经济计量学精要(第4版)(美)古扎拉蒂
古扎拉蒂计量经济学第四版讲义Ch6 Multicollinearity

∗
∑c x
j =2 j
K
∗ j
≅0
3.32
符号 ≅ 表示,如果右端确实等于 0,那么这种线性依赖关系就是 exact,而且 X ' X 不再存在。
2
Use of eigenvalues and eigenvectors to explain multicollinearity 考虑相关系数形式的 X ' X 矩阵。 我们知道,总存在一个正交矩阵(orthogonal matrix) V = [ v 2 v 3 " v K ] ,使得
−1 2
( X ' X)
−1
中的 ( X ' X ) 不存在或无限大。
−1
课本以三元回归模型为例,写出β系数的表达式,比如
b2
∑ ( y − y )( x − x ) ∑ ( x − x ) − ∑ ( y − y )( x − x ) ∑ ( x − x )( x = x − x )( x − x ) ∑( x − x ) ∑(x − x ) − ∑ (
2)实际结果 In case of near or high multicollinearity, one is likely to encounter the following consequences: 1. Although BLUE, the OLS estimators have large variances and covariances, making precise estimation difficult. 2. Due to consequence 1, the confidence intervals tend to be much wider, leading to the acceptance of the zero null hypothesis more readily. 3. Also due to consequence 1, the t ratio of one or more coefficients tends to be statistically
古扎拉蒂计量经济学第四版讲义Ch9 Model Specification

第九章模型设定Model Specification and Diagnostic Testing1. Introduction假如模型没有被正确设定,我们会遇到model specification error或model specification bias 问题。
本章主要回答这些问题:1、选择模型的标准是什么?2、什么样的模型设定误差会经常遇到?3、模型设定误差的后果是什么?4、有那些诊断工具来发现模型设定误差?5、如果诊断有设定误差,如何校正,有何益处?6、怎样评估相互竞争模型的表现(model evaluation)?Model Selection Criteria这是笼统的模型选择标准:1、利用该模型进行预测在逻辑上是可能的;2、模型的参数具有稳定性,否则,预测就很困难。
弗里德曼说:模型有效性的唯一检验标准就是比较模型的预测是否与经验一致。
3、模型要与经济理论一致。
4、解释变量必须与误差项不相关。
5、模型的残差必须是白噪声;否则就存在模型设定误差。
6、最后选择的模型应该涵盖其它可能的竞争模型;也就是说,其他模型不应该比所选模型的表现更好。
Types of specification errors大概有这几种设定误差:设定误差之一:所选模型忽略了重要的解释变量(该解释变量被包含在模型误差中)设定误差之二:所选模型包含了不必要或不相关的解释变量设定误差之三:所选模型具有错误的方程形式(比如y采用了不该采用的对数转换)设定误差之四:被解释变量and/or解释变量测量偏差(所用数据相对于真实值有偏差)导致的误差(commit the errors of measurement bias)设定误差之五:随机误差项进入模型的形式不对引起的误差(比如是multiplicatively还是additively)The assumption of the CLRM that the econometric model is correctly specified has two meanings. One, there are no equation specification errors, and two, there are no model specification errors.上面概括的五种设定误差称为equation specification errors。
计量经济学精要习题参考答案(第四版)

