第10章时间序列数据的基本回归分析
回归分析中的时间序列数据处理技巧(Ⅲ)

回归分析中的时间序列数据处理技巧时间序列数据在回归分析中起着重要的作用,它可以帮助我们预测未来的趋势和变化。
然而,时间序列数据处理并不是一件简单的事情,需要掌握一定的技巧和方法。
本文将介绍在回归分析中处理时间序列数据的一些技巧和方法。
时间序列数据的基本特征在进行时间序列数据处理之前,首先需要了解时间序列数据的基本特征。
时间序列数据是按时间顺序排列的数据序列,它包括趋势、季节性和随机性三个基本特征。
趋势是时间序列数据的长期变化趋势,季节性是周期性的变化趋势,而随机性则是不规律的波动。
对时间序列数据的趋势进行分析在回归分析中,我们通常需要对时间序列数据的趋势进行分析。
趋势分析可以帮助我们了解数据的长期变化趋势,从而进行未来的预测。
常用的趋势分析方法包括移动平均法、指数平滑法和趋势线法。
移动平均法是一种通过计算一定时间段内数据的平均值来消除随机波动,从而找出长期趋势的方法。
指数平滑法则是通过对数据赋予不同的权重来计算未来趋势的方法。
而趋势线法则是通过拟合一条直线或曲线来表示数据的长期变化趋势。
对时间序列数据的季节性进行分析除了趋势分析之外,我们还需要对时间序列数据的季节性进行分析。
季节性分析可以帮助我们找出数据的周期性变化规律,从而进行季节性调整。
常用的季节性分析方法包括周期性分解法、差分法和季节指数法。
周期性分解法是一种通过将数据分解为长期趋势、季节性和随机性三个部分来进行季节性分析的方法。
差分法则是通过对数据进行差分操作来消除季节性变化,从而得到平稳的数据。
而季节指数法则是通过计算季节指数来进行季节性调整的方法。
对时间序列数据的随机性进行分析最后,我们还需要对时间序列数据的随机性进行分析。
随机性分析可以帮助我们了解数据的不规律波动,从而进行随机性调整。
常用的随机性分析方法包括自相关性分析、白噪声检验和残差分析。
自相关性分析是一种通过计算数据的自相关系数来判断数据之间的相关关系的方法。
白噪声检验则是一种通过检验数据的残差序列是否符合白噪声过程来进行随机性分析的方法。
伍德里奇《计量经济学导论》(第5版)笔记和课后习题详解

读书笔记模板
01 思维导图
03 目录分析 05 读书笔记
目录
02 内容摘要 04 作者介绍 06 精彩摘录
思维导图
本书关键字分析思维导图
第版
计量经济 学
时间
习题
序列
经典
变量
笔记
教材
笔记 复习
模型
导论
笔记
第章
习题
分析
数据
回归
内容摘要
本书是伍德里奇《计量经济学导论》(第5版)教材的配套电子书,主要包括以下内容:(1)整理名校笔记, 浓缩内容精华。每章的复习笔记以伍德里奇所著的《计量经济学导论》(第5版)为主,并结合国内外其他计量经 济学经典教材对各章的重难点进行了整理,因此,本书的内容几乎浓缩了经典教材的知识精华。(2)解析课后习 题,提供详尽答案。本书参考国外教材的英文答案和相关资料对每章的课后习题进行了详细的分析和解答。(3) 补充相关要点,强化专业知识。一般来说,国外英文教材的中译本不太符合中国学生的思维习惯,有些语言的表 述不清或条理性不强而给学习带来了不便,因此,对每章复习笔记的一些重要知识点和一些习题的解答,我们在 不违背原书原意的基础上结合其他相关经典教材进行了必要的整理和分析。本书特别适用于参加研究生入学考试 指定考研考博参考书目为伍德里奇所著的《计量经济学导论》的考生,也可供各大院校学习计量经济学的师生参 考。
讨
2.1复习笔记 2.2课后习题详解
3.1复习笔记 3.2课后习题详解
4.1复习笔记 4.2课后习题详解
5.1复习笔记 5.2课后习题详解
6.1复习笔记 6.2课后习题详解
7.1复习笔记 7.2课后习题详解
初计量经济学之时间序列分析

初计量经济学之时间序列分析1. 引言时间序列分析是计量经济学中的一个重要领域,研究的是时间序列数据的性质、模式和预测方法。
