SPSS回归分析报告作业
SPSS实验6-回归分析

SPSS作业6:回归分析(一)回归分析多元线性回归模型的基本操作:(1)选择菜单Analyze-Regression-Linear;(2)选择被解释变量(能源消费标准煤总量)和解释变量(国内生产总值、工业增加值、建筑业增加值、交通运输邮电业增加值、人均电力消费、能源加工转换效率)到对应框中;(3)在Method框中,选择Enter方法;在Statistics框中,选择Estimates、Model fit、Covariancematrix、Collinearity diagnostics选项;在Plots框中,选择ZRESED到Y框,ZPRED到X框,再选择Histogram和Normal plot;(4)选择菜单Analyze-Non Test-1-Sanple K-S;选择菜单Analyze-Correlate-Brivariate;结果如下:Regression能源消费需求的多元线性回归分析结果(强制进入策略)(一)Model Summary bModel R R Square Adjusted R Square Std. Error of the Estimate1 .990a.980 .973 8480.38783a. Predictors: (Constant), 能源加工转换效率/%, 交通运输邮电业增加值/亿元, 工业增加值/亿元, 人均电力消费/千瓦时, 建筑业增加值/亿元, 国内生产总值/亿元b. Dependent Variable: 能源消费标准煤总量/万吨分析:被解释变量和解释变量的复相关系数为0.990,判定系数为0.980,调整的判定系数为0.973,回归方程的估计标准误差为8480.38783。
该方程有6个解释变量,调整的判定系数为0.973,,接近于1,所以拟合优度较高,被解释变量可以被模型解释的部分较多,未能解释的部分较少。
分析:由上可知,被解释变量的总离差平方和为5.882E10,回归平方和及均方分别为5.766E10和9.611E9,剩余平方和及均方分别为1.151E9和7.192E7,F检验统计量的观测值为133.636,对应的概率p值近似为0。
SPSS多元回归实验报告

实验八报告一、数据来源Employee data. sav 二、基本结果(1)确定自变量、因变量:)确定自变量、因变量:一般而言,因变量y与各自变量xj(j=1,2,3,…,n)之间的多元线性回归模型:之间的多元线性回归模型:其中:b0是回归常数;b k (k=1,2,3,…,n)是回归参数;e是随机误差。
是随机误差。
根据employee data.sav的数据,其中Y是当前工资salary,X1是起始资金salbegin,X2是工作经验prevexp,X3是工作时间jobtime,X4是工作种类jobcat,X5是受教育年限edcau。
(2)做出因变量与自变量的散点图:)做出因变量与自变量的散点图:从散点图可以看出因变量与各自变量之间存在线性关系。
(3)检验因变量Y是否服从正态分布的模型假定——因变量Y并没有很好地服从正态分布。
地服从正态分布。
的残差图(4)线性回归Y的残差图此标准化残差图表明,此线性回归的标准化残差呈楔形分布而非带状分布,不满足回归模型同方差的假定。
布,不满足回归模型同方差的假定。
当前薪金多元线性回归分析的残差图图当前薪金多元线性回归分析的残差图(5)通过以上检验可以看出,当前薪金并不是好的变量,对当前薪金进行Ln变换(取对数)生成新的随进变量logsale,将logsale作为因变量Y用逐步回归的方法进行回归分析:的方法进行回归分析:1)p-p图:图:较好的服从了正态分布。
发现取对数后,logY较好的服从了正态分布。
2)logY的标准化残差图:的标准化残差图:上图表明因变量Y(logsale)的标准化残差近似呈带状分布,满足模型同方差的假定。
