hadoop搭建伪分布式集群步骤
hadoop伪分布式集群搭建与安装(ubuntu系统)
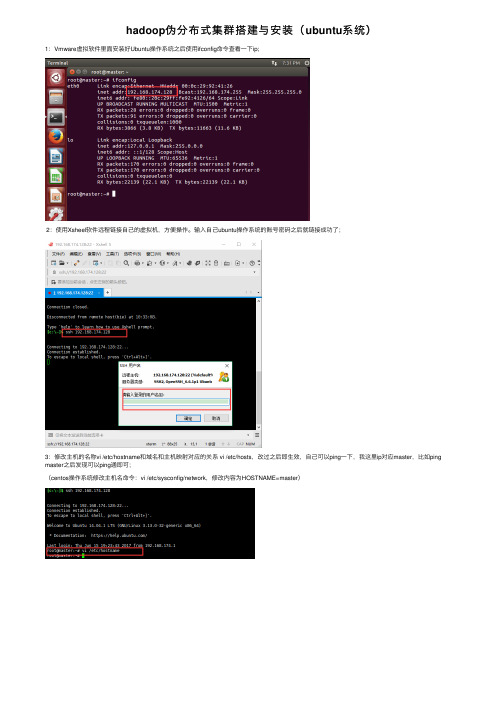
hadoop伪分布式集群搭建与安装(ubuntu系统)1:Vmware虚拟软件⾥⾯安装好Ubuntu操作系统之后使⽤ifconfig命令查看⼀下ip;2:使⽤Xsheel软件远程链接⾃⼰的虚拟机,⽅便操作。
输⼊⾃⼰ubuntu操作系统的账号密码之后就链接成功了;3:修改主机的名称vi /etc/hostname和域名和主机映射对应的关系 vi /etc/hosts,改过之后即⽣效,⾃⼰可以ping⼀下,我这⾥ip对应master,⽐如ping master之后发现可以ping通即可;(centos操作系统修改主机名命令:vi /etc/sysconfig/network,修改内容为HOSTNAME=master)4:修改过主机名称和主机名与ip对应的关系之后;开始上传jdk,使⽤filezilla这个⼯具将jdk⽂件以及其他⽂件上传到ubuntu操作系统中;⿏标左击选中想要上传的⽂件拖到右边即可,如下所⽰:上传成功之后可以检查⼀下,这⾥默认上传到root⽬录下⾯;显⽰已经上传成功即可;5:上传之后创建⼀个⽂件夹⽤于存放上传的⽂件或者压缩包;记住-C是⼤写,⼩写的-c会报错,见下⾯的测试结果;解压缩之后可以进到⾃⼰创建的hadoop⽬录下⾯看看效果,确定已经解压缩了;6:解压缩jdk之后开始将java添加到环境变量中(ubuntu操作系统中配置jdk的环境变量):进去之后按shift+g到最后⾯,到最前⾯双击g,点击a/s/i这三个任意⼀个字母进⼊命令⾏模式,可以对配置⽂件进⾏修改;配置的⽅式有很多种,这只是其中⼀种。
配置好jdk之后可以测试⼀下是否配置成功,如下图,如果没有使⽤source /etc/profile刷新配置是⽆法测试成功的;使⽤source /etc/profile刷新配置之后查看java的版本即可以查看出来;这⾥出了⼀点⼩插曲,我的linux版本的jdk第⼀次好像不能⽤,报了错,以为没配置好呢,后来才发现是jdk错了,所以这⾥都⼩⼼点;7:开始上传hadoop和解压缩hadoop;上传和上传jdk⼀样的做法,这⾥不做多叙述;查看hadoop的⽬录:hadoop-2.4.1/share/hadoop⾥⾯是核⼼jar包;8:解压缩之后开始配置hadoop,找到如下所⽰的路径;修改如下⼏个配置⽂件;详细修改见如下配置所⽰:修改的第⼀个配置⽂件,hadoop-env.sh;修改的内容如下所⽰:主要修改就是jdk的JAVA_HOME;如果忘记⾃⼰jdk的⽬录可以执⾏命令echo $JAVA_HOME复制⼀下结果即可;修改第⼆个配置⽂件:core-site.xml;修改的内容如下所⽰:因为是伪分布式,所以节点配置直接配置主机名了;<!-- 指定HADOOP所使⽤的⽂件系统schema(URI),HDFS的⽼⼤(NameNode)的地址 --><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><!-- 指定hadoop运⾏时产⽣⽂件的存储⽬录 --><property><name>hadoop.tmp.dir</name><value>/home/hadoop/hadoop-2.4.1/tmp</value></property>修改第三个配置⽂件:hdfs-site.xml修改的内容如下所⽰:<!-- 指定HDFS副本的数量 --><property><name>dfs.replication</name><value>1</value></property>修改第四个配置⽂件:⾸先将mapred-site.xml.template修改为mapred.site.xml,然后就将开始修改配置⽂件;修改内容如下所⽰:1 <!-- 指定mr运⾏在yarn上 -->2 <property>3 <name></name>4 <value>yarn</value>5 </property>修改第五个配置⽂件:yarn-site.xml;修改的内容如下所⽰:⾄此配置基本结束;<!-- 指定YARN的⽼⼤(ResourceManager)的地址 --><property><name>yarn.resourcemanager.hostname</name><value>master</value></property><!