spss 分析案例数据
SPSS上机实验案例分析剖析

SPSS上机实验案例分析练习一:下表为10个人对两个不同的问题作出的回答(回答为“Yes”或“No”)后得到的数据,利用SPSS为该数据创建频数分布表。
练习二: 某百货公司连续40天的商品销售额(单位:万元)如下:根据上面的数据进行适当分组,编制频数分布表。
练习三:某行业管理局所属40个企业1999年的产品销售收入数据(单位:万元)如下:(1)根据上面的数据进行适当分组,编制频数分布表,并计算出累计频数和累计频率;(2)按规定,销售收入在125万元以上为先进企业,115万元-125万元为良好企业,105万元-115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
(1)请按下面注明的两个条件计算出该班每位同学的总评成绩。
条件1:总评成绩的构成:总评成绩=0.2*平时成绩+0.8*期末成绩(即总评成绩中,平时成绩占20%,期末成绩占80%)条件2:总评成绩请保留为整数(2)请按100-90分,89-80分,79-70分,69-60分,59分及以下,将该班全体同学按照期末成绩进行分组得出各组人数。
练习五:如下表中所示的是20个股票经纪商对于两种不同交易收取佣金数据的一个样本。
这两种交易分别为: 买(1)计算两种交易佣金的全距和四分位数间距。
(2)计算两种交易佣金的方差和标准差。
(3)计算两种交易佣金的变异系数。
(4)比较两种交易的成本变异程度。
练习六:某生产部门利用一种抽样程序来检验新生产出来的产品的质量,该部门使用下面的法则来决定检验结果:如果一个样本中的14个数据项的方差大于0.005,则生产线必须关闭整修。
假设搜集的数据如下:问此时的生产线是否必须关闭?为什么?练习七:将50个数据输入到SPSS工作表中。
并使用SPSS计算这些数据描述统计量(如最大值、平均值、方差、标准差求晚8:30分时段电视节目中广告所占时间均值的点估计的95%置信区间。
练习九:某年度我国部分工业品产量如下表所示请据表中数据对如下六个问题进行统计图形描述(1)请选择一个适当图形描述各地区所含省市数目(2)请选择一个适当图形描述各地区水泥的平均产量(3)请选择一个适当图形描述每个地区水泥产量低于800万吨的省市数目(4)请选择一个适当图形描述该年度全国生铁、钢、水泥、塑料的平均产量(5)请选择一个适当图形描述该年度华北五省市工业品产量(6)请选择一个适当图形描述各地区塑料总产量占全国总量的比例(1)用平均房价作自变量,画出这些数据的散点图;(2)求客房使用率关于平均房价估计的回归方程;(3)对于平均房价为80美元的一家旅馆,估计它的客房使用率练习十一:某公司采集了美国市场上办公用房的空闲率和租金率的数据。
SPSS数据分析实例
t检验的假设如下: H0:两总体均数相同,μ1 =μ2
Байду номын сангаас
H1:两总体不均数相同,μ1 ≠μ2
两样本t检验对数据的要求: 1.小样本时要求分布不太偏 2.小样本时要求方差齐
第18页/共19页
感谢您的欣赏
第19页/共19页
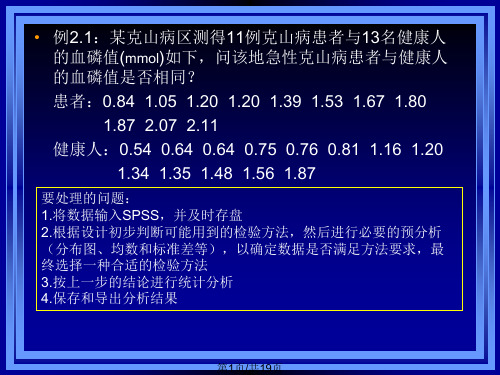
• 例2.1:某克山病区测得11例克山病患者与13名健康人 的血磷值(mmol)如下,问该地急性克山病患者与健康人 的血磷值是否相同? 患者:0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人:0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87
应该观察分组描述情况 选择菜单项 数据 拆分文件 ,系统弹出对话框
选择 比较组 ,将变量group选入分组方式框,点击确定
第11页/共19页
再做一次数据描述,输出结果
根据描述结果,可判断检验结果多半会拒绝H0。
取消文件拆分,不然会影响以后的统计分析
选择菜单项 数据 拆分文件 ,选择 分析所有个案,不创建组
∴应该先判断该数据是否符合t检验要求,即对数据进行简单描述
第8页/共19页
2.2.1 数据的简单描述
选择菜单项 分析
描述统计
描述
,
系统弹出对话框
选择描述变量
第9页/共19页
选择所需描述变量x,点击ok
系统弹出新界面
结果浏览窗口
导航栏
具体输出结果
spss案例分析报告(精选)

spss案例分析报告(精选)本文通过分析一份 SPSS 数据,展示 SPSS 在统计分析中的应用。
数据概述本数据为一家咖啡馆的销售数据,共有 200 条记录,包括 7 个变量:日期、时间、收银员、商品名、销售价格、数量和总价。
SPSS 分析1. 描述性统计使用 SPSS 的描述性统计功能,可以获取数据的基本信息,如均值、标准偏差、最大值、最小值等。
其中,销售价格的均值为 44.71 元,标准偏差为 13.29 元,最小值为 23 元,最大值为 78 元。
数量的均值为 1.62 个,标准偏差为 0.51 个,最小值为 1 个,最大值为3 个。
总价的均值为 73.25 元,标准偏差为 21.89 元,最小值为 23 元,最大值为 156 元。
2. 单样本 t 检验假设一杯咖啡的平均售价为 50 元,我们可以使用单样本 t 检验对这个假设进行检验。
首先,我们需要用 SPSS 的数据透视表功能,计算出每杯咖啡的平均售价。
