管理统计学综合实验
管理统计实验报告心得(3篇)

第1篇一、实验背景随着我国经济的快速发展,企业面临着激烈的市场竞争。
为了提高企业的管理水平和决策能力,统计学在企业管理中的应用越来越广泛。
为了使同学们更好地掌握管理统计的基本理论和方法,我们开展了管理统计实验课程。
通过本次实验,我对管理统计有了更深入的了解,以下是我对本次实验的心得体会。
二、实验目的1. 掌握管理统计的基本理论和方法;2. 熟悉SPSS等统计软件的使用;3. 培养同学们分析问题和解决问题的能力;4. 提高同学们的数据处理和分析能力。
三、实验内容本次实验主要分为以下几个部分:1. 数据收集与整理:通过查阅相关资料,收集实验所需的数据,并对数据进行整理和清洗。
2. 描述性统计:运用SPSS软件对数据进行分析,包括计算均值、标准差、方差等指标,并绘制直方图、频率分布图等。
3. 推断性统计:运用假设检验、相关分析、回归分析等方法对数据进行推断和分析。
4. 统计图表制作:运用SPSS软件制作各种统计图表,如柱状图、折线图、散点图等,以直观地展示数据分析结果。
5. 实验报告撰写:根据实验内容,撰写实验报告,对实验过程、结果和结论进行总结。
四、实验心得1. 理论与实践相结合:通过本次实验,我深刻体会到理论知识和实践操作的重要性。
在实验过程中,我不仅巩固了管理统计的基本理论,还学会了如何运用SPSS 等统计软件进行数据分析。
2. 数据处理与分析能力提升:在实验过程中,我学会了如何对数据进行收集、整理、清洗和分析。
这对我今后的学习和工作具有很大的帮助。
3. 团队合作意识增强:本次实验要求我们分组进行,每个小组负责不同的实验内容。
在实验过程中,我们相互协作,共同解决问题,提高了团队协作能力。
4. 分析问题与解决问题的能力提高:在实验过程中,我们遇到了很多问题,如数据缺失、异常值处理等。
通过查阅资料、讨论和请教老师,我们成功地解决了这些问题,提高了分析问题和解决问题的能力。
5. 对管理统计的深入理解:通过本次实验,我对管理统计有了更深入的理解。
管理里统计学SPSS软件基本窗口熟悉 实验报告

SPSS软件基本窗口熟悉
一、实验目的与要求
1.了解SPSS软件的基本构成。
2.熟悉SPSS软件的启动与退出。
3.掌握常用窗口的操作。
二、实验内容提要
1. SPSS基本操作界面的熟悉
2. SPSS基础设置的操作
三、实验步骤
1、首先打开windows系统, 在“开始”菜单中找到IBM SPSS Statistics组, 选择其中
的启动项IBM SPSS Statistics 20, 就会启动IBM SPSS Statistics 20, 这时你就很清楚地看到spss的基本操作界面, 同时可以根据需求对各个窗口进行操作。
若退出该软件, 则选择“文件”→“退出”菜单项, 或直接关闭窗口, 即可退出Spss。
2、Spss是多窗口软件, 用时最多四种, 下面只做简要说明。
3、数据窗口
首先找到菜单栏, 点击分析→描述统计→频率, 在里面选着合适的一项点击, 最后确定即可。
2、输出窗口
点击主窗口上方的“分析—→频率“, 可以在结果窗口中看到想要分析的数据的结果
结果如下图: 4、语法窗口
5、脚本窗口
四、实验结果与结论
通过spss基本操作界面的熟悉和基础设置的操作, 目前我已熟悉了本软件的基本操作界面和基础设置的操作, 发现SPss这个软件有一定的优势和劣势。
这为我以后的学习打下了一定的基础。
在上述的4类窗口都可以同时打开多个数据文件, 或多个结果文件, 也就
是说实际工作中使用的窗口数可以远远多于4个。
而此时spss系统对数据窗口、输出窗口都是使用工作名称来进行定位的。
《管理统计学》-实验教学大纲

《管理统计学》课程实验教学大纲一、课程基本信息课程代码:16225004课程名称:管理统计学英文名称: Statistics for Management实验总学时:24适用专业:信管专业课程类别:学科基础课先修课程:线性代数,微积分,概率论与数理统计二、实验教学的总体目的和要求1、对学生的要求:了解统计学、数据分析技术对世界、企业的作用及全球化过程中我国快速发展的伟大成就;让学生掌握课程中的基本原理和理论方法;能将实验过程、求解方法及在实验过程中的收获和发现的问题正确地表达出来,并以实验报告的形式总结出来。
