Kaldi语音识别Lecture3
基于Kaldi的语音识别算法
基于Kaldi的语音识别算法作者:杨胜捷朱灏耘冯天祥陈宇来源:《电脑知识与技术》2019年第02期摘要:为了改善传统语音识别算法识别不够准确且消耗时间较大的问题,本文提出了一种基于Kaldi的子空间高斯混合模型与深度神经网络相结合的算法进行语音识别。
针对声音频率信号识别率较低的问题,本文采用了快速傅立叶变换和动态差分的方法进行MFCC特征提取。
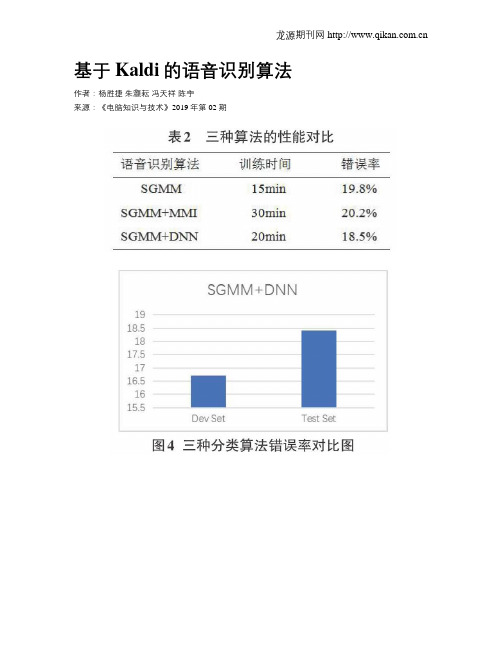
实验证明,相比于单独的SGMM、SGMM+MMI等语音识别算法,该算法对语音识别的错误率更低,对语音识别的研究具有重大意义。
关键词:语音识别;Kaldi;子空间高斯混合模型;深度神经网络中图分类号:TP18; ; ; ; 文献标识码:A; ; ; ; 文章编号:1009-3044(2019)02-0163-04Speech Recognition Algorithm Based on KaldiYANG Sheng-jie ,ZHU Hao-yun , FENG Tian-xiang, CHEN Yu*(School of Information and Computer Science, Northeast Forestry University, Harbin 150040, China)Abstract: In order to improve the problem that the traditional speech recognition algorithm is not accurate enough and consumes a lot of time, this paper proposes a Kaldi-based subspace Gaussian mixture model combined with deep neural network for speech recognition. Aiming at the problem that the recognition rate of sound frequency signal is low, this paper adopts the method of fast Fourier transform and dynamic difference to extract MFCC features. Experiments show that compared with the speech recognition algorithms such as SGMM and SGMM+MMI alone, the algorithm has a lower error rate for speech recognition, which is of great significance for speech recognition research.Key words: Speech recognition; Kaldi; subspace Gaussian mixture model; deep neural network随着互联网技术的高速发展,实现人与计算机之间的自由交互变得尤为重要,作为智能计算机研究的主导方向和人机语音通信的关键技术,语音识别技术一直受到各国科学界的广泛关注。
Kaldi和小米AIoT生态

融合论坛INTEGRATION FORUM46软件和集成电路SOFTWARE AND INTEGRATED CIRCUITKaldi和小米AIoT生态什么是Kaldi?K a ld i是目前全球最流行的开源语音识别工具集。
K a ld i在学术界降低了语音技术的入门门槛,为各大学术研究和挑战赛提供基线系统。
初创公司和团队纷纷使用Kaldi,结合自己的数据迅速验证业务,并为用户服务。
几乎所有做语音识别的机构和企业都在使用Kaldi 。
Kaldi的前身是基于Daniel Povey博士提出的SGMM模型,Daniel主导了Kaldi项目的开发和维护,开发了很多K a ld i模型(包括目前使用广泛的Chain模型),维护了一个开源的语音识别语料库(OpenSLR),并基于此开发了大量的语音识别训练脚本。
Daniel几乎24小时在线回答Kaldi社区用户的问题,他的努力获得了社区的认可。
下面谈谈Kaldi的发展历程。
2009年,在约翰霍普金斯大学夏季研讨会上,语音识别工具包K a ld i正式开始开发,并完成了早期的系统,包括轻量级的解码器和基于HTK的训练脚本。
2010年,布尔诺理工大学K a l d i研讨会,K a ld i作为语音识别工具包的功能被完善,同时研究人员开发了独立于HTK的训练脚本,大量的代码在2010年被开发。
紧接着后面的每一年,Kaldi都做出了里程碑的贡献。
Kaldi在学术界的地位非常高,因为开源模式开放共享共建精神,奠定了它在学术界的扎实地位,成为了学术研究的利器,大大降低了准入门槛,今天有4000多篇论文都在引用Kaldi 。
—小米集团副总裁、集团技术委员会主席崔宝秋围绕语音识别开源工具Kaldi,我们将做到:Daniel和Kaldi项目要赢,K a l d i的全球社区要赢,小米A IoT生态要赢,基于Kaldi的初创公司也要赢。
主题演讲在工业界,Kaldi是语音落地的基石。
kaldi使用cvte模型进行语音识别

kaldi使⽤cvte模型进⾏语⾳识别操作系统: Unbutu18.04_x64gcc版本:7.4.0该模型在thch30数据集上测试的错误率只有8.25%,效果还是不错的。
模型下载地址:选择模型:CVTE Mandarin Model V2测试⽂本:⾃然语⾔理解和⽣成是⼀个多⽅⾯问题,我们对它可能也只是部分理解。
