最新计量经济学案例分析一元回归模型实例分析
计量经济学实验一 一元回归模型
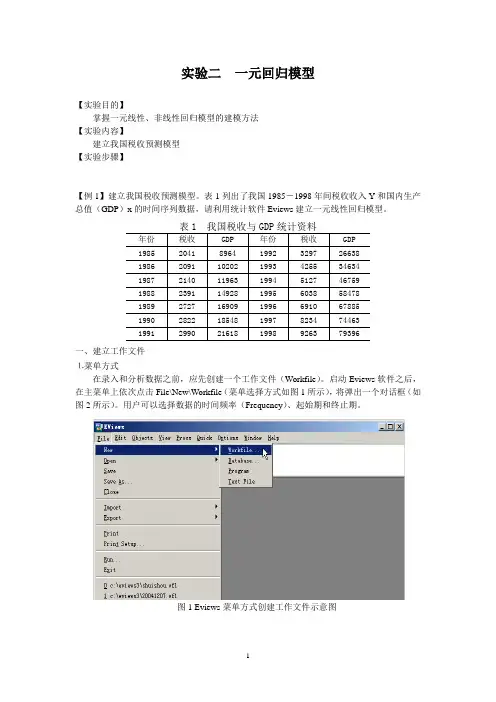
实验二一元回归模型【实验目的】掌握一元线性、非线性回归模型的建模方法【实验内容】建立我国税收预测模型【实验步骤】【例1】建立我国税收预测模型。
表1列出了我国1985-1998年间税收收入Y和国内生产总值(GDP)x的时间序列数据,请利用统计软件Eviews建立一元线性回归模型。
一、建立工作文件⒈菜单方式在录入和分析数据之前,应先创建一个工作文件(Workfile)。
启动Eviews软件之后,在主菜单上依次点击File\New\Workfile(菜单选择方式如图1所示),将弹出一个对话框(如图2所示)。
用户可以选择数据的时间频率(Frequency)、起始期和终止期。
图1 Eviews菜单方式创建工作文件示意图图2 工作文件定义对话框本例中选择时间频率为Annual(年度数据),在起始栏和终止栏分别输入相应的日期85和98。
然后点击OK,在Eviews软件的主显示窗口将显示相应的工作文件窗口(如图3所示)。
图3 Eviews工作文件窗口一个新建的工作文件窗口内只有2个对象(Object),分别为c(系数向量)和resid(残差)。
它们当前的取值分别是0和NA(空值)。
可以通过鼠标左键双击对象名打开该对象查看其数据,也可以用相同的方法查看工作文件窗口中其它对象的数值。
⒉命令方式还可以用输入命令的方式建立工作文件。
在Eviews软件的命令窗口中直接键入CREATE命令,其格式为:CREATE 时间频率类型起始期终止期本例应为:CREATE A 85 98二、输入数据在Eviews软件的命令窗口中键入数据输入/编辑命令:DA TA Y X此时将显示一个数组窗口(如图4所示),即可以输入每个变量的数值图4 Eviews数组窗口三、图形分析借助图形分析可以直观地观察经济变量的变动规律和相关关系,以便合理地确定模型的数学形式。
⒈趋势图分析命令格式:PLOT 变量1 变量2 ……变量K作用:⑴分析经济变量的发展变化趋势⑵观察是否存在异常值本例为:PLOT Y X⒉相关图分析命令格式:SCAT 变量1 变量2作用:⑴观察变量之间的相关程度⑵观察变量之间的相关类型,即为线性相关还是曲线相关,曲线相关时大致是哪种类型的曲线说明:⑴SCAT命令中,第一个变量为横轴变量,一般取为解释变量;第二个变量为纵轴变量,一般取为被解释变量⑵SCAT命令每次只能显示两个变量之间的相关图,若模型中含有多个解释变量,可以逐个进行分析⑶通过改变图形的类型,可以将趋势图转变为相关图本例为:SCA T Y X图5 税收与GDP趋势图图5、图6分别是我国税收与GDP时间序列趋势图和相关图分析结果。
最新计量经济学案例分析一元回归模型实例分析

案例分析1— 一元回归模型实例分析依据1996-2005年《中国统计年鉴》提供的资料,经过整理,获得以下农村居民人均消费支出和人均纯收入的数据如表2-5:表2-5 农村居民1995-2004人均消费支出和人均纯收入数据资料 单位:元 年度 1995199619971998199920002001200220032004人均纯收入1577.7 1926.1 2090.1 2161.1 2210.3 2253.4 2366.4 2475.6 2622.2 2936.4人均消费支出1310.4 1572.1 1617.2 1590.3 1577.4 1670.1 1741.1 1834.3 1943.3 2184.7一、建立模型以农村居民人均纯收入为解释变量X ,农村居民人均消费支出为被解释变量Y ,分析Y 随X 的变化而变化的因果关系。
考察样本数据的分布并结合有关经济理论,建立一元线性回归模型如下:Y i =β0+β1X i +μi根据表2-5编制计算各参数的基础数据计算表。
求得:082.1704035.2262==Y X∑∑∑∑====3752432495.1986.788859011.516634423.1264471222ii i i iX y x y x 根据以上基础数据求得:623865.0423.126447986.788859ˆ21===∑∑iii xyx β8775.292035.2262623865.0082.1704ˆˆ10=⨯-=-=X Y ββ 样本回归函数为:ii X Y 623865.08775.292ˆ+= 上式表明,中国农村居民家庭人均可支配收入若是增加100元,居民们将会拿出其中的62.39元用于消费。
