数据挖掘第二章——认识数据(1)2
数据仓库与数据挖掘技术 第二章 数据仓库

第2章数据仓库2.1数据仓库的基本概念1. 数据仓库的数据是面向主题的数据仓库与数据挖掘技术图2-1主题间的重叠关系2. 数据仓库的数据是集成的3. 数据仓库的数据是不可更新的数据仓库与数据挖掘技术4. 数据仓库的数据是随时间不断变化的图2-2数据仓库体系结构2.2数据仓库的体系结构数据仓库与数据挖掘技术图2-3数据仓库数据组织结构2.2.1元数据1. 元数据在数据仓库中的作用2. 元数据的使用3. 元数据的分类4. 元数据的内容2.2.2粒度的概念1. 按时间段综合数据的粒度2. 样本数据库2.2.3分割问题1. 分割的优越性2. 数据分割的标准3. 分割的层次2.2.4数据仓库中的数据组织形式1. 简单堆积结构图2-4简单堆积结构数据组织形式2. 轮转综合结构数据仓库与数据挖掘技术图2-5轮转综合结构数据组织形式3. 简单直接结构图2-6简单直接结构数据组织形式4. 连续结构图2-7连续结构数据组织形式数据仓库与数据挖掘技术2.3数据仓库的数据模型2.3.1概念数据模型图2-8商品、顾客和供应商E-R图2.3.2逻辑数据模型2.3.3物理数据模型2.3.4高层数据模型、中间层数据模型和低层数据模型1. 高层数据模型2. 中间层数据模型3. 低层数据模型数据仓库与数据挖掘技术2.4数据仓库设计步骤图2-9数据仓库设计步骤2.4.1概念模型设计1. 界定系统边界2. 确定主要的主题域3. 实例2.4.2技术准备工作2.4.3逻辑模型设计1. 分析主题域2. 划分粒度层次3. 确定数据分割策略4. 定义关系模式5. 定义记录系统2.4.4物理模型设计1. 确定数据的存储结构数据仓库与数据挖掘技术2. 确定索引策略3. 确定数据存放位置4. 确定存储分配2.4.5数据仓库的生成1. 接口设计2. 数据装入2.4.6数据仓库的使用和维护1. 开发DSS应用图2-10DSS应用开发步骤2. 进一步理解需求,改善系统,维护数据仓库图2-11William H.Inmon数据仓库设计步骤数据仓库与数据挖掘技术2.5利用SQL Server 2005构建数据仓库图2-12使用Visual Studio 2005系统新建项目图2-13新建Analysis Services项目图2-14新建数据源数据仓库与数据挖掘技术图2-15新建数据源向导图2-16选择如何连接数据源图2-17连接管理器图2-18连接管理器连接测试成功窗口图2-19选择已经连接的数据库作为数据源图2-20选择连接数据源的凭证图2-21新建数据源向导完成图2-22右击新建数据源视图图2-23新建数据源视图向导图2-24选择视图的数据源图2-25选择表和视图图2-26完成新建数据源视图向导图2-27新建多维数据集图2-28多维数据集向导图2-29选择生成多维数据集的方法图2-30选择多维数据集的数据源视图图2-31检测事实数据表和维度表图2-32标示事实表和维度表图2-33选择度量值图2-34扫描维度图2-35查看维度结构图2-36完成多维数据集向导图2-37创建完成数据仓库界面习题21. 如何理解数据仓库是面向主题的、集成的、不可更改的和是随时间不断变化的。
数据仓库与数据挖掘教程(第2版)课后习题答案 第二章

