第十四章--交叉表分析法(课件)
第十四章 交叉表分析法(课件)
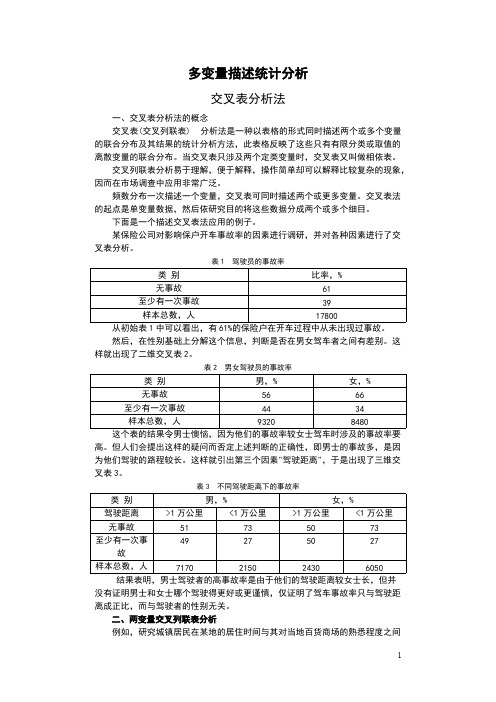
多变量描述统计分析交叉表分析法一、交叉表分析法的概念交叉表(交叉列联表) 分析法是一种以表格的形式同时描述两个或多个变量的联合分布及其结果的统计分析方法,此表格反映了这些只有有限分类或取值的离散变量的联合分布。
当交叉表只涉及两个定类变量时,交叉表又叫做相依表。
交叉列联表分析易于理解,便于解释,操作简单却可以解释比较复杂的现象,因而在市场调查中应用非常广泛。
频数分布一次描述一个变量,交叉表可同时描述两个或更多变量。
交叉表法的起点是单变量数据,然后依研究目的将这些数据分成两个或多个细目。
下面是一个描述交叉表法应用的例子。
某保险公司对影响保户开车事故率的因素进行调研,并对各种因素进行了交叉表分析。
表1 驾驶员的事故率类别比率,%无事故61至少有一次事故39样本总数,人17800从初始表1中可以看出,有61%的保险户在开车过程中从未出现过事故。
然后,在性别基础上分解这个信息,判断是否在男女驾车者之间有差别。
这样就出现了二维交叉表2。
表2 男女驾驶员的事故率类别男,%女,%无事故5666至少有一次事故4434样本总数,人93208480这个表的结果令男士懊恼,因为他们的事故率较女士驾车时涉及的事故率要高。
但人们会提出这样的疑问而否定上述判断的正确性,即男士的事故多,是因为他们驾驶的路程较长。
这样就引出第三个因素"驾驶距离",于是出现了三维交叉表3。
表3 不同驾驶距离下的事故率类别男,%女,%驾驶距离>1万公里<1万公里>1万公里<1万公里无事故51735073至少有一次事49275027故样本总数,人7170215024306050结果表明,男士驾驶者的高事故率是由于他们的驾驶距离较女士长,但并没有证明男士和女士哪个驾驶得更好或更谨慎,仅证明了驾车事故率只与驾驶距离成正比,而与驾驶者的性别无关。
二、两变量交叉列联表分析例如,研究城镇居民在某地的居住时间与其对当地百货商场的熟悉程度之间的关系,对“居住时间”和“熟悉程度”这两个变量进行交叉列联分析。
第十四章--交叉表分析法(课件)

多变量描述统计分析交叉表分析法一、交叉表分析法的概念交叉表(交叉列联表) 分析法是一种以表格的形式同时描述两个或多个变量的联合分布及其结果的统计分析方法,此表格反映了这些只有有限分类或取值的离散变量的联合分布。
当交叉表只涉及两个定类变量时,交叉表又叫做相依表。
交叉列联表分析易于理解,便于解释,操作简单却可以解释比较复杂的现象,因而在市场调查中应用非常广泛。
频数分布一次描述一个变量,交叉表可同时描述两个或更多变量。
交叉表法的起点是单变量数据,然后依研究目的将这些数据分成两个或多个细目。
下面是一个描述交叉表法应用的例子。
某保险公司对影响保户开车事故率的因素进行调研,并对各种因素进行了交叉表分析。
表1 驾驶员的事故率从初始表1中可以看出,有61%的保险户在开车过程中从未出现过事故。
然后,在性别基础上分解这个信息,判断是否在男女驾车者之间有差别。
这样就出现了二维交叉表2。
表2 男女驾驶员的事故率这个表的结果令男士懊恼,因为他们的事故率较女士驾车时涉及的事故率要高。
但人们会提出这样的疑问而否定上述判断的正确性,即男士的事故多,是因为他们驾驶的路程较长。
