第四章 SPSS数据的预处理(副)
SPSS数据的预处理

SPSS数据的预处理SPSS是研究社会科学数据和其他统计分析领域中常用的软件之一。
在进行分析之前,我们需要进行预处理来准备我们的数据集。
数据的清理在进行数据分析之前,我们需要了解数据集中的每个变量并确保它们是正确的,并且符合我们的需要。
在数据清理过程中,我们需要进行以下操作:处理缺失值在数据集中,某些变量可能会缺乏部分值,我们需要进行缺失值处理,以便于数据的分析和处理。
填补缺失值的方法主要有以下几种:1.删除缺失值:删除含有缺失值的行或者列,但是需要注意删除的行和列如果数据量较大,可能会对后续的分析产生影响。
2.插补法:使用其他观测下的变量的平均值、中位数,众数等来填补缺失值。
在SPSS中,我们可以通过Transform->Replace Missing Values来进行缺失值的填补。
其中的缺失值可以设置被替换的数值类型,如我们可以用平均数代替缺失值,也可以用最近邻样本的替换策略等。
处理异常值当数据集中存在异常值时,需要使用删除或替换方法对其进行去除或更正。
异常值是指由于测量、数据输入或其他原因导致的不合理的数据值。
对于极端的异常数据值,删除数据可能是最好的解决方案。
在SPSS中,我们可以使用Analyze->Descriptive Statistics->Explore来寻找异常值,它会检查所有数据和变量,并给我们提供总体统计、中心趋势度量和分布度量等描述。
数据的转换在进行分析之前,我们还需要对数据进行转换来满足分析的要求。
最常见的转换包括下列几种:变量归一化某些变量或变量的值可能存在不同的测量单位,为了能够在同等条件下进行比较,需要对数据进行标准化处理。
在SPSS中,我们可以使用Transform->Recode Into Same Variables来进行数据的归一化操作。
例如,我们可以将数值变量转换为区间变量或类别变量。
变量离散化连续型数据为了进行分析常需要将其转换为类别变量。
SPSS基本操作与数据预处理

数据文件建立 数据文件的建立一般要经过四个步骤: 1.打开新的Data Editor窗口 (操作:File→ New →Data)
术语表
2.在Variable View界面下定义变量
3.在Data View界面下输入各类型数据 4.存储数据文件
(操作:File → Save)
术语表
变量
对话框
数据选择
1. 根据逻辑关系表达式选择数据
2.随机选取数据 3.在给定范围内选择数据
4.用过滤器变量选择数据
对话框
数据转置
1. 在主菜单中单击Data菜单选项,打开该菜单条;
2.单击Transpose选项,打开对话框; 3.在左边窗口选定变量名,再用箭头按钮, 将变量转到Transpose窗口中; 4. 单击“OK”按钮,确认后,生成新的 数据文件。
编辑窗-Variable View
结果输出窗口
SPSS Viewer是SPSS大多数过程的运行结果的显示窗口。 该窗口分两部分:大纲输出区和文本输出区。
Syntax Editor
Chart Editor
文件
1. 数据文件的打开
2. 数据文件的建立 3. 数据文件的调用
打开数据文件 案例一(Case01):休闲调查 数据库说明:883份对城市居民休假状 态的调查问卷 学习在SPSS中输入各种类型的数据类型 Nominal(名义变量) Ordinal(顺序变量) Scale(尺度变量)
对话框
数据汇总
1. 在主菜单中单击Data菜单选项,打开打开对话框;
3.在左边窗口选定变量名,用上方箭头按 钮,将变量转到Break窗口中; 4.在左边窗口选定变量名,用下方箭头按钮, 将变量转到Aggregate Variables窗口中;
SPSS-数据的预处理课件

SPSS 数据的预处理
4/1/2020
SPSS-数据的预处理课件
1
数据文件建立完成之后,为了方便统计分析,需要对数 据进行初步的处理,如对数据进行排序,将一列数据扩大一 个倍数,多列数据的求和等等。
1 数据的排序 1) 数据排序的目的
数据集中的数据是按照录入的先后排列的,并没有规律
2) 数据排序的规则
a) 排序分为升序与降序,可以同时对数据集中的多个变 量进行排序。
b) 排序的规则是:按第一个变量排序,第一个变量相同 时按第二个变量排序,余此类推。
c) 排序后是个案位置的改变,未排序的变量数据随排序 变量的位置同时改变。
3) 数据排序的操作
4/1/2020
SPSS-数据的预处理课件
可言,不便于数据的分析。数据排序有什么好处呢?
