机器学习决策树 ID3算法的源代码
决策树之ID3算法
决策树之ID3算法⼀、决策树之ID3算法简述 1976年-1986年,J.R.Quinlan给出ID3算法原型并进⾏了总结,确定了决策树学习的理论。
这可以看做是决策树算法的起点。
1993,Quinlan将ID3算法改进成C4.5算法,称为机器学习的⼗⼤算法之⼀。
ID3算法的另⼀个分⽀是CART(Classification adn Regression Tree, 分类回归决策树),⽤于预测。
这样,决策树理论完全覆盖了机器学习中的分类和回归两个领域。
本⽂只做了ID3算法的回顾,所选数据的字段全部是有序多分类的分类变量。
C4.5和CART有时间另花篇幅进⾏学习总结。
本⽂需要有⼀定的pandas基础、了解递归函数。
1、ID3算法研究的核⼼思想是if-then,本质上是对数据进⾏分组操作。
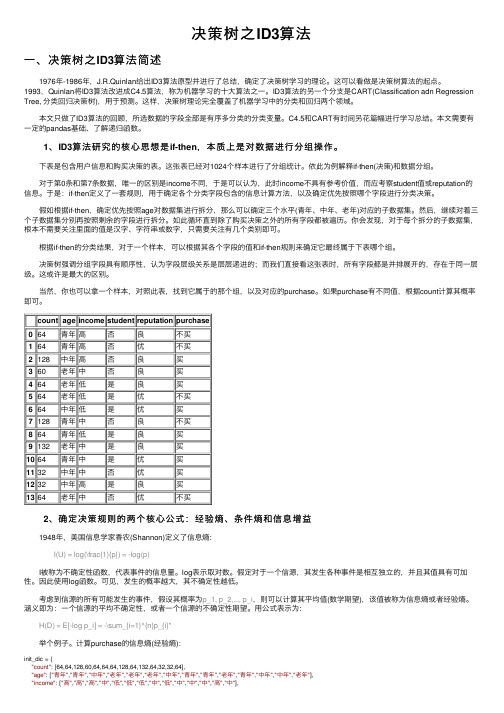
下表是包含⽤户信息和购买决策的表。
这张表已经对1024个样本进⾏了分组统计。
依此为例解释if-then(决策)和数据分组。
对于第0条和第7条数据,唯⼀的区别是income不同,于是可以认为,此时income不具有参考价值,⽽应考察student值或reputation的信息。
于是:if-then定义了⼀套规则,⽤于确定各个分类字段包含的信息计算⽅法,以及确定优先按照哪个字段进⾏分类决策。
假如根据if-then,确定优先按照age对数据集进⾏拆分,那么可以确定三个⽔平(青年、中年、⽼年)对应的⼦数据集。
然后,继续对着三个⼦数据集分别再按照剩余的字段进⾏拆分。
如此循环直到除了购买决策之外的所有字段都被遍历。
你会发现,对于每个拆分的⼦数据集,根本不需要关注⾥⾯的值是汉字、字符串或数字,只需要关注有⼏个类别即可。
根据if-then的分类结果,对于⼀个样本,可以根据其各个字段的值和if-then规则来确定它最终属于下表哪个组。
决策树强调分组字段具有顺序性,认为字段层级关系是层层递进的;⽽我们直接看这张表时,所有字段都是并排展开的,存在于同⼀层级。
id3决策树算法python程序

id3决策树算法python程序关于ID3决策树算法的Python程序。
第一步:了解ID3决策树算法ID3决策树算法是一种常用的机器学习算法,用于解决分类问题。
它基于信息论的概念,通过选择最佳的特征来构建决策树模型。
ID3算法的核心是计算信息增益,即通过选择最能区分不同类别的特征来构建决策树。
第二步:导入需要的Python库和数据集在编写ID3决策树算法的Python程序之前,我们需要导入一些必要的Python库和准备好相关的数据集。
在本例中,我们将使用pandas库来处理数据集,并使用sklearn库的train_test_split函数来将数据集拆分为训练集和测试集。
pythonimport pandas as pdfrom sklearn.model_selection import train_test_split# 读取数据集data = pd.read_csv('dataset.csv')# 将数据集拆分为特征和标签X = data.drop('Class', axis=1)y = data['Class']# 将数据集拆分为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) 第三步:实现ID3决策树算法的Python函数在此步骤中,我们将编写一个名为ID3DecisionTree的Python函数来实现ID3决策树算法。
该函数将递归地构建决策树,直到满足停止条件。
在每个递归步骤中,它将计算信息增益,并选择最佳特征作为当前节点的分裂依据。
pythonfrom math import log2from collections import Counterclass ID3DecisionTree:def __init__(self):self.tree = {}def calc_entropy(self, labels):label_counts = Counter(labels)entropy = 0for count in label_counts.values():p = count / len(labels)entropy -= p * log2(p)return entropydef calc_info_gain(self, data, labels, feature):feature_values = data[feature].unique()feature_entropy = 0for value in feature_values:subset_labels = labels[data[feature] == value]feature_entropy += len(subset_labels) / len(labels) * self.calc_entropy(subset_labels)return self.calc_entropy(labels) - feature_entropydef choose_best_feature(self, data, labels):best_info_gain = 0best_feature = Nonefor feature in data.columns:info_gain = self.calc_info_gain(data, labels, feature)if info_gain > best_info_gain:best_info_gain = info_gainbest_feature = featurereturn best_featuredef build_tree(self, data, labels):if len(set(labels)) == 1:return labels[0]elif len(data.columns) == 0:return Counter(labels).most_common(1)[0][0] else:best_feature = self.choose_best_feature(data, labels)sub_data = {}for value in data[best_feature].unique():subset = data[data[best_feature] == value].drop(best_feature, axis=1)sub_labels = labels[data[best_feature] == value]sub_data[value] = (subset, sub_labels)tree = {best_feature: {}}for value, (subset, sub_labels) in sub_data.items():tree[best_feature][value] = self.build_tree(subset, sub_labels)return treedef fit(self, data, labels):self.tree = self.build_tree(data, labels)def predict(self, data):predictions = []for _, row in data.iterrows():node = self.treewhile isinstance(node, dict):feature = list(node.keys())[0]value = row[feature]node = node[feature][value]predictions.append(node)return predictions第四步:使用ID3决策树模型进行训练和预测最后一步是使用我们实现的ID3DecisionTree类进行训练和预测。
id3算法代码

id3算法代码ID3算法简介ID3算法是一种常用的决策树算法,它通过对数据集的属性进行分析,选择最优属性作为节点,生成决策树模型。
ID3算法是基于信息熵的思想,通过计算每个属性对样本集合的信息增益来选择最优划分属性。
ID3算法步骤1. 计算数据集的熵首先需要计算数据集的熵,熵越大表示样本集合越混乱。
假设有n个类别,则数据集D的熵可以表示为:$$ Ent(D) = -\sum_{i=1}^{n}p_i\log_2p_i $$其中$p_i$表示第i个类别在数据集D中出现的概率。
2. 计算每个属性对样本集合的信息增益接下来需要计算每个属性对样本集合的信息增益。
假设有m个属性,则第j个属性$A_j$对数据集D的信息增益可以表示为:$$ Gain(D, A_j) = Ent(D) - \sum_{i=1}^{v}\frac{|D_i|}{|D|}Ent(D_i) $$其中$v$表示第j个属性可能取值的数量,$D_i$表示在第j个属性上取值为$i$时所包含的样本子集。
3. 选择最优划分属性从所有可用属性中选择最优划分属性作为当前节点。
选择最优划分属性的方法是计算所有属性的信息增益,选择信息增益最大的属性作为当前节点。
4. 递归生成决策树使用选择的最优划分属性将数据集划分成若干子集,对每个子集递归生成子树。
ID3算法代码实现下面是Python语言实现ID3算法的代码:```pythonimport mathimport pandas as pd# 计算熵def calc_entropy(data):n = len(data)label_counts = {}for row in data:label = row[-1]if label not in label_counts:label_counts[label] = 0label_counts[label] += 1entropy = 0.0for key in label_counts:prob = float(label_counts[key]) / n entropy -= prob * math.log(prob, 2) return entropy# 划分数据集def split_data(data, axis, value):sub_data = []for row in data:if row[axis] == value:sub_row = row[:axis]sub_row.extend(row[axis+1:])sub_data.append(sub_row)return sub_data# 计算信息增益def calc_info_gain(data, base_entropy, axis):values = set([row[axis] for row in data])new_entropy = 0.0for value in values:sub_data = split_data(data, axis, value)prob = len(sub_data) / float(len(data))new_entropy += prob * calc_entropy(sub_data) info_gain = base_entropy - new_entropyreturn info_gain# 选择最优划分属性def choose_best_feature(data):num_features = len(data[0]) - 1base_entropy = calc_entropy(data)best_info_gain = 0.0best_feature = -1for i in range(num_features):info_gain = calc_info_gain(data, base_entropy, i)if info_gain > best_info_gain:best_info_gain = info_gainbest_feature = ireturn best_feature# 多数表决函数,用于确定叶子节点的类别def majority_vote(class_list):class_count = {}for vote in class_list:if vote not in class_count:class_count[vote] = 0class_count[vote] += 1sorted_class_count = sorted(class_count.items(), key=lambda x:x[1], reverse=True)return sorted_class_count[0][0]# 创建决策树def create_tree(data, labels):class_list = [row[-1] for row in data]if class_list.count(class_list[0]) == len(class_list):return