在线识别测试脚本./online2-wav-nnet3-latgen-faster --do-endpointing=false --online=false --feature-type=fbank --fbank-config=../../egs/cvte/s5/conf/fbank.conf --max-active=7000 --beam=15.0 --lattice-beam=6.0 --acoustic-scale=1.0 --word-symbol-table=../../egs/cvte 识别结果:LOG (online2-wav-nnet3-latgen-faster[5.5.421~1453-85d1a]:RemoveOrphanNodes()::948) Removed 1 orphan nodes.LOG (online2-wav-nnet3-latgen-faster[5.5.421~1453-85d1a]:RemoveOrphanComponents()::847) Removing 2 orphan components.LOG (online2-wav-nnet3-latgen-faster[5.5.421~1453-85d1a]:Collapse()::1463) Added 1 components, removed 2LOG (online2-wav-nnet3-latgen-faster[5.5.421~1453-85d1a]:CompileLooped()::345) Spent 0.00508595 seconds in looped compilation.utter1 ⾃然语⾔理解和⽣成时你该付多少拗暗批我们对他能爷只是部分理解LOG (online2-wav-nnet3-latgen-faster[5.5.421~1453-85d1a]:main()::286) Decoded utterance utter1LOG (online2-wav-nnet3-latgen-faster[5.5.421~1453-85d1a]:Print()::55) Timing stats: real-time factor for offline decoding was 0.442773 = 3.21453 seconds / 7.26 seconds.LOG (online2-wav-nnet3-latgen-faster[5.5.421~1453-85d1a]:main()::292) Decoded 1 utterances, 0 with errors.LOG (online2-wav-nnet3-latgen-faster[5.5.421~1453-85d1a]:main()::294) Overall likelihood per frame was 1.84166 per frame over 724 frames.可以看到,在线识别的效果⽐较差。
kaldi语音识别的基本原理

Kaldi是一个开源的语音识别工具包,它基于HMM-GMM(隐马尔可夫模型-高斯混合模型)和DNN(深度神经网络)的基本原理。
在Kaldi中,语音识别的基本流程如下:
1. 数据准备:首先,需要准备训练数据和测试数据。
训练数据通常是一系列音频文件,每个文件都有对应的文本标签。
测试数据是用于评估模型性能的音频文件。
2. 特征提取:对于每个音频文件,需要提取一系列特征向量作为输入。
常用的特征包括MFCC(梅尔频率倒谱系数)、FBANK(滤波器组频率倒谱系数)等。
3. 训练HMM-GMM模型:使用训练数据和特征向量,通过EM算法训练HMM-GMM模型。
HMM-GMM模型用于建模语音信号的时序特性和声学特征。
4. 训练DNN模型:使用训练数据和特征向量,通过反向传播算法训练DNN模型。
DNN模型用于建模语音信号的高层抽象特征。
5. 解码:对于测试数据,使用训练好的模型进行解码。
解码过程中,通过动态规划算法(如Viterbi算法)找到最可能的词序列。
6. 评估:将解码结果与真实标签进行比较,计算识别准确率等性能指标。
总的来说,Kaldi的基本原理是通过训练HMM-GMM和DNN 模型,对音频数据进行特征提取和解码,从而实现语音识别的功能。
Kaldi语音识别Lecture1

Finding speech data
A lot of speech resources are available from the Linguistic Data Consortium (LDC) Also Appen, ELRA None of this is for free. Typically one to several thousand dollars for LDC databases Not a download. It’s FedEx. Some lexicons available for free (e.g. CMUDict) A limited amount of free speech data is available. gutenberg audio
Structure of this lecture series
Some of the theory of speech recognition Practical examples with the Kaldi toolkit Note: various toolkits exist. I believe Kaldi is the best one... but I wrote much of it. Note: this was released ~1 year ago.
