cache性能分析实验报告
体系结构试验报告(cache存储过程)
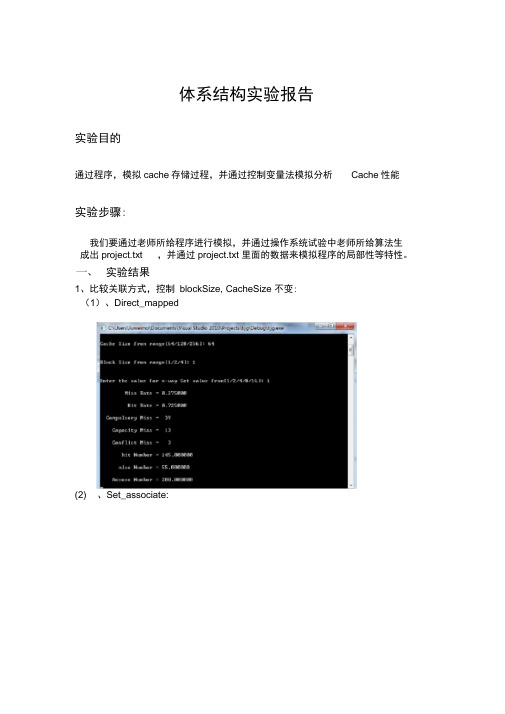
体系结构实验报告实验目的通过程序,模拟cache存储过程,并通过控制变量法模拟分析Cache性能实验步骤:我们要通过老师所给程序进行模拟,并通过操作系统试验中老师所给算法生成出project.txt ,并通过project.txt 里面的数据来模拟程序的局部性等特性。
实验结果1、比较关联方式,控制blockSize, CacheSize 不变:(1)、Direct_mapped(2) 、Set_associate:(3) 、Fully_associate通过上述三个比较可以看出,各种映射有自己的优点。
但是不难看出,增大关联度会减小miss rate,但是增加到一定程度又会有抑制作用。
2.比较Cache大小对于性能的影响。
(1)、Direct_mapped,Cache容量为64 时:(2rDirecflmapped〉Cache朿*R128 手(3r Direcflmapped〉Cache助*R256口F一pwsef 峑s 2O J I 0\^J.e e K ^g 63-L w g <J g -f aJnnnrEd理"巧 nmrMecIrlxMLH肆一事呼LJw匸-dJ-LUfJF U »»a iB cinIJr ltRn x li 黑鱼*=£1K s 1!蚯c a p w p llrt t M:C4mw JLl n rll n i H HHi L n h != l£lx-瞌忻恥f*<41.匸«F 23L L/2\.*X «礼 j !H F i <n对比实验结果,不难发现,随着Cache容量的增加,Cache的命中率一直在提升。
分析原因发现,虽然Cache容量大了,但并不等于其预存的内容增多,所以命中率会上升。
3、比较Cache大小对于性能的影响。
(1)、Direct_mapped,关联度为 1 时:(2)、Direct_mapped,关联度为2 时:(3)、Direct_mapped,关联度为4 时:(4) 、Direct mapped ,关联度为 8 时:I ■ C -\LI wrs 1.11uwei mo\Dw_-m e ts'_Vi EUUI I ^tud o l£f Pre e-crE\tt. q\Dfft!uq\ti'g.-i-j rIE Is-* -IrMHiF OP n tiny Ret U <A lun f 1± flhissH41# a 聊C4pnic4tv Conflictnx5S(5) 、Direct map ped ,关联度为 16 时:可以看出,随着关联度的提高,命中率也有所增加Canipuilsnry 1XSE-hH MuflfafiP = I44.MIUUM1Ace R -S3 NumWr ■寸-F口寸 灭 」eqlunu>loo-q〈 p ①ddelu —10①」一q <(L)S33I・鹫詡M us y u s L l's童wr#*■L 書-E .f n -sr e U F K e$us.H92m £百1-■阿*E戏*%贰%严一&丫A*u-uk s ?£Lc 』 C3"f l a毒* 1和4£sE E *B J W11v m 「>!5q言石-d ^l L l e l迟E n p xll -,.I 曰右号v d d -o'w -o M n 「口釜l Y ci-te L ^R 」eqlunu>loo-q 〈 p ①ddelu —10①」Q <通过以上三组数据不难看出,当block number增加时,命中率明显增高了。
Cache模拟器实验报告

Cache模拟器一、实验目标:程序运行时,都会对内存进行相关操作,所访问的内存地址可以被记录下来,形成memory trace文件。
在本实验中,你将使用benchmark 程序产生的memory trace文件来测试Cache命中率,文件可以在/classes/fa07/cse240a/proj1-traces.tar.gz上获得。
每次存储器访问都包含了三个信息:1.访问类型,’l’表示Load操作,’s’表示Store操作;2.地址。
采用32位无符号的十六进制表示;3.存储器访问指令之间的间隔指令数。
例如第5条指令和第10条指令为存储器访问指令,且中间没有其他存储器访问指令,则间隔指令数为4。
通过写一段程序,模拟Cache模拟器的执行过程。
二、实验要求:写一段程序模拟Cache模拟器的执行过程,并对5个trace文件进行测试,完成以下目标:1.请统计Load类型指令和Store类型指令在这5个trace文件中的指令比例。
2.设Cache总容量为32KB,对以下所有参数进行组合(共有72种组合),测量相应5个文件的Cache命中率。
