有序多分类逻辑斯蒂回归模型
逻辑斯蒂(logistic)回归深入理解、阐述与实现

逻辑斯蒂(logistic)回归深⼊理解、阐述与实现第⼀节中说了,logistic 回归和线性回归的区别是:线性回归是根据样本X各个维度的Xi的线性叠加(线性叠加的权重系数wi就是模型的参数)来得到预测值的Y,然后最⼩化所有的样本预测值Y与真实值y'的误差来求得模型参数。
我们看到这⾥的模型的值Y是样本X各个维度的Xi的线性叠加,是线性的。
Y=WX (假设W>0),Y的⼤⼩是随着X各个维度的叠加和的⼤⼩线性增加的,如图(x为了⽅便取1维):然后再来看看我们这⾥的logistic 回归模型,模型公式是:,这⾥假设W>0,Y与X各维度叠加和(这⾥都是线性叠加W)的图形关系,如图(x为了⽅便取1维):我们看到Y的值⼤⼩不是随X叠加和的⼤⼩线性的变化了,⽽是⼀种平滑的变化,这种变化在x的叠加和为0附近的时候变化的很快,⽽在很⼤很⼤或很⼩很⼩的时候,X叠加和再⼤或再⼩,Y值的变化⼏乎就已经很⼩了。
当X各维度叠加和取⽆穷⼤的时候,Y趋近于1,当X各维度叠加和取⽆穷⼩的时候,Y趋近于0.这种变量与因变量的变化形式就叫做logistic变化。
(注意不是说X各个维度和为⽆穷⼤的时候,Y值就趋近1,这是在基于W>0的基础上,(如果W<0,n那么Y趋近于0)⽽W是根据样本训练出来,可能是⼤于0,也可能是⼩0,还可能W1>0,W2<0…所以这个w值是样本⾃动训练出来的,也因此不是说你只要x1,x2,x3…各个维度都很⼤,那么Y值就趋近于1,这是错误的。
凭直觉想⼀下也不对,因为你连样本都还没训练,你的模型就有⼀个特点:X很⼤的时候Y就很⼤。
这种强假设肯定是不对的。
因为可能样本的特点是X很⼤的时候Y就很⼩。
)所以我们看到,在logistic回归中,X各维度叠加和(或X各维度)与Y不是线性关系,⽽是logistic关系。
⽽在线性回归中,X各维度叠加和就是Y,也就是Y与X就是线性的了。
逻辑斯蒂模型各参数的意义

逻辑斯蒂模型各参数的意义
一、逻辑斯蒂模型的概念
逻辑斯蒂回归模型是一种用于建立二元分类的统计学模型,它将预测结果视作一个随机变量(可能的值是0或1),而结果由一个条件概率分布来确定。
当对一个新样本做预测时,将计算出一个概率,如果概率超过某个已设定的阈值,则判定此样本属于1类,反之属于0类。
二、参数的概念
在逻辑斯蒂回归模型中,参数指模型中变量的权重,参数的估计即为拟合样本所需要调整的参数,以最大化模型的拟合精度。
三、参数的含义
1、w:w是权值向量,可以确定一个样本分类的阈值,模型预测的概率大于或小于这个阈值就可以得出类别的判断结果。
2、b:b是偏置,是模型决定正负样本的阈值,b的取值不用影响模型的预测结果,但是影响到分类的阈值。
3、θ:θ是参数的集合,即w和b。
4、α:α是学习率,是一种超参数,改变其值可以调整参数更新的速度,从而影响模型收敛的速度和性能。
四、参数的调整
参数的调整包括参数估计和超参数调整。
(1)参数估计
参数估计是指根据训练样本,计算出逻辑斯蒂模型的参数,从而
拟合训练样本。
在估计参数的过程中,可以使用最大似然估计、最小二乘估计等方法。
(2)超参数调整
超参数调整是指调整逻辑斯蒂回归模型中的其他参数,比如学习率、迭代次数、正则化强度等,从而使模型的拟合精度更高。
逻辑斯蒂回归(LogisticRegression)

逻辑斯蒂回归(LogisticRegression)展开全文本文是结合书来作出自己的理解和总结的,主要的参考书目是《统计学习方法》,后期的修改中,我会加入相关的其他书籍进来。
欢迎批评和指正~~本文的思路是根据《统计学习方法》第一章所提到的:统计学习方法 = 模型+策略+算法的思路来讲的,所以,如果对于这个思路有疑问,自行看第一章。
本文主要介绍的是逻辑斯蒂模型的模型、策略和算法,至于最大熵模型,这里不予介绍。
首先会介绍逻辑斯蒂模型的基本模型,然后会介绍极大似然估计的基本原理和逻辑回归的策略并求出逻辑回归的目标函数,最后介绍梯度上升算法和逻辑回归目标函数的最优化。
