第三章 定性数据的 检验
定性数据统计分析概要课件

组织文化研究
要点一
总结词
组织文化研究是定性数据统计分析在组织管理领域的运用 ,通过对组织文化的深入了解,提升组织的凝聚力和竞争 力。
要点二
详细描述
组织文化研究关注组织的价值观、行为规范、沟通方式等 方面。通过收集员工反馈、观察组织行为等方法获取数据 ,运用统计分析方法探究组织文化的特点和影响因素。这 有助于组织发现问题、改进管理方式,并培养积极向上的 组织文化,提高员工的工作满意度和忠诚度。
定性数据统计分析概 要课件
目录
• 定性数据统计分析概述 • 定性数据收集方法 • 定性数据分析方法 • 定性数据统计分析软件 • 定性数据统计分析应用案例
01
定性数据统计分析概述
定义与特点
定义
定性数据统计分析是一种基于非数值 型数据的研究方法,通过对数据的内 容、性质、结构和关系进行分析,揭 示数据背后的意义和规律。
特点
定性分析强调对数据的深入理解和主 观解读,注重数据的背景、语境和情 境,能够揭示数据背后的复杂性和多 样性。
目的与意义
目的
定性数据统计分析旨在深入理解数据的意义和内在联系,揭示研究对象的特点 、规律和变化趋势,为决策提供科学依据。
意义
定性分析在社会科学、市场调研、组织研究等领域具有广泛应用,能够帮助研 究者深入探索研究对象,理解复杂的社会现象,为决策提供更加全面和深入的 信息。
访谈法
通过与研究对象进行面对面的交流,收集口头表达的信息。
访谈法是一种常用的定性数据收集方法,通过与研究对象的 直接交流,可以获取他们的观点、感受和经验等深层次的信 息。访谈可以采用开放式或半开放式的问题形式,以便更好 地引导研究对象展开讨论。
数据分析方法课后答案

数据分析方法课后答案【篇一:数据的分析练习题及答案】、选择题:(每题3分,共15分)1.小明家要买台电脑,下面是甲、乙、丙三种电脑近几年来的销量,如果小明想买一台近期比较流行的电脑,他应买()a.甲b.乙c.丙2.小李是个彩票迷,为了能得奖,他特意询问了前15天的中奖号码分别是:519、、706、328、556、768、215、435、741、624、307、821、696、741、471、285. 你认为这样的观点是否合理()a.不合理b.合理3.小靖想买双好的运动鞋,于是她上网查找有关资料,得到下表:她想买一双价格在300-600元之间,且她喜欢白色、红白相间、浅绿或淡黄色, 并且防水性能很好,那么她应选()a.甲b.乙c.丙d.丁4.为了计算植树节时本班同学所种植的30棵树苗的平均高度, 三位同学先将所有树苗的然后,他们分别这样计算这30棵树苗的平均高度:130130列式正确的是()a.(1)b.(1)和(2);c.(1)和(3)d.(2)和(3)5.某班在一次物理测试中的成绩为:100分7人,90分14人,80分17人,70分8人, 60分2人,50分2人.则该班此次测试的平均成绩为() a.82分b.62分c.64分d.75分二、填空题:(每题4分,共20分)6.一次知识竞赛中,36名参赛选手的得分情况为:5人得75分,8人得80分,6 人得85分,8人得90分,7人得95 分, 2 人得100 分, 要计算他们的平均得分, 可列算式:_____________.(1)7.某校九年级6个班级的学生的人数和平均体重如下表:要计算全校学生的平均体重,可列算式________,平均体重约为__________.8.某家庭搬进新居后,又添置了新的家用电器,为了了解用电量的大小, 该家庭在6月初连续几天观察电表的度数,如下表所示:9.为了解我国14岁男孩的平均身高,从北方抽取了300个男孩,平均身高1.60m; 从南方抽取了200个男孩,平均身高为1.50m;若北方14岁男孩数与南方14岁男孩数的比为3:2,由此可推断我国14岁男孩的平均身高约为______m.10.小明先用5千米/时的速度行驶3小时后,又用4千米/时的速度行驶5小时到达目的地,则小明的平均速度为________. 