SPSS对主成分回归实验报告
主成分分析报告
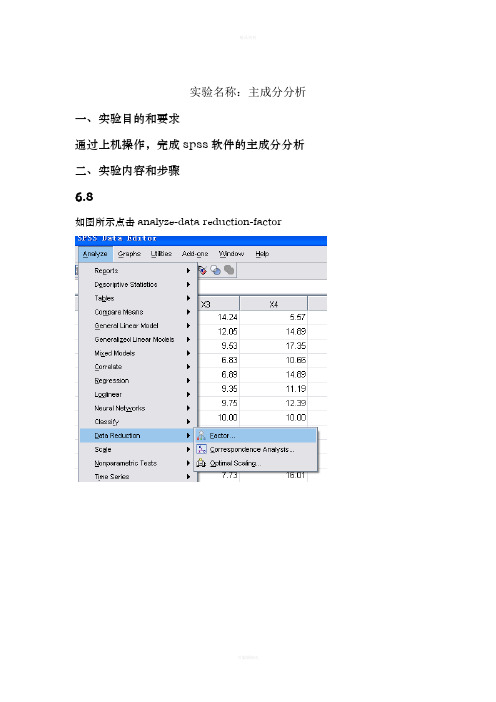
实验名称:主成分分析一、实验目的和要求通过上机操作,完成spss软件的主成分分析二、实验内容和步骤6.8如图所示点击analyze-data reduction-factor将6个变量选入变量框中分别点击descriptive rotation选项,进行以下操作点击extraction进行以下分析点击options结果如下所示Correlation MatrixX1X2X3X4X5X6Correlation X1 1.000.711.420.182.081-.166 X2.711 1.000.141.275.302-.051X3.420.141 1.000.028-.142.353X4.182.275.028 1.000.384.042X5.081.302-.142.384 1.000.104X6-.166-.051.353.042.104 1.000上表为相关矩阵,给出了6个变量之间的相关系数主对角线的值均为1,绝大大部分小于0.01,因此可以说明因子之间相关性不是特别的大。
KMO and Bartlett's TestKaiser-Meyer-Olkin Measure of Sampling Adequacy..434Bartlett's Test of Sphericity Approx. Chi-Square45.919 df15 Sig..000上表为KMO和Bartlett检验表,KMO检验是对变量是否适合做因子分析的检验,根据Kaiser常用度量标准,因为此时KMO=0.434,表示此事不适合做因子分析,所以我们用主成分分析。
上表额为公因子方差,给出了盖茨分析中从每个原始变量中提取的信息,从表中可以看出除了人均城市道路面积X4(平方米),主成分几乎都包含了其余各个变量至少80%的信息。
Total Variance ExplainedComponentInitial Eigenvalues Extraction Sums of Squared Loadings Total% of Variance Cumulative %Total% of Variance Cumulative %1 2.08234.69534.695 2.08234.69534.6952 1.39223.19757.892 1.39223.19757.8923 1.24520.75778.649 1.24520.75778.6494.66511.09089.7395.4427.36297.1016.174 2.899100.000Extraction Method: Principal Component Analysis.上表为特征根于方差贡献表,给出了个主成分解释原始变量总方差的情况,从表中可以看出,本例中保留了3个主成分,集中了原始变量总信息的78.649%上图为碎石土,分析碎石土看出因子1与因子2与因子3特征值差值比较大,而其他特征值比较小,可以出保留3个因子能概括绝大部分信息。
主成份数据分析报告Spss和R语言

一、实验题目主成份分析实验二、实验目的通过本次实验对数据的处理,掌握主成份分析的原理,熟悉主成份分析在SPSS软件和R语言中的实现。
三、实验原理四、实验数据如下给出中国近年国民经济主要指标统计,用主成分分析法对这些指标提取主成份,写出提取的主成份与这些指标之间的表达式。
原始数据如下:四、SPSS实验步骤○1、定义变量②、输入数据③在菜单栏中选择“分析”→“降维”→“因子分析”。
④、除了“年份”选项都选入变量列表。
⑤、单击“描述”→选中“原始分析结果”复选框→“度”设为线性;选中“系数”⑥单击“抽取”,选中“未旋转的因子解”复选框。
