计量经济学之双变量线性回归模型
经典线性回归模型

一、线性回归模型的基本假设---P99-100-105
假设1. 解释变量X是确定性变量,不是随机变 量;
假设2. 随机误差项具有零均值、同方差和无自 相关:
E(i)=0 Var (i)=2 Cov(i, j)=0
i=1,2, …,n i=1,2, …,n i≠j i,j= 1,2, …,n
– (2)对回归方程、参数估计值进行显著性 检验;
– (3)利用回归方程进行分析、评价及预测。
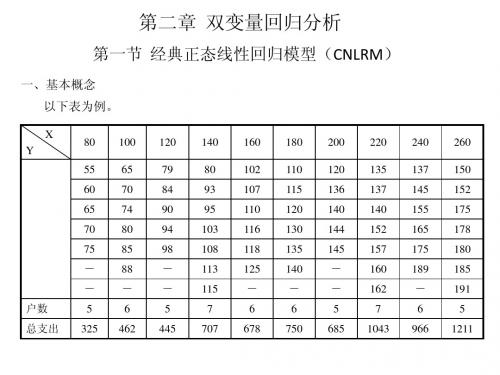
二、总体回归函数
• 回归分析关心的是根据解释变量的已知或
给定值,考察被解释变量的总体均值,即当 解释变量取某个确定值时,与之统计相关的
被解释变量所有可能出现的对应值的平均值。
• 例2.1:一个假想的社区有100户家庭组成,要 研究该社区每月家庭消费支出Y与每月家庭可 支配收入X的关系。 即如果知道了家庭的月收 入,能否预测该社区家庭的平均月消费支出水 平。
一双变量线性回归模型的基本假设二参数的普通最小二乘估计ols三最小二乘估计量的性质四参数估计量的概率分布及随机干扰项方差的估计回归分析的主要目的是要通过样本回归函数模型srf尽可能准确地估计总体回归函数模型prf
第二章 经典线性回归模型: 双变量线性回归模型
• 回归分析概述 • 双变量线性回归模型的参数估计 • 双变量线性回归模型的假设检验 • 双变量线性回归模型的预测 • 实例
3500
每 月 消 费 支 出 Y (元)
3000 2500 2000 1500 1000
500
0
500
1000
1500 2000 2500 3000 每月可支配收入X(元)
3500 4000
• 在给定解释变量Xi条件下被解释变量Yi的期望 轨迹称为总体回归线(population regression line),或更一般地称为总体回归曲线 (population regression curve)。
计量经济学第二章经典线性回归模型

Yt = α + βXt + ut 中 α 和 β 的估计值 和
,
使得拟合的直线为“最佳”。
直观上看,也就是要求在X和Y的散点图上
Y
* * Yˆ ˆ ˆX
Yt
* **
Yˆt
et * *
*
*
**
*
**
**
*
Xt
X
图 2.2
残差
拟合的直线 Yˆ ˆ ˆX 称为拟合的回归线.
对于任何数据点 (Xt, Yt), 此直线将Yt 的总值 分成两部分。
β
K
βK
β1 β1
...
βK
βK
Var(β 0 )
Cov(β1 ,β
0
)
Cov(β 0 ,β1 )
Var(β1 )
...
Cov(β
0
,β
K
)
...
Cov(β1
,β
K
)
...
...
...
...
Cov(β
K
,β
0
)
Cov(β K ,β1 )
...