二、模型检验1.拟合优度检验952594.0011.516634423.1264471986.788859))(()(22222=⨯==∑∑∑iii i yx y x r2.t 检验525164.3061 210423.12644710.623865011.166345 2ˆˆ222122=-⨯-=--=∑∑n x y iiβσ049206.0423.1264471525164.3061ˆ)ˆ()ˆ(2211====∑ie xVar S σββ6717.112525164.3061423.126447110137.52432495ˆ)ˆ()ˆ(22200=⨯===∑∑σββii e xn X Var S 在显著性水平α=0.05,n-2=8时,查t 分布表,得到:306.2)2(2=-n t α提出假设,原假设H 0:β1=0,备择假设H 1:β1≠067864.12049206.0623865.0)ˆ(ˆ)ˆ(111==-=ββββe S t)2(67864.12)ˆ(21->=n t t αβ,差异显著,拒绝β1=0的假设。
一元线性回归模型案例分析

一元线性回归模型案例分析一元线性回归是最基本的回归分析方法,它的主要目的是寻找一个函数能够描述因变量对于自变量的依赖关系。
在一元线性回归中,我们假定存在满足线性关系的自变量与因变量之间的函数关系,即因变量y与单个自变量x之间存在着线性关系,可表达为:y=β0+ β1x (1)其中,β0和β1分别为常量,也称为回归系数,它们是要由样本数据来拟合出来的。
因此,一元线性回归的主要任务就是求出最优回归系数和平方和最小平方根函数,从而评价模型的合理性。
下面我们来介绍如何使用一元线性回归模型进行案例分析。
数据收集:首先,研究者需要收集自变量和因变量之间关系的相关数据。
这些数据应该有足够多的样本观测值,以使统计分析结果具有足够的统计力量,表示研究者所研究的关系的强度。
此外,这些数据的收集方法也需要正确严格,以避免因相关数据缺乏准确性而影响到结果的准确性。
模型构建:其次,研究者需要利用所收集的数据来构建一元线性回归模型。
即建立公式(1),求出最优回归系数β0和β1,即最小二乘法拟合出模型方程式。
模型验证:接下来,研究者需要对所构建的一元线性回归模型进行验证,以确定模型精度及其包含的统计意义。
可以使用F检验和t检验,以检验回归系数β0和β1是否具有统计显著性。
另外,研究者还可以利用R2等有效的拟合检验统计指标来衡量模型精度,从而对模型的拟合水平进行评价,从而使研究者能够准确无误地判断其研究的相关系数的统计显著性及包含的统计意义。
另外,研究者还可以利用偏回归方差分析(PRF),这是一种多元线性回归分析技术,用于计算每一个自变量对相应因变量的贡献率,使研究者能够对拟合模型中每一个自变量的影响程度进行详细的分析。
模型应用:最后,研究者可以利用一元线性回归模型进行应用,以实现实际问题的求解以及数据挖掘等功能。
例如我们可以使用这一模型来预测某一物品价格及销量、研究公司收益及投资、检测影响某一地区经济发展的因素等。
综上所述,一元线性回归是一种利用单变量因变量之间存在着线性关系来拟合出回归系数的回归分析方法,它可以应用于许多不同的问题,是一种非常实用的有效的统计分析方法。
《计量经济学》案例:用回归模型预测木材剩余物(一元线性回归)

案例:用回归模型预测木材剩余物(一元线性回归)伊春林区位于黑龙江省东北部。
全区有森林面积2189732公顷,木材蓄积量为23246.02万m 3。
森林覆盖率为62.5%,是我国主要的木材工业基地之一。
1999年伊春林区木材采伐量为532万m 3。
按此速度44年之后,1999年的蓄积量将被采伐一空。
所以目前亟待调整木材采伐规划与方式,保护森林生态环境。
为缓解森林资源危机,并解决部分职工就业问题,除了做好木材的深加工外,还要充分利用木材剩余物生产林业产品,如纸浆、纸袋、纸板等。