其余默认⑦、选中“得分”→“保存为变量”⑧、选中“转换”→“计算变量”,数字表达式中分别输入“a9=b9/SQR(3.849)”“a10=b1 0/SQR(1.808)”,由载荷矩阵得到主成份特征向量矩阵(a9 a10),(变量视图中改变增加的变量b9、b10、a9、a10的小数位数为3)五、SPSS实验结果与分析1、运行结果图如下所示:2、spss结果分析:由成分矩阵可以得到各个变量的线性组合表达的主成份:F1=0.322*全国人口+0.448*农林牧渔业总产值+0.497*工业总产值+0.475*国内生产总值+0.392*油料+0.432*全社会投资总额+0.458*棉花-0.093*粮食;F2=-0.021*全国人口+0.267*农林牧渔业总产值+0.062*工业总产值+0.027*国内生产总值-0.368*油料+0.261*全社会投资总额-0.126*棉花+0.719*粮食。
在第一主成份中,除了粮食以外的变量的系数比较大,可以看成反映那些变量的综合指标;在第二主成份中,变量粮食的系数比较大,可以看成反映粮食的综合指标。
主成分分析是一种矩阵变换,各个主成分并不一定有实际意义,本题目中的主成份含义不明确。
由系数相关矩阵,各个变量之间都有一定的相关关系,一些相关系数接近于1,适合用主成分分析。
SPSS对主成分回归实验报告

《多元统计剖析剖析》试验陈述学院经贸学院姓名学号试验试验成绩名称一.试验目标(一)应用SPSS对主成分回归进行盘算机实现.(二)请求闇练软件操纵步调,重点控制对软件处理成果的说明.二.试验内容以教材例题7.2为试验对象,应用软件对例题进行操纵演习,以控制多元统计剖析办法的应用三.试验步调(以文字列出软件操纵进程并附上操纵截图)1.数据文件的输入或树立:(文件名以学号或姓名定名)将表7.2数据输入spss:点击“文件”下“新建”——“数据”见图1:图1点击左下角“变量视图”起首界说变量名称及类型:见图2:图2:然后点击“数据视图”进行数据输入(图3):图3完成数据输入2.具体操纵剖析进程:(1)起首做因变量Y与自变量X1-X3的通俗线性回归:在变量视图下点击“剖析”菜单,选择“回归”-“线性”(图4):图4将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5):然后选择相干要输出的成果:①点击右上角“统计量(s)”:“回归系数”下选择“估量”;“残差”下选择“”;在右上角选择输出“模子拟合度”.“部分相干和偏相干”“共线性诊断”(后两项是做多重共线性磨练).选完后点击“持续”(见图6)②假如须要对因变量与残差进行图形剖析则须要在“绘制”下选择相干项目(图7),一般不须要则持续③假如须要将相干成果如因变量猜测值.残差等保管则点击“保管”(图8),选摘要保管的项目④假如是慢慢回归法或者设置不带常数项的回归模子则点击“选项”(图9)其他选项按软件默认.最后点击“肯定”,运行线性回归,输出相干成果(见表1-3)图5 图6图7图8图9回归剖析输出成果:表1模子汇总b可以做因子剖析)选完后点击“持续”进行下一步;②点击“抽取”(见图13):在“办法”下默认“主成分”;“剖析”下,默认“相干性矩阵”(寄义是要对变量做尺度化处理,然后基于尺度化后的协差阵也就是相干阵进行分化做因子剖析或主成分剖析),假如不须要对变量做尺度化处理就选“协方差矩阵”;“输出”中的两项都选,请求输出没有扭转的因子解(主成分剖析必选项)和碎石图(用图形决议提取的主成分或因子的个数);“抽取“下,默认的是基于特点值(大于1暗示提取的因子或主成分至少代表1个单位尺度差的变量信息,因为尺度化后的变量方差为1,因子或者主成分作为提取的分解变量应当至少代表1个变量的信息),也可以自选提取的因子个数(即第二项),本例中做主成分回归,选择提取全体可能的3个主成分,所以自选个数填3.选完后点击“持续”进行下一步;③点击“扭转”(图14),按默认的“办法”下不扭转(留意,主成分剖析不克不及扭转!)其他不必选,点击“持续”进行下一步;④点击“得分”,盘算不扭转的初始因子得分(图15),选中“保管为变量”,“办法”下按默认,其他不修正,点击“持续”进行下一步.⑤“选项”下可以不选按默认(选项里重要针对缺掉值和系数显示格局,不影响剖析成果)最后点击“肯定”,运行因子剖析.图10图11图12图13图14图15由运行成果盘算主成分:表4.描写统计量均值尺度差剖析 N x1 11 x2 11 x311表5.