LZW编码编程实现(C++版)
lzw压缩、解压缩 C语言算法实现

将源文件拷贝到当前目录下,打开源程序lzw.cbp,在main.cpp中更改源文件、压缩文件、解压文件的名称、路径:#define S() (strcpy(sourfile, "sourfile.jpg")) //源文件名及路径#define C() (strcpy(codefile, "codefile.lzw")) //压缩文件名及路径#define D() (strcpy(destfile, "destfile.jpg")) //解压文件名及路径下面是具体实现,总共四个文件://头文件模块:lzw.h#ifndef LZW_H_INCLUDED#define LZW_H_INCLUDED#define N 90000#define M 100typedef unsigned int Uint;/*函数功能: 将sourfile文件用LZW压缩到codefile文件中函数参数:待压缩文件/压缩目标文件函数返回值:压缩成功(TRUE)/压缩失败(FALSE)*/void LzwEncoding(char sourfile[], char codefile[]);/*函数功能: 将codefile文件用LZW解压到destfilefile文件中函数参数:压缩目标文件/解压文件函数返回值:解压成功(TRUE)/解压失败(FALSE)*/void LzwDecoding(char codefile[], char destfile[]);/*函数功能:判断前缀数组与当前字符的结合是否在字典中存在索引函数参数:当前字符(cbuff)函数返回值:在字典中(TRUE)/不在字典中(F ALSE)*/bool IsFindDictKey(Uint buff);/*函数功能:判断前缀数组与当前字符的结合是否在字典中存在索引函数参数:前缀数组(preFix)/前缀数组的有效长度(preCount)/当前字符(cbuff)函数返回值:在字典中(TRUE)/不在字典中(F ALSE)*/bool IsDictValue(Uint preFix[], Uint preCount, Uint cbuff);/*函数功能:查找前缀数组在字典中的索引函数参数:前缀数组(preFix)/前缀数组的有效长度(preCount)函数返回值:前缀数组在字典中的索引*/Uint FindDictKey(Uint preFix[], Uint preCount);extern Uint dict[N][M]; //全局字典extern char sourfile[20]; //全局带压缩文件extern char codefile[20]; //全局压缩文件extern char destfile[20]; //全局解压文件#endif // LZW_H_INCLUDED运行源程序将执行压缩机解压缩两个过程:LzwEncoding(sourfile, codefile); //压缩文件sourfile到codefile LzwDecoding(codefile, destfile); //解压文件codefile到destfile//主函数模块:main.cpp#include <stdio.h>#include <stdlib.h>#include <string.h>#include "lzw.h"#define S() (strcpy(sourfile, "sourfile.pdf"))#define C() (strcpy(codefile, "codefile.lzw"))#define D() (strcpy(destfile, "destfile.pdf"))using namespace std;Uint dict[N][M]; //全局字典int main(void){char sourfile[20];char codefile[20];char destfile[20];S();C();D();LzwEncoding(sourfile, codefile);LzwDecoding(codefile, destfile);return 0;}//压缩模块:LzwEncoding.cpp#include <stdio.h>#include <stdlib.h>#include <windows.h>#include "lzw.h"using namespace std;/*函数功能:查找前缀数组在字典中的索引函数参数:前缀数组(preFix)/前缀数组的有效长度(preCount) 函数返回值:前缀数组在字典中的索引*/Uint DictKey(Uint preFix[], Uint preCount){Uint i;int flag = 0;for (i = 0; i < N; i++){Uint j = preCount;if (dict[i][0] == preCount){flag = 1;while ( j-- ){if (dict[i][j+1] != preFix[j]){flag = 0;break;}}}if ( flag ) break;}return i;}/*函数功能:判断前缀数组与当前字符的结合是否在字典中存在索引函数参数:前缀数组(preFix)/前缀数组的有效长度(preCount)/当前字符((int)sbuff[count]) 函数返回值:在字典中(TRUE)/不在字典中(F ALSE)*/bool IsDictValue(Uint preFix[], Uint preCount, Uint cbuff){int flag = 0;for (Uint i = 0; i < N; i++){if ((dict[i][0] == preCount+1) && (dict[i][preCount+1] == cbuff)){flag = 1;for (Uint j = 0; j < preCount; j++){if (dict[i][j+1] != preFix[j]){flag = 0;break;}}}if ( flag ) break;}if ( flag )return true;elsereturn false;}/*O(n*n)*//*函数功能: 将sourfile文件用LZW压缩到codefile文件中函数参数:待压缩文件/压缩目标文件函数返回值:压缩成功(TRUE)/压缩失败(FALSE)*/void LzwEncoding(char sourfile[], char codefile[]){FILE *sfp; //源文件句柄FILE *cfp; //编码文件句柄BYTE sbuff[N]; //源文件字节缓冲区Uint cbuff[N]; //压缩文件字节缓冲区Uint preCount; //前缀数组小标Uint preFix[N]; //前缀数组Uint dictCount = 255; //字典索引位置Uint cCount = 0; //压缩字节缓冲区下标Uint count = 0; //计数器Uint code; //临时编码if ((sfp = fopen(sourfile, "rb")) == NULL){printf("Read source file error!");exit( 0 );}if ((cfp = fopen(codefile, "wb")) == NULL){printf("Write code file error!");fclose(sfp);exit( 0 );}//初始化字典for (int i = 0; i < N; i++){if (i < 256){dict[i][0] = 1; //第i个索引处有一个字符dict[i][1] = i; //第i个索引处的字符}else{dict[i][0] = 0; //第i个索引处没有字符}}fseek(sfp, 0, SEEK_END);long fl = ftell(sfp); //获取原文件的字节数fseek(sfp, 0, SEEK_SET); //将文件指针移到文件开头处fread(sbuff, sizeof(sbuff[0]), fl, sfp); //将文件一次性读到缓冲区preCount = 0; //初始化前缀数组下标while ( fl-- ) //读取源文件内容并进行编码{if (IsDictValue(preFix, preCount, (int)sbuff[count])) //当前字符串在字典中preFix[preCount++] = (int)sbuff[count]; //将当前字符复制给前缀数组else{ //当前字符串不在字典中dictCount++; //字典增长//将前缀数组对应的索引写入编码文件code = DictKey(preFix, preCount);cbuff[cCount++] = code;//将前缀数组的字符及当前字符添加到字典中Uint icount = preCount; //记录前缀数组的有效长度dict[dictCount][0] = icount+1; //将dictCount索引处的字符数记录到字典while ( icount-- ){dict[dictCount][preCount-icount] = preFix[preCount-icount-1];}dict[dictCount][preCount-icount] = (int)sbuff[count];preCount = 0;preFix[preCount++] = (int)sbuff[count]; //将当前字符复制给前缀数组}count++;}code = DictKey(preFix, preCount);cbuff[cCount++] = code;fwrite(cbuff, sizeof(Uint), cCount, cfp); //将压缩文件整块写入文件fclose(sfp);fclose(cfp);}/* O(n^2*m) *///解压模块:LzwDecoding.cpp#include <stdio.h>#include <stdlib.h>#include <windows.h>#include "lzw.h"using namespace std;/*函数功能:判断buff是否为字典中的一个索引函数参数:无符号整形数buff函数返回值:是(TRUE)/否(FALSE)*/bool IsDictKey(Uint buff){if (dict[buff][0] == 0)return false;return true;}/*函数功能: 将codefile文件用LZW解压到destfilefile文件中函数参数:压缩目标文件/解压文件函数返回值:解压成功(TRUE)/解压失败(FALSE)*/void LzwDecoding(char