这样就引出第三个因素"驾驶距离",于是出现了三维交叉表3。
表3 不同驾驶距离下的事故率结果表明,男士驾驶者的高事故率是由于他们的驾驶距离较女士长,但并没有证明男士和女士哪个驾驶得更好或更谨慎,仅证明了驾车事故率只与驾驶距离成正比,而与驾驶者的性别无关。
二、两变量交叉列联表分析例如,研究城镇居民在某地的居住时间与其对当地百货商场的熟悉程度之间的关系,对“居住时间”和“熟悉程度”这两个变量进行交叉列联分析。
如表4所示。
间低于30年的居民比居住时间在30年以上的居民似乎更熟悉百货商场。
进一步计算出百分比,则可以看得更直观一些。
见表5。
表5 居住时间与对百货商场的熟悉程度的交叉列联分析(%)行百分比与列百分比的选择取决于哪个变量是因变量哪个变量是自变量。
交叉列表分析

交叉列表分析主要是用来检验两个变量之间是否存在关系,或者说是独立,其零假设为两个变量之间没有关系。
通过录入数据,建立数据库,然后确定交叉分析变量,对变量进行分析,得出交叉表。
通过表中数据分析出来结论。
如材料中的性别---对休闲生活的满意度---夫妻共度休闲时间状况。
多选变量是指对于包含了多个答案的一个问题,可以允许被调查者在其中作多项选择。
就是我们第一次实验做的一个问题
老师说的其中一个方法是多选变量二分法。
然后学习了多选变量的分析多选变量的频数分析多选变量的交叉分析实例。
SPSS多选变量分析方法可以把多个变量中相同答案的频数累加起来。
比如。
交叉表分析

data05-02为某公司工资数据(n=15)。
使用变量性别sex、收入高低earnings分析男女经理间薪金是否平等。
可以利用data05-01中的数据,使用变量occcat80为工作性质分类,region为地区,childs 为每个家庭的孩子数。
将childs为行变量,occcat80为列变量,region为控制变量选入Layer of框中,进行交叉表分析。
列联表(交叉表)分析1、项目名称Crosstabs过程4、实训原理Crosstabs过程用于定类数据和定序数据进行统计描述和简单的统计推断。
在分析时可以产生二维至n维列联表,并计算相应的百分数指标。
4-1 列联表分析的含义与任务在实际分析中,当问题涉及到多个变量时,我们不仅要了解单个变量的分布特征,还要分析多个变量不同取值下的分布,掌握多变量的联合分布特征,进而分析变量之间的相互影响和关系。
很明显,如果还采用单纯的频数分析方法显然不能满足要求。
因此,我们需要借助交叉分组下的频数分析,即列联表分析。
列联表分析的主要任务有两个:(1)根据样本数据产生二维或多维交叉列联表。
交叉列联表是两个或两个以上变量交叉分组后形成的频数分布表。
(2)在交叉列联表的基础上,分析两变量之间是否具有独立性或一定的相关性。
4-2 卡方检验的原理为了理解列联表中行变量(Row)和列变量(Column)之间的关系,我们需要借助非参数检验方法。
通常采用的方法是卡方检验。
和一般假设检验一样,卡方检验主要包括三个步骤:(1)建立零假设:行变量和列变量相互独立。
(2)选择和计算检验统计量。
列联表分析中的检验统计量是Pearson卡方统计量。
其公式为:()∑∑==-=r i cj eij e ij o ijf f f1122χ(4-9-1)其中,r 为列联表的行数,c 为列联表的列数,0f 为实际观测频数,e f 期望观测频数。
