双语平行语料库对齐技术述评
利用Trados进行平行语料库的句对齐

就在几年前 , 语 料 库研 究 对 高校 生 , 甚 至 许 多 高 校 老 师 而 言 都 是 一 个 新鲜 事 物 。 而 现在 , 随 着 MT I 专 业的 不 断 推 广 , 许 多大 学相继开设 了与语料库研究 相关的课程 , 如“ 语料库语言学 、 计 算 机 辅 助翻 译 ” 等, 众 多高校 老 师 进 入 到这 一 相 对 较 新 的领 域进 行研究 , 一 部 分 高 校 毕 业 生 也 开 始 以 此 方 向作 为 论 文 选 题 , 语 料 库 研 究 正 以 蓬 勃 之 势迅速发展。 对 于语 料库 的定 义 , 杨 慧 中 指 出, 所谓 语 料 库 是 指 在随 机 采 样 的基 础 上 收 集 的 有 代 表 性 的真 实语 言 材 料 的 集 合 , 是语言 运用的样 本。 通 过有 关 语 料 库 的论 文统 计 可 以 看 出 , 语 料 库 研 究 实 实 在 在 在 翻 译对 比 、 翻译教学 、 译 员培 养 、 语 言 学研 究 等方 面 发 挥 了 重 要 作 用 。目前 一 些 大 型 翻译公 司 , 如传神 , 都 有 专 门 的 语 料 库 部 门, 并 雇 用 专 员 负 责 入 库 文 件 的 校 对 和 录 入 工作 。 笔 者 在 这 里所 提 及 的 语料 库 , 主 要 是 指双 语 语 料 库 下 的 一 个 类 别 , 即 平 行 语 料库。 平 行 语 料 库 中含 有 大 量 真 实 译 语 言 研 究 和 语 言 对 比研 究提 供 了 良 好 的 基 础 。
还可在“ 匹配 ” 栏 下进 行 设 定 , 提 刘 克 强 也 并 未 明 确 指 出具 体 的 方法 。 对 齐 在 此 之前 , 升 对 齐准 确 率 , 并在“ 导出” 栏 下 选 择 格 式 后 导 出的 t x t 文本如下: <Tr U> 为“ 翻译记 忆库 交换格 式( T MX) ” 。 Wi n A l i g n <Qu a l i t y >8 5 自动 对 源语 文 件 和 目标 语 文 件 进 行 句 对 <Cr U>AL I GN ! 齐, 如 两种 语 言 断 句 一 致 , 则对 齐 准 确率 会 < CR D> 0 4 0 9 201 3, 1 1: 55 非 常高 。 此外 , Wi n Al i g n 支 持手 工调 整 , 调 <S e g L=EN-U S> 1 . 1 4 J OI NT AN D 整 的方 法 也非 常 简 单 。 利 用Wi n Al i g n 将双 SEVER AL LI ABI LI TY 语 文件 完 全对 齐后 , 选择“ 导 出 文件 对 ” , 注 导 出” 栏 中对 格 式 进 行 正 确 选 < S e g L = Z H- C N >{ \ f 3 1 . 1 4 } 共 同的 意 必 须 在 “
平行语料库对齐技术的语言学思考

frf t r t d . Usn u h c n e t ss m b l nta dta sain u i,t i p p rc n l d st a o u u esu y ig s c o c p sa y oi u i n r n lto n t h s a e o cu e h t c
了对齐 的结果 以及 S MT系统 的翻译 质量 。 B
本文首先简要概述了当前平行语料库对齐研究的现状 , 然后从语言学角度出发, 重点结合象征单位
—
孥藤 一 杨 勇 熙 ,
(. 1南京大学 外国语学 院, 南京 20 9 ;. 10 3 2 合肥工业大学 外 国语言学 院, 合肥 20 0 ) 30 9
摘 要 : 双语对齐是平行语料库处理 的基本环节之一 。文章从语 言学角度强调当前 双语对齐研究能够为今后
的工作起到指导作用 。