codefile[], char destfile[]){FILE *cfp; //编码文件句柄FILE *dfp; //源文件句柄Uint oldCount; //old数组下标Uint oldCode[N] = {0}; //解码过的索引值??Uint cbuff[N/4]; //压缩文件缓冲区Uint cCount = 0; //压缩文件缓冲区下标BYTE dbuff[N] = {0}; //解压文件缓冲区Uint dCount = 0; //解压文件缓冲区下标Uint dictCount = 255; //字典长度Uint i, j; //循环变量if ((cfp = fopen(codefile, "rb")) == NULL){printf("Read coding file error!");exit( 0 );}if ((dfp = fopen(destfile, "wb")) == NULL){printf("Write decoding file error!");fclose(cfp);exit( 0 );}//初始化字典for (i = 0; i < N; i++){if (i < 256){dict[i][0] = 1; //第i个索引处有一个字符dict[i][1] = i; //第i个索引处的字符}else{dict[i][0] = 0; //第i个索引处没有字符}}fseek(cfp, 0, SEEK_END);long fl = ftell(cfp)/4; //获取原文件的编码数fseek(cfp, 0, SEEK_SET); //将文件指针移到文件开头处oldCount = 0; //初始化前缀数组下标、处理第一个编码fread(cbuff, sizeof(Uint), fl, cfp);//将压缩文件整块读入dbuff[dCount++]=cbuff[cCount];oldCode[oldCount++]=cbuff[cCount];fl--;while ( fl-- ) //读取源文件内容并进行编码{cCount++; //处理下一编码dictCount++; //字典增长if (IsDictKey(cbuff[cCount])) //字节在字典中{j = oldCount;dict[dictCount][0] = oldCount+1;while ( j-- ) //更新字典dict[dictCount][oldCount-j] = oldCode[oldCount-j-1];dict[dictCount][oldCount-j] = dict[cbuff[cCount]][1];i = dict[cbuff[cCount]][0];while ( i-- ) //将当前索引对应的字典值加入解压文件缓冲区dbuff[dCount++] = dict[cbuff[cCount]][dict[cbuff[cCount]][0]-i];//更新前缀数组oldCount = 0;i = dict[cbuff[cCount]][0];while ( i-- ){oldCode[oldCount]=dict[cbuff[cCount]][oldCount+1];oldCount++;}}else{i = oldCount;while ( i-- ) //前缀数组中的字典值加入解压文件缓冲区dbuff[dCount++]=oldCode[oldCount-i-1];dbuff[dCount++]=oldCode[0];dict[cbuff[cCount]][0] = oldCount+1;j = oldCount;while ( j-- ) //将前缀数组及前缀数组的第一个字符更新到字典dict[dictCount][oldCount-j+1] = oldCode[oldCount-j];dict[dictCount][oldCount-j]=oldCode[0];oldCode[oldCount++]=oldCode[0];}}fwrite(dbuff, sizeof(BYTE), dCount, dfp); //将解压文件缓冲区整块写入解压文件fclose(cfp);fclose(dfp);}改进方案:用结构体代替数组实现全局字典字典!其实现很简单,留给读者自行解决!。
LZW编码算法详解

LZW编码算法详解LZW(Lempel-Ziv & Welch)编码又称字串表编码,是Welch将Lemple和Ziv所提出来的无损压缩技术改进后的压缩方法。
GIF图像文件采用的是一种改良的LZW 压缩算法,通常称为GIF-LZW压缩算法。
下面简要介绍GIF-LZW的编码与解码方程解:例现有来源于二色系统的图像数据源(假设数据以字符串表示):aabbbaabb,试对其进行LZW编码及解码。
1)根据图像中使用的颜色数初始化一个字串表(如表1),字串表中的每个颜色对应一个索引。
在初始字串表的LZW_CLEAR和LZW_EOI分别为字串表初始化标志和编码结束标志。
设置字符串变量S1、S2并初始化为空。
2)输出LZW_CLEAR在字串表中的索引3H(见表2第一行)。
3)从图像数据流中第一个字符开始,读取一个字符a,将其赋给字符串变量S2。
判断S1+S2=“a”在字符表中,则S1=S1+S2=“a”(见表2第二行)。
4)读取图像数据流中下一个字符a,将其赋给字符串变量S2。
判断S1+S2=“aa”不在字符串表中,输出S1=“a”在字串表中的索引0H,并在字串表末尾为S1+S2="aa"添加索引4H,且S1=S2=“a”(见表2第三行)。
5)读下一个字符b赋给S2。
判断S1+S2=“ab”不在字符串表中,输出S1=“a”在字串表中的索引0H,并在字串表末尾为S1+S2=“ab”添加索引5H,且S1=S2=“b”(见表2第四行)。
6)读下一个字符b赋给S2。
S1+S2=“bb”不在字串表中,输出S1=“b”在字串表中的索引1H,并在字串表末尾为S1+S2=“bb”添加索引6H,且S1=S2=“b”(见表2第五行)。
7)读字符b赋给S2。
S1+S2=“bb”在字串表中,则S1=S1+S2=“bb”(见表2第六行)。
8)读字符a赋给S2。
S1+S2=“bba”不在字串表中,输出S1=“bb”在字串表中的索引6H,并在字串表末尾为S1+S2=“bba”添加索引7H,且S1=S2=“a”(见表2第七行)。
实验三LZW编码
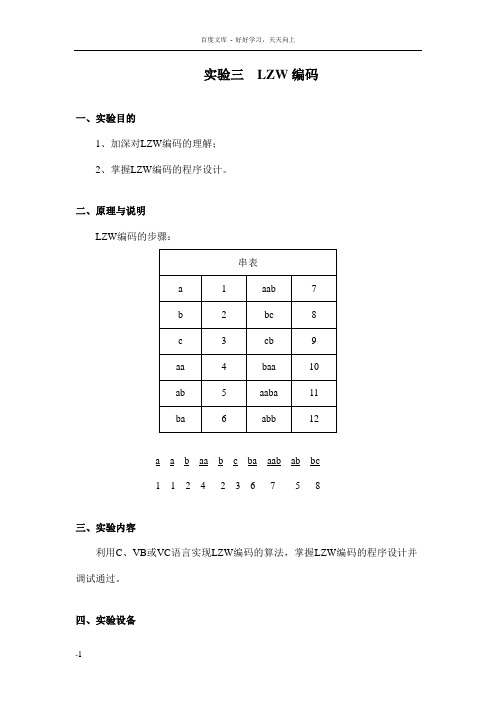
实验三LZW编码一、实验目的1、加深对LZW编码的理解;2、掌握LZW编码的程序设计。
二、原理与说明LZW编码的步骤:a ab aa bc ba aab ab bc1 12 4 23 6 7 5 8三、实验内容利用C、VB或VC语言实现LZW编码的算法,掌握LZW编码的程序设计并调试通过。
四、实验设备计算机程序如下:#include<>#include""#include""#include""#include""#define BIRS 12#define HASHING_SHIFT BITS-8#define MAX_V ALUE(1<<BITS)-1#define MAX_CODE MAX_V ALUE-1 #if BITS==14#define TABLE_SIZE 18041#endif#if BITS==13#define TABLE_SIZE 9029#endif#if BITS<=12#define TABLE_SIZE 5021int *code_value;unsigned int *prefix_code;unsigned char *append_character; unsigned char decode_stack[4000];char ok;find match(int hash_perfix,unsigned int hash_character){int index;int offset;index=(hash_character<<HASHING_SHIFT)^hash_prefix;if(index==0)offset=1;elseoffset=TABLE_SIZE-index;while(1){if(code_value[index]==-1)return(index);if(prefix_code[index]==hash_prefix&&append_character[index]==hash_character) return(index);index-=offset;if(index<0)index+=TABLE_SIZE;}}input_code(FILE*input){unsigned int return_value;static int input_bit_count=0;static unsigned long input_bit_buffer=0L;while(input_bit_count<=24){input_bit_buffer|=(unsigned long)getc(input)<<(24-input_bit_count);input_bit_count+=8;}return_value=input_bit_buffer>>(32-BITS);input_bit_buffer<<=BITS;input_bit_count-=BITS;return(return_value);}void output_code(FILE*output,unsigned int code){static int output_bit_count=0;static unsigned long output_bit_buffer=0L;output_bit_buffer|=(unsigned long)code<<(32-BITS-output_bit_count);output_bit_count+=BITS;while(output_bit_count>=8)putc(output_bit_buffer>>24,output);output_bit_buffer<<=8;output_bit_count-=8;}}void compress(FILE *input,FILE *output){unsigned int next_code;unsigned int character;unsigned int string_code;unsigned int index;int i;next_code=256;for(i=0;i<TABLE_SIZE;i++)code_value[i]=-1;i=0;printf("\n\nCompressing...\n);string_code=getc(input);while((character=getc(input))!