汉字编码标准与识别
我国汉字编码标准

我国汉字编码标准首先,我国的汉字编码标准在不同阶段都遵循了统一性、规范性和适用性的原则。
在GB2312-80发布之后,我国的计算机领域得到了长足的发展,但是随着信息化建设的深入,GB2312-80已经不能满足当今社会对汉字编码的需求。
因此,1995年发布了GBK编码,它在GB2312-80的基础上增加了对繁体字和少数民族文字的支持。
而随着国际化的发展,GB18030-2005标准的发布则进一步完善了我国汉字编码标准,使其更加符合国际标准。
其次,我国汉字编码标准的发展也受益于技术的进步和应用的需求。
随着计算机技术的不断发展,对于汉字编码的要求也越来越高。
GB18030-2005标准的发布,不仅支持了Unicode标准,还对繁体字和少数民族文字进行了更好的支持,使得我国的汉字编码标准更加符合当今信息化建设的需要。
再者,我国汉字编码标准的发展也受益于国际化的趋势。
随着我国在国际上的地位不断提升,对于国际标准的遵循和应用也越来越重要。
GB18030-2005标准的发布,使得我国的汉字编码标准更加符合国际标准,为我国在国际上的信息交流和合作提供了更好的支持。
最后,我国汉字编码标准的发展也为我国的信息化建设和文化传承提供了更好的支持。
汉字是我国的传统文化符号,对于汉字的数字化编码,不仅可以更好地保护和传承我国的传统文化,还可以更好地适应当今信息化建设的需要。
因此,我国汉字编码标准的不断完善和发展,为我国的信息化建设和文化传承提供了更好的基础和保障。
总之,我国汉字编码标准的发展经历了多个阶段,每一次的更新都是为了更好地适应当代社会的需求。
随着技术的进步、国际化的趋势以及信息化建设的需求,我国汉字编码标准将会不断完善和发展,为我国的信息化建设和文化传承提供更好的支持和保障。
汉字国标码 (gb2312-80) 规定的汉字编码,每个汉字用

汉字国标码 (gb2312-80) 规定的汉字编码,每个汉字用概念汉字国标码 (gb2312-80) 规定的汉字编码,每个汉字用 2为每个汉字编上唯一的代码,方便计算机识别与处理。
2. 国标码1980年,我国颁布了汉字编码的标准:GB2312-80《信息交换汉字编码字符集》,简称国标码。
国标码是4位十六进制数组成。
3. 区位码GB2312是一种汉字编码方式,具体由区位码实现,GB2312将所有汉字编入一个94*94的二维表中,行和列共同定位一个字,行就是“区”,列就是“位”,合并就为区内码。
区位码是一组4位十进制的数,前两位是区码,后两位是位码。
例如:譬如“万” 字在 45 区 82 位, 所以“万” 字的区位码是: 4582.00-09 区(682个): 是符号、数字、英文字符...制表符等;10-15 区: 空白, 留待扩展;16-55 区(3755个): 常用汉字(也有叫一级汉字), 按拼音排序;56-87 区(3008个): 非常用汉字(也有叫二级汉字), 这是按部首排序的;88-94 区: 空白, 留待扩展4. 机内码机内码是微软为了解决汉字编码与ASCLL编码冲突。
从而规定把每个字节的最高位都从 0 换成 1(这之前它们都是 0),或者说把每个字节(区和位)都再加上 80H(128的十六进制表示),从而得到“机内码”,简称"内码"。
关系与转换1.三者的关系国标码 = 区位码 + 2020H;机内码 = 国标码 +8080H;2020H解释因为ASCLL码中分为控制型编码和有形字符编码,前32位是控制码(如回车,退格等),沿用前32个,覆盖后面的。
故国标码规定在区位码的基础上每个字节分别加上20H(32的十六进制表示)。
8080H解释为避免与ASCLL编码冲突,从而规定把每个字节的最高位都从0 换成 1(这之前它们都是 0),或者说把每个字节(区和位)都再加上 80H(128的十六进制表示)。
汉字编码

具体的,
GBKindex = ((unsigned char)GBKword[0]-129)*190 +
((unsigned char)GBKword[1]-64) - (unsigned char)GBKword[1]/128;
三、怎样判断一个汉字的是什么编码
return true;
else return false;
}
else return false;
}
2、判断是否是GBK编码
