回归分析实验课 实验8
应用多元回归分析探讨同型半胱氨酸对高血压、冠心病的危险度判断

8 O1・
企 医刊
第 3期
值。后绘制曲线图, 以标准样 品浓度为横坐标 , O D值为 纵 坐标 , 可根据血清样 品的 O D值在标 准曲线上查询 其浓
度值 。在酶标 仪上可 以显示 标本 HL A—B 2 7浓度 。 健康 人 H L A— B 2 7 预期 值 浓度 < 3 5 U / m l , > 3 5 U / m l 为阳性 , 试 剂盒 敏感度 0 . 5 U / m l 。 1 . 3统计 分析 方法 对试 验 的数据 根 据如下 公式计 算 : 敏 感度 ( s e )= 真 阳性 列 数/ ( 真 阳性列 数 +加 阴性 列数 ) , 特异性 ( s p )=真 阴性 列 数/ ( 假 阳性 列 数 +真 阴 性 列 数) 。统计 分析采 用卡方 检验 。
[ 5 ] 裴兵 . 探讨流式细胞术检测 H L A—B 2 7在强直性脊柱炎 中的临床 应用 价值 [ J ] . 实用 检 验 医师 杂 志 , 2 0 1 2 , 0 4
一
且分析客观 、 准确 、 可靠 。 本实验操作 过 程需 认 真仔 细 , 试 验器 材 都要 消 毒处理 , 防止 D N A被污染 , 操作过程都需注意交 叉污 染, 以免导致结果错误 。 [ 参 考 文 献]
[ 1 ] 刘殉 , 赵艳 , 刘金 花 , 等. H L A —B宽特 异 性 抗 原表 位 B w 4对 HC V特异性 T细胞反应影 响分析 [ J ] . 中华微生 物学和免疫学杂志 , 2 0 1 2, 3 2 ( 1 0 ) : 8 7 4— 8 7 8 . [ 2 ] 赵晓君 , 薛鸾 , 陈云 飞等. 三种 方法 检测强 直性脊 柱炎 患者 H L A—B 2 7的效 果 比较 [ J ] . 山东 医药 , 2 0 1 1 , 5 1
实验心理学(第八讲 准实验设计和非实验设计)

中断时间序列设计模式
系列前测
系列后测
实验处理
(一)简单中断时间序列设计 (simple interrupted time-series design)
简单中断时间序列设计是最基本的时间序列设计,基 本上是一种单组前测后测设计。
又由于两组都使用前测验安排,因而其 实验结果不能校直接推广到无前测的情 境中去。
(2)不相等组实验组控制组前测后测时间序列 设计
不相等实验组控制组前测后测时间序列 设计是在单组时间序列设计和不相等实 验组控制组前测后测设计的基础上,组 合而成的一种多组准实验设计。
设计模式
(3)平衡设计
平衡设计又叫轮换设计,或拉丁方设计。 在该设计中,研究者为了达到对实验控 制的目的,使各组被试都接受不同的实 验处理.而对实验处理的顺序相实验时 间的顺序采用了轮换的方法。
设计模式
4.事后回溯设计
事后回溯设计是指所研究的对象是已发 生过的事件。
在研究过程中,研究者不需要设计实验 处理或操纵自变量,只需通过观察存在 的条件或事实,将这种已自然发生的处 理或自变量与某种结果或因变量联系起 来加以分析,以便从中发现某种可能的 简单关系。
设计模式
两类事后回溯设计
(1)相关研究设计 (2)准则组设计
交叉滞后组相关设计举例
➢ 三年级儿童对于暴力或凶杀电视片与他 们的攻击性行为之间的关系
➢ 饮食和体重之间的关系
(4)回归间断点设计
这种准实验设计通过实验处理与事后测 量回归线的间断点的特征,确定准实验 处理的主效应。即如果实验处理前后的 的回归线出现了间断,说明实验处理是 有效果的。
2014年上机实习指导书eviews8