Var(β K )
不难看出,这是 β 的方差-协方差矩阵,它是一 个(K+1)×(K+1)矩阵,其主对角线上元素为各 系数估计量的方差,非主对角线上元素为各系 数估计量的协方差。
ut ~ N (0, 2 ) ,t=1,2,…n
二、最小二乘估计
1. 最小二乘原理
为了便于理解最小二乘法的原理,我们用双
变量线性回归模型作出说明。
对于双变量线性回归模型Y = α+βX + u, 我 们
的任务是,在给定X和Y的一组观测值 (X1 ,
计量经济学-多元线性回归模型

Y=β0+β1X1+β2X2+...+βkXk+ε,其中Y为因变 量,X1, X2,..., Xk为自变量,β0, β1,..., βk为回归 系数,ε为随机误差项。
多元线性回归模型的假设条件
包括线性关系假设、误差项独立同分布假设、无 多重共线性假设等。
研究目的与意义
研究目的
政策与其他因素的交互作用
多元线性回归模型可以引入交互项,分析政策与其他因素(如技 术进步、国际贸易等)的交互作用,更全面地评估政策效应。
实例分析:基于多元线性回归模型的实证分析
实例一
预测某国GDP增长率:收集该国历史数据,包括GDP、投资、消费、出口等变量,建立 多元线性回归模型进行预测,并根据预测结果提出政策建议。
最小二乘法原理
最小二乘法是一种数学优化技术,用 于找到最佳函数匹配数据。
残差是观测值与预测值之间的差,即 e=y−(β0+β1x1+⋯+βkxk)e = y (beta_0 + beta_1 x_1 + cdots + beta_k x_k)e=y−(β0+β1x1+⋯+βkxk)。
在多元线性回归中,最小二乘法的目 标是使残差平方和最小。
t检验
用于检验单个解释变量对被解释变量的影响 是否显著。
F检验
用于检验所有解释变量对被解释变量的联合 影响是否显著。
拟合优度检验
通过计算可决系数(R-squared)等指标, 评估模型对数据的拟合程度。
残差诊断
检查残差是否满足独立同分布等假设,以验 证模型的合理性。
04
多元线性回归模型的检验与 诊断
计量经济学 第3章 双变量模型:假设检验

假设检验的前提是什么?
本章框图 一、古典假设
回归结果好坏? 三、高斯马尔科夫定理
二、估计量的分布问题
四、 假设 检验
七、正态性检验
方法 统计量 显著性
结论
五、拟合优度 六、预测
一、OLS估计需要的基本假设有哪些?
一、OLS估计需要的基本假设有哪些?
一、OLS估计需要的基本假设有哪些
一、OLS估计需要的基本假设有哪些?
十三、案例2股票价格和利率
理论和假说 变量选择 数据6-13 散点图 估计和结果 结论的经济意义
十四、案例3房价和贷款利率
理论和假说 变量选择 数据6-6 散点图 估计和结果 结论的经济意义
十五、案例4古董和拍卖价格
理论和假说 变量选择 数据6-14 散点图 估计和结果 结论的经济意义
第3章 双变量模型:模型检验
引子、样本回归参数的估计问题
引子、样本回归参数的估计问题
结论:
样本回归系数随样本变化。 样本回归系数是随机变量,如何描述? 样本回归系数和总体回归参数是什么关系 基于什么条件下,利用最小二乘估计的得
到的样本回归系数可以用来作为总体回归 参数的估计? 根据什么说明:总体回归函数的模型设定 是正确的。
习题讨论
习题讨论
习题讨论
习题讨论
习题讨论
习题讨论
习题讨论
五、显著性检验方法的原理是什么
五、显著性检验方法的原理是什么
五、显著性检验方法的原理是什么
五、显著性检验方法的原理是什么
六、样本回归函数拟合数据好坏的标准是什么?
六、样本回归函数拟合数据好坏的标准是什么?
六、样本回归函数拟合数据好坏的标准是什么?
七、判决系数的性质有哪些?