因此预测林区的年木材剩余物是安排木材剩余物加工生产的一个关键环节。
下面,利用简单线性回归模型预测林区每年的木材剩余物。
显然引起木材剩余物变化的关键因素是年木材采伐量。
给出伊春林区16个林业局1999年木材剩余物和年木材采伐量数据如表2.1。
散点图见图2.14。
观测点近似服从线性关系。
建立一元线性回归模型如下:y t = β0 + β1 x t + u t表2.1 年剩余物y t 和年木材采伐量x t 数据林业局名 年木材剩余物y t (万m 3) 年木材采伐量x t(万m 3) 乌伊岭 26.1361.4 东风 23.49 48.3 新青 21.97 51.8 红星 11.53 35.9 五营 7.18 17.8 上甘岭 6.80 17.0 友好 18.43 55.0 翠峦 11.69 32.7 乌马河 6.80 17.0 美溪 9.69 27.3 大丰 7.99 21.5 南岔 12.15 35.5 带岭 6.80 17.0 朗乡 17.20 50.0 桃山 9.50 30.0 双丰 5.52 13.8 合计202.87532.005101520253010203040506070yx图2.14 年剩余物y t 和年木材采伐量x t 散点图图2.15 Eviews 输出结果Eviews 估计结果见图2.15。
建立Eviews 数据文件的方法见附录1。
计量经济学 第二章 一元线性回归模型范文
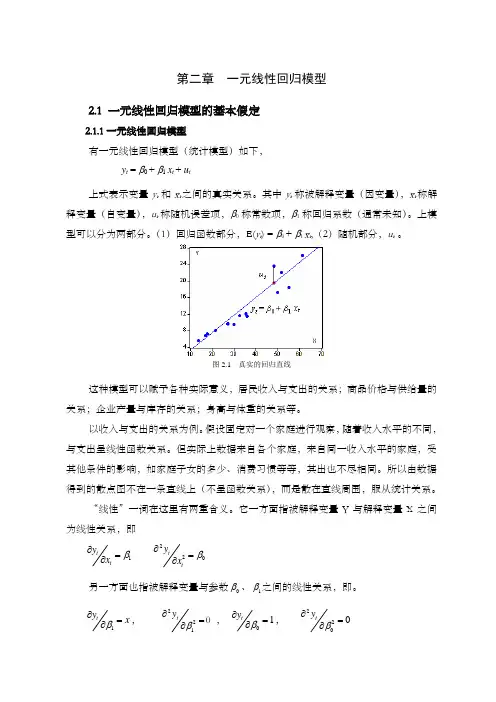
第二章 一元线性回归模型2.1 一元线性回归模型的基本假定2.1.1一元线性回归模型有一元线性回归模型(统计模型)如下, y t = β0 + β1 x t + u t上式表示变量y t 和x t 之间的真实关系。
其中y t 称被解释变量(因变量),x t 称解释变量(自变量),u t 称随机误差项,β0称常数项,β1称回归系数(通常未知)。
上模型可以分为两部分。
(1)回归函数部分,E(y t ) = β0 + β1 x t ,(2)随机部分,u t 。
图2.1 真实的回归直线这种模型可以赋予各种实际意义,居民收入与支出的关系;商品价格与供给量的关系;企业产量与库存的关系;身高与体重的关系等。
以收入与支出的关系为例。
假设固定对一个家庭进行观察,随着收入水平的不同,与支出呈线性函数关系。
但实际上数据来自各个家庭,来自同一收入水平的家庭,受其他条件的影响,如家庭子女的多少、消费习惯等等,其出也不尽相同。
所以由数据得到的散点图不在一条直线上(不呈函数关系),而是散在直线周围,服从统计关系。
“线性”一词在这里有两重含义。
它一方面指被解释变量Y 与解释变量X 之间为线性关系,即1tty x β∂=∂220tt y x β∂=∂另一方面也指被解释变量与参数0β、1β之间的线性关系,即。
1ty x β∂=∂,221ty β∂=∂0 ,1ty β∂=∂,2200ty β∂=∂2.1.2 随机误差项的性质随机误差项u t 中可能包括家庭人口数不同,消费习惯不同,不同地域的消费指数不同,不同家庭的外来收入不同等因素。
所以在经济问题上“控制其他因素不变”是不可能的。
随机误差项u t 正是计量模型与其它模型的区别所在,也是其优势所在,今后咱们的很多内容,都是围绕随机误差项u t 进行了。
回归模型的随机误差项中一般包括如下几项内容: (1)非重要解释变量的省略, (2)数学模型形式欠妥, (3)测量误差等,(4)随机误差(自然灾害、经济危机、人的偶然行为等)。
一元线性回归模型典型例题分析

第二章 一元线性回归模型典型例题分析例1、令kids 表示一名妇女生育孩子的数目,educ 表示该妇女接受过教育的年数.生育率对教育年数的简单回归模型为μββ++=educ kids 10(1)随机扰动项μ包含什么样的因素?它们可能与教育水平相关吗?(2)上述简单回归分析能够揭示教育对生育率在其他条件不变下的影响吗?请解释.例2.已知回归模型μβα++=N E ,式中E 为某类公司一名新员工的起始薪金(元),N 为所受教育水平(年).随机扰动项μ的分布未知,其他所有假设都满足。