2、对教师的要求:授课教师实验前在课堂上简单讲解实验流程,实验中解答学生的疑问。
3、对实验条件的要求:SPSS,Office软件以及网络开发环境。
实验教学内容实验项目一实验名称:界面介绍和基础操作介绍实验内容:1.了解SPSS软件界面:菜单栏;工具栏;数据窗口;数据视图与变量视图切换.2.SPSS数据结构1)变量名是变量存取的唯一标志。
起名规则:不多于8个字符组成;不区分大小写;允许汉字作为变量名;默认变量名为VARn,如:var00001。
2)变量的类型(type)和显示宽度(width)3)变量名标签(Variable label) :对变量名的一些解释说明,增强分析结果的可视性。
可以省略。
4)变量名标签(Variable label) :对变量名的一些解释说明,增强分析结果的可视性。
可以省略。
5)变量列格式(Column Format):对齐方式(Text Alignment):左对齐(Left):字符型默认,右对齐(Right):数值型默认居中对齐(Center);列宽度:默认值为变量的总长度。
6)缺失值(Missing Values):对缺失值的一般处理包括事先指定和其他处理方法。
3.变量度量(Measurement):scale: 定距数据,一般为数值型数据。
如:收入、人数。
ordinal:有固有顺序的顺序水准的数值型或字符型数据。
统计学四篇实验报告

《统计学》四篇实验报告实验一:用Excel构建指数分布、绘制指数分布图图1-2:指数分布在日常生活中极为常见,一般的电子产品寿命均服从指数分布。
在一些可靠性研究中指数分布显得尤为重要。
所以我们应该学会利用计算机分析指数分布、掌握EXPONDIST函数的应用技巧。
指数函数还有一个重要特征是无记忆性。
在此次实验中我们还学会了产生“填充数组原理”。
这对我们今后的工作学习中快捷地生成一组有规律的数组有很大的帮助。
实验二:用Excel计算置信区间一、实验目的及要求1、掌握总体均值的区间估计2、学习CONFIDENCE函数的应用技巧二、实验设备(环境)及要求1、实验软件:Excel 20072、实验数据:自选某市卫生监督部门对当地企业进行检查,随机抽取当地100家企业,平均得分95,已知当地卫生情况的标准差是30,置信水平0.5,试求当地企业得分的置信区间及置信上下限。
三、实验内容与步骤某市卫生监督部门对当地企业进行检查,随机抽取当地100家企业,平均得分95,已知当地卫生情况的标准差是30,置信水平0.5,试求当地企业得分的置信区间及置信上下限。
第1步:打开Excel2007新建一张新的Excel表;第2步:分别在A1、A2、A3、A4、A6、A7、A8输入“样本均值”“总体标准差”“样本容量”“显著性水平”“置信区间”“置信上限”“置信下限”;在B1、B2、B3、B4输入“90”“30”“100”“0.5”第3步:在B6单元格中输入“=CONFIDENCE(B4,B2,B3)”,然后按Enter键;第4步:在B7单元格中输入“=B1+B6”,然后按Enter键;第5步:同样在B8单元格中输入“=B1-B6”,然后按Enter键;计算结果如图2-1四、实验结果或数据处理图2-1:实验二:用Excel产生随机数见图3-1实验二:正态分布第1步:同均匀分布的第1步;第2步:在弹出“随机数发生器”对话框,首先在“分布”下拉列表框中选择“正态”选项,并设置“变量个数”数值为1,设置“随机数个数”数值为20,在“参数”选区中平均值、标准差分别设置数值为30和20,在“输出选项”选区中单击“输出区域”单选按钮,并设置为D2 单元格,单击“确定”按钮完成设置。
管理学综合类实验报告

管理学综合类实验报告实验目的:本实验旨在通过对管理学综合类知识的学习和实践,加深对相关理论的理解并提高实际问题解决的能力。
实验过程:1. 阅读相关管理学综合类教材和参考书籍,了解管理学的基本理论框架和相关概念。
2. 在实践中选择一个具体的管理问题,例如组织内部沟通不畅或决策效率低下等。
