Hive安装
Hive入门

Hive⼊门第⼀章 Hive 基本概念1.1 什么是 HiveApache Hive是⼀款建⽴在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop⽂件中的结构化、半结构化数据⽂件映射为⼀张数据库表,基于表提供了⼀种类似SQL的查询模型,称为Hive查询语⾔(HQL),⽤于访问和分析存储在Hadoop⽂件中的⼤型数据集。
Hive核⼼是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执⾏。
Hive由Facebook实现并开源。
1.2 为什么使⽤Hive使⽤Hadoop MapReduce直接处理数据所⾯临的问题⼈员学习成本太⾼需要掌握java语⾔MapReduce实现复杂查询逻辑开发难度太⼤使⽤Hive处理数据的好处操作接⼝采⽤类SQL语法,提供快速开发的能⼒(简单、容易上⼿)避免直接写MapReduce,减少开发⼈员的学习成本⽀持⾃定义函数,功能扩展很⽅便背靠Hadoop,擅长存储分析海量数据集1.3 Hive与Hadoop的关系从功能来说,数据仓库软件,⾄少需要具备下述两种能⼒:存储数据的能⼒分析数据的能⼒Apache Hive作为⼀款⼤数据时代的数据仓库软件,当然也具备上述两种能⼒。
只不过Hive并不是⾃⼰实现了上述两种能⼒,⽽是借助Hadoop。
Hive利⽤HDFS存储数据,利⽤MapReduce查询分析数据。
这样突然发现Hive没啥⽤,不过是套壳Hadoop罢了。
其实不然,Hive的最⼤的魅⼒在于⽤户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。
1.4 Hive与MysqlHive虽然具有RDBMS数据库的外表,包括数据模型、SQL语法都⼗分相似,但应⽤场景却完全不同。
Hive只适合⽤来做海量数据的离线分析。
Hive的定位是数据仓库,⾯向分析的OLAP系统。
因此时刻告诉⾃⼰,Hive不是⼤型数据库,也不是要取代Mysql承担业务数据处理。
Hive用户手册)_中文版

Hive 用户指南v1.0目录1. HIVE结构 (5)1.1HIVE架构 (5)1.2Hive 和Hadoop 关系 (6)1.3Hive 和普通关系数据库的异同 (7)1.4HIVE元数据库 (8)1.4.1 DERBY (8)1.4.2 Mysql (9)1.5HIVE的数据存储 (10)1.6其它HIVE操作 (10)2. HIVE 基本操作 (11)2.1create table (11)2.1.1总述 (11)2.1.2语法 (11)2.1.3基本例子 (13)2.1.4创建分区 (14)2.1.5其它例子 (15)2.2Alter Table (16)2.2.1Add Partitions (16)2.2.2Drop Partitions (16)2.2.3Rename Table (17)2.2.4Change Column (17)2.2.5Add/Replace Columns (17)2.3Create View (18)2.4Show (18)2.5Load (18)2.6Insert (20)2.6.1Inserting data into Hive Tables from queries (20)2.6.2Writing data into filesystem from queries (21)2.7Cli (22)2.7.1Hive Command line Options (22)2.7.2Hive interactive Shell Command (23)2.7.3Hive Resources (24)2.7.4调用python、shell等语言 (25)2.8DROP (26)2.9其它 (26)2.9.1Limit (26)2.9.2Top k (26)2.9.3REGEX Column Specification (27)3. Hive Select (27)3.1Group By (27)3.2Order /Sort By (28)4. Hive Join (28)5. HIVE参数设置 (31)6. HIVE UDF (33)6.1基本函数 (33)6.1.1 关系操作符 (33)6.1.2 代数操作符 (34)6.1.3 逻辑操作符 (35)6.1.4 复杂类型操作符 (35)6.1.5 内建函数 (36)6.1.6 数学函数 (36)6.1.7 集合函数 (36)6.1.8 类型转换 (36)6.1.9 日期函数 (36)6.1.10 条件函数 (37)6.1.11 字符串函数 (37)6.2UDTF (43)6.2.1Explode (44)7. HIVE 的MAP/REDUCE (45)7.1JOIN (45)7.2GROUP BY (46)7.3DISTINCT (46)8. 