如果被解释变量新员工起始薪金的计量单位由元改为100元,估计的截距项与斜率项有无变化?如果解释变量所受教育水平的度量单位由年改为月,估计的截距项与斜率项有无变化?例3.对于人均存款与人均收入之间的关系式t t t Y S μβα++=使用美国36年的年度数据得如下估计模型,括号内为标准差:)011.0()105.151(067.0105.384ˆtt Y S +=2R =0.538 023.199ˆ=σ(1)β的经济解释是什么?(2)α和β的符号是什么?为什么?实际的符号与你的直觉一致吗?如果有冲突的话,你可以给出可能的原因吗?(3)对于拟合优度你有什么看法吗? (4)检验统计值?例4.下列方程哪些是正确的?哪些是错误的?为什么?⑴ y x t n t t =+=αβ12,,, ⑵ y x t n t t t =++=αβμ12,,,⑶ y x t n t t t=++= ,,,αβμ12⑷ ,,,y x t n t t t =++=αβμ12 ⑸ y x t n t t =+= ,,,αβ12 ⑹ ,,,y x t n t t =+=αβ12⑺ y x t n t t t =++= ,,,αβμ12 ⑻ ,,,y x t n t tt =++=αβμ12其中带“^”者表示“估计值”.例5.对于过原点回归模型i i i u X Y +=1β ,试证明∑=∧221)(iu XVar σβ例6、对没有截距项的一元回归模型i i i X Y μβ+=1称之为过原点回归(regression through the origin )。
计量经济学第二章 一元线性回归模型(1)(肖)
10
2.在经济学中,经济学家要研究个人
消费支出与个人可支配收入的依赖关系。
这种分析有助于估计边际消费倾向,就是
可支配收入每增加一元引起消费支出的平
均变化。
11
3.在企业中,我们很想知道人们对企
业产品的需求与广告费开支的关系。这种
研究有助于估计出相对于广告费支出的需
求弹性,即广告费支出每变化百分之一的
(2.3)
想想:结合表2.1的资料 ,怎样理解式(2.3)
变量Y 的原因, 给定变量X 的值也不能具
体确定变量Y的值, 而只能确定变量Y 的
统计特征,通常称变量X 与Y 之间的这种
关系为统计关系。
16
例如,企业总产出Y 与企业的资本投入
K 、劳动力投入L 之间的关系就是统计关 系。虽然资本K 和劳动力L 是影响产出Y 的两大核心要素,但是给定K 、L 的值并 不能确定产出Y 的值。因为,总产出Y 除 了受资本投入K、劳动力投入L 的影响外
在进入正式的回归理论之前,先斟酌一下变量y与变 量x可以互换的不同名称、术语。 Y 因变量 X 自变量
被解释变量 响应变量
被预测变量
解释变量 控制变量
预测变量
回归子
归回元
22
第二节
一、引例
一元线性回归模型
假定我们要研究一个局部区域的居 民消费问题,该区域共有80户家庭组成 ,将这80户家庭视为一个统计总体。
32
函数f (Xi)采取什么函数形式,是一个
需要解决的重要问题。在实际经济系统
中,我们不会得到总体的全部数据,因
而就无法据已知数据确定总体回归函数 的函数形式。同时,对总体回归函数的 形式只能据经济理论与经验去推断。
一元线性回归案例分析
ˆ 0 135 .31 是样本回归方程的截距,它表示不受可支 配收入的影响的自发消费行为。
参数估计量的符号和大小,பைடு நூலகம்符合经济理论及南通市的 实际情况。
第三步 评价模型——统计检验
r2=0.98,说明总离差平方和的98%被样本回归直线解 释,仅有2%违背解释。因此,样本回归直线对样本点 的拟合优度是很好的。 F=786.13﹥F0.05(1,17)=4.45,总体线性显著。 给出显著水平α=0.05,查自由度ν =19-2=17的t分布, 得临界值t0.025(17)=2.11, t0=5.47﹥t0.025(17), t1=28.04 ﹥t0.025(17), 故回归系数均显著不为零,回归模型中应包含常数项, X对Y有显著影响。
从以上的评价可以看出,此模型是比较好的
第四步 预测应用
1.
2.
假如给出1999年、2000年南通的人均可支 配收入(1980年不变价格)分别为 X99=1763元,X00=1863元,求1999年、 2000年人均消费性支出预测值? 假如2001——2004年的人均可支配收入未 知,你能预测2001——2004年的人均消费 性支出吗?如何预测?