数据仓库与数据挖掘教程(第2版)课后习题答案第二章1. 什么是数据仓库?它与传统数据库有什么不同?答:数据仓库是一个面向主题、集成、稳定、可学习的数据集合,用于支持企业决策制定和决策支持系统。
与传统数据库相比,数据仓库更注重数据的整合和大数据的处理能力,以支持更高级别的数据分析和决策。
2. 什么是元数据?有哪些类型?答:元数据指描述数据仓库中数据的数据,用于描述数据的含义、格式、内容、质量、来源、使用和存储等方面的信息。
元数据有三种类型:技术元数据、业务元数据和操作元数据。
3. 数据仓库的架构有哪些组成部分?请简述各组成部分的作用。
答:数据仓库的架构主要包括数据源、数据抽取、清理和转换、存储和管理、元数据管理、查询和分析等几个组成部分。
- 数据源:指数据仓库的数据来源,可以是事务处理系统、外部数据源、第三方提供商等。
- 数据抽取、清理和转换:将数据从各种不同的来源抽取出来并转化为简单、标准的格式,以便进行加工和分析。
- 存储和管理:将经过抽取、转换和清洗后的数据存储在数据仓库中并进行管理,查找、更新和删除等操作。
- 元数据管理:对数据仓库中的元数据进行管理,并将其存储在元数据存储库中。
- 查询和分析:通过各种查询和分析工具来进行数据挖掘、分析和报告。
4. 请列出数据仓库中的三种主要数据类型。
答:数据仓库中的三种主要数据类型包括事实数据、维度数据和元数据。
5. 请列出数据仓库的三种不同的操作类型。
答:数据仓库的三种不同的操作类型包括基础操作、加工操作和查询操作。
6. 数据挖掘的定义是什么?答:数据挖掘是一种通过分析大量数据来发现有意义模式、趋势和关联的过程。
它是既包含统计学、机器学习和数据库技术的交叉学科,又包含更广泛的知识和业务领域。
7. 请列出数据挖掘中的四个主要任务。
答:数据挖掘中的四个主要任务包括描述性数据挖掘、预测性数据挖掘、关联数据挖掘和分类和聚类。
8. 数据仓库中经常使用OLAP分析方式,您了解OLAP是什么吗?答: OLAP是一种面向主题的数据分析方式,可以帮助用户对快速变化的数据进行多维分析和决策支持。
数据挖掘2

(4)数据压缩技术 (5)复合键码技术 (6)有效地装载数据
2. 数据存储技术
数据的存储技术包含多介质存储设备的管 理技术,数据存储的控制技术,数据的并行存 储与管理技术,可变长技术和锁切换技术、双 层环境等。
3. 数据仓库接口技术
(1)多技术的接口:对于数据仓库的创建和运行来说,能够 使用各种不同的技术获取或传送数据是很重要的。 (2)语言的接口:数据仓库的实际应用必须依赖某种语言来 完成,典型的数据仓库语言接口必须满足如下要求:
• • • • 能够一次访问一条记录或一组数据 能够确保索引可以满足用户需要 有SQL接口 能够插入、删除和更新数据
(3)数据加载技术
2.2 数据仓库中的数据
2.2.1数据仓库的数据组织
1.数据仓库组成 (1)数据仓库管理部分 数据仓库的数据来自多个数据源,包括企业内 部数据和市场调查与分析的外部数据。数据仓库管 理部分的组成包括:
图2-11 企业数据模型
财务部门 销售收入帐 应收帐 应付帐 成本帐 销售部门 销售计划 销售合同 销售统计 人事部门 员工业绩记录 员工技能情况 员工薪酬表 财务 销售
企业数据模型
人事
…….. …..
…….