a) 经过排序的数据,有助于了解数据的取值状况、缺失
值的数量等。
b) 经过数据的排序,方便的找出了变量的最大、最小值,
计算出数据的全距,了解数据的离散程度。
4/1/2020
SPSS-数据的预处理课件
2
c) 通过排序,可以快速发现异常值,以便及时对其进行 处理。
择默认数据类型。见图3-3。
3) 算术表达式及运算符的定义
a) 算术表达式(Numeric Expression) 定义:将常数、变
量用算术运算符和函数组合起来的式子。
b) 算术表达式的元素。变量可以从左侧的变量列表中选
择;数字、运算符号可以在软键盘中选择;函数可以从右侧
选择,这些也都可以直接用键盘输入。
c) 在这里可以输入筛选条件。需要说明的是,每次只能
编辑一个筛选条件,不能同时编辑多个筛选条件。
SPSS之数据预处理

三、分析前数据预处理
本章主要介绍数据的主要预处 理过程,主要包括数据的排序、 理过程,主要包括数据的排序、转 拆分、合并、选择、加权、 置、拆分、合并、选择、加权、和 转换。 转换。
数据预处理
1.数据排序(Sort Cases) 2.数据转置(Transpose) 3.文件拆分(Split File) 4.文件合并(Merge File) 5.选择(Select Cases) 6.加权(Weight Cases) 7.转换(Count,Recode等)
数据文件合并
个案合并( 1. 个案合并(Add Cases )
演示:商店 商店2.sav 演示:商店1.sav ,商店 商店
具体的解释可以点击help 具体的解释可以点击
2.变量合并(Add Variable) 2.变量合并(Add Variable) 变量合并 两种情况: 两种情况: 含有多个共同变量的一般合并; 含有多个共同变量的一般合并; 通过一个关键变量的合并- 通过一个关键变量的合并-排序 演示:商店1.sav ,商店 商店2.sav 演示:商店1.sav ,商店2.sav
Variables栏中放入将要进行转置的变量名 栏中放入将要进行转置的变量名 Name variable:变量命名栏。该变量的 :变量命名栏。 数据将作为转置后的变量名。 数据将作为转置后的变量名。 如不是将所有数据进行转置, 如不是将所有数据进行转置,则会有提示 为参加转置的数据将丢失。 为参加转置的数据将丢失。
对话框
6、数据加权 、
数据加权: 数据加权:[Data] →[Weight Cases]; [Weight Cases]; 加权是一种通过人为方法来调节样本或数 据大小的方法。 各门课程的学分数不同, 据大小的方法。如:各门课程的学分数不同, 不能算简单的平均, 不能算简单的平均,而要根据不同的学分进 行加权处理。 行加权处理。 注意: Cases后数据编辑窗没有变 注意:Weight Cases后数据编辑窗没有变 但在右下角显示“ on”字样 字样。 化,但在右下角显示就是利用原有数据, 数据转换,就是利用原有数据,通 过某种函数或数值之间的联系, 过某种函数或数值之间的联系,转换关 系来生成新数据, 系来生成新数据,为达到特定的统计目 的作准备。 的作准备。 如:将汽车的耗油量由每英里耗 油量为多少加仑转变为每公里多少公 升。
spss数据的预处理基本统计分析心得感悟

spss数据的预处理基本统计分析心得感悟
在进行SPSS数据的预处理基本统计分析时,我有以下心得感悟:
1. 对数据进行清洗和筛选
在进行数据分析之前,需要对数据进行清洗和筛选,去除无用的数据和异常值,提高数据的准确性和可靠性。
2. 理解数据的分布情况
在进行基本统计分析时,需要理解数据的分布情况,包括数据的平均值、方差、标准差、偏度和峰度等统计指标。
这有助于了解数据是否符合正态分布,数据的离散程度,以及数据的分布形态。
3. 分析变量之间的关系
分析变量之间的关系可以使用相关分析、回归分析、t检验等方法。
通过分析变量之间的关系,可以了解不同变量之间的相关性,并找出影响变量的因素。
4. 对数据进行可视化处理
可视化处理是一种直观的分析方法,可以使用直方图、散点图等图表来表示数据的分布情况、变量之间的关系和趋势。
