flink cdc 读取oralce 归档日志的原理
oracle 归档日志解析

oracle 归档日志解析摘要:一、归档日志概述二、归档日志的作用三、归档日志的解析方法四、归档日志解析的应用场景五、总结与建议正文:随着大数据时代的到来,Oracle 数据库归档日志在各行各业中发挥着越来越重要的作用。
本文将对归档日志进行简要概述,分析其作用,介绍解析方法,并讨论应用场景。
最后给出总结与建议。
一、归档日志概述Oracle 归档日志(Archive Log)是一种用于记录数据库事务日志的技术。
它可以将数据库中的更改操作(如插入、更新和删除)记录下来,以便在出现故障时恢复数据。
归档日志采用增量方式记录,即每次更改操作后,日志文件会逐步变大。
二、归档日志的作用1.数据恢复:归档日志可以在数据库发生故障时,用于恢复数据至故障发生前的状态。
2.数据审计:归档日志可以记录所有对数据库的更改操作,方便审计人员追溯和分析数据变更原因。
3.性能优化:通过分析归档日志,可以找出数据库性能瓶颈,为优化数据库性能提供依据。
三、归档日志解析方法1.手工解析:通过编写SQL 语句或使用第三方工具,查询归档日志文件内容,分析日志中的数据。
2.使用Oracle 提供的事件解析工具:如DBMS_LOGSTD.REPORT 等,可以方便地生成归档日志的报表和统计数据。
3.使用第三方归档日志分析工具:如Oracle 的Partner 产品OraInsight 等,可以提供更丰富的归档日志分析功能。
四、归档日志解析的应用场景1.数据库故障排查:通过分析归档日志,可以找出导致数据库故障的原因,快速恢复业务。
2.性能监控与优化:分析归档日志中的SQL 语句执行情况,找出性能瓶颈,优化数据库性能。
3.数据审计与追溯:归档日志可以记录所有数据变更操作,方便审计人员分析和追溯数据变更原因。
4.数据库安全分析:通过分析归档日志,可以监控数据库访问权限和操作,提高数据库安全。
五、总结与建议归档日志在数据库管理中具有重要意义。
对于数据库管理员而言,应充分利用归档日志进行故障排查、性能优化和数据审计等工作。
oracle 历史归档日志检查

oracle 历史归档日志检查Oracle是一种强大的关系数据库管理系统,自1977年推出以来,一直在数据库领域占据重要地位。
在Oracle数据库中,历史归档日志(Archived Redo Log)是一项重要的功能。
本文将详细介绍Oracle历史归档日志检查的相关内容。
一、什么是历史归档日志?历史归档日志是Oracle数据库中的一种记录机制,用于记录数据库中发生的所有修改操作。
它包含了数据库的完整变更历史,可以追溯到数据库创建以来的任何时间点。
历史归档日志的主要作用是保证数据库的完整性和可恢复性。
二、为什么需要检查历史归档日志?1. 数据库恢复:当数据库出现故障或数据损坏时,可以利用历史归档日志进行数据库恢复。
通过检查历史归档日志,可以确定数据库故障发生的时间点,并将数据库恢复到指定的时间点。
2. 数据库备份:历史归档日志也是数据库备份的一部分。
通过检查历史归档日志,可以确保备份的完整性,以便在需要时进行恢复操作。
3. 数据审计:历史归档日志可以用于数据库审计,记录数据库中的所有修改操作,以满足合规性和安全性的要求。
三、如何进行历史归档日志检查?1. 查看归档模式:首先需要确认数据库是否启用了归档模式。
可以使用以下命令查询数据库的归档模式:```SELECT log_mode FROM v$database;```归档模式有两种:NOARCHIVELOG(未启用归档模式)和ARCHIVELOG(已启用归档模式)。