=(unsigned)EOF) {index=find_match(string_code,character);if(code_value[index]!=-1)string_code=code_value[index];{if(next_code<=MAX_CODE){code_value[index]=next_code++;prefix_code[index]=string_code;append_character[index]=character;}output_code(output,string_code);string_code=character;}}output_code(output,string_code);output_code(output,MAX_V ALUE);output_code(output,0);printf("\n");getchar();void expand(FILE*input,FILE*output){unsigned int next_code;unsigned int nex_code;unsigned int old_code;int character;unsigned char*string;char*decode_string(unsigned char*buffer,unsigned int code)lnext_code=256;counter=0;printf("\n\nExpanding...\n");old_code=input_code(input);character=old_code;putc(old_code,output);while((nex_code=input_code(input))!=(MAX_V ALUE)){if(new_code>=next_code){*decode_stack=character;string=(unsigned char*)decode_string(decode_stcak+1,old_code);}elsestring=(unsigned char*)decode_string(decode_stck,nex_code);character=*string;while(string>=decode_stack)putc(*string--,output);if(next_code<=MAX_CODE){append_character[next_code]=character;next_code++;}old_code=nex_code;}printf("\n");getchar();}char *decode_string(unsigned char*buffer,unsigned int code) {int i;i=0;while(code>255){*buffer++=append_character[code];code=prefix_code[code];if(i++>=4094){printf("Fatal error during code expansion.\n");exit(0);}}*buffer=code;int main(int argc,char*argv[]){FILE*input_file;FILE*output_file;FILE*lzw_file;char input_file_name[81];int select;character=*string;while(string>=decode_stack)putc(*string--,output);if(next_code<=MAX_CODE){prefix_code[next_code]=old_code;append_character[next_code]=character;next_code++;}old_code=new_code;}printf("\n");getchar();}printf("**\n");printf("**********************\n");scanf("%d",&select);if(select==1){if(argc>1)strcpy(input_file_name,argv[1]);else{printf("\nInput file name?");scanf("%s",input_file_name);printf("\nCompressed file name?");scanf("%s",compressed_file_name);}input_file=fopen(input_file_name,"rb");lzw_file=fopen(compressed_filename,"wb");while(input_file==NULL||lzw_file==NULL){printf("Fatal error opening files!\n");printf("\nInput file names?");scanf("%s",input_file_name);printf("\nCompressed file name?");scanf("%s",compressed_file_name);input_file=fopen(input_file_name,"rb");};compress(input_file,lzw_file);fclose(input_file);fclode(lzw_file);free(code_value);else if(select==2){printf("\nOnput file names?");scanf("%s",onput_filename);printf("\nExpanded file name?");scanf("%s",expanded_filename);input_file=fopen(onput_filename,"rb");lzw_file=fopen(expanded_filename,"wb");while(lzw_file==NULL||output_file==NULL){printf("Fatal error opening files!\n");printf("\nOnput file names?");scanf("%s",onput_filename);printf("\nExpanded file name?");scanf("%s",expanded_filename);input_file=fopen(onput_filename,"rb");lzw_file=fopen(expanded_filename,"wb");};expand(lzw_file,output_file);fclose(lzw_file);-11fclose(output_file);}else{exit(0);}printf("\nContinue or not(y/n)?");scanf("%c",&ok);getchar();if(ok=='y'){goto loop;}else{printf("Complete......\n\nPress any key to continue");getchar();free(prefix_code);free(append_character);}return 0;}}-12。
LZW编码详解

1 NULL 2a 3a 4b 5b 6b 7a 8a 9b
NULL 2H
a
aa
0H
ab
0H
bb
1H
bb
bba
6H
aa
aab
4H
NULL a a b b bb a aa b
aa<4H> ab<5H> bb<6H>
bba<7H>
Aab<8H>
LZW编码步骤
(11)读字符b赋给S2。S1+S2=”bb”,在字符串表中,
序号 输入数据S2 S1+S2 输出结果
S1
生成新字符及索引
1
NULL
2
a
3
a
NULL
2H
a
aa
0H
NULL a a
aa<4H>
LZW编码步骤
(5)读下一个字符b赋给S2。判断S1+S2=”ab”不在字符串 表中,输出S1=“a”在字串表中的索引0H,并在字符串表末 尾为S1+S2=“ab”添加索引5H,且S1= S2=“b”
则 S1= S1+S2=“b”
序号 输入数据S2 S1+S2 输出结果
S1
生成新字符及索引
1 NULL 2a 3a 4b 5b 6b 7a 8a 9b 10 b
NULL 2H
a
aa
0H
ab
0H
bb
1H
bb
bba
6H
aa
aab
4H
bb
NULL a a b b bb a aa b bb
aa<4H> ab<5H> bb<6H>
lzw压缩算法的c语言实现

lzw压缩算法的c语言实现1 程序由五个模块组成。
(1) lzw.h 定义了一些基本的数据结构,常量,还有变量的初始化等。
#ifndef __LZW_H__#define __LZW_H__//------------------------------------------------------------------------------#include <stdio.h>#include <stdlib.h>#include <windows.h>#include <memory.h>//------------------------------------------------------------------------------#define LZW_BASE 0x102// The code base#define CODE_LEN 12 // Max code length#define TABLE_LEN 4099 // It must be prime number and bigger than 2^CODE_LEN=4096.// Such as 5051 is also ok.#define BUFFERSIZE 1024//------------------------------------------------------------------------------typedef struct{HANDLE h_sour; // Source file handle.HANDLE h_dest; // Destination file handle.HANDLE h_suffix; // Suffix table handle.HANDLE h_prefix; // Prefix table handle.HANDLE h_code; // Code table handle.LPWORD lp_prefix; // Prefix table head pointer.LPBYTE lp_suffix; // Suffix table head pointer.LPWORD lp_code; // Code table head pointer.WORD code;WORD prefix;BYTE suffix;BYTE cur_code_len; // Current code length.