马尔可夫过程实例
马尔可夫决策过程中的策略迭代算法应用案例(五)

马尔可夫决策过程(MDP)是一种用于描述随机决策问题的数学框架。
在MDP 中,一个决策代理通过与环境进行交互,从而实现某些目标。
马尔可夫决策过程中的策略迭代算法是一种通过不断改进策略来寻找最优策略的方法。
本文将通过介绍一个实际应用案例,来说明策略迭代算法在马尔可夫决策过程中的应用。
案例背景假设有一个餐厅,餐厅的主要目标是最大化利润。
餐厅有两种菜品A和B,每天的客流量是不确定的。
为了最大化利润,餐厅需要确定每天供应菜品A和菜品B的数量。
在这个情景下,可以将餐厅的经营问题建模为一个马尔可夫决策过程。
状态空间和动作空间在这个例子中,状态空间可以表示为餐厅每天的客流量,动作空间可以表示为供应的菜品A和菜品B的数量。
在这个案例中,为了简化问题,我们假设客流量只有两种可能的状态:高客流量和低客流量。
动作空间也简化为两个动作:供应大量菜品A和供应大量菜品B。
奖励函数餐厅的目标是最大化利润,因此可以将利润作为奖励函数。
具体来说,对于每一种状态和动作组合,可以通过计算供应菜品A和菜品B所带来的收入和成本来确定奖励值。
策略迭代算法策略迭代算法是一种通过不断改进策略来寻找最优策略的方法。
在马尔可夫决策过程中,策略可以表示为在每个状态下采取每个动作的概率。
策略迭代算法包括两个步骤:策略评估和策略改进。
策略评估在策略评估阶段,需要计算当前策略下每个状态的值函数。
值函数表示在给定策略下,从某个状态开始能够获得的未来奖励的期望值。
对于我们的餐厅案例,值函数可以表示为在高客流量和低客流量下供应菜品A和菜品B所能获得的预期利润。
在策略评估阶段,可以使用动态规划算法来计算值函数。
动态规划算法是一种通过将问题分解为子问题并逐步求解这些子问题来找到最优解的方法。
在我们的案例中,可以利用动态规划算法来计算每个状态下的值函数。
策略改进在策略改进阶段,需要找到可以改进当前策略的动作。
具体来说,对于每个状态,需要选择能够最大化值函数的动作作为新策略。
马尔可夫决策过程在金融领域的使用案例(Ⅰ)

马尔可夫决策过程在金融领域的使用案例一、引言马尔可夫决策过程(Markov Decision Process, MDP)是一种在金融领域广泛应用的数学模型。
它基于马尔可夫链和动态规划理论,用于描述随机决策问题,并在金融领域中被用于风险管理、投资组合优化和衍生品定价等方面。
本文将探讨马尔可夫决策过程在金融领域的使用案例,并分析其应用价值和局限性。
二、马尔可夫决策过程概述马尔可夫决策过程是一种描述在随机环境下进行决策的数学模型。
它包括状态空间、行动空间、状态转移概率和奖励函数等要素。
在金融领域中,状态空间可以表示不同的市场状态,行动空间可以表示不同的投资决策,状态转移概率可以表示市场状态之间的转移概率,奖励函数可以表示投资行为的收益或损失。
通过建立马尔可夫决策过程模型,可以帮助金融从业者制定有效的投资决策,并优化投资组合。
三、马尔可夫决策过程在风险管理中的应用在金融领域,风险管理是一个重要的问题。
马尔可夫决策过程可以用于描述和优化风险管理策略。
例如,基于马尔可夫决策过程模型,可以制定投资组合调整策略,以应对市场波动和风险敞口的变化。
同时,马尔可夫决策过程还可以用于模拟和优化对冲策略,帮助金融机构降低交易风险,提高资产配置效率。
