word2vec词向量模型
中文 wrod2vec 酒店评价模型

文章题目:探索中文word2vec模型在酒店评价中的应用一、引言在当今数字化时代,酒店业的发展已经离不开大数据和人工智能技术的支持。
随着社交媒体和在线点评评台的兴起,越来越多的用户在网上共享对酒店的评价和体验。
对这些评价进行有效地分析和挖掘,可以帮助酒店业主了解用户需求、改善服务质量,并优化营销策略。
二、使用word2vec模型分析酒店评价1. 介绍中文word2vec模型中文word2vec模型是一种词向量表示模型,它可以将中文文本中的词语转换成向量形式,从而方便计算机对文本进行分析和处理。
通过训练大规模中文语料库,word2vec模型可以学习每个词语的语义和语境信息,进而实现对文本信息的深度理解和挖掘。
2. 应用word2vec模型分析酒店评价通过使用word2vec模型分析酒店评价,可以实现以下几个方面的应用:(1)评价情感分析通过构建酒店评价文本的word2vec表示,可以对评价文本中的情感进行分析和分类。
通过识别出评价文本中的关键词语,并根据这些关键词语的向量表示,可以准确判断评价文本的情感倾向,从而帮助酒店业主了解用户对其服务的满意度和不满意度。
(2)评价关键词提取利用word2vec模型可以实现对酒店评价文本中的关键词提取。
通过计算每个词语的相似度,可以找出在评价文本中频繁出现的关键词,并进一步进行关键词的聚类和分类分析,从而帮助酒店业主了解用户对不同方面的服务和设施的评价和需求。
(3)评价主题挖掘通过对酒店评价文本进行word2vec表示,可以实现对评价文本中的主题进行挖掘。
通过计算词语之间的语义相似度,可以发现评价文本中涉及的主题和话题,并据此对评价文本进行主题分类和归纳,从而帮助酒店业主更好地了解用户对酒店的各个方面的评价和建议。
三、总结和展望通过本文对中文word2vec模型在酒店评价中的应用进行探讨,我们可以看到该模型在酒店评价分析中具有很大的潜力。
通过利用word2vec模型,可以实现对酒店评价的情感分析、关键词提取和主题挖掘,从而帮助酒店业主更好地理解用户需求和改进服务质量。
word2vec构建中文词向量
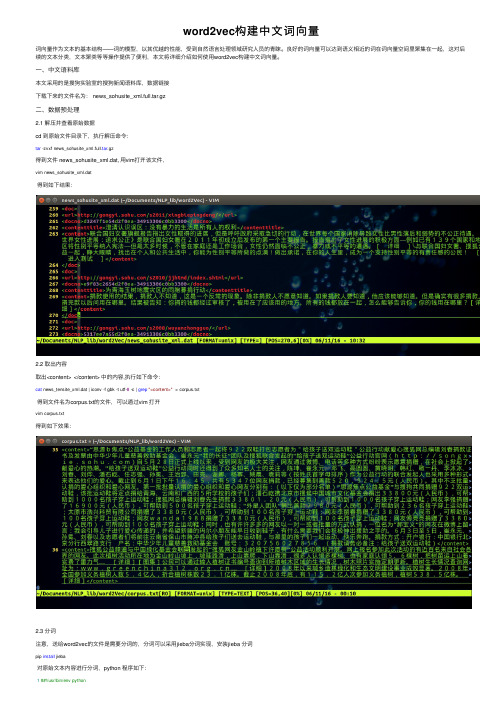
word2vec构建中⽂词向量词向量作为⽂本的基本结构——词的模型,以其优越的性能,受到⾃然语⾔处理领域研究⼈员的青睐。
良好的词向量可以达到语义相近的词在词向量空间⾥聚集在⼀起,这对后续的⽂本分类,⽂本聚类等等操作提供了便利,本⽂将详细介绍如何使⽤word2vec构建中⽂词向量。
⼀、中⽂语料库本⽂采⽤的是搜狗实验室的搜狗新闻语料库,数据链接下载下来的⽂件名为: news_sohusite_xml.full.tar.gz⼆、数据预处理2.1 解压并查看原始数据cd 到原始⽂件⽬录下,执⾏解压命令:tar -zvxf news_sohusite_xml.full.tar.gz得到⽂件 news_sohusite_xml.dat, ⽤vim打开该⽂件,vim news_sohusite_xml.dat得到如下结果:2.2 取出内容取出<content> </content> 中的内容,执⾏如下命令:cat news_tensite_xml.dat | iconv -f gbk -t utf-8 -c | grep"<content>" > corpus.txt得到⽂件名为corpus.txt的⽂件,可以通过vim 打开vim corpus.txt得到如下效果:2.3 分词注意,送给word2vec的⽂件是需要分词的,分词可以采⽤jieba分词实现,安装jieba 分词pip install jieba对原始⽂本内容进⾏分词,python 程序如下:1##!