三、解答题:(每题9分,共54分)11.某同学对他在本学期的自我检测成绩进行了统计:95分的有12次,90 分的有10次,85分的有15次,80分的有3次,75分的有1次,65分的有3次.试计算该同学本学期自我检测的平均成绩..12.超市里要举行转盘摇奖活动,转盘如图所示,买满100元可摇奖一次,有人说:如果大家都摇到自行车,那么超市岂不是亏本了?如果你是超市决策者,会不会因此而改变有奖销售的方案呢?说说你的理由?自行车300元洗洁精2.80元酱油5.0元西红柿2.00元墨水3.50元13.请你根据上表比较这两个国家的数据,你能得出什么结论?14.由于水资源贫乏,节约用水非常重要,请你调查一下,本班每位学生所在家庭的月人均用水量,并据此制作频数分布图,同时估计一下当地家庭的月人均用水量.15.爸爸给小明一串钥匙,共有4把,小明决定先试试哪把是防盗门的钥匙. 请你用模拟实验方法估计一下,他第1次试开就成功的机会有多大?16.转动如图所示的转盘两次,每次指针都指向一个数字. 如果两次所指的数字之积是质数,游戏者a得10分;乘积不是质数,游戏者b得10分.你认为这个游戏公平吗?如果你认为这个游戏不公平,你愿意做游戏者a还是游戏者b?为什么?31246517.有人对记忆和遗忘的规律进行研究,人在记忆过某些知识后, 在不同时间段对其进行测试,结果如下表:分析测试结果,在图中绘制曲线图,并回答遗忘在数量上的变化规律.记忆效果1%记忆的保持曲线图答案:一、1.b 2.a 3.d 4.d 5.a148?50?49.8?46?50.2?55?49.5?48?51?52?50.3?547., 49.8kg50?46?55?48?52?54358.387.75 9.1.56 10.千米/时8三、144所以,美国的吸烟总人数和每天吸烟的总数都大于日本,但吸烟人口占总人口的比例小于日本.14.列出调查表,对本班学生实事求是地进行调查以获得真实的信息.15.可用4个相同的球,1个白的,3个黑的,每次抽1个,则第1次抽到白球的概率为所求概率,1为. 41516.不公平,愿做b 解:乘积是质数的概率是,乘积不是质数的概率是, 游戏不公平,故66愿做b.17.遗忘曲线表明了遗忘在数量上的变化规律,遗忘的数量随时间的前进而递增;这种递增先快后慢,在识记后的短时间内特别迅速,然后逐渐缓慢下来.二、6.记忆效果1%/d记忆的保持曲线图【篇二:定性数据分析第三章课后答案】9、对72个可疑患者用两种不同的方法进行检测,检测结果如下:问:检测方法1阳性和阴性的比例是否与检测方法2阳性和阴性的比例相同?解:(1)提出原假设根据题意,我们假设检测方法1阳性和阴性的比例与检测方法2阳性和阴性的比例是相同。
定性数据分析第三章课后答案
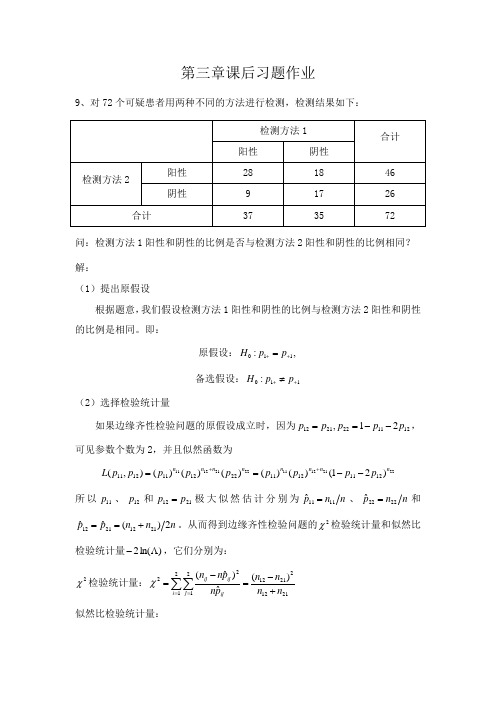
第三章课后习题作业9、对72个可疑患者用两种不同的方法进行检测,检测结果如下:问:检测方法1阳性和阴性的比例是否与检测方法2阳性和阴性的比例相同? 解:(1)提出原假设根据题意,我们假设检测方法1阳性和阴性的比例与检测方法2阳性和阴性的比例是相同。
即:原假设:011:,H p p ++= 备选假设:011:H p p ++≠(2)选择检验统计量如果边缘齐性检验问题的原假设成立时,因为121122211221,p p p p p --==,可见参数个数为2,并且似然函数为2221121122211211)21()()()()()(),(121112112212111211n n n n n n n n p p p p p p p p p L --==++所以11p 、12p 和2112p p =极大似然估计分别为n n p1111ˆ=、n n p 2222ˆ=和n n n p p2)(ˆˆ21122112+==。
