LZW编码算法详解
数据压缩算法LZLZ和LZW的原理与实现

数据压缩算法LZLZ和LZW的原理与实现在计算机科学领域,数据压缩算法是一种用于减小数据文件大小的方法。
其中,LZLZ和LZW是两种常见的数据压缩算法。
本文将详细介绍这两种算法的原理和实现。
一、LZLZ算法LZLZ算法是一种基于字典的数据压缩算法。
该算法的原理是将连续出现的重复字符序列替换为较短的标记。
具体实现过程如下:1. 初始化字典,将所有可能的字符序列添加到字典中。
2. 从输入数据中读取字符序列,并查找字典中是否存在相同的序列。
3. 如果找到匹配的序列,则将其替换为字典中对应的标记,并将序列长度增加1。
4. 如果未找到匹配的序列,则将当前字符添加到字典中,并输出该字符。
5. 重复步骤2至4,直到处理完所有输入数据。
通过将重复的序列替换为较短的标记,LZLZ算法可以有效地减小数据文件的大小。
二、LZW算法LZW算法也是一种基于字典的数据压缩算法,与LZLZ算法类似,但存在一些差异。
下面是LZW算法的原理和实现过程:1. 初始化字典,将所有可能的单字符添加到字典中。
2. 从输入数据中读取字符序列,并根据当前已读的序列来搜索字典。
3. 如果找到匹配的序列,则将已读的序列继续扩展一个字符,并重复步骤2。
4. 如果未找到匹配的序列,则将字典中最长的已读序列对应的标记输出,并将已读的序列和下一个字符添加到字典中。
5. 重复步骤2至4,直到处理完所有输入数据。
LZW算法通过动态扩展字典,可以更好地利用数据的重复性。
相比于LZLZ算法,LZW算法通常能够达到更高的压缩率。
三、LZLZ和LZW的比较LZLZ算法和LZW算法在原理上有相似之处,都是通过字典来实现数据压缩。
然而,两者之间存在一些差异。
首先,LZLZ算法使用固定长度的标记,这使得算法相对简单,但可能导致压缩率较低。
与之相反,LZW算法可以根据需要动态扩展字典,以适应不同类型的数据,从而获得更高的压缩率。
其次,LZLZ算法的字典只包含单个字符和字串,而LZW算法的字典可以包含任意长度的序列。
LZW编码

• 前缀(Prefix):也是一个字符串,不过通常用在 另一个字符的前面,而且它的长度可以为0;根 (Root):一个长度的字符串;编码(Code):一 个数字,按照固定长度(编码长度)从编码流中取 出,编译表的映射值;图案:一个字符串,按不定 长度从数据流中读出,映射到编译表条目.
LZW编码算法基本原理 • 提取原始文本文件数据中的不同字符,基于这 些字符创建一个编译表,然后用编译表中的字符的 索引来替代原始文本文件数据中的相应字符,减少 原始数据大小。 看起来和调色板图象的实现原理差不多,但是 应该注意到的是,我们这里的编译表不是事先创建 好的,而是根据原始文件数据动态创建的,解码时 还要从已编码的数据中还原出原来的编译表.