/usr/bin/env python2## coding=utf-83import jieba45 filePath='corpus.txt'6 fileSegWordDonePath ='corpusSegDone.txt'7# read the file by line8 fileTrainRead = []9#fileTestRead = []10 with open(filePath) as fileTrainRaw:11for line in fileTrainRaw:12 fileTrainRead.append(line)131415# define this function to print a list with Chinese16def PrintListChinese(list):17for i in range(len(list)):18print list[i],19# segment word with jieba20 fileTrainSeg=[]21for i in range(len(fileTrainRead)):22 fileTrainSeg.append([''.join(list(jieba.cut(fileTrainRead[i][9:-11],cut_all=False)))])23if i % 100 == 0 :24print i2526# to test the segment result27#PrintListChinese(fileTrainSeg[10])2829# save the result30 with open(fileSegWordDonePath,'wb') as fW:31for i in range(len(fileTrainSeg)):32 fW.write(fileTrainSeg[i][0].encode('utf-8'))33 fW.write('\n')可以得到⽂件名为 corpusSegDone.txt 的⽂件,需要注意的是,对于读⼊⽂件的每⼀⾏,使⽤结巴分词的时候并不是从0到结尾的全部都进⾏分词,⽽是对[9:-11]分词 (如⾏22中所⽰: fileTrainRead[i][9:-11] ),这样可以去掉每⾏(⼀篇新闻稿)起始的<content> 和结尾的</content>。
基于word2vec模型的文本特征抽取方法详解

基于word2vec模型的文本特征抽取方法详解在自然语言处理领域,文本特征抽取是一个重要的任务。
它的目标是将文本数据转换为机器学习算法可以处理的数值特征。
近年来,基于word2vec模型的文本特征抽取方法在该领域取得了显著的进展。
本文将详细介绍这一方法的原理和应用。
一、word2vec模型简介word2vec是一种用于将词语表示为向量的技术。
它基于分布假设,即上下文相似的词语往往具有相似的含义。
word2vec模型通过学习大量的文本数据,将每个词语表示为一个固定长度的向量,使得具有相似含义的词语在向量空间中距离较近。
二、word2vec模型的训练过程word2vec模型有两种训练方法:Skip-gram和CBOW。
Skip-gram模型通过给定中心词语,预测其周围的上下文词语;CBOW模型则相反,通过给定上下文词语,预测中心词语。
这两种方法都使用神经网络进行训练,通过最大化预测准确率来学习词语的向量表示。
三、基于word2vec模型的文本特征抽取方法基于word2vec模型的文本特征抽取方法主要有两种:词袋模型和平均词向量模型。
1. 词袋模型词袋模型是一种简单而常用的文本特征抽取方法。
它将文本表示为一个词语频率的向量,其中每个维度对应一个词语。
基于word2vec模型的词袋模型将每个词语的向量表示相加,并除以文本长度得到平均向量。
这种方法可以捕捉到文本中词语的语义信息,但忽略了词语的顺序。
2. 平均词向量模型平均词向量模型是一种更加复杂的文本特征抽取方法。
它将文本表示为所有词语向量的平均值。
通过这种方式,平均词向量模型可以保留词语的顺序信息。
与词袋模型相比,平均词向量模型可以更好地捕捉到文本的语义信息。