(2)星型数据模型 星型数据模型将数据分为两类:事实和维。星 型模型是数据的图形视图。星形的中心是事实表 (有时称为主表),其中存放要考查的数据—事实。 在事实表的外围是维表(有时称为副表、维度表), 主要存储事实的特征数据。每个维表利用维关键字 通过事实表中的外键被约束在事实表中的某一行, 以与事实表相关联。
这种方式在提高性能和可靠性、降低数据传输 量以及保证数据的安全性等方面有来很大的好处。
2. 数据仓库的数据组织
数据仓库中数据的组织方式与数据库不同, 通常采用分级的方式进行组织。一般包括早期 细节数据、当前细节数据、轻度综合数据、高 度综合数据以及元数据五部分。 (1)早期细节数据:指存储过去的详细数据, 它反映了真实的历史情况。 (2)当前细节数据:指最近时期的业务数据, 它反映了当前业务的情况,数据量大,是数据 仓库用户最感兴趣的部分。
数据挖掘第三版第二章课后习题答案

1.1什么是数据挖掘?(a)它是一种广告宣传吗?(d)它是一种从数据库、统计学、机器学和模式识别发展而来的技术的简单转换或应用吗?(c)我们提出一种观点,说数据挖掘是数据库进化的结果,你认为数据挖掘也是机器学习研究进化的结果吗?你能结合该学科的发展历史提出这一观点吗?针对统计学和模式知识领域做相同的事(d)当把数据挖掘看做知识点发现过程时,描述数据挖掘所涉及的步骤答:数据挖掘比较简单的定义是:数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际数据中,提取隐含在其中的、人们所不知道的、但又是潜在有用信息和知识的过程。
数据挖掘不是一种广告宣传,而是由于大量数据的可用性以及把这些数据变为有用的信息的迫切需要,使得数据挖掘变得更加有必要。
因此,数据挖掘可以被看作是信息技术的自然演变的结果。
数据挖掘不是一种从数据库、统计学和机器学习发展的技术的简单转换,而是来自多学科,例如数据库技术、统计学,机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成。
数据库技术开始于数据收集和数据库创建机制的发展,导致了用于数据管理的有效机制,包括数据存储和检索,查询和事务处理的发展。
提供查询和事务处理的大量的数据库系统最终自然地导致了对数据分析和理解的需要。
因此,出于这种必要性,数据挖掘开始了其发展。
当把数据挖掘看作知识发现过程时,涉及步骤如下:数据清理,一个删除或消除噪声和不一致的数据的过程;数据集成,多种数据源可以组合在一起;数据选择,从数据库中提取与分析任务相关的数据;数据变换,数据变换或同意成适合挖掘的形式,如通过汇总或聚集操作;数据挖掘,基本步骤,使用智能方法提取数据模式;模式评估,根据某种兴趣度度量,识别表示知识的真正有趣的模式;知识表示,使用可视化和知识表示技术,向用户提供挖掘的知识1.3定义下列数据挖掘功能:特征化、区分、关联和相关性分析、分类、回归、聚类、离群点分析。
数据挖掘第一与第二章概述数据收集讲解学习

2022年3月12日星期六
数据挖掘导论
25
数据集的重要特性
• 维度(Dimensionality) – 数据集的维度是数据集中的对象具有的属性数目 – 维灾难(Curse of Dimensionality) – 维归约(dimensionality reduction)
• 稀疏性(Sparsity) – 具有非对称特征的数据集,一个对象的大部分属性上的值都为 0 – 只存储和处理非零值
数据
– 数据中的联系
• 如时间和空间的自相关性、图的连通性、半结构化文本和XML文 档中元素之间的父子联系
2022年3月12日星期六
数据挖掘导论
9
挑战4
• 数据的所有权与分布
– 数据地理上分布在属于多个机构的资源中
• 需要开发分布式数据挖掘技术
– 分布式数据挖掘算法面临的主要挑战包括
• (1) 如何降低执行分布式计算所需的通信量? • (2) 如何有效地统一从多个资源得到的数据挖掘结果? • (3) 如何处理数据安全性问题?