-- reducer获取数据的⽅式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>修改第六个配置⽂件:vi slaves修改的内容即是⾃⼰的主机名称:9:查看⼀下ubuntu下⾯的防⽕墙的状态和关闭开启防⽕墙:下图所⽰分别是关闭防⽕墙,查看防⽕墙的状态,开始防⽕墙和查看防⽕墙的状态;10:为了执⾏hadoop命令⽅便,同样配置⼀下hadoop的环境变量;同样vi /etc/profile ,配置如下所⽰:配置保存之后记得source /etc/profile刷新配置;11:格式化namenode(是对namenode进⾏初始化)执⾏格式化命令后看到successfully表⽰格式化成功;12:启动hadoop,先启动HDFS,sbin/start-dfs.sh;再启动YARN,sbin/start-yarn.sh;启动过程中输出⼤概三次yes和密码;输⼊即可;13:验证是否启动成功,使⽤jps命令验证;查看有⼏个进程;分别是启动start-dfs.sh和start-yarn.sh的效果;14:搭建好伪分布式集群之后可以在window访问集群的web服务;注意:如果在window浏览器⽆法访问的时候(jps正常启动),这个时候估计是linux操作系统的防⽕墙的问题:service iptables stop : 关闭防⽕墙service iptables status : 查看防⽕墙的状态service iptables start : 开启防⽕墙15:简单测试⼀下,将⼀个⽂件上传到hdfs上⾯,如下所⽰:假如你这样书写hadoop fs -put jdk-7u65-linux-i586.tar.gz hdfs://master:9000这个9000后⾯没有这个/那么你在浏览器是看不到任何⽂件的;去web服务查看效果如下所⽰:就是刚刚上传的⽂件;16:将⽂件从hdfs分布式集群中下载下来:效果如下所⽰:17:使⽤hadoop⾃带的mapreduce程序来测试mapreduce的效果:计算圆周率的程序;简单使⽤⼀下mapreduce,以计算单词的个数为例;创建⼀个count.txt⽤于测试⾥⾯的单词重复的次数:因为数据是在集群上⾯跑的,所以⽂件要放到集群上⾯;⾸先需要创建⼀个⽂件夹,⽤于存放⽂件;创建好的⽂件夹可以在web服务器⾥⾯查看,如下所⽰:将新建的count.txt⽂件放到input⽂件夹⾥⾯,如下所⽰:开始使⽤mapreduce的⾃带案例进⾏单词重读测试:可以查询执⾏之后出现的结果:也可以直接去web服务器查看执⾏的结果;可以使⽤命令查看执⾏的结果,如下所⽰:HDFS的⼤体实现的思想:1:hdfs是通过分布式集群来存储⽂件,为客户端提供了⼀个便捷的访问⽅式,就是⼀个虚拟的⽬录结构2:⽂件存储到hdfs集群中去的时候是被切分成block块的3:⽂件的block存放在若⼲台datanode节点上的4:hdfs⽂件系统中的⽂件于真实的block之间有映射关系,由namenode管理5:每⼀个block在集群中会存储多个副本,好处是可以提⾼数据的可靠性,还可以提供访问的吞吐量;18:hdfs常使⽤的命令:1 hadoop fs 显⽰hadoop 的fs的功能 2 hadoop fs -ls / 列举某⽬录下⾯的⽂件夹3 hadoop fs -lsr 列举某⽬录下⾯的⽂件夹及其⽂件夹⾥⾯的⽂件4 hadoop fs -mkdir /user/hadoop 在user⽂件夹下⾯创建⼀个hadoop⽂件夹5 hadoop fs -put a.txt /user/hadoop/ 将a.txt⽂件上传到user⽂件夹下⾯的hadoop⽂件夹下⾯6 hadoop fs -get /user/hadoop/a.txt / 获取到user⽂件夹下⾯的hadoop⽂件夹下⾯的a.txt⽂件7 hadoop fs -cp /原路径 /⽬标路径 拷贝⽂件,从原路径拷贝到⽬标路径 8 hadoop fs -mv /原路径 /⽬标路径 从原路径移动到⽬标路径9 hadoop fs -cat /user/hadoop/a.txt 查看a.txt⽂件⾥⾯的内容10 hadoop fs -rm /user/hadoop/a.txt 删除user⽂件夹下⾯的hadoop⽂件夹下⾯的a.txt⽂件11 hadoop fs -rm -r /user/hadoop/a.txt 递归删除,⽂件夹和⽂件12 hadoop fs -copyFromLocal /本地路径 /⽬的路径 与hadoop fs -put功能类似。
hadoop伪分布式搭建2.0