四、基于word2vec模型的文本特征抽取方法的应用基于word2vec模型的文本特征抽取方法在许多自然语言处理任务中得到了广泛应用。
例如,情感分析任务可以通过将文本表示为词袋模型或平均词向量模型的特征向量,然后使用机器学习算法进行分类。
词向量模型的原理

词向量模型的原理
词向量模型基于分布式假设,即具有相似上下文的词语往往具有
相似的语义含义。
它通过训练大规模语料库来获取词语的分布式表示。
词向量模型常用的算法包括Word2Vec和GloVe。
Word2Vec基于
神经网络模型,通过训练一个浅层神经网络来预测某个词语的上下文
或者根据上下文预测词语。
GloVe则采用基于共现矩阵的方法,利用某个词语与其他词语的共现信息构建一个词词共现矩阵,并通过优化目
标函数来得到词向量。
在训练过程中,模型通过调整词向量的参数,使得目标函数最小
化或者最大化,从而得到每个词语的词向量表示。
词向量通常是一个
固定长度的向量,可以用于表示词语的语义信息。
利用词向量模型,我们可以进行词语之间的相似度计算、词语的
聚类以及文本的语义分析等任务。
同时,将词向量应用于自然语言处
理任务中,可以大大提高模型的性能和效果。
word2vec和doc2vec词向量表示

word2vec和doc2vec词向量表⽰Word2Vec 词向量的稠密表达形式(⽆标签语料库训练)Word2vec中要到两个重要的模型,CBOW连续词袋模型和Skip-gram模型。
两个模型都包含三层:输⼊层,投影层,输出层。
1.Skip-Gram神经⽹络模型(跳过⼀些词)skip-gram模型的输⼊是⼀个单词wI,它的输出是wI的上下⽂wO,1,...,wO,C,上下⽂的窗⼝⼤⼩为C。
举个例⼦,这⾥有个句⼦“I drive my car to the store”。
我们如果把”car”作为训练输⼊数据,单词组{“I”, “drive”, “my”, “to”, “the”, “store”}就是输出。
所有这些单词,我们会进⾏one-hot编码2.连续词袋模型(Continuos Bag-of-words model)CBOW模型是在已知当前词w(t)的上下⽂w(t-2),w(t-1),w(t+1),w(t+2)的前提下预测当前词w(t)Hierarchical Softmax 实现加速。
3.传统的神经⽹络词向量语⾔模型DNN,⾥⾯⼀般有三层,输⼊层(词向量),隐藏层和输出层(softmax层:要计算词汇表中所有词softmax概率)。
⾥⾯最⼤的问题在于从隐藏层到输出的softmax层的计算量很⼤,因为要计算所有词的softmax概率,再去找概率最⼤的值。
word2vec也使⽤了CBOW与Skip-Gram来训练模型与得到词向量,但是并没有使⽤传统的DNN模型。
最先优化使⽤的数据结构是⽤霍夫曼树来代替隐藏层和输出层的神经元,霍夫曼树的叶⼦节点起到输出层神经元的作⽤,叶⼦节点的个数即为词汇表的⼩⼤。
⽽内部节点则起到隐藏层神经元的作⽤体如何⽤霍夫曼树来进⾏CBOW和Skip-Gram的训练我们在下⼀节讲,这⾥我们先复习下霍夫曼树。
霍夫曼树的建⽴其实并不难,过程如下:(节点权重可看作词频) 输⼊:权值为(w1,w2,...wn)的n个节点 输出:对应的霍夫曼树1)将(w1,w2,...wn)看做是有n棵树的森林,每个树仅有⼀个节点。
word2vec训练模型实现文本转换词向量

word2vec训练模型实现⽂本转换词向量利⽤ Word2Vec 实现⽂本分词后转换成词向量步骤:1、对语料库进⾏分词,中⽂分词借助jieba分词。
