信息检索作业分析
信息检索实验报告

信息检索实验报告一、实验目的信息检索是一门旨在帮助人们快速、准确地获取所需信息的学科。
本次实验的目的在于深入了解和掌握信息检索的基本原理、方法和技术,提高信息检索的效率和质量,培养我们在信息时代中获取、评估和利用信息的能力。
二、实验环境本次实验在学校的计算机实验室进行,使用的操作系统为 Windows 10,浏览器为 Chrome,主要利用了以下几个信息检索工具和数据库:1、百度搜索引擎2、中国知网3、万方数据知识服务平台三、实验内容及步骤(一)简单检索实验1、打开百度搜索引擎,输入关键词“人工智能的发展趋势”,浏览搜索结果的前几页,观察并分析返回的网页内容。
2、调整关键词为“人工智能发展的最新动态”,再次进行搜索,比较两次搜索结果的差异。
(二)高级检索实验1、在中国知网中,选择“高级检索”功能,以“信息检索”为主题词,设置时间范围为“2018 年至 2023 年”,文献类型为“期刊论文”,进行检索。
2、对检索结果进行筛选,按照被引次数从高到低排序,选择前 10 篇论文进行阅读和分析。
(三)专业数据库检索实验1、进入万方数据知识服务平台,选择“科技”分类,输入关键词“大数据在医疗领域的应用”,进行检索。
2、查看检索结果的详细信息,包括标题、作者、摘要、关键词等,选择 5 篇相关度较高的文献进行下载和阅读。
四、实验结果与分析(一)简单检索实验结果分析1、第一次使用“人工智能的发展趋势”作为关键词进行搜索,返回的结果较为广泛,包含了新闻报道、学术论文、博客文章等多种类型的网页。
其中,一些网页提供了较为全面和深入的分析,但也有部分网页内容质量不高,存在信息不准确或过时的情况。
2、调整关键词为“人工智能发展的最新动态”后,搜索结果更加聚焦于近期的信息,并且相关的学术研究和权威报道所占比例有所增加。
这表明关键词的选择对于搜索结果的准确性和相关性具有重要影响。
(二)高级检索实验结果分析1、在中国知网的高级检索中,通过设置主题词、时间范围和文献类型等条件,检索到的文献更加符合研究需求。
信息检索期末总结作业

信息检索期末总结作业一、引言信息检索是在大数据时代非常重要的一个领域,它帮助用户从庞大的信息资源中找到所需的信息。
信息检索技术的发展,对于提高人们的信息获取效率和信息利用价值有着非常重要的作用。
在本学期的信息检索课程中,我学习了信息检索的基本概念、原理和技术,并进行了一系列的实践操作,通过这些学习和实践,我对信息检索有了更深入的了解和认识,本文将对本学期所学的内容进行总结和归纳。
二、信息检索的基本概念和原理(一)信息检索的定义信息检索是指根据用户需求,在信息资源中搜索、筛选、获取与需求相匹配的信息的过程。
(二)信息检索的基本原理1. 文本预处理文本预处理是信息检索的第一步,它包括文本的分词、去停用词、词干提取等操作。
通过这些操作,可以将文本转换为能够被计算机处理的形式。
2. 索引构建索引是信息检索的核心,它将文本中的关键词与对应的文档进行关联。
常用的索引方法有倒排索引和正排索引。
倒排索引通过关键词来查找对应的文档,而正排索引则是通过文档来查找对应的关键词。
3. 查询解析查询解析是将用户查询转化为计算机能够理解的形式。
查询解析的过程包括词法分析、句法分析和语义分析等步骤。
4. 检索模型信息检索的核心问题是如何衡量文档与查询之间的相关性。
常用的检索模型有向量空间模型、布尔模型和概率模型等。
这些模型通过计算文档与查询之间的相似度来确定文档的排序。
三、信息检索的技术与工具(一)倒排索引倒排索引是一种常用的索引结构,它通过关键词来查找对应的文档。
倒排索引由词典和倒排文件组成,词典记录了所有出现过的关键词和对应的指针,倒排文件则记录了每个关键词出现过的文档。
(二)TF-IDF算法TF-IDF算法是常用的文本特征权重算法,它用于衡量关键词在文档中的重要性。
TF指的是关键词在文档中的频率,IDF指的是关键词在整个文集中的逆文档频率。
(三)通配符搜索通配符搜索是一种模糊搜索的方法,它可以通过通配符(如通配符*和?)来匹配文本中的关键词。