计量经济学(第四版)习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2 NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设 120:0=μH备择假设 120:1≠μH 检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即此样本不是取自一个均值为120元、标准差为10元的正态总体。
计量经济学古扎拉蒂课后答案

计量经济学古扎拉蒂课后答案【篇一:计量经济学考试习题及答案】双对数模型 lny?ln?0??1lnx??中,参数?1的含义是()a.y关于x的增长率b.y关于x的发展速度c. y关于x的弹性d. y关于x 的边际变化2、设k为回归模型中的参数个数,n为样本容量。
则对多元线性回归方程进行显著性检验时,所用的f统计量可表示为()ess(/n?k)r2/(k?1)b. a.2rss(/k?1)(1?r)(/n?k)ess(/k?1)r2(/n-k)d.c. tss(/n?k)(1?r2)(/k?1)3、回归模型中具有异方差性时,仍用ols估计模型,则以下说法正确的是()a. 参数估计值是无偏非有效的b. 参数估计量仍具有最小方差性c. 常用f 检验失效d. 参数估计量是有偏的4、利用德宾h检验自回归模型扰动项的自相关性时,下列命题正确的是()a. 德宾h检验只适用一阶自回归模型b. 德宾h检验适用任意阶的自回归模型c. 德宾h 统计量渐进服从t分布d. 德宾h检验可以用于小样本问题5、一元线性回归分析中的回归平方和ess的自由度是()a. nb. n-1c. n-kd. 16、已知样本回归模型残差的一阶自相关系数接近于1,则dw统计量近似等于( )a. 0b. 1 c. 2 d. 47、更容易产生异方差的数据为 ( )a. 时序数据b. 修匀数据c. 横截面数据d. 年度数据8、设m为货币需求量,y为收入水平,r为利率,流动性偏好函数为?2分别是?1 、?2的估计值,则根据经济理m??0??1y??2r??,又设?1、论,一般来说(a )a. ?1应为正值,?2应为负值b. ?1应为正值,?2应为正值c. ?1应为负值,?2应为负值d. ?1应为负值,?2应为正值9、以下选项中,正确地表达了序列相关的是()a.co(v?i,?j)?0,i?jb.co(v?i,?j)?0,i?j ??????????vxi,?j)?0,i?j c.cov(xi,xj)?0,i?jd.co(10、在一元线性回归模型中,样本回归方程可表示为()a. yt??0??1??tb.yt?e(yt/x)??ic. yt??0??1xtd. e(yt/xt)??0??1xt11、对于有限分布滞后模型 ???yt????0xt??1xt?1??2xt?2????kxt?k??t在一定条件下,参数?i 可近似用一个关于i的阿尔蒙多项式表示(i?0,1,2,?,m),其中多项式的阶数m必须满足() ?a.mk b.m=kc.mkd.m?k12、设?t为随机误差项,则一阶线性自相关是指()a.cov(?t,?s)?0(t?s) b. ?t???t?1??tc. ?t??1?t?1??2?t?2??td. ?t??2?t?1??t13、把反映某一总体特征的同一指标的数据,按一定的时间顺序和时间间隔排列起来,这样的数据称为()a. 横截面数据b. 时间序列数据c. 修匀数据d. 原始数据14、多元线性回归分析中,调整后的可决系数r与可决系数r2之间的关系()22n?122a.?1?(1?r) b. ?r n?k22n?k2 c. ?0 d. ?1?(1?r) n?115、goldfeld-quandt检验法可用于检验( )a.异方差性b.多重共线性c.序列相关d.设定误差16、用于检验序列相关的dw统计量的取值范围是( )a.0?dw?1b.?1?dw?1c.?2?dw?2 d.0?dw?417、如果回归模型中解释变量之间存在完全的多重共线性,则最小二乘估计量的值为()a.不确定,方差无限大b.确定,方差无限大c.不确定,方差最小d.确定,方差最小18、应用dw检验方法时应满足该方法的假定条件,下列不是其假定条件的为()a.解释变量为非随机的b.被解释变量为非随机的c.线性回归模型中不能含有滞后内生变量d.随机误差项服从一阶自回归二、多项选择题1、古典线性回归模型的普通最小二乘估计量的特性有()a. 无偏性b. 线性性c. 最小方差性d. 不一致性e. 有偏性2、如果模型中存在自相关现象,则会引起如下后果()a.参数估计值有偏b.参数估计值的方差不能正确确定c.变量的显著性检验失效d.预测精度降低e.参数估计值仍是无偏的????x的特点() ???3、利用普通最小二乘法求得的样本回归直线yt12ta. 必然通过点(,)b. 可能通过点(,)?的平均值与y?的平均值相等 c. 残差et的均值为常数 d. ytte. 残差et与解释变量xt之间有一定的相关性4、广义最小二乘法的特殊情况是()a.对模型进行对数变换 b.加权最小二乘法c.数据的结合d.广义差分法e.增加样本容量5、计量经济模型的检验一般包括内容有()a、经济意义的检验b、统计推断的检验c、计量经济学的检验d、预测检验e、对比检验三、判断题(判断下列命题正误,并说明理由)1、在实际中,一元回归几乎没什么用,因为因变量的行为不可能仅由一个解释变量来解释。
