CBOW词向量模型课件
词向量

算法架构
1
Skip-gram (SG)
训练策略
1
Hierarchical Softmax
2
Continuous Bags of Words (CBOW)
2
Negative Sampling
去掉了计算资源昂贵的中间层
改
进
运用语言模型来更多地考虑上下文
特定的训练策略
2–算 法 与 模 型
② Word2Vec模型-算法架构
模型特点:1,从深度学习的RBM模型出发,构建出Log-bilinear纯线性模型
2.隐藏层到输出层复用词向量,减少了变量使用 3.训练和预测速度得到提升
RNNLM模型
Mikolov,2012,” Statistical Language Models based on Neural Networks”
2–算 法 与 模 型
③ GloVe模型
Pennington,2014,”GloVe: Global Vectors for Word Representation”
训练速度快 统计信息利用充分 主要只用于词相似性分析 不适用于大规模语料分析
训练速度和效果取决于语料库大小
统计信息未得到充分利用 可进行更复杂的模式分析 可提升其他学习任务效果
xX wV
C&W 的词向量特点:1.避免了对于 softmax 层的昂贵计算 2.词表中只有小写单词 3.词向量是二次优化得到
2–算 法 与 模 型
①早 期 模 型
HLBL模型
03
Minh & Hinton,2007,” Three new graphical models for statistical language modelling” Minh & Hinton,2008,” A scalable hierarchical distributed language model”
《商务数据分析》第九章——复杂数据分析方法