需要对标点符号进⾏处理2、处理后的词语⽂本利⽤word2vec模块进⾏模型训练,并保存 词向量维度可以设置⾼⼀点,3003、保存模型,并测试,查找相似词,相似词topN1import re2import jieba3from gensim.models import Word2Vec, word2vec456def tokenize():7"""8分词9 :return:10"""11 f_input = open('166893.txt', 'r', encoding='utf-8')12 f_output = open('yttlj.txt', 'w', encoding='utf-8')13 line = f_input.readline()14while line:15 newline = jieba.cut(line, cut_all=False)16 newline = ''.join(newline)17 fileters = [',', ':', '。
', '!', '!', '"', '#', '$', '%', '&', '\(', '\)', '\*', '\+', ',', '-', '\.', '/', ':', ';', '<', '=', '>', '\?', '@'18 , '\[', '\\', '\]', '^', '_', '`', '\{', '\|', '\}', '~', '”', '“', '?']19 newline = re.sub("<.*?>", "", newline, flags=re.S)20 newline = re.sub("|".join(fileters), "", newline, flags=re.S)21 f_output.write(newline)22print(newline)23 line = f_input.readline()24 f_input.close()25 f_output.close()262728def train_model():29"""30训练模型31 :return:32"""33 model_file_name = 'model_yt.txt'34 sentences = word2vec.LineSentence('yttlj.txt')35 model = word2vec.Word2Vec(sentences, window=5, min_count=5, workers=4, vector_size=300)36 model.save(model_file_name)373839def test():40"""41测试42 :return:43"""44 model = Word2Vec.load('model_yt.txt')45print(model.wv.similarity('赵敏', '赵敏'))46print(model.wv.similarity('赵敏', '周芷若'))47for k in model.wv.most_similar('赵敏', topn=10):48print(k[0], k[1])495051if__name__ == '__main__':52 test()View Code⼩结:word2vec是实现词嵌⼊的⼀种⽅式。
Word2Vec算法简介
Word2Vec算法简介⼀.简介 word2vec是Google在2003年开源的⼀款将词表征为实数值向量的⾼效算法,采⽤的模型有CBOW【Continuous Bag-Of-Words 连续的词袋模型】和Skip-Gram两种。
word2vec通过训练,可以把⽂本内容的处理简化为k维向量空间中的向量运算,⼆向量空间上的相似度可以⽤来表⽰⽂本语义上的相似度。
⼆.背景知识 1.One-hot Representation NLP相关的任务中最常见的第⼀步是创建⼀个词表库并把每个词顺序编号。
这实际就是词表⽰⽅法中的One-hot Representation,这种⽅法把每个词顺序编号,每个词就是⼀个很长的向量,向量的维度等于词表⼤⼩,⼀般采⽤稀疏编码存储,只有对应位置上的数字为1其它都为0。
这种表⽰⽅法最⼤的问题是⽆法捕捉词与词之间的相似度,⽽且还容易发⽣维数灾难,尤其是在Deep Learning相关的⼀些应⽤中。