通过可视化处理可以更加直观地了解数据的特征和规律。
综上所述,进行SPSS数据的预处理基本统计分析需要仔细分析数据的特征,了解变量之间的关系,并运用统计分析和可视化处理等方法,以提高分析结果的精度和有效性。
spss数据文件的预处理实验报告

spss数据文件的预处理实验报告spss实习报告一、教学实验时间与地点:时间:年 1月9日至年1月13日地点:二、实训目的:SPSS统计数据软件教学实验课就是在我们在自学《统计学》理论课程之后所开办的一门课堂教学课。
通过教学实验,并使学生在掌控了理论知识的基础上,能够具体内容的运用所学的统计数据方法展开统计分析并化解实际问题,努力做到理论联系实际并掌控统计数据软件SPSS的采用方法。
通过对SPSS软件的自学和运用,增进对统计学科学知识的介绍和运用及对课程内容的认知,培育学生的自我非政府能力和动手能力。
三、实训的内容与要求教学实验的内容包含两个方面:个人教学实验和小组教学实验。
1、个人实训:(1)个人教学实验内容学习SPSS软件文件的建立、管理以及统计数据的录入;学习结合统计数据进行统计分组并会制作统计图和统计表;学习结合统计数据进行初步统计描述分析、计算相关指标;学习结合统计数据运用统计分析软件对一元线性回归模型进行分析并能解释输出结果。
每天记录实训日志、实训结束后撰写一篇实训报告。
(2)小组教学实验任务小组通过查找自己感兴趣的研究资料并经过讨论确定实训的题目和方向,自己动手实训变量,选择反映社会经济现象发展趋势的数据作为该实训的基础内容,能应用SPSS软件对所选题目进行统计分析并完成专题分析报告。
2、教学实验建议:围绕实训课题和统计方法的要求,有目的、有步骤的进行调查研究,获取统计资料,并加以整理;对所收集与整理的资料,运用选好的统计数据方法加以分析,建议资料整理、排序与叙述均在计算机上操作方式顺利完成;实训报告以书面形式完成,字数不少于字,要求文字分析、数据计算与运用、统计图或统计表相结合,图文并茂。
四、教学实验的过程:经过这几天的实训,我基本明白了SPSS软件的基本操作流程,也掌握了如何利用SPSS处理数据并绘制图表;学会了如何计算定基发展速度、环比发展速度等动态数列的计算;了解了如何进行频数分析、描述分析、探索分析以及作图分析;其中我最大的收获是学会了如何运用SPSS软件对变量进行相关分析、回归分析和计算平均值、T检验和假设性检验。
第四章_SPSS数据的预处理(副)

3.3.2 数据选取的基本操作
(1)选择菜单Data—Select cases (2)根据分析需要选择数据选取方法 (3)Unselected cases are指定对未选中 个案的处理方式
•
•
Filtered表示在未被选中的个案号码上打一 个“/”标记; Deleted表示将未被选中的个案从数据编辑 窗口中删除。
3.1.1数据排序的作用
•
•
•
数据排序便于数据的浏览,有助于了解数据 的取值状况、缺失值数量的多少等; 通过数据排序能够快捷的找到数据的最大值 和最小值,进而可以计算出数据的全距,初 步把握和比较数据的离散程度; 通过数据排序能够快捷地发现数据的异常值, 为进一步明确它们是否会对分析产生重要影 响提供帮助。
(4)如果希望对符合一定条件的个案进行变量计算,则 单击If按钮,出现下面的窗口,选择Include if case satisfies condition选项,然后输入条件表达式。对 不满足条件的个案,将不进行变量值计算,对新变量 取值为系统缺失值。
3.2.6 变量计算的应用举例
利用数据1,计算当数据为男生数据时, 新变量总分3为总分1和2的和。
(1)选取全部数据(All cases) (2)按指定条件选取( If condition is satisfied ) SPSS要求用户以条件表达式给出数据选 取的条件,SPSS将自动对数据编辑窗口中的 所有个案进行条件判断。那些满足条件的个案, 即条件判断为真的个案将被自动选取出来,而 那些条件判断为假的个案则不被选中。
Select Cases对话框
3.3.4 数据选取的应用举例