1. virtualbox安装1. 1. 安装步骤1. 2. virtualbox安装出错情况1. 2.1. 安装时直接报发生严重错误1. 2.2. 安装好后,打开Vitualbox报创建COM对象失败,错误情况11. 2.3. 安装好后,打开Vitualbox报创建COM对象失败,错误情况21. 2.4. 安装将要成功,进度条回滚,报“setup wizard ended prematurely”错误2. 新建虚拟机2. 1. 创建虚拟机出错情况2. 1.1. 配制好虚拟光盘后不能点击OK按钮3. 安装Ubuntu系统3. 1. 安装Ubuntu出错情况3. 1.1. 提示VT-x/AMD-V硬件加速在系统中不可用4. 安装增强功能4. 1. 安装增强功能出错情况4. 1.1. 报未能加载虚拟光盘错误5. 复制文件到虚拟机5. 1. 复制出错情况5. 1.1. 不能把文件从本地拖到虚拟机6. 配置无秘登录ssh7. Java环境安装7. 1. 安装Java出错情况7. 1.1. 提示不能连接8. hadoop安装8. 1. 安装hadoop的时候出错情况8. 1.1. DataNode进程没启动9. 开机自启动hadoop10. 关闭服务器(需要时才关)1. virtualbox安装1. 1. 安装步骤1.选择hadoop安装软件中的VirtualBox-6.0.8-130520-Win2.双击后进入安装界面,然后直接点击下一步3.如果不想把VirtualBox安装在C盘,那么点击浏览4.直接把最前面的C改成D注意:安装路径中不能有中文如果只有一个C盘,那么这里就不用改动了5.然后直接点击下一步就行了6.这个界面直接点下一步就行7.网络界面的时候直接点“是”就行8.然后点击安装9.在用户账户控制里面点击“是”10.安装完成出现如下界面,点击完成就行11.然后出现如下界面1. 2. virtualbox安装出错情况1. 2.1. 安装时直接报发生严重错误1. 右键点击此电脑,选择管理2. 选择服务和应用程序下面的服务3. 查看如下两个服务的状态4. 如果不是显示的正在运行,那么右键点击服务,然后启动它5. 启动好这两个服务过后,再重新安装VirtulBox1. 2.2. 安装好后,打开Vitualbox报创建COM对象失败,错误情况1这种错误也有可能是没有启用硬件虚拟化,以下是常用笔记本启用虚拟化技术的方法1. 惠普笔记本启用虚拟化功能2. 戴尔笔记本启用虚拟化功能3. 联想笔记本启用虚拟化功能4. 华硕笔记本启用虚拟化功能5. 其他品牌电脑可以按如下方式到百度中搜索电脑品牌怎么启用虚拟化技术1. 2.3. 安装好后,打开Vitualbox报创建COM对象失败,错误情况2这种可能是你的路径中有中文。
hadoop系统伪分布搭建

Mapreduce程序设计报告姓名:学号:题目:Hadoop系统伪分布搭建和运行1、实验环境联想pc机虚拟机:VM 10.0操作系统:Centos 6.4Hadoop版本:hadoop 1.2.1Jdk版本:jdk-7u252、系统安装步骤:2.1安装配置SSH在CentOs中,已经安装ssh与sshd,可用which命令查看打开终端,在终端中中键入:ssh -keygen -t rsa生成无密码密钥对,询问其保存路径时直接回车采用默认路径。
生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/home/hadoop/.ssh"目录下。
接着将id_rsa.pub追加到授权的key里面去cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys2.2 安装JDK:打开终端,输入命令mkdir /usr/java //建立java文件夹//复制JDK文件夹包cd /usr/java //进入jdk文件夹tar –zxvf jdk-7u25-linux-x64.tar.gz //解压jdk文件mv jdk1.7.0_25 jdk //重新命名jdk文件夹rm –rf jdk-7u25-linux-x64.tar.gz //删除jkd压缩包2.3配置JDK环境变量使用root权限进行操作,输入命令:vim /etc/profile按i进入编辑,在文件的最后,添加环境变量语句:按esc,接着按:wq保存退出,执行命令source /etc/profile 使环境变量生效使用命令java -version检测环境变量是否配置成功。
要是出现以上情况,说明jdk配置成功。