河北工业大学经济管理学院《计量经济学》课程上机指导书(2014年春季学期)班级:学号:姓名:2014年3月上机实习指导书1——EViews的基本使用一、实验目的1.认识计量经济学软件包EViews82.掌握EViews8的基本使用3.建立工作文件并将数据输入存盘二、实验要求熟悉E Views的基本使用三、实验数据四、实验内容(一)怎样启动EViews 8?安装软件后,开始==>程序==> Eviews 8==>Eviews 8。
或者,在桌面双击"EVIEWS"图标,或者双击Eviews8工作文件,进入EVIEWS,启动“EVIEWS”软件。
(二)怎样用EViews 8开始工作进入Eviews8 窗口以后,用户必须创建一个新的工作文件或者打开一个已经存在的工作文件,才能开始工作。
1、创建一个新的工作文件在主菜单上选择File,并点击其下的New,然后选择Workfile。
Eviews将弹出Workfile Creat 窗口。
要求用户输入工作文件的workfile structure type: 如果你的数据是非日期型的截面数据或时间间隔不一致的时间序列数据选unstructured/undated,然后在data specification的Observations 中输入观测值个数;如果你的数据是日期型的选dated——regular frequency,然后在data specification中选择数据的频度,如:年度,季度,月度,周等,最后输入开始日期和结束日期:如果数据是月度数据,则按下面的形式输入(从Jan. 1950 到 Dec. 1994): 1950:01 1994:12,如果数据是季度数据,则按下面的形式输入(从1st Q. 1950到3rd Q. of 1994):1950:1 1995:3,如果数据是年度数据,则按下面的形式输入(从1950 到 1994) 1950 1994,如果数据是按周的数据,则按下面的形式输入(从2001年1月第一周到2010年1月第四周): 2001 1 2010 4;如果你的数据是平衡的面板数据选balanced panel,然后在data specification中输入起始日期(同时间序列数据)及观测对象的个数(同截面数据)。
SPSS实验8-二项Logistic回归分析
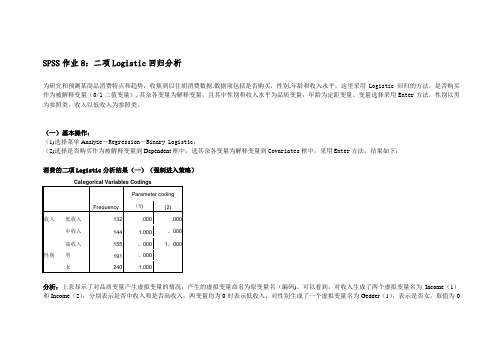
SPSS作业8:二项Logistic回归分析为研究和预测某商品消费特点和趋势,收集到以往胡消费数据.数据项包括是否购买,性别,年龄和收入水平。
这里采用Logistic回归的方法,是否购买作为被解释变量(0/1二值变量),其余各变量为解释变量,且其中性别和收入水平为品质变量,年龄为定距变量。
变量选择采用Enter方法,性别以男为参照类,收入以低收入为参照类。
(一)基本操作:(1)选择菜单Analyz e-Regression-Binary Logistic;(2)选择是否购买作为被解释变量到Dependent框中,选其余各变量为解释变量到Covariates框中,采用Enter方法,结果如下:消费的二项Logistic分析结果(一)(强制进入策略)Categorical Variables CodingsFrequency Parameter coding (1) (2)收入低收入132 .000 .000中收入144 1.000 。
000高收入155 。
000 1。
000性别男191 。
000女240 1.000分析:上表显示了对品质变量产生虚拟变量的情况,产生的虚拟变量命名为原变量名(编码)。
可以看到,对收入生成了两个虚拟变量名为Income(1)和Income(2),分别表示是否中收入和是否高收入,两变量均为0时表示低收入;对性别生成了一个虚拟变量名为Gedder(1),表示是否女,取值为0时表示为男。
消费的二项Logistic 分析结果(二)(强制进入策略)Block 0: Beginning BlockClassification Table a,bObserved Predicted是否购买 Percentage Correct不购买购买Step 0是否购买不购买 269 0 100。
购买162。
0 Overall Percentage62。
4a 。
Constant is included in the model 。
数学建模——线性回归分析82页PPT