3. 分析问题背景和原因,结合管理学理论和模型,制定解决问题的方案。
4. 将解决问题的方案运用到实际情境中,观察并记录实施效果。
5. 结合实际情况,对方案的有效性和可行性进行评估,总结经验教训。
实验结果与讨论:在实践中我们选择了一个组织内部沟通不畅的问题作为例子进行分析和解决。
通过运用有效的沟通模型和理论,我们制定了一系列改善沟通的方案,包括改善团队内外部沟通渠道、优化沟通流程以及提升员工沟通能力等。
在实施改善沟通方案的过程中,我们注意到团队成员之间的沟通效果明显增强,信息传递更为顺畅,决策过程也更加迅速高效。
员工的工作满意度也得到了提升,整体组织氛围也更加和谐。
然而,我们也发现了一些问题和不足之处。
例如,有些员工对新的沟通方式和流程不够认同和适应,需要进一步的培训和引导。
此外,中层管理者对信息沟通的重要性认识不够,需要加强其沟通能力和意识。
实验结论:通过本次实验,我们深刻认识到了管理学综合类知识的重要性和实际应用的必要性。
管理学理论和模型可以帮助我们解决组织管理中的一系列问题,并提高团队的绩效。
然而,仅仅知道理论是不够的,只有将其运用到实际中并不断调整和优化,才能取得良好的效果。
同时,我们也认识到管理学的知识是不断更新和变革的,我们需要不断学习和跟进最新的研究成果和实践经验。
综上所述,管理学综合类实验为我们提供了一个锻炼和应用管理知识的机会,同时也提醒我们管理是一个持续学习和改进的过程。
只有不断改进和创新,才能应对日益复杂和多变的管理挑战。
管理统计学实验报告

管理统计学实验报告《管理统计学实验报告》在现代管理中,统计学是一项非常重要的工具,它可以帮助管理者更好地理解和分析数据,从而做出更明智的决策。
在本次实验中,我们将探讨如何运用统计学的方法来分析管理数据,并得出有效的结论。
首先,我们收集了一份关于员工工作满意度的调查数据。
通过对这些数据进行整理和分析,我们发现了一些有趣的现象。
例如,我们发现工作满意度与工作年限之间存在一定的相关性,工作年限越长的员工,工作满意度也越高。
这一发现对于管理者来说是非常有价值的,因为他们可以根据员工的工作年限来制定相应的激励政策,从而提高员工的工作满意度。
其次,我们利用统计学的方法对员工绩效评价数据进行了分析。
通过对这些数据进行回归分析,我们发现了绩效评价与培训时长之间存在一定的正相关关系。
这意味着员工接受的培训越多,其绩效评价也越高。
这一发现为管理者提供了一个重要的参考,他们可以通过加强员工培训来提高整体绩效水平。
最后,我们还对员工离职率数据进行了统计分析。
通过对这些数据进行比较,我们发现了一些离职率高的部门和岗位。
这为管理者提供了一个重要的参考,他们可以通过调整人员配置和改善工作环境来降低离职率。
综上所述,通过本次实验,我们深入了解了如何运用统计学的方法来分析管理数据,并得出有效的结论。
这些结论对于管理者来说是非常有价值的,他们可以根据这些结论来制定相应的管理策略,从而提高组织的整体绩效水平。
希望我们的实验报告能对管理者们有所启发,帮助他们更好地运用统计学的方法来管理和优化组织。
管理统计学SPSS数据管理 实验报告(精编文档).doc
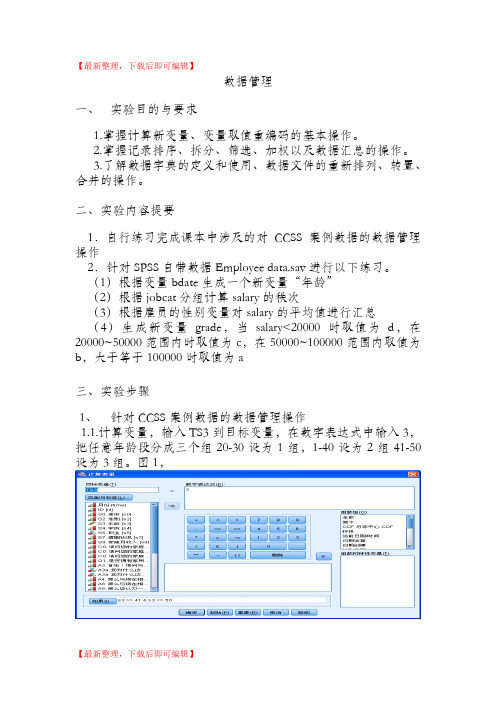
【最新整理,下载后即可编辑】数据管理一、实验目的与要求1.掌握计算新变量、变量取值重编码的基本操作。
2.掌握记录排序、拆分、筛选、加权以及数据汇总的操作。
3.了解数据字典的定义和使用、数据文件的重新排列、转置、合并的操作。
二、实验内容提要1.自行练习完成课本中涉及的对CCSS案例数据的数据管理操作2.针对SPSS自带数据Employee data.sav进行以下练习。
(1)根据变量bdate生成一个新变量“年龄”(2)根据jobcat分组计算salary的秩次(3)根据雇员的性别变量对salary的平均值进行汇总(4)生成新变量grade,当salary<20000时取值为d,在20000~50000范围内时取值为c,在50000~100000范围内取值为b,大于等于100000时取值为a三、实验步骤1、针对CCSS案例数据的数据管理操作1.1.计算变量,输入TS3到目标变量,在数字表达式中输入3,把任意年龄段分成三个组20-30设为1组,1-40设为2组41-50设为3组。