从而得到边缘齐性检验问题的2χ检验统计量和似然比检验统计量)ln(2Λ-,它们分别为:2χ检验统计量:211222112212122)(ˆ)ˆ(n n n n p n p n n i j ij ij ij +-=-=∑∑==χ似然比检验统计量:⎪⎪⎭⎫⎝⎛+++-=⎪⎪⎭⎫⎝⎛-=Λ-∑∑==212112211221121221212ln 2ln 2ˆln 2)ln(2n n n n n n n n n p n n i j ijijij它们都有渐近2χ分布,其自由度都是4-2-1=1。
(3)计算检验统计量和p 值,并作出决策则McNemar 2χ检验统计量和似然检验统计量)ln(2Λ-的值分别为:3918)918(22=+-=χ 05818.392918ln 9182918ln 182)ln(2=⎪⎭⎫ ⎝⎛⋅++⋅+-=Λ-我们在Excel 中分别输入“)1,3(chidist =”和“)1,05818.3(chidist =”,可得到2χ检验统计量和似然检验统计量)ln(2Λ-的p 值分别为:083264517.0)3)1((2=≥=χP p 080331601.0)05818.3)1((2=≥=χP p由于p 值都不小,我们不能拒绝原假设,从而认为检测方法1阳性和阴性的比例与检测方法2阳性和阴性的比例是相同。
定性数据统计分析概要课件

通过降维技术,将行变量与列变量在同一低维空间中表示,以便直观揭示行变量 与列变量间的结构关系。
应用场景
适用于有多个分类变量且变量间存在关联性的情况,如市场调研中的品牌与消费 者特征关系分析、生物学中的物种与环境因子关系分析等。
多维尺度分析原理及应用场景
多维尺度分析原理
通过保持原始数据点间的距离关系,在低维空间中重新排列 数据点,以便揭示数据的潜在结构。
适用于研究公众意见、消费行 为、市场需求等领域。
文本分析法
优点
能够深入挖掘文本中的信息,发现其中的 规律和趋势,同时可以进行大规模的分析。
定义
文本分析法是通过对研究对象产生 的文本进行分析,了解其观点、态 度、情感等,收集相关数据和信息
的方法。
A
B
C
D
应用场景
适用于研究社交媒体言论、新闻报道、广 告文案等领域。
相对频率
计算交叉表中各单元格的相对频率, 以百分比形式表示,便于比较。
卡方检验原理及应用场景
卡方检验原理
基于实际观测频数与期望频数之间的差异,判断两个定性变量是否独立。
应用场景
适用于分析两个定性变量之间的关系,如不同性别对某品牌产品的偏好程度。
04
定性数据探索性统计分析 方法
对应分析原理及应用场景
定义:定性数据也称为分类数据 或品质数据,是说明事物性质、 规定事物类别的非数值型数据, 表现为互不相容的类别或属性。
数据的取值是离散的,且一般无 顺序。
数据之间具有独立性,一个数据 的取值不影响另一个数据的取值。
定性数据统计分析意义
了解数据的分布特征
通过统计定性数据的频数分布,可以了解不同类别或属性数据的 分布情况,从而对数据有一个整体的把握。
报告中定性数据的有效分析方法

报告中定性数据的有效分析方法一、什么是定性数据定性数据是指用文字、描述或标签等形式来表示的数据,与定量数据相对。
它主要关注事物的属性、特征或品质,并不能直接用数字进行度量。
在报告中,定性数据的分析常常涉及到对调查问卷、访谈记录或文本材料等进行细致观察和深入理解。
二、定性数据的整理与分类1. 数据整理定性数据的第一步是进行数据整理。
这一步通常包括:将数据输入电子表格中,对材料进行注释,检查和纠正可能出现的错误,并将数据按照一定的方式排序,以便更好地进行分析。
2. 数据分类定性数据的下一步是进行数据分类。
分类可以根据不同的属性、特征或品质进行,以帮助我们更好地理解数据的结构和特点。
可以采用基于主题的分类、基于情感的分类或者基于目标的分类等。
三、定性数据的内容分析方法1. 文本内容分析文本内容分析是一种针对定性数据的常用方法。
它基于对文本材料的深入理解和解释,通过对语言的分析来揭示隐藏在文字背后的信息。
在报告中,可以使用文本内容分析方法来提取和总结调查问卷或访谈记录的主题、观点或趋势,并加以解释和讨论。
2. 语义网络分析语义网络分析是一种将文本数据转化为图形结构的分析方法。
