SPSS实验回归分析
SPSS回归分析过程详解

线性回归的假设检验
01
线性回归的假设检验主要包括拟合优度检验和参数显著性 检验。
02
拟合优度检验用于检验模型是否能够很好地拟合数据,常 用的方法有R方、调整R方等。
1 2
完整性
确保数据集中的所有变量都有值,避免缺失数据 对分析结果的影响。
准确性
核实数据是否准确无误,避免误差和异常值对回 归分析的干扰。
3
异常值处理
识别并处理异常值,可以使用标准化得分等方法。
模型选择与适用性
明确研究目的
根据研究目的选择合适的回归模型,如线性回 归、逻辑回归等。
考虑自变量和因变量的关系
数据来源
某地区不同年龄段人群的身高 和体重数据
模型选择
多项式回归模型,考虑X和Y之 间的非线性关系
结果解释
根据分析结果,得出年龄与体 重之间的非线性关系,并给出 相应的预测和建议。
05 多元回归分析
多元回归模型
线性回归模型
多元回归分析中最常用的模型,其中因变量与多个自变量之间存 在线性关系。
非线性回归模型
常见的非线性回归模型
对数回归、幂回归、多项式回归、逻辑回归等
非线性回归的假设检验
线性回归的假设检验
H0:b1=0,H1:b1≠0
非线性回归的假设检验
H0:f(X)=Y,H1:f(X)≠Y
检验方法
残差图、残差的正态性检验、异方差性检验等
非线性回归的评估指标
判定系数R²
SPSS处理多重回归分析

实验二多重回归分析一、实验目的研究样本数据离差阵、样本协方差阵,以及变量之间的相关系数(包括偏相关)并作相关性分析。
二、实验要求为研究高等院校人文社会科学研究中立项课题数受那些因素的影响,收集到某年31个地区部分高校有关社科研究方面的数据(见SPSS数据),利用此的数据,设定立项课题数X5为因变量(被解释变量),X2,X3,X4,X6,X7,X8为解释变量,作多重回归分析。
三、实验内容1.依次点击“分析→回归→线性回归”,得到如下图一所示:【图一】2.点击“统计量”,得到如下图二所示:【图二】3.点击“继续”,得到如下图三所示:【图三】4.点击“继续→确定”,得到如下表一所示:【表一】回归其中,容差(容忍度):21i i Tol R =- 2i R 是解释变量i X 与其他解释变量间的复相关系数的平方。
容忍度取值范围为0-1,越接近0表示多重共线性越强,容忍度越接近于1表示多重共线性越弱。
方差膨胀因子(VIF ):1iiV I F T o l =即为容忍度的倒数。
i VIF 的值大于等于1,i VIF 越小,说明多重共线性越弱。
可见,投入高级职称的人年数的容差最小,为0.007,多重共线性是最弱的,其次是投入人年数;获奖数的容差最大,为0.358,多重共线性最强。
其中,解释变量相关阵的特征根和方差比:如果解释变量有较强的相关性,则它们之间必然存在信息重叠。
可通过解释变量相关阵的特征值来反映。
解释变量相关阵的最大特征根能够解释说明解释变量信息的比例是最高的,其他特征根随其特征值的减小对解释变量方差的的解释能力依次减弱。
如果这些特征根中,最大特征根远远大于其他特征根,说明这些解释变量间具有相当多的重叠信息。
条件指数:是在特征值基础上的定义的能反映解释变量间多重共线性的指标mi ik λλ=i k 为第i 个条件指数,m λ是最大特征根。
通常当010i k ≤<时,认为多重共线性弱;当10100i k ≤<时,认为多重共线性较强;当是100i k ≥,认为多重共线性很严重。
SPSS回归分析

SPSS回归分析SPSS(统计包统计软件,Statistical Package for the Social Sciences)是一种强大的统计分析软件,广泛应用于各个领域的数据分析。
在SPSS中,回归分析是最常用的方法之一,用于研究和预测变量之间的关系。
接下来,我将详细介绍SPSS回归分析的步骤和意义。
一、回归分析的定义和意义回归分析是一种对于因变量和自变量之间关系的统计方法,通过建立一个回归方程,可以对未来的数据进行预测和预估。
在实际应用中,回归分析广泛应用于经济学、社会科学、医学、市场营销等领域,帮助研究人员发现变量之间的关联、预测和解释未来的趋势。
二、SPSS回归分析的步骤1. 导入数据:首先,需要将需要进行回归分析的数据导入SPSS软件中。