t e a i n n e u t h u d a q ie u i sa u ,t a h o r et x n a g tt x h u d b l n h l me t r s ls s o l c u r n t t t s h t e s u c e ta d t r e e ts o l e a i — g t g me td n mia l n a p o r t c ls n h t t e q a i n u n iy o h a a s o l lo b n y a c l o p r p i e s ae ,a d t a h u l y a d q a t f t e d t h u d a s e y a t t
s r t ie yt eain n d 1 c u i z db h l me tmo e. n g Ke r s p r l l o p s i n u l l n n ;s b l nt r n lto nt ywo d : a al r u ;bl g a i me t y oi u i;ta sain u i ec i ag m c
上海外语教育出版社英汉双语平行句对语料库的构建

关键 词 平行 语料
语 料库 建设
双语 词典 编纂 系统
上海外语教育出版社( 以下简称“ 外教社” 承担的上海市科委课题“ ) 双语词典编纂系
统 的研发 ” 是上 海市 政府 扶持 辞书 编纂 出版 数 字 化 的重 大科 研 项 目, 该课 题 的总体 目标 是 开发 一个 基 于语料 库 的数字化 双语 词典 编纂 出版 系统 , 子课 题之 一 就是 构建 一 个服 务 于 其 双语词 典编 纂 、 过深 加工 的 、 用 共 时并 在 句 子层 面 对 齐 的英 汉 双语 书 面语 语 料 库 。该 经 通
限制的开放数据。X L的设 计宗 旨是传输数据 , M 使其成为独立 的信息传输与集成工具 。 X L文件 没有 任何预 定义标 签 , M 因其 “ 高度 灵 活 , 展性 强 ” 梁 茂 成等 2 1 ) 扩 ( 00 的特 点 , 在跨
平 台数 据交 换 、 据建模 与 分 析 、 数 网络 服 务等 众 多领 域 得 到 了广 泛 应用 。Jfe e ma在 efyZl r d
D s nn i e Sa d rs( n d ) e g igwt W b tn ad 2 dE . 中这样 描述 X i h ML的开放 性入 软件 工业 界时 , 它给整 个 行业 带 来 了一 场 风暴 。有史 以来 第 一 次 , 这个 世 界 拥 有 了
的在 线辅助语料 库之一 , 为双语词 典编纂提供 英 汉平行 句对例证 , 并为词 典编纂 提
供 语 言 统 计信 息 、 分析 信 息 等 。 文 章 综 述 了该 语 料 库 的 设 计 和 构 建 过 程 , 内容 涉 及 语 料 的 采 集 、 工 、 注 、 索 等 方 面 , 时 也 探 讨 今 后 如 何 进 一 步 开发 与 利 用 该 语 加 标 检 同
机器翻译中的双语对齐和平行数据支持研究

机器翻译中的双语对齐和平行数据支持研究摘要:机器翻译是当今自然语言处理领域的一项重要研究方向。
为了提高机器翻译的性能,双语对齐和平行数据的使用成为研究的关键。
本文首先介绍了双语对齐与平行数据的概念和作用,然后讨论了当前的主要方法和技术,包括基于规则的对齐方法、统计对齐方法和深度学习方法。
最后,还对当前研究中存在的问题和未来研究方向进行了展望。
关键词:机器翻译、双语对齐、平行数据、规则对齐、统计对齐、深度学习1. 引言随着全球化的发展和互联网的普及,人们之间的交流更加频繁,各种语言之间的沟通变得越来越重要。
然而,不同语言之间的差异给交流带来了困难,因此机器翻译作为一种实现跨语言交流的工具变得越来越重要。
机器翻译是将一种语言文本自动转化为另一种语言的过程,其中双语对齐和平行数据的使用是提高机器翻译性能的关键。
2. 双语对齐与平行数据概述双语对齐是指将两种不同语言的文本进行对应的过程,通常是将源语言和目标语言的句子两两对齐。
双语对齐的目的是为了构建平行语料库,即源语言和目标语言之间一一对应的句子对。
平行语料库是机器翻译的重要数据资源,可以用于训练和评估机器翻译系统的性能。