它通过构建和分析词语之间的关系网络来揭示数据之间的联系。
在报告中,可以使用语义网络分析方法来探索和呈现调查问卷或访谈记录中的潜在关系和相互影响。
四、定性数据的模式识别方法1. 主题模式识别主题模式识别是一种通过对定性数据进行归类和总结,识别出数据中的主题和模式的方法。
它通过对数据的频次、相对比例和相关关系进行统计分析,从而揭示数据中隐藏的结构。
2. 情感模式识别情感模式识别是一种通过对定性数据中的情感内容进行识别和分析,揭示数据中蕴含的情感态度和情绪的方法。
它可以通过对文本表达的情感词汇、语气和语境等进行分析,得出调查对象的情感倾向或态度。
五、定性数据的质性验证方法1. 基于质性的逻辑验证基于质性的逻辑验证是一种通过对定性数据进行逻辑推理和验证的方法。
定性数据分析——卡方检验

定性数据分析——卡方检验卡方检验(Chi-square test)是统计学中用于检验两个定性变量之间关联性的方法。
它可以帮助我们确定两个变量之间的差异是由于随机因素导致的还是由于真实的关联性。
卡方检验的基本原理是,通过比较实际观察到的频数与期望频数之间的差异来判断变量之间是否存在关联。
在卡方检验中,我们首先要计算期望频数,即假设两个变量之间没有关联时,我们预计每个组别内的频数应该是多少。
然后,我们计算实际观察到的频数与期望频数之间的差异,并将这些差异加总得到一个卡方值。
最后,我们将卡方值与自由度相结合,使用卡方分布表来确定检验结果是否具有统计学意义。
卡方检验可以分为两种类型:拟合优度检验(goodness-of-fit test)和独立性检验(independence test)。
拟合优度检验用于确定观察到的频数是否与预期的频数相匹配。
它在比较一个变量的分布与一个预先给定的理论分布之间的差异时非常有用。
例如,我们可以使用卡方检验来检验一个骰子是否公平,即骰子的六个面是否具有相等的概率。
独立性检验用于确定两个变量之间是否存在关联。
它可以帮助我们确定两个变量是否独立,即它们的分布是否相互独立。
例如,我们可以使用卡方检验来确定男性和女性之间是否存在偏好其中一种产品的差异。
在进行卡方检验时,我们需要满足一些前提条件。
首先,两个变量必须是独立的,即每个观察值只能属于一个组别。
其次,每个组别中的观察值必须相互独立。
最后,期望频数应该足够大,通常要求每个组别的期望频数大于5卡方检验的结果通常以p值的形式呈现。
p值表示观察到的差异是由于随机因素导致的可能性。
如果p值小于预先设定的显著性水平(通常为0.05),则我们可以拒绝原假设,即认为变量之间存在关联。
在实际应用中,卡方检验可以帮助我们解决许多问题。
例如,我们可以使用卡方检验来确定广告宣传对购买行为的影响,消费者对不同品牌的偏好程度,或者员工对不同工作条件的满意度。
定性数据的分析——卡方检验

2 ) 理论频数计算公式
TRC
nR nC n
T频RC数表;示列联表中第R行第C列交叉格子的理论
nR表示该格子所在的第R行的合计数; nC表示该格子所在的第C列的合计数; n表示总例数。
例10-1 用磁场疗法治疗腰部扭挫伤患者 708人,其中有效673例。用同样疗法治 疗腰肌劳损患者347人,有效312例。观 察结果如表10-6所示。
χ2检验连续性校正公式为
2 ( A T 0.5)2 T
四格表χ2检验连续性校正公式*
2 ( ad bc 0.5n)2 n
(a b)(c d)(a c)(b d )
例10-4 某医生用复合氨基酸胶囊治疗肝硬 化病人,观察其对改善某实验室指标的 效果,见表10-7。
分组 B1
B2
合计
A1
a
b
a+b
A2
c
d
c+d
合计 a+c
b+d
a+b+c+d
案例1 治疗肺炎新药临床试验 用某新药治疗肺 炎病,并选取另一常规药作为对照药,治疗结果 如下:采用新药治100例,有效 60例;采用对照 药治40例,有效 30例。
试问:1) 列表描述临床试验结果;
2)两种药物疗效有无差别?