然后,使用单样本 t 检验功能,输入样本均值、假设的总体均值(50 元)、样本标准差、样本大小以及置信度水平。
在这个数据集中,单样本 t 检验得出的 t 值为 -2.36,P 值为 0.019,显著性水平为 0.05,因此我们可以拒绝原假设,认为该咖啡馆的咖啡售价不是 50 元。
4. 相关分析假设我们想要了解商品数量和销售额之间的关系,我们可以使用 SPSS 的相关分析功能来进行分析。
首先,我们需要使用数据透视表功能,计算出每个订单的总价和数量。
然后,使用相关分析功能,输入这两个变量的值,得出相关系数和显著性水平。
在这个数据集中,商品数量和销售额之间的相关系数为 0.749,P 值为 0,显著性水平非常显著。
因此,我们可以认为商品数量和销售额之间存在极强的正相关关系。
结论本文通过 SPSS 对一份咖啡馆销售数据进行分析,展示了 SPSS 在统计分析中的应用。
通过描述性统计、单样本 t 检验、双样本 t 检验和相关分析等功能,我们可以获得数据的基本信息,检验假设,分析变量之间的关系,从而帮助企业更好地决策和管理。
spss地大数据分析资料报告案例

spss地大数据分析资料报告案例spss 的大数据分析资料报告案例在当今数字化时代,数据已成为企业和组织决策的重要依据。
SPSS (Statistical Product and Service Solutions)作为一款功能强大的统计分析软件,在处理和分析大数据方面发挥着重要作用。
本文将通过一个实际的案例,展示如何运用 SPSS 进行大数据分析,并从中得出有价值的结论。
一、案例背景假设我们是一家电商公司,拥有大量的用户交易数据。
我们希望通过对这些数据的分析,了解用户的购买行为、偏好以及市场趋势,以便优化产品推荐、营销策略和供应链管理。
二、数据收集与整理首先,我们从数据库中提取了相关的数据,包括用户的基本信息(如年龄、性别、地域等)、购买记录(产品类别、购买时间、购买金额等)以及浏览行为等。
这些数据量庞大,可能达到数百万甚至数千万条记录。
在将数据导入 SPSS 之前,我们需要对数据进行预处理,包括数据清洗、缺失值处理和异常值检测。
例如,删除重复的记录、填充缺失的关键信息,并剔除明显不符合常理的异常值。
三、数据分析方法1、描述性统计分析通过计算均值、中位数、标准差等统计量,对用户的年龄、购买金额等变量进行概括性描述,了解数据的集中趋势和离散程度。
2、相关性分析分析不同变量之间的相关性,例如用户年龄与购买金额之间、购买频率与产品类别之间的关系。
3、分类分析使用聚类分析将用户分为不同的群体,以便针对不同群体制定个性化的营销策略。
4、时间序列分析对于购买时间等变量,运用时间序列分析方法预测未来的销售趋势。
四、SPSS 操作与结果解读1、描述性统计分析结果例如,我们发现用户的平均年龄为 30 岁,购买金额的中位数为 500 元,标准差为 200 元。
这表明大部分用户年龄较为年轻,购买金额分布相对较为集中。
2、相关性分析结果发现用户年龄与购买金额之间存在较弱的正相关关系,即年龄较大的用户可能购买金额相对较高。
SPSS统计分析分析案例

SPSS统计分析案例一、我国城镇居民现状近年来;我国宏观经济形势发生了重大变化;经济发展速度加快;居民收入稳定增加;在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下;全国居民的消费支出也强劲增长;消费结构发生了显著变化;消费结构不合理现象得到了一定程度的改善..本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点..二、我国居民消费结构的横向分析第一;食品消费支出比重随收入增加呈现出明显的下降趋势;这与恩格尔定律的表述一致..但最低收入户与最高收入恩格尔系数相差太过悬殊;城镇最低收入户刚刚解决了温饱问题;而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型;甚至接近最富裕型..第二;衣着消费支出比重随收入增加缓慢上升;到高收入户又有所下降;但各收入组支出比重相差不大..衣着支出比重没有更多的递增且最高收入户的支出比重有所下降;这些都符合恩格尔定律关于衣着消费的引申..随着收入的增加;衣着支出比重呈现先上升后下降的走势..事实上;在当前的价格水平和服装业的发展水平下;城镇居民的穿着是有一定限度的;而且居民对衣着的需求也不是无限膨胀的;即使收入水平继续提高;也不需要将更大的比例用于购买服饰用品了..第三;家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势;说明居民的生活水平随收入的增加而不断提高和改善..第四;医疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势..这是因为医疗保健支出作为生活必须支出;不论居民生活水平高低;都要将一定比例的收入用于维持自身健康;而且由于医疗制度改革;加重了个人负担的同时;也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别;因而不同收入等级的居民在医疗保健支出比重上差别不大..第五;居住支出比重基本上呈先上升后下降的趋势;这与我国居民消费能级不断提升;住宅商品正在越来越成为城镇居民关注的热点是相吻合的;同时与恩格尔定律的引申也是一致的..