LZW编码举例
输入数据流: 位置 1
字符
2 3 4 5 6 7 8 9
编码过程:
步骤AB源自B 码字1 2 3
A
B
A 词典
A B C AB BB BA ABA ABAC
B
A 输出
C
位置
1 2 3 4 5
2014-5-16
1 2 3 4 6
4 5 6 7 8
1 2 2 4 7 3
6
LZW解压算法
解压步骤如下: (1)译码开始时Dictionary包含所有的根。 (2)读入在编码数据流中的第一个码字 cW(它表示一个Root)。 (3)输出String.cW到字符数据流Charstream。 (4)使pW=cW 。 (5)读入编码数 据流 的下一个码字cW 。 (6)目前在字典中有String.cW吗? 如果是:1)将String.cW输出给字符数据流; 2)使P=String.pW; 3)使C=String.cW的第一个字符; 4)将字符 串P+C添 加进Dictionray。 如果否: 1)使P=String.pW ; 2)使C=String.pW的第一个字符; 3)将字符串P+C输出到字符数据流并将其添加进Dictionray(现在它与cW相一致)。 (7)在编码数据 流中还有Codeword吗? 如果是:返回(4)继 续进行 译码 。 如果否:结束译码 。
LZW编码算法详解

LZW编码算法详解LZW(Lempel-Ziv & Welch)编码又称字串表编码,是Welch将Lemple和Ziv所提出来的无损压缩技术改进后的压缩方法。
GIF图像文件采用的是一种改良的LZW 压缩算法,通常称为GIF-LZW压缩算法。
下面简要介绍GIF-LZW的编码与解码方程解:例现有来源于二色系统的图像数据源(假设数据以字符串表示):aabbbaabb,试对其进行LZW编码及解码。
1)根据图像中使用的颜色数初始化一个字串表(如表1),字串表中的每个颜色对应一个索引。
在初始字串表的LZW_CLEAR和LZW_EOI分别为字串表初始化标志和编码结束标志。
设置字符串变量S1、S2并初始化为空。
2)输出LZW_CLEAR在字串表中的索引3H(见表2第一行)。
3)从图像数据流中第一个字符开始,读取一个字符a,将其赋给字符串变量S2。
判断S1+S2=“a”在字符表中,则S1=S1+S2=“a”(见表2第二行)。
4)读取图像数据流中下一个字符a,将其赋给字符串变量S2。
判断S1+S2=“aa”不在字符串表中,输出S1=“a”在字串表中的索引0H,并在字串表末尾为S1+S2="aa"添加索引4H,且S1=S2=“a”(见表2第三行)。
5)读下一个字符b赋给S2。
判断S1+S2=“ab”不在字符串表中,输出S1=“a”在字串表中的索引0H,并在字串表末尾为S1+S2=“ab”添加索引5H,且S1=S2=“b”(见表2第四行)。
6)读下一个字符b赋给S2。
S1+S2=“bb”不在字串表中,输出S1=“b”在字串表中的索引1H,并在字串表末尾为S1+S2=“bb”添加索引6H,且S1=S2=“b”(见表2第五行)。
7)读字符b赋给S2。
S1+S2=“bb”在字串表中,则S1=S1+S2=“bb”(见表2第六行)。
8)读字符a赋给S2。
S1+S2=“bba”不在字串表中,输出S1=“bb”在字串表中的索引6H,并在字串表末尾为S1+S2=“bba”添加索引7H,且S1=S2=“a”(见表2第七行)。
LZW编码详解

1 NULL 2a 3a 4b 5b 6b 7a 8a 9b
NULL 2H
a
aa
0H
ab
0H
bb
1H
bb
bba
6H
aa
aab
4H
NULL a a b b bb a aa b
aa<4H> ab<5H> bb<6H>
bba<7H>
Aab<8H>
LZW编码步骤
(11)读字符b赋给S2。S1+S2=”bb”,在字符串表中,