• 主题模型是用来在大量的文档中发现潜在主题的一种统计模型。
• 一个文档通常包含多个主题且每个主题所占比例各不相同,主题模型能够统计文档中
的词语,根据文档中词的信息判断文档包含的主题以及各个主题所占比重。
• 一种典型的词袋模型:LDA
• 基本设想为一篇文档是由一组词组成的集合,词与词之间没有顺序和先后关系。同时,
• 为了将文本处理为模型可用的数据,需要先对文本进行预处理。一般预
处理步骤为分词、清洗、标准化、特征提取,然后将提取出来的特征应
用下游任务中,如分类、情感分析等。
商务数据分析
1. 文本预处理
• (1)文本分词
• 组成文本的词,被认为是重要的特征。因此文本分析首先要做的
是对文本进行分词。
• 对于英文来说,文本本来就是根据空格分开的,可以直接以空格
• Word2vec词向量模型
• 是一个小型的神经网络,目前较为流行的有两种模型:
• (1)CBOW模型:用上下文单词作为输入来预测目标词语,对于小型数据比较合适。
• (2)skip-gram模型:用一个词语作为输入来预测它周围的上下文,在大型语料中表
现更好。
• 两个模型均是一个三层的神经网络,分别包含输入层、隐藏层和输出层,输入层以词
出现的频率,它默认文档中的每个单词都是独立的。不依赖于其他单词是否出现。
• (1)词袋模型之TF-IDF算法(Term Frequency–Inverse Document Frequency,TF-IDF)
• 特征关键词应该是那些在某个文本中出现频率高而在整个语料库的其他文档中出现频率少的词或短语。
• 首先用d表示待处理的文档,t表示文档分词后的词语,用D表示语料库。TF(t, d)是词语t在文档d中出现的次数:
word2vec模型原理与实现
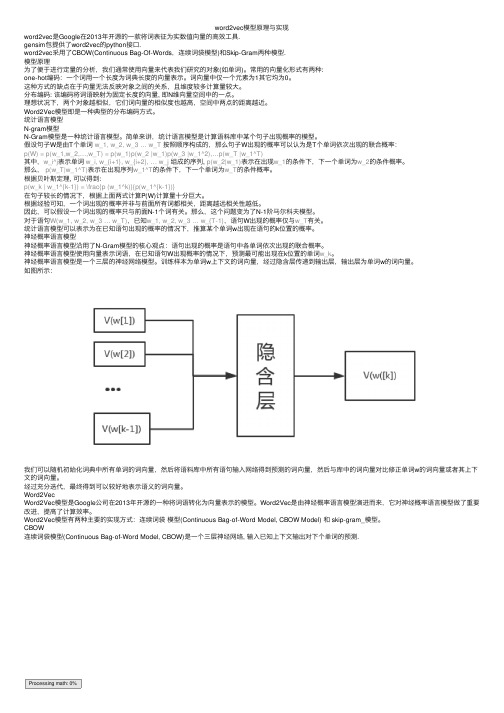
word2vec模型原理与实现word2vec是Google在2013年开源的⼀款将词表征为实数值向量的⾼效⼯具.gensim包提供了word2vec的python接⼝.word2vec采⽤了CBOW(Continuous Bag-Of-Words,连续词袋模型)和Skip-Gram两种模型.模型原理为了便于进⾏定量的分析,我们通常使⽤向量来代表我们研究的对象(如单词)。
常⽤的向量化形式有两种:one-hot编码:⼀个词⽤⼀个长度为词典长度的向量表⽰。
词向量中仅⼀个元素为1其它均为0。
这种⽅式的缺点在于向量⽆法反映对象之间的关系,且维度较多计算量较⼤。
分布编码: 该编码将词语映射为固定长度的向量, 即N维向量空间中的⼀点。
理想状况下,两个对象越相似,它们词向量的相似度也越⾼,空间中两点的距离越近。
Word2Vec模型即是⼀种典型的分布编码⽅式。
统计语⾔模型N-gram模型N-Gram模型是⼀种统计语⾔模型。
简单来讲,统计语⾔模型是计算语料库中某个句⼦出现概率的模型。
假设句⼦W是由T个单词w_1, w_2, w_3 … w_T 按照顺序构成的,那么句⼦W出现的概率可以认为是T个单词依次出现的联合概率:p(W) = p(w_1,w_2,…,w_T) = p(w_1)p(w_2 |w_1)p(w_3 |w_1^2),…p(w_T |w_1^T)其中,w_i^j表⽰单词w_i, w_{i+1}, w_{i+2}, … w_j组成的序列, p(w_2|w_1)表⽰在出现w_1的条件下,下⼀个单词为w_2的条件概率。
那么,p(w_T|w_1^T)表⽰在出现序列w_1^T的条件下,下⼀个单词为w_T的条件概率。
根据贝叶斯定理, 可以得到:p(w_k | w_1^{k-1}) = \frac{p (w_1^k)}{p(w_1^{k-1})}在句⼦较长的情况下,根据上⾯两式计算P(W)计算量⼗分巨⼤。
根据经验可知,⼀个词出现的概率并⾮与前⾯所有词都相关,距离越远相关性越低。
词向量原理

词向量原理词向量原理是自然语言处理中的重要概念,它通过将文本转化为向量表示,实现了计算机对文本的理解和处理。
本文将从词向量原理的基本概念、训练方法和应用领域三个方面进行阐述。
一、词向量原理的基本概念词向量是用来表示词语语义信息的向量,它能够将词语转化为计算机能够理解和处理的形式。
词向量的基本思想是通过将词语嵌入到一个高维空间中,使得具有相似语义的词语在该空间中距离较近。
常用的词向量表示方法有one-hot编码、词袋模型和分布式表示。
二、词向量的训练方法词向量的训练方法有基于统计的方法和基于神经网络的方法。
基于统计的方法主要有词频统计、共现矩阵和主题模型等。
其中,共现矩阵方法通过计算词语之间的共现频次来构建词向量。
基于神经网络的方法主要有CBOW和Skip-gram两种模型。
CBOW模型通过上下文预测目标词语,而Skip-gram模型则是通过目标词语预测上下文。
三、词向量的应用领域词向量在自然语言处理领域有广泛的应用。
其中,词语相似度计算是词向量应用的重要方向之一。
通过计算词向量之间的距离或相似度,可以实现词语的语义比较和相关性分析。
此外,词向量还可以用于文本分类、情感分析、信息检索等任务。
通过将文本转化为词向量表示,可以提高模型的表达能力和性能。
词向量原理是自然语言处理中的重要概念,它通过将词语转化为向量表示,实现了计算机对文本的理解和处理。
词向量的训练方法有基于统计的方法和基于神经网络的方法,而词向量的应用领域涵盖了词语相似度计算、文本分类、情感分析等任务。
词向量的应用为自然语言处理提供了重要的工具和方法,也为人们的语言交流和信息处理带来了便利。
NLP之word2vec:word2vec简介、安装、使用方法之详细攻略