相干矩阵x1 x2 x3相干x1 .026 .997 x2 .026.036x3.997 .036Sig.(单侧)x1.470 .000x2 .470.459x3.000 .459表6.KMO 和 Bartlett 的磨练 取样足够度的 Kaiser-Meyer-Olkin 器量..492Bartlett 的球形度磨练 近似卡方 df3 Sig..000表7.说明的总方差成份初始特点值 提取平方和载入合计 方差的 % 累积 % 合计 方差的 % 累积 % 12 .998.9983.003 .090 .003 .090提取办法:主成份剖析.表8.成份矩阵a图16图17图18 图19图20图21主成分回归成果:表9.模子汇总模子R R 方调剂 R 方尺度估量的误差1 .994a.988 .985 .12104901a. 猜测变量: (常量), F1, F2.表10.Anova b模子平方和df 均方 F Sig.。
利用SPSS进行主成分回归分析1

题〔1~4〕。
1 基本原理与计算方法
111 以应变量 Y 和全部自变量 X 进行逐步回归 ,筛选出 P 个
有统计学意义的自变量 ,并且诊断各自变量的多重共线性 。
112 用 P 个自变量进行主成分分析 ,得到主成分矩阵和各主
成分的累计方差百分比 。
113 计算标化应变量和 P 个标化自变量分别见式 ( 111) 和
0102
0100
3 0106533 71166 0156
0110
0101
4 01007352 211362 0129
0188
0199
X4 0100 0100 0124 0176
212 使用 SPSS Factor Analysis 过程 ,对自变量 X1 , X3 和 X4 进行主成分分析 在 Factor Analysis 对话框 ,把自变量 X1 ,X3 和 X4 放入 Variables 栏 。
Abstract: Objective To introduce how to do t he principal component regression analysis wit h SPSS. Methods The analysis steps of t he principal component regression by combining t he Lin2 ear Regression , Factor Analysis , Compute Variable and Bivariate Correclations procedures in SPSS 8. 0 for Windows wit h t he basic principles of t he principal component regression are introduced. Results An example is used to describe all operations of each pro2 cedures in SPSS8. 0 and all calculating processes of principal com2 ponent regression ,and t he“best”equation is built . Conclusions The each indexes of multicollinearity diagnosis and t he advantage and t he point for attention about principal component regression analysis are introduced ,and t he simplified ,speeded up and accurate statistical effect are reached t hrough t he prinicipal component re2 gression analysis wit h SPSS.
SPSS数据的主成分分析报告

2019/9/10
4
zf
多个指标的问题:
1、指标与指标可能存在相关关系 信息重叠,分析偏误
2、指标太多,增加问题的复杂性和分析难度
如何避免?