可以看出;城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响;但归根结底仍取决于居民的收入水平;要提高城镇居民的消费支出;必须增加居民收入..因此;采取切实有效的措施增加城镇居民的可支配收入;不仅可以提高全国城镇居民的总体消费水平;促进消费结构向着更加健康、合理的方向发展;而且在启动内需;促进我国的经济发展方面有着重大的现实意义..三、我国居民消费结构的纵向分析进入21世纪以来;随着经济体制改革的深入;国民经济的迅速发展;我国城乡居民的消费水平显著提高;居民的各项支出显著增加..随着消费水平的提高;我国城乡居民消费从注重量的满足到追求质的提高;从以衣食消费为主的生存型到追求生活质量的享受型、发展型;消费质量和消费结构都发生了明显的变化..城镇居民在食品、衣着、家庭设备用品三项支出在消费支出中的比重呈现明显的下降趋势;其中食品类支出比重降幅最大;衣着类有所下降;家庭设备用品类下降幅度不是很大..与此同时;医疗保健、交通通讯、文化娱乐教育服务、居住及杂项商品支出在消费支出中的比例均有上升;富裕阶段的消费特征开始显现..四、我国城镇居民消费结构及趋势的统计分析下图是出自中国统计年鉴—2009这一资料性年刊;它系统收录了全国和各省、自治区、直辖市2008年经济、社会各方面的统计数据;以及近三十年和其他重要历史年份的全国主要统计数据..此年鉴正文内容分为24个篇章;本文选取其中的第九篇章-人民生活;用以探究我国城镇居民消费结构及其趋势..表1 中国统计年鉴—2009统计表9-5 城镇居民家庭基本情况可支配收入1510.16 4282.95 6279.98 13785.81 15780.76平均每人消费性支出元1278.89 3537.57 4998.00 9997.47 11242.85 食品693.77 1771.99 1971.32 3628.03 4259.81衣着170.90 479.20 500.46 1042.00 1165.91居住60.86 283.76 565.29 982.28 1145.41 家庭设备用品及服务108.45 263.36 374.49 601.80 691.83 医疗保健25.67 110.11 318.07 699.09 786.20交通通信40.51 183.22 426.95 1357.41 1417.12 教育文化娱乐服务112.26 331.01 669.58 1329.16 1358.26 杂项商品与服务66.57 114.92 171.83 357.70 418.31 平均每人消费性支出构成人均消费性支出=100食品54.25 50.09 39.44 36.29 37.89衣着13.36 13.55 10.01 10.42 10.37居住 6.98 8.02 11.31 9.83 10.19 家庭设备用品及服务10.14 7.44 7.49 6.02 6.15 医疗保健 2.01 3.11 6.36 6.99 6.99交通通信 1.20 5.18 8.54 13.58 12.60 教育文化娱乐服务11.12 9.36 13.40 13.29 12.08 杂项商品与服务0.94 3.25 3.44 3.58 3.72注:1.本表至9-17表为城镇住户抽样调查资料..2.从2002年起;城镇住户调查对象由原来的非农业人口改为城市市区和县城关镇住户;本篇章相关资料均按新口径计算;历史数据作了相应调整..五、SPSS统计分析图一给出了基本的描述性统计图;图中显示各个变量的全部观测量的Mean均值、Std.Dev iation标准差和观测值总数N..图2给出了相关系数矩阵表;其中显示3个自变量两两间的Pearson相关系数;以及关于相关关系等于零的假设的单尾显著性检验概率..图1 描述性统计表图2 相关系数矩阵从表中看到因变量家庭设备用品及服务与自变量食品、衣着之间相关关系数依次为0.869、0.684;反映家庭设备用品及服务与食品、衣着之间存在显著的相关关系..说明食品与衣着对于家庭设备用品及服务条件的好转有显著的作用..自变量居住于因变量家庭设备用品及服务之间的相关系数为-0.894;它于其他几个自变量之间的相关系数也都为负;说明它们之间的线性关系不显著..此外;食品与衣着之间的相关系数为0.950;这也说明它们之间存在较为显著的相关关系..按照常识;它们之间的线性相关关系也是符合事实的..图3给出了进入模型和被剔除的变量的信息;从表中我们可以看出;所有3个自变量都进入模型;说明我们的解释变量都是显著并且是有解释力的..图3 变量进入/剔除信息表图4给出了模型整体拟合效果的概述;模型的拟合优度系数为0.982;反映了因变量于自变量之间具有高度显著的线性关系..表里还显示了R平方以及经调整的R值估计标准误差;另外表中还给出了杜宾-瓦特森检验值DW=2.632;杜宾-瓦特森检验统计量DW是一个用于检验一阶变量自回归形式的序列相关问题的统计量;DW在数值2到4之间的附近说明模型变量无序列相关..图4 模型概述表图4给出了方差分析表;我们可以看到模型的设定检验F统计量的值为9.229;显著性水平的P值为0.236..图5 方差分析表图6给出了回归系数表和变量显著性检验的T值;我们发现;变量居住的T值太小;没有达到显著性水平;因此我们要将这个变量剔除;从这里我们也可以看出;模型虽然通过了设定检验;但很有可能不能通过变量的显著性检验..