2.Distributed Representation Distributed Representation 通过训练将每个词映射成k维实数向量【k⼀般为模型的超参数】,通过词之间的距离【⽐如:cosine相似度、欧式距离等】来判断它们之间的语义相似度。
word2vec就是采⽤这种词向量表⽰⽅式。
三.统计语⾔模型 传统的统计语⾔模型是表⽰语⾔基本单位【⼀般为句⼦】的概率分布函数,这个概率分布也就是该语⾔的⽣成模型。
⼀般语⾔模型可以使⽤各个词语条件的概率表⽰。
1.上下⽂⽆关模型 该模型仅仅考虑当前词本⾝的概率,不考虑词所对应的上下⽂环境,仅仅依赖于训练⽂本中的词频统计。
这是⼀种最简单,易于实现,但没有多⼤实际应⽤价值的统计语⾔模型。
它是n-gram模型中n=1时候的特殊情况,所以也称为Unigram Model【⼀元⽂法统计模型】。
2.n-gram模型 当n=1时,就是上⾯所说的上下⽂⽆关模型,这⾥n-gram⼀般认为是n>=2时的上下⽂相关模型。
词向量生成模型
词向量生成模型
词向量生成模型是一种自然语言处理技术,它的主要目的是将单词转换为向量表示。
这种模型可以通过学习单词之间的语义和上下文关系来生成词向量。
常见的词向量生成模型包括Word2vec、GloVe和FastText等。
其中,Word2vec是一种基于神经网络的词向量生成模型。
它主要包括两种算法,即CBOW和Skip-gram。
CBOW算法是基于上下文预测目标单词,而Skip-gram算法则是基于目标单词预测上下文单词。
GloVe是一种基于全局向量的词向
量生成模型,它通过对单词之间的共现关系进行建模来生成词向量。
FastText则是
一种基于子词的词向量生成模型,它将单词表示为其子词的向量和单词向量的加和。
词向量生成模型已经被广泛应用于自然语言处理领域,包括语言建模、文本分类、信息检索、机器翻译等方面。
通过将单词表示为向量,可以更好地处理自然
语言中的语义和上下文关系,从而提高自然语言处理的效果。
向量对齐模型
向量对齐模型向量对齐模型是一种用于将文本表示为向量的方法,它在自然语言处理和信息检索等领域中具有广泛的应用。
本文将介绍向量对齐模型的基本原理、常用方法以及应用场景。
一、向量对齐模型的基本原理向量对齐模型的基本原理是通过将文本映射到一个高维向量空间中,使得具有相似语义的文本在向量空间中的距离较近,从而实现对文本的语义关系建模。
常用的向量对齐模型包括Word2Vec、GloVe 和BERT等。
二、常用的向量对齐方法1. Word2VecWord2Vec是一种基于神经网络的词向量表示模型,它通过训练一个浅层的神经网络,将词语映射到一个低维向量空间中。
Word2Vec模型可以学习到词语的分布式表示,同时保留了词语之间的语义关系。
2. GloVeGloVe是一种基于全局词汇统计信息的词向量表示模型,它通过对词语的共现矩阵进行分解,得到词语的向量表示。
GloVe模型在学习词向量时考虑了全局词汇的统计信息,使得词向量更加准确。
3. BERTBERT是一种基于Transformer的预训练语言模型,它通过训练一个深层的神经网络,将词语和上下文的关系进行建模。
BERT模型不仅可以学习到词语的向量表示,还可以捕捉到词语之间的语义关系和上下文信息。
1. 文本分类向量对齐模型可以将文本表示为向量,从而方便进行文本分类任务。
通过计算文本向量之间的相似度,可以实现对文本的分类和聚类。
2. 信息检索向量对齐模型可以将查询文本和文档表示为向量,通过计算它们之间的相似度,可以实现信息检索任务。
在搜索引擎中,可以根据查询文本的向量与文档的向量进行匹配,返回与查询相关的文档。
3. 问答系统向量对齐模型可以将问题和候选答案表示为向量,通过计算它们之间的相似度,可以实现问答系统。
在问答系统中,可以根据问题的向量与候选答案的向量进行匹配,选择最相似的答案。