利用数据1: (1)如果只希望分析男性被试的情况,可以通 过数据选择功能采用指定条件的抽样方法进行 抽样; (2)如果只希望对其中的70%的数据进行分析, 可通过数据选择功能采用随机抽样中的近似抽 样方法进行抽样。
第4章数据预处理
第4章数据预处理4数据预处理数据⽂件建⽴好之后,还需要对数据进⾏必要的预处理,因为不同的统计分析⽅法对数据结构的要求不同。
SPSS提供了强⼤的数据预处理能⼒——主菜单【转换】,可从变量和个案⾓度对数据进⾏全⾯的处理。
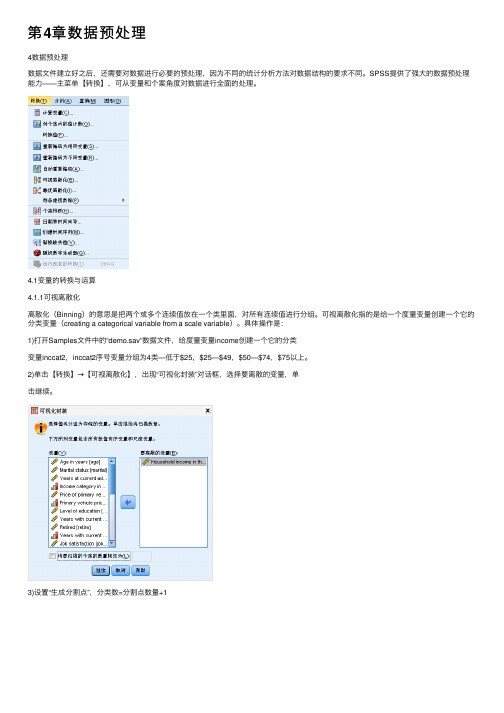
4.1变量的转换与运算4.1.1可视离散化离散化(Binning)的意思是把两个或多个连续值放在⼀个类⾥⾯,对所有连续值进⾏分组。
可视离散化指的是给⼀个度量变量创建⼀个它的分类变量(creating a categorical variable from a scale variable)。
具体操作是:1)打开Samples⽂件中的“demo.sav”数据⽂件,给度量变量income创建⼀个它的分类变量inccat2,inccat2序号变量分组为4类—低于$25,$25—$49,$50—$74,$75以上。
2)单击【转换】→【可视离散化】,出现“可视化封装”对话框,选择要离散的变量,单击继续。
3)设置“⽣成分割点”,分类数=分割点数量+14)点击“⽣成标签”,表格如图所⽰数据视图窗⼝的最后⼀列为income的分类变量inccat2。
4.1.2根据已存在的变量建⽴新变量(变量的计算)有时候,⼀个或两个连续变量都不符合正态分布,但通过它或他们计算(转换)出来的新的变量可能就接近正态分布。
计算新变量(computing new variables)的具体操作是:1)打开数据⽂件“demo.sav”,⽂件中有受试者“现在的年龄”和“已参加⼯作的年数”这两个变量,但却没有他们“开始⼯作的年龄”这个变量,以简单地计算现存的两个变量的差,把这两变量的差值作为⼀个新的变量为例。
营业收⼊-利润总额,营运成本2)单击【转换】→【计算变量】,在打开的“计算变量”对话框中设定“⽬标变量”,在“⽬标变量”对话框中输⼊⽬标变量的名称,单击“类型与标签”按钮,在弹出的“计算变量:类型和标签”对话框中设置新⽣成变量的变量类型与标签。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(4)如果希望对符合一定条件的个案进行变量计算,则 单击If按钮,出现下面的窗口,选择Include if case satisfies condition选项,然后输入条件表达式。对 不满足条件的个案,将不进行变量值计算,对新变量 取值为系统缺失值。
3.2.6 变量计算的应用举例
利用数据1,计算当数据为男生数据时, 新变量总分3为总分1和2的和。
第三章 SPSS数据的预处理
为什么要进行数据的预处理
在数据文件建立之后,通常还需要对分 析的数据进行必要的预加工处理,这是 数据分析过程中必不可少的一个关键步 骤。 数据的预加工处理服务于数据分析和建 模,主要包括以下几个问题:
预处理的内容
数据的排序 变量计算 数据选取 数据分组 数据预处理的其他功能:转置、加权、 数据预处理的其他功能:转置、加权、数据 拆分等。 拆分等。
第二,精确抽样(Exactly) 精确抽样要求用户给出两个参数。第 一个参数是希望选取的个案数,第二个 参数是指定在前几个个案中选取。SPSS 自动在数据编辑窗口的前若干个个案中 随机精确地抽出相应个数的个案来。
(4)选取某一区域内的样本( Based on time or case range ),即选取数据编辑窗口中样 本号在指定范围内的所有个案,要求给出这个 范围的上、下界个案号码。这种抽样方法适用 这种抽样方法适用 于时间序列数据。 于时间序列数据。 (5)通过过滤变量选取样本( Use filter variable ),即依据过滤变量的取值进行样 本选取。要求指定一个变量作为过滤变量,变 量值为非0或非系统缺失值的个案将被选中。 这种方法通常用于排除包含系统缺失值的个案。 这种方法通常用于排除包含系统缺失值的个案。