class_list[0]if len(data[0]) == 1:return majority_vote(class_list)best_feature_idx = choose_best_feature(data)best_feature_label = labels[best_feature_idx]tree_node = {best_feature_label: {}}del(labels[best_feature_idx])feature_values = [row[best_feature_idx] for row in data] unique_values = set(feature_values)for value in unique_values:sub_labels = labels[:]sub_data = split_data(data, best_feature_idx, value) tree_node[best_feature_label][value] =create_tree(sub_data, sub_labels)return tree_node# 预测函数def predict(tree, labels, data):first_str = list(tree.keys())[0]second_dict = tree[first_str]feat_index = labels.index(first_str)key = data[feat_index]value_of_feat = second_dict[key]if isinstance(value_of_feat, dict):class_label = predict(value_of_feat, labels, data) else:class_label = value_of_featreturn class_label# 测试函数def test():# 读取数据集df = pd.read_csv('iris.csv')data = df.values.tolist()# 划分训练集和测试集train_data = []test_data = []for i in range(len(data)):if i % 5 == 0:test_data.append(data[i])else:train_data.append(data[i])# 创建决策树labels = df.columns.tolist()[:-1]tree = create_tree(train_data, labels)# 测试决策树模型的准确率correct_count = 0for row in test_data:true_label = row[-1]pred_label = predict(tree, labels, row[:-1])if true_label == pred_label:correct_count += 1accuracy = float(correct_count) / len(test_data)if __name__ == '__main__':test()```代码解释以上代码实现了ID3算法的主要功能。
matlab实现的ID3 分类决策树 算法

function D = ID3(train_features, train_targets, params, region)% Classify using Quinlan's ID3 algorithm% Inputs:% features - Train features% targets - Train targets% params - [Number of bins for the data, Percentage of incorrectly assigned samples at a node]% region - Decision region vector: [-x x -y y number_of_points]%% Outputs% D - Decision sufrace[Ni, M] =size(train_features); %·µ»ØÐÐÊýNiºÍÁÐÊýM%Get parameters[Nbins, inc_node] = process_params(params);inc_node = inc_node*M/100;%For the decision regionN = region(5);mx = ones(N,1) * linspace(region(1),region(2),N); %linspace(Æðʼֵ£¬ÖÕÖ¹Öµ£¬ÔªËظöÊý)my = linspace (region(3),region(4),N)' * ones(1,N);flatxy = [mx(:), my(:)]';%Preprocessing[f, t, UW, m] = PCA(train_features,train_targets, Ni, region);train_features = UW * (train_features -m*ones(1,M));flatxy = UW * (flatxy - m*ones(1,N^2));%First, bin the data and the decision region data [H, binned_features]=high_histogram(train_features, Nbins, region); [H, binned_xy] = high_histogram(flatxy, Nbins, region);%Build the tree recursivelydisp('Building tree')tree = make_tree(binned_features,train_targets, inc_node, Nbins);%Make the decision region according to the tree disp('Building decision surface using the tree') targets = use_tree(binned_xy, 1:N^2, tree, Nbins, unique(train_targets));D = reshape(targets,N,N);%ENDfunction