图1,图11.2.对已有变量的分组合并,在“名称”文本框中输入新变量名TS3单击“更改”按钮,原来的S3->?就会变为S3->TS3,单击“旧值和新值”按钮,系统打开“重新编码到其他变量:旧值和新值”,如下图2,图2图31.3.可视离散化,选择“转换”->“可视离散化”,打开的对话框要求用户选择希望进行离散化的变量,单击继续,如下图4,图4单击“生成分割点”,设定分割点数量为10,宽度为5,第一个分割点位置为18,单击“应用”,如下图,图5结果显示如下,图62.针对SPSS自带数据Employee data.sav进行以下练习。
2.1.根据变量bdate生成一个新变量“年龄”,选择“转换”->”计算变量”,如下图,图7结果显示如下,图82.2.根据jobcat分组计算salary的秩次,图9结果显示如下,图102.3.根据雇员的性别变量对salary的平均值进行汇总图11结果显示如下,图122.4.生成新变量grade,当salary<20000时取值为d,在20000~50000范围内时取值为c,在50000~100000范围内取值为b,大于等于100000时取值为a图13结果显示如下,图14 四、实验结果与结论。
统计学专业综合实验智慧树知到课后章节答案2023年下安徽财经大学

统计学专业综合实验智慧树知到课后章节答案2023年下安徽财经大学安徽财经大学第一章测试1.以下选项不能展现数据集中趋势的是()。
A:平均数B:众数C:上四分位数D:变异系数答案:变异系数2.请计算数列“1、5、3、8、4、7、2、1”的中位数()。
A:3.5B:4C:3D:2答案:3.53.某厂商希望了解区域内消费者对饮料品牌的需求数据,其最希望得到的是以下的哪种数据类型()。
A:均值B:众数C:四分位数D:中位数答案:众数4.如果一组变量值中有一项为0,则不能计算()。
A:众数B:算术平均数C:中位数D:调和平均数答案:调和平均数5.一组数据呈微偏分布,且知其均值为510,中位数为516,则可推算众数为()A:526B:528C:513D:512答案:5286.下列哪项不是统计表的必要的构成元素()A:横行B:表头C:纵栏D:表注答案:表注7.考察某个变量随时间的变化情况时,我们常规会作()A:散点图B:直方图C:箱线图D:折线图答案:折线图8.下述能展现数据离散趋势的有()A:变异系数B:极差C:标准差D:四分位距E:众数答案:变异系数;极差;标准差;四分位距9.下述哪种统计图通常能展现两个变量之间的关系()A:折线图B:散点图C:饼图D:箱线图E:条形图答案:折线图;散点图;条形图10.极差是最简单的变异指标,不易受极端值影响。
()A:对 B:错答案:错11.R里用rbind合并两个数据框时,要求两个数据框行数相同。
()A:对 B:错答案:错第二章测试1.( )表示由解释变量所解释的部分,表示x对y的线性影响。
A:残差平方和B:剩余平方和C:总离差平方和D:回归平方和答案:回归平方和2.用一组有40个观测值的样本估计模型后,在0.05的显著性水平上对的显著性作t检验,则显著地不等于零的条件是其统计量t大于等于( )。
A:B:C:D:答案:3.判定系数指的是()A:残差平方和占总离差平方和的比重B:总离差平方和占回归平方和的比重C:回归平方和占总离差平方和的比重D:回归平方和占残差平方和的比重答案:回归平方和占总离差平方和的比重4.在回归分析中,用来检验模型拟合优度的统计量是( )。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
管理统计学综合实验
根据给定的数据Employee data.sav完成以下数据分析:
1.根据出生日期变量生成一个新变量“年龄”,并考察其是否服从正态分布
2.根据雇员的教育水平对起始薪金的平均值进行汇总
3.选择合适的图形考查不同雇佣类别人群的当前薪金的分布
4.通过假设检验来推断不同性别的人群的教育水平是否有差异
5.考察经验和当前薪金之间的数量关系,并建立二者的回归模型,预测当经验为300时,相应的薪金应是多少?