古扎拉蒂《经济计量学精要》(第4版)笔记和课后习题详解-双变量模型:假设检验(圣才出品)

第3章双变量模型:假设检验3.1 复习笔记一、古典线性回归模型古典线性回归模型假定如下:假定1:回归模型是参数线性的,但不一定是变量线性的。
回归模型形式如下:Y i=B1+B2X i+u i这个模型可以扩展到多个解释变量的情形。
假定2:解释变量X与扰动误差项u不相关。
但是,如果X是非随机的(即为固定值),则该假定自动满足。
即使X值是随机的,如果样本容量足够大,也不会对分析产生严重影响。
假定3:给定X,扰动项的期望或均值为零。
即E(u|X i)=0(3-1)假定4:u i的方差为常数,或同方差,即var(u i)=σ2(3-2)假定5:无自相关假定,即两个误差项之间不相关。
即:cov(u i,u j)=0,i≠j(3-3)无自相关假定表明误差u i是随机的。
由于假定任何两个误差项不相关,所以任何两个Y值也是不相关的,即cov(Y i,Y j)=0。
由于Y i=B1+B2X i+u i,则给定B值和X值,Y 随u的变化而变化。
因此,如果u是不相关的,则Y也是不相关的。
假定6:回归模型是正确设定的。
换句话说,实证分析的模型不存在设定偏差或设定误差。
这一假定表明,模型中包括了所有影响变量。
二、普通最小二乘估计量的方差与标准误有了上述假定就能够估计出OLS估计量的方差和标准误。
由此可知,教材式(2-16)和教材式(2-17)给出的OLS估计量是随机变量,因为其值随样本的不同而变化。
这种抽样变异性通常由估计量的方差或其标准误(方差的平方根)来度量。
教材式(2-16)和式(2-17)中OLS估计量的方差及标准误是:(3-4)(3-5)(3-6)(3-7)其中,var表示方差,se表示标准误,σ2是扰动项u i的方差。
根据同方差假定,每一个u i具有相同的方差σ2。
一旦知道了σ2,就很容易计算等式右边的项,从而求得OLS估计量的方差和标准误。
根据下式估计σ2:(3-8)其中,σ∧2是σ2的估计量,是残差平方和,是Y的真实值与估计值差的平方和,即()122212var ibiXbn xσσ==∑∑1se()b=()22222varbibxσσ==∑()2se b=22ˆ2ienσ=−∑2ie∑n -2称为自由度,可以简单地看作是独立观察值的个数。
古扎拉蒂《经济计量学精要》(第4版)笔记和课后习题详解-自相关:如果误差项相关会有什么结果(圣才出品

量对其滞后一期的回归。
(2)德宾-沃森 d 统计量的定义
n
( ) et − et−1 2
d = t=2 n
et 2
t =1
5 / 28
(10-3)
圣才电子书 十万种考研考证电子书、题库视频学习平台
即残差递差的平方和与残差平方和的比值。注意:在计算 d 统计量分子时,其样本容量
1 / 28
圣才电子书 十万种考研考证电子书、题库视频学习平台
图 10-1 自相关的模式 3.自相关产生的原因 (1)惯性 大多数经济时间序列的一个显著特征就是惯性或者说是迟滞性,即各经济变量的观测值 在时间前后存在着关联性。因此,在涉及时间序列数据的回归方程中,连续的观察值之间很 可能是互相依赖或是相关的。 (2)模型设定误差 不正确的模型设定是指本应纳入模型的重要变量未纳入模型或是模型选择了错误的函 数形式,如果发生这样的模型设定误差,得到的残差则会呈现出系统模式。一个简单的检验 方法是将遗漏变量纳入模型,判定残差是否仍然呈现系统模式。如果不存在系统模式,则序
可见,自相关的后果与异方差相似,也是严重的。因此,与异方差情形相同,在实际应 用中必须确定是否存在自相关问题。
三、自相关的诊断 1.图形法 与异方差情形相同,通过直接观察 OLS 残差 e 来判断误差项 u 中是否存在自相关。有 多种不同的残差图形的检验方法。 (1)残差 e 对时间的散点图 可以用残差对时间作图,如果随着时间的变化,残差呈现出某种有规律的趋势,则可能 存在着自相关。图 10-2 是回归的残差关于时间的时序图,从图可以看出:残差 e 并不是随 机分布的,而是呈现出明显的变动模式——开始是正的,接着变成负的,然后是正的,再然 后是负的,最后又是正的。图形展示了这样一种趋势:残差的递差之间正相关,表明序列存 在着正的自相关。
计量经济学精要习题参考答案(第四版)

计量经济学(第四版)习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2 NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设 120:0=μH备择假设 120:1≠μH2检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即此样本不是取自一个均值为120元、标准差为10元的正态总体。