信息检索作业

信息检索作业
信息检索是一种重要的信息处理技术,它主要是由用户使用某种工具检索信息、整合信息、过滤杂乱无关信息以及利用查询语义等方式,运用相关知识和技术获取需要的信息,以满足用户的需求。
而信息检索作业就是为了更好地进行信息检索,将相关的信息检索的任务细分为多个更容易处理的子任务,才有了信息检索作业的这一概念。
信息检索作业的基本步骤包括:收集有关信息的元数据,如文档的标题、关键字等;对元数据进行指定的解析,将原文档转为可操作的形式;建立可检索的索引库,在有关文档中查询有关信息;根据查询结果,进行信息检索作业,在不同的数据库中查询更准确的信息。
信息检索作业有多种可行的工作方法,其中,最常用的两种方法是抽象查询和检索索引。
抽象查询,指的是使用固定的词语,尽可能获取更准确的信息,从而得到更有效的信息检索结果;而检索索引则是将查询语句中的关键字作为索引,在有关的数据库中进行检索,以获取更多的信息。
此外,信息检索作业还可以通过文本挖掘技术得到更准确的信息。
文本挖掘是一种计算机对文本信息的智能分析,它可以根据文本的关联性来挖掘出有用的信息,辅助信息检索作业。
此外,还有许多其他的技术,如机器学习、大数据分析等,都可以帮助信息检索作业获得更好的效果。
需要指出的是,信息检索作业是一项非常复杂的工作,要求对查询语句的结构、意义、相关性以及语言的运用有精确的把握和处理能
力,并且需要及时更新和完善信息检索系统,以确保检索系统可靠可行。
信息检索作业不仅是一项必不可少的工作,而且还能够有效地帮助用户获取需要的信息。
由于其丰富的信息资源,信息检索作业得到了广泛的应用,在科技、企业、政府等多个领域都得到了广泛的应用,为社会经济的发展做出了积极的贡献。
信息检索作业

【作业1】在这六个方面, 我在有效运用信息达到特定目的方面最强, 在运用信息同时了解所涉及的经济,法律和社会范畴,合法和合理地获得和利用信息方面最弱, 我打算试着去改变弱点。
生活在信息时代的我们, 有感于城市的发展, 看着以前的痕迹渐渐变淡,看着新的建筑以一种不可抗拒的姿态环绕于我们的四周。
或是用我们的眼睛, 我们的思维去感觉不一样的信息时代。
这个时代建立的文明, 其核心就是变化的精神。
信息传播的方式在变, 信息传播的速度在变, 相应的我们的生活拥有了更丰富的元素存在。
互联网的普及为我们的生活带来了更多便捷。
它为我们提供了一个获取大量信息的平台。
然而, 信息量更大、内容更加丰富的同时也使得信息质量更加良莠不齐。
要成为优秀的当代大学生, 不仅要求我们能够更快的获取最新的信息, 而且要求我们获取最高质量的信息。
因此我们必须具备良好的信息素养, 以保证我们在信息泛滥的时代可以有效地获取信息, 并掌控好人生的航向, 使生活更加简约美好。
《美国高等教育信息素养能力标准》是美国专为培养现代人信息素养而制定的。
其重视信息素养在现实生活中所发挥的作用。
所谓信息素养, 简而言之就是人们解决问题时利用信息检索工具和主要信息源的技术和技能。
随着信息社会的飞速发展, 人们对信息素养有了新的认识, 认为信息素养是信息能力、信息意识和良好信息道德的总和。
信息素养是人的整体素质的一部分, 它是未来信息社会生活必备的基本能力。
我想对于大学生而言, 信息素养是大学生终身学习的关键因素。
具有了一定的信息素养, 大学生才有可能将学习延伸到正规的课堂教学之外, 才能在离开学校后, 在复杂的生活环境中进行独立自主的学习。
具有信息素养能力的学生能评判性地评价信息及其来源, 并能把所遴选出的信息与原有的知识背景和评价系统结合起来。
这是第三个标准, 人和机器最大的不同, 我想是因为人拥有思维, 这是任何人工智能所无法媲美的。
人在一秒钟内产生的无数想法, 我们会从自己角度看问题, 故而具有分析的能力, 在信息爆炸的今天, 学会分析所获取的信息显得尤为重要。
生工-信息检索大作业

课题大作业1课题的分析1.1用思维导图对你的课题涉及到的主要概念进行分析。