平行数据是指同时包含源语言和目标语言的数据集,可以用于训练机器翻译模型。
平行数据既可以来自于人工创造,也可以来自于互联网上的双语网页、书籍等。
相比于单语数据,平行数据具有更多的信息,可以提供双语之间的对应关系和翻译信息,有助于提高机器翻译的准确性和流畅度。
3. 当前研究方法和技术(1)基于规则的对齐方法基于规则的对齐方法是最早被使用的双语对齐方法之一,它基于语言学规则和对齐规则进行对齐。
该方法通常需要依赖领域专家来定义规则,并且对于词汇差异和句法结构差异的处理较为困难。
然而,基于规则的对齐方法在一些特定领域和语言对上具有较好的性能。
(2)统计对齐方法统计对齐方法是基于统计机器学习的方法,它通过建立统计模型来学习双语对齐的规则。
该方法通过对大规模平行数据进行训练来学习双语对齐的概率模型,然后使用该模型对新的句子进行对齐。
双语平行语料库对齐技术述评

双语平行语料库对齐技术述评对齐的双语语料库在机器翻译、词义消歧和双语词典编撰等领域都非常有用。
语料对齐的单位由大到小,有篇章、段落、句子、短语、词等不同的层次。
粒度越小,提供的语言信息就越多,应用的价值也就越大。
然而平行语料库的自动对齐并非是一件容易的事情。
由于语料大都来自人工翻译,句子之间并不都是一对一的翻译模式,还有一对多、多对多的翻译模式。
这种复杂性加大了对齐的难度,特别是对更细粒度级别的对齐。
由于语言之间存在着差异,找到固定的对应翻译很难,再加上文本预处理工具难以保证处理效果,以及一些电子文本的噪声纷繁复杂,这都增加了对齐的难度。
而对于英汉两种差别很大的语言来说,目前的语料库对齐算法并不一定完全适用于汉英语料库的对齐。
本文首先回顾了当前国外平行语料库的对齐技术,然后分析了国内在对齐中所使用的技术,旨在为本研究所今后构建小型汉英平行语料库提供一个技术支持。
1 目前平行语料库对齐技术的现状1.1 句子级对齐技术在各级对齐研究中,其中最为重要且较为成熟的自动对齐技术是句子一级的对齐。
句子级对齐的方法主要有三种:①基于长度的方法(length-based)(Brown et al,1991; Gale & Church, 1991a);②基于词汇的方法(lexical-based)(Kay & Roscheisen, 1993);③混合法(combination)(Tan & Nagao, 1995; Wu,1994)。
基于长度的方法最早是由Brown和Gale提出,虽然他们的算法都是由源文本中句子长度和译文本中的句子长度有很大的正相关这一观察得出,但其侧重点却不同。
Brown的算法以词为单位计算句子的长度,而Gale和Church则是以字符为单位计算句子的长度。
他们分别用各自的算法对加拿大议会会议所录英法双语语料库进行了对齐实验,准确率达96~97%。
然而该方法在处理复杂句子的对齐(如2∶1或2∶2的句子对齐,或非直译和省略的句子)以及不同语系的句子对齐时,准确率却并不高,而且此算法一旦出错,便不可能自动纠正。
英汉双语平行语料库人工对齐方法说明
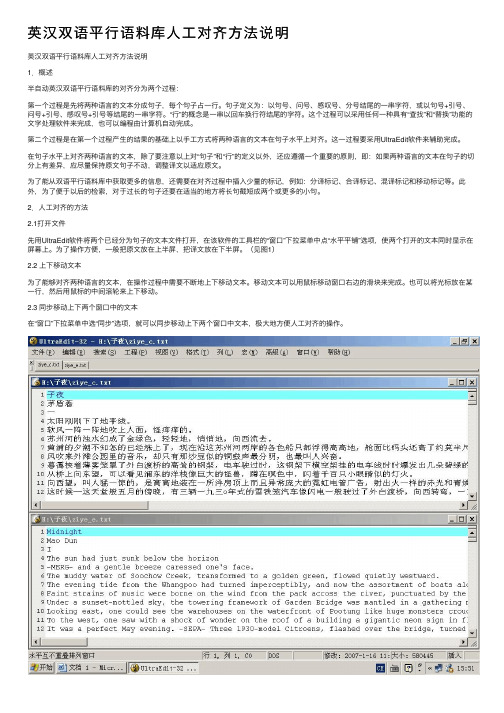
英汉双语平⾏语料库⼈⼯对齐⽅法说明英汉双语平⾏语料库⼈⼯对齐⽅法说明1.概述半⾃动英汉双语平⾏语料库的对齐分为两个过程:第⼀个过程是先将两种语⾔的⽂本分成句⼦,每个句⼦占⼀⾏。
句⼦定义为:以句号、问号、感叹号、分号结尾的⼀串字符,或以句号+引号、问号+引号、感叹号+引号等结尾的⼀串字符。
“⾏”的概念是⼀串以回车换⾏符结尾的字符。
这个过程可以采⽤任何⼀种具有“查找”和“替换”功能的⽂字处理软件来完成,也可以编程由计算机⾃动完成。
第⼆个过程是在第⼀个过程产⽣的结果的基础上以⼿⼯⽅式将两种语⾔的⽂本在句⼦⽔平上对齐。
这⼀过程要采⽤UltraEdit软件来辅助完成。
在句⼦⽔平上对齐两种语⾔的⽂本,除了要注意以上对“句⼦”和“⾏”的定义以外,还应遵循⼀个重要的原则,即:如果两种语⾔的⽂本在句⼦的切分上有差异,应尽量保持原⽂句⼦不动,调整译⽂以适应原⽂。
为了能从双语平⾏语料库中获取更多的信息,还需要在对齐过程中插⼊少量的标记,例如:分译标记、合译标记、混译标记和移动标记等。