[ used in Dynamic-Code-Length mode ] }LZW_DATA,*PLZW_DATA;typedef struct{WORD top;WORD index;LPBYTE lp_buffer;HANDLE h_buffer;BYTE by_left;DWORD dw_buffer;BOOL end_flag;}BUFFER_DATA,*PBUFFER_DATA;typedef struct //Stack used in decode{WORD index;HANDLE h_stack;LPBYTE lp_stack;}STACK_DATA,*PSTACK_DATA;//------------------------------------------------------------------------------VOID stack_create( PSTACK_DATA stack ){stack->h_stack = GlobalAlloc( GHND , TABLE_LEN*sizeof(BYTE) );stack->lp_stack = GlobalLock( stack->h_stack );stack->index = 0;}//------------------------------------------------------------------------------VOID stack_destory( PSTACK_DATA stack ){GlobalUnlock( stack->h_stack );GlobalFree ( stack->h_stack );}//------------------------------------------------------------------------------VOID buffer_create( PBUFFER_DATA buffer ){buffer->h_buffer = GlobalAlloc( GHND, BUFFERSIZE*sizeof(BYTE) ); buffer->lp_buffer = GlobalLock( buffer->h_buffer );buffer->top = 0;buffer->index = 0;buffer->by_left = 0;buffer->dw_buffer = 0;buffer->end_flag = FALSE;}//------------------------------------------------------------------------------VOID buffer_destory( PBUFFER_DATA buffer ){GlobalUnlock( buffer->h_buffer );GlobalFree ( buffer->h_buffer );}//------------------------------------------------------------------------------VOID re_init_lzw( PLZW_DATA lzw ) //When code table reached its top it should { //be reinitialized.memset( lzw->lp_code, 0xFFFF, TABLE_LEN*sizeof(WORD) );lzw->code = LZW_BASE;lzw->cur_code_len = 9;}//------------------------------------------------------------------------------VOID lzw_create(PLZW_DATA lzw, HANDLE h_sour, HANDLE h_dest) {WORD i;lzw->h_code = GlobalAlloc( GHND, TABLE_LEN*sizeof(WORD) );lzw->h_prefix = GlobalAlloc( GHND, TABLE_LEN*sizeof(WORD) );lzw->h_suffix = GlobalAlloc( GHND, TABLE_LEN*sizeof(BYTE) );lzw->lp_code = GlobalLock( lzw->h_code );lzw->lp_prefix = GlobalLock( lzw->h_prefix );lzw->lp_suffix = GlobalLock( lzw->h_suffix );lzw->code = LZW_BASE;lzw->cur_code_len = 9;lzw->h_sour = h_sour;lzw->h_dest = h_dest;memset( lzw->lp_code, 0xFFFF, TABLE_LEN*sizeof(WORD) );}//------------------------------------------------------------------------------VOID lzw_destory(PLZW_DATA lzw){GlobalUnlock( lzw->h_code );GlobalUnlock( lzw->h_prefix );GlobalUnlock( lzw->h_suffix );GlobalFree( lzw->h_code );GlobalFree( lzw->h_prefix );GlobalFree( lzw->h_suffix );}//------------------------------------------------------------------------------#endif(2) fileio.h 定义了一些文件操作#ifndef __FILEIO_H__#define __FILEIO_H__//------------------------------------------------------------------------------#include <stdio.h>#include <stdlib.h>#include <windows.h>//------------------------------------------------------------------------------HANDLE file_handle(CHAR* file_name){HANDLE h_file;h_file = CreateFile(file_name,GENERIC_READ|GENERIC_WRITE,FILE_SHARE_READ|FILE_SHARE_WRITE,NULL,OPEN_ALWAYS,0,NULL);return h_file;}//------------------------------------------------------------------------------WORD load_buffer(HANDLE h_sour, PBUFFER_DATA buffer) // Load file to buffer{DWORD ret;ReadFile(h_sour,buffer->lp_buffer,BUFFERSIZE,&ret,NULL);buffer->index = 0;buffer->top = (WORD)ret;return (WORD)ret;}//------------------------------------------------------------------------------WORD empty_buffer( PLZW_DATA lzw, PBUFFER_DATA buffer)// Output buffer to file {DWORD ret;if(buffer->end_flag) // The flag mark the end of decode{if( buffer->by_left ){buffer->lp_buffer[ buffer->index++ ] = (BYTE)( buffer->dw_buffer >>32-buffer->by_left )<<(8-buffer->by_left);}}WriteFile(lzw->h_dest, buffer->lp_buffer,buffer->index,&ret,NULL);buffer->index = 0;buffer->top = ret;return (WORD)ret;}//------------------------------------------------------------------------------#endif(3) hash.h 定义了压缩时所用的码表操作函数,为了快速查找使用了hash算法,还有处理hash冲突的函数#ifndef __HASH_H__#define __HASH_H__//------------------------------------------------------------------------------#include <stdio.h>#include <stdlib.h>#include <windows.h>//------------------------------------------------------------------------------#define DIV TABLE_LEN#define HASHSTEP 13 // It should bigger than 0.