要求:要有主概念面、相关概念、隐含概念、英文检索词【课题名称】:FISH在乳腺癌组织中HER-2检测的应用与开发【主要概念】:FISH、乳腺癌、HER-2;【相关概念】:荧光原位杂交、c-erbB-2基因、人表皮生长因子受体2;【隐含概念】:免疫组织化学、双色荧光原位杂交;【英文检索词】:FISH、HER-2、breast cancer、c-erbB-2、IHC;1.2写出拟进行检索的检索策略、涉及到的学科范围【检索策略】:(1)(FISH+荧光原位杂交)*HER-2(2)(FISH+荧光原位杂交)*乳腺癌(3)(FISH+荧光原位杂交+免疫组织化学)*乳腺癌*HER-2(4)(c-erbB-2+HER-2)*(FISH+IHC)*breast cancer【涉及学科及分类号】:生物学(K826.15);医药卫生科技(G353.1)1.3总体检索思路你目前对这个课题了解的大致情况,以及你希望解决的问题。
由此你准备如何展开(国内、国外、年限、文献类型)。
【当前课题了解】:正常细胞中HER-2基因为2个拷贝,HER-2基因扩增,将导致转录上调、增加蛋白合成,驱动带有该异常分子改变的肿瘤细胞大量增殖。
研究表明,HER-2基因活性与乳腺癌不良预后密切相关,并且HER-2基因过表达与淋巴结阳性、癌的高级别、阴性激素受体状态及高增殖活性有关。
基于这些争论,研究者们采用FISH和IHC法分别检测HER-2蛋白质和基因状态并比较了两者与乳腺癌相关临床特征之间的一致性。
在临床研究上发现,HER-2阳性肿瘤对环磷酰胺、氨甲喋呤、氟尿嘧啶联合化疗有一定抵抗性,HER-2过表达的患者对此联合化疗反应性下降,对三苯氧胺无效,甚至将导致患者病情恶化;HER-2基因的扩增对含葸环类抗生素的联合化疗却时分地敏感。
实验研究还显示HER-2过表达对肿瘤表型和肿瘤侵袭、转移有影响,而近年发现对此类患者进一步使用HER-2蛋白人源性单克隆抗体“Herceptin”(赫赛汀)进行靶向治疗,可以取得较好疗效。
信息检索课题大作业课题分析
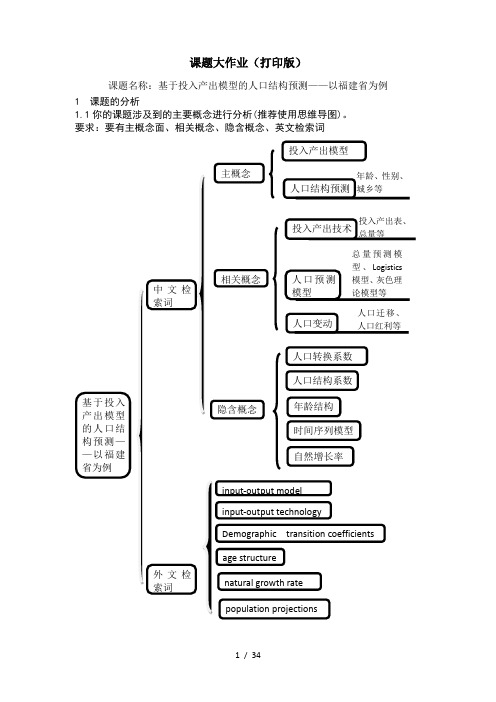
课题大作业(打印版)课题名称:基于投入产出模型的人口结构预测——以福建省为例1 课题的分析1.1你的课题涉及到的主要概念进行分析(推荐使用思维导图)。
要求:要有主概念面、相关概念、隐含概念、英文检索词总量预测模主概念面:投入产出模型、人口结构预测相关概念:投入产出、人口变动、人口迁移、人口红利、人口年龄结构、人口性别结构、人口城乡结构、人口预测模型、总量预测模型、灰色理论模型隐含概念:人口转换系数、人口结构系数、时间序列模型、自然增长率英文检索词:input-output model、input-output technology、Demographic transition coefficients、age structure、natural growth rate、population projections1.2写出拟进行检索的检索策略、涉及到的学科范围。
(1)检索策略:投入产出and人口结构and预测投入产出and(年龄结构or性别结构or城乡结构)and预测投入产出and(年龄结构or性别结构or城乡结构)and(总量预测or 时间序列or灰色理论or“logistics模型”)英文检索式:Input-output AND population* AND projectionInput-output AND(age OR sex OR urban-rural)AND projectionInput-output AND(age OR sex OR urban-rural)AND (Forecasting OR time series OR logistics)以中国知网(cnki)为例进行相关的论文期刊文献检索,使用cnki的高级搜索功能。
(2)涉及到的学科包括经济学、统计学、社会学、人口学和数学等。
1.3总体检索思路你目前对这个课题了解的大致情况,以及你希望解决的问题。