一元线性回归案例分析
南通市消费函数实证研究
南通市年人均可支配收入为x,研究它与年人均消费性支 出Y之间的关系。已知1980-1998年样本观测值如下:
年份 Y X 年份 Y X 年份 Y X
80 ¥474.7 ¥526.9 87 ¥798.6 ¥884.4 93 81 ¥479.9 ¥532.7 88 ¥815.4 ¥847.3 94
计量经济学实验二-一元线性回归模型的估计、检验和预测
目录一、加载工作文件 (7)二、选择方程 (7)1.作散点图 (7)2.进行因果关系检验 (9)三、一元线性回归 (10)四、经济检验 (12)五、统计检验 (13)六、回归结果的报告 (15)七、得到解释变量的值 (15)八、预测应变量的值 (17)实验二一元线形回归模型的估计、检验和预测实验目的:掌握一元线性回归模型的估计、检验和预测方法。
实验要求:选择方程进行一元线性回归,进行经济、拟合优度、参数显著性和方程显著性等检验,预测解释变量和应变量。
实验原理:普通最小二乘法,拟合优度的判定系数R2检验和参数显著性t检验等,计量经济学预测原理。
实验步骤:已知广东省宏观经济部分数据如表2-1所示,要根据这些数据研究和分析广东省宏观经济,建立宏观计量经济模型,从而进行经济预测、经济分析和政策评价。
实验二~实验十二主要都是用这些数据来完成一系列工作。
表2-1 广东省宏观经济数据续上表续上表一、加载工作文件广东省宏观经济数据已经制成工作文件存在盘中,命名为GD01.WF1,进入EViews后选择File/Open打开GD01.WF1。
二、选择方程根据广东数据(GD01.WF1)选择收入法国国内生产总值(GDPS)、财政收入(CS)、财政支出(CZ)和社会消费品零售额(SLC),分别把①CS作为应变量,GDPS作为解释变量;②CZ作为应变量,CS作为解释变量;③SLC作为应变量,GDPS作为解释变量进行一元线性回归分析。
1.作散点图从三个散点图(图2-1~图2~3)可以看出,三对变量都呈现线性关系。
图2-1 图2-2图2-3 2.进行因果关系检验从三个因果关系检验可以看出,GDPS是CS的因;CS不是CZ 的因;GDPS不是SLC的因。
但根据理论CS是CZ的因,GDPS是SLC的因,可能是由于指标设置问题。
所以还是把CS作为应变量,GDPS作为解释变量;CZ作为应变量,CS作为解释变量;SLC作为应变量,GDPD作为解释变量进行一元线性回归分析。
一元线性回归模型案例分析
一元线性回归模型案例分析一、研究的目的要求居民消费在社会经济的持续发展中有着重要的作用。
居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。
改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。
但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。
例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。
为了研究全国居民消费水平及其变动的原因,需要作具体的分析。
影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。
二、模型设定我们研究的对象是各地区居民消费的差异。
居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。
而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。
所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。
因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。
因此建立的是2002年截面数据模型。
影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