2019/11/15
zhaoswallow
2
表1 各机组出力方案 (单位:兆瓦,记作MW)
方案\机组 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
1
2
3
4
5
6
7
8
120
73
180
80
125
125
81.1
90
133.02 73
180
80
125
125
81.1
90
3 -144.25 -145.14 -144.92 -146.91 -145.92 -143.84 -144.07 -143.16 -143.49 -152.26 -147.08 -149.33 -145.82 -144.18 -144.03 -144.32
4 119.09 118.63 118.7 117.72 118.13 118.43 118.82 117.24 117.96 129.58 122.85 125.75 121.16 119.12 119.31 118.84
5 135.44 135.37 135.33 135.41 135.41 136.72 136.02 139.66 137.98 132.04 134.21 133.28 134.75 135.57 135.97 135.06
6 157.69 160.76 159.98 166.81 163.64 157.22 157.5 156.59 156.96 153.6 156.23 155.09 156.77 157.2 156.31 158.26
ˆ0
ˆ1 xi )2
min
0 ,1
实验设计与分析第六版课程设计

实验设计与分析第六版课程设计一、设计背景实验设计与分析是统计学和实验设计学科的重要基础课程,旨在培养学生对实验数据进行分析和解释的能力,以及提高他们在设计和执行实验时的技能。
本课程设计旨在通过设计一个实验来巩固和运用所学的理论知识和实践技能,同时提高学生的创新思维和解决问题的能力。
二、设计目标本课程设计的主要目标如下:1.确保学生掌握实验设计和数据分析的基本理论知识和实践技能;2.培养学生的实验设计和数据分析能力,提高他们的创新思维;3.培养学生的沟通、协作和问题解决能力,以便他们能够在多学科团队中发挥重要作用。
三、设计流程1.确定研究问题:为了研究某个现象或事物,首先需要明确研究的目的并确定研究问题。
考虑到本课程的性质,我们将选择一个具体的实验进行分析。
2.建立假设:假设是实验的重要组成部分,它们提供了关于可能的结果和因果关系的推测,并指导实验的设计和数据分析。
3.确定研究设计:根据研究问题和假设确定实验的设计。
在这个阶段,需要考虑下面的问题:实验设计类型、因子水平、处理次数、重复次数等。
4.收集实验数据:使用合适的方法收集实验数据。
要求使用至少两种数据收集方法,如问卷、实验记录、测试、观察等。
5.进行数据分析:对收集到的数据进行统计分析。
推荐使用至少两种数据分析方法,如t检验、方差分析、回归分析等。
6.结果展示和分析:根据实验的结果进行数据展示,解释和讨论。
将数据分析和统计结果清晰地展示出来,并结合假设和研究问题进行解释和讨论。
7.撰写实验报告:根据实验流程和结果撰写实验报告。
要求使用科学的语言和格式,报告中应包括实验设计、数据收集、分析和结果展示等重要信息。
四、评估标准为了确保本课程设计的顺利进行和学生的有效学习,我们将使用下面的几个标准来评估学生的成绩:1.实验报告的完成情况和质量;2.学生对实验设计和数据分析的理解和应用;3.学生对实验设计和数据分析中遇到问题的解决能力;4.学生对团队合作和沟通的表现。
Stata软件之回归分析

obs:
1,225
vars:
11
25 Aug 2009 08:38
size:
58,800 (99.4% of memory free)
storage display variable name type format
value label
variable label
age female married edulevel
2、给出数据的简要描述。使用describe命令,简写为: des 得到以下运行结果;
三、简单回归分析的Stata软件操作实例
Contains data fromD:\½²¿Î×ÊÁÏ\ÖÜÝíµÄÉÏ¿Î×ÊÁÏ\Êý¾Ý\¡¾ÖØÒª¡¿\¡¾¼ÆÁ¿¾¼ÃѧÈí¼þÓ¦Ó
> ÿμþ¡¿\10649289\stata10\¹¤×Ê·½³Ì1.dta
age in years 1:female; 0:male 1:married; 0:unmarried 1:primary; 2:junior; 3:senior;
4:college years of education years of work experience:
age-edu-6 exp^2 1:bad; 2:good; 3:very good 1:migrant worker; 0:local worker hourly wage
graph twoway lfit wage edu || scatter wage edu 得到以下运行结果,保存该运行结果;
40
30
20
10
0
0
5
10
15
20
years of education
4、高级实验设计—回归的旋转设计(Regressional Rotary Design)