2. 查看归档日志的存储路径:使用以下命令可以查询归档日志的存储路径:```SELECT name FROM v$archived_log;```这将返回归档日志的存储路径信息。
3. 检查归档日志的完整性:可以使用以下命令检查归档日志的完整性:```SELECT sequence#, first_time, next_time, applied FROM v$archived_log;```该命令将列出归档日志的序列号、第一次创建时间、下一个归档时间以及是否已应用到数据库中。
OracleCDC简介及异步在线日志CDC部署示例
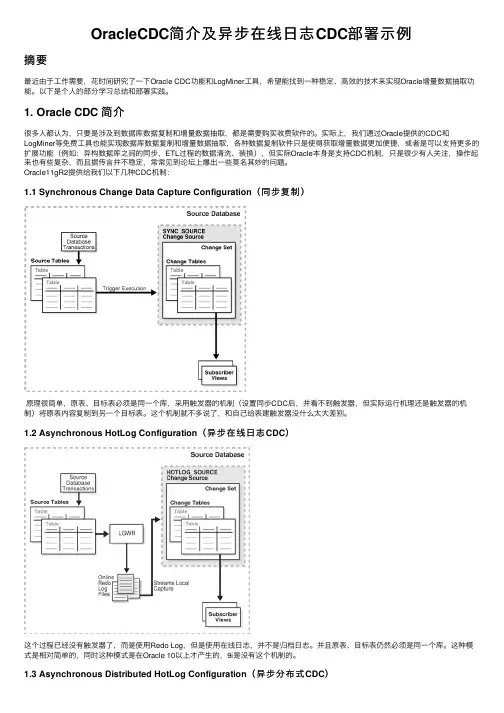
OracleCDC简介及异步在线⽇志CDC部署⽰例摘要最近由于⼯作需要,花时间研究了⼀下Oracle CDC功能和LogMiner⼯具,希望能找到⼀种稳定、⾼效的技术来实现Oracle增量数据抽取功能。
以下是个⼈的部分学习总结和部署实践。
1. Oracle CDC 简介很多⼈都认为,只要是涉及到数据库数据复制和增量数据抽取,都是需要购买收费软件的。
实际上,我们通过Oracle提供的CDC和LogMiner等免费⼯具也能实现数据库数据复制和增量数据抽取,各种数据复制软件只是使得获取增量数据更加便捷,或者是可以⽀持更多的扩展功能(例如:异构数据库之间的同步,ETL过程的数据清洗、装换),但实际Oracle本⾝是⽀持CDC机制,只是很少有⼈关注,操作起来也有些复杂,⽽且据传⾔并不稳定,常常见到论坛上爆出⼀些莫名其妙的问题。
Oracle11gR2提供给我们以下⼏种CDC机制:1.1 Synchronous Change Data Capture Configuration(同步复制)原理很简单,原表、⽬标表必须是同⼀个库,采⽤触发器的机制(设置同步CDC后,并看不到触发器,但实际运⾏机理还是触发器的机制)将原表内容复制到另⼀个⽬标表。
这个机制就不多说了,和⾃⼰给表建触发器没什么太⼤差别。
1.2 Asynchronous HotLog Configuration(异步在线⽇志CDC)这个过程已经没有触发器了,⽽是使⽤Redo Log,但是使⽤在线⽇志,并不是归档⽇志。
并且原表、⽬标表仍然必须是同⼀个库。
这种模式是相对简单的,同时这种模式是在Oracle 10以上才产⽣的,9i是没有这个机制的。
1.3 Asynchronous Distributed HotLog Configuration(异步分布式CDC)实际这个模式是对异步在线⽇志CDC的⼀种优化,也⽐较容易理解,就是加⼊了DB-LINK机制,使原表、⽬标表不在同⼀个数据库。
flinkcdc实践

flinkcdc实践
最近,我在工作中初次接触到了FlinkCDC并进行了一些实践。
FlinkCDC是一种基于Apache Flink的数据同步工具,可以帮助我们实现 MySQL、PostgreSQL、Oracle等数据库到各种数据仓库(如Hadoop、Kafka等)的实时同步。
在使用过程中,我发现FlinkCDC有以下几点
优点:
1. 低延迟:FlinkCDC的核心组件是Flink引擎,利用Flink引
擎的流式计算能力,实现了低延迟的数据同步;
2. 稳定可靠:FlinkCDC的设计思想是基于“Exactly Once”的
精准语义,保证了在出现故障时可以实现数据准确无误的同步;
3. 灵活扩展:FlinkCDC支持自定义Sink(目标端)和Source (源端),使其具有较高的灵活性和可扩展性。
在具体实践中,我用FlinkCDC将MySQL中的数据同步到了Kafka 中。
首先,我在MySQL中创建了一个数据库和一张表,然后在