数据可以以Excel、CSV等格式准备好,然后使用SPSS的数据导入功能将数据导入软件。
2. 变量选择:选择需要作为自变量和因变量的变量。
自变量是被用来预测或解释因变量的变量,而因变量是我们希望研究或预测的变量。
可以通过点击"Variable View"选项卡来定义变量的属性。
3. 回归分析:选择菜单栏中的"Analyze" -> "Regression" -> "Linear"。
然后将因变量和自变量添加到正确的框中。
4.回归模型选择:选择回归方法和模型。
SPSS提供了多种回归方法,通常使用最小二乘法进行回归分析。
然后,选择要放入回归模型的自变量。
可以进行逐步回归或者全模型回归。
6.残差分析:通过检查残差(因变量和回归方程预测值之间的差异)来评估回归模型的拟合程度。
可以使用SPSS的统计模块来生成残差,并进行残差分析。
7.结果解释:最后,对回归结果进行解释,并提出对于研究问题的结论。
要注意的是,回归分析只能描述变量之间的关系,不能说明因果关系。
因此,在解释回归结果时要慎重。
回归分析spss

回归分析spss回归分析是一种常用的统计方法,用于探究变量之间的关系。
它通过建立一个数学模型,通过观察和分析实际数据,预测因变量与自变量之间的关联。
回归分析可以帮助研究者得出结论,并且在决策制定和问题解决过程中提供指导。
在SPSS(统计包括在社会科学中的应用)中,回归分析是最常用的功能之一。
它是一个强大的工具,用于解释因变量与自变量之间的关系。
在进行回归分析之前,我们需要收集一些数据,并确保数据的准确性和可靠性。
首先,我们需要了解回归分析的基本概念和原理。
回归分析基于统计学原理,旨在寻找自变量与因变量之间的关系。
在回归分析中,我们分为两种情况:简单回归和多元回归。
简单回归适用于只有一个自变量和一个因变量的情况,多元回归适用于多个自变量和一个因变量的情况。
在进行回归分析之前,我们需要确定回归模型的适用性。
为此,我们可以使用多种统计性检验,例如检验线性关系、相关性检验、多重共线性检验等。
这些检验可以帮助我们判断回归模型是否适用于收集到的数据。
在SPSS中进行回归分析非常简单。
首先,我们需要打开数据文件,然后选择“回归”功能。
接下来,我们需要指定自变量和因变量,并选择适当的回归模型(简单回归或多元回归)。
之后,SPSS将自动计算结果,并显示出回归方程的参数、标准误差、显著性水平等。
在进行回归分析时,我们需要关注一些重要的统计指标,例如R方值、F值和P值。
R方值表示自变量对因变量的解释程度,它的取值范围在0到1之间,越接近1表示模型的拟合效果越好。
F值表示回归模型的显著性,P值则表示自变量对因变量的影响是否显著。
我们通常会将P值设定为0.05作为显著性水平,如果P值小于0.05,则我们可以认为自变量对因变量有显著影响。
此外,在回归分析中,我们还可以进行一些额外的检验和分析。
比如,我们可以利用残差分析来检查回归模型的拟合优度,以及发现可能存在的异常值和离群点。
此外,我们还可以进行变量选择和交互效应的分析。
如何使用统计软件SPSS进行回归分析

如何使用统计软件SPSS进行回归分析如何使用统计软件SPSS进行回归分析引言:回归分析是一种广泛应用于统计学和数据分析领域的方法,用于研究变量之间的关系和预测未来的趋势。
SPSS作为一款功能强大的统计软件,在进行回归分析方面提供了很多便捷的工具和功能。
本文将介绍如何使用SPSS进行回归分析,包括数据准备、模型建立和结果解释等方面的内容。
一、数据准备在进行回归分析前,首先需要准备好需要分析的数据。
将数据保存为SPSS支持的格式(.sav),然后打开SPSS软件。
1. 导入数据:在SPSS软件中选择“文件”-“导入”-“数据”命令,找到数据文件并选择打开。
此时数据文件将被导入到SPSS的数据编辑器中。
2. 数据清洗:在进行回归分析之前,需要对数据进行清洗,包括处理缺失值、异常值和离群值等。
可以使用SPSS中的“转换”-“计算变量”功能来对数据进行处理。
3. 变量选择:根据回归分析的目的,选择合适的自变量和因变量。
可以使用SPSS的“变量视图”或“数据视图”来查看和选择变量。