案例分析1— 一元回归模型实例分析
依据1996-2005年《中国统计年鉴》提供的资料,经过整理,获得以下农村居民人均消费支出和人均纯收入的数据如表2-5:
表2-5 农村居民1995-2004人均消费支出和人均纯收入数据资料 单位:元 年度 1995
1996
1997
1998
1999
2000
2001
2002
2003
2004
人均纯收入
1577.7 1926.1 2090.1 2161.1 2210.3 2253.4 2366.4 2475.6 2622.2 2936.4
人均消
费支出
1310.4 1572.1 1617.2 1590.3 1577.4 1670.1 1741.1 1834.3 1943.3 2184.7
一、建立模型
以农村居民人均纯收入为解释变量X ,农村居民人均消费支出为被解释变量Y ,分析Y 随X 的变化而变化的因果关系。
考察样本数据的分布并结合有关经济理论,建立一元线性回归模型如下:
Y i =β0+β1X i +μi
根据表2-5编制计算各参数的基础数据计算表。
求得:
082
.1704035.2262==Y X
∑∑∑∑====37
52432495.1986.788859011.516634423.1264471222i
i i i i
X y x y x 根据以上基础数据求得:
623865.0423
.126447986
.788859ˆ21
==
=∑∑i
i
i x
y
x β
8775.292035.2262623865.0082.1704ˆˆ1
0=⨯-=-=X Y ββ 样本回归函数为:
i
i X Y 623865.08775.292ˆ+= 上式表明,中国农村居民家庭人均可支配收入若是增加100元,居民们将会拿出其中的62.39元用于消费。
二、模型检验
1.拟合优度检验
952594.0011.516634423.1264471986.788859))(()(
2
2
222
=⨯==
∑∑∑i
i
i i y
x y x r
2.t 检验
525164
.3061 2
10423
.12644710.623865011.166345 2
ˆˆ222122=-⨯-=
--=
∑∑n x y i
i
βσ
049206.0423
.1264471525164
.3061ˆ)ˆ()ˆ(2
21
1==
==∑i
e x
Var S σ
ββ
6717
.112525164.3061423
.126447110137
.52432495ˆ)ˆ()ˆ(22
20
0=⨯===∑∑σββi
i e x
n X Var S 在显著性水平α=0.05,n-2=8时,查t 分布表,得到:
306.2)2(2
=-n t α
提出假设,原假设H 0:β1=0,备择假设H 1:β1≠0
67864.12049206
.0623865.0)ˆ(ˆ)ˆ(111==-=ββββe S t
)2(67864.12)ˆ(2
1->=n t t α
β,差异显著,拒绝β1=0的假设。
3. F 检验
提出原假设H 0:β1=0,备择假设H 1:β1≠0
在显著性水平α=0.05,n-2=8时,查F 分布表,得到: F (1,8)=5.32。
7505.160525164.30618097.4921412
1ˆ2
221==-=
∑∑n e x F i i
β
160.7505>5.32,即F > F (1,8),差异显著,拒绝β1=0的假设。
三、预测
当农村居民家庭人均纯收入增长到3500元时,对农村居民人均消费支出预测如下:
)(405.24763500623865.08775.292ˆ0
元=⨯+=Y
13257219
.84 423.1264471)035.22623500(1011525164.3061 )(11ˆ)(11ˆ)(S 2
22022200e =⎪⎪⎭
⎫ ⎝⎛-++⨯=⎪⎪⎭
⎫ ⎝⎛-++=-++=∑∑i i x X X n x X X n e σσ
在显著性水平α=0.05,n -2=8时, 025.0t =2.306 从而
)(S ˆ0
e 2
0e t Y α-=2476.405-2.306⨯84.13257219=2282.40(元) )(S ˆ0
e 2