NLP之word2vec:word2vec简介、安装、使用方法之详细攻略NLP之word2vec:word2vec简介、安装、使用方法之详细攻略word2vec简介word distributed embedding最早是Bengio 03年的论文"A Neural Probabilistic Language Model"提出来,rnn lm 在10年被mikolov提出。
word2vec 是 Google 于 2013 年开源推出的一个用于获取词向量(word vector)的工具包,它简单、高效。
word2vec也叫word embeddings,中文名“词向量”,作用就是将自然语言中的字词转为计算机可以理解的稠密向量Dense Vector。
所谓的word vector,就是指将单词向量化,将某个单词用特定的向量来表示。
将单词转化成对应的向量以后,就可以将其应用于各种机器学习的算法中去。
一般来讲,词向量主要有两种形式,分别是稀疏向量和密集向量。
word2vec的思想类似于antodecoder,但是并不是将自身作为训练目标,也不是用RBM来训练。
word2vec将 context和word5:别作为训练目标,Wskip-gram和CBOW。
word2vec其实就是two layer shallow neural network,减少了深度神经网络的复杂性,快速的生成word embedding.Skip-gram: works well with small amount of the training data, represents well even rare words or phrases.CBOW: several times faster to train than the skip-gram, slightly better accuracy for the frequent wordsThis can get even a bit more complicated if you consider that there are two different ways how to train the models: the normalized hierarchical softmax, and the un-normalized negative sampling. Both work quite differently.1、稀疏向量One-Hot Encoder在word2vec出现之前,自然语言处理经常把字词转为离散的单独的符号,也就是One-Hot Encoder。
doc2vec原理

Doc2Vec原理解析1. 引言Doc2Vec是一种用于将文本转换为向量表示的算法,它是Word2Vec的扩展。
Word2Vec算法将单词映射为固定长度的向量,而Doc2Vec则将整个文档映射为向量。
Doc2Vec广泛应用于文本分类、信息检索、推荐系统等领域。
2. Word2Vec回顾在介绍Doc2Vec之前,我们先回顾一下Word2Vec的基本原理。
Word2Vec是一种用于学习单词向量表示的算法,它有两个变体:CBOW(Continuous Bag of Words)和Skip-gram。
2.1 CBOW模型CBOW模型通过上下文预测中心词。
假设我们有一个句子”the cat sat on the mat”,我们希望通过上下文”the”, “sat”, “on”, “mat”来预测中心词”cat”。
CBOW模型的目标是最大化给定上下文条件下中心词的概率。
具体来说,CBOW模型将上下文中的单词向量进行平均,并通过一个全连接层将其转换为中心词的预测向量。
然后使用softmax函数计算预测向量对应每个单词的概率分布,并最大化实际中心词的概率。
2.2 Skip-gram模型Skip-gram模型与CBOW相反,它通过中心词预测上下文。
假设我们有一个句子”the cat sat on the mat”,我们希望通过中心词”cat”来预测上下文”the”, “sat”, “on”, “mat”。
Skip-gram模型的目标是最大化给定中心词条件下上下文单词的概率。
具体来说,Skip-gram模型将中心词向量通过一个全连接层转换为预测向量,并使用softmax函数计算预测向量对应每个上下文单词的概率分布。
然后最大化实际上下文单词的概率。
3. Doc2Vec原理Doc2Vec是Word2Vec的扩展,它不仅可以学习单词向量表示,还可以学习整个文档(或段落)的向量表示。
Doc2Vec有两个变体:PV-DM(Paragraph Vector - Distributed Memory)和PV-DBOW(Paragraph Vector - Distributed Bag of Words)。
在python下实现word2vec词向量训练与加载实例