四、马尔可夫决策过程在投资组合优化中的应用投资组合优化是金融领域中的一个经典问题。
马尔可夫决策过程可以用于描述资产价格的随机波动,并基于市场状态预测制定最优的投资组合。
通过建立马尔可夫决策过程模型,可以找到最优的投资组合,以最大化预期收益或最小化投资风险。
此外,马尔可夫决策过程还可以用于实时动态调整投资组合,以适应市场环境的变化。
五、马尔可夫决策过程在衍生品定价中的应用在金融衍生品交易中,马尔可夫决策过程也有着重要的应用。
通过建立包含随机市场因素的马尔可夫决策过程模型,可以对衍生品的定价进行建模和分析。
这有助于金融从业者理解衍生品的价格形成机制,并进行有效的风险对冲和套利交易。
第7章 马尔可夫过程与泊松过程

第7章 马尔可夫过程与泊松过程7.1 马尔可夫过程1.引例例1:随机游动问题。
质点在一直线上作随机游动,如果某一时刻质点位于点i ,则下一步质点以概率p 向左移动一格达到点1-i ,以概率)1(p -向右移动一格达到点1+i 。
用)(n X 表示时刻n 质点的位置,则)(n X 是一随机过程。
在时刻1+n 质点所处的位置)1(+n X 只与时刻n 质点的位置)(n X 有关,而与n 以前的位置)1(-n X …)2(X 、)1(X 无关。
例2:遗传病问题。
某些疾病常遗传给下一代,但不隔代遗传。
第1+n 代是否有此种疾病只与第n 代是否有此疾病有关,而与n 代以前的健康状况无关。
2.马尔可夫过程描述性概念一般而言,若随机过程在时刻n t 所处的状态)(n t X 为已知的条件下,过程在时刻t (n t t >)所处的状态)(t X 只与过程在时刻n t 的状态)(n t X 有关,而与n t 以前的状态无关,则称此过程为马尔可夫过程。
3.马尔可夫过程分类马尔可夫过程分为四类:(1) 离散马尔可夫链:时间t 取离散值1t , ,2t ,n t ,可直接记为 ,,2,1n t =。
状态)(n X 取离散值1a , ,2a ,n a ,可直接记为 ,,2,1n X =。
(2) 连续马尔可夫链:时间t 取离散值1t , ,2t ,n t ,状态)(n X 取连续值。
(3) 离散马尔可夫过程:时间t 取连续值,状态)(t X 取离散值。
(4) 连续马尔可夫过程:时间t 取连续值,状态)(t X 取连续值。
.4.马尔可夫过程的研究与应用概况在随机过程的研究领域,马尔可夫过程是主要的研究对象,有关的专著、专题无计其数,其原因是马尔可夫过程与众多的应用领域有关联。
5.马尔可夫链(1)定义设时间t 取离散值 ,,2,1n t =,记)(n X X n =,设状态n X 取有限个离散值N X ,2,1=,若{}{}i X j X P i X i X i X j X P n n n n n n =======+--+111111,,称n X 马尔可夫链。
马尔可夫链的基本概念与应用实例

马尔可夫链的基本概念与应用实例马尔可夫链是一种数学模型,用于描述一个过程,该过程在任何给定状态下进行的概率取决于前一状态,而与过去状态无关。
它在许多领域中有着广泛的应用,如统计学、经济学、化学、物理学等等。
本文将对马尔可夫链的基本概念和一些应用实例进行阐述。
一、马尔可夫链的基本概念马尔可夫链是一种随机过程,在任何给定状态下,转移到另一个状态的概率只取决于前一个状态,而与之前的状态无关。
这被称为马尔可夫性质。
因此一个马尔可夫链可以完全由初始状态和转移概率矩阵来描述。