此外,为了便于以后的检索,对于过长的句⼦还要在适当的地⽅将长句截短成两个或更多的⼩句。
2.⼈⼯对齐的⽅法2.1打开⽂件先⽤UltraEdit软件将两个已经分为句⼦的⽂本⽂件打开,在该软件的⼯具栏的“窗⼝”下拉菜单中点“⽔平平铺”选项,使两个打开的⽂本同时显⽰在屏幕上。
为了操作⽅便,⼀般把原⽂放在上半屏,把译⽂放在下半屏。
(见图1)2.2 上下移动⽂本为了能够对齐两种语⾔的⽂本,在操作过程中需要不断地上下移动⽂本。
移动⽂本可以⽤⿏标移动窗⼝右边的滑块来完成。
也可以将光标放在某⼀⾏,然后⽤⿏标的中间滚轮来上下移动。
2.3 同步移动上下两个窗⼝中的⽂本在“窗⼝”下拉菜单中选“同步”选项,就可以同步移动上下两个窗⼝中⽂本,极⼤地⽅便⼈⼯对齐的操作。
图1:⽤UltraEdit同时打开两种语⾔的⽂本。
2.4 译⽂句⼦的合并如上所述,对齐的原则是尽量保持原⽂不变。
公示语双语平行语料库的现状与发展

公示语双语平行语料库的现状与发展引言公示语作为一种特殊的语言形式,在日常生活中扮演着重要的角色。
公示语的翻译不仅需要准确传达信息,还需要考虑文化差异和社会背景等因素。
为了提高公示语翻译的质量和效率,建立一个双语平行语料库是非常必要的。
本文将探讨公示语双语平行语料库的现状与发展,并提出相关的建议。
现状分析1. 公示语翻译的挑战公示语通常具有简洁、凝练的特点,其翻译需要考虑到信息的准确传达和文化的适应性。
公示语翻译的挑战主要包括以下几个方面:•语言表达的简洁性:公示语常常使用简短的句子和短语,翻译时需要保持信息的完整性和准确性。
•文化背景的差异:不同地区和国家的文化背景不同,公示语的翻译需要考虑到文化差异,使其在目标语言中能够被准确理解。
•法律和规范性要求:公示语往往涉及到法律和规范性要求,翻译时需要遵循相关的法律和规定,确保翻译的准确性和合法性。
2. 公示语双语平行语料库的重要性公示语双语平行语料库的建立对于公示语翻译的质量和效率具有重要意义。
双语平行语料库可以提供大量的语料样本,帮助翻译人员更好地理解公示语的语言特点和文化内涵。
同时,平行语料库还可以用于机器翻译和自然语言处理等领域的研究和应用。
3. 现有公示语双语平行语料库的问题目前,公示语双语平行语料库的建设还存在一些问题:•数据稀缺:由于公示语的特殊性,公示语双语平行语料库的数据相对较少,难以满足翻译和研究的需求。
•质量不一:现有的公示语双语平行语料库质量参差不齐,存在翻译不准确、信息不完整等问题,需要进一步的改进和完善。
•缺乏标准化:现有的公示语双语平行语料库缺乏统一的标准和规范,难以进行比较和共享。
发展建议1. 增加数据来源为了解决公示语双语平行语料库数据稀缺的问题,可以通过以下途径增加数据来源:•收集公示语文本:通过收集各地的公示语文本,建立一个全面的公示语数据库,为双语平行语料库的建设提供更多样本。
•合作机构建设:与政府机构、企事业单位等合作,建立合作机构的公示语双语平行语料库,实现资源共享和数据互通。
利用Trados的WinAlign进行汉英平行语料库的句对齐

参 考 文 献
[】B k rM . op r rnlt nsu i : 1 a e , C r oai ta s i t de n ao s
An ov r iw nd s e v e a ome s gg sins f r u e to o
f t r r sa c [】Ta g t 7 : 2 u u e e e r h J. r e ,/2 2 3~
a s r s no nd pa e pa ns t i r a e a m e s’ i o nc e s f r r
£ R 断 l l i P; 啜
鐾 酗 i 神
髫
滞
图 1
① 基 金项 目: 文 系 作 者 主 持 的 云 南 省 教 育 厅科 学研 究基 金 项 目“ 语 常 用 动 词 及 其 英 译 的 聚 类 研 究 ” 部分 成 果 , 项 目编 号 为 本 汉 的 该 0 C4 1 4。 此 对项 目资 助 方表 示 衷 心 的 感 谢 。 7 08 在
243.