1、逻辑斯蒂模型1.1、逻辑斯蒂分布为什么先讲逻辑斯蒂分布呢?因为我们的逻辑斯蒂模型就是根据逻辑斯蒂分布得到的,所以说逻辑斯蒂方法是属于判别方法,即知道了P(Y|X)的形式(当然,我们是不知道P(X,Y)的,要不然机器学习也就没有意义了。
),通过参数估计方法直接估计出参数,从而得到P(Y|X)。
下面给出《统计学习方法》上逻辑斯蒂分布的定义:1.2、二项逻辑斯蒂回归模型知道分布的定义之后,就是给出我们的逻辑斯蒂模型了:这里需要注意的有两点:(1)最终的结果是通过比较P(Y=1|X)和P(Y=0|X)的大小来确定类别的;(2)b在这里其实可以看做是w0x0,其中x0 = 1;(3)其实本质上这个就是一个二项分布,所以遵循二项分布的分布律。
1.3、事件的对数几率(log odds)废话不说,还是看看统计学习方法上面的定义:1.4、第一个结论根据之前,我们就得到了两个定义:(1)逻辑回归模型;(2)事件的对数几率。
那么从这两个定义,我们可以得到什么推论呢?也就是说,如果我的模型是逻辑回归模型,那么事件{Y=1|X}发生的对数几率就是输入X的线性函数(模型)。
所以只要知道了这个推论,我们是可以反推出逻辑斯蒂模型的形式的:1.5、比较逻辑斯蒂模型和感知机首先,很显然,这里的逻辑斯蒂模型可以看成是f(wx),也就是wx的函数:sigmoid函数,感知机则是sign函数。
有序logit回归

有序logit回归前言Logistic模型属于非线性回归分析,它的研究主要是针对于因变量二分类或多分类变量结果与某些影响因素之间的一种多重回归方法,本学堂已有推文已经介绍了Logistic回归的作用,在这里就不再赘述。
我们常见的因变量为二分类变量,即因变量只有两种取值,如某病发生记为1,不发生记为,这或许是平常最常见也是使用最多的形式。
但是Logistic回归还包括条件Logistic回归,有序Logistic 回归,无序多分类Logistic回归。
这次我将给大家分享的是有序Logistic回归。
有序Logistic回归应用条件1. 与二分类Logistic不同的是,有序Logistic回归适用于因变量为等级或者程度差别的资料,如因变量满意度分为不满意记为1,满意记为2,非常满意记为3。
2. 自变量可以使任意类型的变量,如定量变量、二分类变量、无序多分类变量或者是有序分类变量等等。
有序Logistic回归注意事项1. 对于自变量的取值要求、样本含量的计算、变量的选择等方面与二分类一致,在这里就不赘述。
2. 有序Logistic回归独有的一个对于模型的检验是平行性假设检验,我将在后面讲解模型的时候阐述。
如果平行性假设不成立,就换用其他不需要进行平行性假设的模型,或者使用无序多分类Logistic 回归。
3. 按照OR的意义,常指病例组中暴露人数与非暴露人数的比值除以对照组中暴露人数与非暴露人数的比值,OR=1,表示该因素没有作用,OROR>1,表示该因素为危险因素,其是流行病学研究的一个常用指标。
我们常常对因变量Y的赋值要根据专业知识,将最有利的等级赋予最高等级,最不利的赋予最低等级,如因变量满意度分为不满意记为1,满意记为2,非常满意记为3。
有序Logistic回归几种模型实现有序Logistic回归的模型有很多种,我列出我所见过的四种模型,欢迎大家补充。
1.累积Logit模型:因变量Y包含g个类别,自变量X包含m个,为各自变量的回归系数。
逻辑斯蒂回归基本原理

逻辑斯蒂回归基本原理最近在研究逻辑斯蒂回归,发现了一些有趣的原理,今天来和大家聊聊。
你知道吗?生活中有很多情况就像是逻辑斯蒂回归的实例呢。
就像我们预测一个人会不会买某件商品。
假设我们考虑两个因素,一个是这个人的收入,另一个是这个商品是不是很流行。
一般来说,收入高的人可能更有能力买东西,流行的东西也更容易被购买。
但这个关系又不是绝对的,不是说收入高就肯定会买,流行就所有人都会买。
逻辑斯蒂回归的基本原理其实就是想找到一种数学上的关系,来描述这种可能性。
从专业角度来说,逻辑斯蒂回归是一种广义的线性回归模型,它的响应变量(我们要预测的结果,例如会不会买东西,1代表会,0代表不会)是一种分类变量。
我们把输入的各种特征(像前面说的收入和商品流行程度等)通过特定的函数计算,这个函数就像是一个魔法变换器。