1. 状态空间状态空间是指一个马尔可夫链中所有可能的状态的集合。
它可以是有限的,也可以是无限的。
例如,一个投掷硬币的例子,状态空间为{正面, 反面}。
2. 转移概率矩阵转移概率矩阵描述的是从一个状态到另一个状态的概率。
在一个马尔可夫链中,概率矩阵的每一行表示从一个状态转移到所有其他状态的概率。
在一个有限状态空间中,概率矩阵是一个n x n 的矩阵(n表示状态的数量)。
例如一个2 x 2的矩阵表示如下:s1 s2s1 p11 p12s2 p21 p22其中,p11 表示从状态 s1 转移到状态 s1 的概率;p12 表示从状态 s1 转移到状态 s2 的概率;p21 表示从状态 s2 转移到状态 s1 的概率;p22 表示从状态 s2 转移到状态 s2 的概率。
3. 初始状态概率分布每个马尔可夫链起始状态可以是任何一个状态。
初始状态概率分布表示从哪个可能的起始状态开始进行模型。
它通常会假定为一个向量,其中每个元素表示该状态成为起始状态的概率。
二、马尔可夫链的应用实例随机漫步是马尔可夫链的一个重要应用。
在随机漫步中,一个行动的结果只取决于之前的状态,而与其之前的状态无关。
这种情况下,马尔可夫链为该过程提供了一个可靠的模型。
在金融领域,股市价格变动也被认为是一个形式的马尔可夫链。
一个股票的价格在任何时间不仅取决于过去的价格,还受到多种经济因素的影响。
马尔可夫决策过程

马尔可夫决策过程马尔可夫决策过程1. 概述现在我们开始讨论增强学习(RL,reinforcement learning)和⾃适应控制( adaptive control)。
在监督式学习中,我们的算法总是尝试着在训练集合中使预测输出尽可能的模仿(mimic)实际标签y(或者潜在标签)。
在这样的设置下,标签明确的给出了每个输⼊x的正确答案。
然⽽,对于许多序列决策和控制问题(sequential decision making and control problems),很难提供这样的明确的监督式学习。
⽐如我们现在正在做⼀个四条腿的机器⼈,⽬前我们正在尝试编程让他能够⾏⾛,在最开始的时候,我们就⽆法定义什么是正确的⾏⾛,那么我们就⽆法提供⼀个明确的监督式学习算法来尝试模仿。
在增强学习框架下,我们的算法将仅包含回报函数(reward function),该函数能够表明学习主体(learning agent)什么时候做的好,什么时候做的不好。
在四⾜机器⼈⾏⾛例⼦中,回报函数可以是在机器⼈向前移动时,给予机器⼈积极的回报,在机器⼈后退后者跌倒时给予消极的回报。
那么我们的学习算法任务是如何随着时间的变化⽽选择⼀个能够让回报最⼤的⾏动。
⽬前增强学习已经能够成功的应⽤在不同的⾃主直升飞机驾驶、机器⼈步态运动、⼿机⽹络路由、市场策略选择、⼯⼚控制和不同的⽹页检索等等。
在这⾥,我们的增强学习将从马尔可夫决策过程(MDP, Markov decision processes)开始。
1. 马尔可夫决策过程⼀个马尔可夫决策过程是⼀个元组 (S, A, {P sa}, γ, R),其中(以⾃主直升飞机驾驶为例):S是状态(states)集合,例:直升飞机的所有可能的位置和⽅向的集合。
A是动作(actions)集合,例:可以控制直升飞机⽅向的⽅向集合P sa是状态转移概率,例:对于每个状态s∈ S,动作a∈ A,P sa是在状态空间的⼀个分布。