2019/9/10
5
zf
主成分分析的基本思想
一项十分著名的工作是美国的统计学家斯通(stone)在 1947年关于国民经济的研究。他曾利用美国1929一1938 年各年的数据,得到了17个反映国民收入与支出的变量 要素,例如雇主补贴、消费资料和生产资料、纯公共支 出、净增库存、股息、利息外贸平衡等等。
运用主成分得分系数矩阵解释主成分:
王冬《我国外汇储备增长因素主成分分析》,《北京工商大学学报》, 2006年4期。
田波平等《主成分分析在中国上市公司综合评价中的作用》,《数学 的实践与认识》,2004年4期
2019/9/10
25
zf
主成分解释的案例分析
基于相关系数矩阵的主成分分析。对美国纽约上市的有关化学产业的三支股票 (Allied Chemical, du Pont, Union Carbide)和石油产业的2支股票(Exxon and Texaco )做了100周的收益率调查(1975年1月-1976年10月)。
F1
F2
F3
i
i
t
F1
1
F201源自F3001
i 0.995 -0.041 0.057 l
Δi -0.056 0.948 -0.124 -0.102 l
t -0.369 -0.282 -0.836 -0.414 -0.112 1
2019/9/10
7
zf
主成分分析:将原来具有相关关系的多个指标简化为少数几个 新的综合指标的多元统计方法。
统计分析软件应用SPSS-主成分分析实验报告

本科学生综合性、设计性实验报告实验课程名称统计分析软件应用开课学期2010至2011学年下学期上课时间2011 年4 月25 日辽宁师范大学教务处编印、实验方案、实验目的:掌握主成分分析的思想和具体步骤。
掌握SPSS实现主成分分析的具体操作,并对处理结果做出解释。
5、参考文献:[1]卢纹岱.SPSS for Window銃计分析[M].电子工程出版社,2006[2]郭显光.如何用SPS歎件进行主成分分析[J].统计与信息论坛,1998, (2)[3]何晓群.现代统计分析方法与应用[M].中国人民大学出版社,1998[4]余建英、何旭宏.数据统计分析与SPSS^用[M].人民邮电出版社,2003、实验报告1、 实验目的、设备与材料、理论依据、实验方法步骤见实验设计方案2、 实验现象、数据及结果表1描述性统计量表表2主成分因子荷载矩阵表表3相关系数矩阵表表4公因子方差表Descriptive Statistics图1碎石图Component U 刨乡至拜占,3 GQmponenls extrudedCommunalitiesExtraction Method: Principal Component Analysis.表总方差分解表Total Variance ExplainedCompoiieint initial EigenvaluesExtraction Sums of Squared Loadings Tota J cf Variance Cumulabv? % Total % of '/a™nee Cumulative %1 3&14 48.929 +£.929 3.914 4S929 48.92921 312 23.BSS 723271.912 23B96 72 S2? 3■1.430 17.9911.43917 曲■!&G.S1B4 S79 7.335 SB.'353 5,1441,797 9^.3506.012150 100.000 76 13E-Q13 7.66E-017 1Q0JO0S-4.2E-016-4.25E-015IQO.OOQExtraction Method: Prkicipal Component AnalysisInitial Extraction赔付率1.000 .964 净收入与总收入之比 1.000 .993 投资收益率 1.000 .923 再保险率 1.000 .968 总资产报酬率 1.000 .919 两年保费收入收益率 1.000 .659 保费收入变化率 1.000 .961 流动性比率 1.000.879Plolb1= *X1+*X2+**X4+*X5+***X8b2=*X1+**X3+***X6+*X7+*X8 b3=*X1+*X2+*X3+***X6+**X8表7Y1= *x1+*x2+**x4+*x5+***x8 Y2=*xi+*x2- **x4+*x5+***x8 Y3=*x1+*x2+*x3+*x4+**x6+**x8加权:输出结果,并从高到低进行排序:表81:人保2:平安3:太平洋4:大众5:华泰6:永安7:华安 Z 主成分综合得分Num 1 Z 主成分综合得分 | Num华泰1:人保可以如上所述计算主成分得分,还可以通过综合评价函数计算综合得分综合评价函数:Z=%*Y1+%*Y2+%*Y34、结论:表8中,综合得分出现负值,这只表明该保险公司的综合水平处于平均水平之下。