时间序列数据是按照时间顺序排列的一系列观测值,包括经济指标、股票价格、气象数据等。
时间序列分析可以帮助我们理解和预测经济现象的发展趋势,为政府和企业决策提供科学依据。
本文将介绍时间序列分析的基本概念、方法和应用。
首先,我们将介绍时间序列分析的基本步骤和基本假设。
然后,我们将介绍时间序列模型的常用类型,包括自回归模型(AR)、滑动平均模型(MA)和自回归滑动平均模型(ARMA)。
最后,我们将介绍时间序列的应用领域,包括经济预测、金融风险管理和气象预测。
2. 时间序列分析的基本步骤时间序列分析的基本步骤包括数据的收集和准备、数据的探索性分析、模型的选择和估计、模型的诊断和预测。
下面将对每个步骤进行详细介绍。
2.1 数据的收集和准备数据的收集和准备是时间序列分析的第一步。
我们需要收集时间序列数据,并进行数据清洗和预处理。
数据清洗包括删除缺失值、处理异常值和去除趋势。
数据预处理包括对数据进行平滑处理、差分和变换。
2.2 数据的探索性分析数据的探索性分析是时间序列分析的第二步。
我们需要对时间序列数据进行可视化和统计分析,以了解数据的基本性质和模式。
可视化方法包括绘制时间序列图、自相关图和偏自相关图。
统计分析方法包括计算统计指标、分析趋势、季节性和周期性。
2.3 模型的选择和估计模型的选择和估计是时间序列分析的第三步。
我们需要选择合适的时间序列模型,并进行参数估计。
常用的时间序列模型包括自回归模型(AR)、滑动平均模型(MA)、自回归滑动平均模型(ARMA)和季节性模型。
2.4 模型的诊断和预测模型的诊断和预测是时间序列分析的最后一步。
我们需要对模型进行诊断,检验模型的拟合程度和残差的平稳性、独立性和正态性。
然后,我们可以使用模型进行未来值的预测。
3. 时间序列模型时间序列模型是描述和预测时间序列数据的数学模型。
回归分析数据

回归分析数据回归分析是一种经济学和统计学中常用的方法,用于研究两个或更多变量之间的关系。
这种分析方法广泛应用于各个领域,包括市场研究、金融分析、经济预测等。
在此文档中,我们将介绍回归分析数据以及如何使用它们进行分析和解释。
回归分析的基本概念是研究一个或多个自变量对某个因变量的影响。
自变量是独立变量,而因变量则是依赖于自变量的变量。
通过分析自变量与因变量之间的关系,我们可以得出它们之间的数学模型,用于预测或解释因变量。
在进行回归分析之前,我们首先需要收集回归分析数据。
这些数据包括自变量和因变量的观测值。
通常,我们会收集一组样本数据,其中包含自变量和对应的因变量的数值。
这些数据可以是经过实验或观测得到的,也可以是从其他来源获取的。
一旦我们收集到回归分析数据,接下来就可以使用统计软件或编程语言进行数据分析。
常见的回归分析方法包括简单线性回归、多元线性回归和非线性回归。
在简单线性回归中,我们将自变量和因变量之间的关系建模为一条直线。
在多元线性回归中,我们可以考虑多个自变量对因变量的影响。
非线性回归则允许我们考虑更复杂的关系模型。
回归分析的结果通常包括回归方程、参数估计和统计显著性检验。
回归方程描述了自变量和因变量之间的数学关系。
参数估计给出了回归方程中的系数估计值,用于解释自变量与因变量之间的关系。
统计显著性检验则用于判断回归方程的有效性和模型的拟合度。
当我们得到回归分析的结果后,我们可以进行解释和预测。
通过解释回归方程中的系数估计值,我们可以了解自变量与因变量之间的关系强度和方向。
通过预测模型,我们可以根据自变量的数值预测因变量的数值。
回归分析数据在许多实际应用中具有重要的价值。
在市场研究中,回归分析数据可以帮助我们理解产品价格与销售量之间的关系。
在金融分析中,回归分析数据可以用于预测股票价格或汇率变动。
在经济预测中,回归分析数据可以用于预测GDP增长率或失业率。
总而言之,回归分析数据是一种强大的工具,用于研究自变量与因变量之间的关系。