使用HIVE注意点 (47)8.1字符集 (47)8.2压缩 (47)8.3count(distinct) (47)8.4JOIN (47)8.5DML操作 (48)8.6HAVING (48)8.7子查询 (48)8.8Join中处理null值的语义区别 (48)9. 优化与技巧 (51)9.1全排序 (53)9.1.1 例1 (53)9.1.2 例2 (56)9.2怎样做笛卡尔积 (59)9.3怎样写exist/in子句 (60)9.4怎样决定reducer个数 (60)9.5合并MapReduce操作 (61)9.6Bucket 与sampling (62)9.7Partition (62)9.8JOIN (63)9.8.1 JOIN原则 (63)9.8.2 Map Join (64)9.8.3 大表Join的数据偏斜 (66)9.9合并小文件 (67)9.10Group By (67)10. HIVE FAQ: (68)1.HIVE结构Hive 是建立在 Hadoop 上的数据仓库基础构架。
hivemetastoreclient用法

hivemetastoreclient用法HIVETASTORECLIENT是一个用于访问Hive Metastore的客户端工具,它提供了方便的方式来管理和查询Hive Metastore中的元数据信息。
Hive Metastore是Hive中的组件,用于存储和管理集群中的表、存储以及数据转换的元数据信息。
一、安装和配置首先,确保您已经正确安装了Hive集群,并且能够通过Hive客户端访问Hive Metastore。
然后,您需要下载并安装HIVETASTORECLIENT工具。
可以从官方网站或相关文档中找到安装说明。
安装完成后,您需要配置HIVETASTORECLIENT以连接到Hive Metastore。
您需要提供正确的连接参数,包括Metastore服务的主机名、端口号和用户名/密码。
这些参数通常在HIVETASTORECLIENT的配置文件中进行设置。
二、使用方法HIVETASTORECLIENT提供了多种命令行工具来管理和查询Hive Metastore中的元数据信息。
以下是常用的一些命令:1. 列出所有注册的数据库:使用`list-databases`命令可以列出所有已注册的数据库名称。
2. 列出指定数据库中的所有表:使用`list-tables`命令可以列出指定数据库中的所有表名。
3. 查询表的相关信息:使用`describe-table`命令可以获取指定表的详细信息,包括表类型、存储格式、分区信息等。
4. 添加、更新或删除表:使用`create-table`、`alter-table`和`drop-table`命令可以添加、修改或删除表。
这些命令需要提供表的基本信息和详细配置参数。
5. 查询存储信息:使用`list-storage-locations`命令可以列出指定表的存储位置信息。
6. 其他命令:HIVETASTORECLIENT还提供了其他一些命令,如查看Metastore状态、刷新Metastore缓存等。
大数据平台安装实训报告

一、实训背景随着信息技术的飞速发展,大数据已成为国家战略资源。
为了培养具备大数据技术能力的人才,我国高校纷纷开设大数据相关课程。
本实训旨在通过实际操作,使学生掌握大数据平台的搭建与配置,为今后从事大数据相关工作打下坚实基础。
二、实训目标1. 熟悉大数据平台的基本概念、架构及常用技术。
2. 掌握Hadoop、Hive、HBase等大数据组件的安装与配置。
3. 熟悉大数据平台的集群部署与维护。
4. 提高动手实践能力,培养团队合作精神。
三、实训环境1. 操作系统:CentOS 72. 虚拟机软件:VMware Workstation3. 大数据组件:Hadoop 3.1.0、Hive 3.1.2、HBase 2.2.4四、实训内容1. 创建虚拟机与操作系统的安装(1)使用VMware Workstation创建虚拟机,并安装CentOS 7操作系统。
(2)配置虚拟机网络,实现虚拟机与主机之间的网络互通。
2. 集群主节点JDK和Hadoop的安装与配置(1)修改主机名,便于区分不同节点。
(2)进入hosts文件,配置IP地址及对应的主机名。
(3)配置本机网卡配置文件,确保网络连通性。