2.4安装Hadoop打开终端,输入命令cp /home/tzj/hadoop/hadoop-1.2.1.tar /usr #复制hadoop安装包到usr目录cd /usr #进入"/usr"目录tar –zxvf hadoop-1.2.1.tar.gz #解压"hadoop-1.2.1.tar.gz"安装包mv hadoop-1.2.1 hadoop #将"hadoop-1.2.1"文件夹重命名"hadoop"mkdir /usr/hadoop/tmp #在hadoop文件夹下创建tmp文件夹chown –R tzj:tzj hadoop #将文件夹"hadoop"读权限分配给hadoop用户rm –rf hadoop-1.0.0.tar.gz #删除"hadoop-1.0.0.tar.gz"安装包2.5hadoop配置(1)使用root权限进行操作,输入命令:vim /etc/profile按i进入编辑,在文件的最后,添加环境变量语句:按esc,接着按:wq保存退出,执行命令source /etc/profile 使环境变量生效(2)配置hadoop-env.sh在文本最后添加# set java environmentexport JAVA_HOME=/jdk1.7.0_25(3)配置core-site.xml在文本最后添加:<configuration><property><name>hadoop.tmp.dir</name><value>/usr/hadoop/tmp</value>(备注:请先在/usr/hadoop 目录下建立tmp 文件夹)<description>A base for other temporary directories.</description> </property><!-- file system properties --><property><name></name></property></configuration>(4)配置hdfs-site.xml在文本最后添加:<configuration><property><name>dfs.replication</name><value>1</value>(备注:replication 是数据副本数量,默认为3,salve少于3台就会报错) </property><configuration>(5)配置mapred-site.xml在文本最后添加:<configuration><property><name>mapred.job.tracker</name></property></configuration>2.6启动hadoop和验证(1)格式化hdfs文件系统hadoop namenode -format(2)启动hadoop2.7启动hadoopstart-all.sh启动守护程序,使用以下方式进行验证:(1)使用自带的JPS验证启动情况。
超详细!CentOS7+Hadoop3.0.0搭建伪分布式集群

超详细!CentOS7+Hadoop3.0.0搭建伪分布式集群超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群ps:本⽂的步骤已⾃实现过⼀遍,在正⽂部分避开了旧版教程在新版使⽤导致出错的内容,因此版本⼀致的情况下照搬执⾏基本不会有⼤错误。
如果按本⽂步骤进⾏的时候出事了,可以⿏标选中博客页⾯右侧的⽬录导航看看最后⼀部分的意外出事的坑点解决⽅案。
主机环境准备准备linux主机环境⼀、安装虚拟机⼀、安装虚拟机下载地址:(附:)系统iso:基本上就是下⼀步下⼀步这种简单的默认安装就好了。
除了在安装过程中配置分区的时候可能需要⼿动分区,然后选择标准分区即可。
装好后,修改内存,因为不需要图形界⾯,所以只给个512M内存也没问题。
并更改⽹络适配器为VMnet8(NAT)。
附上NAT⽅式的⼯作原理(CentOS和Windows这两台机⼦通过虚拟⽹关互联,虚拟⽹关由VMware workstation⽣成,在Windows上会⽣成⼀个虚拟⽹卡VMnet8,这个⽹卡地址和本机的物理⽹卡没有关系)⼆、⽹络配置⼆、⽹络配置在VMware workstation的菜单编辑 -> 虚拟⽹络编辑器可以查看和修改虚拟⽹关地址。
然后打开控制⾯板的⽹络连接查看VMnet8的IP地址如图,在我这台机⼦上:虚拟⽹关地址 192.168.216.1VMnet8 IP地址 192.168.216.2运⾏虚拟机,进⾏⽹络配置:1.输⼊ip addr看到我的⽹卡叫做ens332.输⼊ls /etc/sysconfig/network-scripts/看到⽹卡ip信息的配置⽂件名叫做ifcfg-ens333.输⼊cat /etc/sysconfig/network-scripts/ifcfg-ens33查看,可以发现虽然BOOTPROTO=dhcp,但是ONBOOT=no(下⾯4-6步纯属实验性质可忽视,直接开始第7步)4.输⼊vi /etc/sysconfig/network-scripts/ifcfg-ens33将ONBOOT=no修改为yes,在此之前要先进⼊root模式chmod 777 ⽂件名把⽂件改为可写状态。