相应地此时率的标准误估计值按下式计算:
S p ˆ p
p(1 p) n
(10 2)
• 式中,Sp为率的标准误的估计值;p为样本率。
二、率的区间估计
总体率的点估计是计算样本的率,很简单, 但计算得到的样本率不等于总体率,它们 间存在差异。因此,我们还需要知道总体 率大概会在一个什么样的区间范围,即所 谓总体率的可信区间估计。
报告中的定性数据分析方法和技巧

报告中的定性数据分析方法和技巧定性数据分析是研究领域中重要的一部分,通过对定性数据的分析可以得出一些关键的洞察和结论。
然而,与定量数据相比,定性数据的分析方法和技巧更加复杂。
本文将讨论报告中使用的定性数据分析方法和技巧,以帮助读者深入了解这一领域。
一、定性数据的定义和特点定性数据是描述性的、非数值化的数据,通常用于描述观察到的事物或现象的特征、情况和变化。
与定量数据不同,定性数据通常是以文字、图像、音频或视频等形式进行记录和呈现的。
定性数据的分析具有以下特点:1.主观性:定性数据通常涉及主观评价和观察者的主观解释。
因此,在进行分析时需要考虑到观察者的背景和经验对结果的影响。
2.多元性:定性数据可以根据不同维度和特征进行分类和归纳,从而提供丰富的信息。
但是,在进行分析时需要防止信息过载和维度混乱。
3.主题性:定性数据通常涉及特定问题或主题,因此分析师需要针对特定主题进行分析,以获得有意义的结果。
二、定性数据分析方法1. 文本分析:文本分析是通过对定性数据中的文字记录进行分析和解释来了解相关信息。
常见的文本分析方法包括内容分析和主题建模。
内容分析是一种系统提取和解释文本数据中的信息的方法,通过确定关键词、主题和观点等来分析文本数据。
主题建模则是一种自动发现文本数据中的主题和模式的方法,通过统计模型和机器学习算法进行分析。
2. 图像分析:图像分析是通过对定性数据中的图像进行处理和解读,以获取相关信息。
图像分析可以包括图像识别、图像分类、图像分割和图像加工等方法。
例如,通过对产品图片进行图像分类,可以了解产品的特征和品质。
3. 音频分析:音频分析是通过对定性数据中的音频进行处理和分析,以获取相关信息。
音频分析可以包括声音识别、情感识别和语音分析等方法。
例如,在市场调研中,可以通过分析用户在电话录音中的语调和语言表达来了解其情感和需求。
三、定性数据分析技巧1. 数据清洗:在进行定性数据分析之前,需要对数据进行清洗,以去除重复、错误和不相关的数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3
? ? 假 如设果三H0类成的立观,察我次们数希分望别在为样本n1中, n喜2和欢n每3 一,品i?1 牌ni 的? n顾。
从而
c
?
?
2
?
(k
? 1)
对例3.1来说,k ? 3 ,当? ? 0.05 时,??2(k ?1)? ?02.05(2)? 5.991
? 2 ? (61 ? 50)2 ? (53 ? 50)2 ? (36 ? 50)2 ? 6.52
50
50
50
? 由于? 2 ? 6.52 ? 5.991,因此拒绝零假设。
由假设检验的一般原理知, c的值可由给定的显
著性水平 ? 确定,即c满足 P(? 2 ? c) ? ?
关于统计量 ? 2的分布,英国统计学家 Karl Pearson
给出下面的定理:
设总体中的每一个个体属于且只属 A1, A2 , , Ak
,k个类之一。总体中属于 k个类的比例为 p1, p 2 , , pk
即认为顾客对这三种品牌矿泉水的喜好确实存 在差异。
利用统计分析软件SPSS13.0可以大大简 化计算过程,下面用统计软件对例3.1进行分析。
?1.按要求录入数据; ?2.选择 Data ? weightCase 对数据进行加权; ?3.选择 Analyze ? Non ? parametricTest ? Chi ? square 进行非参数检验
3.1 多项分布与? 2 分布
?收集分类数据的目的是分析在每个类中 数据的分布。例如,我们为了估计消费 者中喜欢三种牙膏中每一种的比例,则 统计购买者三种牙膏的顾客购买每一种 的人数。在这里仅仅是根据牙膏的种类 来分类,我们称之为一维分类或一向分 类。下面通过例子来介绍一向分类数据 的分析。
[例3.1] 某超市为了研究顾客对三种矿泉水的 喜好比例,以便为下一次进货提供决策,随机 观察了150名购买者,并记录下他们所买的品 牌,统计出购买三种品牌的人数,如下表所示:
?列联表(contingency table )
顾客购买喜好调查
品牌
甲
乙
丙
人数
61
53
36
这些数据是否说明顾客对这三种矿泉水的喜好 确实存在差异?