(4)测试网络连接是否正常。
(5)安装JDK 8,为Hadoop提供运行环境。
(6)安装Hadoop 3.1.0,并配置Hadoop环境变量。
(7)初始化Hadoop集群,确保集群正常运行。
3. 集群从节点JDK和Hadoop的实现(1)将集群主节点的配置文件分发到其他子节点上。
(2)在从节点上安装JDK 8和Hadoop 3.1.0。
(3)修改从节点的hosts文件,确保集群内节点之间可以相互通信。
4. Hive和HBase的搭建与配置(1)安装Hive 3.1.2和HBase 2.2.4。
(2)配置Hive环境变量,并启动Hive服务。
(3)配置HBase环境变量,并启动HBase服务。
5. 大数据平台的集群部署与维护(1)测试Hadoop集群的MapReduce、YARN等组件是否正常运行。
Hive的三种安装方式(内嵌模式,本地模式远程模式)

Hive的三种安装⽅式(内嵌模式,本地模式远程模式)⼀、安装模式介绍:Hive官⽹上介绍了Hive的3种安装⽅式,分别对应不同的应⽤场景。
1、内嵌模式(元数据保村在内嵌的derby种,允许⼀个会话链接,尝试多个会话链接时会报错)2、本地模式(本地安装mysql 替代derby存储元数据)3、远程模式(远程安装mysql 替代derby存储元数据)⼆、安装环境以及前提说明:⾸先,Hive是依赖于hadoop系统的,因此在运⾏Hive之前需要保证已经搭建好hadoop集群环境。
本⽂中使⽤的hadoop版本为2.5.1,Hive版本为1.2.1版。
OS:Linux Centos 6.5 64位jdk:java version "1.7.0_79"假设已经下载了Hive的安装包,且安装到了/home/install/hive-1.2.1在~/.bash_profile中设定HIVE_HOME环境变量:export HIVE_HOME=/home/install/hive-1.2.1三、内嵌模式安装:这种安装模式的元数据是内嵌在Derby数据库中的,只能允许⼀个会话连接,数据会存放到HDFS上。
1、切换到HIVE_HOME/conf⽬录下,执⾏下⾯的命令:cp hive-env.sh.template hive-env.shvim hive-env.sh在hive-env.sh中添加以下内容:HADOOP_HOME=/home/install/hadoop-2.5.12、启动hive,由于已经将HIVE_HOME加⼊到了环境变量中,所以这⾥直接在命令⾏敲hive即可:然后我们看到在hadoop的HDFS上已经创建了对应的⽬录。
注意,只要上⾯2步即可完成内嵌模式的安装和启动,不要画蛇添⾜。
⽐如下⾯================================【下⾯这段就不要看了】==============================================(作废)2、提供⼀个hive的基础配置⽂件,执⾏如下代码,就是将conf⽬录下⾃带的⽂件修改为配置⽂件:cp hive-default.xml.template hive-site.xml(作废)3、启动hive,由于已经将HIVE_HOME加⼊到了环境变量中,所以这⾥直接在命令⾏敲hive即可:(作废)结果报错了,看错误⽇志中提到system:java.io.tmpdir,这个配置项在hive-site.xml中有提到。
Hadoop2.4、Hbase0.98、Hive集群安装配置手册

Hadoop、Zookeeper、Hbase、Hive集群安装配置手册运行环境机器配置虚机CPU E5504*2 (4核心)、内存 4G、硬盘25G进程说明QuorumPeerMain ZooKeeper ensemble member DFSZKFailoverController Hadoop HA进程,维持NameNode高可用 JournalNode Hadoop HA进程,JournalNode存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,保证数据高可用 NameNode Hadoop HDFS进程,名字节点DataNode HadoopHDFS进程, serves blocks NodeManager Hadoop YARN进程,负责 Container 状态的维护,并向 RM 保持心跳。
ResourceManager Hadoop YARN进程,资源管理 JobTracker Hadoop MR1进程,管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