时间序列数据差分gmm模型回归

时间序列数据差分GMM模型回归引言时间序列数据是在金融、经济学、气象学等领域中广泛应用的一种数据类型。
时间序列的特点是包含了时间顺序的信息,因此在分析和预测时常常需要考虑时间的影响。
时间序列数据的分析方法有很多种,其中一种常用的方法是差分GMM模型回归。
本文将深入探讨时间序列数据差分GMM模型回归的原理、应用和优势。
什么是时间序列数据差分GMM模型回归?时间序列数据差分GMM模型回归是一种利用差分和广义矩估计方法来建立模型并进行回归分析的方法。
差分是将时间序列数据转化为平稳序列的一种常用方法,平稳序列的特点是均值和方差不随时间变化。
广义矩估计方法(GMM)是一种通过选择适当的权重矩阵来估计参数的方法,可以解决估计过程中的异方差和内生性问题。
差分GMM模型回归可以用于分析和预测时间序列数据的关联性以及变量之间的影响关系。
它可以应用于金融数据中的股票价格预测、经济数据中的经济增长预测等问题。
通过对差分后的时间序列数据进行拟合和回归分析,可以得到关于时间序列数据的有用信息,从而做出准确的预测和决策。
差分GMM模型回归的原理1.差分:差分是将非平稳时间序列数据转化为平稳序列的一种方法。
差分的步骤是将当前观测值减去前一观测值,得到的差分序列具有无趋势和平稳性质。
差分的数学表达式如下:Δx t=x t−x t−1其中,Δx t表示第t时刻的差分值,x t表示第t时刻的原始观测值,x t−1表示第t−1时刻的原始观测值。
2.广义矩估计方法(GMM):广义矩估计方法是一种利用样本矩和理论矩之间的差异来估计参数的方法。
在GMM中,通过选择适当的权重矩阵来优化估计的效果,可以解决估计过程中的异方差和内生性问题。
GMM的数学表达式如下:θ̂GMM=argming(θ)′Wg(θ)θ其中,θ̂GMM表示通过GMM方法得到的参数估计值,θ表示待估计的参数向量,g(θ)表示由样本矩和理论矩之间差异构成的矩方程,W表示选择的权重矩阵。
第章时间序列预测习题答案
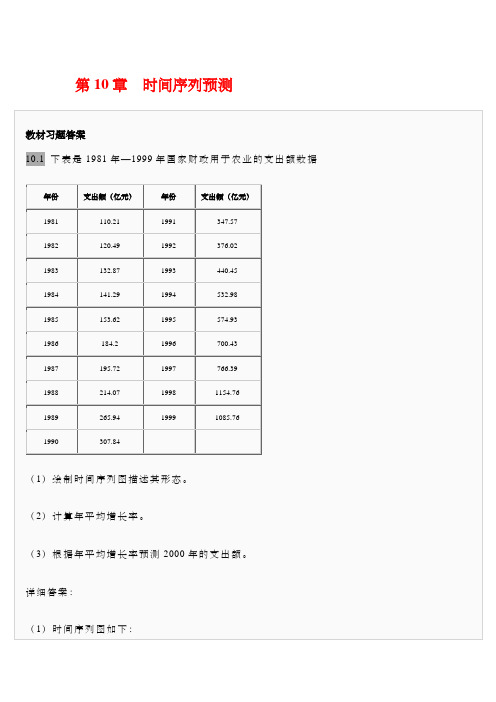
第10章时间序列预测从时间序列图可以看出,国家财政用于农业的支出额大体上呈指数上升趋势。
(2)年平均增长率为:。
(3)。
10.2 下表是1981年—2000年我国油彩油菜籽单位面积产量数据(单位:kg / hm2)年份单位面积产量年份单位面积产量1981 1451 1991 12151982 1372 1992 12811983 1168 1993 13091984 1232 1994 12961985 1245 1995 14161986 1200 1996 13671987 1260 1997 14791988 1020 1998 12721989 1095 1999 14691990 1260 2000 1519(1)绘制时间序列图描述其形态。
(2)用5期移动平均法预测2001年的单位面积产量。
(3)采用指数平滑法,分别用平滑系数a=0.3和a=0.5预测2001年的单位面积产量,分析预测误差,说明用哪一个平滑系数预测更合适?详细答案:(1)时间序列图如下:(2)2001年的预测值为:|(3)由Excel输出的指数平滑预测值如下表:2001年a=0.3时的预测值为:a=0.5时的预测值为:比较误差平方可知,a=0.5更合适。
10.3 下面是一家旅馆过去18个月的营业额数据月份营业额(万元)月份营业额(万元)1 295 10 4732 283 11 4703 322 12 4814 355 13 4495 286 14 5446 379 15 6017 381 16 5878 431 17 6449 424 18 660(1)用3期移动平均法预测第19个月的营业额。