Single 70K
No
Married 120K No
Divorced 95K
Yes
Married 60K
No
Divorced 220K No
Single 85K
Yes
Married 75K
No
Single 90K
Yes
2022年3月12日星期六
数据挖掘导论
28
记录数据: 数据矩阵
• 如果一个数据集族中所有数据对象都具有相同的数 值属性值,则数据对象可以看做多维空间中的点, 每个维代表对象的一个不同属性。
2.1 数据类型
• 数据集的不同表现在很多方面。例如, 某些数据集包含时间序列或者彼此之间具 有明显联系的对象。毫不奇怪,数据的类 型决定我们应使用何种工具和技术来分析 数据。此外,数据挖掘研究常常是为了适 应新的应用领域和新的数据类型的需要而 展开的。
研究生《知识发现与数据挖掘》教学大纲
《知识发现与数据挖掘》教学大纲Knowledge Discovery and Data Mining第一部分大纲说明1. 课程代码:1030812082. 课程性质:专业非学位课3. 学时/学分:20/24. 课程目标和任务:数据挖掘是一门新兴的交叉性学科,在很多重要领域,数据挖掘技术发挥着重要作用,如地球科学领域、矿业工程领域、生物工程工程、商业领域、金融和保险领域等。
本课程课程主要讲授数据挖掘技术的基本原理、方法、算法,具体包括:数据挖掘技术内涵、数据特征、聚类分析,关联规则分析、分类等,以及数据挖掘技术在地矿领域的应用。
通过本课程的学习,使研究生掌握数据挖掘技术的基本原理、方法和算法,了解数据挖掘技术的研究与应用热点、数据挖掘技术能够解决的问题和今后研究与应用的发展方向,以及如何利用数据挖掘技术解决实际问题。
5. 教学方式:课堂教学6. 考核方式:考查7. 先修课程:掌握一定的计算机基础知识9. 教材及教学参考资料:(一)教材:Pang-Ning Tan, Michael Steinbach and Vipin Kumar.《Introduction to Data Mining》,北京:人民邮电出版社,2006(二)教学参考资料:Jia-Wei Han and Micheline Kamber.《数据挖掘概念与技术》,北京:机械工业出版社,2003第二部分教学内容和教学要求第一章数据挖掘概述1.1 教学目的与要求重点讲解数据挖掘的起源、数据挖掘过程与功能,以及面临的主要问题。
1.2 教学内容理解和掌握数据挖掘的基本概念、数据挖掘过程以及数据挖掘功能;了解数据挖掘的应用和面临的问题;重点是对数据挖掘能够解决的问题和解决问题思路有清晰的认识。
1.2.1 什么是数据挖掘数据挖掘(Data Mining)就是从大量的、不完全的、模糊的、随机的实际应用数据中,提取隐含在其中的、事先不知道的但又是潜在有用的信息和知识的过程。
数据挖掘的认识及应用

维普资讯
得 了较好的效果 , 为人们的正确决策提供 了很大 的帮助 。
2 数 据挖掘 的任 务 .
数 据 挖 掘技 术 的 任务 一 般 可 以分 为 两 类 : 述 和 预 测 。描 描
述性挖掘任务是描述数据库 中数据 的一 般性质 ; 预测性 挖掘任
务是对当前数据进行 推断 , 以做 出预测 。数据 挖掘 的功能主要
大量 的数 据 中提 取 有 用 的 知 识 , 成 为 当 务 之 急 。在 这 种 情 况 就
知的对象类 , 它要解决的问题是 为一个事件 或对象归类 。在使 用上 , 既可以用分类模 型分 析 已有 的 数据 , 也可 以用 它来预测 未来 的数 据。例如 银行 部门 可以根 据以前 的数 据将客 户分成
数据挖掘概述数据挖掘datamining简称dm就是从大量的不完全的有噪声的模糊的随机的数据中抽取出潜在的人们事先不知道的有用信息模式和趋势用来提高市场决策能力检测异常模式在过去经验的基础上预测未来趋势解决传统分析方法的不足
维普资讯
管 理 干 部 学 院 学 报