序号 输入数据S2 S1+S2 输出结果
S1
生成新字符及索引
1
NULL
2
a
3
a
NULL
2H
a
aa
0H
NULL a a
aa<4H>
LZW编码步骤
(5)读下一个字符b赋给S2。判断S1+S2=”ab”不在字符串 表中,输出S1=“a”在字串表中的索引0H,并在字符串表末 尾为S1+S2=“ab”添加索引5H,且S1= S2=“b”
则 S1= S1+S2=“b”
序号 输入数据S2 S1+S2 输出结果
S1
生成新字符及索引
1 NULL 2a 3a 4b 5b 6b 7a 8a 9b 10 b
NULL 2H
a
aa
0H
ab
0H
bb
1H
bb
bba
6H
aa
aab
4H
bb
NULL a a b b bb a aa b bb
aa<4H> ab<5H> bb<6H>
LZW压缩算法介绍

LZW压缩算法介绍LZW (Lempel-Ziv-Welch) 压缩算法是一种基于字典的无损压缩算法。
它由Abraham Lempel、Jacob Ziv和Terry Welch于1977年共同开发,被广泛应用于无损图像压缩、文本压缩等领域。
在编码阶段中,首先通过初始化一个字典,其中包含了所有可能的输入符号,并将其索引与其对应编码值相对应。
算法从输入数据的第一个符号开始,将其添加到当前待编码的字符串中。
然后,它迭代地检查是否存在一个包含当前字符串和下一个符号的条目在字典中。
如果存在,则将当前字符串扩展为当前字符串加上下一个符号,并继续检查。
如果不存在,则将当前字符串的编码输出,并将当前字符串加上下一个符号添加到字典中。
此过程将重复,直到输入数据中的所有符号都编码为字典中的条目。
在解码阶段中,解码器初始化一个与编码过程使用相同的字典。
它从压缩数据流中读取编码值,并将其对应的字符串输出。
解码器在字典中根据编码值查找对应的字符串,然后将它添加到输出流中。
然后,解码器通过查找输出流尾部的条目,将一个新的编码加上条目的第一个符号创建一个新的条目,并将该新的条目添加到字典中。
这个过程将重复,直到所有编码值都被解码为对应的字符串。
LZW压缩算法的优点是它能够达到很高的压缩比。
由于它利用了字典中的重复条目,它可以将输入数据中的相同模式编码为较短的编码值。
此外,它还具有较快的压缩和解压缩速度,因为它只需要查找字典而不需要进行复杂的算术操作。
然而,LZW算法也有一些限制。
首先,它要求压缩器和解压器具有相同的初始化字典。
这使得在使用LZW算法进行数据传输时,压缩器和解压器必须事先共享相同的字典,否则解压得到的数据可能会不正确。
另外,由于字典的大小是固定的,当字典已满时,新的条目无法添加,这会限制算法的扩展性。
尽管有一些限制,LZW压缩算法仍然是一种经典且广泛使用的压缩算法。
它在图像、音频、视频以及文本等领域都有应用。
JPEG压缩 原理 LZW算法

1 LZW算法的大体思想LZW是一种比较复杂的压缩算法,其压缩效率也比较高。
我们在这里只介绍一下它的基本原理:LZW把每一个第一次出现的字符串用一个数值来编码,在还原程序中再将这个数值还成原来的字符串。
例如:用数值0x100代替字符串“abccddeee”,每当出现该字符串时,都用0x100代替,这样就起到了压缩的作用。
至于0x100与字符串的对应关系则是在压缩过程中动态生成的,而且这种对应关系隐含在压缩数据中,随着解压缩的进行这张编码表会从压缩数据中逐步得到恢复,后面的压缩数据再根据前面数据产生的对应关系产生更多的对应关系,直到压缩文件结束为止。
LZW是无损的。
GIF文件采用了这种压缩算法。
要注意的是,LZW算法由Unisys公司在美国申请了专利,要使用它首先要获得该公司的认可。