FlinkCDC的配置文件中设置好了相关参数,如source(MySQL)和
sink(Kafka)的连接地址、用户名、密码等信息。
接着,我在FlinkCDC的控制台中启动了相应的同步任务,并且
观察了同步过程中的日志信息,发现数据能够按照预期被同步到了Kafka中。
总之,通过对FlinkCDC的实践,我对其在数据同步方面的优秀
表现有了更深入的了解。
在今后的工作中,我将继续利用FlinkCDC这
个强大工具来实现更加高效、准确的数据同步。
cdc实现原理

cdc实现原理CDC(Change Data Capture)是一种数据同步的技术,其实现原理是通过捕获数据库的变更操作,将变更数据记录下来并传输到目标系统,实现数据的实时同步。
CDC的实现原理主要包括以下几个步骤:1. 数据库事务日志的利用:CDC通过解析数据库的事务日志来获取数据库的变更信息。
事务日志是数据库管理系统用来记录数据库操作的一种机制,包括插入、更新和删除等操作。
CDC会监控数据库的事务日志,根据日志中的变更操作来捕获数据的变更。
2. 数据提取:CDC会通过特定的接口或工具来提取数据库的变更数据。
提取的方式可以是轮询数据库的事务日志,或者是监听数据库的变更事件。
一旦有数据发生变化,CDC就会将变更数据提取出来。
3. 数据记录和传输:提取到的变更数据会被记录下来,并且根据配置将数据传输到目标系统。
记录变更数据的方式可以是使用日志文件或者数据库表来存储。
传输数据的方式可以是使用消息队列、网络传输或者直接写入目标数据库等。
4. 数据应用:目标系统会接收到CDC传输过来的变更数据,并进行相应的处理。
处理的方式根据具体的需求而定,可以是将数据写入目标数据库,或者是进行进一步的计算和分析。
CDC的实现原理可以用以下的流程图来表示:1. 监控数据库事务日志2. 提取变更数据3. 记录变更数据4. 传输变更数据5. 接收变更数据6. 处理变更数据通过CDC,可以实现数据的实时同步和共享。
它可以应用在很多场景下,比如数据仓库的数据同步、数据备份和灾难恢复、实时数据分析等。
CDC的优点是能够减少数据的冗余和不一致,提高数据的可靠性和一致性。
CDC是一种基于数据库事务日志的数据同步技术,通过捕获数据库的变更操作来实现数据的实时同步。
它的实现原理包括监控数据库事务日志、提取变更数据、记录和传输变更数据、接收和处理变更数据等步骤。
通过CDC,可以实现数据的实时同步和共享,提高数据的可靠性和一致性。
flinkcdc oracle 测试案例

flinkcdc oracle 测试案例Flink CDC(Change Data Capture)是一种用于实时数据同步和流式数据处理的开源技术,它可以捕获数据库中的变化,并将这些变化作为数据流进行处理。
本文将以Flink CDC与Oracle数据库的测试案例为题,介绍一些常见的测试场景和案例。
1. 测试CDC连接Oracle数据库在这个测试案例中,我们将测试Flink CDC与Oracle数据库的连接是否正常。
通过配置正确的数据库连接信息和表名,运行CDC作业,并观察是否可以成功捕获变化数据并进行处理。
2. 测试CDC捕获新增数据在这个测试案例中,我们将在Oracle数据库中插入一些新的数据,并观察Flink CDC是否可以及时捕获到这些新增数据,并将其作为数据流进行处理。
3. 测试CDC捕获更新数据在这个测试案例中,我们将在Oracle数据库中更新一些已有的数据,并观察Flink CDC是否可以及时捕获到这些更新数据,并将其作为数据流进行处理。
4. 测试CDC捕获删除数据在这个测试案例中,我们将在Oracle数据库中删除一些已有的数据,并观察Flink CDC是否可以及时捕获到这些删除数据的变化,并将其作为数据流进行处理。