图6 回归系数表图7给出了残差分析表;表中显示了预测值、残差、标准化预测值、标准化残差的最小值、最大值、均值、标准差及样本容量等;根据概率的3西格玛原则;标准化残差的绝对值最大为1.618;小于3;说明样本数据中没有奇异值..图7 残差统计表图8给出了模型的直方图;由于我们在模型中始终假设残差服从正态分布;因此我们可以从这张图中直观地看出回归后的实际残差是否符合我们的假设;从回归残差的直方图于附于图上的正态分布曲线相比较;可以认为残差的分布不是明显地服从正态分布..尽管这样也不能盲目的否定残差服从正态分布的假设;因为我们用了进行分析的样本太小;样本容量仅为5..图8 残差分布直方图从上面图4的分析结果看;我们的模型需要剔除居住这个变量;用本次实验中的方法和步骤重新令家庭设备用品及服务对食品和衣着回归;得到的主要结果如图9、图10和图11所示;跟上面的分析类似;从中可以看出;剔除居住这个变量后;模型拟合优度为0.964;比原来有所降低;而方差分析的F检验为27.071;新模型与原来的模型相比;各个系数都通过了显著性T检验;因此更加合理;从而我们可以得出结论:剔除居住这个变量后的模型更加合理;因此在做预测过程中要使用剔除不显著变量后的模型..图9 模型概述图10 方差分析表图11 回归系数表六、我国居民消费变化的趋势特点1食品消费质量提高;衣着消费支出比重下降..食品消费水平由过去简单的吃饱吃好;转变为品种更加丰富;营养更加全面..一方面由于食品供应的日益充足..另一方面由于在外饮食的增加;粮食消费比重减小;购买量大幅度下降..衣着是两项基本生存资料之一;衣着消费向时装化、名牌化、个性化发展的倾向更加明显;成衣化倾向成为主流..从衣着和食品消费比重的下降可以看出城镇居民满足基本生活的支出并没有随着收入水平的提高而提高;这表明我国城镇居民满足吃、穿为主的生存型消费需求阶段已经结束;逐步向以发展型和享受型消费的阶段过渡..2 居民收入迅速增长;消费水平大幅度提高;消费结构呈现明显的富裕型特征消费是收入的函数;收入的增加是消费水平提高和消费结构变化的前提..随着我国经济的发展;我国居民的收入水平不断提高;特别是21世纪以来;我国居民的收入水平迅速提高..伴随着收入水平的提高;城乡居民各项支出全面增加;消费性支出大幅度增长..今后5—10年以至更长时间;我国经济保持一个较高的增长速度是完全可能的;城乡居民的消费水平将大幅度提高..3消费能级不断提高;消费内容日益丰富;住房与轿车消费同时升温;可望提前成为消费热点在消费水平提高和消费结构改善的同时;城乡居民的消费能级不断提高....4以教育为龙头的娱乐教育文化服务类消费继续攀升随着人们对知识认知程度的提高和自我完善意识的增强;对教育的投入仍会保持增长..目前从子女教育在人们储蓄目的位居前列的情况看;对教育及教育产品的投入仍是今后一个时期的消费热点..大力发展教育事业;特别是高等教育、成人教育、职业教育应是政府长期坚持和倡导的提高城镇居民收入水平;缩小收入差距;应做到:1.进一步强化收入分配的宏观调控力度采取切实措施努力提高低收入群体的收入水平..2.加快西部大开发步伐;做好扶贫开发工作..3.进一步完善社会保障制度;改善居民整体尤其是社会弱势群体的生存环境..4.通过完善税收制度来缩小部分不合理的高低收入阶层差距..5.对不动产、金融资产收益以及财产的继承与赠与;要通过合理设置税种税率;征收房产税、利息税以及遗产与赠与税等税种来进行调节..参考文献1 吕振通张凌云spss统计分析与应用机械工程出版社;2009年2 Nancy L.Leech Karen C.Barrett Ceorge A.Morgan SPSS for Intermediate Statistics Use and InterpretationThird Edition PUBLISHING HOUSE OF ELECTRONICS INDUSTRY;2009年。
统计学课SPSS数据分析实战案例

统计学课SPSS数据分析实战案例SPSS(统计分析系统)是一款常用的统计软件,被广泛应用于社会科学、商业、医学等领域的数据分析工作中。
通过这个案例,我们将运用SPSS软件进行数据分析,以展示统计学课的实战应用。
案例背景假设你是一位市场研究员,你的公司正在调查消费者对某产品的满意度。
你已经收集了一份随机抽样的数据集,包含了消费者的满意度评分以及他们的一些个人信息。
你的任务是对这些数据进行分析,以了解消费者满意度与个人信息之间是否存在关联。
数据集说明数据集包括了500个消费者的信息,具体变量如下:1. 变量1:满意度评分(连续变量,取值范围从1到10);2. 变量2:性别(分类变量,取值为男性和女性);3. 变量3:年龄(连续变量);4. 变量4:收入水平(分类变量,取值为低、中、高三个层次);5. 变量5:购买次数(连续变量,表示过去一年内购买该产品的次数)。
数据分析步骤以下是对这份数据集进行分析的步骤:1. 数据清洗和准备首先,我们需要检查数据集中是否存在缺失值或异常值,并进行数据清洗。
在SPSS中,我们可以使用数据查看和数据清洗的功能来完成这一步骤。
确保数据集中的每一列都没有缺失值,并且所有的异常值已经得到恰当的处理。
2. 描述性统计分析接下来,我们可以使用SPSS的描述性统计分析功能,对数据集进行描述性统计分析。
我们可以计算满意度评分、年龄和购买次数的平均值、标准差、最小值、最大值,并生成频数分布表和柱状图。