targets = use_tree(features, indices, tree, Nbins, Uc)%Classify recursively using a treetargets = zeros(1,size(features,2)); %size(features,2)·µ»Øfeatu resµÄÁÐÊýif (size(features,1) == 1),%Only one dimension left, so work on itfor i = 1:Nbins,in = indices(find(features(indices) == i));if ~isempty(in),if isfinite(tree.child(i)),targets(in) = tree.child(i);else%No data was found in the training set for this bin, so choose it randomallyn = 1 +floor(rand(1)*length(Uc));targets(in) = Uc(n);endendendbreakend%This is not the last level of the tree, so:%First, find the dimension we are to work ondim = tree.split_dim;dims= find(~ismember(1:size(features,1), dim)); %And classify according to itfor i = 1:Nbins,in = indices(find(features(dim, indices) == i));targets = targets + use_tree(features(dims, :), in, tree.child(i), Nbins, Uc);end%END use_treefunction tree = make_tree(features, targets,inc_node, Nbins)%Build a tree recursively[Ni, L] = size(features);Uc = unique(targets);%When to stop: If the dimension is one or the number of examples is smallif ((Ni == 1) | (inc_node > L)),%Compute the children non-recursivelyfor i = 1:Nbins,tree.split_dim = 0;indices = find(features == i);if ~isempty(indices),if(length(unique(targets(indices))) == 1),tree.child(i) =targets(indices(1));elseH =hist(targets(indices), Uc);[m, T] = max(H);tree.child(i) = Uc(T);endelsetree.child(i) = inf;endendbreakend%Compute the node's Ifor i = 1:Ni,Pnode(i) = length(find(targets == Uc(i))) / L; endInode = -sum(Pnode.*log(Pnode)/log(2));%For each dimension, compute the gain ratio impurity delta_Ib = zeros(1, Ni);P = zeros(length(Uc), Nbins);for i = 1:Ni,for j = 1:length(Uc),for k = 1:Nbins,indices = find((targets == Uc(j)) & (features(i,:) == k));P(j,k) = length(indices);endendPk = sum(P);P = P/L;Pk = Pk/sum(Pk);info = sum(-P.*log(eps+P)/log(2));delta_Ib(i) =(Inode-sum(Pk.*info))/-sum(Pk.*log(eps+Pk)/log( 2));end%Find the dimension minimizing delta_Ib[m, dim] = max(delta_Ib);%Split along the 'dim' dimensiontree.split_dim = dim;dims = find(~ismember(1:Ni, dim));for i = 1:Nbins,indices = find(features(dim, :) == i); tree.child(i) = make_tree(features(dims, indices), targets(indices), inc_node, Nbins); end。
【IT专家】决策树ID3算法python实现

本文由我司收集整编,推荐下载,如有疑问,请与我司联系决策树ID3算法python实现1 from math import log2 import numpy as np3 import matplotlib.pyplot as plt4 import operator56 #计算给定数据集的香农熵7 def calcShannonEnt(dataSet):8 numEntries = len(dataSet)9 labelCounts = {}10 for featVec in dataSet: #|11 currentLabel = featVec[-1] #|12 if currentLabel not in labelCounts.keys(): #|获取标签类别取值空间(key)及出现的次数(value)13 labelCounts[currentLabel] = 0 #|14 labelCounts[currentLabel] += 1 #|15 shannonEnt = 0.016 for key in labelCounts: #|17 prob = float(labelCounts[key])/numEntries #|计算香农熵18 shannonEnt -= prob * log(prob, 2) #|19 return shannonEnt20 21 #创建数据集22 def createDataSet():23 dataSet = [[1,1,’yes’],24 [1,1,’yes’],25 [1,0,’no’],26 [0,1,’no’],27 [0,1,’no’]]28 labels = [‘no surfacing’, ‘flippers’]29 return dataSet, labels30 31 #按照给定特征划分数据集32 def splitDataSet(dataSet, axis, value):33 retDataSet = []34 for featVec in dataSet: #|35 if featVec[axis] == value: #|36 reducedFeatVec = featVec[:axis] #|抽取出符合特征的数据37 reducedFeatVec.extend(featVec[axis+1:]) #|38 retDataSet.append(reducedFeatVec) #|39 return retDataSet40 41 #选择最好的数据集划分方式42 def chooseBestFeatureToSplit(dataSet):43 numFeatures = len(dataSet[0]) - 144 basicEntropy = calcShannonEnt(dataSet)45 bestInfoGain = 0.0; bestFeature = -146 for i in range(numFeatures): #计算每一个特征的熵增益47 featlist = [example[i] for example in dataSet]48 uniqueVals = set(featlist)49 newEntropy = 0.050 for value in uniqueVals: #计算每一个特征的不同取值的熵增益51 subDataSet = splitDataSet(dataSet, i, value)52 prob = len(subDataSet)/float(len(dataSet))53 newEntropy += prob * calcShannonEnt(subDataSet) #不同取值的熵增加起来就是整个特征的熵增益54 infoGain = basicEntropy - newEntropy55 if (infoGain bestInfoGain): #选择最高的熵增益作为划分方式56 bestInfoGain = infoGain57 bestFeature = i58 return bestFeature59 #挑选出现次数最多的类别60 def majorityCnt(classList):61 classCount={}62 for vote in classList:63 if vote not in classCount.keys():64 classCount[vote] = 065 classCount[vote]。
ID3决策树算法实现(Python版)

ID3决策树算法实现(Python版) 1# -*- coding:utf-8 -*-23from numpy import *4import numpy as np5import pandas as pd6from math import log7import operator89#计算数据集的⾹农熵10def calcShannonEnt(dataSet):11 numEntries=len(dataSet)12 labelCounts={}13#给所有可能分类创建字典14for featVec in dataSet:15 currentLabel=featVec[-1]16if currentLabel not in labelCounts.keys():17 labelCounts[currentLabel]=018 labelCounts[currentLabel]+=119 shannonEnt=0.020#以2为底数计算⾹农熵21for key in labelCounts:22 prob = float(labelCounts[key])/numEntries23 shannonEnt-=prob*log(prob,2)24return shannonEnt252627#对离散变量划分数据集,取出该特征取值为value的所有样本28def splitDataSet(dataSet,axis,value):29 retDataSet=[]30for featVec in dataSet:31if featVec[axis]==value:32 reducedFeatVec=featVec[:axis]33 reducedFeatVec.extend(featVec[axis+1:])34 retDataSet.append(reducedFeatVec)35return retDataSet3637#对连续变量划分数据集,direction规定划分的⽅向,38#决定是划分出⼩于value的数据样本还是⼤于value的数据样本集39def splitContinuousDataSet(dataSet,axis,value,direction):40 retDataSet=[]41for featVec in dataSet:42if direction==0:43if featVec[axis]>value:44 reducedFeatVec=featVec[:axis]45 reducedFeatVec.extend(featVec[axis+1:])46 retDataSet.append(reducedFeatVec)47else:48if featVec[axis]<=value:49 reducedFeatVec=featVec[:axis]50 reducedFeatVec.extend(featVec[axis+1:])51 retDataSet.append(reducedFeatVec)52return retDataSet5354#选择最好的数据集划分⽅式55def chooseBestFeatureToSplit(dataSet,labels):56 numFeatures=len(dataSet[0])-157 baseEntropy=calcShannonEnt(dataSet)58 bestInfoGain=0.059 bestFeature=-160 bestSplitDict={}61for i in range(numFeatures):62 featList=[example[i] for example in dataSet]63#对连续型特征进⾏处理64if type(featList[0]).