随着数据库和计算机网络 的广 泛应用 , 以及先进 的数据 采 集工具的积极使用 , 人们 所拥 有 的数据 量在急 剧增 大 , 数据迅 速增加与数据分析 方法 滞后 之间 的矛盾 越来越 突 出。人们 往 往希望能够对 已有的数据进行科学 有效 的分 析 , 而得到 自己 从 需要 的更有用 的深层次信息 , 在此基础上 进行商业 决策或 者 并 企业管理等 。但是 , 目前 已有 的数据分析 工具很难满 足人们对 数据进行深层次分析的需要 , 数据处理 的效率也 很低 。如何从
下, 人们 引入 了数 据挖 掘的思 想 , 通过它 预测 未来 的趋势 和行
数据挖掘复习知识点整理
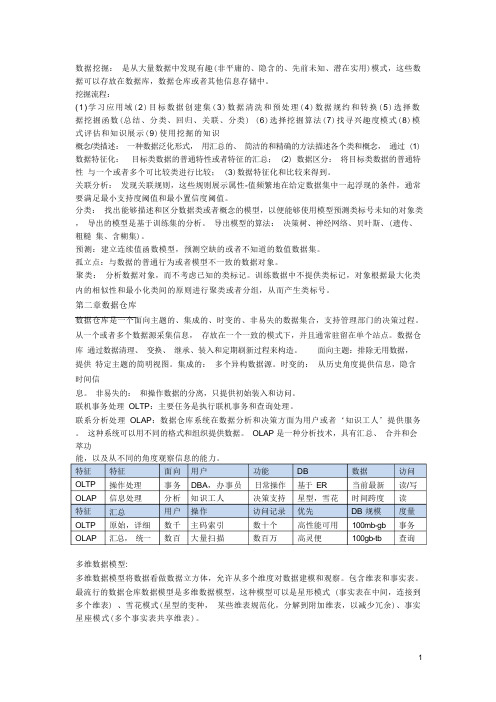
数据挖掘:是从大量数据中发现有趣(非平庸的、隐含的、先前未知、潜在实用)模式,这些数据可以存放在数据库,数据仓库或者其他信息存储中。
挖掘流程:(1)学习应用域(2)目标数据创建集(3)数据清洗和预处理(4)数据规约和转换(5)选择数据挖掘函数(总结、分类、回归、关联、分类) (6)选择挖掘算法(7)找寻兴趣度模式(8)模式评估和知识展示(9)使用挖掘的知识概念/类描述:一种数据泛化形式,用汇总的、简洁的和精确的方法描述各个类和概念,通过 (1) 数据特征化:目标类数据的普通特性或者特征的汇总; (2) 数据区分:将目标类数据的普通特性与一个或者多个可比较类进行比较; (3)数据特征化和比较来得到。
关联分析:发现关联规则,这些规则展示属性-值频繁地在给定数据集中一起浮现的条件,通常要满足最小支持度阈值和最小置信度阈值。
分类:找出能够描述和区分数据类或者概念的模型,以便能够使用模型预测类标号未知的对象类,导出的模型是基于训练集的分析。
导出模型的算法:决策树、神经网络、贝叶斯、(遗传、粗糙集、含糊集)。
预测:建立连续值函数模型,预测空缺的或者不知道的数值数据集。
孤立点:与数据的普通行为或者模型不一致的数据对象。
聚类:分析数据对象,而不考虑已知的类标记。
训练数据中不提供类标记,对象根据最大化类内的相似性和最小化类间的原则进行聚类或者分组,从而产生类标号。
第二章数据仓库数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理部门的决策过程。
从一个或者多个数据源采集信息,存放在一个一致的模式下,并且通常驻留在单个站点。
数据仓库通过数据清理、变换、继承、装入和定期刷新过程来构造。
面向主题:排除无用数据,提供特定主题的简明视图。
集成的:多个异构数据源。
时变的:从历史角度提供信息,隐含时间信息。
非易失的:和操作数据的分离,只提供初始装入和访问。
联机事务处理OLTP:主要任务是执行联机事务和查询处理。
联系分析处理OLAP:数据仓库系统在数据分析和决策方面为用户或者‘知识工人’提供服务。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
▪ 按照对事物计量的精确程度,可将所采用的 计量尺度由低级到高级分为四个层次:
▪ 定类尺度(Nominal Level) ▪ 定序尺度(Ordinal Level) ▪ 定距尺度(Interval Level) ▪ 定比尺度(Ratio Level)
定类尺度
▪ 定类尺度(列名尺度):按照事物的某种 属性对其进行平行的分类或分组。
▪ 例:人口的性别(男、女);企业的所有制性 质(国有、集体、私营等)
▪ 计量层次最低 ▪ 对事物进行平行的分类 ▪ 各类别可以指定数字代码表示 ▪ 具有=或的数学特性 ▪ 数据表现为“类别”
定类尺度
▪ 定类尺度只测度了事物之间的类别差,而对各 类之间的其他差别却无法从中得知,因此各类 地位相同,顺序可以任意改变。
2.25
5678 9
QU 位置
39 4
6.75
QL 780 (850 780) 0.25 QU 1250 (1500 1250) 0.75
797.5
1437.5