TaskTracker Hadoop MR1进程,manages the local Childs RunJar Hive进程HMaster HBase主节点HRegionServer HBase RegionServer, serves regions JobHistoryServer 可以通过该服务查看已经运行完的mapreduce作业记录应用 服务进程 主机/hostname 系统版本mysql mysqld10.12.34.14/ Centos5.810.12.34.15/h15 Centos5.8 HadoopZookeeperHbaseHiveQuorumPeerMainDFSZKFailoverControllerNameNodeNodeManagerRunJarHMasterJournalNodeJobHistoryServerResourceManagerDataNodeHRegionServer10.12.34.16/h16 Centos5.8 HadoopZookeeperHbaseHiveDFSZKFailoverControllerQuorumPeerMainHMasterJournalNodeNameNodeResourceManagerDataNodeHRegionServerNodeManager10.12.34.17/h17 Centos5.8 HadoopZookeeperHbaseHiveNodeManagerDataNodeQuorumPeerMainJournalNodeHRegionServer环境准备1.关闭防火墙15、16、17主机:# service iptables stop2.配置主机名a) 15、16、17主机:# vi /etc/hosts添加如下内容:10.12.34.15 h1510.12.34.16 h1610.12.34.17 h17b) 立即生效15主机:# /bin/hostname h1516主机:# /bin/hostname h1617主机:# /bin/hostname h173. 创建用户15、16、17主机:# useraddhduser密码为hduser# chown -R hduser:hduser /usr/local/4.配置SSH无密码登录a)修改SSH配置文件15、16、17主机:# vi /etc/ssh/sshd_config打开以下注释内容:#RSAAuthentication yes#PubkeyAuthentication yes#AuthorizedKeysFile .ssh/authorized_keysb)重启SSHD服务15、16、17主机:# service sshd restartc)切换用户15、16、17主机:# su hduserd)生成证书公私钥15、16、17主机:$ ssh‐keygen ‐t rsae)拷贝公钥到文件(先把各主机上生成的SSHD公钥拷贝到15上的authorized_keys文件,再把包含所有主机的SSHD公钥文件authorized_keys拷贝到其它主机上)15主机:$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys16主机:$cat ~/.ssh/id_rsa.pub | ssh hduser@h15 'cat >> ~/.ssh/authorized_keys'17主机:$cat ~/.ssh/id_rsa.pub | ssh hduser@h15 'cat >> ~/.ssh/authorized_keys'15主机:# cat ~/.ssh/authorized_keys | ssh hduser@h16 'cat >> ~/.ssh/authorized_keys'# cat ~/.ssh/authorized_keys | ssh hduser@h17 'cat >> ~/.ssh/authorized_keys'5.Mysqla) Host10.12.34.14:3306b) username、passwordhduser@hduserZookeeper使用hduser用户# su hduser安装(在15主机上)1.下载/apache/zookeeper/2.解压缩$ tar ‐zxvf /zookeeper‐3.4.6.tar.gz ‐C /usr/local/配置(在15主机上)1.将zoo_sample.cfg重命名为zoo.cfg$ mv /usr/local/zookeeper‐3.4.6/conf/zoo_sample.cfg /usr/local/zookeeper‐3.4.6/conf/zoo.cfg2.