期望频数的计算公式为:nCTRT f e ⨯=(4-9-2) 其中,RT 是指定单元格所在行的观测频数合计,CT 是指定单元格所在列的观测频数合计,n 是观测频数的合计。
交叉分析表详解

2请问您常上网的原因是什么? □1.方便与家人联络 □2.方便与朋友,同学联络 □3.追求流行 □4.工作需要 □5.别人提供 □6.同事间的比较心理 □7.网络价格下降 □8.网络接入商推出的促销方案 □9.玩在线游戏 □10.其他 3请填写您的基本资料 性别: □1.男 □2.女 该问卷的数据列在”复选题”工作表中 本数据是针对107位大学生进行调查而得,常上网的有104笔数据, 下面就用数据透视表分几次来处理这个复选题的交叉表 1选定B列,单击 “升序排序”按钮,使常上网者的样本集中 在前面 2执行“数据>数据透视表和数据透视图”,单击“下一步”按钮, 转入“数据透视表和数据透视图向导-3步骤2”对话框 3将鼠标移回工作表,重新选取A1:F105作为来源区域(此区域 为上网者的区域)
方法b 1用鼠标单击要求得数据透视表的数据列表的任一单元格 2根据前面所说步骤,逐步转入“数据透视表和数据透视图向 导-3步骤3”对话框 3决定安排数据透视表的位置,单击完成,将显示一个空白的 数据透视表,“数据透视表字段列表”和“数据透视表工作列” 4从“数据透视表字段列表”上,将要作为数据透视表列内容 的字段按钮(如:所在地区),拖拽到“将列字段至此处”;将 要作为数据透视表行内容的字段按钮(所在地区),拖拽到“将 行字段至此处”;将要作为数据透视表数据内容的字段按钮(性 别)拖拽到“请将数据字段拖至此处”,即可得到一个数据透视 表 5由于预设情况是计算加总,所以选取表中数据内容的任意一 个单元格,右击,选择“字段设置”,将“名称”改为“人数”, 将“汇总方式”改为“计数”,单击“确定”,即可得到新的数 据透视表。
6-4加入分页依据
数据透视表内允许加入分页项目(如:性别),作为交叉表的上 一层分组依据,以便查阅不同性别即各地区的品牌倾向。 假设想在前面所说的透视表内加入“性别”作为分页依据,其处 理步骤如下 1用鼠标单击数据透视表内任意一个单元格 2执行“数据透视表>数据透视表向导”,单击“布局”按钮 3将“性别”拖拽至“页(p)”位置,单击“确定”“完成”即可 此时,透视表上方,会有一下拉式选择表 这表示数据表内显示的是全部数据的交叉分析结果,要查阅不同性别 数据时可单击下拉箭头,选择要分析的性别
交叉分析表

將分析結果轉入Word
假定,要將先前『馬上練習』中『偏好原因*品牌交叉 表』,轉到Word文件。其處理步驟為:
1. 以滑鼠右鍵點選輸出結果之交叉表,將出現一選單,選 取「複製(C)」,記下交叉表內容
2. 轉到Excel之空白工作表,按 將選取內容複製過來
『貼上』鈕,
3. 雙按B欄之標題按鈕右側,將其調整為最適欄寬,以便顯 示完整文字
4. 於G3輸入『合計』字串 5. 將C5、C7、C9與C11之『品牌內的 %』改為『%』 6. 將C10之『個數』改為『樣本數』 7. 將所有百分比均改為只留一位小數,並加上『%』
8. 選取B3:G11之內容 9. 按 『複製』鈕,記下所選取之內容
10. 再轉到Word文件,停於要插入交叉表之位置。 按 『貼上』鈕,將選取內容複製過來
(r-1)*(c-1)
r為列數、c為欄數。本例之自由度為3×5=15。