打个比方吧,这个过程就好比是把各种乱七八糟的食材(输入特征)放进一个神奇的搅拌机(逻辑斯蒂函数),最后得出一个蛋糕(预测的结果:买或者不买)。
这个搅拌机的运作原理是特殊的,它要保证最后产出的结果在0到1之间,这个数值就表示会买这个商品的概率。
有意思的是,这个模型是怎么达到对结果良好预测的呢?这就要说到模型中的系数了。
就像刚刚那个例子里,收入和商品流行程度对购买结果的影响程度是不一样的,这个影响程度就是通过系数来体现的。
不一样的系数就像是烹饪里不同食材放的量不一样,某个食材(特征)多放点(系数大),可能对最后的蛋糕(结果)影响就大一些。
老实说,我一开始也不明白为什么不直接用线性回归就好了。
后来才知道,线性回归得到的结果可能是任意实数,但我们这里预测的是某个事件发生的概率,概率只能在0到1之间,所以这就是逻辑斯蒂回归存在的意义之一。
实际应用案例超级多,就比如说银行会根据客户的收入、信用记录这些资料(特征),采用逻辑斯蒂回归来预测这个客户会不会违约(一种分类结果)。
这样银行就可以提前做好应对措施,降低风险。
在应用逻辑斯蒂回归的时候也有一些注意事项。
logistic回归模型

Logistic回归模型
• 列联表中的数据是以概率的形式把属性变量联系 起来的,而概率p的取值在0与1之间,因此,要把
概率 p (x)与 x 之间直接建立起函数关系是不合
适的。即 (x) x
Logistic回归模型
• 因此,人们通常把p的某个函数f(p)假设为变量的 函数形式,取 f ( p) ln (x) ln p
1 (x) 1 p
• 称之为logit函数,也叫逻辑斯蒂变换。 • 因此,逻辑斯蒂变换是取列联表中优势的对数。
当概率在0-1取值时,Logit可以取任意实数,避免 了线性概率模型的结构缺陷。
Logistic回归模型
假设响应变量Y是二分变量,令 p P(Y 1) ,影响Y
的因素有k个 x1, xk,则称:
多项logit模型
• 前面讨论的logit模型为二分数据的情况,有时候 响应变量有可能取三个或更多值,即多类别的属 性变量。
• 根据响应变量类型的不同,分两种情况:
–响应变量为定性名义变量; –响应变量为定性有序变量;
• 当名义响应变量有多个类别时,多项logit模型应 采取把每个类别与一个基线类别配成对,通常取 最后一类为参照,称为基线-类别logit.
• 为二分数据的逻辑斯ln 1蒂pp回归g(模x1,型,,xk简) 称逻辑斯蒂 回归模型。其中的k个因素称为逻辑斯蒂回归模型 的协变量。
• 最重要的逻辑斯蒂回归模型是logistic线性回归模 型,多元logit模型的形式为:
ln
p 1 p
0
1x1
k xk
Logistic回归模型
• 其中,0, 1, , k 是待估参数。根据上式可以得到
多项logit模型
有序多分类逻辑斯蒂回归模型
Logit 变换的分别为p1、p1+p2、p1+p2 +p3,对k 个自变量拟
合三个模型如下:
log it[ p( y 1)]
常数项不同,回归系
log it(
p1 )
ln
1
p1 p1
ln
p2
p1 p3
p4
数完全相同的
1 1x1 2 x2 k xk
• 累积概率的模型并不利用最后一个概率,因为它必然等于1
14.1 有序回归的基本思想
log
it(
pj
)
ln
1
p
jpBiblioteka j
j
1x1
2 x2
n xn
pj = p(y≤j | x),它表示 y 取前 j 个值的累积概率。
累积概率函数:
pj p( y
j
x)
ln
p1 p2 p3 1 ( p1 p2 p3 )
ln
p1
p2 p4
p3
3 1x1 2 x2 k xk
张文彤版本的常数项 前均为负号
• 根据上述公式,可以分别求出:
• 由上述建立的模型可以看出,这种模型实际上是依次
14.1 有序回归的基本思想
• 有序回归模型的类型:
当定性因变量y取k个顺序类别时,记为1,2,…,k,这 里的数字1,2,…,k仅表示顺序的大小。