hadoop伪分布式搭建(2)

hadoop伪分布式搭建(2)需要hadoop安装包,xshell,Linux的jdk,百度搜索下载即可打开xshell,点击⽂件,新建名称随意,主机填写虚拟机的IP地址(虚拟机要先开机),协议选择ssh输⼊⽤户名密码之类的即可连接虚拟机。
之后可以通过是shell命令来对虚拟机进⾏操作先创建两个⽂件夹⼀个⽤来放压缩包⼀个⽤来放软件,代码:mkdir app (存放软件)mkdir soft(存放压缩包)再点击⽂件新建⼀个连接:这次上⾯选择SFTP(⽤于传⽂件)其他照着前⾯填就⾏通过cd命令进⼊soft⽬录,再将压缩包拖进来即可会到ssh协议建⽴的选项卡,通过cd命令进⼊soft⽬录通过ll命令查看,即可看到安装包通过tar命令将两个压缩包解压到同级⽬录app中这样,我们jdk和Hadoop就安装ok了,接下⾥的就是配置问题了。
通过命令sudo vim /etc/profile 配置环境变量如图配置JAVA_HOME,HADOOP_HOME填写⾃⼰安装的⽬录其他照着填即可最后是Hadoop的五个配置⽂件了,配置⽅法如下:先进⼊Hadoop的etc⽬录的hadoop⽬录下:通过ll命令即可查看⽂件我们需要配置五个⽂件:hadoop-env.shcore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xml1hadoop-env.shvim hadoop-env.shexport JAVA_HOME=/usr/java/jdk1.7.0_652core-site.xml<property><name>fs.defaultFS</name><value>hdfs://hadoop00:9000</value></property><!-- 指定hadoop运⾏时产⽣⽂件的存储⽬录 --> <property><name>hadoop.tmp.dir</name><value>/home/hadoop/hadoop-2.4.1/tmp</value> </property>3hdfs-site.xml<!-- 指定HDFS副本的数量 --><property><name>dfs.replication</name><value>1</value></property>4mapred-site.xmlmv mapred-site.xml.template mapred-site.xml vim mapred-site.xml<!-- 指定mr运⾏在yarn上 --><property><name></name><value>yarn</value></property>5yarn-site.xml<!-- 指定YARN的⽼⼤(ResourceManager)的地址 --><property><name>yarn.resourcemanager.hostname</name><value>hadoop00:9000</value></property><!-- reducer获取数据的⽅式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>按照上⾯配置即可,通过vi命令进⼊⽂件,将对应的代码填在对应对接的<configrutation></configrutation>中即可.。
Hadoop运行模式之本地伪分布式模式

Hadoop运⾏模式之本地伪分布式模式Hadoop运⾏模式包括:本地模式、伪分布式模式以及完全分布式模式。
⼀、本地运⾏模式1、官⽅Grep案例1、创建在hadoop-2.7.2⽂件下⾯创建⼀个input⽂件夹[root@centos7 hadoop2.7]# mkdir input2、将Hadoop的xml配置⽂件复制到input[root@centos7 hadoop2.7]# cp etc/hadoop/*.xml input3、执⾏share⽬录下的MapReduce程序[root@centos7 hadoop2.7]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+' 4、查看输出结果[root@centos7 hadoop2.7]# cat output/*2、官⽅WordCount案例1、创建在hadoop-2.7.2⽂件下⾯创建⼀个wcinput⽂件夹[root@centos7 hadoop2.7]# mkdir wcinput2、在wcinput⽂件下创建⼀个wc.input⽂件[root@centos7 hadoop2.7]# cd wcinput[root@centos7 wcinput]# touch