Other Resources
To do large-scale speech training (on hundreds of hours of data), would also need: A cluster of machines (at least 20 or so cores in total, preferably more), running e.g. GridEngine A few hundred gigabytes of space on a fast disk (e.g. NFS mounted) Fast local network
语音识别工具箱之kaldi介绍

语音识别工具箱之kaldi介绍最近有几个人在群里问我kaldi的问题,不巧的是最近我在忙我的开题。
我对kaldi的了解也就是语音识别+深度学习。
如果不是kaldi 有dnn模型,或许我更愿意用htk吧。
其实,基本的都差不多吧。
kaldi可以说是更加丰富吧。
本来准备开题开语音识别,但是由于导师的反对,不得不做现在的歌曲人声分离。
进入到这个新的领域,我不得不怀疑自己的学习能力,现在的我变的不淡定了。
很久没有写博文,也许很忙,也许自己懒……等开题结束,我应该好好规划吧。
此外,学长要和我在kaldi上用深度学习模块做下汉语的语音识别。
等做好了,我一定会公开给大家。
现在先说说kaldi的安装吧。
我一般都会在虚拟机上弄。
大家在实现前的平台可以是物理机或者虚拟机。
然后大家安装网上的教程安装好linux。
我就从安装好平台开始把。
前一段时间,我根据中下载的时候有install.sh文件。
安装时直接就./install.sh,然后make就可以了。
但是今天我重新下载时就直接make就可以了。
具体步骤:1. svn co svn:///p/kaldi/code/trunk kaldi-trunk2.到tools文件夹下,直接make就可以了。
你安装的时候最好看下tools里的install文档,里面说的很清楚。
如果不出意外,基本就安装好了。
如果你想实验下自己到底安装成功没,那就来个例子吧。
下面的是例子。
kaldi里的例子很多,在egs目录下。
因为数据库的原因,一般可以做些简单的实验把。
如果你有大量的数据库,如果愿意跟我分享,那我就非常感谢你了。
里面的wsj数据库是LDC的。
一般大家可以做timit和yesno实验。
下面我演示下yesno实验,希望你可以学到更多吧。
步骤和结果如下:1. 把waves_yesno.zip.gz复制到yesno/s3目录下,然后使用sudo yumzip waves_yesno.zip.gztar –xvf waves_yesno.tar2.运行./run.sh。
语音识别 PPT课件
1. 原理描述 DTW 是把时间规整和距离测度计算结合起来的一种 非线性规整技术。
测试语音参数共有I 帧矢量,而参考模板共有J 帧矢量,
I 和J 不等,寻找一个时间规整函数 j=w(i),它将测试矢量 的时间轴i 非线性地映射到模板的时间轴 j上,并使该函数
代价函数。
j
j
时间规整函数 j=w(i)
A
i
i
B
图13.4 动态时间规整
为了使T(测试)的第i 个样本与R(参考)的第 j 个样本 对正,其对应的点不在直线对角线上,得到一条弯曲的曲 线j=w(i)。j=w(i) 称为规整函数。
2. 时间规整解决的问题
设 T={a1 , a2 , …… , ai , …… , aI} i=1~I,
矢量量化识别时,将输入语音的K维帧矢量与已有的 码本中M个区域边界比较,按失真测度最小准则找到与该 输入矢量距离最小的码字标号来代替此输入的K维矢量, 这个对应的码字即为识别结果,再对它进行K维重建就得 到被识别的信号。
模型1 码本1
语音 信号 预 处 理
参 数 提 取
模型2 码本2
· · ·
识别输 判决逻辑 出结果
由此来判别出未知语音。
特征提取的基本思想:将信号通过一次变换,去除 冗余部分,将代表语音本质的特征参数抽取出来。 与特征提取相关的内容是特征间的距离测度。 特征的选择对识别效果至关重要。同时,还要考虑特征
参数的计算量。
语音信号的特征主要有时域和频域两种。
时域特征:短时平均能量、短时平均过零率、共 振峰、基音周期等; 频 域 特 征 : 线 性 预 测 系 数 (LPC) 、 LP 倒 谱 系 数 (LPCC)、线谱对参数(LSP) 、短时频谱、 Mel频率倒谱 系数(MFCC)等。 目前已有结合时间和频率的特征,即时频谱,充
python kaldi用法
标题:Python在kaldi语音识别中的应用概述:随着人工智能技术的不断发展,语音识别技术在各个领域得到了广泛的应用。
Kaldi作为一个开源的语音识别工具包,提供了丰富的工具和库,能够帮助开发者进行语音识别模型的训练和部署。
而Python作为一种流行的编程语言,也在各种领域得到广泛应用。
本文将介绍Python在Kaldi语音识别中的用法及相关技术。
一、Kaldi简介1. Kaldi是什么Kaldi是一个开源的语音识别工具包,由Daniel Povey在2009年发起,它采用C++编写,拥有丰富的语音识别工具和库,为开发者提供了便利的语音识别模型训练和部署环境。
2. Kaldi的特点Kaldi具有高效、灵活、模块化等特点,它支持各种语音识别相关的算法和模型,包括GMM、HMM、DNN等,能够满足不同应用场景下的需求。