四、总结向量对齐模型是一种将文本表示为向量的方法,它可以将文本的语义关系建模,并在自然语言处理和信息检索等领域中具有广泛的应用。
词向量算法的使用教程及语义关联分析
词向量算法的使用教程及语义关联分析引言:近年来,随着自然语言处理 (natural language processing, NLP) 技术的快速发展,词向量 (word vectors) 算法成为了学术界和实际应用中广泛使用的工具。
词向量是一种将词语表示为高维向量的方法,其能够捕捉到词语之间的语义关联,大大促进了文本处理和理解的效果。
本文将介绍词向量算法的使用教程,并详细探讨如何利用词向量进行语义关联分析。
一、词向量算法简介1.1 Word2VecWord2Vec 是一种由 Tomas Mikolov 等人于 2013 年提出的词向量算法。
该算法包括两种模型:连续词袋模型 (Continuous Bag-of-Words, CBOW) 和 Skip-Gram 模型。
CBOW 模型通过上下文预测目标单词,而 Skip-Gram 模型则通过目标单词预测上下文。
这两种模型在训练过程中,根据给定的文本语料库来学习每个词语的向量表示。
1.2 GloVeGloVe (Global Vectors for Word Representation) 是由 Stanford NLP Group 提出的一种词向量算法。
与 Word2Vec 不同,GloVe 是基于全局词共现矩阵的统计特征进行训练的。
通过计算词语之间的共现概率,GloVe 可以获得更准确的词向量表示。
二、使用词向量算法建立词向量模型2.1 数据预处理在使用词向量算法前,首先需要进行数据预处理。
预处理包括去除标点符号、分词、去除停用词等步骤,目的是将文本转换为可供词向量训练的格式。
2.2 训练词向量模型使用预处理后的文本语料库,我们可以开始训练词向量模型。
对于 Word2Vec算法,可以选择使用 CBOW 模型或 Skip-Gram 模型。
通过调整模型参数,如窗口大小、向量维度等,可以优化词向量模型的性能。
2.3 优化词向量模型在训练词向量模型之后,我们可以通过一些优化算法进一步改进词向量的性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
机器翻译 • 机器翻译
• 语言词语的关系集合被表征为向量集合 • 向量空间内,不同语言享有许多共性 • 实现一个向量空间到另一个向量空间的映射和转换
word2vec作为神经概率语言模型的输入,其本身其实是神经概率模型的副产品,是为了通过神经网 络学习某个语言模型而产生的中间结果。具体来说,“某个语言模型”指的是“CBOW”和“SkipGram”。具体学习过程会用到两个降低复杂度的近似方法——Hierarchical Softmax或Negative Sampling。
.
Skip-Gram模型结构
小明 喜欢 吃
甜甜 的苹果d吃 cb Nhomakorabeaa.
目录
1
基本概念
2
模型与方法
3
实际应用
.
词相似度 训练数据集:经过分词后的新闻数据,大小184MB查看
"中国","钓鱼岛","旅游","苹果"几个词语的相似词语如下所示
.
向量加减法 向量加减法
"中国+北京-日本","中国+北京-法国"
常用的语言模型都是在近似地求 P(wt|w1,w2,…,wt−1)。 比如 n-gram 模型就是用 P(wt|wt−n+1,…,wt−1) 近似表示前者。 N-pos 先对词进行了词性分类
.
目录
1
基本概念
2
模型与方法
3
实际应用
.
Word2Vec
Google的Mikolov在2013年推出了一款计算词向量的工具
.
CBOW模型结构
输入层是上下文的词语的词 向量,是CBOW模型的一 个参数。训练开始的时候, 词向量是个随机值,随着训 练的进行不断被更新。当模 型训练完成之后可以获得较 为准确的词向量。
时间复杂度:
O(|V|)
O(log2(|V|))
.