由此你准备如何展开(国内、国外、年限、文献类型)。
百度搜索引擎—信息检索作业
1
• 选择适当的查询词
搜索的基本技巧
选择查询词是一种经验积累,在一定程查找2005年国内十大新闻,查询词可以是 “2005年国内十大新闻”;但如果把查询词换成“2005 年国内十大事件”,搜索结果就不满足需求了。 另一类典型的表述不准确,是查询词中包含错别字。 例如,要查找钟汉良的写真图片,用“钟汉良写真”,当 然是没什么问题;但如果写错了字,变成“钟韩良写真”, 搜索结果质量就差得远了。点击快照3. 搜索特色功能
3.2 相关搜索
搜索结果不佳,可通过参考别人是怎么搜的,来获得一些启发。 “相关搜索” 提示和用户的搜索很相似的一系列查询词,按搜索 热门度排序。3. 搜索特色功能3.3 拼音提示
拼音提示功能,只需输入查询词的汉语拼音,就能把最符合要 求的对应汉字提示出来。
址”。比如我在经验网址里面搜索包含“老师”的结果,那我 五
指定文档类型搜索 文半角:)+文件格式。
– 表达式为:“关键词” + ”空格“+“filetype:”(英 – 文档格式可以是DOC、PDF、PPT、XLS 、 ALL (全部文档) 等类型。
比如我搜包含老师的PPT文档,那我就在搜索框输入 “老师 filetype:ppt”
六、限定在标题中搜索
– “TITLE:和“INTITLE:”都用于针对标题进行搜索。 – 格式: “intitle:”+“关键词”。 比如我要求搜索结果中所有的标如果有两个及以上关 键词,那就是“allintitle:”+“关键词1”+“空格”+“关键词2”。
• • 汉互译词典 计算器和度量衡转 专业文档搜索 股票、列车时刻表和飞机航班查询 高级搜索语法 高级搜索、地区搜索和个性设置 天气查询 货币换算3. 搜索特色功能3.1 快照
信息检索作业 (3)
信息检索作业1. 简介信息检索(Information Retrieval)指的是通过计算机系统从大量的信息中找到用户所需的有效信息的过程。
本篇文档将介绍信息检索的基本概念、技术和应用,并探讨信息检索系统的优化策略。
2. 信息检索的基本概念2.1 信息检索定义信息检索是指从大规模的、非结构化的信息资源中寻找用户所需信息的过程。
不同于数据库查询,信息检索更关注的是如何从大规模、动态的信息资源中快速准确地提取出用户需要的信息。
2.2 信息检索过程信息检索过程主要包括以下几个步骤:1.收集信息源:从互联网、数据库、文件等资源中收集大量的信息。
2.预处理:对收集到的信息进行清洗、分词、去除停用词等操作,将原始文本转化为可以处理的形式。
3.索引构建:根据预处理后的文本,构建倒排索引(Inverted Index),用于快速定位文档。
4.查询处理:根据用户的查询词,通过倒排索引定位相关的文档。
5.评价与排序:根据查询与文档的匹配程度,计算出相关性分数,并对结果进行排序。
6.结果展示:将获取的信息以用户易读的方式展示给用户。
2.3 常见的信息检索模型•布尔模型:把检索任务看作是布尔逻辑运算,通过组合关键词的逻辑运算进行检索。
•向量空间模型:将查询和文档表示为向量,在向量空间中计算相似度并排序结果。
•概率检索模型:基于概率论统计的模型,通过计算查询与文档的相关性得分进行排序。
•语言模型:将查询和文档都看作是语言模型,通过计算两者的相似度进行排序。
3. 信息检索的技术3.1 分词技术分词是信息检索的基础步骤,通过将文本切分成一个一个的词语,构建倒排索引。
常见的分词技术有:基于字典的分词、最大匹配法、最少切分法等。
3.2 倒排索引倒排索引是一种将词语映射到文档的数据结构,用于快速定位包含某个词语的文档。
倒排索引一般由词典和倒排列表组成,可以通过词典快速查找到包含某个词语的文档列表。
3.3 相似度计算相似度计算是信息检索中评价文档与查询之间相关性的指标,常见的相似度计算方法有:余弦相似度、BM25等。
法律信息检索案例分析报告(3篇)
第1篇一、背景随着社会经济的发展和法治建设的不断推进,法律信息检索在法律实践中扮演着越来越重要的角色。