5. 测试CDC处理数据在这个测试案例中,我们将使用Flink CDC捕获到的变化数据,进行一些数据处理操作,比如数据清洗、数据过滤、数据转换等,并观察处理结果是否符合预期。
6. 测试CDC数据写入外部系统在这个测试案例中,我们将使用Flink CDC捕获到的变化数据,将其写入到外部系统,比如Kafka、HDFS等,并观察数据写入是否成功,并且数据是否与源数据保持一致。
7. 测试CDC的容错和恢复能力在这个测试案例中,我们将模拟Flink CDC的异常情况,比如网络中断、数据库故障等,观察CDC作业的容错和恢复能力,以及是否可以正确处理数据流的连续变化。
8. 测试CDC的性能和吞吐量在这个测试案例中,我们将对Flink CDC进行性能测试,包括数据捕获的延迟、数据处理的吞吐量等指标,以评估CDC作业的性能和效率。
flink oracle cdc案例
flink oracle cdc案例Flink Oracle CDC案例1. 什么是Flink Oracle CDC?Flink Oracle CDC是指在Flink流处理框架中使用Change Data Capture(CDC)技术来捕获和处理Oracle数据库中的数据变化。
CDC是一种数据集成技术,可以实时捕获数据库中的数据变化,并将其作为流数据发送到其他系统进行处理或分析。
2. Flink Oracle CDC的优势Flink Oracle CDC具有以下优势:- 实时性:能够准实时地捕获和处理Oracle数据库中的数据变化,使得其他系统可以及时获得最新的数据。
- 可靠性:通过Flink的容错机制,保证数据的可靠性和一致性。
- 灵活性:支持多种数据格式和数据源,可以根据需求进行灵活的配置和定制。
- 高性能:Flink的流处理引擎具备高吞吐和低延迟的特点,能够处理大规模的数据流。
- 可扩展性:可以根据需求水平扩展,以处理大规模的数据变化。
3. Flink Oracle CDC的应用场景Flink Oracle CDC可以应用于以下场景:- 数据仓库更新:将Oracle数据库中的数据变化实时发送到数据仓库,以保证数据仓库中的数据与源数据库保持同步。
- 实时分析:将Oracle数据库中的数据变化实时发送到分析系统,以进行实时的数据分析和处理。
- 业务监控:通过捕获Oracle数据库中的数据变化,实时监控业务指标并生成报警或通知。
- 数据同步:将Oracle数据库中的数据变化实时同步到其他系统,以保持数据的一致性。
4. Flink Oracle CDC的实现原理Flink Oracle CDC的实现原理如下:- 首先,通过Oracle的日志文件(Redo Log)来捕获数据库中的数据变化。
- 然后,将捕获到的数据变化解析成具体的操作(插入、更新、删除)和对应的数据内容。
- 接着,将解析到的数据变化作为流数据发送到Flink流处理引擎进行处理。
flinkcdc的原理
flinkcdc的原理FlinkCDC是一种基于Apache Flink的开源工具,用于实现实时数据同步和增量数据处理。
它的原理是通过解析数据库的Binlog(二进制日志)来捕获数据库的增量更新,并将这些更新作为事件流进行处理和输出。
在传统的数据同步中,通常采用全量数据复制的方式,即将整个数据库的数据复制到目标系统中。
这种方式存在一些问题,首先是全量数据复制需要占用大量的网络带宽和存储资源,其次是全量数据复制的延迟较高,无法满足实时数据处理的需求。
FlinkCDC通过解析数据库的Binlog来实现增量数据处理。