差的假定。
3)逐步回归的判定系数:)逐步回归的判定系数:通过逐步回归,得到方程的判定系数如下表。
R²越接近1,说明回归方程解释了因变量总变异量的绝大部分比例。
本估计的回归方程有一个好的拟合,,可以认为拟合度高。
在模型5中达到0.810,且调整后的R²达到0.808,可以认为拟合度高。
回归分析报告例题SPSS求解过程

回归分析例题SPSS求解过程1、一元线性回归SPSS求解过程:判别:x y 202.0173.2ˆˆˆ10+=+=ββ,且x 与y 的线性相关系数为R=0.951 ,回归方程的F 检验值为75.559,对应F 值的显著性概率是0.000<0.05,表示线性回归方程具有显著性 ,当对应F 值的显著性概率>0.05,表示回归方程不具有显著性。
每个系数的t 检验值分别是3.017与8.692,对应的检验显著性概率分别为:0.017(<0.05)和0.000(<0.05),即否定0H ,也就是线性假设是显著的。
二、一元非线性回归SPSS求解过程:1、Y与X的二次及三次多项式拟合:所以,二次式为:2029.07408.00927.6x x Y -+=三次式为:320046.01534.07068.1118.4x x x Y +-+=2、把Y 与X 的关系用双曲线拟合: 作双曲线变换:xV y U 1,1==判别:V U 131.0082.0-=,xV y U 1,1==,V 与U 的相关系数为R=0.968,回归方程系数的F 检验值为196.227,对应F 值的显著性概率是0.000(<0.05),表示线性回归方程具有显著性 ,每个系数的t 检验值分别是440514与14.008,对应的检验显著性概率分别为:0.000(<0.05)和0.000(<0.05),即否定0H ,也就是线性假设是显著的。
3、把Y 与X 的关系用倒指数函数拟合: xbae Y =,则xb a Y 1ln ln +=令U1=LN (Y ),V1=V=1/x,有 U1=c+b V1.判别:V U 111.1458.21-=,x V y U /1,ln 1==,V 与1U 的相关系数为R=0.979,回归方程的F 检验值为303.190,对应F 值的显著性概率是0.000(<0.05),表示线性回归方程具有显著性 ,每个系数的t 检验值分别是195.221与-17.412,对应的检验显著性概率分别为:0.000(<0.05)和0.000(<0.05),即否定0H ,也就是线性假设是显著的。
SPSS实验8-二项Logistic回归分析
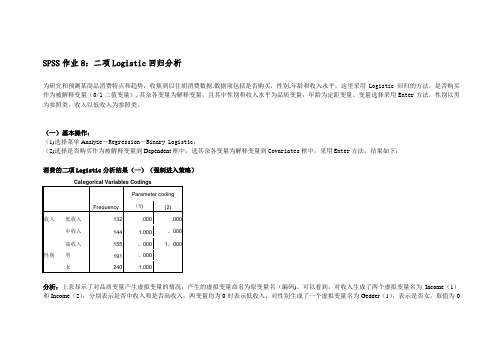
SPSS作业8:二项Logistic回归分析为研究和预测某商品消费特点和趋势,收集到以往胡消费数据.数据项包括是否购买,性别,年龄和收入水平。
这里采用Logistic回归的方法,是否购买作为被解释变量(0/1二值变量),其余各变量为解释变量,且其中性别和收入水平为品质变量,年龄为定距变量。
变量选择采用Enter方法,性别以男为参照类,收入以低收入为参照类。
(一)基本操作:(1)选择菜单Analyz e-Regression-Binary Logistic;(2)选择是否购买作为被解释变量到Dependent框中,选其余各变量为解释变量到Covariates框中,采用Enter方法,结果如下:消费的二项Logistic分析结果(一)(强制进入策略)Categorical Variables CodingsFrequency Parameter coding (1) (2)收入低收入132 .000 .000中收入144 1.000 。
000高收入155 。
000 1。
000性别男191 。
000女240 1.000分析:上表显示了对品质变量产生虚拟变量的情况,产生的虚拟变量命名为原变量名(编码)。