法律信息检索是指通过查阅法律文献、法律法规、案例等资料,为法律事务提供依据和参考的过程。
本案例报告以某公司涉嫌侵犯他人著作权一案为例,分析法律信息检索在案件办理中的作用。
二、案情简介某公司(以下简称“甲公司”)在其产品宣传手册中使用了一幅图片,该图片系乙公司(以下简称“乙公司”)的著作权作品。
乙公司发现后,向甲公司发出律师函,要求其停止侵权行为并赔偿损失。
甲公司不服,认为其所使用的图片系免费下载,不构成侵权。
双方就此事产生纠纷,乙公司将甲公司诉至法院。
三、法律信息检索过程1. 确定检索范围针对本案,检索范围主要包括以下三个方面:(1)著作权法及相关法律法规;(2)类似案例;(3)免费下载图片的合法性。
2. 检索方法(1)法律法规检索:通过中国裁判文书网、北大法宝等法律数据库,检索著作权法、侵权责任法等相关法律法规。
(2)案例检索:通过中国裁判文书网、北大法宝等法律数据库,检索类似案例,了解法院在类似案件中的判决标准。
(3)免费下载图片合法性检索:通过搜索引擎、专业网站等途径,了解免费下载图片的合法性及相关法律法规。
3. 检索结果(1)法律法规检索结果:根据检索结果,我国《著作权法》规定,未经著作权人许可,以复制、发行、出租、展览、表演、放映、信息网络传播等方式使用作品,均构成侵权。
(2)案例检索结果:检索到多起类似案例,法院在判决中均认定,未经著作权人许可使用其作品,构成侵权。
(3)免费下载图片合法性检索结果:检索结果显示,免费下载图片的合法性存在争议,部分法院认为,即使免费下载,未经著作权人许可使用其作品,仍构成侵权。
四、案例分析1. 甲公司使用图片是否构成侵权根据检索到的法律法规和案例,甲公司使用乙公司的著作权作品,未经其许可,已构成侵权。
2. 甲公司抗辩理由是否成立甲公司抗辩其使用的图片系免费下载,不构成侵权。
信息检索课作业-青岛理工大学
青岛理工大学《信息检索与利用》课程作业与实习报告2014学年实习目的:了解检索的基本概念和原理,掌握一般的检索流程和常用的检索技巧,熟悉本馆国内外数字资源系统的内容体系、检索方法等,并能根据本专业课题需要熟练地从相关资源系统中迅速、准确地检索出所需文献并加以分析利用。
实习报告要求1.所写报告符合要求的格式规范,检索的过程合理、结果准确全面,记录项目完整。
2.纸质文本以A4纸打印交给各班负责人,按学号整序后交给任课老师。
3.“课程作业与实习报告”为本课程考核形式,最迟请于课程结束后一周内完成。
第一部分基础练习(10分)1. 《中图法》的全称是什么?《中图法》分为几个基本大类?分类号怎么组成的?标引你所选检索实习课题的《中图法》分类号(注明课题名称、类号和类名)答:(1)《中图法》的全称是《中国图书馆分类法》。
(2)分为二十二个基本大类。
(3)采用拼音字母与阿拉伯数字相结合的混合编码制。
除T大类外的其它二十一个基本大类均以一个字母(第一大类)加多位数字(二级以后类目)的形式,T大类下的二级类目为双字母,三级以后类目在两位字母后加数字。
具体分类号如下:A马克思主义、列宁主义、毛泽东思想、邓小平理论;B哲学、宗教;C社会科学总论;D 政治、法律;E军事;F经济;G文化、科学、教育、体育;H语言、文字;I文学;J 艺术;K历史、地理;N自然科学总论;O数理科学和化学;P天文学、地球科学;Q 生物科学;R医药、卫生;S农业科学;T工业技术;U交通运输;V航空、航天;X 环境科学、安全科学;Z综合性图书;(4)课题名称:村庄规划编制和实施的研究。
中图法分类: TU2 TU92. IPC的中文全称是什么?它用于类分什么类型文献?A41H3/015是几级IPC类目,其类目名称是什么?(参考下列IPC类表信息)答:(1)IPC的中文全称《国际专利分类法》;(2)它是属于专利文献检索;(3)六级(二点小组),类目名称:服装的缝制用的可调整款式的裁剪样版的用型板。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