马尔可夫(Markov)分析法范例
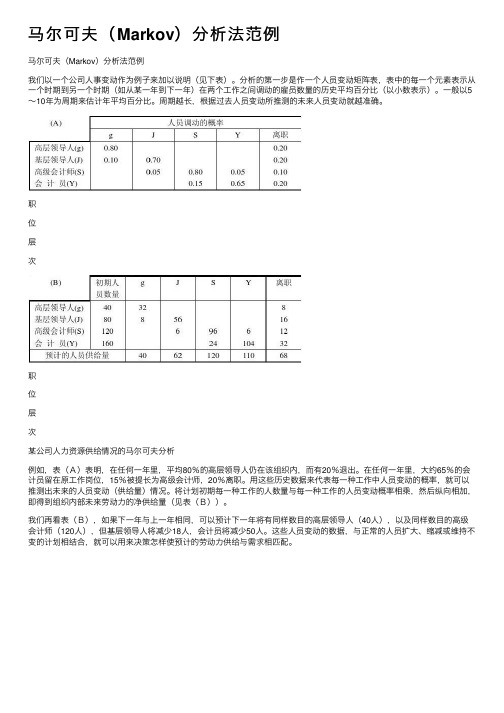
马尔可夫(Markov)分析法范例
马尔可夫(Markov)分析法范例
我们以⼀个公司⼈事变动作为例⼦来加以说明(见下表)。
分析的第⼀步是作⼀个⼈员变动矩阵表,表中的每⼀个元素表⽰从⼀个时期到另⼀个时期(如从某⼀年到下⼀年)在两个⼯作之间调动的雇员数量的历史平均百分⽐(以⼩数表⽰)。
⼀般以5~10年为周期来估计年平均百分⽐。
周期越长,根据过去⼈员变动所推测的未来⼈员变动就越准确。
职
位
层
次
职
位
层
次
某公司⼈⼒资源供给情况的马尔可夫分析
例如,表(A)表明,在任何⼀年⾥,平均80%的⾼层领导⼈仍在该组织内,⽽有20%退出。
在任何⼀年⾥,⼤约65%的会计员留在原⼯作岗位,15%被提长为⾼级会计师,20%离职。
⽤这些历史数据来代表每⼀种⼯作中⼈员变动的概率,就可以推测出未来的⼈员变动(供给量)情况。
将计划初期每⼀种⼯作的⼈数量与每⼀种⼯作的⼈员变动概率相乘,然后纵向相加,即得到组织内部未来劳动⼒的净供给量(见表(B))。
我们再看表(B),如果下⼀年与上⼀年相同,可以预计下⼀年将有同样数⽬的⾼层领导⼈(40⼈),以及同样数⽬的⾼级会计师(120⼈),但基层领导⼈将减少18⼈,会计员将减少50⼈。
这些⼈员变动的数据,与正常的⼈员扩⼤、缩减或维持不变的计划相结合,就可以⽤来决策怎样使预计的劳动⼒供给与需求相匹配。
如何在实际应用中使用马尔可夫决策过程(十)

马尔可夫决策过程(MDP)是一种在人工智能和机器学习领域广泛应用的数学模型。
它可以帮助我们理解和解决一系列问题,例如自动驾驶、游戏策略、金融决策等。
在本文中,我将探讨如何在实际应用中使用马尔可夫决策过程,并且给出一些具体的案例。
首先,让我们来了解一下马尔可夫决策过程是什么。
马尔可夫决策过程是一种用来建模决策问题的数学框架,它基于马尔可夫链和决策理论。
在马尔可夫决策过程中,我们考虑的是一个代理在一个环境中做决策的过程。
这个环境可以是任何可以描述为状态空间和动作空间的系统。
在每个时刻,代理根据当前的状态选择一个动作,然后环境对状态和动作做出响应,代理得到奖励并转移到新的状态。
这个过程就是马尔可夫决策过程的基本框架。
在实际应用中,我们可以使用马尔可夫决策过程来建模和解决很多问题。
比如,假设我们要设计一个自动驾驶系统,我们可以将道路交通环境建模为一个马尔可夫决策过程。
每个交通状态(比如红绿灯、车辆行驶速度等)可以被看作是一个状态,而每个驾驶决策(比如加速、减速、转弯等)可以被看作是一个动作。
然后,我们可以使用强化学习算法来训练代理,使其学会在不同交通状态下做出最优的驾驶决策。
另一个例子是金融领域的应用。
假设我们要设计一个股票交易系统,我们可以将股市行情建模为一个马尔可夫决策过程。
每个市场状态(比如股票价格、成交量等)可以被看作是一个状态,而每个交易决策(买入、卖出、持有等)可以被看作是一个动作。
然后,我们可以使用强化学习算法来训练代理,使其学会在不同市场状态下做出最优的交易决策。
在实际应用中,使用马尔可夫决策过程需要我们解决一些具体的问题。
首先,我们需要定义环境的状态空间和动作空间。
这需要对问题领域有一定的理解和抽象能力。
其次,我们需要定义环境对状态和动作的响应方式,以及代理获得奖励的规则。