2JPEG压缩编码标准JPEG是联合图象专家组(Joint Picture Expert Group)的英文缩写,是国际标准化组织(ISO)和CCITT联合制定的静态图象的压缩编码标准。
和相同图象质量的其它常用文件格式(如GIF,TIFF,PCX)相比,JPEG是目前静态图象中压缩比最高的。
我们给出具体的数据来对比一下。
例图采用Windows95目录下的Clouds.bmp,原图大小为640*480,256色。
用工具SEA(version1.3)将其分别转成24位色BMP、24位色JPEG、GIF(只能转成256色)压缩格式、24位色TIFF压缩格式、24位色TGA压缩格式。
得到的文件大小(以字节为单位)分别为:921,654,17,707,177,152,923,044,768,136。
可见JPEG比其它几种压缩比要高得多,而图象质量都差不多(JPEG处理的颜色只有真彩和灰度图)。
正是由于JPEG的高压缩比,使得它广泛地应用于多媒体和网络程序中,例如HTML语法中选用的图象格式之一就是JPEG(另一种是GIF)。
这是显然的,因为网络的带宽非常宝贵,选用一种高压缩比的文件格式是十分必要的。
C语言数据压缩哈夫曼编码和LZW算法

C语言数据压缩哈夫曼编码和LZW算法C语言数据压缩——哈夫曼编码与LZW算法在计算机科学中,数据压缩是一种重要的技术,它可以有效地减少数据的存储空间和传输带宽。
本文将介绍两种常用的数据压缩算法,分别是哈夫曼编码和LZW算法,并给出它们在C语言中的实现方法。
一、哈夫曼编码1. 哈夫曼编码的原理哈夫曼编码是一种前缀编码方法,它根据字符出现的频率构建一棵表示编码的二叉树,频率越高的字符离根节点越近。
通过将二叉树的左、右分支分别标记为0和1,可以得到每个字符的唯一编码。
2. 实现哈夫曼编码的步骤(1)统计字符频率:遍历待压缩的数据,统计每个字符出现的频率。
(2)构建哈夫曼树:根据字符频率构建哈夫曼树,使用优先队列或堆来实现。
(3)生成哈夫曼编码表:通过遍历哈夫曼树,从根节点到各个叶子节点的路径上的0、1序列构建编码表。
(4)进行编码:根据生成的哈夫曼编码表,将待压缩数据转换为对应的编码。
(5)进行解码:利用哈夫曼树和生成的哈夫曼编码表,将编码解析为原始数据。
二、LZW算法1. LZW算法的原理LZW算法是一种字典压缩算法,它不需要事先进行字符频率统计,而是根据输入数据动态构建一个字典。
将输入数据中的序列与字典中的条目逐一匹配,若匹配成功则继续匹配下一个字符,若匹配失败则将当前序列加入字典,并输出该序列的编码。
2. 实现LZW算法的步骤(1)初始化字典:将所有可能的单字符作为字典的初始条目。
(2)读入输入数据:依次读入待压缩的数据。
(3)匹配字典:将读入的字符与字典中的条目逐一匹配,直到无法匹配成功。
(4)输出编码:将匹配成功的条目对应的编码输出。
(5)更新字典:若匹配失败,则将当前序列添加到字典中,并输出前一个匹配成功的条目对应的编码。
(6)重复步骤(3)至(5),直到输入数据全部处理完毕。
三、C语言实现1. 哈夫曼编码的C语言实现```c// TODO:哈夫曼编码的C语言实现```2. LZW算法的C语言实现```c// TODO:LZW算法的C语言实现```四、总结本文介绍了C语言中两种常用的数据压缩算法——哈夫曼编码和LZW算法。
多媒体技术编码
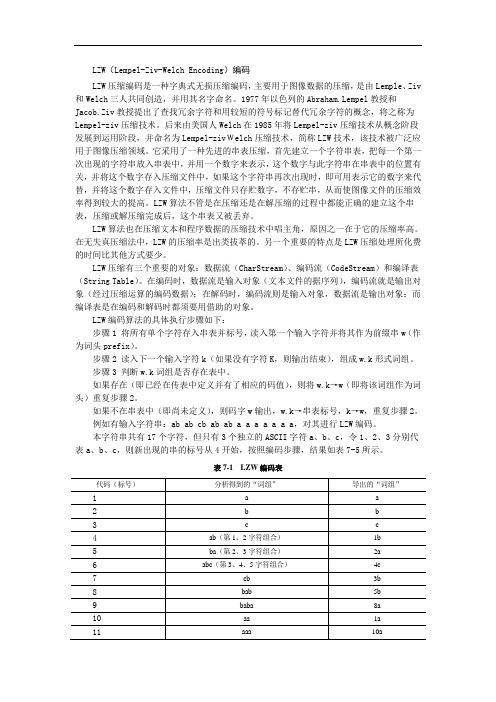
LZW(Lempel-Ziv-Welch Encoding)编码LZW压缩编码是一种字典式无损压缩编码,主要用于图像数据的压缩,是由Lemple、Ziv 和Welch三人共同创造,并用其名字命名。
1977年以色列的Abraham.Lempel教授和Jacob.Ziv教授提出了查找冗余字符和用较短的符号标记替代冗余字符的概念,将之称为Lempel-ziv压缩技术。