wc.input3、编辑wc.input⽂件[root@centos7 wcinput]# vim wc.input在⽂件中输⼊如下内容hadoop yarnhadoop mapreduceatguiguatguigu保存退出::wq!4、回到Hadoop⽬录/opt/module/hadoop-2.7.25、执⾏程序[root@centos7 hadoop2.7]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput 6、查看结果[root@centos7 hadoop2.7]# cat wcoutput/part-r-00000atguigu 2hadoop 2mapreduce 1yarn 1⼆、伪分布式运⾏模式1、启动HDFS并运⾏MapReduce程序(1)配置集群步骤⼀:配置:/opt/software/hadoop2.7/etc/hadoop/hadoop-env.shLinux系统中获取JDK的安装路径:[root@centos7 sbin]# echo $JAVA_HOME/opt/software/jdk1.8修改 JAVA_HOME 路径:export JAVA_HOME=/opt/software/jdk1.8步骤⼆:配置:core-site.xml<!-- 指定HDFS中NameNode的地址 --><property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value></property><!-- 指定Hadoop运⾏时产⽣⽂件的存储⽬录 --><property> <name>hadoop.tmp.dir</name> <value>/opt/software/hadoop2.7/data/tmp</value></property>步骤三:配置:hdfs-site.xml<!-- 指定HDFS副本的数量 --><property><name>dfs.replication</name><value>1</value></property>(2)启动集群步骤⼀:格式化NameNode(第⼀次启动时格式化,以后就不要总格式化)[root@centos7 hadoop2.7]# bin/hdfs namenode -format步骤⼆:启动NameNode[root@centos7 hadoop2.7]# sbin/hadoop-daemon.sh start namenode步骤三:启动DataNode[root@centos7 hadoop2.7]# sbin/hadoop-daemon.sh start datanode(3)查看集群(a)查看是否启动成功[root@centos7 hadoop2.7]# jps6967 DataNode6905 NameNode7004 Jps注意:jps是JDK中的命令,不是Linux命令。
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
1.Hadoop集群搭建(单机伪分布式)

1.Hadoop集群搭建(单机伪分布式)>>>加磁盘1)⾸先先将虚拟机关机2)选中需要加硬盘的虚拟机:右键-->设置-->选中硬盘,点击添加-->默认选中硬盘,点击下⼀步-->默认硬盘类型SCSI(S),下⼀步-->默认创建新虚拟磁盘(V),下⼀步-->根据实际需求,指定磁盘容量(单个或多个⽂件⽆所谓,选哪个都⾏),下⼀步。
-->指定磁盘⽂件,选择浏览,找到现有虚拟机的位置(第⼀次出现.vmdk⽂件的⽂件夹),放到⼀起,便于管理。
点击完成。
-->点击确定。
3) 可以看到现在选中的虚拟机有两块硬盘,点击开启虚拟机。
这个加硬盘只是在VMWare中,实际⼯作中直接买了硬盘加上就可以了。
4)对/dev/sdb进⾏分区df -h 查看当前已⽤磁盘分区fdisk -l 查看所有磁盘情况磁盘利⽤情况,依次对磁盘命名的规范为,第⼀块磁盘sda,第⼆块为sdb,第三块为sdc。
可以看到下图的Disk /dev/sda以第⼀块磁盘为例,磁盘分区的命名规范依次为sda1,sda2,sda3。
同理也会有sdb1,sdb2,sdb3。
可以参照下图的/dev/sda1。
下⾯的含义代表sda盘有53.7GB,共分为6527个磁柱,每个磁柱单元Units的⼤⼩为16065*512=8225280 bytes。
sda1分区为1-26号磁柱,sda2分区为26-287号磁柱,sda3为287-6528号磁柱下⾯的图⽚可以看到,还未对sdb磁盘进⾏分区fdisk /dev/sdb 分区命令可以选择m查看帮助,显⽰命令列表p 显⽰磁盘分区,同fdisk -ln 新增分区d 删除分区w 写⼊并退出选w直接将分区表写⼊保存,并退出。