在python下实现word2vec词向量训练与加载实例项⽬中要对短⽂本进⾏相似度估计,word2vec是⼀个很⽕的⼯具。
本⽂就word2vec的训练以及加载进⾏了总结。
word2vec的原理就不描述了,word2vec词向量⼯具是由google开发的,输⼊为⽂本⽂档,输出为基于这个⽂本⽂档的语料库训练得到的词向量模型。
通过该模型可以对单词的相似度进⾏量化分析。
word2vec的训练⽅法有2种,⼀种是通过word2vec的官⽅⼿段,在linux环境下编译并执⾏。
在github上下载word2vec的安装包,然后make编译。
查看demo-word.sh脚本,得到word2vec的执⾏命令:./word2vec -train text8 -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads20 -binary 1 -iter 15参数解释:1)-train:需要训练的语料库,text8为语料库⽂件名2)-output:输出的词向量⽂件,vectors.bin为输出词向量⽂件名,.bin后缀为⼆进制⽂件。
若要以⽂档的形式查看词向量⽂件,需要将-binary参数的值由1改为03)-cbow:是否使⽤cbow模型进⾏训练。
参数为1表⽰使⽤cbow,为0表⽰不使⽤cbow4)-size:词向量的维数,默认为200维。
5)-window:训练过程中截取上下⽂的窗⼝⼤⼩,默认为8,即考虑⼀个词前8个和后8个词6)-negative:若参数⾮0,表明采样随机负采样的⽅法,负样本⼦集的规模默认为25。
若参数值为0,表⽰不使⽤随机负采样模型。
使⽤随机负采样⽐Hierarchical Softmax模型效率更⾼。
7)-hs:是否采⽤基于Hierarchical Softmax的模型。
参数为1表⽰使⽤,0表⽰不使⽤8)-sample:语料库中的词频阈值参数,词频⼤于该阈值的词,越容易被采样。
word2vec词向量模型 ppt课件

实现时可以用0,1,2,3等对词语进行计算,这样的“话筒”可以用4表示,麦克 可以用10表示
问题: 1. 维度很大,当词汇较多时,可能会达到百万维,造成维度灾难 2. 词汇鸿沟:任意两个词之间都是孤立的,不能体现词与词之间的关系。
ppt课件
4
词向量
• Distributional Representation
两个语言模型 CBOW:Continuous Bag-of-Words Skip-Gram:Continuous Skip-Gram Model
两种优化方法 Hierarchical Softmax Negative Sampling
ppt课件
8
CBOW and Skip-Gram
初始化值是零向量, 叶节点对应的单词的词向量是 随机初始化的。 CBOW 的目 标 是 根 据 上 下 文 来 预 测 当 前 词 语 的 概率Skip-Gram恰好相反, 它是根据当前词语来预测上下文的概率。这 两 种 方 法 都 利 用 人 工 神 经 网 络 作 为它们的分类 算法。起 初, 每 个 单 词 都 是 一 个 随 机 N 维 向 量,经过训练之后, 利用 CBOW 或者 SkipGram方法获得每个单词的最优向量。
ppt课件
1
前言
计算机
人类
VS
老外来访被请吃饭。落座后,一中国人说: “我先去方便一下。”老外不解,被告知 “方便”是“上厕所”之意。席间主宾大 悦。道别时,另一中国人对老外发出邀请: “我想在你方便的时候也请你吃饭。”老 外愣了,那人接着说: “如果你最近不 方便的话,咱找个你我都方便的时候一起 吃。
ppt课件
9
CBOW模型结构
输入层是上下文的词语的词 向量,是CBOW模型的一 个参数。训练开始的时候, 词向量是个随机值,随着训 练的进行不断被更新。当模 型训练完成之后可以获得较 为准确的词向量。