3. 相关性分析为了确定满意度评分与其他个人信息变量之间的关联性,我们可以使用SPSS的相关性分析功能。
通过计算满意度评分与性别、年龄、收入水平和购买次数之间的相关系数,我们可以评估它们之间的相关性。
4. 单因素方差分析我们可以使用SPSS进行单因素方差分析,以了解不同收入水平的消费者在满意度评分上是否存在显著差异。
通过观察方差分析表和显著性水平,我们可以得出初步结论。
5. 多元线性回归分析最后,我们可以使用SPSS的多元线性回归分析功能来建立一个回归模型,以预测满意度评分。
spss数据分析报告案例
SPSS数据分析报告案例1. 研究背景本研究旨在调查大学生是否存在晚睡现象,并探究晚睡与健康问题之间的关系。
通过采集大学生的睡眠时间、就寝时间以及健康状况等数据,利用SPSS软件进行数据分析,进一步了解大学生的睡眠状况与健康问题的关联。
2. 数据概况本研究共收集了200名大学生的数据,其中包括性别、年级、每晚睡眠时间、平均就寝时间、是否存在健康问题等变量。
下面是对数据的描述统计分析结果:•性别分布:男性占50%,女性占50%。
•年级分布:大一占25%,大二占30%,大三占25%,大四占20%。
•每晚睡眠时间:平均睡眠时间为7.8小时,标准差为1.2小时。
最小值为5小时,最大值为10小时。
•平均就寝时间:平均就寝时间为23:30,标准差为0.5小时。
最早就寝时间为22:00,最晚就寝时间为01:00。
•健康问题:共有45%的大学生存在健康问题。
3. 数据分析结果3.1 性别与睡眠时间的关系首先,我们探究性别与睡眠时间之间的关系。
利用独立样本T检验,得出以下的结果:•假设检验:男性和女性的睡眠时间是否存在显著差异?•结果:独立样本T检验显示,男性平均睡眠时间为7.6小时,女性平均睡眠时间为8.0小时。
T值为-2.14,P值为0.034,意味着男性和女性的睡眠时间存在显著差异。
3.2 年级与睡眠时间的关系我们进一步探究年级与睡眠时间的关系。
使用单因素方差分析(ANOVA),得出以下结果:•假设检验:各年级的睡眠时间是否存在显著差异?•结果:单因素方差分析显示,大一、大二、大三和大四的平均睡眠时间分别为7.7小时、7.9小时、8.1小时和7.6小时。
F值为2.75,P值为0.043,说明各年级之间的睡眠时间存在显著差异。
3.3 睡眠时间与健康问题的关系最后,我们分析睡眠时间与健康问题之间的关系。
利用相关分析,得出以下结果:•假设检验:睡眠时间与健康问题之间是否存在相关性?•结果:相关分析结果显示,睡眠时间和健康问题之间存在显著负相关(r = -0.25,P值 = 0.001),即睡眠时间越少,存在健康问题的可能性越大。
spss案例分析
1、某班共有28个学生,其中女生14人,男生14人,下表为某次语文测验的成绩,请用描述统计方法分析女生成绩好,还是男生成绩好。
方法一:频率分析(1) 步骤:分析→描述统计→频率→女生成绩、男生成绩右移→统计量设置→图表(直方图)→确定 (2) 结果:统计量女生成绩男生成绩N有效 1515 缺失73 73 均值 69.9333 67.0000 中值 71.0000 72.0000 众数 76.00a48.00a标准差 8.91601 14.53567 方差 79.495 211.286 全距 30.00 46.00 极小值 54.00 43.00 极大值 84.00 89.00 和1049.001005.00a. 存在多个众数。
显示最小值(3)分析:由统计量表中的均值、标准差及直方图可知,女生成绩比男生成绩好。
方法二:描述统计(1)步骤:分析→描述统计→描述→女生成绩、男生成绩右移→选项设置→确定(2)结果:(3)分析:由描述统计量表中的均值、标准差、方差可知,女生成绩比男生成绩好。
2、某公司经理宣称他的雇员英语水平很高,现从雇员中随机随出11人参加考试,得分如下:80、81、72、60、78、65、56、79、77、87、76,请问该经理的宣称是否可信?(1)方法:单样本T检验H 0:u=u,该经理的宣称可信H 1:u≠u,该经理的宣称不可信(2)步骤:①输入数据:(80,81,…76)②分析→比较均值→单样本T检验→VAR00001右移→检验值(75)→确定(3)结果:单个样本统计量N 均值标准差均值的标准误VAR00001 11 73.73 9.551 2.880(4)分析:由单个样本检验表中数据知t=0.668>0.05,所以接受H,即该经理的宣称是可信的。
3、某医院分别用 A 、B 两种血红蛋白测定仪器检测了16名健康男青年的血红蛋白含量(g/L ),检测结果如下。
问:两种血红蛋白测定仪器的检测结果是否有差别?仪器A :113,125,126,130,150,145,135,105,128,135,100,130,110,115,120 ,155仪器B :140,150,138,120,140,145,135,115,135,130,120,133,147,125,114,165(1)方法:配对样本t 检验H 0:u 1=u 2,两种血红蛋白测定仪器的检测结果无差别 H 1:u 1≠u 2,两种血红蛋白测定仪器的检测结果有差别(2)步骤:①输入两列数据:A 列(113,125,…155);B 列(140,125,…165);②分析→比较均值→配对样本t 检验→仪器A 、仪器B 右移→确定(3)结果:成对样本统计量均值 N标准差 均值的标准误对 1仪器A 126.38 16 15.650 3.912 仪器B134.501613.7703.442(4)分析:由成对样本检验表的Sig 可见t =0.032小于0.05,所以拒绝H 0,即两种血红蛋白测定仪器的检测结果有差别。