bool isGBKCode(const string& strIn)
{
unsigned char ch1;
if (ch1>=129 && ch1<=254 && ch2>=64 && ch2<=254)
return true;
else return false;
}
else return false;
}
3、对于Big5
对于第二块,计算偏移量时因为有两块数值,所以在计算后面一段值时,不要忘了前面还有一段值。0x7E-0x40+1=63。
四、如果判断一个字符是西文字符还是中文字符
大家知道西文字符主要是指ASCII码,它用一个字节表示。且这个字符转换成数字之后,该数字是大于0的,而汉字是两个字节的,第一个字节的转化为数字之后应该是小于0的,因此可以根据每个字节转化为数字之后是否小于0,判断它是否是汉字。
{
ch1 = (unsigned char)strIn.at(0);
ch2 = (unsigned char)strIn.at(1);
汉字的编码方式以及相应的关系

汉字的编码方式以及相应的关系汉字的编码方式以及相应的关系在当今信息时代,汉字编码方式是一个备受关注的话题。
汉字作为中文的基本表达形式,其编码方式的选择和规范对于信息技术、文化传承以及国际交流都具有重要的意义。
我们有必要对汉字的编码方式进行全面评估,并根据深度和广度的要求来探讨其相关的问题。
我们来看一下汉字的编码方式。
汉字的编码方式有多种,其中最为常见的是Unicode、GBK、Big5等。
Unicode是一个国际标准,它主要用于整合和统一世界上所有的符号和文字。
而GBK是我国最常用的字符集,它包含了大部分常用汉字和少量的生僻字,是我国计算机领域的标准。
与此相对应的是Big5编码,它是台湾地区所使用的一种传统编码方式。
这些不同的编码方式在一定程度上反映了汉字的传统与现代、国际化与本土化的关系。
进一步来说,汉字的编码方式与其发展历史、文化底蕴以及实际运用之间存在着紧密的关系。
汉字作为中国文字的代表,承载着悠久的历史和深厚的文化内涵。
其编码方式不仅仅是一种技术手段,更是对于汉字所承载的文化价值和民族认同的体现。
我们在选择和规范汉字的编码方式时,需要全面考量文化传承、技术发展和国际交流的多重需求,确保汉字得到妥善的保护和传承。
我们还需要深入思考汉字的编码方式对于教育、出版、文化创意产业等方面的影响和作用。
随着信息化技术的发展,汉字的编码方式不仅仅是影响计算机输入、网页显示等技术领域,更是对于教育教学、文学创作、文化传播等领域产生着深远的影响。
我们需要在汉字的编码方式上进行深入的评估和探讨,更好地发挥其在各个领域中的作用和效果。
在总结和回顾上述内容时,我们可以清晰地看到汉字的编码方式是一个涵盖文化、技术、教育等多个领域的综合话题。
其深度和广度不仅需要我们全面理解其相关知识和背景,更需要我们具备跨学科、跨领域的能力来进行分析和思考。
个人而言,我认为汉字的编码方式是一个值得我们深入研究和关注的话题,它不仅关乎我国的文化传承和软实力的提升,更关乎我们对于技术发展和人文精神的综合理解。
汉字编码的原理

同时补充增加输入:
汉字编码的原理:
汉字编码是一种将汉字转换成计算机可以识别的二进制代码的过程。
在汉字编码中,通常采用两种方式:拼音编码和字形编码。
拼音编码是根据汉字的拼音来编码的。
例如,汉字“中”的拼音是“zh ōng”,将其转换成二进制代码即可。
这种编码方式简单易学,但缺点是重码较多,即有许多不同的汉字可能有相同的拼音。
字形编码则是根据汉字的字形来编码的。
这种方式需要将汉字的字形进行一定的处理,转换成计算机可以识别的二进制代码。
这种编码方式能够避免重码问题,但缺点是编码过程较为复杂,需要一定的计算机技术知识。
目前,汉字编码标准主要有GB2312、GBK、GB18030等。
其中,GB2312是最早的汉字编码标准,包含了常用汉字和符号,适用于简体中文;GBK是在GB2312的基础上扩展了更多的汉字和符号,适用于简体中文和繁体中文;GB18030则是目前最完整的汉字编码标准,包含了几乎所有的汉字和符号,适用于简体中文、繁体中文以及少数民族文字。
总之,汉字编码是计算机处理汉字的基础,对于计算机语言的发展和应用具有重要意义。
汉字编码标准
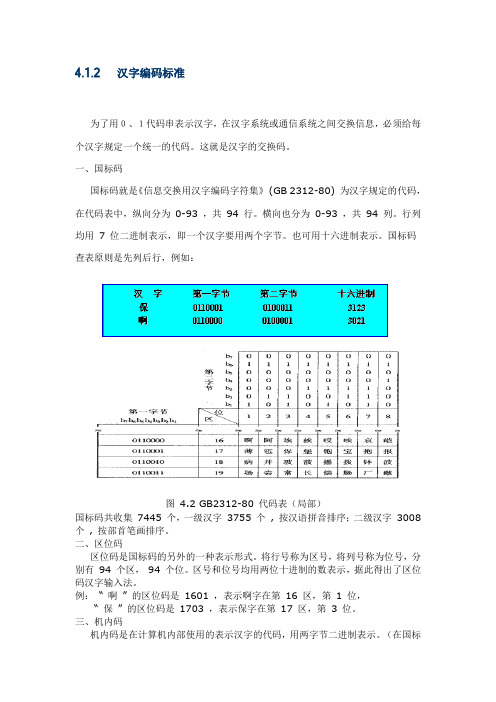