信息检索
学院机电工程学院
专业机械制造及其自动化
学生姓名李海龙
学号 152080201016
1.写出目前我国国内的主要文献传递服务机构,阐述其主要特点及功能。
(1)中国高等教育文献保障系统(CALIS),中国高等教育文献保障系统(China Academic Library & Information System,简称CALIS),是经国务院批准的我国高等教育“211工程”“九五”“十五”总体规划中三个公共服务体系之一。
CALIS的宗旨是,在教育部的领导下,把国家的投资、现代图书馆理念、先进的技术手段、高校丰富的文献资源和人力资源整合起来,建设以中国高等教育数字图书馆为核心的教育文献联合保障体系,实现信息资源共建、共知、共享,以发挥最大的社会效益和经济效益,为中国的高等教育服务。
特点:CALIS 采用的分布式文献服务传递,CALIS 管理中心设在北京大学,下设了文理、工程、农学、医学四个全国文献信息服务中心,华东北、华东南、华中、华南、西北、西南、东北七个地区文献信息服务中心和一个东北地区国防文献信息服务中心。
(2)国家科技图书文献中心(NSTL),国家科技图书文献中心(NSTL)是根据国务院领导的批示于2000年6月12日组建的一个虚拟的科技文献信息服务机构,成员单位包括中国科学院文献情报中心、工程技术图书馆(中国科学技术信息研究所、机械工业信息研究院、冶金工业信息标准研究院、中国化工信息中心)、中国农业科学院图书馆、中国医学科学院图书馆。
网上共建单位包括中国标准化研究院和中国计量科学研究院。
中心设办公室,负责科技文献信息资源共建共享工作的组织、协调与管理。
特点:统筹协调,较完整地收藏国内外科技文献信息资源制订数据加工标准、规范,建立科技文献数据库利用现代网络技术,提供多层次服务推进科技文献信息资源的共建共享组织科技文献信息资源的深度开发和数字化应用开展国内外合作与交流。
(3)中国科学院国家科学图书馆,中国科学院文献情报中心(National Science Library,Chinese Academy of Sciences)立足中国科学院、面向中国,主要为自然科学、边缘交叉科学和高技术领域的科技自主创新提供文献信息保障、战略情报研究服务、公共信息服务平台支撑和科学交流与传播服务,同时通过国家科技文献平台和开展共建共享为国家创新体系其他领域的科研机构提供信息服务。
同时该中心为国际图书馆协会与机构联合会(IFLA)成员。
特点:中科院文献情报中心机构知识库(以下简称NSL-IR)以发展机构知识能力和知识管理能力为目标,快速实现对该机构知识资产的收集、长期保存、合理传播利用,建设对知识内容进行捕获、转化、传播、利用和审计的能力,逐步建设包括知识内容分析、关系分析和能力审计在内的知识服务能力,开展综合知识管理。
中科院文献情报中心一方面是嵌入到了中国科学院科研环境之中的网络化“国家科学数字图书馆”(Chinese Science Digital Library),按照“资源到所、服务到人“的服务模式,通过公共集成服务平台,将数字化文献资源和网络化信息服务推送到科研现场,使科研人员在实验室、办公室、野外场站和家里就能随时随地获取丰富的科技信息;另一方面,又是一系列拥有丰富文献资源收藏和多方面服务力量的多层
次的图书馆体系。
2006年建立了学科馆员制度,推行面向一线创新基地、研究所、实验室、课题组和个人的学科化服务,努力“融入一线、嵌入过程”,致力于提升科技自主创新的文献保障能力和学科情报服务能力。
(4)中国高校人文社会科学文献中心(CASHL), CASHL是中国高校人文社会科学文献中心(China Academic Humanities and Social Sciences Library)的英文简称,该项目是教育部根据高校人文社会科学的发展和文献资源建设的需要引进专项经费建立的。
其宗旨是组织若干所具有学科优势、文献资源优势和服务条件优势的高等学校图书馆,有计划、有系统地引进国外人文社会科学期刊,借助现代化的服务手段,为全国高校的人文社会科学教学和科研提供高水平的文献保障。