//------------------------------------------------------------------------------WORD get_hash_index( PLZW_DATA lzw ){DWORD tmp;WORD result;DWORD prefix;DWORD suffix;prefix = lzw->prefix;suffix = lzw->suffix;tmp = prefix<<8 | suffix;result = tmp % DIV;return result;}//------------------------------------------------------------------------------WORD re_hash_index( WORD hash ) // If hash conflict occured we must recalculate { // hash index .WORD result;result = hash + HASHSTEP;result = result % DIV;return result;}//------------------------------------------------------------------------------BOOL in_table( PLZW_DATA lzw ) // To find whether current code is already in table. {BOOL result;WORD hash;hash = get_hash_index( lzw );if( lzw->lp_code[ hash ] == 0xFFFF ){result = FALSE;}else{if( lzw->lp_prefix[ hash ] == lzw->prefix &&lzw->lp_suffix[ hash ] == lzw->suffix ){result = TRUE;}else{result = FALSE;while( lzw->lp_code[ hash ] != 0xFFFF ){if( lzw->lp_prefix[ hash ] == lzw->prefix &&lzw->lp_suffix[ hash ] == lzw->suffix ){result = TRUE;break;}hash = re_hash_index( hash );}}}return result;}//------------------------------------------------------------------------------WORD get_code( PLZW_DATA lzw ){WORD hash;WORD code;hash = get_hash_index( lzw );if( lzw->lp_prefix[ hash ] == lzw->prefix &&lzw->lp_suffix[ hash ] == lzw->suffix ){code = lzw->lp_code[ hash ];}else{while( lzw->lp_prefix[ hash ] != lzw->prefix ||lzw->lp_suffix[ hash ] != lzw->suffix ){hash = re_hash_index( hash );}code = lzw->lp_code[ hash ];}return code;}//------------------------------------------------------------------------------ VOID insert_table( PLZW_DATA lzw ){WORD hash;hash = get_hash_index( lzw );if( lzw->lp_code[ hash ] == 0xFFFF ){lzw->lp_prefix[ hash ] = lzw->prefix;lzw->lp_suffix[ hash ] = lzw->suffix;lzw->lp_code[ hash ] = lzw->code;}else{while( lzw->lp_code[ hash ] != 0xFFFF ){hash = re_hash_index( hash );}lzw->lp_prefix[ hash ] = lzw->prefix;lzw->lp_suffix[ hash ] = lzw->suffix;lzw->lp_code[ hash ] = lzw->code;}}//------------------------------------------------------------------------------ #endif(4) encode.h 压缩程序主函数#ifndef __ENCODE_H__#define __ENCODE_H__//------------------------------------------------------------------------------#include <stdio.h>#include <stdlib.h>#include <windows.h>//------------------------------------------------------------------------------VOID output_code( DWORD code ,PBUFFER_DATA out, PLZW_DATA lzw) {out->dw_buffer |= code << ( 32 - out->by_left - lzw->cur_code_len );out->by_left += lzw->cur_code_len;while( out->by_left >= 8 ){if( out->index == BUFFERSIZE ){empty_buffer( lzw,out);}out->lp_buffer[ out->index++ ] = (BYTE)( out->dw_buffer >> 24 );out->dw_buffer <<= 8;out->by_left -= 8;}}//------------------------------------------------------------------------------VOID do_encode( PBUFFER_DATA in, PBUFFER_DATA out, PLZW_DATA lzw) {WORD prefix;while( in->index != in->top ){if( !in_table(lzw) ){// current code not in code table// then add it to table and output prefixinsert_table(lzw);prefix = lzw->suffix;output_code( lzw->prefix ,out ,lzw );lzw->code++;if( lzw->code == (WORD)1<< lzw->cur_code_len ){// code reached current code top(1<<cur_code_len) // then current code length add onelzw->cur_code_len++;if( lzw->cur_code_len == CODE_LEN + 1 ){re_init_lzw( lzw );}}}else{// current code already in code table// then output nothingprefix = get_code(lzw);}lzw->prefix = prefix;lzw->suffix = in->lp_buffer[ in->index++ ];}}//------------------------------------------------------------------------------ VOID encode(HANDLE h_sour,HANDLE h_dest){LZW_DATA lzw;BUFFER_DATA in ;BUFFER_DATA out;BOOL first_run = TRUE;lzw_create( &lzw ,h_sour,h_dest );buffer_create( &in );buffer_create( &out );while( load_buffer( h_sour, &in ) ){if( first_run ){// File length should be considered but here we simply// believe file length bigger than 2 bytes.lzw.prefix = in.lp_buffer[ in.index++ ];lzw.suffix = in.lp_buffer[ in.index++ ];first_run = FALSE;}do_encode(&in , &out, &lzw);}output_code(lzw.prefix, &out , &lzw);output_code(lzw.suffix, &out , &lzw);out.end_flag = TRUE;empty_buffer( &lzw,&out);lzw_destory( &lzw );buffer_destory( &in );buffer_destory( &out );}//------------------------------------------------------------------------------#endif(5) decode.h 解压函数主函数#ifndef __DECODE_H__#define __DECODE_H__//------------------------------------------------------------------------------#include <stdio.h>#include <stdlib.h>#include <windows.h>//------------------------------------------------------------------------------VOID out_code( WORD code ,PBUFFER_DATA buffer,PLZW_DATA lzw,PSTACK_DATA stack){WORD tmp;if( code < 0x100 ){stack->lp_stack[ stack->index++ ] = code;}else{stack->lp_stack[ stack->index++ ] = lzw->lp_suffix[ code ];tmp = lzw->lp_prefix[ code ];while( tmp > 0x100 ){stack->lp_stack[ stack->index++ ] = lzw->lp_suffix[ tmp ];tmp = lzw->lp_prefix[ tmp ];}stack->lp_stack[ stack->index++ ] = (BYTE)tmp;}while( stack->index ){if( buffer->index == BUFFERSIZE ){empty_buffer(lzw,buffer);}buffer->lp_buffer[ buffer->index++ ] = stack->lp_stack[ --stack->index ] ; }}//------------------------------------------------------------------------------VOID insert_2_table(PLZW_DATA lzw ){lzw->lp_code[ lzw->code ] = lzw->code;lzw->lp_prefix[ lzw->code ] = lzw->prefix;lzw->lp_suffix[ lzw->code ] = lzw->suffix;lzw->code++;if( lzw->code == ((WORD)1<<lzw->cur_code_len)-1 ){lzw->cur_code_len++;if( lzw->cur_code_len == CODE_LEN+1 )lzw->cur_code_len = 9;}if(lzw->code >= 1<<CODE_LEN ){re_init_lzw(lzw);}}//------------------------------------------------------------------------------WORD get_next_code( PBUFFER_DATA buffer , PLZW_DATA lzw ) {BYTE next;WORD code;while( buffer->by_left < lzw->cur_code_len ){if( buffer->index == BUFFERSIZE )load_buffer( lzw->h_sour, buffer );}next = buffer->lp_buffer[ buffer->index++ ];buffer->dw_buffer |= (DWORD)next << (24-buffer->by_left);buffer->by_left += 8;}code = buffer->dw_buffer >> ( 32 - lzw->cur_code_len );buffer->dw_buffer <<= lzw->cur_code_len;buffer->by_left -= lzw->cur_code_len;return code;}//------------------------------------------------------------------------------VOID do_decode( PBUFFER_DATA in, PBUFFER_DATA out, PLZW_DATA lzw, PSTACK_DATA stack){WORD code;WORD tmp;while( in->index != in->top ){code = get_next_code( in ,lzw );if( code < 0x100 ){// code already in table// then simply output the codelzw->suffix = (BYTE)code;}else{if( code < lzw->code ){// code also in table// then output code chaintmp = lzw->lp_prefix[ code ];while( tmp > 0x100 ){tmp = lzw->lp_prefix[ tmp ];}lzw->suffix = (BYTE)tmp;}else// code == lzw->code// code not in table// add code into table// and out put codetmp = lzw->prefix;while( tmp > 0x100 ){tmp = lzw->lp_prefix[ tmp ];}lzw->suffix = (BYTE)tmp;}}insert_2_table( lzw );out_code(code,out,lzw,stack);lzw->prefix = code;}}//------------------------------------------------------------------------------ VOID decode( HANDLE h_sour, HANDLE h_dest ){LZW_DATA lzw;BUFFER_DATA in ;BUFFER_DATA out;STACK_DATA stack;BOOL first_run;first_run = TRUE;lzw_create( &lzw ,h_sour,h_dest );buffer_create( &in );buffer_create( &out );stack_create(&stack );while( load_buffer( h_sour, &in ) ){if( first_run ){lzw.prefix = get_next_code( &in, &lzw );lzw.suffix = lzw.prefix;out_code(lzw.prefix, &out, &lzw , &stack);first_run = FALSE;}do_decode(&in , &out, &lzw, &stack);}empty_buffer( &lzw,&out);lzw_destory( &lzw );buffer_destory( &in );buffer_destory( &out );stack_destory( &stack);}#endif2 下面给出一个应用上面模块的简单例子#include <stdio.h>#include <stdlib.h>//------------------------------------------------------------------------------#include "lzw.h"#include "hash.h"#include "fileio.h"#include "encode.h"#include "decode.h"//------------------------------------------------------------------------------ HANDLE h_file_sour;HANDLE h_file_dest;HANDLE h_file;CHAR* file_name_in = "d:\\code.c";CHAR* file_name_out= "d:\\encode.e";CHAR* file_name = "d:\\decode.d";//------------------------------------------------------------------------------ int main(int argc, char *argv[]){h_file_sour = file_handle(file_name_in);h_file_dest = file_handle(file_name_out);h_file = file_handle(file_name);encode(h_file_sour, h_file_dest); // decode(h_file_dest,h_file);CloseHandle(h_file_sour);CloseHandle(h_file_dest);CloseHandle(h_file);return 0;}。
lzw压缩算法的c语言实现

标准的LZW压缩原理:~~~~~~~~~~~~~~~~~~先来解释一下几个基本概念:LZW压缩有三个重要的对象:数据流(CharStream)、编码流(CodeStream)和编译表(String Table)。
在编码时,数据流是输入对象(图象的光栅数据序列),编码流就是输出对象(经过压缩运算的编码数据);在解码时,编码流则是输入对象,数据流是输出对象;而编译表是在编码和解码时都须要用借助的对象。
字符(Character):最基础的数据元素,在文本文件中就是一个字节,在光栅数据中就是一个像素的颜色在指定的颜色列表中的索引值;字符串(String):由几个连续的字符组成;前缀(Prefix):也是一个字符串,不过通常用在另一个字符的前面,而且它的长度可以为0;根(Root):单个长度的字符串;编码(Code):一个数字,按照固定长度(编码长度)从编码流中取出,编译表的映射值;图案:一个字符串,按不定长度从数据流中读出,映射到编译表条目.LZW压缩的原理:提取原始图象数据中的不同图案,基于这些图案创建一个编译表,然后用编译表中的图案索引来替代原始光栅数据中的相应图案,减少原始数据大小。
看起来和调色板图象的实现原理差不多,但是应该注意到的是,我们这里的编译表不是事先创建好的,而是根据原始图象数据动态创建的,解码时还要从已编码的数据中还原出原来的编译表(GIF文件中是不携带编译表信息的),为了更好理解编解码原理,我们来看看具体的处理过程:编码器(Compressor)~~~~~~~~~~~~~~~~编码数据,第一步,初始化一个编译表,假设这个编译表的大小是12位的,也就是最多有4096个单位,另外假设我们有32个不同的字符(也可以认为图象的每个像素最多有32种颜色),表示为a,b,c,d,e...,初始化编译表:第0项为a,第1项为b,第2项为c...一直到第31项,我们把这32项就称为根。
开始编译,先定义一个前缀对象Current Prefix,记为[.c.],现在它是空的,然后定义一个当前字符串Current String,标记为[.c.]k,[.c.]就为Current Prefix,k就为当前读取字符。
c语言lzw编码解码

LZW(Lempel-Ziv-Welch)是一种无损数据压缩算法。