最後,依自由度查『附錄一 卡方分配的臨界值』, 比較所計算之卡方值,是否超過所指定顯著水準 (α=0.05)的臨界值?若超過,則應棄卻欄變數 與列變數並無關聯之虛無假設。反之,則否。
查『附錄一 卡方分配的臨界值』,於自由度15、 α=0.05,其臨界值為25.00。而我們所求算出之 卡方值32.743>25.00,故應棄卻政黨傾向與地 區別無關之虛無假設。也就是說,政黨支持率會 隨地區別不同而有顯著差異。
11. 將表格安排成置中格式,將其外框安排為雙線、 內框為單線之表格,修飾一下表格之對齊方式
往後,即可於表格之下,輸入分析結果的文字內 容:
百分比
交叉表的百分比有三種:
橫列(R) 求以橫向總計為分母之百分比
直行(C) 求以縱向總計為分母之百分比
總和(T) 求以總樣本數為分母之百分比
交叉分析
进一步分析1.农民工外出务工原因的影响因素分析前面已经分别了解过了性别比例以及务工原因的比例。
但是,由于性别不同,思维方式的不同,我们想进一步了解不同性别与务工原因的之间是否有差异性?基于此我们利用统计分析方法得到表14和表15:⑴性别与外出务工原因的交叉分析首先,观察表14的合计横栏,选择务工原因“在外收入高”的占37.4%,“就业机会多”的占15.1%,“为了今后发展”的占21.9%,另外因为其他原因的占14.4%。
这与之前的结论是一致的。
其次,对不同性别的农民工的务工原因进行分析。
被调查的农民工选择务工原因中“外出收入高”男性有的有118人,占男性的45.4%;选择务工原因中“外出收入高”女性有的有46人,占性的45.4%。
由此,我们猜想性别是影响外出务工原因的因素。
最后,对不同务工原因进行分析。
被调查的农民工中选择“在外收入高”的原因里男性占72%,女性占28%;选择“就业机会多”的原因男性比重为53%,女性为47%;选择“为了今后发展”的原因男性比重为57.3%,女性为42.7%;选择“向往城市生活”的原因里女性占58.6%,男性为41.4%。
表14 不同性别务工原因列联表由上述分析可看出男女性在选择外出务工原因在性别之间有一定差异,因此我们猜想性别是造成这一差异的因素。
⑵性别与外出务工原因的卡方检验分析为了证明上述猜想猜想是否合理,我们进行了了假设性检验,得到表15。
表15 性别与务工原因的卡方检验表本检验的原假设,性别与务工原因之间不相关。
从表15中有:如果显著性水平α为0.05,由于卡方检验的概率P-值为0.001,显然是概率P-值小于显著性水平α,因此我们应该拒绝原假设,也就是说性别与务工原因之间存在着相关性,即性别是影响外出务工原因的因素。
结合表14的样本数据,不同体现在:男性与女性之间的外出务工原因有着显著性差异。
2.影响农民工对相关法律熟悉度的影响在现实情况中,由于人们总是想尽办法增加自己的文化程度,以此想增加自己的收入。
交叉分析表
6-3
若選「新工作表(N)」,將再自動產生一新的工作表,以顯示樞紐分 析表。
STEP 5
按
鈕,續利用捲動軸,轉到可以看見 K3 儲存格之位置,
可發現已有一空白的樞紐分析表,且右側也有一個『樞紐分析表欄
位』窗格
STEP 6Leabharlann 於右側『樞紐分析表欄位』窗格上方之『選擇要新增到報表的欄位:』
處,以拖曳之方式,將『□零用金』拉到下方『在以下區域之間拖
),將其拉
STEP 4