因变量y取值于每个类别的概率仍与一组自变量x1,x2,…,xk 有关,对于样本数据 (xi1,xi2,…,xip ;yi),i=1,2,…,n ,顺序类别回 归模型有两种主要类型, •位置结构(Location component)模型,位置模型,定位模型 •规模结构(Scale component)模型,尺度模型,定量模型
第6章逻辑斯蒂回归模型

–其中probit变换是将概率变换为标准正态分布的 z −值, 形式为:
Logistic回归模型
–双对数变换的形式为:
f ( p ) = ln(− ln(1 − p ))
• 以上变换中以logit变换应最为广泛。 • 假设响应变量Y是二分变量,令 p = P(Y = 1) ,影响Y 的因素有k个 x1 ,L xk ,则称:
β • 其中, 0 , β1 ,L , β k 是待估参数。根据上式可以得到 优势的值: p β + β x +L+ β x
1− p
=e
0
1 1
k k
• 可以看出,参数 βi是控制其它 x 时 xi 每增加一个 单位对优势产生的乘积效应。 • 概率p的值: e β + β x +L+ β x
p=
0 1 1 k k
含有名义数据的logit
• 前例中的协变量为定量数据,logistic回归模型的 协变量可以是定性名义数据。这就需要对名义数 据进行赋值。 • 通常某个名义数据有k个状态,则定义个变量 M 1 ,L , M k −1 代表前面的k-1状态,最后令k-1变量均 为0或-1来代表第k个状态。 • 如婚姻状况有四种状态:未婚、有配偶、丧偶和 离婚,则可以定义三个指示变量M1、M2、M3, 用(1,0,0)、 (0,1,0) 、(0,0,1) 、(0,0,0)或(-1,-1,-1) 来对以上四种状态赋值。
G 2 = −2 ∑ 观测值[ln(观测值/拟合值)]
• 卡方的df应等于观测的组数与模型参数的差,较小的统计量的 值和较大的P-值说明模型拟合不错。 • 当至多只有几个解释变量且这些解释变量为属性变量,并且所 有的单元频数不少于5时,以上统计量近似服从卡方分布。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• Y的累积概率是指Y落在一个特定点的概率,对结果为类别j 时,其累积概率为:
p(Y j x) p1 p2 pj , j 1, , k • 累积概率满足: p(Y 1) p(Y k) 1
时求出的OR 值表示自变量每改变一个单位,反应变量
提高一个及一个以上等级的比数比。 OR exp(i )
• 张文彤认为,这里拟合的模型中常数项之前的符号应
当是“负号”,原因在于此处的常数项正好表示低级
别和高级别相比的情况,且必Fra bibliotek有, 但由
于研究者主要关心的是各参数(系数)的大小,因此
这种差异影响不大。并且由SPSS给出的系数无需再添
p(1)=p1 ,y 取第二个值的概率p(2)=p2 -p1,y 取第三个值的概率 p(3)=1- p2 。它们的截距不同,斜率相同,所以是J-1条平行直线 族。多值因变量logistic回归模型要求进行数据的平行性检验。
• 平行性检验(只适用于位置模型/位置参数/斜率系数)
• 当因变量维多值变量时,模型包含多个回归方程。Logistic回 归分析要求这多个回归方程中自变量的系数是相等的。因此 需要做平行行检验,也称为比例比数假设检验(test fo the proportional odds assumption),使用的方法是计分检验法。 当P>a时,接受平行的原假设。否则,应该将因变量的某些 值进行合并,减少因变量的取值个数,使得多值变量logistic 回归模型平行性成立。还可以尝试其他链接函数。
多元回归中的几种重要模型
• 第一部分:多重共线情况的处理
– 第10章 岭回归分析( Ridge Regression )
• 第二部分:自变量中含定性变量的处理 – 第11章 自变量中含有定性变量的回归分析
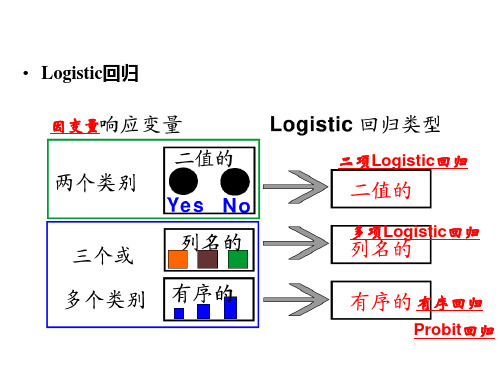
• 第三部分:因变量中含有定性变量情况的处理 – 第12章 二项Logistic回归 – 第13章 多项Logistic回归 – 第14章 有序回归(等级回归分析) – 第15章 Probit回归(概率单位回归) – 第16章 最佳尺度回归