通过对命中率的分析,可以发现什么规律。
行大小:32字节、64字节、128字节相连度:8路相联、4路相联、2路相联、1路相联替换策略:FIFO,随机替换,LRU写策略:写直达、写回3. 给出5个文件的最佳Cache命中率的参数组合。
针对不同的trace 文件,最佳配置是否相同。
4. 测量各种组合下Cache和主存之间的数据传输量。
5. 给出5个文件的最小数据传输量的参数组合。
这个组合和第3问中得到的组合是否一致。
针对不同的trace文件,最佳配置是否相同。
6. Cache缺失有三种原因:1)强制缺失;2)容量缺失;3)冲突缺失。
分析这三种缺失并说明你的分析方法。
7. 请给出5个trace文件在最优Cache命中率的情况下,这三种缺失所占的比例,并和教材图C.8给出的比例进行比较。
Cache矩阵乘积算法性能改善实验

1 实验目地及要求★了解Cache对系统性能地影响★了解基于系统结构地算法设计思想2 实验模块及实验原理2.1 实验模块(1)编写两个C语言程序.一个是实现矩阵乘积地一般算法.另一个是基于Cache地矩阵乘积优化算法.(2) 采用不同矩阵大小来进行多组测量,使实验地结果更加准确.2.2 实验原理本实验采用控制变量地方法.矩阵大小相同时比较两算法地优略.在相同算法中采用改变矩阵大小地方式,使结果更加准确.3 实验步骤与结果3.1 实验步骤(1)编译并运行程序1,记录相关数据.(2)不改变矩阵大小时,编译并运行程序2,记录相关数据.(3)改变矩阵大小,重复(1)、(2)两步.(4)通过以上地实验现象,分析出现这种现象地原因.3.2 实验结果1.用C语言实现矩阵(方阵)乘积一般算法(程序1),填写下表:矩阵大小:500 一般算法执行时间:2. 62500矩阵大小:1000 一般算法执行时间:20.171875矩阵大小:1500 一般算法执行时间:73.718750矩阵大小:2000 一般算法执行时间:167. 93750矩阵大小:2500 一般算法执行时间:394.828125矩阵大小:3000 一般算法执行时间:1099. 312502.程序2是基于Cache地矩阵(方阵)乘积优化算法,填写下表:矩阵大小:500 优化算法执行时间:1.562500矩阵大小:1000 优化算法执行时间:12.625000矩阵大小:1500 优化算法执行时间:42.875000矩阵大小:2000 优化算法执行时间:102.171875矩阵大小:2500 优化算法执行时间:202.796875矩阵大小:3000 优化算法执行时间:360. 31250矩阵大小:500 加速比:1.68矩阵大小:1000 加速比:1.598矩阵大小:1500 加速比:1.72矩阵大小:2000 加速比:1.63矩阵大小:2500 加速比:1.63矩阵大小:3000 加速比:3.05加速比定义:加速比=优化前系统耗时/优化后系统耗时;所谓加速比,就是优化前地耗时与优化后耗时地比值.加速比越高,表明优化效果越明显.4 实验代码程序1:#include <sys/time.h>#include <unistd.h>#include <stdio.h>main(int argc,char *argv[]){float *a,*b,*c,temp;long int i,j,k,size,m;struct timeval time1,time2;if(argc<2){printf("\n\tUsage:%s <Row of square matrix>\n",argv[0]);exit(-1);}size=atoi(argv[1]);m=size*size;a=(float*)malloc(sizeof(float)*m);b=(float*)malloc(sizeof(float)*m);c=(float*)malloc(sizeof(float)*m);for(i=0;i<size;i++)for(j=0;j<size;j++){a[i*size+j]=(float)(rand()%1000/100.0);b[i*size+j]=(float)(rand()%1000/100.0);}gettimeofday(&time1,NULL);for(i=0;i<size;i++)for(j=0;j<size;j++){c[i*size+j]=0;for(k=0;k<size;k++)c[i*size+j]+=a[i*size+k]*b[k*size+j];}gettimeofday(&time2,NULL);_sec-=_sec;_usec-=_usec;if(_usec<0L){_usec+=1000000L;_sec-=1;}printf("Executiontime=%ld.