按右下方『Σ值』方塊內,『加總-性別』項右側之下拉鈕,續選 「 值欄位設定(N)…」 , 轉 入 『 值 欄 位 設 定 』 對 話 方 塊 , 於 『 摘 要 值
欄位方式(S)』處將其改為「項目個數」,以求算出現次數,另於『自 訂名稱(C)』處,將原內容『加總-性別』改為『%』
市場調查或民意調查,常利用交叉分析表來以探討兩個類別變數間之 關聯性(如:地區別與某政策之贊成與否、性別與偏好政黨、教育程度與 使用品牌、品牌與購買原因、……)。
於 Excel 中,交叉分析表除可利用前章所提到之 COUNTIFS()函數進 行求算以外;還可以利用『樞紐分析表』或『模擬分析/運算列表』來建立。 不過,還是以『樞紐分析表』較為簡單。所以,我們就僅介紹『樞紐分析 表』。
鈕,轉入『建立樞紐分析表』對
話方塊
6-2
STEP 3
於上半部,選「選取表格或範圍(S)」,其內所顯示者恰為問卷資料 之範圍(Excel 會自動判斷正確範圍,若有不適,仍可自行輸入或 重選正確之範圍)
STEP 4 於下半部,選「已經存在的工作表(E)」項,續選按 K3 儲存格。表 欲將樞紐分析表安排於目前工作表之 K3 處
6-10
STEP 5
交叉分析表
縮減組數--組距分組(5)
將『重新編碼』結果安排到『時間分組』:
縮減組數--組距分組(6)
續以『時間分組』與『性別』重建一次交叉表:
縮減組數--組距分組(7)
即可得到經縮減組數後之交叉表:
縮減組數--組距分組(8)
期望值個數<5之儲存格比例為10%,並未超過20%。表 格無須再行合併以縮減組別。 卡 方 值 為 11.312 , 自 由 度 為 4 , 其 顯 著 水 準 0.023<α=0.05。所以,應棄卻運動時間長短與性別無關 之虛無假設。
交叉分析表交叉分析隐身spss交叉分析数据交叉分析什么是交叉分析交叉分析图excel交叉分析excel交叉分析表交叉分析法问卷交叉分析
第六章 交叉分析表
交叉分析表
市場調查或民意調查,常利用交叉分析表來探討兩個類別 變數間之關聯性(如:地區別與某政策之贊成與否、性別 與偏好政黨、教育程度與使用品牌、品牌與購買原因、所 得與是否有數位相機、……)。
應注意下列事項(1)
卡方檢定僅適用於類別資料(名目變數,如:性別、地 區、政黨傾向、宗教信仰、是否有手機、……)。 各儲存格之期望次數不應少於5。通常要有80%以上的儲 存格期望次數≧5,否則會影響其卡方檢定的效果。若有 期望次數小於5時,可將其合併。
應注意下列事項(2)
由於,各儲存格之期望次數不應少於5。通常要有80%以 上的儲存格期望次數≧5,否則會影響其卡方檢定的效 果。故而,SPSS之卡方檢定結果,會於最底下計算期望 值<5之儲存格比例:
縮減類別(1)
進行交叉分析表時,通常要有80%以上的儲存格期望次數 ≧5,否則會影響卡方檢定的效果。若有期望次數小於5 時,可將其合併。如,『Ch06\手機.sav』之資料:
第十四章 交叉表分析法(课件)
多变量描述统计分析交叉表分析法一、交叉表分析法的概念交叉表(交叉列联表) 分析法是一种以表格的形式同时描述两个或多个变量的联合分布及其结果的统计分析方法,此表格反映了这些只有有限分类或取值的离散变量的联合分布。
当交叉表只涉及两个定类变量时,交叉表又叫做相依表。
交叉列联表分析易于理解,便于解释,操作简单却可以解释比较复杂的现象,因而在市场调查中应用非常广泛。
频数分布一次描述一个变量,交叉表可同时描述两个或更多变量。