编辑配置文件$ vi /usr/local/zookeeper‐3.4.6/conf/zoo.cfga)修改数据目录dataDir=/tmp/zookeeper修改为dataDir=/usr/local/zookeeper‐3.4.6/datab)配置server添加如下内容:server.1=h15:2888:3888server.2=h16:2888:3888server.3=h17:2888:3888server.X=A:B:C说明:X:表示这是第几号serverA:该server hostname/所在IP地址B:该server和集群中的leader交换消息时所使用的端口C:配置选举leader时所使用的端口3.创建数据目录$ mkdir /usr/local/zookeeper‐3.4.6/data4.创建、编辑文件$ vi /usr/local/zookeeper‐3.4.6/data/myid添加内容(与zoo.cfg中server号码对应):1在16、17主机上安装、配置1.拷贝目录$ scp ‐r /usr/local/zookeeper‐3.4.6/ hduser@10.12.34.16:/usr/local/$ scp ‐r /usr/local/zookeeper‐3.4.6/ hduser@10.12.34.17:/usr/local/2.修改myida)16主机$ vi /usr/local/zookeeper‐3.4.6/data/myid1 修改为2b)17主机$ vi /usr/local/zookeeper‐3.4.6/data/myid1修改为3启动$ cd /usr/local/zookeeper‐3.4.6/$./bin/zkServer.sh start查看状态:$./bin/zkServer.sh statusHadoop使用hduser用户# su hduser安装(在15主机上)一、安装Hadoop1.下载/apache/hadoop/common/2.解压缩$ tar ‐zxvf /hadoop‐2.4.0.tar.gz ‐C /usr/local/二、 编译本地库,主机必须可以访问internet。
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册
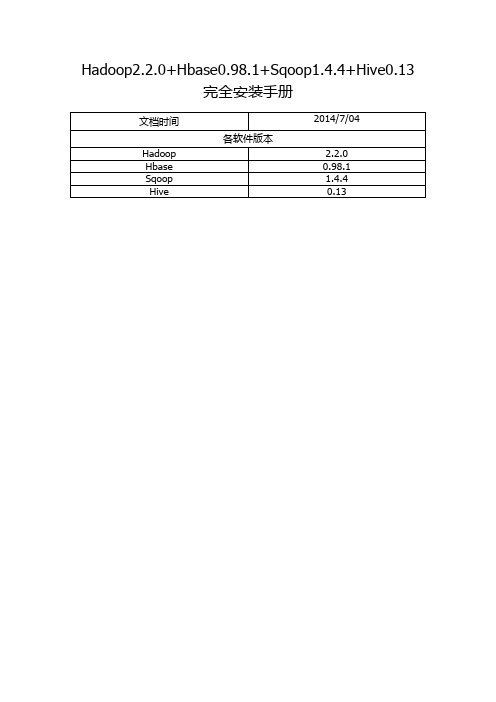
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册前言: (3)一. Hadoop安装(伪分布式) (4)1. 操作系统 (4)2. 安装JDK (4)1> 下载并解压JDK (4)2> 配置环境变量 (4)3> 检测JDK环境 (5)3. 安装SSH (5)1> 检验ssh是否已经安装 (5)2> 安装ssh (5)3> 配置ssh免密码登录 (5)4. 安装Hadoop (6)1> 下载并解压 (6)2> 配置环境变量 (6)3> 配置Hadoop (6)4> 启动并验证 (8)前言:网络上充斥着大量Hadoop1的教程,版本老旧,Hadoop2的中文资料相对较少,本教程的宗旨在于从Hadoop2出发,结合作者在实际工作中的经验,提供一套最新版本的Hadoop2相关教程。
为什么是Hadoop2.2.0,而不是Hadoop2.4.0本文写作时,Hadoop的最新版本已经是2.4.0,但是最新版本的Hbase0.98.1仅支持到Hadoop2.2.0,且Hadoop2.2.0已经相对稳定,所以我们依然采用2.2.0版本。
一. Hadoop安装(伪分布式)1. 操作系统Hadoop一定要运行在Linux系统环境下,网上有windows下模拟linux环境部署的教程,放弃这个吧,莫名其妙的问题多如牛毛。
2. 安装JDK1> 下载并解压JDK我的目录为:/home/apple/jdk1.82> 配置环境变量打开/etc/profile,添加以下内容:export JAVA_HOME=/home/apple/jdk1.8export PATH=$PATH:$JAVA_HOME/binexport CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar执行source /etc/profile ,使更改后的profile生效。
hive安装配置实验实训报告