以下是一个简单的C语言实现的LZW编码和解码示例:```c#include <stdio.h>#include <stdlib.h>#include <string.h>#define MAX_CODE_SIZE 128typedef struct {int code;char ch;} Code;void init_codes(Code codes[]) {for (int i = 0; i < MAX_CODE_SIZE; i++) {codes[i].code = i;codes[i].ch = i;}}int next_code(Code codes[], char ch) {for (int i = 0; i < MAX_CODE_SIZE; i++) {if (codes[i].ch == ch) {return codes[i].code;}}return -1;}void compress(char *input, char *output) {Code codes[MAX_CODE_SIZE];init_codes(codes);int input_len = strlen(input);int output_index = 0;int current_code = 256;int current_len = 1;int max_len = 1;int next_index = 0;output[output_index++] = codes[current_code].ch;for (int i = 1; i < input_len; i++) {next_index = next_code(codes, input[i]);current_len++;if (next_index != -1) {current_code = next_index;} else {current_code = codes[current_code].code;codes[current_code].ch = input[i];current_code++;current_len = 1;}if (current_len > max_len) {max_len = current_len;}if (current_len == max_len && current_code < MAX_CODE_SIZE) { output[output_index++] = codes[current_code].ch;current_code++;current_len = 0;max_len = 1;}}output[output_index] = '\0';}void decompress(char *input, char *output) {Code codes[MAX_CODE_SIZE];init_codes(codes);int input_len = strlen(input);int output_index = 0;int current_code = 0;int current_len = 0;int max_len = 0;int next_index = 0;while (input[current_code] != '\0') {current_len++;next_index = next_code(codes, input[current_code]);if (next_index != -1) {current_code = next_index;} else {codes[current_code].ch = input[current_code];current_code++;current_len = 1;}if (current_len > max_len) {max_len = current_len;}if (current_len == max_len && current_code < MAX_CODE_SIZE) {output[output_index++] = codes[current_code].ch;current_code++;current_len = 0;max_len = 0;}}output[output_index] = '\0';}int main() {char input[] = "ABABABABA";char output[256];compress(input, output);printf("Compressed: %s", output);char decompressed[256];decompress(output, decompressed);printf("Decompressed: %s", decompressed);return 0;}```这个示例中,`init_codes`函数用于初始化编码表,`next_code`函数用于查找下一个编码,`compress`函数用于压缩输入字符串,`decompress`函数用于解压缩输出字符串。
用C++实现数据无损压缩、解压(使用LZW算法)

用C++实现数据无损压缩、解压(使用LZW算法)小俊发表于 2008-9-10 14:50:00推荐LZW压缩算法由Lemple-Ziv-Welch三人共同创造,用他们的名字命名。
LZW就是通过建立一个字符串表,用较短的代码来表示较长的字符串来实现压缩。
LZW压缩算法是Unisys的专利,有效期到2003年,所以对它的使用是有限制的。
字符串和编码的对应关系是在压缩过程中动态生成的,并且隐含在压缩数据中,解压的时候根据表来进行恢复,算是一种无损压缩。
个人认为LZW很适用于嵌入式系统上。
因为:1、压缩和解压速度比较快,尤其是解压速度;2、占用资源少;3、压缩比也比较理想;4、适用于文本和图像等出现连续重复字节串的数据流。
LZW算法有一点比较特别,就是压缩过程中产生的字符串对应表,不需要保存到压缩数据中,因为这个表在解压过程中能自动生成回来。
LZW算法比较简单,我是按照这本书上写的算法来编程的:以下是源代码:class LZWCoder{private:struct TStr{char *string;unsigned int len;};TStr StrTable[4097];unsigned int ItemPt;unsigned int BytePt;unsigned char BitPt;unsigned char Bit[8];unsigned char Bits;unsigned int OutBytes;void InitStrTable();void CopyStr(TStr *d, TStr s);void StrJoinChar(TStr *s, char c);unsigned int InStrTable(TStr s);void AddTableEntry(TStr s);void WriteCode(char *dest, unsigned int b);unsigned int GetNextCode(char *src);void StrFromCode(TStr *s, unsigned int c);void WriteString(char *dest, TStr s);public:unsigned int Encode(char *src, unsigned int len, char *dest);unsigned int Decode(char *src, unsigned int *len, char *dest);LZWCoder();~LZWCoder();};void LZWCoder::InitStrTable(){unsigned int i;for(i = 0; i < 256; i ++){StrTable[i].string = (char *)realloc(StrTable[i].string, 1);StrTable[i].string[0] = i;StrTable[i].len = 1;}StrTable[256].string = NULL;StrTable[256].len = 0;StrTable[257].string = NULL;StrTable[257].len = 0;ItemPt = 257;Bits = 9;}void LZWCoder::CopyStr(TStr *d, TStr s){unsigned int i;d->string = (char *)realloc(d->string, s.len);for(i = 0; i < s.len; i ++)d->string[i] = s.string[i];d->len = s.len;}void LZWCoder::StrJoinChar(TStr *s, char c){s->string = (char *)realloc(s->string, s->len + 1);s->string[s->len ++] = c;}unsigned int LZWCoder::InStrTable(TStr s){unsigned int i,j;bool b;for(i = 0; i <= ItemPt; i ++){if(StrTable[i].len == s.len){b = true;for(j = 0; j < s.len; j ++)if(StrTable[i].string[j] != s.string[j]){b = false;break;}if(b) return i;}}return 65535;}void LZWCoder::AddTableEntry(TStr s){CopyStr(&StrTable[++ItemPt], s);void LZWCoder::WriteCode(char *dest, unsigned int b){unsigned char i;for(i = 0; i < Bits; i++){Bit[BitPt ++] = (b & (1 << (Bits - i - 1))) != 0;if(BitPt == 8){BitPt = 0;dest[BytePt ++] = (Bit[0] << 7)+ (Bit[1] << 6)+ (Bit[2] << 5)+ (Bit[3] << 4)+ (Bit[4] << 3)+ (Bit[5] << 2)+ (Bit[6] << 1)+ Bit[7];}}}unsigned int LZWCoder::GetNextCode(char *src){unsigned char i;unsigned int c = 0;for(i = 0; i < Bits; i ++){c = (c << 1) + ((src[BytePt] & (1 << (8 - (BitPt ++) - 1))) ! = 0);if(BitPt == 8){BitPt = 0;BytePt ++;}}return c;void LZWCoder::StrFromCode(TStr *s, unsigned int c){CopyStr(s, StrTable[c]);}void LZWCoder::WriteString(char *dest, TStr