Softmax
CBOW模型结构——霍夫曼树
在训练阶段,当给定一个上下文,要 预测词(Wn)的时候,实际上知道要的 是哪个词(Wn),而Wn是肯定存在于 二叉树的叶子节点的,因此它必然有 一个二进制编号,如“010011”,那 么接下来我们就从二叉树的根节点一 个个地去遍历,而这里的目标就是预 测这个词的二进制编号的每一位.即对 于给定的上下文,我们的目标是使得 预测词的二进制编码概率最大。形象 地说,我们希望在根节点,词向量和 与根节点相连经过logistic计算得到的 概率尽量接近0(即预测目标是 bit=1);在第二层,希望其bit是1, 即概率尽量接近1……这么一直下去, 我们把一路上计算得到的概率相乘, 即得到目标词Wn在当前网络下的概率 (P(Wn)),那么对于当前这个sample 的残差就是1-P(Wn)。于是就可以 SGD优化各种权值了。
将词表示为 [0.793, -0.177, -0.107, 0.109, 0.542, …]的矩阵,通常该类矩阵设置为50维或 100维
通过计算向量之间的距离,来体现词与词之间的相似性,解决词汇鸿沟的问题 实现时可以用0,1,2,3等对词语进行计算,这样的“话筒”可以用4表示,麦克可以用10表示
如何训练: 1. 没有直接的模型可以训练得到 2. 可以在训练语言模型的同时,得到词向量。
两个语言模型 CBOW:Continuous Bag-of-Words Skip-Gram:Continuous Skip-Gram Model
两种优化方法 Hierarchical Softmax Negative Sampling
.
CBOW and Skip-Gram
初始化值是零向量, 叶节点对应的单词的词向量是 随机初始化的。 CBOW 的目 标 是 根 据 上 下 文 来 预 测 当 前 词 语 的 概率Skip-Gram恰好相反, 它是根据当前词语来预测上下文的概率。这 两 种 方 法 都 利 用 人 工 神 经 网 络 作 为它们的分类算 法。起 初, 每 个 单 词 都 是 一 个 随 机 N 维 向 量,经过训练之后, 利用 CBOW 或者 Skip-Gram 方法获得每个单词的最优向量。
.
语言模型
• 判断一句话是不是正常人说出来的
给定一个字符串”w1, w2, w3, w4, … , wt”,计算它是自然语言的概率、 P(w1,w2,…,wt)=P(w1)×P(w2|w1)×P(w3|w1,w2)×…×P(wt|w1,w2,…,wt−1) P(大家,喜欢,吃,苹果)=p(大家)p(喜欢|大家)p(吃|大家,喜欢)p(苹果|大 家,喜欢,吃) p(大家)表示“大家”这个词在语料库里面出现的概率; p(喜欢|大家)表示“喜欢”这个词出现在“大家”后面的概率; p(吃|大家,喜欢)表示“吃”这个词出现在“大家喜欢”后面的概率; p(苹果|大家,喜欢,吃)表示“苹果”这个词出现在“大家喜欢吃”后面的概 率。 把这些概率连乘起来,得到的就是这句话平时出现的概率。 如果这个概率特别低,说明这句话不常出现,那么就不算是一句自然语言, 因为在语料库里面很少出现。如果出现的概率高,就说明是一句自然语言。
词向量模型—Word2Vec
.
前言
计算机
人类
VS
老外来访被请吃饭。落座后,一中国人说: “我先去方便一下。”老外不解,被告知 “方便”是“上厕所”之意。席间主宾大 悦。道别时,另一中国人对老外发出邀请: “我想在你方便的时候也请你吃饭。”老 外愣了,那人接着说: “如果你最近不 方便的话,咱找个你我都方便的时候一起 吃。
.
目录
1
基本概念
2
模型与方法
3
实际应用
.
词向量
• 自然语言中的词语在机器学习中的表示符号
• One-Hot Representation
例如: “话筒”表示为:[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, …] “麦克”表示为:[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, …]
实现时可以用0,1,2,3等对词语进行计算,这样的“话筒”可以用4表示,麦克 可以用10表示
问题: 1. 维度很大,当词汇较多时,可能会达到百万维,造成维度灾难 2. 词汇鸿沟:任意两个词之间都是孤立的,不能体现词与词之间的关系。
.
词向量
• Distributional Representation