mkfs -t ext4 /dev/sdb1 格式化分区,ext4是⼀种格式mkdir /newdisk 在根⽬录下创建⼀个⽤于挂载的⽂件mount /dev/sdb1 /newdisk 挂载sdb1到/newdisk⽂件(这只是临时挂载的解决⽅案,重启机器就会发现失去挂载)blkid /dev/sdb1 通过blkid命令⽣成UUIDvi /etc/fstab 编辑fstab挂载⽂件,新建⼀⾏挂载记录,将上⾯⽣成的UUID替换muount -a 执⾏后⽴即⽣效,不然的话是重启以后才⽣效。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
hadoop搭建伪分布式集群步骤
Hadoop是一个开源的分布式计算框架,可以处理大规模数据集的并行计算。
搭建伪分布式集群是学习Hadoop的第一步,本文将介绍搭建伪分布式集群的步骤。
步骤一:安装Java环境
Hadoop是基于Java开发的,所以首先需要安装Java环境。
可以从Oracle官网下载最新版本的JDK,并按照官方文档进行安装。
步骤二:下载Hadoop
在官方网站上下载Hadoop的稳定版本。
下载后解压缩到指定目录,我们假设解压缩后的目录为/home/hadoop/hadoop。
步骤三:配置Hadoop环境变量
打开终端,运行以下命令编辑环境变量配置文件:
```
$ sudo nano ~/.bashrc
```
在文件末尾添加如下内容:
```
export HADOOP_HOME=/home/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
```
保存并退出文件,然后运行以下命令使环境变量生效:
```
$ source ~/.bashrc
```
步骤四:配置Hadoop核心文件
进入Hadoop的安装目录,找到conf目录下的hadoop-env.sh文件,使用文本编辑器打开该文件,并修改JAVA_HOME的值为Java的安装路径。
保存并退出文件。
步骤五:配置Hadoop的核心文件
进入Hadoop的安装目录,找到conf目录下的core-site.xml文件,使用文本编辑器打开该文件,添加以下内容:
```
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
```
保存并退出文件。
步骤六:配置Hadoop的HDFS文件系统
进入Hadoop的安装目录,找到conf目录下的hdfs-site.xml文件,使用文本编辑器打开该文件,添加以下内容:
```
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
```
保存并退出文件。
步骤七:配置Hadoop的YARN资源管理器
进入Hadoop的安装目录,找到conf目录下的yarn-site.xml文件,使用文本编辑器打开该文件,添加以下内容:
```
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-
services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value> </property>
</configuration>
```
保存并退出文件。
步骤八:格式化HDFS文件系统
运行以下命令格式化HDFS文件系统:
```
$ hdfs namenode -format
```
步骤九:启动Hadoop集群
运行以下命令启动Hadoop集群:
```
$ start-dfs.sh
$ start-yarn.sh
```
步骤十:验证Hadoop集群是否正常运行
运行以下命令查看Hadoop集群的状态:
```
$ jps
```
如果输出结果中包含NameNode、DataNode、ResourceManager、NodeManager等进程,则表示Hadoop集群已成功启动。
至此,伪分布式集群的搭建已完成。
通过以上步骤,你可以在单台机器上模拟出一个分布式的Hadoop环境,进行开发和学习。
总结:
本文介绍了使用Hadoop搭建伪分布式集群的步骤,包括安装Java 环境、下载Hadoop、配置Hadoop环境变量、配置Hadoop核心文件、配置Hadoop的HDFS文件系统、配置Hadoop的YARN资源管理器、格式化HDFS文件系统、启动Hadoop集群以及验证Hadoop集群是否正常运行。
通过这些步骤,你可以快速搭建一个本地的Hadoop环境,进行分布式计算的学习和开发。