4.1.2 汉字编码标准为了用0、1代码串表示汉字,在汉字系统或通信系统之间交换信息,必须给每个汉字规定一个统一的代码。
这就是汉字的交换码。
一、国标码国标码就是《信息交换用汉字编码字符集》(GB 2312-80) 为汉字规定的代码,在代码表中,纵向分为0-93 ,共94 行。
横向也分为0-93 ,共94 列。
行列均用7 位二进制表示,即一个汉字要用两个字节。
也可用十六进制表示。
国标码查表原则是先列后行,例如:图 4.2 GB2312-80 代码表(局部)国标码共收集7445 个,一级汉字3755 个, 按汉语拼音排序;二级汉字3008 个, 按部首笔画排序。
二、区位码区位码是国标码的另外的一种表示形式。
将行号称为区号,将列号称为位号,分别有94 个区,94 个位。
区号和位号均用两位十进制的数表示,据此得出了区位码汉字输入法。
例:“ 啊” 的区位码是1601 ,表示啊字在第16 区,第 1 位,“ 保” 的区位码是1703 ,表示保字在第17 区,第 3 位。
三、机内码机内码是在计算机内部使用的表示汉字的代码,用两字节二进制表示。
(在国标码每个字节前添1 就是机内码,添1 是为了确保与英文字符区分开)。
输入汉字→国标码( 区位码) →机内码→存储转换关系:十六进制的区位码+ 2020H →国标码十六进制的国标码+ 8080H →机内码8080H 等于二进制的l000000010000000 ,国标码加上8080H ,可以保证机内码每个字节首位均为 1 。
例:“ 啊” 的区位码是:1601 转换成十六进制10011001 +2020=3021 (国标码)再转换成机内码:3021+8080=B0A1二进制表示为1011000010100001 (B0A1 )中山市港口理工学校计算机科温金辉。
我国已颁布的汉字编码标准 -回复

我国已颁布的汉字编码标准-回复汉字编码是现代信息技术中非常重要的一部分,它为计算机处理中文文字提供了标准化的方法。
我国在发展汉字编码方面做出了巨大的努力,已颁布了多种汉字编码标准。
本文将一步一步地回答关于我国已颁布的汉字编码标准的问题,并对每个标准进行详细介绍。
1. 什么是汉字编码标准?汉字编码标准是为了使计算机能够准确地处理中文文字而制定的规范。
它定义了每个汉字在计算机系统中的唯一编码,使得计算机可以根据编码来识别、存储和传输汉字。
2. 请介绍一下GB2312编码。
GB2312编码是我国最早的一种汉字编码标准,于1980年发布。
它共收录了包括6763个简体汉字在内的7445个字符。
GB2312采用了双字节表示方式,其中第一个字节的范围是0xA1至0xF7,第二个字节的范围是0xA1至0xFE。
这种编码标准在早期计算机系统中得到广泛应用,但由于字符集较小、无法涵盖繁体字等问题,逐渐被后续标准所取代。
3. 请介绍一下GBK编码。
GBK编码是GB2312的扩展版本,于1995年发布。
GBK编码在GB2312基础上增加了包括繁体汉字和生僻字在内的21886个字符,总共包含了21003个汉字和682个其他符号。
GBK编码同样采用了双字节表示方式,但第一个字节的范围是0x81至0xFE,第二个字节的范围是0x40至0xFE。
这种编码在多数计算机系统中得到了广泛应用,同时也作为其他后续编码标准的基础。
4. 请介绍一下GB18030编码。
GB18030编码是我国当前最新的一种汉字编码标准,于2005年发布。
GB18030编码不仅是GBK编码的扩展版本,还兼容了Unicode编码。
它收录了27484个汉字,同时支持繁体汉字、日韩汉字以及其他的国际字符。
GB18030编码同样采用了双字节和四字节表示方式,具有很高的兼容性和扩展性。
这种编码标准广泛应用于现代计算机和操作系统中。
5. 请介绍一下Unicode编码。
Unicode编码是一种全球通用的字符编码标准,用于表示世界上几乎所有的字符和符号。
汉字字符的编码范围 -回复

汉字字符的编码范围-回复汉字字符的编码范围,是指用于表示汉字的字符编码的范围。
在计算机中,常用的汉字字符编码方式有GBK、GB2312、Big5、Unicode等。
这些编码方式用于将汉字字符转换为计算机可以识别和储存的数字代码,以便于计算机进行处理和显示。
首先,让我们来了解一下GBK编码和GB2312编码。