[】Ka M.n sh i n, T x—ta s 2 y, a dRoc es M. e t rn — e lto a i n n [】 C mp t to a ai n lg me tJ. o u a i n l 活。 L n ua is 1 9 , 9 1 : 2 ~1 2 i g itc ,9 3 1 () 1 1 4 . 英: The sae a o t fe t e me - tt d p s efci a [】王 克非 . 型 双语 对 应 语 料 库 的设 计 与 v 3 新 s r s o nc e s i ut nt a r c t e u e t i r a e np i o g iulur 构 建【】 中国翻 译 , 0 4 6 J. 20 ,.
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
双语平行语料库对齐技术述评对齐的双语语料库在机器翻译、词义消歧和双语词典编撰等领域都非常有用。
语料对齐的单位由大到小,有篇章、段落、句子、短语、词等不同的层次。
粒度越小,提供的语言信息就越多,应用的价值也就越大。
然而平行语料库的自动对齐并非是一件容易的事情。
由于语料大都来自人工翻译,句子之间并不都是一对一的翻译模式,还有一对多、多对多的翻译模式。
这种复杂性加大了对齐的难度,特别是对更细粒度级别的对齐。
由于语言之间存在着差异,找到固定的对应翻译很难,再加上文本预处理工具难以保证处理效果,以及一些电子文本的噪声纷繁复杂,这都增加了对齐的难度。
而对于英汉两种差别很大的语言来说,目前的语料库对齐算法并不一定完全适用于汉英语料库的对齐。
本文首先回顾了当前国外平行语料库的对齐技术,然后分析了国内在对齐中所使用的技术,旨在为本研究所今后构建小型汉英平行语料库提供一个技术支持。
1 目前平行语料库对齐技术的现状1.1 句子级对齐技术在各级对齐研究中,其中最为重要且较为成熟的自动对齐技术是句子一级的对齐。
句子级对齐的方法主要有三种:①基于长度的方法(length-based)(Brown et al,1991; Gale & Church, 1991a);②基于词汇的方法(lexical-based)(Kay & Roscheisen, 1993);③混合法(combination)(Tan & Nagao, 1995; Wu,1994)。
基于长度的方法最早是由Brown和Gale提出,虽然他们的算法都是由源文本中句子长度和译文本中的句子长度有很大的正相关这一观察得出,但其侧重点却不同。
Brown的算法以词为单位计算句子的长度,而Gale和Church则是以字符为单位计算句子的长度。
他们分别用各自的算法对加拿大议会会议所录英法双语语料库进行了对齐实验,准确率达96~97%。
然而该方法在处理复杂句子的对齐(如2∶1或2∶2的句子对齐,或非直译和省略的句子)以及不同语系的句子对齐时,准确率却并不高,而且此算法一旦出错,便不可能自动纠正。
基于词汇的方法是由Kay和Rosheisen提出的。
他们认为最佳的句子对是那些使系统词汇对齐数量最大化的句子。
基于词汇的算法虽然可以提高对齐的准确性,但却费时;而且目前还没有充分证明这一方法适合于大型语料库。
Chen(1993)对Kay 和 Rosheisen的算法进行了改进,这一算法运用词汇信息构建了一对一词汇统计翻译模型,用这样的翻译模型找到语料库生成的最大可能性。
他用此算法对旧的Hansard语料库进行双语对齐。
与Brown和Gale的对齐算法相比,这一算法不仅正确率高,而且在处理大量省略的对齐中能轻易确定省略的位置,且鲁棒性(robust)较好。
基于词汇方法的另一种做法是利用同源词(cognate)(Church,1993)。