二、Python在Kaldi中的应用1. Python的优势Python作为一种流行的编程语言,具有简洁、易读、易学等特点,广泛应用于数据处理、科学计算、人工智能等领域。
在Kaldi语音识别中,Python的应用也十分广泛,它能够帮助开发者更加便捷地进行语音识别模型的开发和部署。
2. Python与Kaldi的集成在Kaldi的使用过程中,开发者可以借助Python的各种库和工具来完成对语音数据的预处理、特征提取、模型训练等工作。
Python也提供了丰富的可视化工具和库,能够帮助开发者更加直观地分析和展示语音识别模型的效果。
三、Python在Kaldi语音识别中的具体应用1. 语音数据的预处理在语音识别模型的训练过程中,预处理是一个十分重要的环节。
开发者可以借助Python的各种库和工具,对语音数据进行预处理,包括信号处理、数据清洗、噪音去除等,以保证语音识别模型的训练数据质量。
2. 特征提取特征提取是语音识别过程中的关键环节,它能够提取语音数据中的重要特征,为后续的模型训练提供支持。
Kaldi语音识别快速入门
Kaldi语⾳识别快速⼊门⼀.简介 Kaldi是使⽤C++编写的语⾳识别⼯具包,Apache License v2.0许可。
主要供语⾳识别研究⼈员使⽤。
Kaldi的⽬标和范围与HTK类似。
⽬标是拥有易于修改和扩展的现代⽽灵活的代码。
主要功能包括: 1.与有限状态传感器FST的代码进⾏集成,根据OpenFst⼯具箱【作为库】进⾏编译。
2.⼴泛的线性代数⽀持,包括⼀个包装标准BLAS和LAPACK例程的矩阵库。
3.可扩展的设计,以⽅便使⽤为⽬的提供算法。
⼆.安装Kaidi 1.下载 2.更新 当需要更新时,可以执⾏:git pull 3.安装环境 理想的计算环境是运⾏在SGE【Sun GridEngine】的Linux机器的集群上,可以通过NFS或某些类似的⽹络⽂件系统访问共享⽬录。
在理想情况下,⽹格上的某些计算机将具有NVidia GPU,这样可以将它们⽤于神经⽹络的训练,并且可以通过向qsub添加⼀些额外的选型将它们保留在队列中。
在实际情况或⽤于学习时,可能单机是⽐较普遍的,在单机情况下,Kaldi是可以运⾏的,尽管这样做会执⾏的慢⼀点,并且可能必须要减少某些⽰例脚本中使⽤的作业数量,以免耗尽机器的内存。
4.所需的软件包 1.Git这是下载Kaldi及其依赖的其他软件所必须的。
2.wget是安装某些⾮Kaldi组件时所必须的。
3.⽰例脚本需要标准的UNIX实⽤程序,例如bash,perl,awk,grep和make。
5.安装依赖 执⾏命令:cd kaldi/tools/ 执⾏命令:./check_dependencies.sh脚本检查需要安装的依赖 注意:你的机器上可能提⽰的⽐这多,这就需要单独执⾏yum install xxx -y进⾏逐个安装! 在安装可能会报这个异常: 此时可以安装gcc的gfortran 再次执⾏检测脚本,可以查看已经完成所有依赖的安装 6.编译【tools⽬录下】 然后执⾏:cd .. 回退到上⼀级,接着执⾏make进⾏编译【make中也会执⾏检测脚本】 若最后提⽰报错: 这是因为openfst-1.6.7在解压时内存不⾜报错,之后重试时重新下载了jar包命名为openfst-1.6.7.tar.gz.1。
基于机器学习的声纹识别研发
中文摘要- -I 中文摘要声音是人与人之间进行交流的信息载体,声音在人机交互中也起到了举足轻重的作用。
声纹识别是语音识别中一个十分重要的方向,这种技术应用到人机交互中就会大大提高人机语音交互的安全性。
作为一种生物认证识别方式,声纹识别还有很多重要的应用前景。
近些年来,机器学习技术在自动语音识别领域取得了重大的突破,越来越多的机器学习方法尤其是深度学习方法被引入到声纹识别中,并取得了显著的成效。
基于i-vector 的声纹识别方法是目前与文本不相关声纹识别的基准方法。
但这种方法面对短时语音时的识别率较低,也容易受到噪声干扰。
本文利用机器学习的理论设计了基于时延神经网络的声纹识别方法,相比于基准方法,这种方法提高了声纹系统的识别率和稳定性,尤其是在短时声音的识别效果方面,应对噪声的鲁棒性也更强。
为了进一步提高系统的识别效果,本文又设计了基于生成向量的声纹识别方法,这种方法将基于i-vector 的声纹识别方法与基于时延神经网络的声纹识别方法进行了“融合”。
此方法利用典型关联分析,将部分i-vector 的信息融合到时延神经网络提取的特征向量中,使得生成向量更能表征说话者的身份特征。
对三种声纹识别方法进行了实验验证,比如在V oxCeleb 语音库下模型的识别效果上生成式特征向量模型的等错误率EER 比传统的i-vector 模型降低了3.1%。
生成式特征向量模型比传统的i-vector 声纹识别模型应对噪声的鲁棒性更强。
本文还对设计的模型进行了实际的应用测试,验证了系统在应用的可行性。