计量经济学ch2 双变量模型:系数估计

9
28
10
29
需求量
消平 费均 者需 数求 量量
46 47 48 49 50 51 7 48
45 46 47 48
5 46
42 44 46 48
5 44
38 42 44 46 47
6 42
39 40 42 43
5 40
35 37 38 39 42 43 7 38
34 36 38 40
5 36
32 33 34 35 36 37 7 34
五、案例6:通货膨胀率和设备利用率
理论分析(当产能利用率超过95%以上,代 表设备使用率接近全部,通货膨胀的压力将 随产能无法应付而急速升高)
数据表7-4 散点图 估计和结果 结论的经济意义
案例6:通货膨胀率和设备利用率
设备利用率是指每年度设备实际使用时间 占计划用时的百分比。是指设备的使用效 率。是反映设备工作状态及生产效率的技 术经济指标。
反向拍卖反向拍卖也叫拍买,常用于政府 采购、工程采购等。由采购方提供希望得 到的产品的信息、需要服务的要求和可以 承受的价格定位,由卖家之间以竞争方式 决定最终产品提供商和服务供应商,从而 使采购方以最优的性能价格比实现购买。
定向拍卖这是一种为特定的拍卖标的物而 设计的拍卖方式,有意竞买者必须符合卖 家所提出的相关条件,才可成为竞买人参 与竞价
密封递价拍卖 称招标式拍卖。由买主在规定的时 间内将密封的报价单(也称标书)递交拍卖人, 由拍卖人选择买主。这种拍卖方式,和上述两种 方式相比较,有以下两个特点:一是除价格条件 外,还可能有其他交易条件需要考虑:二是可以 采取公开开标方式,也可以采取不公开开标方式。 拍卖大型设施或数量较大的库存物资或政府罚没 物资时,可能采用这种方式。
第二章 双变量回归分析(计量经济学,南开大学)
ˆ 和 ˆ 1 2
i
为Yi的线性函数
i 2 i
ˆ
2
xY x
(
xi )Yi 2 x i
k Y
i
i
其中k i
xi xi2 1 xi2
ki k i2
x
2
i
0
2 xi
1 xi2 1 xi2
i
1 xi2
6、样本回归函数(SRF) 由于在大多数情况下,我们只知道变量值得一个样本,要用样本信息的基础 上估计PRF。(表) 样本1
X(收入) Y(支出) 80 55 100 65 120 79 140 80 160 102 180 110 200 120 220 135 240 137 260 150
样本2
ˆ ) VAR( 2
x
2 i
2
2 i
x
ˆ: 对于 1
ˆ Y ˆ X 1 ˆ X Yi 1 2 2 n 1 ˆ X ( 1 2 X i ui ) 2 n u 1 i X k i ui n ˆ ) E[( ui X 方差:VAR( k i ui ) 2 ] 1 n
ˆ ) E( ki E (ui ) 2 2 2 ˆ Y ˆ X 1 2 ( 1 2 X i ui ) ( 1 k i u i ) X 1 u i X k i u i ˆ ) E( 1 1
1 1 2 21
估计量(Estimator):一个估计量又称统计量(statistic),是指一个规则、公式 或方法,以用来根据已知的样本所提供的信息去估计总体参数。在应用中,由估 计量算出的数值称为估计(值)(estimate)。 样本回归函数SRF的随机形式为:
计量经济学回归分析模型
计量经济学回归分析模型计量经济学是经济学中的一个分支,通过运用数理统计和经济理论的工具,研究经济现象。
其中回归分析模型是计量经济学中最为常见的分析方法之一、回归分析模型主要用于确定自变量与因变量之间的关系,并通过统计推断来解释这种关系。
回归分析模型中的关系可以是线性的,也可以是非线性的。
线性回归模型是回归分析中最为常见和基础的模型。
它可以表示为:Y=β0+β1X1+β2X2+...+βkXk+ε其中,Y代表因变量,X1,X2,...,Xk代表自变量,β0,β1,β2,...,βk代表回归系数,ε代表随机误差项。