? 解:由于该问题有甲、乙、丙三类,所以这个分布称为多项
概率分布,简称多项分布。
多项分布是二项分布的推广,可以看成多项实验得到的分
布。多项试验有如下一些性质:
1.多项试验由n个相同的实验组成;
2.每个实验的结果落在k组的某一组中;
。先从总体中随机抽查 n个,其中属于 Ai 类有n i个
(i ? 1,2, , k) 。
?定义统计量
? ? 2 ? k [ ni ? E(ni )]2 i?1 E(ni )
则当n充分大时,? 2统计量遵从自由度为 k-1的 ? 2 分布
一般要求 n应较大,使得每一类中的期望值个数
不少于5。
由以上定理知,当 n充分大时,? 2 ~ ? 2 (k ? 1) ,
理由拒绝 H 0。为此考虑如下统计量:
? 2 ? [ n1 ? E(n1)]2 ? [ n2 ? E(n2 )]2 ? [ n3 ? E(n3 )]2
E(n1 )
E(n2 )
E(n3 )
? (n1 ? 50)2 ? (n2 ? 50)2 ? (n3 ? 50)2
50
50
50
如果? 2值很大,则有理由拒绝 H0,拒绝域为:{? 2 ? c}
例3.1 1.录入数据
1 2 3
brand
freq
1
61
2
53
3
36
?2.打开 weightCase 对话框,将 freq 放
入 frequency ,单击OK。
பைடு நூலகம்
?3.打开Chi ? squaretest 对话框,把 freq 选入 ?Test Variable List 栏中,单击OK。
? 得到如下分析结果
客差不多 1/3的比例。或者说对 n个顾客中喜欢第一 种品牌的顾客的人数的期望值应为:
11
E (n1 )
?
np
?
n 3
?
? 150 3
?
50
同理 E(n2 ) ? E(n3) ? 50
于是对某一次抽样来说,ni 和E(ni )的差距在H0成 立时比较小;反之,如 ni和 E(ni )的差距比较大,则有
第三章 定性数据的 ? 2检验
?对定性指标的基本分析方法是按照它的变动 范围进行分类,调查机构按照某种设计方案 发放问卷,从回收的问卷中可统计出各种属 性的计数结果,如喜欢某种商品包装设计的 人数,这种数据称为频数。由此可以计算出 不同分类的频数分布,为深入分析这些定性 资料奠定基础。本章的目的是提高定性资料 的分析水平,主要介绍定性数据的列联表分 析和 ? 2检验在实际统计分析中的应用。
3.某个实验的结果落在某一特定组,比如说组i 中的概率为
pi (i ? 1,2, ? , k) 且在试验之间保持不变,且有 k pi ? 1
4.实验是独立的;
i?1
5.实验者关心 n1, n2 , , nk ,这里 ni (i ? 1,2, , k)等于实验
结果落在组 i 中的数目。注意: n1 ? n2 ? ? nk ? n
在多数试验中,当k ? 2 时,就得到二项分布。
在多数实际情况下,k个可能结果的概率 p1, p 2 , , pk 通常
是未知的,我们的目的就是对他们进行推断。
?对于例3.1,我们希望去检验顾客对三种矿泉 水品牌的喜好是否存在差异,考虑检验零假设 为对三种品牌的喜好没有差异,对立假设为对
三种品牌的喜好存在差异。 令
? 从输出结果可以看出,? 2 ? 6.520 ,且p值(sig )为
0.038小于 ? ? 0.05 ,检验结果与上述计算结果一
致,故有理由拒绝原假设,认为顾客顾客对三种品 牌矿泉水的喜好确实是有差异的。 ? 例3.2见课本,方法完全相同。
3.2 列联表分析
?问卷调查中常涉及对某个问题两个或多个不 同特征的分类。如:房地产商考虑顾客选择 房子设计的类型与职业的关系,所调查的每 个顾客都有两个特性,一个是选择房子的类 型,一个是职业。……例子中我们通常关心 的是按照两个特性进行的分类的方法之间是 否相互依赖,或者说是否相互独立。