS-regression-linear
Dependent ——因变量这里应该为人口
Independent ——自变量这里可以为年份,也可以为GDP或其他认为可以引起人口变动的自变量
用箭头添加到相应的框中,然后点击ok,生成结果。
二、结果检验
Model Summary
a Predictors: (Constant), V1
R2=0.11,模型拟合效果不好(此数应该越接近1越好,如果在0.7以上均可认为模型拟合效果较好)
ANOVA(b)
a Predictors: (Constant), V1
b Dependent Variable: V2
sig=0.771,模型线性特征不显著(如果该值小于0.05,可认为线性关系较为显著)
Coefficients(a)
a Dependent Variable: V2
每个参数的sig分别为0.772和0.771,表示参数也不显著(如果该值小于0.05,可认为线性关系较为显著)
列出的一元一次方程为y=88.709x-176626.982。
将x=??带入方程,得到y=??,则??年人口为??。
但由于未通过显著性检验,模型拟合效果也不好,所以该方法预测的结果应当去掉。
(这里如果前面的拟合度和显著性检验效果均较好的话,就应当保留该方法预测的结果。
线性回归分析步骤

线性回归分析步骤线性回归分析是一种统计学方法,用于确定两个变量之间的线性关系。
它可以用于预测特定的变量,并估计它们之间的关系。
它也可以用于识别影响变量的其他因素,以验证假设。
线性回归是定量分析的一个重要方面,可以帮助研究人员更好地理解数据,并从中得出有意义的结论。
本文将介绍线性回归分析的基本步骤,包括数据收集、数据分析、回归分析和结果解释。
首先,在进行线性回归分析之前,需要收集数据。
这可通过实验、观察、实地考察或从其他人获得这些资料。
通常,数据收集者需要有清晰的研究目的,确定有关数据的变量类型和范围,以及所涉及的样本大小。
收集的数据需要记录,以便进行数据分析的第二步。
接下来,需要对收集的数据进行分析。
其核心方法是计算两个变量之间的相关系数,以确定它们之间的线性关系。
如果两个变量之间呈线性关系,那么可以使用线性回归分析,以估计它们之间的相关性。
同时,在样本内可以应用其他技术,比如回归的分类、因变量的探索和多变量的线性回归分析,以帮助调查人员更好地理解数据。
第三步是实施回归分析,以估计变量之间的关系。
回归分析的过程包括选择回归模型、计算参数、检验模型好坏和比较模型之间的区别。
需要注意的是,计算参数时,应该考虑到所采用的统计方法,以确保结果的准确性。
最后,还需要解释结果,以获得有意义的结论。
结果解释可以采用模型诊断和参数检验的结果,以识别模型的弱点,并根据结果对结论进行调整。
另外,也可以检查预期的变量之间的联系,以及其他变量对模型结果的影响。
最后,可以利用结果改善和解释过程中的假设,以验证研究的可行性。
综上所述,线性回归分析是一种重要的定量分析技术,可以帮助研究人员更好地理解数据,以及从中得出有意义的结论。
它的基本步骤包括数据收集、数据分析、回归分析和结果解释。
在收集数据时,应记录所涉及的变量类型、范围和样本大小的信息;在进行数据分析时,要计算变量之间的相关系数;在运行回归分析时,应考虑回归模型、计算参数和检验模型的好坏;在解释结果时,应诊断模型弱点、检查预期变量及其他变量对模型结果的影响,以及利用结果改善和验证假设。
总结线性回归分析的基本步骤