spss案例大数据分析报告
spss案例大数据分析报告SPSS 案例大数据分析报告在当今数字化时代,数据已成为企业和组织决策的重要依据。
通过对大量数据的分析,可以揭示隐藏在其中的规律和趋势,为决策提供有力支持。
本报告将以一个具体的案例为例,展示如何使用 SPSS 进行大数据分析。
一、案例背景本次分析的对象是一家电商企业的销售数据。
该企业在过去一年中积累了大量的销售记录,包括商品信息、客户信息、订单金额、购买时间等。
企业希望通过对这些数据的分析,了解客户的购买行为和偏好,优化商品推荐和营销策略,提高销售业绩。
二、数据收集与整理首先,从企业的数据库中提取了相关数据,并进行了初步的清理和整理。
删除了重复记录和缺失值较多的字段,对数据进行了标准化处理,使其具有统一的格式和单位。
在整理数据的过程中,发现了一些问题。
例如,部分客户的地址信息不完整,部分商品的分类存在错误。
通过与相关部门沟通和核实,对这些问题进行了修正和补充。
三、数据分析方法本次分析主要采用了以下几种方法:1、描述性统计分析计算了数据的均值、中位数、标准差、最大值、最小值等统计指标,以了解数据的集中趋势和离散程度。
2、相关性分析分析了不同变量之间的相关性,例如商品价格与销量之间的关系,客户年龄与购买金额之间的关系。
3、聚类分析将客户按照购买行为和偏好进行聚类,以便更好地了解客户群体的特征。
4、因子分析提取了影响客户购买行为的主要因素,为进一步的分析和建模提供基础。
四、数据分析结果1、描述性统计分析结果商品的平均价格为_____元,中位数为_____元,标准差为_____元。
销量的最大值为_____件,最小值为_____件,均值为_____件。
客户的平均年龄为_____岁,中位数为_____岁,标准差为_____岁。
购买金额的最大值为_____元,最小值为_____元,均值为_____元。
2、相关性分析结果商品价格与销量之间呈现负相关关系,相关系数为_____。
这表明价格越高,销量越低。
spss案例分析报告精选文档
s p s s案例分析报告精选文档TTMS system office room 【TTMS16H-TTMS2A-TTMS8Q8-S p s s分析身高与体重的相互影响一、案例介绍:这是某幼儿园学生的身高体重数据,数据中主要包括编号,学生姓名,性别,学生年龄,每个学生的体重以及身高数值。
主要是看下幼儿园学生体重与身高的相互关系。
二、研究案例的目的:分析幼儿园学生身高体重的相互关系和影响。
三、下面是数据来源:四、研究的方法:主要是使用spss中的描述统计分析和线性回归分析;在描述统计分析中主要是分析出身高体重的最大值和最小值、均值,在图表中可以看出身高的最大值;在线性回归分析中主要是采用身高为自变量,体重为因变量来进行分析的。
五、研究的结果:1)描述分析:打开文件“某班23名同学的身高、体重、年龄数据”,通过菜单兰中的分析选项,进行描述性分析,选择体重和身高,求最大值最小值和均值,得到如下结果:从结果看出,该班学生样本数为23,体重最小值为13.7kg,最大值为23kg,平均体重为17.7167kg。
身高最小值为105cm,最大值为116cm,平均身高为108.85cm。
以身高为例子,选择描述中的频率选项可以得出分布,在频率对话框的图形选项中,选择条形图,即可用图形直观看到结果。
从图形中可以很直观的看出不同身高段的人数分布情况,其中108cm左右的人数最多。
从表格中则可以清楚地看到具体数目。
2)线性回归分析:选择分析——回归——线性,在弹出的对话框中,以身高作为自变量,体重作为因变量,结果如下:从表中可以得出。
R=0.223,即两者具有弱相关性。
从图表中,可以看出它们之间的线性关系大概可以表示为y=-0.139x+2.617 六、研究结论:从描述分析和回归分析可以身高和体重的相关性是相对比较弱的,也就是弱相关性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《数据分析及其应用软件》习题姓名__学号___成绩习题1:出钢时所用盛钢水的钢包,因钢水对耐火材料的侵蚀,容积不断增大我们希望找出使用次数与增大的容积之间的关系,试验数据如下:写出分析报告(内容包括以下四点)1.用双曲线1/y = a+b/x作曲线拟合:(1)画出散点图,(2)写出回归方程,(3)进行检验,(4)分析结果,(α= 0.05)2.用指数曲线y = ae b/x 作曲线拟合:(1)画出散点图,(2)写出回归方程,(3)进行检验,(4)分析结果,(α= 0.05)3.比较两种曲线后,写出较优的曲线回归方程.4.使用较优的曲线回归方程预测当使用次数为17次时钢包的容积增大多少?习题2:1.研究货运总量(万吨)与工业总值(亿元)、农业总产值(亿元)、居民非商品支出(亿元)的关系。
数据见下表(1)计算出的相关系数矩阵;(2)求关于的三元线性回归方程;(3)对所求得的回归方程作拟合优度检验;(4)对回归方程做显著性检验;(5)对每一个回归系数做显著性检验;(6)如果有的回归系数没有通过显著性检验,将其剔除。