(3)随机抽样( Random sample of cases ), 即对数据编辑窗口中的所有个案进行随机筛选,包 括如下两种方式: 第一,近似抽样(Approximately) 近似抽样要求用户给出一个百分比数值,SPSS 将按照这个比例自动从数据编辑窗口中随机抽取相 应百分比数目的个案。
注:由于SPSS在样本抽样方面的技术特点,抽取出的 个案总数不一定恰好精确地等于用户指定的百分比数目, 会有小的偏差,因而称为近似抽样。
说明: 说明:
(1)完成数据选取后,以后的SPSS分析操作 仅针对那些被选中的个案直到用户再次改变数 据的选取为止。 (2)采用指定条件选取和随机抽样方法进行 数据选取后,SPSS将在数据编辑窗口中自动生 成一个名为filter_$的新变量,取值为1或0。1 表示本个案被选中,0表示未被选中。该变量 是SPSS产生的中间变量,如果删除它则自动取 消样本抽样。
Select Cases对话框
3.3.4 数据选取的应用举例
利用数据1: (1)如果只希望分析男性被试的情况,可以通 过数据选择功能采用指定条件的抽样方法进行 抽样; (2)如果只希望对其中的70%的数据进行分析, 可通过数据选择功能采用随机抽样中的近似抽 样方法进行抽样。
3.4 数据分组
3.4.1 数据分组的方法 数据分组就是根据统计研究的需要,将数 据按照某种标准重新划分为不同的组别。在数 据分组的基础上进行的频数分析更能够概括和 体现数据的分布特征。 为适用于不同的统计分析需要,SPSS提供 了以下几种数据分组方法:
在组距式分组中涉及到了几个关键点: 在组距式分组中涉及到了几个关键点: 关键点 a.组距:区间的距离即为组距。 组距: 组距 区间的距离即为组距。 b.组数:组数的多少以分组后能恰当反映总体内部的分 组数: 组数 布特征和规律为好。 布特征和规律为好。 c.组距=(最大值 最小值) 组数。 c.组距=(最大值-最小值)÷组数。 组距=(最大值-最小值 d.根据组距各组的组距是否相等,又可以分为等距分组 根据组距各组的组距是否相等, 根据组距各组的组距是否相等 和不等距分组两种方式。 和不等距分组两种方式。 e.组限:组距两端的数值称为组限,每组的最大值称为 组限: 组限 组距两端的数值称为组限, 上限,用U(Upper limit)表示,每组的最小值称为下 上限, ( )表示, 限,用L(Lower limit)表示。 统计数据时,注意“上 ( )表示。 统计数据时,注意“ 组限不在内”法则。另外,极端组可采用开放式组距。 组限不在内”法则。另外,极端组可采用开放式组距。 f.组中值:每组上、下限之间的中点数值。即:组中值 组中值: 组中值= 组中值 每组上、下限之间的中点数值。 上限十下限) (上限十下限)÷2。 。
3.2.3 SPSS条件表达式 条件表达式
在变量计算中通常要求对不同的个案分 别按照不同的方法进行计算,于是就需 要通过一定的方式来指定个案; SPSS条件表达式是一个对条件进行判断 的式子。其结果有两种取值:如果判断 条件成立,则结果为真;如果判断条件 不成立,则结果为假。条件表达式包括 简单条件表达式和复合条件表达式 复合条件表达式。 简单条件表达式 复合条件表达式
3.2.5 变量计算的基本操作
(1)选择菜单Transform-Compute,弹出 - Compute Variable对话框如下:
(2)在Target框中输入存放计算结果的变量名。 该变量可以是一个新变量,也可以是已经存在 的变量。如果指定存放计算结果的变量为新变 量,SPSS会自动创建它;如果指定产生的变量 已经存在,SPSS会提问是否以计算结果覆盖原 有值。新的变量默认为数值型,用户可以根据 需要单击Type&Label按钮修改,还可以对新 变量加变量名标签。 (3)在Numeric Expression框给出SPSS算术 表达式。可以手工输入,也可以按窗口的按钮 以及函数下拉菜单输入。