交叉表法的起点是单变量数据,然后依研究目的将这些数据分成两个或多个细目。
下面是一个描述交叉表法应用的例子。
某保险公司对影响保户开车事故率的因素进行调研,并对各种因素进行了交叉表分析。
表1 驾驶员的事故率类别比率,%无事故61至少有一次事故39样本总数,人17800从初始表1中可以看出,有61%的保险户在开车过程中从未出现过事故。
然后,在性别基础上分解这个信息,判断是否在男女驾车者之间有差别。
这样就出现了二维交叉表2。
表2 男女驾驶员的事故率类别男,%女,%无事故5666至少有一次事故4434样本总数,人93208480这个表的结果令男士懊恼,因为他们的事故率较女士驾车时涉及的事故率要高。
但人们会提出这样的疑问而否定上述判断的正确性,即男士的事故多,是因为他们驾驶的路程较长。
这样就引出第三个因素"驾驶距离",于是出现了三维交叉表3。
表3 不同驾驶距离下的事故率类别男,%女,%驾驶距离>1万公里<1万公里>1万公里<1万公里无事故51735073至少有一次事49275027故样本总数,人7170215024306050结果表明,男士驾驶者的高事故率是由于他们的驾驶距离较女士长,但并没有证明男士和女士哪个驾驶得更好或更谨慎,仅证明了驾车事故率只与驾驶距离成正比,而与驾驶者的性别无关。
二、两变量交叉列联表分析例如,研究城镇居民在某地的居住时间与其对当地百货商场的熟悉程度之间的关系,对“居住时间”和“熟悉程度”这两个变量进行交叉列联分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多变量描述统计分析
交叉表分析法
一、交叉表分析法的概念
交叉表(交叉列联表) 分析法是一种以表格的形式同时描述两个或多个变量的联合分布及其结果的统计分析方法,此表格反映了这些只有有限分类或取值的离散变量的联合分布。
当交叉表只涉及两个定类变量时,交叉表又叫做相依表。
交叉列联表分析易于理解,便于解释,操作简单却可以解释比较复杂的现象,因而在市场调查中应用非常广泛。
频数分布一次描述一个变量,交叉表可同时描述两个或更多变量。
交叉表法的起点是单变量数据,然后依研究目的将这些数据分成两个或多个细目。
下面是一个描述交叉表法应用的例子。
某保险公司对影响保户开车事故率的因素进行调研,并对各种因素进行了交叉表分析。
表1 驾驶员的事故率
然后,在性别基础上分解这个信息,判断是否在男女驾车者之间有差别。
这样就出现了二维交叉表2。
表2 男女驾驶员的事故率
高。
但人们会提出这样的疑问而否定上述判断的正确性,即男士的事故多,是因为他们驾驶的路程较长。
这样就引出第三个因素"驾驶距离",于是出现了三维交叉表3。
表3 不同驾驶距离下的事故率
有证明男士和女士哪个驾驶得更好或更谨慎,仅证明了驾车事故率只与驾驶距离成正比,而与驾驶者的性别无关。
二、两变量交叉列联表分析
例如,研究城镇居民在某地的居住时间与其对当地百货商场的熟悉程度之间
的关系,对“居住时间”和“熟悉程度”这两个变量进行交叉列联分析。
如表4所示。
间低于30年的居民比居住时间在30年以上的居民似乎更熟悉百货商场。
进一步计算出百分比,则可以看得更直观一些。
见表5。
表5 居住时间与对百货商场的熟悉程度的交叉列联分析(%)
行百分比与列百分比的选择取决于哪个变量是因变量哪个变量是自变量。