重新建立回归方程,再作回归方程的显著性检验和回归系数显著性检验;(7)求出每一个回归系数的之置信水平为95%的置信区间;(8)求出标准化回归方程;(9)求当=75,=42,=3.1时的值,给定置信水平为99%,用SPSS软件计算精确置信区间,用手工计算近似预测区间;(10)结合回归方程对问题作一些基本分析。
习题3:为研究某地区人口死亡状况,已按某种方法将15个已知样品分为3类,指标及原始数据如下表。
利用费歇线性判别函数,判定另外4个待判样品属于哪一类?某地区人口死亡状况指标及原始数据表组别序号= 0岁组死亡概率=1岁组死亡概率= 1 0岁组死亡概率=55岁组死亡概率=80岁组死亡概率=平均预期寿命第一组134.167.44 1.127.8795.1969.30233.06 6.34 1.08 6.7794.0869.70336.269.24 1.048.9797.3068.80440.1713.45 1.4313.88101.2066.20550.0623.03 2.8323.74112.5263.30第二组133.24 6.24 1.1822.90160.0165.40 232.22 4.22 1.0620.70124.7068.70 341.1510.08 2.3232.84172.0665.85 453.0425.74 4.0634.87152.0363.50 538.0311.20 6.0727.84146.3266.80第三组134.03 5.410.07 5.2090.1069.50 232.11 3.020.09 3.1485.1570.80 344.1215.12 1.0815.15103.1264.80 454.1725.03 2.1125.15110.1463.70 528.07 2.010.07 3.0281.2268.30待判样品150.22 6.66 1.0822.54170.6065.20 234.647.33 1.117.7895.1669.30 333.42 6.22 1.1222.95160.3168.30 444.0215.36 1.0716.45105.3064.20习题4:对中国乡镇企业绩效的进行聚类分析.数据见表1.表1、原始数据地区净利润营业收入增加值率企业个数盈利个数全员劳动生产率北京567266 9571555 22.37 118754 117100 20698 天津1220685 15752865 22.06 121329 120836 29242 河北6114274 76293862 25.67 1012984 979370 23661 山西1195722 14942048 26.15 294139 277568 16115 内蒙古3111870 30425815 28.45 911161 905113 21476 辽宁4285894 63966481 24.59 1028432 1015913 37607 吉林1530642 19087038 27.17 764616 755917 22758 黑龙江534765 11755916 24.17 245869 245746 18796 上海923336 20663611 21.29 37692 21902 42769 江苏2594757 95448009 21.44 903456 885401 28529 浙江5582807 127806784 21.17 1081514 1010268 32250 安徽1790990 24180813 28.37 710774 695017 14342 福建2334878 55988718 22.62 807022 740241 25070 江西947204 14546944 25.85 717680 693557 13515 山东4602505 109758971 21.6 2048217 1950135 20274 河南5298053 60458827 26.09 1081731 1043324 18701 湖北2005403 45241972 22.85 926207 891023 17094 湖南4255453 69601456 25.71 2226562 2169514 20262 广东4277645 85557573 23.72 766557 726893 23573 广西989634 22889759 20.59 867907 832509 10570 海南120524 1501225 26.12 40719 39811 14270 重庆271802 9225735 23.64 106691 105284 15351 四川910281 37355764 19.34 1374560 1348002 14009贵州669816 6381031 25.52 372996 320339 12429 云南830682 17790905 22.05 654923 650341 10539 西藏陕西1103286 20162275 25.11 897491 868285 12591 甘肃419893 6701579 22.3 224908 222668 10595 青海34616 649227 20.98 54865 53228 7394 宁夏109083 1565055 24.16 130357 129507 7644 新疆191764 3071497 24.68 316524 