后来由美国人Welch在1985年将Lempel-ziv压缩技术从概念阶段发展到运用阶段,并命名为Lempel-zivWelch压缩技术,简称LZW技术,该技术被广泛应用于图像压缩领域。
它采用了一种先进的串表压缩,首先建立一个字符串表,把每一个第一次出现的字符串放入串表中,并用一个数字来表示,这个数字与此字符串在串表中的位置有关,并将这个数字存入压缩文件中,如果这个字符串再次出现时,即可用表示它的数字来代替,并将这个数字存入文件中,压缩文件只存贮数字,不存贮串,从而使图像文件的压缩效率得到较大的提高。
LZW算法不管是在压缩还是在解压缩的过程中都能正确的建立这个串表,压缩或解压缩完成后,这个串表又被丢弃。
LZW算法也在压缩文本和程序数据的压缩技术中唱主角,原因之一在于它的压缩率高。
在无失真压缩法中,LZW的压缩率是出类拔萃的。
另一个重要的特点是LZW压缩处理所化费的时间比其他方式要少。
LZW压缩有三个重要的对象:数据流(CharStream)、编码流(CodeStream)和编译表(String Table)。
在编码时,数据流是输入对象(文本文件的据序列),编码流就是输出对象(经过压缩运算的编码数据);在解码时,编码流则是输入对象,数据流是输出对象;而编译表是在编码和解码时都须要用借助的对象。
LZW编码算法的具体执行步骤如下:步骤1 将所有单个字符存入串表并标号,读入第一个输入字符并将其作为前缀串w(作为词头prefix)。
步骤2 读入下一个输入字符k(如果没有字符K,则输出结束),组成w.k形式词组。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LZW编码算法详解LZW(Lempel-Ziv & Welch)编码又称字串表编码,是Welch将Lemple和Ziv所提出来的无损压缩技术改进后的压缩方法。
GIF图像文件采用的是一种改良的LZW 压缩算法,通常称为GIF-LZW压缩算法。
下面简要介绍GIF-LZW的编码与解码方程解:例现有来源于二色系统的图像数据源(假设数据以字符串表示):aabbbaabb,试对其进行LZW编码及解码。
1)根据图像中使用的颜色数初始化一个字串表(如表1),字串表中的每个颜色对应一个索引。
在初始字串表的LZW_CLEAR和LZW_EOI分别为字串表初始化标志和编码结束标志。
设置字符串变量S1、S2并初始化为空。
2)输出LZW_CLEAR在字串表中的索引3H(见表2第一行)。
3)从图像数据流中第一个字符开始,读取一个字符a,将其赋给字符串变量S2。
判断S1+S2=“a”在字符表中,则S1=S1+S2=“a”(见表2第二行)。
4)读取图像数据流中下一个字符a,将其赋给字符串变量S2。
判断S1+S2=“aa”不在字符串表中,输出S1=“a”在字串表中的索引0H,并在字串表末尾为S1+S2="aa"添加索引4H,且S1=S2=“a”(见表2第三行)。
5)读下一个字符b赋给S2。
判断S1+S2=“ab”不在字符串表中,输出S1=“a”在字串表中的索引0H,并在字串表末尾为S1+S2=“ab”添加索引5H,且S1=S2=“b”(见表2第四行)。
6)读下一个字符b赋给S2。
S1+S2=“bb”不在字串表中,输出S1=“b”在字串表中的索引1H,并在字串表末尾为S1+S2=“bb”添加索引6H,且S1=S2=“b”(见表2第五行)。
7)读字符b赋给S2。
S1+S2=“bb”在字串表中,则S1=S1+S2=“bb”(见表2第六行)。
8)读字符a赋给S2。
S1+S2=“bba”不在字串表中,输出S1=“bb”在字串表中的索引6H,并在字串表末尾为S1+S2=“bba”添加索引7H,且S1=S2=“a”(见表2第七行)。
9)读字符a赋给S2。
S1+S2=“aa”在字串表中,则S1=S1+S2=“aa”(见表2第八行)。