(2)采用指数平滑法,分别用平滑系数a=0.3、a=0.4和a=0.5预测各月的营业额,分析预测误差,说明用哪一个平滑系数预测更合适?(3)建立一个趋势方程预测各月的营业额,计算出估计标准误差。
详细答案:(1)第19个月的3期移动平均预测值为:(2)月份营业额预测a=0.3误差平方预测a=0.4误差平方预测a=0.5误差平方1 2952 283 295.0 144.0 295.0 144.0 295.0 144.03 322 291.4 936.4 290.2 1011.2 289.0 1089.04 355 300.6 2961.5 302.9 2712.3 305.5 2450.35 286 316.9 955.2 323.8 1425.2 330.3 1958.16 379 307.6 5093.1 308.7 4949.0 308.1 5023.37 381 329.0 2699.4 336.8 1954.5 343.6 1401.68 431 344.6 7459.6 354.5 5856.2 362.3 4722.39 424 370.5 2857.8 385.1 1514.4 396.6 748.510 473 386.6 7468.6 400.7 5234.4 410.3 3928.711 470 412.5 3305.6 429.6 1632.9 441.7 803.112 481 429.8 2626.2 445.8 1242.3 455.8 633.513 449 445.1 15.0 459.9 117.8 468.4 376.914 544 446.3 9547.4 455.5 7830.2 458.7 7274.815 601 475.6 15724.5 490.9 12120.5 501.4 9929.416 587 513.2 5443.2 534.9 2709.8 551.2 1283.317 644 535.4 11803.7 555.8 7785.2 569.1 5611.718 660 567.9 8473.4 591.1 4752.7 606.5 2857.5合计——87514.7—62992.5—50236由Excel输出的指数平滑预测值如下表:a=0.3时的预测值:,误差均方=87514.7。
stata时间序列回归步骤命令
stata时间序列回归步骤命令1.引言1.1 概述概述部分的内容:时间序列回归是一种经济学和统计学领域中常用的分析方法,用于研究随时间变化的因果关系。
它涉及使用时间上的观测数据来分析自变量和因变量之间的关系,并预测未来的值。
Stata是一种功能强大的统计软件,广泛用于数据分析和经济研究。
在Stata中,有一系列的命令可供使用,用于进行时间序列回归分析。
本文将介绍使用Stata进行时间序列回归分析的步骤和相应的命令。
通过学习这些命令,读者将能够熟练地使用Stata进行时间序列回归分析,并获得准确和可靠的结果。
本文主要包括以下章节内容:1. 引言部分介绍了时间序列回归的概述、文章结构和目的,旨在帮助读者全面了解本文内容。
2. 正文部分将详细介绍时间序列回归的概念和原理,并介绍Stata中的时间序列回归命令。
这些命令包括数据准备、建立模型、模型估计和统计推断等步骤。
3. 结论部分对本文进行总结,并展望时间序列回归在未来的应用前景。
同时,还会指出时间序列回归分析中可能存在的局限性,以及可能的改进方向。
通过本文的学习,读者将了解时间序列回归分析的基本概念和步骤,掌握对时间序列数据进行回归分析的方法和技巧,并能够运用Stata软件进行实际的分析工作。
1.2文章结构文章结构(Article Structure)本文将按照以下结构进行叙述。
第一部分为引言部分,目的是对时间序列回归步骤命令进行一个概述,并说明本文的目的。
接下来,第二部分将详细介绍时间序列回归的概念和一般步骤,并使用stata命令进行说明。