__name__=='float'or type(featList[0]).__name__=='int':65#产⽣n-1个候选划分点66 sortfeatList=sorted(featList)67 splitList=[]68for j in range(len(sortfeatList)-1):69 splitList.append((sortfeatList[j]+sortfeatList[j+1])/2.0)7071 bestSplitEntropy=1000072 slen=len(splitList)73#求⽤第j个候选划分点划分时,得到的信息熵,并记录最佳划分点74for j in range(slen):75 value=splitList[j]76 newEntropy=0.077 subDataSet0=splitContinuousDataSet(dataSet,i,value,0)78 subDataSet1=splitContinuousDataSet(dataSet,i,value,1)79 prob0=len(subDataSet0)/float(len(dataSet))80 newEntropy+=prob0*calcShannonEnt(subDataSet0)81 prob1=len(subDataSet1)/float(len(dataSet))82 newEntropy+=prob1*calcShannonEnt(subDataSet1)83if newEntropy<bestSplitEntropy:84 bestSplitEntropy=newEntropy85 bestSplit=j86#⽤字典记录当前特征的最佳划分点87 bestSplitDict[labels[i]]=splitList[bestSplit]88 infoGain=baseEntropy-bestSplitEntropy89#对离散型特征进⾏处理90else:91 uniqueVals=set(featList)92 newEntropy=0.093#计算该特征下每种划分的信息熵94for value in uniqueVals:95 subDataSet=splitDataSet(dataSet,i,value)96 prob=len(subDataSet)/float(len(dataSet))97 newEntropy+=prob*calcShannonEnt(subDataSet)98 infoGain=baseEntropy-newEntropy99if infoGain>bestInfoGain:100 bestInfoGain=infoGain101 bestFeature=i102#若当前节点的最佳划分特征为连续特征,则将其以之前记录的划分点为界进⾏⼆值化处理103#即是否⼩于等于bestSplitValue104if type(dataSet[0][bestFeature]).__name__=='float'or type(dataSet[0][bestFeature]).__name__=='int': 105 bestSplitValue=bestSplitDict[labels[bestFeature]]106 labels[bestFeature]=labels[bestFeature]+'<='+str(bestSplitValue)107for i in range(shape(dataSet)[0]):108if dataSet[i][bestFeature]<=bestSplitValue:109 dataSet[i][bestFeature]=1110else:111 dataSet[i][bestFeature]=0112return bestFeature113114#特征若已经划分完,节点下的样本还没有统⼀取值,则需要进⾏投票115def majorityCnt(classList):116 classCount={}117for vote in classList:118if vote not in classCount.keys():119 classCount[vote]=0120 classCount[vote]+=1121return max(classCount)122123#主程序,递归产⽣决策树124def createTree(dataSet,labels,data_full,labels_full):125 classList=[example[-1] for example in dataSet]126if classList.count(classList[0])==len(classList):127return classList[0]128if len(dataSet[0])==1:129return majorityCnt(classList)130 bestFeat=chooseBestFeatureToSplit(dataSet,labels)131 bestFeatLabel=labels[bestFeat]132 myTree={bestFeatLabel:{}}133 featValues=[example[bestFeat] for example in dataSet]134 uniqueVals=set(featValues)135if type(dataSet[0][bestFeat]).__name__=='str':136 currentlabel=labels_full.index(labels[bestFeat])137 featValuesFull=[example[currentlabel] for example in data_full]138 uniqueValsFull=set(featValuesFull)139del(labels[bestFeat])140#针对bestFeat的每个取值,划分出⼀个⼦树。