主成分分析、因子分析实验报告--SPSS

主成分分析、因子分析实验报告--SPSS主成分分析、因子分析实验报告SPSS一、实验目的主成分分析(Principal Component Analysis,PCA)和因子分析(Factor Analysis,FA)是多元统计分析中常用的两种方法,旨在简化数据结构、提取主要信息和解释变量之间的关系。
本次实验的目的是通过使用 SPSS 软件对给定的数据集进行主成分分析和因子分析,深入理解这两种方法的原理和应用,并比较它们的结果和差异。
二、实验原理(一)主成分分析主成分分析是一种通过线性变换将多个相关变量转换为一组较少的不相关综合变量(即主成分)的方法。
这些主成分是原始变量的线性组合,且按照方差递减的顺序排列。
主成分分析的主要目标是在保留尽可能多的数据信息的前提下,减少变量的数量,从而简化数据分析和解释。
(二)因子分析因子分析则是一种探索潜在结构的方法,它假设观测变量是由少数几个不可观测的公共因子和特殊因子线性组合而成。
公共因子解释了变量之间的相关性,而特殊因子则代表了每个变量特有的部分。
因子分析的目的是找出这些公共因子,并估计它们对观测变量的影响程度。
三、实验数据本次实验使用了一份包含多个变量的数据集,这些变量涵盖了不同的领域和特征。
数据集中的变量包括具体变量 1、具体变量 2、具体变量 3等,共X个观测样本。
四、实验步骤(一)主成分分析1、打开 SPSS 软件,导入数据集。
2、选择“分析”>“降维”>“主成分分析”。
3、将需要分析的变量选入“变量”框。
4、在“抽取”选项中,选择主成分的提取方法,如基于特征值大于1 或指定提取的主成分个数。
5、点击“确定”,运行主成分分析。
(二)因子分析1、同样在 SPSS 中,选择“分析”>“降维”>“因子分析”。
2、选入变量。
3、在“描述”选项中,选择相关统计量,如 KMO 检验和巴特利特球形检验。
4、在“抽取”选项中,选择因子提取方法,如主成分法或主轴因子法。
SPSS回归分析实验报告

中国计量学院现代科技学院实验报告实验课程:应用统计学实验名称:回归分析班级:学号:姓名:实验日期: 2012.05.23 实验成绩:指导教师签名:一.实验目的一元线性回归简单地说是涉及一个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。
本实验要求掌握一元线性回归的求解和多元线性回归理论与方法。
二.实验环境中国计量学院现代科技学院机房310三.实验步骤与内容1打开应用统计学实验指导书,新建excel表地区供水管道长度(公里)全年供水总量(万平方米)北京15896 128823 天津6822 64537 河北10771.2 160132 山西5669.3 77525 内蒙古5635.5 59276 辽宁21999 280510 吉林6384.9 159570 黑龙江9065.9 153387 上海22098.8 308309 江苏36632.4 380395 浙江24126.9 235535 安徽7389.4 204128 福建6270.4 118512 江西5094.7 143240 山东26073.9 259782 河南11405.6 185092 湖北15668.6 257787 湖南9341.8 262691 广东35728.8 568949 广西6923.1 134412 海南1726.7 20241 重庆6082.7 71077 四川12251.3 165632 贵州3275.3 45198 云南5208.5 52742 西藏364.9 5363陕西4270 73580甘肃5010 62127青海893 14390宁夏1538.2 22921新疆3670.2 766852.打开SPSS,将数据导入3.打开分析,选择回归分析再选择线性因变量选全年供水总量,自变量选供水管道长度统计里回归系数选估计,再选择模型拟合按继续再按确定会出来分析的结果对以上结果进行分析:(1)回归方程为:y=28484.712+11.610X(X是自变量供水管道长度,Y是因变量全年供水总量)(2)检验1)拟合效果检验根据表2可知,R2=0.819,即拟合效果好,线性成立。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《多元统计分析分析》实验报告
2012 年月日
学院经贸学院姓名学号
实验
实验成绩名称
一、实验目的
(一)利用SPSS对主成分回归进行计算机实现.
(二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释.