此方法在处理英法和英德语言中的诸如名字、日期、数字、术语等可辨认单位出现比率高的情况下效果更好。
如前所述,基于词汇的方法相对可靠精确,但计算起来相当复杂且速度较慢;而基于长度的算法模型虽然简单,独立于语言知识和外部资源,但鲁棒性不好,极易造成错误蔓延。
由于每种方法都有自己的优缺点,人们试图将各种方法混合起来找到问题的解决途径(Tan & Nagao, 1995; Wu,1994; ;Collier,1998; Vronis,1999;Melamed,2000)。
试验结果表明,混合的方法优于单纯使用其中的任何一种方法。
1.2 词汇级对齐技术与句子对齐相比,词汇对齐的应用价值更加直接。
目前词对齐主要有基于统计(也称为基于同现)的方法、基于词典和语言学知识的方法。
基于统计的方法是通过大规模双语语料的统计训练,获得双语对译词的同现概率,以此来获得对齐。
一种统计法是基于机器翻译模型的词汇对齐法(Brown et al., 1993,吴尉林,2003 )。
此法用词汇对齐模型来实现翻译模型并通过EM(expectation-maximization)算法来进行词汇对齐。
但是该方法不仅在运行时需要很大的内存空间,而且EM算法本身也缺乏鲁棒性。
另一种统计法是基于同现的词汇对齐(Gale & Church,1991b; Zhang Ying et al., 2001)。
其中,Gale & Church 用同现测度函数对译双语词汇,通过统计对译词在双语句对中同现的频率来确定双语词汇之间的对应关系,并为每个双语词对引入一个联列表(Contingency Table)。
基于同现的对齐算法简单,鲁棒性也比EM算法好,但是该方法在计算时没有考虑词汇的上下文关系,因此获得的词汇翻译对应存在着间接相关的问题。
基于词典和语言学知识的词汇对齐方法。
机读双语词典包含丰富的词汇对译信息,是进行词对齐的重要资源。
Ker(1997)根据语义类实现词对齐,结果显示该方法在获得很高的准确率的同时,能克服基于统计方法中存在的低覆盖率的问题。
Huang(2000)用语言学比较的方法进行词对齐。
此外还有用隐马尔可夫模型和最大熵模型(Necip,2006)进行词对齐。
1.3 多词组合单位对齐多词组合单位(multi-word unit alignment——MWU)对齐也就是短语或词的搭配对齐。
在自然语言的理解过程中,更多的是通过短语或者固定搭配而非单个的词来传达要表达的意义。
在双语平行语料库中许多词并没有直接的翻译对等词。
为了理解这些多词单位的意义,不仅要考虑不同语言词之间的相互关系,而且也要考虑同一语言中这些词的搭配。
因此,多词组合单位的对齐也是双语语料库对齐工作中的一项重要且富有挑战的任务。
许多研究者对此已做了深入的研究,方法主要有n-gram、近似字符匹配、有限状态机、双语语法分析树等。
其中有些做法最为典型,如Dagan & Church的Termight系统、Smadja et al.的Champollion系统和McEnery et al.(1997)用近似字符串匹配技术ASMT和有限状态自动机从平行语料库中提取术语翻译。
但是英语和汉语使用不同的文字系统,所以ASMT不能应用于英汉多词单位的对齐。
1.4 从句和段落的对齐如前所述,与句子和词汇对齐研究相比较,对段落和从句对齐的研究要少的多。
其中一个原因就是段落的界限比句子清楚,所以其对齐也简单。
Gale & Church(1991a)认为,基于长度对齐的算法可以用于段落的对齐。
尽管从句对齐对于诸如基于实例的翻译、语言教学、对比研究等领域的应用非常有用,但是由于每种语言,尤其是不同语系语言之间存在如何界定从句界限的问题,所以与简单句相比较,从句的对齐更难且容易出错。
Kit et al.(2004)用包含双语法律术语表、双语字典的词汇方法和相似性度量法对香港法律文本进行了从句对齐。