304569 9248续表一、原始数据地区流动资产固定资产职工人数银行借款资本金北京4659389 3931311 1018117 1024308 2924903天津4943290 4148950 1204863 1180493 2303981河北12465461 17484175 8226605 4038086 10332912山西3557340 5780890 2804201 938541 2934108内蒙古3227037 5267496 4016866 460290 3333205辽宁8763313 9329875 4539619 1999724 6980228吉林2372734 3614685 2494526 513310 2409414黑龙江1861422 2679007 1451692 563340 1871204上海10832675 7789596 1379837 2684161 6258380江苏32606238 25073003 7680355 8096730 16462531浙江34257475 29714853 8311974 9979972 20763537安徽5089323 7351798 4747880 1450082 4952914福建9853152 11160445 5436920 1646883 10778050江西2264148 3399940 3025862 844116 2425545山东25610281 26447082 12671968 6284596 14179543河南11262505 15312738 8389316 2711629 9442756湖北8419188 10129567 6216411 2027642 6427542湖南7557258 9399762 9262393 1699073 6723945广东24910272 32230553 9232307 6736240 19485556广西3234113 5269620 3471206 871565 3214208海南278001 796182 275868 182675 465657重庆2418088 2267023 1499882 624348 1656726四川6569307 7031491 5938049 2504647 5130203贵州3241104 1774185 1406217 541997 2387169云南3301461 5809520 2546765 1031743 2912189西藏陕西3224570 3934343 3850600 1148287 2769354甘肃1364007 1735031 1531755 501074 1124357青海176344 363754 232662 124070 209130宁夏411855 679716 484183 147424 429111新疆790981 1266081 752463 263604 677916习题5:利用主成分分析方法和下表中20个城市高新技术产业化能力数据,《对20个城市高新技术产业化能力进行横向评价》20个城市高新技术产业化能力指标和数值表(2006年原始数据)一级指标高新技术产业化二级指标高新技术产业化水平高新技术产业化效益三级指标高技术产业增加值占工业增加值比重知识密集型产业增加值占生产总值比重高新技术产品出口额占商品出口额比重新产品销售收入占产品销售收入比重高技术产业劳动生产率高技术产业增加值率知识密集型产业劳动生产率地区%%%%万元/人%万元/人北京26.5732.4546.0117.6421.5118.3821.94天津24.3910.0147.3928.1230.6326.3817.39沈阳9.328.9327.3619.5711.7627.2919.09大连10.4512.3314.4110.9115.5627.8137.70长春 3.2210.35 6.8145.1110.3342.2421.18哈尔滨14.018.72 4.2415.9510.0930.9116.88上海19.2417.7240.6030.1421.5620.7926.80南京16.9510.7026.0019.5018.6318.3931.90苏州31.847.2865.837.5212.9222.1769.21杭州12.5112.3634.3216.5616.0814.7633.48宁波 6.599.94 5.8913.97 5.9117.6249.76厦门42.4110.9232.9022.6117.8225.5344.63济南34.4510.9910.1917.7329.7638.3729.39青岛8.807.7411.6332.4116.3324.6938.84武汉17.2611.4726.8210.6524.9437.1219.23广州8.8112.0823.7117.889.1523.5934.99深圳51.8213.0248.2215.5315.0020.6851.15重庆 6.248.14 4.3731.4610.7034.7810.22成都16.8512.5020.8817.9714.3837.1325.71西安27.8014.3213.8212.949.3233.7013.42全国11.049.6729.0414.8013.0823.9414.59(数据参见附件表2:“2003-2006年高新技术产业化”数据。