可以看到,对收入生成了两个虚拟变量名为Income(1)和Income(2),分别表示是否中收入和是否高收入,两变量均为0时表示低收入;对性别生成了一个虚拟变量名为Gedder(1),表示是否女,取值为0时表示为男。
消费的二项Logistic 分析结果(二)(强制进入策略)Block 0: Beginning BlockClassification Table a,bObserved Predicted是否购买 Percentage Correct不购买购买Step 0是否购买不购买 269 0 100。
购买162。
0 Overall Percentage62。
4a 。
Constant is included in the model 。
SPSS软件分析7-回归分析作业
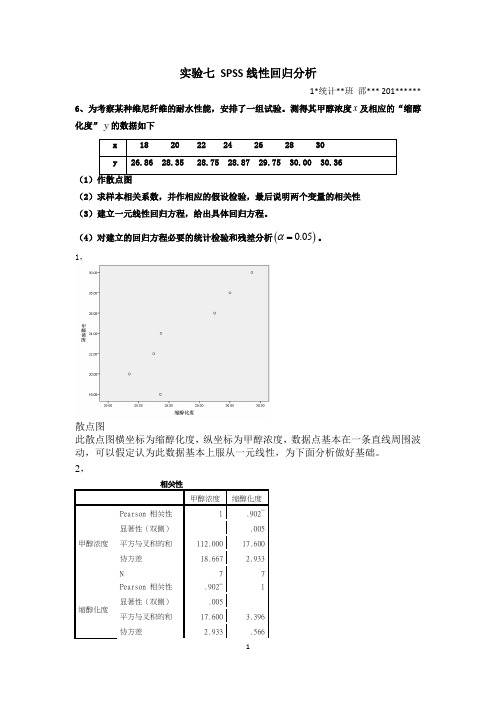
实验七 SPSS 线性回归分析1*统计**班 邵*** 201******6、为考察某种维尼纤维的耐水性能,安排了一组试验。
测得其甲醇浓度x 及相应的“缩醇化度”y 的数据如下(1(2)求样本相关系数,并作相应的假设检验,最后说明两个变量的相关性 (3)建立一元线性回归方程,给出具体回归方程。
(4)对建立的回归方程必要的统计检验和残差分析()0.05α=。
1,散点图此散点图横坐标为缩醇化度,纵坐标为甲醇浓度,数据点基本在一条直线周围波动,可以假定认为此数据基本上服从一元线性,为下面分析做好基础。
2,相关性甲醇浓度缩醇化度甲醇浓度Pearson 相关性 1.902**显著性(双侧).005平方与叉积的和 112.000 17.600 协方差 18.6672.933N7 7 缩醇化度Pearson 相关性.902**1显著性(双侧) .005 平方与叉积的和 17.600 3.396 协方差2.933.566N 7 7**. 在 .01 水平(双侧)上显著相关。
相关性检验-Pearson简单相关系数原假设:认为甲醇浓度和缩醇化度不存在线性关系。
从表中可知,甲醇浓度和缩醇化度的简单相关系数是0.902。
他们的相关系数检验的P值为0.005,因此,给定显著性水平为0.05或0.01时,都应该拒绝原假设,认为两总体存在线性关系。
相关系数旁两个(**)是说明这两个变量的相关性很强。
总之,甲醇浓度和缩醇化度从在极强的正的线性相关性。
建立一元线性模型Y=A+BX原假设:变量甲醇浓度的偏回归系数与0无显著差异。
此表各数列数据项的含义依次为:偏回归系数,对应的概率P值,偏回归系数的标准误,标准化的偏回归系数,回归系数显著性检验中T的观测值,对应的概率p值,解释变量的容忍度和方差膨胀因子。
依据该表可以进行回归系数显著性检验,写出回归方程Y=25.506+0.157X该表还可以检验相关系数的显著性,甲醇浓度的P值为0.005,在显著水平为0.05或0.01下,都应拒绝原假设,认为变量甲醇浓度的偏回归系数与0有显著差异。
SPSS实验多元线性回归分析12

这里我们以总成绩作为因变量Y,平时成绩和期中成绩分别作为自变量X1,X2,建立的多元回归模型为:
Байду номын сангаас2,估计参数,建立回归预测模型
利用SPSS可得一下结果:
Variables Entered/Removedb
Model
Variables Entered
Variables Removed
1183.800
19
a. Predictors: (Constant),期中成绩,平时成绩
b. Dependent Variable:总成绩
注释:从表中可得拟合方程的F统计量值为7.586,相应的P值为0.000说明,拟合方程是显著的。是具有统计意义的。
Coefficientsa
Model
Unstandardized Coefficients
Method
1
期中成绩,平时成绩a
.