Binlog 是数据库中记录了对数据进行增删改操作的日志文件,它包含了所有的数据更新操作,包括更新前的数据和更新后的数据。
FlinkCDC 通过解析Binlog中的数据,可以获取到数据库的增量更新,并将其转化为事件流进行处理。
FlinkCDC的工作流程如下:1. 配置数据库连接信息:首先需要配置源数据库和目标数据库的连接信息,包括数据库的地址、端口号、用户名和密码等。
2. 启动FlinkCDC:启动FlinkCDC,并指定需要同步的数据库和表的信息。
3. 解析Binlog:FlinkCDC会定时解析数据库的Binlog,将其中的增量更新操作解析为事件流。
4. 数据处理和输出:FlinkCDC将解析得到的事件流进行处理,可以进行数据清洗、转换、聚合等操作,并将处理结果输出到目标数据库或其他数据存储系统中。
FlinkCDC的核心是Binlog的解析和事件流的处理。
Binlog的解析是通过解析Binlog文件中的二进制数据来获取增量更新的操作,这需要对Binlog的格式和结构进行解析。
FlinkCDC支持多种数据库的Binlog格式,包括MySQL、Oracle等。
解析Binlog需要考虑到数据的一致性和完整性,因此需要处理一些特殊情况,如事务的提交和回滚等。
事件流的处理是指对解析得到的增量更新操作进行处理和转换。
Oracle归档模式及归档日志的操作
ORACLE归档模式及归档日志的操 作
归档模式及归档日志基本概念
为什么要给Oracle做归档操作? Oracle数据库有联机重做日志,这个日志是记录对数据库所做的修改,比如插 入,删除,更新数据等,对这些操作都会记录在联机重做日志里。 当ORACLE数据库运行在ARCHIVELOG(归档模式)模式时,所有的事务重做日志 都将保存.这意味着对数据库进行的所有事务都留有一个备份,尽管重做日志以 循环方式工作,但在一个重做日志被覆盖前均将为其建立一个副本.在重做日志 文件复制完成之前,ORACLE数据库将停止一切新的操作,在旧的事务记录完成之 前ORACLE不对其进行覆盖.有了所有事务的副本,数据库就可以从所有类型的失 败中恢复,包括用户错误或磁盘崩溃.这是一种最安全的数据库工作方式。在实 际开发中,归档模式是符合开发的,归档模式可以提高Oracle数据库的可恢复 性,生产数据库都应该运行在此模式下,数据库使用归档方式运行时才可以进 行灾难性恢复。
LINUX系统开启归档模式
修改数据库为归档模式(需在关闭数据库后操作,操作完成后启动数据库) alter database 改为非归档,则执行: alter database noarchivelog;)
WINDOWS开启归档模式
删除归档日志释放磁盘空间
先查看归档日志状态: RMAN>list archivelog all; 手工删除归档日志文件(删除7天前的所有归档日志) RMAN>DELETE ARCHIVELOG ALL COMPLETED BEFORE 'SYSDATE-7'; 说明: SYSDATA-7,表明当前的系统时间7天前,before关键字表示在7天前的归档日志, 如果使用了闪回功能,也会删除闪回的数据。 同样道理,也可以删除从7天前到现在的全部日志,不过这个命令要考虑清楚, 做完这个删除,最好马上进行全备份数据库。
flink-cdc 读取binlog原理
Flink-CDC 是一种基于 Flink 的 Change Data Capture (CDC) 数据流处理工具,它能够读取MySQL、PostgreSQL 等数据库的binlog(二进制日志),并生成数据流。
下面是 Flink-CDC 读取binlog 的原理概述:
1. 连接数据库:Flink-CDC 首先连接到目标数据库,并获取binlog 的位置和配置信息。