%6ldseconds\n",_sec,_usec);}return(0);}程序2:#include <sys/time.h>#include <unistd.h>#include <stdio.h>main(int argc,char *argv[]){float *a,*b,*c,temp;long int i,j,k,size,m;struct timeval time1,time2;if(argc<2){printf("\n\tUsage:%s <Row of squarematrix>\n",argv[0]);exit(-1);}size=atoi(argv[1]);m=size*size;a=(float*)malloc(sizeof(float)*m);b=(float*)malloc(sizeof(float)*m);c=(float*)malloc(sizeof(float)*m);for(i=0;i<size;i++)for(j=0;j<size;j++){a[i*size+j]=(float)(rand()%1000/100.0);c[i*size+j]=(float)(rand()%1000/100.0);}gettimeofday(&time1,NULL);for(i=0;i<size;i++)for(j=0;j<size;j++){b[i*size+j]=c[j*size+i];for(i=0;i<size;i++)for(j=0;j<size;j++){c[i*size+j]=0;for(k=0;k<size;k++)c[i*size+j]+=a[i*size+k]*b[j*size+k];}gettimeofday(&time2,NULL);_sec-=_sec;_usec-=_usec;if(_usec<0L){_usec+=1000000L;_sec-=1;}printf("Executiontime=%ld.%6ldseconds\n",_sec,_usec);}return(0);}5 实验结果分析(1)对于矩阵乘法,用一般算法执行时,执行时间随着矩阵地增大变化较大. (2)用优化算法执行时,执行时间随着矩阵地增大变化较小.(3)由加速比计算结果可清晰看到在矩阵比较小时,优化前后区别不大;随着矩阵规模变大,加速就比较明显了.。
Cache实验

Caches实验杨祯 15281139实验目的1.阅读分析附件模拟器代码2.通过读懂代码加深了解cache的实现技术3.结合书后习题1进行测试4.通过实验设计了解参数(cache和block size等)和算法(LRU,FIFO 等)选择的优化配置与组合,需要定性和定量分析,可以用数字或图表等多种描述手段配合说明。
阅读分析模拟器代码课后习题stride=132下直接相连映射1)实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个组数位16array[0]的块地址为0/4=0 映射到cache的块号为0%16=0 array[132]的块地址为132/4=33 映射到cache的块号为33%16=1第一次访问cache中的0号块与1号块时,会发生强制性失效,之后因为调入了cache中,不会发生失效,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000 实验验证stride=131下直接相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个组数位16array[0]的块地址为0/4=0 映射到cache的块号为0%16=0array[131]的块地址为131/4=32 映射到cache的块号为32%16=0 第一次访问cache中的0号时,一定会发生强制性失效,次数为1;之后因为cache中块号为0的块不断地被替换写入,此时发生的是冲突失效,冲突失效次数为19999,则发生的失效次数为19999+1=20000 所以misscount=20000 missrate=20000/(2*10000)=1实验验证stride=132下2路组相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个Noofset=16/2=8组array[0]的块地址为0/4=0 映射到cache的组号为0%8=0array[132]的块地址为132/4=33 映射到cache的组号为33%8=1第一次访问cache中的0号块与1号块时,一定会发生强制性失效,之后因为调入了cache中,不会发生失效,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000 