10)读字符b赋给S2。
S1+S2=“aab”不在字串表中,输出S1=“aa”在字串表中的索引4H,并在字串表末尾为S1+S2=“aab”添加索引8H,且S1=S2=“b”(见表2第九行)。
11)读字符b赋给S2。
S1+S2=“bb”,在字串表中,则S1=S1+S2=“b”(见表2第十行)。
12)输出S1中的字符串"b"在字串表中的索引1H(见表2第十一行)。
13)输出结束标志LZW_EOI的索引3H,编码完毕。
最后的编码结果为"30016463“。
下面对上述编码结果"30016463"进行解码。
同样先初始化字符串表,结果如表1所示。
1)首先读取第一个编码Code=3H,由于它为LZW_CLEAR,无输出(见表3第一行)。
2)读入下一个编码Code=0H,由于字符串表中存在该索引,因此输出字符串表中0H对应的字符串"a",同时使OldCode=Code=0H(见表3第二行)。
3)读下一个编码Code=0H,字符串表中存在该索引,输出0H所对应的字符串"a",然后将OldCode=0H所对应的字符串"a"加上Code=0H所对应的字符串的第一个字符"a",即"aa"添加到字串表中,其索引为4H,同时使OldCode=Code=0H(见表3第三行)。
4)读下一个编码Code=1H,字串表中存在该索引,输出1H所对应的字符串"b",然后将OldCode=0H所对应的字符串"a"加上Code=1H所对应的字符串的第一个字符"b",即"ab"添加到字串表中,其索引为5H,同时使OldCode=Code=1H(见表3第四行)。
5)读入下一个编码Code=6H,由于字串表中不存在该索引,因此输出OldCode=1H所对应的字符串"b"加上OldCode的第一个字符"b“,即"bb",同时将"bb"添加到字符串表中,其索引为6H,同时使OldCode=Code=6H(见表3第五行)。
6)读下一个编码Code=4H,字串表中存在该索引,输出4H所对应的字符串"aa",然后将OldCode=6H所对应的字符串"bb"加上Code=4H所对应的字符串的第一个字符"a",即"bba"添加到字串表中,其索引为7H,同时使OldCode=Code=4H(见表3第六行)。
7)读下一个编码Code=6H,字串表中存在该索引,输出6H所对应的字符串"bb",然后将OldCode=4H所对应的字符串"aa"加上Code=6H所对应的字符串的第一个字符"b",即"aab"添加到字串表中,其索引为8H,同时使OldCode=Code=6H(见表3第七行)。
8)读下一个编码Code=3H,它等于LZW_EOI,数据解码完毕(见表3第八行)。
最后的解码结果为aabbbaabb。
由此可见,LZW编码算法在编码与解码过程中所建立的字符串表是一样的,都是动态生成的,因此在压缩文件中不必保存字符串表。
1.LZW的全称是什么?Lempel-Ziv-Welch (LZW).2. LZW的简介和压缩原理是什么?LZW压缩算法是一种新颖的压缩方法,由Lemple-Ziv-Welch 三人共同创造,用他们的名字命名。
它采用了一种先进的串表压缩,将每个第一次出现的串放在一个串表中,用一个数字来表示串,压缩文件只存贮数字,则不存贮串,从而使图象文件的压缩效率得到较大的提高。
奇妙的是,不管是在压缩还是在解压缩的过程中都能正确的建立这个串表,压缩或解压缩完成后,这个串表又被丢弃。
LZW算法中,首先建立一个字符串表,把每一个第一次出现的字符串放入串表中,并用一个数字来表示,这个数字与此字符串在串表中的位置有关,并将这个数字存入压缩文件中,如果这个字符串再次出现时,即可用表示它的数字来代替,并将这个数字存入文件中。
压缩完成后将串表丢弃。