这需要我们对环境的运行机制有一定的了解。
接下来,我们需要选择合适的强化学习算法来训练代理。
常用的算法包括Q-learning、SARSA、DQN等。
马尔可夫决策过程实例讲解

} 算法步骤简单,思想也简单但有效:重复贝尔曼公式(4),更新V (s) 。经过验证,该算
法 最 终 能 够 使 得 V (s) V *(s) 。 具 体 证 明 值 迭 代 算 法 收 敛 的 过 程 可 以 参 考 文 档
file:///E:/rearchStudent3/201501.15@MDP/MDP%E8%B5%84%E6%96%99/introduction%20of% 20MDP--Princeton.pdf 中的 3-10 部分。
上图的场景表征的是机器人导航任务,想象一个机器人生活在网格世界中,阴暗单元是 一个障碍。假设我希望机器人到达的目的地是右上角的格子(4,3),于是我用+1 奖励来 关联这个单元;我想让它避免格子(4,2),于是我用-1 奖励来关联该单元。现在让我们 来看看在该问题中,MDP 的五元组是什么: S:机器人可以在 11 个网格中的任何一个,那么一共有 11 个状态;集合 S 对应 11 个可 能到达的位置。 A={N S E W}。机器人可以做出的动作有 4 个:向东 向南 向西 向北。 Psa :假设机器人的行为核心设计并不是那么精准,机器人在受到相关指令后有可能会走偏 方向或者行走距离不那么精确,为简化分析,建立机器人随机动态模型如下:
P(3,1)N ((3, 2)) 0.8; P(3,1)N ((2,1)) 0.1; P(3,1)N ((4,1)) 0.1;P(3,1)N ((3,3)) 0;...
R:奖励函数可以设置为:
R((4,3)) 1 R((4, 2)) 1 R(s) 0.02对于其他状态s
去状态是条件独立的。在一些资料中将 Psa 写成矩阵形式,即状态转换矩阵。
[0,1) 表示的是 discount factor,具体含义稍后解释。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
马尔可夫过程实例
马尔可夫过程的大概意思就是未来只与现在有关,与过去无关。
简单理解就是渣男只在乎下一刻会不会爱你只取决于这一时刻
对你的新鲜感,而与你之前对这段感情的付出毫无关系。
设有一个随机过程X(t),如果对于下一个任意的时间序列,在给定随机变量的条件下的分布可表示为则称X(t)为马尔可夫过程或者简称马氏过程。
这种“下一时刻的状态至于当前状态有关,与上一时刻状态无关”的性质,称为无后效性或者马尔可夫性。
而具有这种性质的过程就称为马尔可夫过程。
在马尔可夫过程中有两个比较重要的概念:转移分布函数、转移概率马氏过程,称条件概率为过程的转移分布函数。
其条件概率为转移概率密度,称为转移概率。
马尔科夫链(Markov)是最简单的马氏过程,即时间和状态过程的取值参数都是离散的马氏过程。
时间和状态的取值都是离散值。
假定在每一个时刻(n=1,2,…),所有可能的状态的集合S是可数的,即可表示为S={0,1,2,…}。
对应于时间序列t1,t2 ,…,tn,…,马氏链的状态序列为i1,i2,…, in,…。
对于马尔科夫链,若转移概率与n无关(即与哪一次转移无关,仅与转移前后的状态有关),则该马氏链为齐次马氏链;否则称为非齐次马氏链。
接下来我们仅讨论齐次马氏链。