同时,本文还将重点介绍两个关键要点,这些要点对于正确进行时间序列回归分析非常重要。
最后,第三部分为结论,将总结本文的主要内容,并展望一下未来可能的研究方向。
在正文部分,我们将首先概述时间序列回归的基本概念,并提供了一个对该方法的整体认识。
然后,我们将详细介绍stata时间序列回归步骤命令的使用方法,包括数据导入、变量设定、模型拟合和结果解释等。
研究生统计学教案:回归分析和时间序列分析
研究生统计学教案:回归分析和时间序列分析1. 引言•统计学在现代社会中扮演着极为重要的角色,它可以帮助我们揭示数据背后的规律和趋势。
•在研究生阶段,统计学是一门必修课程,帮助学生理解统计方法的原理和应用。
2. 回归分析2.1 理论背景•回归分析是一种研究自变量与因变量之间关系的方法。
•通过建立一个数学模型来描述自变量对因变量的影响。
•最常见的回归模型是线性回归模型。
2.2 基本步骤1.数据收集:获取用于回归分析的数据集。
2.变量选择:确定自变量和因变量。
3.模型拟合:使用适当的统计软件进行回归模型拟合。
4.解释与评估:解释拟合结果并评估模型拟合程度。
2.3 应用领域1.经济学:通过回归分析来探讨经济指标之间的关系。
2.社会科学:研究人类行为和社会现象之间的相互作用。
3.医学研究:寻找风险因素或预测疾病发生概率。
4.市场营销:分析市场需求和消费者行为。
3. 时间序列分析3.1 理论背景•时间序列分析是一种统计方法,用于研究随时间变化的数据。
•它可以揭示数据的趋势、周期性和季节性。
3.2 基本步骤1.数据收集:获取包含时间变化信息的数据集。
2.数据预处理:对数据进行平滑处理,去除趋势和季节性成分。
3.模型拟合:基于历史数据建立合适的时间序列模型。
4.预测与评估:使用已有模型对未来数据进行预测,并评估模型拟合程度。
3.3 应用领域1.经济学:预测经济指标如GDP、通货膨胀率等。
2.气象学:预测天气变化和气候演变。
3.财务管理:分析股市走向和金融市场波动性。
4.销售预测:帮助企业确定销售计划和库存管理。
4. 总结•回归分析和时间序列分析是研究生统计学课程中的重要内容。
•回归分析用于研究自变量对因变量的影响关系,并解释其变异性。
•时间序列分析适用于研究随时间变化的数据,预测未来趋势和波动性。
•这两种方法在各个学科领域具有广泛的应用,帮助我们理解数据并做出合理决策。
伍德里奇《计量经济学导论》(第5版)笔记和课后习题详解-第10章 时间序列数据的基本回归分析【圣才出
第10章时间序列数据的基本回归分析10.1复习笔记一、时间序列数据的性质时间序列数据与横截面数据的区别:(1)时间序列数据集是按照时间顺序排列。
(2)时间序列数据与横截面数据被视为随机结果的原因不同。
①横截面数据应该被视为随机结果,因为从总体中抽取不同的样本,通常会得到自变量和因变量的不同取值。
因此,通过不同的随机样本计算出来的OLS估计值通常也有所不同,这就是OLS统计量是随机变量的原因。
②经济时间序列满足作为随机变量是因为其结果无法事先预知,因此可以被视为随机变量。
一个标有时间脚标的随机变量序列被称为一个随机过程或时间序列过程。
搜集到一个时间序列数据集时,便得到该随机过程的一个可能结果或实现。
因为不能让时间倒转重新开始这个过程,所以只能看到一个实现。
如果特定历史条件有所不同,通常会得到这个随机过程的另一种不同的实现,这正是时间序列数据被看成随机变量之结果的原因。
(3)一个时间序列过程的所有可能的实现集,便相当于横截面分析中的总体。
时间序列数据集的样本容量就是所观察变量的时期数。
二、时间序列回归模型的例子1.静态模型假使有两个变量的时间序列数据,并对y t和z t标注相同的时期。
把y和z联系起来的一个静态模型(staticmodel)为:10 1 2 t t t y z u t nββ=++=⋯,,,,“静态模型”的名称来源于正在模型化y 和z 同期关系的事实。