计量经济学精要第四版课后习题答案(2020年10月整理).pdf
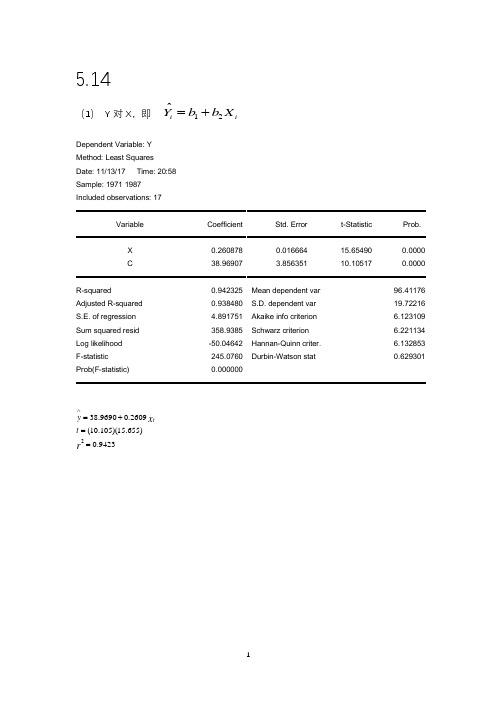
5.14(1) Y 对X ,即12ˆi iY b b X =+Dependent Variable: Y Method: Least Squares Date: 11/13/17 Time: 20:58 Sample: 1971 1987 Included observations: 17Variable Coefficient Std. Error t-Statistic Prob.X 0.260878 0.016664 15.65490 0.0000 C38.969073.85635110.10517 0.0000R-squared0.942325 Mean dependent var 96.41176 Adjusted R-squared 0.938480 S.D. dependent var 19.72216 S.E. of regression 4.891751 Akaike info criterion 6.123109 Sum squared resid 358.9385 Schwarz criterion 6.221134 Log likelihood -50.04642 Hannan-Quinn criter. 6.132853 F-statistic 245.0760 Durbin-Watson stat 0.629301Prob(F-statistic) 0.0000009423.0)655.15)(105.10(2609.09690.382==+=∧r x t y t(2)InY 对InX ,即 12ˆi iInY b b InX =+9642.0)090.20)(954.8(ln 5890.04041.1ln 2==+=∧r x t y tDependent Variable: LNY Method: Least Squares Date: 11/13/17 Time: 21:40 Sample: 1971 1987 Included observations: 17Variable Coefficient Std. Error t-Statistic Prob.C 1.404051 0.156813 8.953649 0.0000 LNX0.5889650.02931720.08981 0.0000R-squared0.964166 Mean dependent var 4.547848 Adjusted R-squared 0.961777 S.D. dependent var 0.213165 S.E. of regression 0.041675 Akaike info criterion -3.407698 Sum squared resid 0.026052 Schwarz criterion -3.309673 Log likelihood 30.96543 Hannan-Quinn criter. -3.397954 F-statistic 403.6007 Durbin-Watson stat 0.734161Prob(F-statistic)0.000000(3),即 12i iDependent Variable: LNY Method: Least Squares Date: 11/13/17 Time: 21:42 Sample: 1971 1987 Included observations: 17Variable Coefficient Std. Error t-Statistic Prob.C 3.931578 0.046430 84.67764 0.0000 X0.0027990.00020113.94972 0.0000R-squared0.928433 Mean dependent var 4.547848 Adjusted R-squared 0.923662 S.D. dependent var 0.213165 S.E. of regression 0.058896 Akaike info criterion -2.715956 Sum squared resid 0.052031 Schwarz criterion -2.617930 Log likelihood 25.08562 Hannan-Quinn criter. -2.706212 F-statistic 194.5946 Durbin-Watson stat 0.529132Prob(F-statistic) 0.0000009284.0)950.13)(678.84(0028.09316.3ln 2==+=∧r X t y t(4),即 12i