二、模型建立在进行回归分析时,需要建立合适的模型来描述变量之间的关系。
1. 确定回归模型类型:根据研究目的和数据类型,选择适合的回归模型,如线性回归、多项式回归、对数回归等。
2. 自变量的选择:根据自变量与因变量的相关性和理论基础,选择合适的自变量。
可以使用SPSS的“逐步回归”功能来进行自动选择变量。
3. 建立回归模型:在SPSS软件中选择“回归”-“线性”命令,然后将因变量和自变量添加到相应的框中。
点击“确定”即可建立回归模型。
三、结果解释在进行回归分析后,需要对结果进行解释和验证。
1. 检验模型拟合度:可以使用SPSS的“模型拟合度”命令来检验模型的拟合度,包括R方值、调整R方值和显著性水平等指标。
2. 检验回归系数:回归系数表示自变量对因变量的影响程度。
通过检验回归系数的显著性,可以判断自变量是否对因变量有统计上显著的影响。
SPSS实验8-二项Logistic回归分析
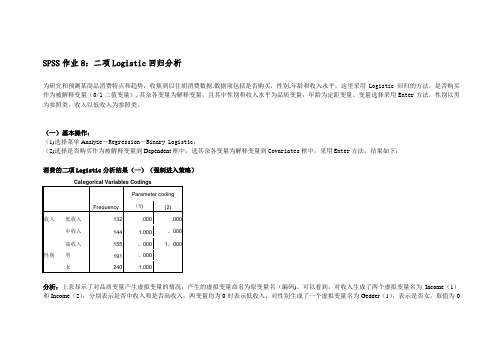
SPSS作业8:二项Logistic回归分析为研究和预测某商品消费特点和趋势,收集到以往胡消费数据.数据项包括是否购买,性别,年龄和收入水平。
这里采用Logistic回归的方法,是否购买作为被解释变量(0/1二值变量),其余各变量为解释变量,且其中性别和收入水平为品质变量,年龄为定距变量。
变量选择采用Enter方法,性别以男为参照类,收入以低收入为参照类。
(一)基本操作:(1)选择菜单Analyz e-Regression-Binary Logistic;(2)选择是否购买作为被解释变量到Dependent框中,选其余各变量为解释变量到Covariates框中,采用Enter方法,结果如下:消费的二项Logistic分析结果(一)(强制进入策略)Categorical Variables CodingsFrequency Parameter coding (1) (2)收入低收入132 .000 .000中收入144 1.000 。
000高收入155 。
000 1。
000性别男191 。
000女240 1.000分析:上表显示了对品质变量产生虚拟变量的情况,产生的虚拟变量命名为原变量名(编码)。
可以看到,对收入生成了两个虚拟变量名为Income(1)和Income(2),分别表示是否中收入和是否高收入,两变量均为0时表示低收入;对性别生成了一个虚拟变量名为Gedder(1),表示是否女,取值为0时表示为男。
消费的二项Logistic 分析结果(二)(强制进入策略)Block 0: Beginning BlockClassification Table a,bObserved Predicted是否购买 Percentage Correct不购买购买Step 0是否购买不购买 269 0 100。
购买162。
0 Overall Percentage62。
4a 。
Constant is included in the model 。
实用回归分析论文(SPSS实验结果)
实用回归分析论文(SPSS实验结果)由于没有具体的数据或研究题目,以下仅为回归分析论文的一般模板。
1. 研究背景和目的:介绍本次研究的背景和目的。
描述相关文献对该领域的研究情况,指出知识空白和研究的必要性。
例如:本研究旨在探讨X变量与Y变量之间的关系,并研究其他可能因素对此关系的影响。
回归分析被广泛应用于社会科学、经济学和医学等领域,但在某些情况下,该方法可能被错误地应用或解读。
因此,本研究旨在提供更多有关回归分析的实用性信息,以便更好地应用于实际研究中。
2. 变量选择和数据收集:介绍所选的独立变量、因变量以及可能的干扰因素。
描述数据收集的方法和样本的特点,阐述数据的统计学特征。
例如:本研究选择了X1、X2和X3作为独立变量,Y作为因变量。
在探究X和Y之间的关系时,本研究考虑了干扰因素A和B。
数据收集采用了问卷调查的方法,样本为100位大学生。
调查数据的统计学特征如下:均值、标准差、最大值和最小值。
3. 回归模型:描述所使用的回归模型及其假设。
根据假设,说明如何进行统计分析。
例如:本研究选择了多元线性回归模型。
假设独立变量与因变量之间存在线性关系,且同时考虑了干扰因素的影响。