若认为z 在时间t 的一个变化对y 有影响,即1t t y z β∆=∆,那么可以将y 和z 设定为一个静态模型。
一个静态模型的例子是静态菲利普斯曲线。
在一个静态回归模型中也可以有几个解释变量。
2.有限分布滞后模型(1)有限分布滞后模型有限分布滞后模型(finitedistributedlagmodel,FDL)是指一个或多个变量对y 的影响有一定时滞的模型。
考察如下模型:001122t t t t ty z z z u αδδδ--=++++它是一个二阶FDL。
第十章时间序列数据的基本回归分析-2
基期的变化;
价格指数:可用于计算通胀率,和将名义值换算为实际 值
大多数经济行为受真实变量而非名义变量的影响 工作时间与小时工资
Hale Waihona Puke log(hours)= 0+ 1log(w/p)+u log(hours)= 0+ 1log(w)+ 2log(p)+u
对华反倾销: 交互影响
R2 1 SSR SST
R21SSSS/R(n/T( nk1)1)
y的方差y2不等于SST/(n-1)
更合理的拟合优度度量:
R2 1
SSR
n t1
yt2
R2
1
SSR/(nk1) tn1yt2 (n2)
Var(yt)=Var(et)= e2
指数趋势
log(yt)=0+1t+et 参数1的经济含义:
1=log(yt) (yt-yt-1)/yt-1
回归分析中的趋势变量
若因变量y和自变量x1和x2含有线性趋势,引入趋势变 量:
yt=0+1x1t+2x2t+3t+ut
估计模型:
yˆt ˆ1x1t +ˆ2x2t
这与包含线性趋势的回归模型是等同的:
yt=0+1x1t+2x2t+3t+ut
包含线性趋势时的可决系数R2
yt=0+1x1t+2x2t+3t+ut
总体可决系数:
R2=1-(u2/y2)
样本可决系数和调整可决系数:
可以将线性趋势t理解为除x1和x2外,导致y中线性趋势 的其他不可观测因素。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 1、静态模型 • 我们将有两个变量(例如y和z)的时间序列数据标注
相同的时期,将这样的y和z联系起来即为一个静态模 型(static model):
y t01 zt u t,t 1 ,2 , ,n
• “静态模型”的名称来源于我们正在模型化y和z的同 期关系的事实。
• 在一个静态回归模型中也可以有几个解释变量。 2、有限分布滞后模型 在有限分布滞后模型(finite distributed lag model,
FDL)中,我们容许一个或多个变量对y的影响有一定 时滞。
假定 TS.1(线性于参数)
假定 TS.2(无完全共线性):在样本中,没有任何自变量是恒 定不变的,或者是其他自变量的一个完全线性组合。
假定 TS.3(零条件均值): E(ut X)0,t1,2,,n
假定 TS.4(同方差性): V(u a tX )r V(u a t) r2 ,t 1 ,2 , ,n 该假定意味着,Var(ut X不) 能依赖于X(只要 u和t X相互独立就足够
例10.2 通货膨胀和赤字对利率的影响 1948-2019年数据。
i3:三月期国债利率; inf:据消费者价格指数得出的年通货膨胀率 def:联邦赤字占GDP 的百分比 文件:INTDEF.RAW 命令:reg i3 inf def 结果:
Inf与def对于i3的影响在统计上十分显著,即通货膨 胀上升或赤字相对规模的扩大都会提高短期利率。 (但前提是CLM假定成立)
10.4 函数形式、虚拟变量和指数
在应用研究中经常出现具有恒定百分比效应的时间序 列回归(自然对数形式)
将对数函数形式用于分布滞后模型:
方程中的冲击倾向 0 也被称为短期弹性(short-run
elasticity):它度量了GDP增长1%时货币供给的即期 百分比变化;