Enter
a. All requested variables entered.
b. Dependent Variable:总成绩
注释:根据这个表的结果我们可以初步的知道,经过检验自变量X1,X2是可以加入到准备估计的回归方程中作为变量的。
Model Summaryb
Standardized Coefficients
t
Sig.
95% Confidence Interval for B
Correlations
Collinearity Statistics
B
Std. Error
Beta
Lower Bound
Upper Bound
Zero-order
spss多元回归分析报告案例
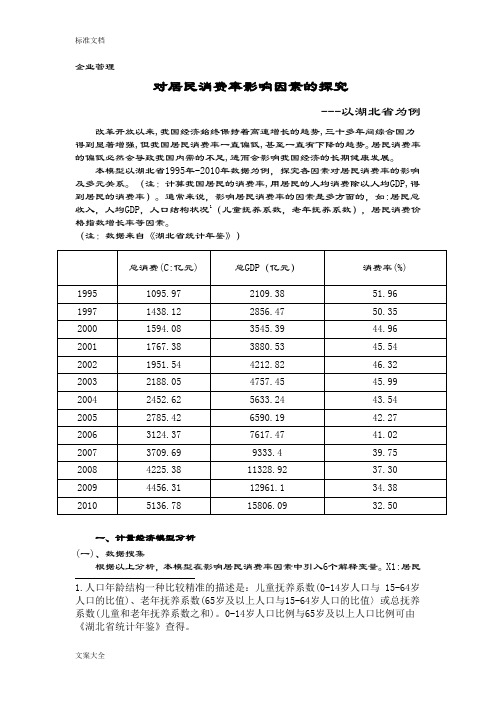
企业管理对居民消费率影响因素的探究---以湖北省为例改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。
居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。
本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。
(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。
通常来说,影响居民消费率的因素是多方面的,如:居民总收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。
(注:数据来自《湖北省统计年鉴》)总消费(C:亿元) 总GDP(亿元)消费率(%)1995 1095.97 2109.38 51.96 1997 1438.12 2856.47 50.35 2000 1594.08 3545.39 44.96 2001 1767.38 3880.53 45.54 2002 1951.54 4212.82 46.32 2003 2188.05 4757.45 45.99 2004 2452.62 5633.24 43.54 2005 2785.42 6590.19 42.27 2006 3124.37 7617.47 41.02 2007 3709.69 9333.4 39.75 2008 4225.38 11328.92 37.30 2009 4456.31 12961.1 34.38 2010 5136.78 15806.09 32.50一、计量经济模型分析(一)、数据搜集根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。
X1:居民1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。
SPSS回归分析实验报告

中国计量学院现代科技学院实验报告实验课程:应用统计学实验名称:回归分析班级:学号:姓名:实验日期: 2012.05.23 实验成绩:指导教师签名:一.实验目的一元线性回归简单地说是涉及一个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。
本实验要求掌握一元线性回归的求解和多元线性回归理论与方法。
二.实验环境中国计量学院现代科技学院机房310三.实验步骤与内容1打开应用统计学实验指导书,新建excel表地区供水管道长度(公里)全年供水总量(万平方米)北京15896 128823 天津6822 64537 河北10771.2 160132 山西5669.3 77525 内蒙古5635.5 59276 辽宁21999 280510 吉林6384.9 159570 黑龙江9065.9 153387 上海22098.8 308309 江苏36632.4 380395 浙江24126.9 235535 安徽7389.4 204128 福建6270.4 118512 