【机器学习笔记】ID3构建决策树

【机器学习笔记】ID3构建决策树 好多算法之类的,看理论描述,让⼈似懂⾮懂,代码⾛⼀⾛,现象就了然了。
引:from sklearn import treenames = ['size', 'scale', 'fruit', 'butt']labels = [1,1,1,1,1,0,0,0]p1 = [2,1,0,1]p2 = [1,1,0,1]p3 = [1,1,0,0]p4 = [1,1,0,0]n1 = [0,0,0,0]n2 = [1,0,0,0]n3 = [0,0,1,0]n4 = [1,1,0,0]data = [p1, p2, p3, p4, n1, n2, n3, n4]def pred(test):dtre = tree.DecisionTreeClassifier()dtre = dtre.fit(data, labels)print(dtre.predict([test]))with open('treeDemo.dot', 'w') as f:f = tree.export_graphviz(dtre, out_file = f, feature_names = names)pred([1,1,0,1]) 画出的树如下: 关于这个树是怎么来的,如果很粗暴地看列的数据浮动情况: 或者说是⽅差,⽅差最⼩该是第三列,fruit,然后是butt,scale(⽅差3.0),size(⽅差3.2857)。
再⼀看树节点的分叉情况,fruit,butt,size,scale,两相⽐较,好像发现了什么?衡量数据⽆序度: 划分数据集的⼤原则是:将⽆序的数据变得更加有序。
那么如何评价数据有序程度?⽐较直观地,可以直接看数据间的差距,差距越⼤,⽆序度越⾼。
但这显然还不够聪明。
组织⽆序数据的⼀种⽅法是使⽤信息论度量信息。
机器学习-ID3决策树算法(附matlaboctave代码)
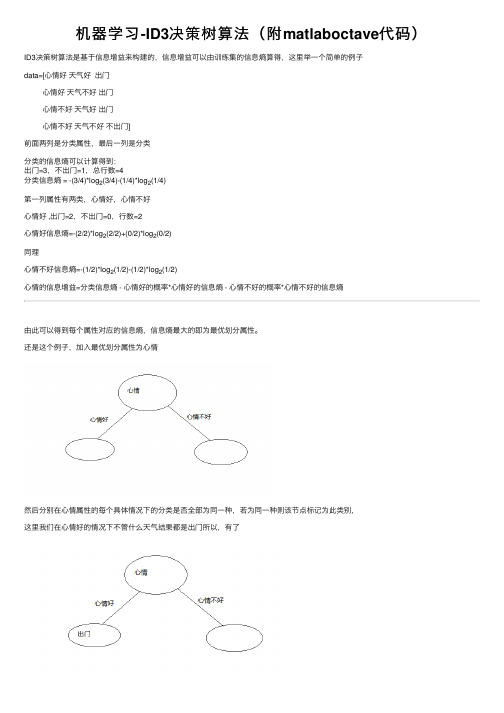
机器学习-ID3决策树算法(附matlaboctave代码)ID3决策树算法是基于信息增益来构建的,信息增益可以由训练集的信息熵算得,这⾥举⼀个简单的例⼦data=[⼼情好天⽓好出门⼼情好天⽓不好出门⼼情不好天⽓好出门⼼情不好天⽓不好不出门]前⾯两列是分类属性,最后⼀列是分类分类的信息熵可以计算得到:出门=3,不出门=1,总⾏数=4分类信息熵 = -(3/4)*log2(3/4)-(1/4)*log2(1/4)第⼀列属性有两类,⼼情好,⼼情不好⼼情好 ,出门=2,不出门=0,⾏数=2⼼情好信息熵=-(2/2)*log2(2/2)+(0/2)*log2(0/2)同理⼼情不好信息熵=-(1/2)*log2(1/2)-(1/2)*log2(1/2)⼼情的信息增益=分类信息熵 - ⼼情好的概率*⼼情好的信息熵 - ⼼情不好的概率*⼼情不好的信息熵由此可以得到每个属性对应的信息熵,信息熵最⼤的即为最优划分属性。
还是这个例⼦,加⼊最优划分属性为⼼情然后分别在⼼情属性的每个具体情况下的分类是否全部为同⼀种,若为同⼀种则该节点标记为此类别,这⾥我们在⼼情好的情况下不管什么天⽓结果都是出门所以,有了⼼情不好的情况下有不同的分类结果,继续计算在⼼情不好的情况下,其它属性的信息增益,把信息增益最⼤的属性作为这个分⽀节点,这个我们只有天⽓这个属性,那么这个节点就是天⽓了,天⽓属性有两种情况,如下图在⼼情不好并且天⽓好的情况下,若分类全为同⼀种,则改节点标记为此类别有训练集可以,⼼情不好并且天⽓好为出门,⼼情不好并且天⽓不好为不出门,结果⼊下图对于分⽀节点下的属性很有可能没有数据,⽐如,我们假设训练集变成data=[⼼情好晴天出门⼼情好阴天出门⼼情好⾬天出门⼼情好雾天出门⼼情不好晴天出门⼼情不好⾬天不出门⼼情不好阴天不出门]如下图:在⼼情不好的情况下,天⽓中并没有雾天,我们如何判断雾天到底是否出门呢?我们可以采⽤该样本最多的分类作为该分类,这⾥天⽓不好的情况下,我们出门=1,不出门=2,那么这⾥将不出门,作为雾天的分类结果在此我们所有属性都划分了,结束递归,我们得到了⼀颗⾮常简单的决策树。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
if(bn==0) {//待分结点的样本集为空时,加上一个树叶,标记为训练集中最普通的类
//记录路径与前一路径相同的部分 for(i=1;i<Trip;i++)
if(path_a[leaves][i]==0){ path_a[leaves][i]=path_a[leaves-1][i]; path_b[leaves][i]=path_b[leaves-1][i];
cout<<"无法使用训练集,请重试!"<<'\n'; exit(1); } count_test=0; j=-1;
//读取测试集数据 while(testfile>>temp){
j=j+1; k=j%(M+2); if(k==0) count_test+=1; switch(k){ case 0:test[count_test][7]=temp;
Trip-=1;
leaves+=1; //未分类的样本集减少 for(i=0,l=-1;i<=count;i++){
for(j=0,lll=0;j<bn;j++) if(s[i][M+1]==b[j][M+1]) lll++;
if(lll==0){ l+=1; for(ll=0;ll<M+2;ll++) a[l][ll]=s[i][ll];
int av[M]={3,3,2,3,4,2}; int s[N][M+2],a[N][M+2]; //数组 s[j]用来记录第 i 个训练样本的第 j 个属性值 int path_a[N][M+1],path_b[N][M+1]; //用 path_a[N][M+1],path_b[N][M+1]记录每一片叶子的路径 int count_list=M; //count_list 用于记录候选属性个数 int count=-1; //用 count+1 记录训练样本数 int attribute_test_list1[M]; int leaves=1; //用数组 ss[k][j]表示第 k 个候选属性划分的子集 Sj 中类 Ci 的样本数,数组的具体大小可根据给定训练数据调整 int ss[M][c][s_max]; //第 k 个候选属性划分的子集 Sj 中样本属于类 Ci 的概率 double p[M][c][s_max]; //count_s[j]用来记录第 i 个候选属性的第 j 个子集中样本个数 int count_s[M][s_max]; //分别定义 E[M],Gain[M]表示熵和熵的期望压缩 double E[M]; double Gain[M]; //变量 max_Gain 用来存储最大的信息增益 double max_Gain; int Trip=-1; //用 Trip 记录每一个叶子递归次数