实验验证stride=131下2路组相连映射实验分析由题意得:cachesize=256B blockinbyte=4*4BNoofblock=256B/16B=16个Noofset=16/2=8组array[0]的块地址为0/4=0 映射到cache的组号为0%8=0array[131]的块地址为131/4=32 映射到cache的组号为32%8=0 第一次访问cache中的0组时,一定会发生强制性失效,因为1组中有2个块,不妨假设array[0]对应0组中的第0块,array[131]对应0组中的第1块,则强制失效次数为1;之后因为 array[0]与array[131]都在0组,不会发生失效则发生的失效次数为2次,命中次数为19998,所以misscount=2 missrate=2/(2*10000)=1/10000hitcount=19998 hitrate=9999/10000实验验证实验分析(1)block块大小与Cache容量对Cache效率的影响实验以Hitrate作为衡量指标,在直接相连映射,组相连度为1,project.txt 为500个1---100的随机数。
Cache性能分析

第22卷第1期新乡教育学院学报2009年3月 V ol.22,N o.1JOURNA L OF XINXIANG E DUCATION COLLEGE M AR,2009 Cache性能分析Ξ程军锋(陇南师范高等专科学校,甘肃陇南742500)摘 要:随着计算机CPU的速度越来越快,计算机主存和CPU之间速度差异问题也日益突出,已经严重影响了计算机系统性能的提高。
现已有多种技术改进主存的存取速度来提高计算机系统性能,其中通过Cache提高存储系统速度是广泛采用的一种技术。
笔者主要介绍Cache的基本工作原理,同时也分析了引入Cache后计算机系统的性能,并介绍了一些改进Cache性能的方法。
关键词:高速缓冲存储器;命中率;加速比;失效;映射中图分类号:TP3 文献标识码:A 文章编号:1672Ο3325(2009)01Ο0111Ο03作者简介:程军锋(1980Ο),男,甘肃礼县人,助教。
研究方向:计算机基础理论教学。
计算机发展到现在,CPU主频的提升使得计算机系统性能有了极大地提高,但计算机系统性能提高不仅取决于CPU的性能,还与系统结构、指令系统、数据在各部件间的传送速度及存储部件的存取速度等因素有密切关系,特别是与CPU和主存之间的存取速度有着很大的关系。
如果CPU工作速度较快,而主存访问速度相对较慢,这样就会造成CPU 等待,浪费CPU的性能,降低处理器速度,进而影响计算机整体性能。
长期以来,计算机工作者一直研究解决主存与CPU的速度差异问题的方法,已有多种技术用来提高主存的访问速度,其中通过Cache(高速缓冲存储器)来提高存储系统速度就是一种有效的技术。
Cache是容量较小但速度快的半导体随机存储器,位于CPU和大容量主存之间,但存取速度比主存快得多。
它的作用是为CPU提供一个速度与之相当,而容量与主存相同的存储系统,以解决CPU和主存间速度不匹配的一项技术。
这种技术可在计算机系统成本增加很小的前提下,使计算机性能得到明显的提升。
8 VxWorks操作系统Cache试验

#elif defined(CPU_940T) || defined(CPU_940T_T) mmuArm940tLibInstall (NULL, NULL);
三 实验步骤
1. 参照实验 2 和实验 3 下载编译生成的 VxWorks 映象文件,在 VxWorks 的 Target Shell 中观察启动过程,主要是观察从 go 0x30010000 命令后到启动到 Target Shell 的启动过程所 花费的时间,此时正常应该为 1 秒钟左右。
2. 在实验 2 的工程的组件配置窗口中将 hardware→memory→enable cache 组件使用右键 菜单的 Exclude ‘enable cache’选项将 enable cache 功能去掉。然后重新编译工程并使用 gen bin 工具产生新的映象文件二进制代码。
五 实验报告书编写要点
1. 下载实验 3 中的 VxWorks 操作系统映象的二进制代码,并运行,观察启动时间; 2. 配置内核,去掉 enable cache 组件; 3. 重新下载编译后的内核并运行,观察启动时间,并与 1 的时间进行比较。
六 编程指导内容
VxWorks 的 BSP 中与 Cache 相关的代码主要在什么地方,怎样查找? 解答:
3. 下载新的映象文件二进制代码到目标板,并运行,观察启动过程,主要是观察从 go 0x30010000 命令后到启动到 Target Shell 的启动过程所花费的时间,此时正常应该为 6 秒钟 左右。速度比第 1 步中的启动过程慢了很多,此时说明 cache 已经关闭。
实验7—— 基于Cache的矩阵乘积算法性能改善实验——计师2班白涵冰
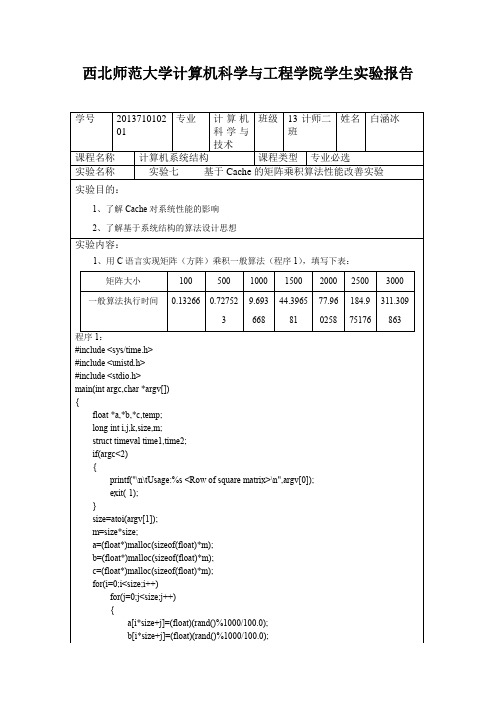
c[i*size+j]+=a[i*size+k]*b[k*size+j];
}
gettimeofday(&time2,NULL);
_sec-=_sec;
_usec-=_usec;
if(_usec<0L)
2000
2500
3000
一般算法执行时间
0.13266
0.727523
9.693668
44.396581
77.960258
184.975176
311.309863
程序1:
#include <sys/time.h>
#include <unistd.h>
#include <stdio.h>
main(intargc,char*argv[])
5.61707
17.696994
38.165972
76.3326
127.5312
加速比
0.46
1.2
1.72
2.51
2.04
2.42
2.44
实验总结:
通过本次实验了解Cache对系统性能的影响知道了cache是如何提高计算机的性能的,通过对程序的优化终于看到了比较惊人的结果。本次实验收获颇多,受益匪浅。
for(j=0;j<size;j++)
{
a[i*size+j]=(float)(rand()%1000/100.0);
c[i*size+j]=(float)(rand()%1000/100.0);
}
gettimeofday(&time1,NULL);
西安交大计算机系统结构实验报告.

《计算机系统结构课内实验》实验报告第一次实验:记分牌算法和Tomasulo算法第二次实验:cache性能分析班级:物联网21姓名:李伟东学号:2120509011日期:2015.5.21第一次实验:记分牌算法和Tomasulo算法一、实验目的及要求1. 掌握DLXview模拟器的使用方法;2. 进一步理解指令动态调度的基本思想,了解指令动态调度的基本过程与方法;3. 理解记分牌算法和Tomasulo算法的基本思想,了解它们的基本结构、运行过程;4. 比较分析基本流水线与记分牌算法和Tomasulo算法的性能及优缺点。
二、实验环境DLXview模拟器三、实验内容1.用DLX汇编语言编写代码文件*.s(程序中应包括指令的数据相关、控制相关以及结构相关),以及相关的初始化寄存器文件*.i和数据文件*.d;2.观察程序中出现的数据相关、控制相关、结构相关,并指出三种相关的指令组合;四、实验步骤将自己编写的程序*.s、*.i、*.d装载到DLXview模拟器上,(1)分别用基本流水线、记分牌算法和Tomasulo算法模拟,针对每一种模拟做如下分析:①统计程序的执行周期数和流水线中的暂停时钟周期数;②改变功能部件数目重新模拟,观察并记录性能的改变;③改变功能部件延迟重新模拟,观察并记录性能的改变;论述功能部件数目、功能部件延迟对性能的影响。
(2)记录运行记分牌算法时的功能部件状态表和指令状态表;(3)记录运行Tomasulo算法时的指令状态表和保留站信息;五、实验结果1)基本流水线原始即加法延迟2,乘法延迟5,实验结果显示该段程序运行了11个时钟周期增加了一个除法器。
加法器延迟2,乘法器延迟5,除法器延迟19。
实验结果显示该段程序运行了11个时钟周期。
增加除法器对程序的执行无影响。
加法器延迟2,乘法器延迟6,无除法器。
实验结果显示该段程序运行了12个时钟周期乘法器的延迟对程序执行有有影响。
加法器延迟1,乘法器延迟5。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计算机系统结构实验报告名称: Cache性能分析学院:信息工程姓名:学号:S121055专业:计算机系统结构年级:实验目的1.加深对Cache的基本概念、基本组织结构以及基本工作原理的理解;2.了解Cache的容量、相联度、块大小对Cache性能的影响;3.掌握降低Cache失效率的各种方法,以及这些方法对Cache性能提高的好处;4.理解Cache失效的产生原因以及Cache的三种失效;5.理解LRU与随机法的基本思想,及它们对Cache性能的影响;实验平台Vmware 虚拟机,redhat 9.0 linux 操作系统,SimpleScalar模拟器实验步骤1.运行SimpleScalar模拟器;2.在基本配置情况下运行程序(请指明所选的测试程序),统计Cache总失效次数、三种不同种类的失效次数;3.改变Cache容量(*2,*4,*8,*64),运行程序(指明所选的测试程序),统计各种失效的次数,并分析Cache容量对Cache性能的影响;4.改变Cache的相联度(1路,2路,4路,8路,64路),运行程序(指明所选的测试程序),统计各种失效的次数,并分析相联度对Cache性能的影响;5.改变Cache块大小(*2,*4,*8,*64),运行程序(指明所选的测试程序),统计各种失效的次数,并分析Cache块大小对Cache性能的影响;6.分别采用LRU与随机法,在不同的Cache容量、不同的相联度下,运行程序(指明所选的测试程序)统计Cache总失效次数,计算失效率。