0e t Y α+=2476.405+2.306⨯84.13257219=2670.41(元) []%9541.267040.22820=≤≤Y P
当农村居民家庭人均纯收入增长到3500元时,,农村居民人均消费支出在2282.40元至2670.41元之间的概率为95%。
四、利用计算机进行分析的步骤
以上分析内容可以借助计算机完成,下面以EViews3.0软件为例,介绍其分析过程。
1.设定工作范围
打开EViews ,按照以下步骤设定工作范围:
File →New →Workfile →Workfile Range →Annual →Start data(1995)→End data(2004)(图2-5、图2-6)→OK
图2-5 Workfile Range 对话框
图2-6 Workfile 工作状态图
2.输入变量
在Workfile工作状态下输入变量X,Y
Objects→New Object→Type of Object(series)→Name for Object(X)(图2-7、图2-8)→OK。
同理,可输入变量Y。
图2-7输入变量X状态图
图2-8 Workfile工作状态图
3.输入样本数据
在Workfile工作状态下选中X、Y,右击鼠标,Open→as Group→Edit,输入数据(见图2-9)。
图2-9 Edit工作状态图
4.输入方程式
在Workfile工作状态下,选中Y、X,右击鼠标,Open→as Equation→Equation Specification→(Y C X)(图2-10)→OK,输出回归分析结果(见图2-11)。
图2-10 输入Y C X工作状态图
图2-11 回归分析表
输出结果的解释:
Variable 解释变量
Coefficient 解释变量的系数 Std.Error 标准差
t-Statistic t-检验值
Prob. t-检验的相伴概率 R-squared 样本决定系数
Adjusted R-squared 调整后的样本决定系数
S.E.regression 回归标准差
Sum squared resid 残差平方和 Log likelihood 对数似然比
Durbin-Watson stat D-W 统计量
Mean dependent var 被解释变量的均值 S.D.dependent var 被解释变量的标准差 Akaike info criterion 赤池信息量 Schwarz criterion 施瓦兹信息量 F-statistic F 统计量
Prob(F-statistic) F 统计量的相伴概率 由图2-11可以获得以下信息:
952594
.0623865.0ˆ8769.292ˆ210===r ββ
是β0, β1回归系数的估计量值,r 2是在双变量情况下,样本的可决系数
67889.12)ˆ( 599413.2)ˆ( 049205.0)ˆ(6704.112)ˆ(1
1
====β
ββ
βt t S S e
e
)ˆ(),ˆ(10ββe e S S 是10ˆˆββ,估计量的标准差,)ˆ(),ˆ(10ββt t 是1
0ˆˆββ,估计量的t 统计量。
F =160.7542是F 检验统计量的值 样本回归函数为:
i
i X Y 623865.08769.292ˆ+= 样本回归函数(Sample Regression Function ,SRT )
5.预测
(1)扩展工作范围
在Workfile工作状态下,Procs→Change Workfile Range→End data(2005)→OK
再选择Sample(1995 2005)( 图2-12) →OK
图2-12 工作范围图
(2)输入解释变量值
在Workfile工作状态下,X→Edit →(3500)。
(3)预测
在图2-11 Equation工作状态下,选择For ecast→OK(见图2-13),得到预测结果(见图2-14)
图2-13 设定预测状态图
在Workfile工作状态下,显示YF,可得到点预测值(见图2-15)
图2-15 预测值输出图
根据模型预测结果,当中国农村居民家庭人均纯收入达到3500元时,每个人将会拿出
2476.41元用于消费。