机器学习决策树 ID3 算法的源代码(VC6.0)
#include<iostream.h> #include<fstream.h> #include<string.h> #include<stdlib.h> #include<math.h> #include<iomanip.h> #define N 500 //N 定义为给定训练数据的估计个数 #define M 6 //M 定义为候选属性的个数 #define c 2 //定义 c=2 个不同类 #define s_max 5 //定义 s_max 为每个候选属性所划分的含有最大的子集数
cout<<" THEN class="<<b[0][0]; path_a[leaves][0]=b[0][0];
//修改树的深度 if(path_a[leaves][Trip]==av[path_b[leaves][Trip]-1])
for(i=Trip;i>1;i--) if(path_a[leaves][i]==av[path_b[leaves][i]-1]) Trip-=1; else break;
if(path_a[leaves][i]==av[path_b[leaves][i]-1]) Trip-=1; else
break; Trip-=1; leaves+=1; } else { same_class=1; for(i=0;i<bn-1;i++) if(b[i][0]==b[i+1][0])
} } for(i=0,k=-1;i<l;i++){
k++; for(ll=0;ll<M+2;ll++)
s[k][ll]=a[i][ll]; } count=count-bn; } else { if(sn==0){//候选属性集为空时,标记为训练集中最普通的类 //记录路径与前一路径相同的部分
void Generate_decision_tree(int b[][M+2],int bn,int attribute_test_list[],int sn,int ai,int aj) {
//定义数组 a 记录目前待分的训练样本集,定义数组 b 记录目前要分结点中所含的训练样本集 //same_class 用来记数,判别 samples 是否都属于同一个类 Trip+=1;//用 Trip 记录每一个叶子递归次数 path_a[leaves][Trip]=ai;//用 path_a[N][M+1],path_b[N][M+1]记录每一片叶子的路径 path_b[leaves][Trip]=aj; int same_class,i,j,k,l,ll,lll;
break; case 5:test[count_test][5]=temp;
break; case 6:test[count_test][6]=temp;
break;
} } testfile.close(); for(i=1;i<=count_test;i++)
test[0]=0; //以确保评估分类准确率 cout<<"count_test="<<count_test<<'\n'; cout<<"count_train="<<count_train<<'\n'; //用测试集来评估分类准确率 for(i=1;i<=count_test;i++){
cout<<setw(4)<<s[j]; } //most 记录训练集中哪类样本数比较多,以用于确定递归终止时不确定的类别 for(i=0,j=0,k=0;i<=count;i++){
if(s[0]==0) j+=1; else k+=1; } if(j>k) most=0; else most=1; //count_train 记录训练集的样本数 count_train=count+1; //训练的属性 for(i=0;i<M;i++) attribute_test_list1=i+1;
break; case 1:test[count_test][1]=temp;
break; case 2:test[count_test][2]=temp;
break; case 3:test[count_test][3]=temp;
break; case 4:test[count_test][4]=temp;
cout<<"无法使用训练集,请重试!"<<'\n'; exit(1); } //读取训练集 while(trainfile>>temp){ j=j+1; k=j%(M+2); if(k==0||j==0) count+=1; //count 为训练集的第几个,k 代表室第几个属性 switch(k){ case 0:s[count][0]=temp;
} cout<<'\n'<<"IF "; for(i=1;i<=Trip;i++)
if(i==1) cout<<"a["<<path_b[leaves][i]<<"]="<<path_a[leaves][i]; else cout<<"^a["<<path_b[leaves][i]<<"]="<<path_a[leaves][i]; cout<<" THEN class="<<most; path_a[leaves][0]=most; //修改树的深度 if(path_a[leaves][Trip]==av[path_b[leaves][Trip]-1]) for(i=Trip;i>1;i--)
} cout<<'\n'<<"IF "; for(i=1;i<=Trip;i++)
if(i==1) cout<<"a["<<path_b[leaves][i]<<"]="<<path_a[leaves][i];
else cout<<"^a["<<path_b[leaves][i]<<"]="<<path_a[leaves][i];