二、实验内容
以教材例题7.2为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用
三、实验步骤(以文字列出软件操作过程并附上操作截图)
1、数据文件的输入或建立:(文件名以学号或姓名命名)
将表7.2数据输入spss:点击“文件”下“新建”——“数据”见图1:
图1
点击左下角“变量视图”首先定义变量名称及类型:见图2:
图2:
然后点击“数据视图”进行数据输入(图3):
图3
完成数据输入
2、具体操作分析过程:
(1)首先做因变量Y与自变量X1-X3的普通线性回归:
在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4):
图4
将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5):
然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“D.W”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。
选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9)
其他选项按软件默认。
最后点击“确定”,运行线性回归,输出相关结果(见表1-3)
图5 图6
图7
图8
图9
回归分析输出结果:
的协差阵也就是相关阵进行分解做因子分析或主成分分析),如果不需要对变量做标准化处理就选“协方差矩阵”;“输出”中的两项都选,要求输出没有旋转的因子解(主成分分析必选项)和碎石图(用图形决定提取的主成分或因子的个数);“抽取“下,默认的是基于特征值(大于1表示提取的因子或主成分至少代表1个单位标准差的变量信息,因为标准化后的变量方差为1,因子或者主成分作为提取的综合变量应该至少代表1个变量的信息),也可以自选提取的因子个数(即第二项),本例中做主成分回归,选择提取全部可能的3个主成分,所以自选个数填3。
选完后点击“继续”进行下一步;③点击“旋转”(图14),按默认的“方法”下不旋转(注意,主成分分析不能旋转!)其他不用选,点击“继续”进行下一步;④点击“得分”,计算不旋转的初始因子得分(图15),选中“保存为变量”,“方法”下按默认,其他不修改,点击“继续”进行下一步。
⑤“选项”下可以不选按默认(选项里主要针对缺失值和系数显示格式,不影响分析结果)
最后点击“确定”,运行因子分析。
图10
图11
图12
图13
图14
图15
由运行结果计算主成分:
表4、描述统计量
均值标准差分析 N
x1 194.5909 29.99952 11
x2 3.3000 1.64924 11
x3 139.7364 20.63440 11
表5、相关矩阵
x1 x2 x3
相关x1 1.000 .026 .997
x2 .026 1.000 .036
x3 .997 .036 1.000
Sig.(单侧)x1 .470 .000
x2 .470 .459
x3 .000 .459
表6、KMO 和 Bartlett 的检验
取样足够度的 Kaiser-Meyer-Olkin 度量。
.492
Bartlett 的球形度检验近似卡方42.687
df 3
Sig. .000
表7、解释的总方差
成份初始特征值提取平方和载入
合计方差的 % 累积 % 合计方差的 % 累积 %
1 1.999 66.638 66.638 1.999 66.638 66.638
2 .998 33.272 99.910 .998 33.272 99.910
3 .003 .090 100.000 .003 .090 100.000 提取方法:主成份分析。
表8、成份矩阵a
成份
1 2 3
x1 .999 -.036 .037
x2 .062 .998 .000
x3 .999 -.026 -.037
提取方法 :主成份。
a. 已提取了 3 个成份。
由表5、6可知适合做主成分或因子分析(KMO检验通过),表7知前两个主成分(初始因子)贡献率已达99.91%,提取前两个主成分用于分析。
由表8(初始因子载荷阵)和表7可计算前两个特征向量,用表8前两列分别除以前两个特征值的平方根得前两个主成分表达式:
F1=0.7066X1*+0.0439X2*+0.7066X3*(式1)
F2=-0.0360X1*+0.9990X2*-0.0260X3*(式2)
其中X1*-X3*表示为标准化变量(这是因为在进行主成分分析时是以标准化变量进行分析的,是从相关阵出发分析的,见图13的选项)。
由于主成分互不相关,可以用提取的主成分代替自变量进行回归分析,因此需要计算主成分得分来代替自变量X1-X3。
主成分的计算:依据式1和2中两个主成分的表达式,对各自变量标准化后带入就可以计算出每个样品的主成分得分。
但是在spss中,由因子分析提取时是用主成分法提取的,根据初始因子与主成分的关系,未旋转的初始因子等于主成分除以特征根的平方根,因此主成分得分等于因子得分乘以特征根的平方根,因此可以由因子得分计算主成分得分。
前面在因子分析选项中保存了因子得分(见图15),因此计算两个主成分得分:点击“转换”—“计算变量”(图16):在弹出的窗口分别定义主成分F1=第一因子得分*第一特征根的平方根(图17)和F2=第二因子得分*第二特征根的平方根。
(3)主成分回归过程:
要做主成分回归,需要用标准化的因变量(因为自变量经过标准化处理做主成分分析,因变量需要对应做标准化)与主成分做回归,对因变量Y做标准化处理,点击“分析”—“描述统计”—“描述”(见图18),在弹出窗口中将Y调入变量,并选中“将标准化得分另存为变量”(图19)后确定完成Y的标准化。
点击“分析”---“回归”---“线性”(图20)在弹出窗口(图21)中将Zscore(y)调入因变量,F1和F2调入自变量,其他选项同前面图6-9,然后点击“确定”运行主成分回归,相关输出结果见表9
图16
图17
图18 图19
图20
图21
主成分回归结果:
表9、模型汇总
模型R R 方调整 R 方标准估计的误
差
1 .994a.988 .985 .12104901
a. 预测变量: (常量), F1, F2。