回归模型的核心是确定回归系数。
通过最小二乘法估计回归系数,使得预测值与实际观测值之间的差异最小化。
最小二乘法通过使得误差的平方和最小化来估计回归系数。
通过对数据进行拟合,我们可以得到回归系数的估计值。
回归分析模型的应用范围非常广泛。
它可以用于解释和预测经济现象,比如价格与需求的关系、生产力与劳动力的关系等。
此外,回归分析模型还可以用于政策评估和决策制定。
通过分析回归系数的显著性,可以判断自变量对因变量的影响程度,并进行政策建议和决策制定。
在实施回归分析模型时,有几个重要的假设需要满足。
首先,线性回归模型要求因变量和自变量之间存在线性关系。
其次,回归模型要求自变量之间不存在多重共线性,即自变量之间没有高度相关性。
此外,回归模型要求误差项具有同方差性和独立性。
在解释回归分析模型的结果时,可以通过回归系数的显著性来判断自变量对因变量的影响程度。
显著性水平一般为0.05或0.01,如果回归系数的p值小于显著性水平,则说明该自变量对因变量具有显著影响。
此外,还可以通过确定系数R^2来评估模型的拟合程度。
R^2可以解释因变量变异的百分比,值越接近1,说明模型的拟合程度越好。
总之,回归分析模型是计量经济学中非常重要的工具之一、它通过分析自变量和因变量之间的关系,能够解释经济现象和预测未来走势。
在应用回归分析模型时,需要满足一定的假设条件,并通过回归系数和拟合优度来解释结果。
第2章 双变量回归模型(2)
计量经济学模型有两种类型:一是总体回归模型,另一是 样本回归模型。两类回归模型都具有确定的形式与随机形式两 种: 总体回归模型的确定形式——总体回归函数
EY X B1 B2 X
总体回归模型的随机形式——总体回归模型
很难知道
Y B1 B2 X
样本回归模型的确定形式——样本回归函数
因此,由该样本估计的回归方程为:
ˆ Yi 103.172 0.777X i
即可支配收入每上升一个百分点,则消费支出上升0.777个百 分点;截距-103.172表明没有收入是负支出,这里没有经济意义。 另一样本结果
ˆ Yi 99.978 0.757 X i
综合图示
不同可支配收入水平组家庭消费支出的条件分布图
1、用OLS法得出的样本回归线经过样本均值点,即
Y b1 b2 X
2、残差的均值总为0,即
e e
n
i
0
3、对残差与解释变量的积求和,其值为0,即
e X
i
i
0
三、用EXCEL和Eviews实现最小二乘法
以“美国高年级学生平均智能测试结果”建立词汇分数 与数学分数的关系,用数学分数(X) 来预测词汇分数(Y) 。
3500 每 月 消 费 支 出 (元) 3000 2500 2000 1500 1000 500 0 0 500 1000 1500 2000 2500 3000 3500 4000 每月可支配收入(元) 每月家庭消费支出Y 条件均值Y* 样本1 预测 样本 样本2 预测 样本2
问题:如何检验?
二、普通最小二乘估计量的一些重要性质
一、参数的普通最小二乘估计(OLS)
建立双变量总体回归模型PRF
第6章双变量回归
2019/4/20
计量经济学讲义
样本数据二 X Y 1 51 2 47 3 46 10 30
20
样本回归线与总体回归线
比较两条样本回归线SRF1和SRF2(假定PRF是 直线),问哪条样本线代表“真实”的总体回归 SRF1 线? Y
2019/4/20 计量经济学讲义 25
样本回归线的几何意义
Y
Yi
Ŷi
E(Y|Xi)
ui
ûi
ˆ ˆX ˆ SRF : Y i 1 2 i
PRF: E(Y| Xi ) 1 2 X i
E(Y|Xi)
Xi
X
2019/4/20
计量经济学讲义
26
样本回归线的几何意义
SRF是PRF的一个近似估计 ˆ 尽可能 问:怎样构造 SRF能使得