四分位数的例子(数值型数据)
▪ 9个家庭的人均月收入数据
▪ 原始数据: 1500 750 780 1080 850 960 2000 1250 1630 ▪ 排 序: 750 780 850 960 1080 1250 1500 1630 2000
离散 vs. 连续属性
▪ Discrete Attribute
▪ 一个有限的或可数无限集值 ▪ E.g., zip codes,the set of words in a collection of documents
▪ 有时,表示为整数变量 ▪ 注: 二元属性是离散属性的一个特殊情况
▪ Continuous Attribute
甲城市 户数 (户) 累计频数
非常不满意
24
24
不满意
108
132
一般
93
225
满意
45
270
非常满意
30
300
合计
300
—
解:QL位置= (300)/4 =75 QU位置 =(3×300)/4 =225
从累计频数看, QL在“ 不 满意”这一组别中; QU在 “一般”这一组别中
四分位数为 QL = 不满意 QU = 一般
▪ e.g., gender ▪ 非对称Asymmetric binary: 非同等重要
▪ e.g., 医疗检查 (positive vs. negative) ▪ 惯例Convention: assign 1 to most important
outcome (e.g., HIV positive) ▪ 顺序的 Ordinal
一个众数 原始数据:
659855
多于一个众数 原始数据: 25 28 28 36 42 42
众数的例子
例 某城市居民关注广告类型的频数分布
广告类型
人数(人) 比例 频率(%)
商品广告
112
0.560
56.0
服务广告
51
0.255
25.5
金融广告
9
0.045
4.5
房地产广告
16
0.080
8.0
招生招聘广告
四种计量尺度的比较
四种计量尺度的比较
定类尺度 定序尺度 定距尺度 定比尺度
分类(=,≠ )
√
√
√
√
排序( < ,> )
√
√
√
间距( + ,- )
√
√
比值( × ,÷)
√
“√”表示该尺度所具有的特性
四种计量尺度的区别与联系
▪ 高层次的计量尺度具有低层次计量尺度的全部特 性,但反之不行
▪ 可将高层次计量尺度的计量结果转换为低层次计 量尺度的计量结果,但不能反过来
属性类型
▪ 名词性Nominal:类别,状态, or “名目”
▪ Hair_color = {auburn, black, blond, brown, grey, red, white}
▪ 婚姻状态, 职业occupation, ID numbers, zip codes ▪ 二元
▪ 只有2个状态的名词性属性 (0 and 1) ▪ 对称二元Symmetric binary: 同样重要的两相
▪ 对事物分类的同时给出各类别的顺序 ▪ 比定类尺度精确 ▪ 不仅可以测度类别差(分类),还可以测
度次序差(比较优劣或排序) ▪ 数据表现为“类别”,但有序
定序尺度
▪ 无法测出类别之间的准确差值 ▪ 该尺度的计量结果只能排序,不能进行算
术运算。 ▪ 具有>或<的数学特性
定距尺度
▪ 定距尺度(间隔尺度):是对事物类别或次序之 间间距的测度。
集中趋势 (Central tendency)
▪ 一组数据向其中心值靠拢的倾向和程度 ▪ 测度集中趋势就是寻找数据一般水平的代表值或
中心值 ▪ 不同类型的数据用不同的集中趋势测度值 ▪ 低层次数据的集中趋势测度值适用于高层次的测
量数据,反过来,高层次数据的集中趋势测度值 并不适用于低层次的测量数据
▪ 对定类尺度的计量结果,可以且只能计算每一 类别中各元素个体出现的频数 (frequency)。
▪ 对事物进行分类时,必须符合穷尽(exhaustive) 和互斥(mutually exclusive)要求。
定序尺度
▪ 定序尺度(顺序尺度):是对事物之间等 级或顺序差别的一种测度。