2. 解析 binlog:Flink-CDC 使用 MySQL 或 PostgreSQL 提供的binlog 格式解析器,将 binlog 文件解析成一个个的事件。
每个事件包含数据库表的数据变更信息,如插入、更新或删除操作。
3. 数据流生成:将解析的事件转换为 Flink 数据流,每个事件对应一个数据流元素。
根据配置,Flink-CDC 可以将数据流中的元素按照指定的数据结构进行处理,如 JSON、Avro 等。
4. 数据处理:在数据流生成后,Flink-CDC 可以对数据进行各种处理操作,如过滤、聚合、窗口等。
这些操作可以根据业务需求进行定制化配置。
5. 数据输出:处理后的数据可以通过 Flink-CDC 输出到不同的目标,如 Kafka、数据库或其他数据存储系统。
Flink-CDC 的核心原理是利用数据库的 binlog 机制,实时捕获数据库表的数据变更,并将其转换为 Flink 数据流进行处理。
这种机制使得 Flink-CDC 能够高效地捕获和处理数据库的变化,为实时数
据流处理提供了强大的支持。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
flink cdc 读取oralce 归档日志的原理
一、引言
Flink CDC(Change Data Capture,变更数据捕获)是一种在大数据环境中实现数据库变更数据捕获的技术。
本篇文章将详细介绍Flink CDC如何读取Oracle归档日志的原理。
二、Flink CDC概述
Flink CDC是Flink框架的一个子项目,用于捕获数据库(如Oracle)中的数据变更,并生成相应的变更数据流。
它通过监听数据库的变更事件,捕获数据的变化,并将这些变化以CDC的模式进行存储和传输。
三、Oracle归档日志
Oracle归档日志是一种数据库日志管理机制,它允许数据库在正常操作期间对重做日志进行存档,并在必要时重用或替换现有的重做日志文件。
这样可以在提高性能的同时,减少磁盘空间的占用。
1. 数据捕获:Flink CDC通过与Oracle数据库的连接器,监听数据库的变更事件,包括数据的插入、更新、删除等操作。
2. 归档日志识别:Flink CDC通过解析归档日志文件,识别出与数据库变更事件相关的信息,如数据表名、数据行ID、变更类型等。
3. 数据更新:Flink CDC将捕获到的变更事件存储到持久化存储中,以便后续处理。
同时,Flink CDC会定期从归档日志中读取新的变更事件,以保持数据的实时性。
4. 增量处理:Flink CDC采用增量处理策略,只处理与上次处理之间有变化的记录,以减少处理的数据量,提高处理效率。
5. 数据传输:Flink CDC将捕获到的变更数据以CDC的模式进行传输,可以实时地将数据变化推送至其他系统或进行进一步的分析处理。
五、实际应用场景
Flink CDC可以广泛应用于数据仓库、数据挖掘、实时分析等场景,帮助企业实现数据的实时分析、监控和预警。
例如,在电商领域,Flink CDC可以帮助实时分析用户的购买行为、推荐商品;在金融领域,Flink CDC可以实时监控数据库中的交易数据,实现风险预警和欺诈检测。
六、总结
本篇文章详细介绍了Flink CDC读取Oracle归档日志的原理,包括数据捕获、归档日志识别、数据更新、增量处理和数据传输等过
程。
通过了解Flink CDC的这一功能,我们可以更好地理解其在大数据环境中的应用价值,为企业提供实时的数据分析支持。
以上就是《Flink CDC读取Oracle归档日志的原理》的全部内容,希望能对大家有所帮助!如有任何疑问,请随时联系我们。