GBK编码是中国国家标准GB 2312-1980的扩展,包含了全部的中文汉字字符以及繁体汉字;GB2312编码是最早的汉字字符集,只包含了简体中文的6763个常用字。
它们的编码范围分别是0x8140至0xFEFE和0xA1A1至0xFEFE。
在计算机发展的过程中,为了统一不同国家和地区的字符编码,出现了Unicode编码,它使用16位或32位来映射世界上几乎所有的字符,包括汉字。
Unicode的编码范围是0x4E00到0x9FA5,这个范围包含了绝大部分的中文汉字。
然而,由于Unicode编码通常使用16位字符表示,这导致了一些问题,比如存储空间的浪费。
为了解决这个问题,出现了UTF-8编码。
UTF-8是一种针对Unicode的可变长度字符编码,可以用一个字节或多个字节来表示一个字符,根据字符的不同而变化。
对于汉字,UTF-8编码通常使用3个字节表示。
UTF-8编码的汉字字符范围是0xE4B880至0xEEA5BF。
除了以上介绍的常用编码方式外,还有一种比较特殊的编码方式是Big5编码。
Big5编码主要用于繁体中文,它的字符范围覆盖了繁体中文的所有字符。
Big5编码的汉字字符范围是0xA440至0xC67E和0xC940至0xF9D5。
对于这些不同的汉字字符编码范围,计算机内部会将汉字字符转换为对应的编码值进行存储和处理。
当需要显示汉字时,计算机则会根据字符编码值,选择对应的字形进行显示。
这也是为什么在不同的字符编码下,同一个字符可能会有不同的显示效果。
总结起来,汉字字符的编码范围包括GBK编码的0x8140至0xFEFE,GB2312编码的0xA1A1至0xFEFE,Unicode编码的0x4E00至0x9FA5,UTF-8编码的0xE4B880至0xEEA5BF,以及Big5编码的0xA440至0xC67E和0xC940至0xF9D5。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
汉字编码标准与识别(三) 汉字编码标准与识别(三)内码转换表的来源与制作由于历史和地域的原因,电脑里的中文标准有不少种共存于Internet中。
这是现实。
因此出现了内码转换。
这方面的程序现在有不少。
不过大多是MS Windows的版本,并且有的毛病不少,所以有必要制作一个完整些的内码转换表。
资料来源自从Unicode/ISO10646/GB13000标准出现后,这项工作变得简单和繁琐。
因此制作转换表时有一个准则:以国际和国家标准为基准,参考有影响的商业公司的转换表,个人和小软件次之。
下面是资料的来源:一)国际和国家标准组织国际标准组织Unicode()提供了GB<=>Unicode转换表:ftp:///Public/MAPPINGS/EASTASIA/GBBIG5<=>Unicode转换表:ftp:///Public/MAPPINGS/EASTASIA/OTHERJIS<=>Unicode转换表:ftp:///Public/MAPPINGS/EASTASIA/JISKSC<=>Unicode转换表:ftp:///Public/MAPPINGS/EASTASIA/KSC因为GBK不是国家标准,所以Unicode并没有提供GBK<=>Unicode的转换表,而只是采用了Microsoft的code page的一个版本:ftp:///Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/CP{936,950}.TXT中国国家标准网入门太难,须8000元/个人。
因此没有得到正式的GB2312-1980和GB13000-1993的标准。
二)商业公司2.1方正集团字体部/fontweb/因为方正是产,学,研的综合体,在排版和字体领域奋斗多年,有很特殊的地位。
他们提供的转换表,几乎可以等同国家标准。
GB2312标准:/fontweb/gb2312.htmGBK标准:/fontweb/gbk.htmGB<=>BIG5转换表:/fontweb/download/Gb-big5.tabGBK<=>BIG5转换表:/fontweb/download/Gbk-big5.tab2.2Microsoft/Microsoft是谁也忽略不了的。
有时候就算是他们错了,最后也是对的。
在有些英文资料里把GBK说成是Microsoft制订的。