▪ 例:产品等级(一等品、二等品…);考试成 绩(优、良、中、可、差)
特性
定比尺度
▪ 定比尺度(比率尺度):是能够测算两个测 度值之间比值的一种计量尺度。
▪ 例:职工月收入;企业产值;公制的距离、重量
▪ 与定距尺度属于同一层次,计量结果也表现 为数值;
▪ 除了具有其他三种计量尺度的全部特点外, 还具有可计算两个测度值之间比值的特点;
▪ “0”表示“没有”,即它有一固定的绝对 “零点”,因此它可进行加、减、乘、除运 算(而定距尺度只可进行加减运算)
▪ 属性值为实数 ▪ E.g., temperature, height, or weight
▪ 实际上,实值只能使用有限位数进行测量和代表 ▪ 连续属性通常表示为浮点变量
数据概述
数据的计量与类型
▪ 数据的计量尺度 ▪ 数据的类型 ▪ 数据的表现形式
数据的计量尺度
▪ 数据的计量尺度(Levels of Measurement)
3n 4
方法2:较准确算法
QL 位置
n 1 4
QU 位置
3(n 1) 4
四分位数
方法3:
Q位置
n 1 2
2
1
▪ 其中[ ]表示中位数的位置取整。这样计算 出的四分位数的位置,要么是整数,要么 在两个数之间0.5的位置上
四分位数的例子(定序数据)
甲城市家庭对住房状况评价的频数分布
回答类别
第2章 认识数据
• 数据对象
▪ 数据集由数据对象构成 ▪ 一个数据对象代表一个实体 ▪ 例子:
▪ 销售数据库sales database:客户/顾客,商店物品, sales ▪ 医学数据库: patients, treatments ▪ 大学数据库: students, professors, courses ▪ 又称为 样本, 事例,实例, 数据点, 对象,元组tuples. ▪ 数据对象由属性来描述 ▪ Database rows -> data objects; columns ->attributes.
四分位数的例子(数值型数据)
▪ 9个家庭的人均月收入数据
▪ 原始数据: 1500 750 780 1080 850 960 2000 1250 1630 ▪ 排 序: 750 780 850 960 1080 1250 1500 1630 2000
▪ 位 置: 1 2 3 4
方法1
QL 位置
9 4
▪ 例:100分制考试成绩;摄氏温度对不同地区温度的测 量
▪ 不仅能将事物区分为不同类型并进行排序,而且 可准确指出类别之间的差距是多少
▪ 比定序尺度精确 ▪ 定距尺度通常以自然或物理单位为计量尺度,因
此数据表现为“数值” ▪ 没有绝对零点;“0”是测量尺度上的一个测量点,
并不代表“没有” ▪ 计量结果可以进行加减运算,具有 + 或 - 的数学
▪ 值有一个有意义的顺序(排序) 但连续值之间的大小未知. ▪ Size = {small, medium, large},等级,军队排名
数值属性的类型
▪ 数量Quantity (integer or real-valued) ▪ 区间Interval
▪ 在某个同等大小的一个尺度单位上Measured on a scale of equal-sized units
属性
▪ 属性Attribute (or维度, 特征, 变量):一个数据字段, 表示 一个数据对象的某个特征. ▪ E.g., customer _ID, name, address
▪ 类型: ▪ 名词性Nominal ▪ 二元的 ▪ 数字的Numeric: 数量的 ▪ Interval-scaled ▪ Ratio-scaled
▪ 选用哪一个测度值来反映数据的集中趋势,要根 据所掌握的数据的类型来确定
定类数据:众数(mode)
▪ 出现次数最多的变量值 ▪ 用Mo表示 ▪ 不受极端值的影响 ▪ 可能没有众数或有几个众数 ▪ 主要用于定类数据,也可用于定序数据和
数值型数据
众数的不唯一性
无众数 原始数据:
10 5 9 12 6 8
当N为奇数时