s){unsigned int i;for(i = 0; i < s.len; i++)dest[OutBytes ++] = s.string[i];}unsigned int LZWCoder::Encode(char *src, unsigned int len, char *dest){TStr Omega, t;char k;unsigned int i;unsigned int p;BytePt = 0;BitPt = 0;InitStrTable();WriteCode(dest, 256);Omega.string = NULL;Omega.len = 0;t.string = NULL;t.len = 0;for(i = 0; i < len; i ++){k = src[i];CopyStr(&t, Omega);StrJoinChar(&t, k);if(InStrTable(t) != 65535)CopyStr(&Omega, t);else{WriteCode(dest, InStrTable(Omega));AddTableEntry(t);switch(ItemPt){case 512: Bits = 10; break;case 1024: Bits = 11; break;case 2048: Bits = 12; break;case 4096: WriteCode(dest, 256); InitStrTable();}Omega.string = (char *)realloc(Omega.string, 1);Omega.string[0] = k;Omega.len = 1;}}WriteCode(dest, InStrTable(Omega));WriteCode(dest, 257);Bits = 7;WriteCode(dest, 0);free(Omega.string);free(t.string);return BytePt;}unsigned int LZWCoder::Decode(char *src, unsigned int *len, char *dest){unsigned int code, oldcode;TStr t, s;BytePt = 0;BitPt = 0;OutBytes = 0;t.string = NULL;t.len = 0;s.string = NULL;s.len = 0;InitStrTable();while((code = GetNextCode(src)) != 257){if(code == 256){InitStrTable();code = GetNextCode(src);if(code == 257) break;StrFromCode(&s, code);WriteString(dest, s);oldcode = code;}else{if(code <= ItemPt){StrFromCode(&s, code);WriteString(dest, s);StrFromCode(&t, oldcode);StrJoinChar(&t, s.string[0]);AddTableEntry(t);switch(ItemPt){case 511: Bit s = 10; break;case 1023: Bi ts = 11; break;case 2047: Bi ts = 12; break;}oldcode = code;}else{StrFromCode(&s, oldcode);StrJoinChar(&s, s.string[0]);WriteString(dest, s);AddTableEntry(s);switch(ItemPt){case 511: Bit s = 10; break;case 1023: Bi ts = 11; break;case 2047: Bi ts = 12; break;}oldcode = code;}}}free(t.string);free(s.string);*len = BytePt + (BitPt != 0);return OutBytes;}LZWCoder::LZWCoder(){unsigned int i;for(i = 0; i < 4097; i ++){StrTable[i].string = NULL;StrTable[i].len = 0;}}LZWCoder::~LZWCoder(){unsigned int i;for(i = 0; i < 4097; i ++)free(StrTable[i].string);}用法:LZWCoder *Coder;Coder = new LZWCoder();然后用Coder->Encode(char *src, unsigned int len, char *dest);Coder->Decode(char *src, unsigned int *len, char *dest);进行压缩或解压。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LZW编码的编程和实现
一、实验目的
编写源程序,实现LZW的编码和解码
二、实验要求
1.编码输入若干字母(如abbababac),输出相应的编码
2.解码输入若干数字(如122473),输出相应的字母
三、编程思想
1.编码
根缀表已知
1 A
2 B
3 C
编码
分析字符串流,从词典中寻找最长匹配串,即字符串P在词典中,而字符串P+后一个字符C不在词典中
此时,输出P对应的码字,将P+C放入词典中。
如第一步:
输入A
此时,A在表中,而AB不在表中,则输出A对应的码字1,同时将AB写入表中,此时表为
1 A
2 B
3 C
4 AB
编码输出为1 (A已编码)
第二步,输入B,B在词典中,而BB不在词典中,则输出2,将BB写入表中,此时表为
1 A
2 B
3 C
4 AB
5 BB
编码输出为12 (AB已经编码)
....
2.解码
根缀表为
1 A
2 B
3 C
定义如下变量
StringP :前一步码字流
pW : StringP的第一个字符
StringC :当前的码字流
cW : StringC的第一个字符
第一步
输出StringC 并StringP = StringC
如:
1解码为A,则StringC = A
那么
输出A,并令StringP = A
---------------------------------------------------------------------------
第二步
1.解码得到StringC,并输出StringC
2.将StringP + cW放入词典(如果当前码字不在词典中,则将StringP + cP放入词典中)
3.StringP = StringC
如:
第二步要解码为2,解码为B,则StringC=B,输出B (此时StringP = A)
将StringP+cW放入表中,即将AB放入表中,此时表为
1 A
2 B
3 C
4 AB
四、实验情况及分析
编码解码
错误提示
附:源代码
#include<iostream>
#include<string>
#include<iomanip>
using namespace std;
string dic[30];
int n;
int find(string s)//字典中寻找,返回序号{
int temp=-1;
for(int i=0;i<30;i++)
{
if(dic[i]==s) temp=i+1;
}
return temp;
}
void init()//字典初始化
{
dic[0]="a";
dic[1]="b";
dic[2]="c";//字根为a,b,c
for(int i=3;i<30;i++)//其余为空
{
dic[i]="";
}
}
void code(string str)
{
init();//初始化
char temp[2];
temp[0]=str[0];//取第一个字符
temp[1]='\0';
string w=temp;
int i=1;
int j=3;//目前字典存储的最后一个位置cout<<"\n 编码为:";
for(;;)
{
char t[2];
t[0]=str[i];//取下一字符
t[1]='\0';
string k=t;
if(k=="") //为空,字符串结束
{
cout<<" "<<find(w);
break;//退出for循环,编码结束
if(find(w+k)>-1)
{
w=w+k;
i++;
}
else
{
cout<<" "<<find(w);
string wk=w+k;
dic[j++]=wk;
w=k;
i++;
}
}
cout<<endl;
for(i=0;i<j;i++)
{
cout<<setw(45)<<i+1<<setw(12)<<dic[i]<<endl; }
cout<<endl;
}
void decode(int c[])
{
init();
int pw,cw;
cw=c[0];
int j=2;
cout<<"\n 译码为:";
cout<<dic[cw-1];
for(int i=0;i<n-1;i++)
{
pw=cw;
cw=c[i+1];
if(cw<=j+1)
{
cout<<dic[cw-1];
char t[2];
t[0]=dic[cw-1][0];
t[1]='\0';
string k=t;
j++;
dic[j]=dic[pw-1]+k;
}
else
char t[2];
t[0]=dic[pw-1][0];
t[1]='\0';
string k=t;
j++;
dic[j]=dic[pw-1]+k;
cout<<dic[cw-1];
}
}
cout<<endl;
for(i=0;i<j+1;i++)
{
cout<<setw(45)<<i+1<<setw(12)<<dic[i]<<endl;
}
cout<<endl;
}
void main()
{
string str;
while(1)
{
cout<<"\n\n\ta.编码\tb.译码\n\n";
cout<<"请选择:";
char cha;
cin>>cha;
if(cha=='a')
{
cout<<"\n输入要编码的字符串(由a、b、c组成):"; cin>>str;
code(str);
}
if(cha=='b')
{
int c[30];
cout<<"\n消息序列长度是:";
cin>>n;
cout<<"\n消息码字依次是:";
for(int i=0;i<n;i++)
{
cin>>c[i];
}
decode(c);
}
else {cout<<"输入错误!"<<endl;
} }。