2019/4/20
计量经济学讲义
11
条件分布
条件分布:以X取定值为条件的Y的条件分 布 注:给定收入X,支出Y并不确定,而是取 不同的值。 问:给定收入X,支出Y取什么值? 例:给定X=80,Y取5个不同的值:55、 60、65、70、75
2019/4/20 计量经济学讲义 12
条件概率
i i
ˆ 是 的估计量; 1 1 ˆ 是 的估计量。 2 2
估计量(Estimator):一个估计量又称统计量, 是指一个规则、公式或方法,是用已知的样本所 提供的信息去估计总体参数。在应用中,由估计 量算出的数值称为估计值。
2019/4/20 计量经济学讲义 24
比较PRF和SRF
P RF : E(Y | X i ) 1 2 X i Yi E(Y | X i ) ui 1 2 X i ui ˆ ˆ X ˆ SRF : Y i 1 2 i ˆ ˆ X u ˆ u ˆ ˆi Yi Y i i 1 2 i ˆi 是残差项 (residual) 其中 u ˆ ˆ X u ˆi 回归分析的主要目的是 根据 SRF Yi 1 2 i 来估计 P RF : Yi 1 2 X i ui
计量经济学第三章 双变量线性回归模型
xtYt
Y
xt
xt2
xt2
xt2
xt2
由于
xt (X t X ) X t X nX nX 0
从而
ˆ xtYt xt ( X t ut )
xt2
xt2
23
ˆ xtYt xt ( X t ut )
xt2
xt2
1 ( xt2
xt
14
残差平方和
我们的目标是使拟合出来的直线在某种意义上是最佳的, 直观地看,也就是要求估计直线尽可能地靠近各观测点,这意
味着应使残差总体上尽可能地小。要做到这一点,就必须用某
种方法将每个点相应的残差加在一起,使其达到最小。理想的 测度是残差平方和,即
et 2 (Yt Yˆt )2
15
最小二乘法
第三章 双变量线性回归模型 (简单线性回归模型)
(Simple Linear Regression Model)
2021/7/22
1
第一节 双变量线性回归模型的估计 第二节 最小二乘估计量的性质 第三节 拟合优度的测度 第四节 双变量回归中的区间估计和假
设检验 第五节 预测 第六节 有关最小二乘法的进一步讨论
9
(3)E(ut2)= 2, t=1,2,…,n 即各期扰动项的方差是一常数,也就是假定各扰
动项具有同方差性。
实际上该假设等同于:
Var( ut) = 2, t=1,2,…,n 这是因为:
Var(ut)=E{[ut-E(ut)]2}= E(ut2) ——根据假设(1)
10
(4) Xt为非随机量 即Xt的取值是确定的, 而不是随机的。 事实上,我们后面证明无偏性和时仅需要解释变量X与扰
是线性估计量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
画一条直线以尽好地拟合该散点图,由于样本取自总体, 可以该直线近似地代表总体回归线。该直线称为样本回归线 (sample regression lines)。
21
样本回归线可以看成总体回归线的近似替代。 ˆ ˆ 样本回归线的函数形式为:ˆi f ( X i ) 0 1 X i Y 即为样本回归函数(sample regression function, SRF)。
数(PRF)的随机设定形式。表明被解释变量除了受 解释变量的系统性影响外,还受其他因素的随机性影 响。由于方程中引入了随机项,成为计量经济学模型, 因此也称为总体回归模型。
18
随机误差项的意义
核心变量与周边变量
样本随机性
实际观测误差
19
四、样本回归函数(SRF)
问题:是否能从一次抽样中获得总体的近似的信息?如果 可以,如何从抽样中获得总体的近似信息? 例:在上例的总体中有如下一个样本,能否从该样本估计 总体回归函数PRF?