江西5094.7 143240 山东26073.9 259782 河南11405.6 185092 湖北15668.6 257787 湖南9341.8 262691 广东35728.8 568949 广西6923.1 134412 海南1726.7 20241 重庆6082.7 71077 四川12251.3 165632 贵州3275.3 45198 云南5208.5 52742 西藏364.9 5363陕西4270 73580甘肃5010 62127青海893 14390宁夏1538.2 22921新疆3670.2 766852.打开SPSS,将数据导入3.打开分析,选择回归分析再选择线性因变量选全年供水总量,自变量选供水管道长度统计里回归系数选估计,再选择模型拟合按继续再按确定会出来分析的结果对以上结果进行分析:(1)回归方程为:y=28484.712+11.610X(X是自变量供水管道长度,Y是因变量全年供水总量)(2)检验1)拟合效果检验根据表2可知,R2=0.819,即拟合效果好,线性成立。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
回归分析作业一、利用软件计算1、数据文件“资产评估1”提供了35家上市公司资产评估增值的数据。
num---公司序号pg---- 资产评估增值率gz----固定资产在总资产中所占比例fz----权益与负债比bc----总资产投资报酬率gm---公司资产规模(亿元)a.建立关于资产评估增值率的四元线性回归方程,并通过统计分析、检验说明所得方程的有效性,解释各回归系数的经济含义。
b.剔除gz变量,建立关于资产评估增值率的三元线性回归方程,与a中的模型相比较,那个更为实用有效,说明理由。
解:由Model Summary和ANOVA表可知,R为0.871,决定系数R2为0.759,校正决定系数为0.727。
拟合的回归模型F值为23.609,P值为0,所以拟合的模型是有统计意义的。
从系数的t检验可以看出,只有固定资产比重的sig值=0.339>0.05,说明只有固定资产比重对资产评估增值率的影响是不显著的,其他自变量对固定资产增值的比率均有显著的影响。
线性回归方程为:pg=0.396+0.079gz+0.063fz+0.602bc-0.044gmα1=0.079表示,在权益与负债比、总资产投资报酬率和公司规模不变的条件下,固定资产比重每增加1个单位,资产评估增值率增加0.079。
α2=0.063表示,在固定资产比重、总资产投资报酬率和公司规模不变的条件下,权益与负债比每增加1个单位,资产评估增值率增加0.063。
α3=0.602表示,在固定资产比重、权益与负债比和公司规模不变的条件下,总资产投资报酬率每增加1个单位,资产评估增值率增加0.602。
α4=-0.044表示,在固定资产比重、权益与负债比和总资产投资报酬率不变的条件下,公司规模每增加1亿元,资产评估增值率减少0.044,校正决定系数为0.727。
从系数的t检验可以看出,该模型的回归系数都通过检验。
所以,剔除 gz 变量,建立关于资产评估增值率的三元线性回归方程为:pg=0.376+0.063fz+0.600bc-0.040gmb更为有效实用,因为所有的回归系数都通过了t检验,并且b模型估计的标准误较小。
2、数据文件“房产销售”提供了20件房地产的销售价格和评估的数据(美元):y----销售价格; x1----地产评估价值; x2----房产评估价值;x3----面积(平方英尺)。
a.建立适当的关于销售价格的多元线性回归模型.b.利用模型预测地产评估价值为2000,房产评估价值为12000,面积为1100的销售价格,并给出预测值的95%的置信区间。
c.通过对模型的统计检验说明预测值的可信度。
解:a.SPSS数据如下由图表所知,地产价值的sig值过高,所以地产价值对销售价格的影响不显著。