SPSS变量计算是在原有数据的基础上,根据用户 给出的SPSS算术表达式以及函数,对所有个案或 满足条件的部分个案,计算产生一系列新变量。 (1)变量计算是针对所有个案(或指定的部 分个案)的,每个个案都有自己的计算结果。 (2)变量计算的结果应保存到一个指定变量 中,该变量的数据类型应与计算结果的数据类型 相一致。 在变量计算过程中涉及到几个概念:SPSS算 数表达式、SPSS条件表达式和SPSS函数。
在左边的源变量框 源变量框中 源变量框 选择排序变量进入Sort by框。如果选择2个以 上的变量,观测量的 排序结果与排序变量 在Sort by框中的顺序 有关。列于首位的为 第一排序变量。
在Sort Order 栏内选择排序 方式——升序 与降序
说明
1、数据排序是整行数据排序,而不是只对某列 变量排序; 2、多重排序中指定排序变量的次序很关键。先 指定的变量优先于后指定的变量。多重排序可 以在按某个变量值升序(或降序)排序的同时 再按其他变量值降序(或升序)排序; 3、数据排序后,原有数据的排序次序必然被打 乱。
(1)简单条件表达式 由关系运算符、常量、变量以及算术表达式 等组成的式子。其中关系运算符包括>、<、 、 、 =、~=(不等于)、>=、 不等于)、 =、<= =、~=(不等于)、 =、 =。(nl<35) (2)复合条件表达式 又称逻辑表达式,是由逻辑运算符号、圆括 号和简单条件表达式等组成的式子。其中,逻 辑运算符号包括&或AND(并且)、 或OR )、|或 或 (并且)、 或者)、~ )、~或 (或者)、~或NOT(非)。NOT的运算优先 ( 级最高,其次是AND,最低是OR。可以通过圆 括号改变运算的优先级。(nl<=35)and not (zc<3)
3.2.4 SPSS函数 函数
SPSS函数是事先编好并存储在SPSS软件中, 能够实现某些特定计算任务的一段计算机程 序。这些程序都有各自的名字称为函数名 函数名。 函数名 执行这些程序段得到的计算结果称为函数值 函数值。 函数值 函数书写的具体形式为:函数名(参数) 函数名( 函数名 参数)
其中,函数名是SPSS已经规定好的,参数 可以是常量(字符型常量应用引号括起来), 也可以是变量或算术表达式。参数可能是一个, 也可能是多个,各参数之间用逗号 逗号分隔。 逗号 SPSS函数大致可以分成八大类:算术函数、 算术函数、 算术函数 统计函数、分布函数、逻辑函数、字符串函数、 统计函数、分布函数、逻辑函数、字符串函数、 缺失值函数、日期函数和其他函数。 缺失值函数、日期函数和其他函数
3.3.2 数据选取的基本操作
(1)选择菜单Data—Select cases (2)根据分析需要选择数据选取方法 (3)Unselected cases are指定对未选中 个案的处理方式
•
•
Filtered表示在未被选中的个案号码上打一 个“/”标记; “ Deleted表示将未被选中的个案从数据编辑 窗口中删除。
组距式分组 组距式分组
在连续型变量或离散 型变量值较多的情况 下,可采用组距式分 组形式。 组形式。 组距式分组就是把全 部变量值划分为几个 区间, 区间,每一区间的变 量值作为一组。 量值作为一组。如右 表:
按日产零件数分组 (个) 50~60 ~ 60~70 ~ 70~80 ~ 80~90 ~ 90以上 以上 合计 工人数 (人)
3.1 数据的排序
SPSS的数据排序是将数据编辑窗口中的 数据按照某个或多个指定变量的变量值 升序或降序重新排列。这里的变量也称 为排序变量 排序变量。排序变量只有一个时,排 排序变量 序称为单值排序 单值排序。排序变量有多个时, 单值排序 排序称为多重排序 多重排序。多重排序中,第一 多重排序 个指定的排序变量称为主排序变量 主排序变量,其 主排序变量 他依次指定的变量分别称为第二排序变 第二排序变 第三排序变量等。 量、第三排序变量 第三排序变量
数据排序应用举例
利用数据1,通过数据排序功能分别找到 总分1和总分2的最大值和最小值
3.2 变量计算
数据的转换处理是在原有数据的基础上,计算 产生一些含有更丰富信息的新数据。例如根据 职工的基本工资、失业保险、奖金等 变量计算的目的