关键词:声纹识别;特征提取;i-vector ;机器学习黑龙江大学硕士学位论文- -II AbstractSound is the information carrier for communication between people, and sound plays a decisive role in human-computer interaction. V oiceprint recognition is a very important direction in speech recognition. The application of this technology to human-computer interaction will greatly improve the security of human-computer voice interaction. As a biometric authentication method, voiceprint recognition has many important application prospects. In recent years, machine learning technology has made major breakthroughs in the field of automatic speech recognition. More and more machine learning methods, especially deep learning methods, have been introduced into voiceprint recognition and have achieved remarkable results.The i-vector based voiceprint recognition method is currently the benchmark method for text-independent voiceprint recognition. However, this method has a low recognition rate in the case of short-term speech and is also susceptible to noise interference. This paper uses the theory of machine learning to design a voiceprint recognition method based on time-delay neural network. Compared with the benchmark method, this method improves the recognition rate and stability of the voiceprint system, especially in the short-term sound recognition effect. In order to further improve the recognition effect of the system, this paper designs a voiceprint recognition method based on generation vector, which combines the voiceprint recognition method based on i-vector with the voiceprint recognition method based on time delay neural network. . This method uses typical correlation analysis to fuse part of the i-vector information into the feature vector extracted by the delay neural network, so that the generated vector can better represent the identity characteristics of the speaker. The three voiceprint recognition methods are experimentally verified. The equal error rate EER of the generated feature vector model is reduced by 3.1% compared with the traditional i-vector model. In this paper, the actual application test of the designed model is carried out to verify the feasibility of the system.Keywords : voiceprint recognition; feature extraction; machine learning; i-vector目 录- -III 目 录中文摘要 ........................................................................................................................... I Abstract .. (II)第1章 绪论 (1)1.1研究背景与意义 (1)1.2发展及现状 (2)1.3主要研究内容 (4)第2章 声纹识别研发理论基础 (6)2.1 声纹识别相关技术概述及应用 (6)2.2 语音信号的预处理与特征提取 (7)2.3 声学特征及主流提取方法 (10)2.3.1 梅尔倒谱系数 (11)2.3.2 身份识别特征向量 (13)2.4 