总结线性回归分析的基本步骤线性回归分析是一种统计方法,用于研究两个或更多变量之间的关系。
它的基本思想是通过构建一个线性函数来描述因变量与自变量之间的关系,并使用最小二乘法估计未知参数。
下面是线性回归分析的基本步骤:1.收集数据:首先,我们需要收集有关自变量和因变量的数据。
这些数据可以通过实验、观察或调查获得。
数据应该涵盖自变量和因变量的所有可能值,并且应该尽可能全面和准确。
2.绘制散点图:一旦我们收集到数据,我们可以使用散点图来可视化自变量和因变量之间的关系。
散点图展示了每个观测值的自变量与相应因变量的值之间的关系图形。
通过观察散点图,我们可以初步判断变量之间的关系类型,如直线、曲线或没有明显关系。
3.选择模型:在进行线性回归分析之前,我们需要选择适当的模型。
线性回归模型的形式为Y=β0+β1X1+β2X2+...+βnXn+ε,其中Y是因变量,X1,X2,...Xn是自变量,β0,β1,β2,...βn是未知参数,ε是误差项。
我们假设因变量与自变量之间的关系是线性的。
4.估计参数:在线性回归模型中,我们的目标是估计未知参数β0,β1,β2,...βn。
我们使用最小二乘法来估计这些参数,最小二乘法的目标是通过最小化残差平方和来选择最佳拟合直线,使预测值与观测值之间的差异最小化。
5.评估模型:一旦我们估计出参数,我们需要评估模型的拟合程度。
常见的评估指标包括残差分析、方差分析、回归系数的显著性检验、确定系数和调整确定系数。
这些指标可以帮助我们判断模型的有效性和可靠性。
6.解释结果:在得到合理的回归模型之后,我们可以使用回归方程来进行预测和解释结果。
通过回归系数可以了解自变量对因变量的影响程度和方向。
同时,我们可以进行假设检验,确定哪些自变量对因变量是显著的。
7.模型修正和改进:一旦我们获得了回归模型,我们可以进一步修正和改进模型。
这可以通过添加更多的自变量或删除不显著的自变量来完成。
同时,我们还可以使用交互项、多项式项或转换变量来探索更复杂的关系。
总结:线性回归分析的基本步骤

线性回归分析的基本步骤步骤一、建立模型知识点:1、总体回归模型、总体回归方程、样本回归模型、样本回归方程①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。
Y X Uβ=+特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。
例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周消费(Y )数据如下:每周收入(X )每周消费支出(Y )805560657075 100657074808588 1207984909498 140809395103108113115160102107110116118125 180110115120130135140 200120136140144145 220135137140152157160162240137145155165175189 260150152175178180185191作出其散点图如下:②总体回归方程(线):由于假定,因此因变量的均值与自变0EU =量总处于一条直线上,这条直线就称为总体回归线(方()|E Y X X β=程)。
总体回归方程的求法:以例1的数据为例1)对第一个X i ,求出E (Y |X i )。
每周收入(X )每周消费支出(Y )E (Y |X i )805560657075 65100657074808588 771207984909498 89140809395103108113115101160102107110116118125 113180110115120130135140 125200120136140144145 137220135137140152157160162149240137145155165175189 161260150152175178180185191173由于()01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ一,并进而得到总体回归方程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
人口预测中线性回归分析简单步骤:
一、进行回归分析
SPSS-regression-linear
Dependent ——因变量这里应该为人口
Independent ——自变量这里可以为年份,也可以为GDP或其他认为可以引起人口变动的自变量
用箭头添加到相应的框中,然后点击ok,生成结果。
二、结果检验
Model Summary
a Predictors: (Constant), V1
R2=0.11,模型拟合效果不好(此数应该越接近1越好,如果在0.7以上均可认为模型拟合效果较好)
ANOVA(b)
a Predictors: (Constant), V1
b Dependent Variable: V2
sig=0.771,模型线性特征不显著(如果该值小于0.05,可认为线性关系较为显著)
Coefficients(a)
a Dependent Variable: V2
每个参数的sig分别为0.772和0.771,表示参数也不显著(如果该值小于0.05,可认为线性关系较为显著)
列出的一元一次方程为y=88.709x-176626.982。
将x=??带入方程,得到y=??,则??年人口为??。
但由于未通过显著性检验,模型拟合效果也不好,所以该方法预测的结果应当去掉。
(这里如果前面的拟合度和显著性检验效果均较好的话,就应当保留该方法预测的结果。