长期倾向01有4时也被称为长期弹性(long-
• 考察一个二阶FDL: y t0 0 z t 1 z t 1 2 z t 2 u t
(1)当z发生一个暂时性的提高时, 0则表示z在t时期提高一
个单位所引起y的即期变化。
0通常被称作冲击倾向(impact propensity)或冲击乘数
(impact multiplier)。
(注意:1,2,,分j别表示这一暂时变化发生后,下一时期、
假定 TS.6(正态性):误差
u
独立于X,且具有独立同分布
t
Norm(0a,l 2)
定理 10.1(OLS的无偏性)
在假定TS.1、TS.2和TS.3下,以X为条件,OLS估计 量是无偏的,并因此下式也无条件地成立:
E(ˆj)j,j0,1,k
定理10.2(OLS的样本方差)
在时间序列高斯-马尔可夫假定TS.1-TS.5下,以X为 条件, 的条ˆ j 件方差为:
V(ˆ a jX ) r2[ Sj( S 1 R 2 T j),j ] 1 , ,k
其中, SST是j 的x tj 总平方和, 为R 2j 由 对x j所有其他 自变量回归得到的 R 2
定理10.3( 2的无偏估计)
在假定TS.1-TS.5下,估计量 ˆ2 S是SR/d的f 一 个2 无 偏估计量,其中df=n-k-1
run elasticity):它度量了GDP持久地增长1%,4个月 后货币供给的百分比变化。
二值或虚拟自变量在时间序列应用中也相当有用。 既然观测单位是时间,所以虚拟变量代表某特定事件 在每个时期是否发生。
例10.1 静态菲利普斯曲线 研究失业和通货膨胀之间是否存在替代关系。
H0: 1 0 H1: 1 0 文件:PHILLIPS.RAW 命令:reg inf unem 结果:
上述方程并没有表明unem和inf之间存在替代关系 (因为 ˆ1 0) 分析中可能存在的问题: (1)CLM假定不成立(12章);(2)静态菲利普斯曲 线不是最佳模型(附加预期的菲利普斯曲线)
一个q阶有限分布滞后模型可写成:
y t0 0 z t 1 z t 1 q z t q u t
静态模型是上式的一种特例,当1,2,,都q为0即可。
冲击倾向总是同期z的系数 。
长期倾向便是所有变量 的0 系数之和。
zt j
LR P 01q
10.3 经典假设下OLS的有限样本性质
第十章 时间序列数据的基本回归分析
10.1 时间序列数据的性质
• 我们应该怎样认识时间序列数据的随机性?
• 回答:很明显,经济时间序列满足作为随机变量结果 所要求的直观条件,这些变量的结果都无法事先预料 到。(例如,我们今天不知道道琼斯工业指数在下一 个交易日收盘时会是多少,我们也不知道加拿大下一 年的年产出增长会是多少。)
了—满足TS.3即可),且在所有时期都保持不变。
假定 TS.5(无序列相关): Co (utr ,usrX)0, ts
【提问:我们为什么不假定不同横截面观测的误差是无关的呢? 答:前述有随机抽样的假定,则以样本中所有解释变量为条件, 不同观测的误差是独立的。因此,就我们当前目的而言,序列 相关只是时间序列和回归中的一个潜在问题。】
定理10.4(高斯-马尔可夫定理)
在假定TS.1-TS.5下,以X为条件,OLS估计量是最 优线性无偏估计量。
定理10.5(正态抽样分布)
在时间序列的CLM假定TS.1-TS.6下,以X为条件, OLS估计量遵循正态分布。而且,在虚拟假设下,每 个t统计量服从t分布,F统计量服从F分布,通常构造 的置信区间也是确当的。
两个时期、…j个时期后y的变化—如图10.1)
(2)当z从t期开始永久性提高,一期后y提高了 0 ,1 两期
后y提高了 01。2 这表明,z的当期和滞后系数之和 01,2 等于z的永久
性提高导致y的长期变化,它被称为长期倾向(long-run propensity, LRP)或长期乘数(long-run multiplier)。