实验步骤及结论:
1.根据出生日期变量生成一个新变量“年龄”,并考察其是否服从正态分布
1)选择“转换”到“计算变量”
2)在“目标变量”中输入“年龄”
3)在“数学表达式”中选择“XDA TE.YEAR”,选择“出生日期”。
以2014为减数。
4)确定
1)选择“分析”到“描述统计”到“P_P图”2)在“变量”中选择“年龄”
3)在“检验分布”中选择“正态分布”
4)确定
模型描述
模型名称MOD_4
序列或顺序 1 年龄
转换无
非季节性差分0 季节性差分0 季节性期间的长度无周期性
标准化未应用
分布类型正态位置估计标度估计
部分排序估计方法Blom
为结指定秩同数的值的秩均值正在应用来自 MOD_4 的模型指定。
个案处理摘要
年龄
序列或顺序长度474 图中的缺失值数
用户缺失0
系统缺失 1 个案未进行加权。
估计的分布参数
年龄
正态分布
位置57.6723
标度11.78409
个案未进行加权。
由图可知,偏差大于0.05,所以不服从正态分布
2.根据雇员的教育水平对起始薪金的平均值进行汇总1)选择“数据”到“分类汇总”
3.选择合适的图形考查不同雇佣类别人群的当前薪金的分布1)选择“图形”到“图表构建程序”
由图可知,职员的当前佣金在27839左右,保管员在30939左右,经理在63978左右。
其中经理最高,职员最低,且相差较大。
4.通过假设检验来推断不同性别的人群的教育水平是否有差异
1)选择“分析”到“比较均值”到“独立样本T检验”
组统计量
性别N 均值标准差均值的标准误
教育水平(年)
男258 14.43 2.979 .185
女216 12.37 2.319 .158
独立样本检验
方差方程的 Levene 检
验
均值方程的 t 检验
F Sig. t df Sig.(双
侧) 均值差值标准误差值差分的 95% 置信区
间
下限上限
教育水平(年)假设方差相等17.884 .000 8.276 472 .000 2.060 .249 1.571 2.549 假设方差不相
等
8.458 469.595 .000 2.060 .244 1.581 2.538
由图可知,F=17.884,P=0.000,由于P值小于0.05,因此拒绝H0,认为两个样本
方差所在总体的方差是不齐的。
因此应选择方差不相等时的t检验结果,即为图
中第二行列出非t=8.458,df=469.595,P=0.000,小于0.05,从而最终得到的统计
结论按α=0.05水准。
拒绝H0不同性别的人群的教育水平是有差异的。
5.考察经验和当前薪金之间的数量关系,并建立二者的回归模型,预测当经验为
300时,相应的薪金应是多少?
选择“分析”到“回归”到“线性”
输入/移去的变量a
模型输入的变量移去的变量方法
1 经验(以月计)b. 输入
a. 因变量: 当前薪金
b. 已输入所有请求的变量。
由此图可知,放入模型的只有一个自变量,选择变量的方法为强行纳入模型的。
模型汇总
模型R R 方调整 R 方标准估计的误
差
1 .097a.009 .007 $17,012.353
a. 预测变量: (常量), 经验(以月计)。
Anova a
模型平方和df 均方 F Sig.
1 回归1310179340.33
2 1 1310179340.332 4.527 .034b 残差
136606316096.0
08
472 289420161.220
总计
137916495436.3
40
473
a. 因变量: 当前薪金
b. 预测变量: (常量), 经验(以月计)。
F=4.527,P<0.05,说明所建立的回归模型是具有统计学意义的,由于只有一个
变量,所以该自变量的回归系数是有统计意义的。
给出了模型的常数项a=35945.029以及自变量的偏回归系数b=-15.913及检验结果,可写出回归方程:
当前薪金Y=35945.029-15.913*经验X
所以,当经验=300时,预测当前薪金为31171元。
成绩评定:。