分析不同的替换算法对Cache性能的影响。
预备知识1. SimpleScalar模拟器的相关知识。
详见相关的文档。
2. 复习和掌握教材中相应的内容(1)可以从三个方面改进Cache的性能:降低失效率、减少失效开销、减少Cache命中时间。
(2)按照产生失效的原因不同,可以把Cache失效分为三类:①强制性失效(Compulsory miss)当第一次访问一个块时,该块不在Cache中,需从下一级存储器中调入Cache,这就是强制性失效。
这种失效也称为冷启动失效或首次访问失效。
②容量失效(Capacity miss)如果程序执行时所需的块不能全部调入Cache中,则当某些块被替换后,若又重新被访问,就会发生失效。
这种失效称为容量失效。
③冲突失效(Conflict miss)在组相联或直接映象Cache中,若太多的块映象到同一组(块)中,则会出现该组中某个块被别的块替换(即使别的组或块有空闲位置),然后又被重新访问的情况。
这就是发生了冲突失效。
这种失效也称为碰撞失效(collision)或干扰失效(interference)。
(3)降低Cache失效率的方法:增加Cache块大小、提高相联度、Victim Cache、伪相联Cache、硬件预取技术、由编译器控制的预取和编译器优化。
(4)替换算法①随机法:为了均匀使用一组中的各块,这种方法随机地选择被替换的块。
②最近最少使用法LRU(Least Recently Used):选择近期最少被访问的块作为被替换的块。
但由于实现比较困难,现在实际上实现的LRU都只是选择最久没有被访问过的块作为被替换的块。
实验内容一关于simplescalar的简要说明SimpleScalar包括多个仿真器:sim-fast ,sim-safe,sim-cache,sim-cheetah,sim-profile,sim-bpred,sim-eio和sim-outorder。
本次实验使用的是sim-cache,下面说明一下sim-cache。
sim-cache:在这个仿真中加入了cache,用户可以对cache及TLB 进行设置,支持两级的cache和一级的TLB,第一级cache和TLB均分为数据和指令两部分。
(摘自百度百科)下面简要说明一下有关cache的信息:一般来说,Cache的结构参数主要包括以下几个方面:容量、块大小、相联度、替换算法等。
在SimpleScalar模拟器中,采用了两级Cache结构,同时数据和指令Cache分开。
SimpleScalar的Cache参数配置命令为:<name>:<nsets>:<bsize>:<assoc>:<repl><name> :Cache的名称,其中:dl1:一级数据Cache;dl2:二级数据Cache;il1:一级指令Cache;il2:二级指令Cache;dtlb:数据TLB;itlb:指令TLB;<nsets> :组的数目;<bsize>:块大小;<assoc> :相联度;<repl> :替换策略。
此时,Cache容量为:<nsets>*<bsize>*<assoc>。
替换策略主要有以下几种:l :LRU,最近最少使用;f : FIFO,先进先出;r : RANDOM,随机策略。
例如:-cache:dl1 dl1:2048:64:4:r,表示对一级数据cache进行配置,2048表示有2048组,64表示cache块大小为64byte,4表示相联度为4,r表示替换策略为RANDOM。
在此配置下,一级数据cache的容量为2048*64*4=512KB。
由于Simplescalar Spec2000测试程序在其官方网站不能下载,故使用simplescalar模拟器自带的测试程序以及自己设计的一个程序进行测试。
自带的测试程序是在/root/simplescalar/simplesim-3.0/tests-pisa/bin.little目录下的test-math,test-fmath,test-llong以及test-printf。
我们所有的实验内容都是对一级数据cache来进行分析的。