iDependent Variable: Y Method: Least Squares Date: 11/13/17 Time: 21:43 Sample: 1971 1987 Included observations: 17Variable Coefficient Std. Error t-Statistic Prob.C -192.9661 16.38000 -11.78059 0.0000 LNX54.212573.06227817.70335 0.0000R-squared0.954325 Mean dependent var 96.41176 Adjusted R-squared 0.951280 S.D. dependent var 19.72216 S.E. of regression 4.353186 Akaike info criterion 5.889824 Sum squared resid 284.2535 Schwarz criterion 5.987849 Log likelihood -48.06350 Hannan-Quinn criter. 5.899568 F-statistic 313.4086 Durbin-Watson stat 0.610822Prob(F-statistic) 0.0000009542.0)703.17)(781.11(ln 2126.549661.1922=−=+−=∧r X t Y t解:1.XY∆∆=1ˆβ斜率说明X 每变动一个单位,Y 的绝对变动量;2. E XX Y Y =∆∆=//ˆ1β斜率便是弹性系数; 3. XY Y ∆∆=/ˆ1β斜率表示X 每变动一个单位,Y 的均值的瞬时增长率; 4,. XX Y/ˆ1∆∆=β斜率表示X 的相对变化对Y 的绝对量的影响。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
⭐️经济计量学精要(第4版)/(美)古扎拉蒂
大佬点个赞支持一下呗ヽ(´▽`)ノヽ(´▽`)ノヽ(´▽`)ノ
经济计量学精要(第4版)/(美)古扎拉蒂
•
综述
1.1 什么是经济计量学
1.2 为什么要学习经济计量学
1.3 经济计量学方法论
经济计量分析步骤:
(1)建立一个理论假说
(2)收集数据
(3)设定数学模型
线性回归模型为例
线性回归模型中,等式左边的变量称为应变量,等式右边的变量称为自变量或解释变量。
线性回归分析的主要目标就是解释一个变量(应变量)与其他一个或多个变量(解释变量)之间的行为关系。
简单数学模型
•
(4)设立统计或经济计量模型
误差项u
•
u代表随机误差项,简称误差项。
u包括了X以外其他所有影响Y,但并未在模型中具体体现的因素以及纯随机影响。
(5)估计经济计量模型参数
线性回归模型常用最小二乘法估计模型中的参数
^读做"帽",表示某的估计值
(6)核查模型的适用性:模型设定检验
(7)检验源自模型的假设:假设检验
(8)利用模型进行预测
数据类型
时间序列数据:按时间跨度收集得到的
截面数据:一个或多个变量在某一时间点上的数据集合
合并数据:既包括时间序列数据又包括截面数据
面板数据:也称纵向数据、围观面板数据,即同一个横截面单位的跨期调查数据
模型因果关系
统计关系无论有多强,有多紧密,也决不能建立起因果关系,如果两变量存在因果关系,则一定建立在某个统计学之外的经济理论基础之上。
第一部分线性回归模型
2.1回归的含义
回归分析的主要目的:根据样本回归函数SRF估计总体回归函数PRF
2.2总体回归函数(PRF):假想一例
总体回归线给出了对应于自变量的每个取值相应的应变量的均值。
(总体回归线表明了Y的均值与每个X的变动关系)PRL
•
E(Y|xi)表示与给定x值相对应的Y的均值。
下标i代表第i个子总体。
B1、B2称为参数,也称为回归系数。
B1称为截距,B2称为斜率。
斜率系数度量了X每变动一单位,Y( 条件)均值的变化率。
2.3总体回归函数的统计或随机设定
随机或统计回归总体函数PRF
•
ui随机误差项,其值无法先验确定,通常用概率分布描述随机变量。
2.4 随机误差项的性质
误差项代表了未纳入模型变量的影响;
即使模型中包括了决定数学分数的所有变量,其内在随机性也不可避免;人类行为并不是完全可预测的或完全理性的。
因而,u反映了人类行为的这种内在随机性。
u还代表了度量误差,如数据的四舍五入;
“奥卡姆剃刀原则”:描述应当尽量简单,只要不遗漏重要的信息。
即使知道其他变量可能会对Y有影响,但这些变量的综合影响是有限的、非确定性的,可以把这些次要因素归人随机项u。
2.5 样本回归函数
样本回归函数SRF
•
估计量或样本统计量是总体参数的估计公式,估计量的某一取值称为估计值。
随机样本回归函数SRF
•
ei残差,可作为ui的估计量,表示Y的实际值与样本回归得到的估计值的差。
回归分析的主要目的:根据样本回归函数SRF估计总体回归函数PRF。