把地产价值剔除后,所得的数据如下:由Coefficients表所知,回归方程为:y=105.382+0.961x2+16.348x3b.解:通常先做enter,然后做逐步(1)对原数据进行回归分析,得到回归方程为:y=105.382+0.961x2+16.348x3(2)地产评估价值为2000,房产评估价值为12000,面积为1100的销售价格的95%的置信区间为:(21468.99197,37776.93332)。
(3)该模型的Adjusted R Square=0.867,也就是这两个自变量可以解释86.7%的因变量变差,应该说是预测的可信度比较高;并且残差符合正态性、独立性和方差齐次性,模型成立,即有95%的可能性b的预测值在区间21468.99197-37776.93332内。
3、大多数公司都提供了β估计值,以反映证券的系统风险。
一种股票的β值所测量的是这种股票的回报率与整个市场平均回报率之间的关系。
这个指标的名称就来自简单线性回归中的斜率参数β。
在这种回归中,因变量是股票回报率(Y)。
而自变量则是市场回报率(X)。
值大于1的股票被称为“攻击性”证券,因为它们的回报率变动(向上或向下)得比整个市场的回报率快。
相反,β值小于1的股票被称为“防御性”证券,因为它们的回报率变动的比市场回报率慢。
值接近1的股票被称为“中性”证券,因为它们的回报率反映市场回报率。
下面表中的数据是随机抽选的7个月内某只特定的股票的月回报率及整个市场的回报率。
试对这些数据完成简单线性回归分析。
根据你的分析结果,你认为这只股票是属于攻击性,防御性,还是中解:得到回归方程:y=1.762x-1.329。
β值为线性回归斜率参数1.762>1,所以,该股票属于“攻击性股票”。
4、参考上题。
股票的β值是否依赖于计算回报率的时间长度?因为有些经济商号用的是按月数据计算的β值,另一些经济商号则用按年数据计算的β值,所以这个问题对投资者来说很重要。
H.莱维分别研究了三类股票的时间长度(月)和平均β值。
将时间长度从一个月逐步增加到30个月,莱维计算了1946---1975年间144只股票的回报率。
根据他所得的β值,这144只股票中有38只攻击性股票,38只防御性股票,以及68只中性股票。
下表中给出的这三类股票对不同时间水平的平均β值。
A、对于攻击性股票、防御性股票和中性股票三种情况,分别求表达平均β值Y与时间长度X之间关系的最小二乘简单线性回归方程。
B、对每一类股票检验假设:时间长度是平均β值的有效线性预测器,检验时用α=0.05。
C、对每一类股票,构造直线斜率的95%置信区间,哪只股票的β值随时间长度的增大而线性增大?5个人计算机(PC 机)正以非凡的技术在发展,PC 机的零售价格也是这样。
由于购买时间和机器特点不同,一台PC 机的零售价格可能发生戏剧性的变化。
不久前收集了一批IBM PC 机和IBM PC 兼容机的零售价格数据,共有N=60,见数据文件“计算机价格”。
这些数据被用来拟合多元回归E (Y )=β0+β1 x 1+β2x 2 其中:Y=零售价格(美元)x 1=微处理器速度(兆赫)⎩⎨⎧= 286CPU0 386CPU1芯片芯片Xa 、 试写出最小二乘预测方程。
b 、 此模型是否适合于预测?用α=0.10进行检验。
c 、 构造β1 的90%置信区间,并对此区间作出解释。
d 、 本模型中的CPU 芯片(x 2)是否是价格(Y )的有效预测器?用α=0.10进行预测。
6、在工厂中,准确估计完成一项作业所需的工时数对于诸如决定雇佣工人的数量,确定向客户报价的最后期限,或者作出与预算有关的成本分析决策等决策管理来说是极端重要的。
一名锅炉筒制造商想预测在一些在未来预测项目中装配锅炉筒所需的工时数。
为了用回归方法实现此目标,他收集了35个锅炉的项目数据(数据文件“锅炉”)。
除工时(Y)外,被测量的变量有锅炉工作容量(X1=磅/小时),锅炉设计压力(X2=磅/平方英寸),锅炉的类型(X3=1,如在生产领域装配;X3=0,如在使用领域装配),以及炉筒类型(X4=1,蒸汽炉筒;X4=0,液体炉筒)。