Microsoft从商业角度出发,提供的是code pages:GBK字形表:/typography/unicode/936gif.zipGBK<=>Unicode转换表:/typography/unicode/936.txtBIG5字形表:/typography/unicode/950gif.zipBIG5<=>Unicode转换表:/typography/unicode/950.txt在Windows97/98中文版里也提供了些资料:GBK标准:windowsGBK.txtcode pages:windowssystemcp{932,936,949,950}.nls三)个人与共享软件有不少个人和小团体也在这方面进行了探索。
3.1 TextPro /~buddha因为他们特殊的需求,TextPro确实在BIG5=>GBK/GB转换方面有独到之处。
同时还有个GBK(繁体)=>GB(简体)转换表,很有特色。
因为繁体=>简体是多对一的映射,因此很难有简体=>繁体的转换表。
特别是基于字到字的映射的转换是不可能的。
目前已有人进行基于词典和上下文的词到词的映射。
有兴趣可以看/articles/c2c.html3.2 Stone Chi 提供了基于RichWin的内码转换表。
收集了不少的资料,对内码标准有较深的了解。
同时还有一个中文检索软件值得一尝。
3.3 NJStar 和MagicWin .my他们在这领域有些日子了。
不过转换表不是很全。
制作根据上面的准则和排列次序制作。
如果上一级有空白,就要下一级填补;如果有冲突,就以上一级的为准。
一)根据Unicode的GB<=>Unicode与BIG5<=>Unicode转换表制作GB<=>BIG5 转换表。
二)根据Microsoft的GBK<=>Unicode与BIG5<=>Unicode转换表制作GBK<=>BIG5转换表。
至此,基于标准的转换实际已经完成。
Unicode的特点就是一字一码,一码一字。
各个国家和地区的汉字标准已编入Unicode的,并有相同的Unicode 码的汉字,就是叫CJK认同汉字。
但有些汉字因为种种原因而未能得到认同,如果制作这些汉字的转换表,只能是基于实用的,有可能多对多映射的转换表。
三)使用方正的GBK<=>BIG5转换表填充(一)的GB<=>BIG5转换表。
四)使用Microsoft的GBK<=>BIG5转换表填充(三)的GBK<=>BIG5转换表。
五)使用TextPro和stonec的GBK<=>BIG5转换表填充(四)的GBK<=>BIG5转换表。
六)NJStar的转换表虽然不是很全,但在BIG5=>GBK转换表中的C6行后半段和C7,C8行却相当完整。
上面的转换表在这里不是空白就是很少转换。
可能这个区域是属于扩充符号区,可有可无。
为保险起见,使用NJStar填充这个区域。
七)校验。
通过电脑对码表进行校验,发现在汉字编码方面基本一致。
有冲突的地方基本上是对制表符的理解不同造成的。
八)目测校验。
也就是用肉眼一个字一个字的检查。
这是最重要的一步。
但因为学识和精力有限,未能做到这一步。
UnicodeUnicode is a worldwide character-encoding standard. Windows NT, Windows 2000, and Windows XP useit exclusively at the system level for character and string manipulation. Unicode simplifies localization ofsoftware and improves multilingual text processing. By implementing it in your applications, you canenable the application with universal data exchange capabilities for global marketing, using a singlebinary file for every possible character code.Unicode defines semantics for each character, standardizes script behavior, provides a standardalgorithm