• 累积概率的模型并不利用最后一个概率,因为它必然等于1
14.1 有序回归的基本思想
log
it
(
p
j
)
ln
1
p
j
p
j
j
1x1 2 x2
n xn
pj = p(y≤j | x),它表示 y 取前 j 个值的累积概率。
累积概率函数:
pj p( y
j
x)
1
exp( j exp( j
it(
p1
p2 )
ln
1
p1 ( p1
p2 p2
)
ln
p1 p3
p2 p4
2 1x1 2 x2 k xk
log it[
p( y
3)]
log
it( p1
p2
p3 )
ln
1
p1 ( p1
p2 p2
p3 p3
)
ln
p1
p2 p4
p3
3 1x1 2 x2 k xk
Logit 变换的分别为p1、p1+p2、p1+p2 +p3,对k 个自变量拟
合三个模型如下:
log it[ p( y 1)]
常数项不同,回归系
log
it(
p1 )
ln
1
p1 p1
ln
p2
p1 p3
p4
数完全相同的
1 1x1 2 x2 k xk
log
it[ p( y
2)]
log
加符号。
• 某大学医院外科采用两种不同的绷带和两种不同的包扎 方式进行腿溃疡的治疗处理。治疗的结果分三种:不愈、 有效和痊愈。试分析治疗方法对治疗效果的影响。
• 设因变量 y 表示治疗效果,0=不愈、1=有效、2=痊愈。 设自变量x1表示绷带种类,自变量 x2 表示包扎方式。
• 对于多值因变量模型,平行性假设决定了每个自变量的 OR值对于前k-1个模型是相同的。例如,变量x1的 OR=5.172,它表示使用第一种绷带治愈腿溃疡的可能性 是使用第二种绷带的5.172倍;它也表示使用第一种绷带 至少有效的可能性是使用第二种绷带的5.172倍。
x) x)
,当1
j
k 1
1,当j k
J等级分为两类:{1,,j } 与 { j+1,,k}
在这两类的基础上定义的 logit 表示:属于后 k-j 个等级的累积 概率与前j个等级的累积概率的优势的对数,故该模型称为累 积优势模型 (cumulative odds model)。
第一个模型表示了y 取第一个值的概率p1与x的关系;第二个模 型表示了y 取前两个值的累积概率p2与x的关系。这两个模型的 常数项不同,回归系数完全相同的。 y 取第一个值的概率
• Logistic回归
因变量
二项Logistic回归
多项Logistic回归
有序回归 Probit回归
第14章 有序回归
(有序多分类因变量Logistic回归)
• 14.1 有序回归的基本思想 • 14.2 有序回归的案例分析
14.1 有序回归的基本思想
• 研究中常遇到反应变量为有序多分类(k>2)的资料,如城 市综合竞争力等级、满意度等可以划分为低、中、高。
14.1 有序回归的基本思想
• 有序回归模型的类型:
当定性因变量y取k个顺序类别时,记为1,2,…,k,这 里的数字1,2,…,k仅表示顺序的大小。
因变量y取值于每个类别的概率仍与一组自变量x1,x2,…,xk 有关,对于样本数据 (xi1,xi2,…,xip ;yi),i=1,2,…,n ,顺序类别回 归模型有两种主要类型, •位置结构(Location component)模型,位置模型,定位模型 •规模结构(Scale component)模型,尺度模型,定量模型
• 如果各种连接函数都无法满足平行性假定,则需要考虑回归 系数是否会随着分割点而发生改变。此时最好使用无序多分 类的Logistic 回归进行模型拟合,然后再根据系数估计值考 虑如何进行处理。
• 以4 水平的反应变量为例,假设反应变量的取值为1 、2 、3 、
4 ,相应取值水平的概率为p1、p2、p3、p4,则此时进行
张文彤版本的常数项 前均为负号
• 根据上述公式,可以分别求出:
• 由上述建立的模型可以看出,这种模型实际上是依次
将反应变量按不同的取值水平分割成两个等级,对这
两个等级建立反应变量为二分类的Logistic 回归模型。
不管模型中反应变量的分割点在什么位置,模型中各
自变量的系数都保持不变,所改变的只是常数项。此