声纹识别主流模型介绍 (14)2.4.1 GMM-UBM 模型 (14)2.4.2 综合因素分析模型 (15)2.4.3 神经网络模型 (16)2.5 本章小结 (17)第3章 基于机器学习的声纹识别设计 (18)3.1 基于身份认证向量的声纹识别 (18)3.1.1 身份认证向量的算法 (18)3.1.2 基于身份认证向量的声纹识别的结构 (19)3.2 基于时延神经网络的声纹识别设计 (20)3.2.1 时延神经网络 (21)3.2.2 时延神经网络的设计 (23)3.2.3 时延神经网络的训练 (25)黑龙江大学硕士学位论文- -IV 3.2.4 基于时延神经网络的声纹识别总体结构设计 (26)3.3 基于生成式特征向量的声纹识别设计 (27)3.3.1 生成式特征向量模型 (27)3.3.2 典型关联分析 (29)3.3.3 基于生成式特征向量的声纹识别结构设计 (30)3.4 后端打分模型的选择 (31)3.4.1 PLDA 模型原理 (31)3.4.2 分数计算 (32)3.4.3 PLDA 改进 (33)3.5 本章小结 (33)第4章 声纹识别的仿真实验与数据分析 (34)4.1 Kaldi 简介 (34)4.2 说话者识别系统评价标准 (35)4.3 语音库的选择 (36)4.3.1 公开语音库选择 (36)4.3.2 语音数据集的处理 (39)4.4 时延神经网络参数确定实验 (39)4.4.1 每层延时时间选取 (39)4.4.2 特征向量提取位置的选取 (40)4.5 实验对比与分析 (41)4.5.1 t-sne 可视化 (41)4.5.2 声纹识别实验对比 (42)4.6 声纹识别系统的应用测试 (45)4.7 本章小结 (48)总 结 .............................................................................................................................49 参考文献 (51)致 谢 (56)目 录- -V 攻读学位期间发表的学术论文 (57)攻读学位期间申请的科研成果 (58)独创性声明 (59)第1章 绪论第1章绪论1.1研究背景与意义语音是人与人之间交流最直接有效的方式,而声音各有特色,声音中包含着不同的信息,比如在日常生活中,只通过声音就可以分辨出同学,老师和朋友们。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Double-precision stats. Max. possible size is 38^3*3*(39+39+1) * 8 = 104M Actual size 14M (~15% of triphones seen).
Looking at tree stats
$ . path.sh $ sum-tree-stats --binary=false - exp/tri1/treeacc | less BTS 19268 EV 4 -1 0 0 0 1 10 2 22 T GCL 10 0.01 [ -319.4122 -47.78007 221.1587 158.8115 335.7153 192.0782 20.63128 99.35792 -48.65273 71.48264 -30.99772 -121.76 16.75381 9.745302 26.61232 20.03452 31.32775 25.1797 8.662501 -11.21577 -10.93547 -5.706181 -8.542741 -17.79073 -14.53732 -4.358661 3.026504 -3.41487 -4.261815 -2.914604 -8.994694 -2.071367 -0.131388 3.215806 2.529252 1.733106 1.000433 2.846173 5.605232 10381.26 1351.984 5520.843 4398.474 12389.38 4130.489 488.7585 1483.611 477.1437 822.2339 1032.555 1925.231 277.2069 19.61546 131.6582 93.57193 264.0651 142.572 61.74911 31.82133 38.00629 46.85469 62.60578 108.7827 51.53504 58.33066 7.887114 18.35285 18.01356 37.78245
Aligning data with monophone system Training triphone system
Weakness of “monophone” model
Phones “sound different” in different contexts. Most strongly affected by phones immediately before/after. Simplest model of context dependency is to build separate model per “triphone” context. For 38 phones, #models required is 38x38x38 Too many models to train!