在此假设下,通过进行多元线性回归分析,得出具体的回归方程。
使用SPSS软件进行统计分析,通过显著性检验和模型拟合程度来验证上述假设。
4. 实验结果:解释回归分析结果,如拟合程度、系数的显著性、变量的解释等。
根据结果,提供对研究目的的回答,对假说进行证明或推翻。
例如:本研究得到的回归方程为Y = a + b1*X1 + b2*X2 + b3*X3 +c1*A + c2*B。
通过F检验,得出回归模型的显著性水平P<0.01,表明回归模型解释了数据的一定程度。
通过系数显著性检验,得出X1、X3和B对Y变量具有显著影响,而其余变量影响不显著。
对于X1、X3和B,本研究解释了其对Y变量的具体贡献,分析了研究问题的深层含义。
5. 结论和建议:总结研究结论,说明其对实践和理论的贡献,并提出未来研究的方向。
spss回归分析报告怎么写
spss回归分析报告怎么写引言回归分析是一种统计分析方法,用于研究自变量与因变量之间的关系。
在社会科学研究中,SPSS是常用的统计分析软件之一,可以进行回归分析并生成回归分析报告。
本文将详细介绍如何使用SPSS生成回归分析报告,并对其中的关键内容进行详细解释。
数据收集与处理在进行回归分析之前,首先需要收集相关的数据,并进行必要的数据处理。
数据收集可以采用问卷调查、实验观测等方式。
数据处理包括数据清洗、缺失值处理、异常值处理等步骤,旨在提高数据的质量和可靠性。
描述性统计分析在进行回归分析之前,可以先进行描述性统计分析,对所研究的变量进行初步了解。
描述性统计分析可以包括计算变量的均值、标准差、最大值、最小值等指标,绘制柱状图、箱线图等图表。
这些统计指标和图表可以帮助我们对数据的分布情况、异常值等情况进行初步判断。
回归分析步骤回归分析的基本步骤包括建立模型、估计参数、模型检验和解释结果。
下面将详细介绍每个步骤。
1. 建立模型在SPSS中,可以通过选择回归分析功能,将自变量和因变量输入模型中。
通常情况下,将因变量放在因变量框中,并将自变量放在预测框中。
可以选择的参数包括常数项、线性项、交互项等。
2. 估计参数在建立模型后,SPSS会自动进行参数估计,并生成相应的结果。
估计参数主要是通过最小二乘法进行计算,得出自变量对因变量的回归系数和截距项的估计值。
3. 模型检验模型检验是分析回归模型的拟合程度和可靠性。
SPSS会给出很多统计指标来评估模型的适应度,例如F统计量、R方、调整的R方等。
此外,还可以检验回归系数的显著性,判断自变量是否对因变量有显著影响。
4. 解释结果在报告中,需要对模型的结果进行解释和详细分析。
可以对回归系数逐个进行讨论,解释每个自变量对因变量的影响程度和方向。
同时,也可以利用图表展示模型的结果,例如画出散点图、拟合直线图等,直观地展示自变量和因变量之间的关系。
结论与建议在回归分析报告的最后,需要对研究结果进行总结,并给出相应的建议。
SPSS实验多元线性回归分析12
这里我们以总成绩作为因变量Y,平时成绩和期中成绩分别作为自变量X1,X2,建立的多元回归模型为:
Байду номын сангаас2,估计参数,建立回归预测模型
利用SPSS可得一下结果:
Variables Entered/Removedb
Model
Variables Entered
Variables Removed
1183.800
19
a. Predictors: (Constant),期中成绩,平时成绩
b. Dependent Variable:总成绩
注释:从表中可得拟合方程的F统计量值为7.586,相应的P值为0.000说明,拟合方程是显著的。是具有统计意义的。
Coefficientsa
Model
Unstandardized Coefficients
Method
1
期中成绩,平时成绩a
.
Enter
a. All requested variables entered.
b. Dependent Variable:总成绩
注释:根据这个表的结果我们可以初步的知道,经过检验自变量X1,X2是可以加入到准备估计的回归方程中作为变量的。
Model Summaryb
Standardized Coefficients
t
Sig.