A、试检验假设:锅炉容量(X1)与工时数(Y)之间有正线性关系。
B、试检验假设:锅炉压力(X3)与工时数(Y)之间有正线性关系。
C、构造β1的95%置信区间并对结果做出解释。
D、构造β3的95%置信区间。
7Cushman & Wakefield 股份有限公司,采集了美国市场上办公用房的空闲率和租金率的数据。
对于18个选取的销售地区,这些地区的中心商业区的综合空闲率(%)和平均租金率(美元/平方英尺)的数据(The Wall Journal Almanac1988)见文件“办公用房”。
a.用水平轴表示空闲率,对这些数据画出散点图。
b.这两个变量之间显出什么关系吗?c.求出在办公用房的综合空闲率已知时,能用来预测平均租金率的估计的回归方程。
d.在0.05显著水平下检验关系的显著性。
e.估计的回归方程对数据的拟合好吗?请解释。
f.在一个综合空闲率是25%的中心商业区,预测该市场的期望租金率。
g.在劳德代尔堡的中心商业区,综合空闲率是11.3%,预测劳德代尔堡的期望租金率。
8.PJH&D公司正在决定是否为公司新的文字处理系统签订一项维修合同。
公司的管理人员认为,维修费用与该系统的使用时间有关。
采集的每周时间(小时)和面维修费用(千美元)的统计资料见“文字处理系统”。
a.求出年维修费用对于每周使用时间的估计的回归方程。
b.在0.05显著水平下,检验在(a)中求出关系的显著性。
c.PJH&D公司预期每周使用文字处理系统的时间是30小时,求出该公司的年维修费用的 95%的预测区间。
d.如果维修合同的费用是每年3000美元,你建议签订这个合同吗,为什么?e.g.9.对于一个较大的人口密集的地区,当地交通部门想要确定公共汽车的使用时间和年维修费用之间是否存在某种关系。
由10辆公共汽车组成一个样本,采集的数据见文件“交通”。
a.利用最小二乘法求出估计的回归方程。
b.在 =0.05的显著水平下,通过检验是否看出二变量之间存在一个显著的关系。
c.最小二乘法回归线给出了观测数据一个好的拟合吗?请做出解释。
d.如果有一辆特定的公共汽车已使用了4年,求出这辆车年维修费用的一个95%的预测区间。
10.美国心脏协会经过10年的研究,得到了与发生中风有关的年龄、血压和吸烟的统计资料。
假设这一研究的部分数据为文件“中风风险”。
我们将病人在今后10年内发生中风的概率(乘100)看作为中风风险。
我们用一个虚拟变量来定义病人是否为吸烟者,1表示是吸烟者,0表示不是吸烟者。
a.利用这些数据,建立一个中风风险关于个人的年龄、血压和是否吸烟的估计的回归方程。
b.在中风风险的估计的回归方程中,吸烟是一个显著的影响因素吗?检验的显著水平=0.05。
对于得到的结果,请做出解释。
c.Art Speen 是一位血压为175的68岁的吸烟者,他在今后10年内发生中风的概率是多少?对于这位病人,医生可以提出什么建议?11.公路管理部门进行一项有关交通流量和车速 之间关系的研究 。
假设模型的形式如下:εββ++=x y 10。
式中y 是交通流量(辆/小时);x 是车速(英里/小时)。
采集数据见文件“公路管理”。
a. 对于这些数据建立一个估计的回归方程。
b. 在显著水平为α=0.01时,检验y x 和之间的显著关系。
12.在对上题做进一步分析时 ,统计学家建议利用下面曲线形式的估计的回归方程。
a.利用上题数据去估计这个方程的参数。
b.显著性水平为01.0=α时,检验关系的显著性。
c.在车速为每小时38英里时,预测每小时的交通流量。
解: a.2210xb x b b y ++=∧由上表可知,回归方程为:y=423.571+38.429x-0.383x 2b. 由Model Summary 和ANOVA 表 可知,拟合的回归模型中相关系数R=0.990;Sig=0.003<0.01;并且也通过T 检验,认为因变量和变量之间存在显著性关系。