是全国性的唯一的人文社会科学外文期刊保障体系。
特点:现已收藏有9148种国外人文社会科学领域的重要期刊、40万种外文图书、1370种电子期刊、25万种电子图书。
涉及地理、法律、教育、经济/商业/管理、军事、历史、区域学、人物/传记、社会科学、社会学、体育、统计学、图书馆学/信息科学、文化、文学、心理学、艺术、语言/文字、哲学/宗教、政治等学科。
2综合练习,根据自己的学科方向,列出文献调研时需要查询的中文或外文数据库,描述其信息资源的主要特点,分别选择期刊数据库,学位论文,图书三种文献类型举一例。
中文数据库:CNKI、万方数据、维普中文期刊、超星汇雅电子书、中文电子图书;
外文数据库:SCI、EI、AMSE、外文电子图书、Web of Sciencce、EI village、IEL、中宏数据。
(1)期刊:CNKI中国期刊全文数据库
CNKI文献搜索是清华同方知网公司以CNKI总库资源为基础,具有自主知识产权的专业文献检索系统。
其搜索范围包含近8000种期刊、300所大学研究院所博士、硕士论文、1000种学术会议论文集、1000种重要报纸文章,而且实时数据更新数据涵盖中国学术期刊、博硕士论文、会议论文、报纸文献、专利标准等近4000多万篇最新专业学术文献。
CNKI知识搜索在KBase独有的搜索引擎技术上,采用了最新的文献排序技术、分组技术以及用户搜索意图智能分析技术。
能够对用户一个简单的搜索请求做全方位的智能解析,在返回最相关最重要的文献基础上,对全部相关文献做立体化分析。
CNKI搜索界面简洁明快,并通过引证文献、相似文献等链接、层层深入搜索,使用户对搜索结果有更全面的了解.用户可以通过指定来源数据库、学科分类等不同分组方式,对检索结果进行进一步筛选,查到符合自己要求的检索内容。
CNKI知识搜索提供相关度、被引次数、下载次数、时间检索等排序方式,搜索结果根据下载次数标出下载指数,供用户参考;CNKI 知识搜索的高级检索提供文献重要度检索,包括核心期刊、SCI、EI文献来源有基金选项,对快速检索出高质量的科技文献很有帮助。
(2)学位论文:中国学位论文全文数据库
中国学位论文全文数据库精选全国重点学位授予单位的硕士、博士学
位论文以及博士后报告。
内容涵盖理学、工业技术、人文科学、社会科学、医药卫生、农业科学、交通运输、航空航天和环境科学等各学科领域,是我国收录数量最多的学位论文全文数据库。
中国学位论文全文数据库与国内570余所高校、科研院所等学位授予单位合作,占研究生学位授予单位的90%以上,其中211高校覆盖率为97%。
收录自1980年以来的学位论文,论文总量200余万篇(截至2011年10月),每年增加约30万篇。
其特点有以下几点:
①权威专家参与学位论文加工,全程辅以专业的标引、分类、及相关引文分析;收录数量多,海量全文资源辅以文摘库。
②收录单位及学科覆盖面广,涉及全国985高校和211重点高校、中科院、工程院、农科院、医科院、林科院等机构的重点精选博硕士论文。
③收录年限跨度长,重点收录2000年以来的学位论文,并将逐年回溯并月度追加,依托丰富的馆藏,可提供1977年以来的学位论文全文传递服务。
(3)图书:超星数字图书馆
超星数字图书馆成立于1993年,是国内专业的数字图书馆解决方案提供商和数字图书资源供应商。
超星数字图书馆,是国家“863”计划中国数字图书馆示范工程项目, 2000年1月,在互联网上正式开通。
超星数字图书馆为目前世界最大的中文在线数字图书馆,提供大
量的电子图书资源提供阅读,其中包括文学、经济、计算机等五十余大类,数百万册电子图书,500 万篇论文,全文总量 13亿余页,数据总量1000000GB,大量免费电子图书,超16万集的学术视频,拥有超过35万授权作者,5300位名师,一千万注册用户并且每天仍在不断的增加与更新。
为目前世界最大的中文在线数字图书馆。
其覆盖范围涉及哲学、宗教、社科总论、经典理论、民族学、经济学、自然科学总论、计算机等各个学科门类。