Байду номын сангаас
Traditional contextdependency tree
Build a “decision tree” for each “monophone” This follows the “Clustering and Regression Tree” (CART) framework Involves a “greedy” (locally optimal) splitting algorithm. Ask questions like “Is the left phone a vowel?” Is the right phone the phone “sh”? Models (HMMs) would correspond to the leaves
“m”
Yes Left=vowel? No
Yes
Right=fricative?
No
Square boxes correspond to Hidden Markov Models
Traditional tree-building
Train a monophone system (or use previously built triphone system) to get time alignments for data. For each seen triphone, accumulate sufficient statistics to train a single Gaussian per HMM state Suff. stats for Gaussian are (count, sum, sumsquared). Total stats size (for 39-dim feats):
Rest of lecture will be about this stage.
Getting stats for tree
$ cd ~/kaldi-trunk/egs/rm/s3 $ ls -l exp/tri1/treeacc -rw-r--r-- 1 dpovey clsp 14M Feb 7 20:57 exp/tri1/treeacc $ cat exp/tri1/acc.tree.log acc-tree-stats --ci-phones=48 exp/mono_ali/final.mdl 'ark:apply-cmvn --norm-vars=false -utt2spk=ark:data/train/utt2spk ark:exp/mono_ali/cmvn.ark scp:data/train/feats.scp ark:- | add-deltas ark:- ark:- |' ark:exp/mono_ali/ali exp/tri1/treeacc apply-cmvn --norm-vars=false --utt2spk=ark:data/train/utt2spk ark:exp/mono_ali/cmvn.ark scp:data/train/feats.scp ark:add-deltas ark:- ark:LOG (acc-tree-stats:main()::113) Processed 1000 utterances. LOG (acc-tree-stats:main()::113) Processed 2000 utterances. LOG (acc-tree-stats:main()::113) Processed 3000 utterances.
Building the triphone system
$ $ $ $ $ $ $ $ cd ~/kaldi-trunk/rm/s3/ # Get alignments from monophone system. steps/align_deltas.sh data/train data/lang exp/mono exp/mono_ali # train tri1 [first triphone pass] steps/train_deltas.sh data/train data/lang exp/mono_ali exp/tri1
Speech REcognition
- a practical guide
Lecture 3
Phonetic Context Dependency
Steps covered in this lecture
$ $ $ $ $ $ $ $ cd ~/kaldi-trunk/rm/s3/ # Get alignments from monophone system. steps/align_deltas.sh data/train data/lang exp/mono exp/mono_ali # train tri1 [first triphone pass] steps/train_deltas.sh data/train data/lang exp/mono_ali exp/tri1
Getting data alignments
$ cd ~/kaldi-trunk/egs/rm/s3 $ head -1 exp/mono_ali/align.log gmm-align --transition-scale=1.0 --acoustic-scale=0.1 --self-loopscale=0.1 --beam=8 --retry-beam=40 exp/mono_ali/tree exp/mono_ali/ final.mdl data/lang/L.fst 'ark:apply-cmvn --norm-vars=false -utt2spk=ark:data/train/utt2spk ark:exp/mono_ali/cmvn.ark scp:data/train/ feats.scp ark:- | add-deltas ark:- ark:- |' ark:exp/mono_ali/train.tra ark:exp/mono_ali/ali
Looking at tree stats
$ . path.sh $ sum-tree-stats --binary=false - exp/tri1/treeacc | less BTS 19268 EV 4 -1 0 0 0 1 10 2 22 T GCL 10 0.01 [ -319.4122 -47.78007 221.1587 158.8115 335.7153 192.0782 20.63128 99.35792 -48.65273 71.48264 -30.99772 -121.76 16.75381 9.745302 26.61232 20.03452 31.32775 25.1797 8.662501 -11.21577 -10.93547 -5.706181 -8.542741 -17.79073 -14.53732 -4.358661 3.026504 -3.41487 -4.261815 -2.914604 -8.994694 -2.071367 -0.131388 3.215806 2.529252 1.733106 1.000433 2.846173 5.605232 10381.26 1351.984 5520.843 4398.474 12389.38 4130.489 488.7585 1483.611 477.1437 822.2339