6
回归分析构成计量经济学的方法论基 础,其主要内容包括:
根据样本观察值对经济计量模型参数进 行估计,求得回归方程;
对回归方程、参数估计值进行显著性检 验; 利用回归方程进行分析、评价及预测。
7
二、总体回归函数(PRF)
回归分析关心的是根据解释变量的已知或给
定值,考察被解释变量的总体均值,即当解
释变量取某个确定值时,与之统计相关的被
17
上例中,给定收入水平 Xi ,个别家庭的支出可表示为两
部分之和: 该收入水平下所有家庭的平均消费支出E(Y | Xi),称为 系统性(systematic)或确定性(deterministic)部分; 其他随机或非确定性(nonsystematic)部分为 ui 。
Yi E (Y X i ) ui 0 1 X i ui 称为总体回归函
解释变量所有可能出现的对应值的平均值。
8
例:一个假想的社区有100户家庭组成,要研 究该社区每月家庭消费支出Y 与每月家庭可支 配收入X 的关系。 即如果知道了家庭的月收入, 能否预测该社区家庭的平均月消费支出水平。 为达到此目的,将该100户家庭划分为组内收 入差不多的10组,以分析每一收入组的家庭消 费支出。
30
以上假定1-4也称为线性回归模型的经 典假设或高斯(Gauss)假设,满足该假 设的线性回归模型,也称为经典线性回 归模型(Classical Linear Regression Model, CLRM)。
又称为同方差性。 Var(ui)= E(ui-E(ui))2 = E(ui2) = u2 , i=1,2, ……,n
Var( ui )
2
Var (Yi )
2
如果误差项的方差不同,那么与其对应的观 测值Yi的可靠程度也不相同。 这会使参数的检验和利用模型进行预测复杂 化。而满足同方差假设,将使检验和预测简化。
样本残差或剩余项(residual), ˆ 也可看成是ui的估计量ui。
由于方程中引入了随机项,成为计量经济模 型,因此也称为样本回归模型(sample regression model)。
23
回归分析的主要目的:根据样本回归函数SRF, 估计总体回归函数PRF。
ˆ ˆ ˆ 即,根据 Yi Yi ei 0 1 X i ei
Yi ~ N 0 1 X i , 2 ) (
如果只利用OLS进行参数估计,不需要该假设。但是若 要进行假设检验和预测,就必须知道总体Yi的分布情况。 如果Xi为非随机变量,总体Yi与误差项ui服从相同的分 布,Yi与ui之间只有均值E(Yi)的差别。
根据中心极限定理,当样本容量趋于无穷大时,假定5 对于任何实际模型都是满足的。
变量间的关系包括: 确定性关系或函数关系:研究的是确定 现象非随机变量间的关系。
圆面积 f , 半径 半径2
统计依赖或相关关系:研究的是非确定 现象随机变量间的关系。
农作物产量 f 气温, 降雨量, 阳光, 施肥量
4
对变量间统计依赖关系的考察主要是通过相关 分析(correlation analysis)或回归分析 (regression analysis)来完成的。
虽然是随机的,但与干扰项 ui 独立;
2) X i 无测量误差; 3)模型设定正确(不存在设定误差)
25
二、对随机扰动项 ui的假定
假定1:随机误差项ui的数学期望(均值)为0,即
E (ui ) 0
E (Yi ) 0 1 X i
PRF:Yi 0 1 X i
26
假定2:随机误差项ui的方差与i无关,为一个常数,
相关分析对称地对待任何(两个)变量,两个
变量都被看作是随机的。回归分析对变量的处
理方法存在不对称性,即区分因变量(被解释
变量)和自变量(解释变量):前者是随机变 量,后者不是。
5
回归分析的基本概念
回归分析(regression analysis)是研究一个变量 关于另一个(些)变量的具体依赖关系的计 算方法和理论。 其目的在于通过后者的已知或设定值,去估 计和(或)预测前者的(总体)均值。 被解释变量(Explained Variable)或因变量 (Dependent Variable)。 解释变量(Explanatory Variable)或自变量 (Independent Variable)。
第二章 双变量线性回归模型
Y 0 1 X u
主要内容
回归分析概述 模型的基本假设 模型的参数估计 模型的统计检验 模型的预测 实例
2
2.1 回归分析概述
变量间的关系及回归分析的基本概念
总体回归函数(PRF) 随机扰动项 样本回归函数(SRF)
3
一、变量间的关系及回归分析的基本概念
的,例如:P(Y=561|X=800)=1/4。
11