hive安装配置实验实训报告一、实验目的本实验旨在通过实际操作,掌握Hive的安装与配置过程,了解Hive的基本功能和使用方法,为后续的大数据处理和分析奠定基础。
二、实验环境1.硬件环境:高性能计算机,至少4核CPU、8GB内存、50GB 硬盘。
2.软件环境:Ubuntu 18.04操作系统,Java Development Kit (JDK) 1.8,Apache Hadoop 2.7.3。
三、实验步骤1.安装与配置Hadoop:首先,在实验环境中安装Hadoop,并配置Hadoop集群。
确保NameNode、SecondaryNameNode、DataNode等节点正常运行。
2.安装Hive:使用apt-get命令安装Hive。
在安装过程中,选择与Hadoop版本兼容的Hive版本。
3.配置Hive:编辑Hive的配置文件hive-site.xml,配置Hive连接到Hadoop集群的相关参数。
4.初始化Hive元数据:运行Hive的元数据初始化脚本,创建Hive元数据库。
5.启动Hive服务:使用以下命令启动Hive的元数据库、Metastore和HiveServer2等服务。
1.元数据库:hive --service metastore &2.Metastore:hive --service metastore &3.HiveServer2:hive --service hiveserver2 &6.测试Hive:使用Hive的命令行工具进入Hive交互式查询环境,执行简单的SQL查询语句,测试Hive是否安装成功。
四、实验结果与分析经过上述步骤,我们成功在实验环境中安装和配置了Hive。
通过执行简单的SQL查询语句,验证了Hive的基本功能。
具体而言,我们执行了以下查询语句:1.创建数据库:CREATE DATABASE mydatabase;2.选择数据库:USE mydatabase;3.创建表:CREATE TABLE mytable (id INT, name STRING);4.插入数据:INSERT INTO TABLE mytable VALUES (1, 'Alice'), (2, 'Bob');5.查询数据:SELECT * FROM mytable;6.删除表:DROP TABLE mytable;7.删除数据库:DROP DATABASE mydatabase;通过这些查询语句的执行,我们验证了Hive的基本功能,包括数据库管理、表创建、数据插入、数据查询、表删除和数据库删除等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.将Hive安装包上传到/opt目录下
2.将/opt目录下的安装包解压到/usr/local目录下,解压命令如下
3.进入到Hive安装包的conf目录下,执行以下命令
在文件hive-env.sh末尾添加Hadoop安装包的路径,添加内容如下所示.
4.登录MySQL,创建hive数据库
1)若还没有安装MySQL,则需要先安装MySQL,执行以下命令。
a)搜索mysql安装包,找到mysql-server.x86_64
b)安装mysql-server.x86_64
c)开启远程权限
i.启动mysql服务
ii.启动mysql:直接在终端输入“mysql”
iii.执行以下命令:
delete from user where 1=1;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root'
WITH GRANT OPTION;
FLUSH PRIVILEGES;
2)若已安装MySQL,则进入到mysql命令行,创建hive数据库(数据库名称为hive)。
Create database hive;
创建完成后推出mysql
Exit
5.将hive-site.xml文件上传到Hive安装包的conf目录下。
6.上传mysql驱动mysql-connector-java-5.1.25-bin.jar到Hive安装包lib目录。
7.在终端执行以下命令
mv
/usr/local/hadoop-2.6.4/share/hadoop/yarn/lib/jline-0.9.94.jar/usr/local/hadoop-2.6.4/ share/hadoop/yarn/lib/jline-0.9.94.jar.bak
cp /usr/local/apache-hive-1.2.1-bin/lib/ /jline-2.12.jar
/usr/local/hadoop-2.6.4/share/hadoop/yarn/lib/
8.启动hive,执行以下命令。