95% Confidence Interval for B
Correlations
Collinearity Statistics
B
Std. Error
Beta
Lower Bound
Upper Bound
Zero-order
SPSS的线性回归分析分析
SPSS的线性回归分析分析SPSS是一款广泛用于统计分析的软件,其中包括了许多功能强大的工具。
其中之一就是线性回归分析,它是一种常用的统计方法,用于研究一个或多个自变量对一个因变量的影响程度和方向。
线性回归分析是一种用于解释因变量与自变量之间关系的统计技术。
它主要基于最小二乘法来评估自变量与因变量之间的关系,并估计出最合适的回归系数。
在SPSS中,线性回归分析可以通过几个简单的步骤来完成。
首先,需要加载数据集。
可以选择已有的数据集,也可以导入新的数据。
在SPSS的数据视图中,可以看到所有变量的列表。
接下来,选择“回归”选项。
在“分析”菜单下,选择“回归”子菜单中的“线性”。
在弹出的对话框中,将因变量拖放到“因变量”框中。
然后,将自变量拖放到“独立变量”框中。
可以选择一个或多个自变量。
在“统计”选项中,可以选择输出哪些统计结果。
常见的选项包括回归系数、R方、调整R方、标准误差等。
在“图形”选项中,可以选择是否绘制残差图、分布图等。
点击“确定”后,SPSS将生成线性回归分析的结果。
线性回归结果包括多个重要指标,其中最重要的是回归系数和R方。
回归系数用于衡量自变量对因变量的影响程度和方向,其值表示每个自变量单位变化对因变量的估计影响量。
R方则反映了自变量对因变量变异的解释程度,其值介于0和1之间,越接近1表示自变量对因变量的解释程度越高。
除了回归系数和R方外,还有其他一些统计指标可以用于判断模型质量。
例如,标准误差可以用来衡量回归方程的精确度。
调整R方可以解决R方对自变量数量的偏向问题。
此外,SPSS还提供了多种工具来检验回归方程的显著性。
例如,可以通过F检验来判断整个回归方程是否显著。
此外,还可以使用t检验来判断每个自变量的回归系数是否显著。
在进行线性回归分析时,还需要注意一些统计前提条件。
例如,线性回归要求因变量与自变量之间的关系是线性的。
此外,还需要注意是否存在多重共线性,即自变量之间存在高度相关性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
回归分析
一.实验描述:
中国民航客运量的回归模型。
为了研究我国民航客运量的变化趋势及其成因,我们以民航客运量作为因变量Y,
以国民收入(X1)、消费额(X2)、铁路客运量(X3)、民航航线里程(X4)、来华旅游入境人数(X5)、为主要
影响因素。
数据如下表。
试建立Y与X1--X5之间的多元线性回归模型。
二.实验过程描述及实验结果
(1)
该表格中输出了5个自变量和1个因变量的一般统计结果,包括各自变量与因变量的平均值,标准差和个案数16。
该表格中列出了各个变量之间的相关性,从该表格可以看出因变量Y和自变量X1之间的相关
系数为0.989,相关性最大,。
因变量Y与自变量X3之间相关系数为0.227,相关性最小。
(3)
该表格输出的是被引入或从回归方程中被剔出的各变量。
说明进行线性回归分析时所采用的
方法是全部引入法Enter。
因变量为Y。
(4)
该表格输出的是常用统计量。
从该表看出相关性系数R为0.999,判定系数R2为0.998,调整的判定系数为0.997,回归估计的标准误差为49.49240。
该表格输出的是方差分析表。
从这部分结果看出:统计量F为1.128E3;相伴概率值小于0.01,拒绝原假设说明多个自变量与因变量Y之间存在线性回归关系。
Sum of Squares一栏中分别代表回归平方和(1.382E7),残差平方和(24494.981)以及总平方和(1.384E7),df为自由度。
判定系数R2=0.99855。
该表格为回归系数分析。
其中Unstandardized Coefficients为非标准化系数,Standardized Coefficients为标准化系数,t为回归系数检验统计量,sig为相伴概率值。
由表知t检验的相伴概率值均小于0.01,拒绝原假设,说明个变量与因变量之间均有显著线性相关关系。
从表格中可以看出该多元线性回归方程为:
y=450.909+0.354 X1-0.561 X2-0.007 X3+21.578 X4+0.435 X5
该表格为残差统计结果表。
列出了预测值,标准预测值,预测值标准差等指标的最小值,最大值,平均值,方差和N数。
(8)
该图为回归因变量Y和自变量X1之间的关系点图。