在simplescalar中,我们使用的模拟器是sim-cache。
二 simplescalar模拟器基本配置情况下的运行模拟在基本的配置情况下运行自己设计的程序,代码如下:#include<stdio.h>Main(){printf(“hello world!\n”);return 0;}1.编辑好程序后,将其保存在/root/simplescalar文件夹下,文件命名为hello.c,用安装好的simplescalar中的编译器sslittle-na-sstrix-gcc(它的访问目录为/root/simplescalar/bin/sslittle-na-sstrix-gcc)对其进行编译,编译后生成了能够在模拟器中可以运行的可执行文件 a.out。
命令行运行界面如下图所示:2.我们使用simplescalar中的模拟器sim-cache对a.out模拟执行,执行后的界面如下图所示:说明:下面的截取的界面是一个完整的界面,限于完整的界面太大,在后面的实验内容的三、四、五、六部分只截取了我们需要的部分界面。
3.对运行结果进行分析从上面的运行结果中我们提取出一级数据cache(dl1)的信息进行分析:dl1.accesses 4420 # total number of accesses 一级数据cache上的总访问次数dl1.hits 3963 # total number of hits 一级数据cache上的命中次数dl1.misses 457 # total number of misses 一级数据cache上的失效次数dl1.replacements 201 # total number of replacements一级数据cache上发生替换的次数dl1.writebacks 190 # total number of writebacks一级数据cache上发生写回的次数dl1.invalidations 0 # total number of invalidations一级数据cache上无效访问的次数dl1.miss_rate 0.1034 # miss rate (i.e., misses/ref) 一级数据cache上的失效率dl1.repl_rate 0.0455 # replacement rate (i.e., repls/ref) 一级数据cache上发生替换的概率dl1.wb_rate 0.0430 # writeback rate (i.e., wrbks/ref) 一级数据cache上发生写回的概率dl1.inv_rate 0.0000 # invalidation rate (i.e., invs/ref) 一级数据cache上发生无效访问的概率从分析中,我们可以得出,一级数据cache总共的失效次数(dl1.misses)为457次,我们知道容量失效和冲突失效都发生了替换,所以它们的失效次数(dl1.replacements)总共为201次,强制性失效次数为457-201=256次。
一级数据cache的总失效率为0.1034。
三 Cache容量对Cache性能的影响1.操作说明:(1)改变simplescalar模拟器中的一级数据cache(dl1)的容量配置,我们通过改变组数来改变它的容量。
与此同时固定块大小为32byte、相联度为2以及替换策略为LRU等参数。
(2)测试的程序是simplescalar自带的测试程序test-math。
2.运行的界面(截取了部分所需的界面)如下图所示:容量为2KB(32*32*2*1)时,容量为4KB(64*32*2*1)时,容量为8KB(128*32*2*1)时,容量为64KB(1024*32*2*1)时,3.运行结果分析从面的运行结果中,我们提取所需要的一级数据cache的信息,如下表所示:从上表,我们可以分析出,随着cache容量的不断增加,程序的失效率不断降低。
容量失效和冲突失效的次数随着cache容量的增加不断地减少,而强制性失效次数则不断地增加。
四 Cache相联度对Cache性能的影响1.操作说明(1)改变simplescalar模拟器中的一级数据cache的相联度大小。
与此同时固定cache的容量16KB、块大小32byte以及替换策略为LRU等参数。
(2)测试的程序是simplescalar自带的测试程序test-fmath。
2.运行的界面(只截取了部分所需的界面)如下图所示:相联度为1路时,相联度为2路时,相联度为4路时,相联度为8路时,相联度为64路时,3.运行结果分析从上面的运行结果中,我们提取所需要的一级数据cache的信息,如下表所示:从上表,我们可以分析得出,随着相联度的增加,程序的失效率逐渐降低,但降低的幅度比较小。