一般的规则是,在自变量的方向上,对因变量计算百分比。
以表5为例,居住时间为自变量,对商场的熟悉程度为因变量,因而可以对各居住时间分别计算熟悉程度的百分比。
由表5可见,53.6%的居住时间低于13年的人和60.9%的居住时间在13年~30年的人都熟悉该商店,而只有32.9%的居住时间在30年以上的人熟悉该商店。
看来,同样住在该地区的人,居住时间越长,对购物环境反而更不熟悉。
这个结论是有一定道理的,在一个地方居住很长时间的人一般相对来说更没有动力去熟悉该商场。
如果我们在因变量的方向上对自变量计算百分比(如表6所示),则显然没意义。
表6暗示,对当地商场不熟悉会影响居民在该地的居住时间,这显然是不合理的。
但是,居住时间与对百货商场的熟悉程度之间的联系可能受第三变量的影响,例如年龄。
居住时间越长的人可能年龄越大。
尽管分析结果表明年龄在此不是影响因素,但由此可见需要检查第三因素的影响。
三、三变量的交叉列联表分析
引入第三变量后再进行交叉列联分析,则可能出现以下四种结果:
(1)剔除外部环境的影响,使原先两变量间的关系更单纯。
例如,在表7中,仅分析婚姻状况和衣服支出水平这两个变量时,从数字上看未婚者在衣服支出方面比已婚者更高一些。
但引入变量性别以后,发现对于男性来说,已婚者与未婚者在衣服支出方面没有显著差异,但对于女性未婚者与已婚者,在衣服支出方面的差异则很明显。
见表8。
表7 婚姻状况对衣服支出水平的交叉列联分析(%)
(2)否定原先两变量间的关系。
例如,根据表9可见,仅对受教育水平和私家车
的拥有情况进行交叉列联分析,发现文化程度越高的人拥有私家车的比例越高。
但引入收
人变量后发现收入才是影响拥有私家车的真正原因,对于低收入者,不论文化程度高低在
购买私家车方面没有差异。
见表10。
表9 受教育水平对私家车拥有状况的交叉列联分析(%)
(3)尽管原先观察两变量间没有关系,第三变量的引入可能揭示了它们之间的一些联系。
由表11可见,仅对年龄和出国旅行的欲望进行交叉列联分析,发现两者之间没有关系。
但引入性别变量后,发现对于男性,年龄越大,出国旅游的欲望越强;而对于女性正好相反,年龄越小,出国欲望越强。
见表12。
(4)没有影响。
以表13为例,引入收入变量后,家庭规模与是否经常吃快餐之间仍旧没有关系。
见表14。
表13 家庭规模对是否经常吃快餐的交叉列联分析 (%)
四、交叉表分析法的优缺点
交叉表被广泛用于商业市场调研,因为它有如下优点:
●交叉表的分析结果很容易直观地被理解;
●明了的解释加强了调研结果与经理行为的联系;
●一系列交叉表比多变量分析更有助于理解复杂的问题;
●交叉表可减弱空格问题,这在多元离散变量分析中更突出;
●交叉表将复杂的数据简单化。
交叉表有两点局限。
其一,如果需要考虑多个变量,样本容量就应相当大;其二,很难确保对所有的相关变量进行了分析,如果变量选择不适当,就会得出错误的结论。
即使变量选择的正确,研究者也许会因使用不当而无法找到真正的关系。
能否制作一个好的交叉表,取决于研究者选择关键变量以及根据这些变量组成交叉表的能力。
另外,用于交叉表分析的变量的类型和数量随研究的目的、性质而变化。
在描述性调研中,研究者有较大的自主权来选择这些变量。
在探索性研究中,研究者凭主观意识选择所有的用于交叉表的变量。
交叉表分析只能用于有数据基础的变量分析,它描述的是变量间的关系,但不一定是因果关系。