for bidirectional text, and defines cross-mappings to other standards. Among the scriptssupported by Unicode are Latin, Greek, Han, Hiragana, and Katakana. Supported languages include, butare not limited to, German, French, English, Greek, Chinese, and Japanese.Unicode can represent all of the world's characters in modern computer use, including technical symbolsand special characters used in publishing. Because each Unicode code value is 16 bits wide, it is possibleto have separate values for up to 65,536 characters. Unicode-enabled functions are often referred to as"wide-character" functions. Note that the implementation of Unicode in 16-bit values is referred to asUTF-16. For compatibility with 8- and 7-bit environments, UTF-8 and UTF-7 are two transformations of16-bit Unicode values. For more information, see The Unicode Standard, Version 2.0.Windows supports applications that use either Unicode or the regular ANSI character set. Mixed use inthe same application is also possible. Adding Unicode support to an application is easy, and you can evenmaintain a single set of sources from which to compile an application that supports either Unicode or the Windows ANSI character set.Functions support Unicode by assigning its strings a specific data type and providing a separate set of entry points and messages to support this new data type. A series of macros and naming conventions make transparent migration to Unicode, or even compiling both non-Unicode and Unicode versions of an application from the same set of sources, a straightforward matter.Implementing Unicode as a separate data type also enables the compiler's type checking to ensure that only Unicode parameters are used with functions expecting Unicode strings.GBK字符集是对GB2312-80的一个扩展,达到GB13000的所有的20902个字符,里面还包含了繁体汉字,总共20975个汉字字符,911个非汉字符号和1894个用户定义字符(如偏旁、部首、笔画等)。