如"print" 字符串,如果在压缩时用266表示,只要再次出现,均用266表示,并将"print"字符串存入串表中,在图象解码时遇到数字266,即可从串表中查出266所代表的字符串"print",在解压缩时,串表可以根据压缩数据重新生成。
3.在详细介绍算法之前,先列出一些与该算法相关的概念和词汇1)'Character':字符,一种基础数据元素,在普通文本文件中,它占用1个单独的byte,而在图像中,它却是一种代表给定像素颜色的索引值。
2)'CharStream':数据文件中的字符流。
3)'Prefix':前缀。
如这个单词的含义一样,代表着在一个字符最直接的前一个字符。
一个前缀字符长度可以为0,一个prefix和一个character可以组成一个字符串(string),4)'Suffix':后缀,是一个字符,一个字符串可以由(A,B)来组成,A是前缀,B是后缀,当A 长度为0的时候,代表Root,根5)'Code:码,用于代表一个字符串的位置编码6)'Entry':一个Code和它所代表的字符串(string)4.压缩算法的简单示例,不是完全实现LZW算法,只是从最直观的角度看lzw算法的思想对原始数据ABCCAABCDDAACCDB进行LZW压缩原始数据中,只包括4个字符(Character),A,B,C,D,四个字符可以用一个2bit的数表示,0-A,1-B,2-C,3-D,从最直观的角度看,原始字符串存在重复字符:ABCCAABCDDAACCDB,用4代表AB,5代表CC,上面的字符串可以替代表示为:45A4CDDAA5DB,这样是不是就比原数据短了一些呢!5.LZW算法的适用范围为了区别代表串的值(Code)和原来的单个的数据值(String),需要使它们的数值域不重合,上面用0-3来代表A-D,那么AB就必须用大于3的数值来代替,再举另外一个例子,原来的数值范围可以用8bit来表示,那么就认为原始的数的范围是0~255,压缩程序生成的标号的范围就不能为0~255(如果是0-255,就重复了)。
只能从256开始,但是这样一来就超过了8位的表示范围了,所以必须要扩展数据的位数,至少扩展一位,但是这样不是增加了1个字符占用的空间了么?但是却可以用一个字符代表几个字符,比如原来255是8bit,但是现在用256来表示254,255两个数,还是划得来的。
从这个原理可以看出LZW 算法的适用范围是原始数据串最好是有大量的子串多次重复出现,重复的越多,压缩效果越好。
反之则越差,可能真的不减反增了。
6.LZW算法中特殊标记随着新的串(string)不断被发现,标号也会不断地增长,如果原数据过大,生成的标号集(string table)会越来越大,这时候操作这个集合就会产生效率问题。
如何避免这个问题呢?Gif在采用lzw算法的做法是当标号集足够大的时候,就不能增大了,干脆从头开始再来,在这个位置要插入一个标号,就是清除标志CLEAR,表示从这里我重新开始构造字典,以前的所有标记作废,开始使用新的标记。
这时候又有一个问题出现,足够大是多大?这个标号集的大小为比较合适呢?理论上是标号集大小越大,则压缩比率就越高,但开销也越高。
一般根据处理速度和内存空间连个因素来选定。
GIF规范规定的是12位,超过12位的表达范围就推倒重来,并且GIF为了提高压缩率,采用的是变长的字长。
比如说原始数据是8位,那么一开始,先加上一位再说,开始的字长就成了9位,然后开始加标号,当标号加到512时,也就是超过9为所能表达的最大数据时,也就意味着后面的标号要用10位字长才能表示了,那么从这里开始,后面的字长就是10位了。
依此类推,到了2^12也就是4096时,在这里插一个清除标志,从后面开始,从9位再来。
GIF规定的清除标志CLEAR的数值是原始数据字长表示的最大值加1,如果原始数据字长是8,那么清除标志就是256,如果原始数据字长为4那么就是16。