实验结果表明,这一算法即简单又有效,其准确率达94.6%。
2 目前国内英汉平行语料库的对齐研究英汉属于不同的语系,上述的对齐方法对印欧语系(尤其是英语和法语)效果较好,但对于语法结构相差甚远的印欧与亚洲语系(汉语和日语)来说,效果却不如前者。
例如,基于长度方法的同源词法能够提高相近语系语料对齐的准确性,但是,对英汉两个完全不同的语系来说,由于没有拼写、语音或语义相似的同源词,所以这种方法就不适用于英汉双语对齐。
如果单纯地使用基于长度的方法,效果也不是很好,因为汉语分词问题很难解决,利用词的个数作为长度单位不但不可靠,而且分词结果也会影响互译信息率的计算。
因此,目前对于汉英句子对齐常用的方法是将基于长度和基于词汇这两种方法进行改进或混合使用。
香港大学的Wu(1994)通过创建特殊词表对Gale 和 Church的基于长度的算法进行了适当的改进,用此算法对香港立法委员会会议记录英汉语料库做了对齐实验。
结果表明,在句子对齐中,1:1 的匹配的准确率接近90%。
Sun(1999)在处理英汉语料库句子对齐时,对基于字符的长度算法进行了改进。
这一方法弥补了基于字符长度算法不能处理1:0或0:1的句子对齐(即省略或插入)的不足。
它与其它混合法不同的是,其它算法通过动态规划把长度和词汇信息结合起来,而此法是先单独使用,然后再用词汇法进行对齐正误判断,正确的对齐从语料库中抽出,然后对剩余的句子再进行对齐,如此反复,其正确率达到93%。
钱丽萍等(2000)提出了基于译文的对齐方法,该方法借助一部翻译较完整的词典,将汉英句子间的对应关系连起来。
实验证明,这一方法虽然“从根本上消除了基于长度的对齐方法中由于文本的缺失或局部对错造成的错误蔓延,并且对于一般文本普遍适用”(2000:61),但却无法处理2:2句对的情况。
Chuang et al.(2005)提出了一种基于标点符号的句子对齐法。
他们用此方法对汉-英SMC(Chinese-English Sinorama Magazine Corpus )平行语料库进行对齐。
结果显示,基于标点符号的方法胜于基于长度的方法,其准确率超过93%。
他们还验证了此方法可以用于其它的双语文本,如日语和英语。
张艳等(2005)使用了一种基于长度的扩展方法。
这一方法以长度算法为基础,引入词汇信息,然后采用基于标点符号的方法作为后处理。
测试结果证明“这种混合方法可以有效地提高汉英双语句子对齐的正确率,并且对多领域的文本具有很好的移植性”(2005:36)。
李维刚等(2006)提出一种基于句子长度和位置信息的结合算法。
为了验证这一算法的有效性,他们使用了基于长度的算法,基于位置信息以及两者结合的方法对《呼啸山庄》第17章的英汉双语文本进行了测试。
三种方法的准确率分别为20.3%、85.2%和92.5%。
对汉-英词汇对齐来说,由于文字系统存在很大的差异,汉语句子不象英语句子那样,词与词之间没有间隔,而且汉语对词的界定很模糊,造成词切分的错误率也就增高,因此英汉语对应词的对齐的难度也相应地增大。
尽管有些方法可以直接用于汉英语料库词汇对齐,如 Wu(1995)用Brown的EM算法对英汉词汇对齐进行测试,正确率达91.2%~95.1%,但这不能完全适用于汉英词汇的对齐。
Fung and Church(1994)提出了K-vec算法。
这一算法的单词对齐不需要在句子对齐的前提下进行,只测试候选词在位置分布上的相似度,但对双语词只能做粗略的估计。
吕学强(2004)提出了基于语料库的无双语词典的英汉词对齐模型。
该模型几乎不需要任何语言学知识和语言学资源,是语料库方法的独立应用。
该方法不仅能对齐高频词、低频词,而且对未登录词和汉语分词错误具有兼容能力。
晋薇等(2002)运用了语义相似度和语言学知识进行双语语句词对齐,达到了85%的准确率。