因此,给定收入 X 的值 Xi ,可以得到消费支出 Y的条件均值(conditional mean)或条件期望 (conditional expectation):E( Y | X = Xi )。
该例中:E(Y | X = 800) = 605
描出散点图发现:随着收入的增加,消费“平 均地”也在增加,且 Y 的条件均值均落在一条 正斜率的直线上。这条直线称为总体回归线。
14
含义:总体回归函数(PRFFra bibliotek说明被解释变量 Y 的平均状态(总体条件期望)随解释变量 X 变 化的规律。 函数形式:可以是线性或非线性的。 例子中,将居民消费支出看成是其可支配收入 的线性函数时: E (Y | X i ) 0 1 X i
为一线性函数。其中,0,1是未知参数,称为 回归系数(regression coefficients)。
15
“线性”一词的含义:
1、模型就变量而言是线性的
例如: E (Y X i ) 0 1 X i 2、模型就参数而言是线性的 例如: E (Y X i ) 0 1 X
2 i
E (Y X i ) 0 1 X i
1 E (Y X i ) 0 1 X
注:在计量经济学中,从回归理论的发展、 参数的估计方法来说,主要考虑的是模型就 参数而言是线性的情形。
28
假定4:扰动项与解释变量之间不相关(相互独立)
Cov( ui , X i ) 0
Cov(ui, Xi)= E(ui-E(ui)) (Xi-E(Xi)) = E(ui (Xi-E(Xi))=E(uiXi)- E(ui)E(Xi) = E(uiXi) =0
29
假定5:随机扰动项服从正态分布
ui ~ N (0, 2 )
表 2.1.3 家庭消费支出与可支配收入的一个随机样本 Y X 800 594 1100 638 1400 1122 1700 1155 2000 1408 2300 1595 2600 1969 2900 2078 3200 2585 3500 2530
20
该样本的散点图(scatter diagram)如下:
16
三、随机扰动项
总体回归函数说明在给定的收入水平 Xi 下,该社区家 庭平均的消费支出水平。 但对某一个别的家庭,其消费支出可能与该平均水平
存在偏差。
ui Yi E (Y X i ) 称为观察值围绕它的期望值的离差
(deviation),它是一个不可观测的随机变量,又称 为随机扰动项(stochastic disturbance)或随机误差项 (stochastic error)。
估计
Yi E(Y | X i ) ui 0 1 X i ui
这就要求我们必须找到合适的方法使得SRF ˆ 尽可能地接近PRF,或者说使 (i 0,1)尽可能接
i
近i (i 0,1)。
24
2.2 模型的基本假设
一、 对变量和模型的假定
1)重复抽样中,解释变量 X i 是一组固定的值或
共计
2420
21450 21285
15510
10
由于不确定性因素的影响,对同一收入水平 X, 不同家庭的消费支出并不完全相同; 但由于调查的完备性,给定收入水平 X 的消费支 出 Y 的分布是确定的,即以 X 的给定值为条件的
Y 的条件分布(Conditional distribution)是已知
9
表 2.1.1 某社区家庭每月收入与消费支出统计表 每月家庭可支配收入X(元) 800 每 月 家 庭 消 费 支 出 Y (元) 561 594 627 638 1100 638 748 814 847 935 968 1400 869 913 924 979 1012 1045 1078 1122 1155 1188 1210 1700 1023 1100 1144 1155 1210 1243 1254 1298 1331 1364 1408 1430 1485 2000 1254 1309 1364 1397 1408 1474 1496 1496 1562 1573 1606 1650 1716 2300 2600 2900 1969 1991 2046 2068 2101 2189 2233 2244 2299 2310 3200 2090 2134 2178 2266 2354 2486 2552 2585 2640 3500 2299 2321 2530 2629 2860 2871 1408 1650 1452 1738 1551 1749 1595 1804 1650 1848 1672 1881 1683 1925 1716 1969 1749 2013 1771 2035 1804 2101 1870 2112 1947 2200 2002 4950 11495 16445 19305 23870 25025