x
i,j =1,2„P;
待定参数
以上为 P 元二次回归旋转设计的旋转性条件。
此外,为了使旋转设计成为可能,还必须使信
息矩阵 A 不退化,为此,必须有不等式:
4 p 2 2 P 2
上式为 P 元二次回归的非退化条件。 已证明,只要使 N 个试验点不在同一个球面上, 就能满足非退化条件。或者说只要使 N 个试验点至少 分布于两个半径不等的球面上,就有可能获得旋转设
P 2 2 ˆ D y P 2 4 PN
4 1 2 P 1 4 P 1 4 1 2 2 4 P 2 4 4
(4.11) 由式(4.11)经研究表明,只有采用恰当的方法 确定 4 ,才能满足通用性的要求。如何确定 4 ?对 4 有什么要求呢?总的来说,它必须使上式中 i处的
ˆ 的 二次旋转组合设计具有同一球面预测值 y
方差相等的优点,但回归统计数的计算较繁琐,
若使它获得正交性就能简化计算手续。
在二次旋转组合计划中,一次项和交互项的 回归系数 bj ,bij 仍保持正交,但 b0 与 bjj 之间,
以及 bii 与 bjj 之间都存在相关,即不具正交性,
它们之间的相关矩分别为:
计方案。
为了获得 P 元二次旋转设计方案,就要求既要
满足非退化条件式,又要满足旋转性条件式。
如何才能满足这两方面的条件呢?这主要借助
于组合设计来实现,因为组合设计中 N 个试验点:
N mc m m0
分布在三个半径不相等的球面上:
mc 个点分布在半径为 P 的球面上; c m 个点分布在半径为 的球面上; m0 个点分布在半径为 0 0 的球面上;
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告八实验课程:回归分析实验课专业:统计学年级:姓名:学号:指导教师:完成时间:得分:教师评语:学生收获与思考:实验八含定性变量的回归模型(4学时)一、实验目的1.掌握含定性变量的回归模型的建模步骤3.运用SAS计算含定性变量的各种回归模型的各参数估计及相关检验统计量二、实验理论与方法在实际问题的研究中,经常会遇到一些非数量型的变量。
如品质变量;性别;战争与和平。
我们把这些品质变量也称为定性变量,在建立回归模型的时候我们需要考虑到这些定性变量。
定性变量的回归模型分为自变量含定性变量的回归模型和因变量是定性变量的回归模型。
自变量含有定性变量的时候,我们一般引进虚拟变量,将这些定性变量数量化。
例如研究粮食产量问题,y为粮食产量,x为施肥量,另外考虑气候问题,分为正常年份和干旱年份两种情况,这个问题数量化方法就是引入一个0-1型变量D,令D i=1 表示正常年份,D i=0表示干旱年份,粮食产量的回归模型为:y i=β0+β1x i+β2D i+εi。
因变量是定性变量时,一般用logistic回归模型(分组数据的logistic回归模型,未分组数据的logistic回归模型,多类别的logistic回归模型),probit回归模型等。
三. 实验内容1.用DATA步建立一个永久SAS数据集,数据集名为xt103,数据见表21;对数据集xt103,建立y 对公司规模和公司类型的回归,并对所得到的模型进行解释。
2.研制一种新型玻璃,对其做耐冲实验。
用一个小球从不同的高度h对玻璃做自由落体撞击,玻璃破碎记为y=1,玻璃未破碎记y=0.数据见表22.是对表中数据建立玻璃耐冲性对高度h的logistic回归,并解释回归方程的含义。
3.某学校对本科毕业生的去向做了一个调查,分析影响毕业去向的相关因素,结果见表23.其中毕业去向“1”=工作,“2”=读研,“3”=出国留学。
性别“1”=男生,“0”=女生。
用多类别的Logisitic回归分析影响毕业去向的因素。
四.实验仪器计算机和SAS软件五.实验步骤和结果分析1.用DATA步建立一个永久SAS数据集,数据集名为xt103,数据见表21;对数据集xt103,建立y 对公司规模和公司类型的回归,并对所得到的模型进行解释。
R检验中R方为0.8951,可以认为回归拟合效果较好。
回归方程通过F检验,说明模型是显著成立的。
由参数估计表,可以看出,全部变量都是显著的,回归方程为:21^06.8102.087.33x x y +-=其中,x2是虚拟变量,当公司类型为“互助”时,x2为0,为“股份”时,x2为1。
由方程可知,x2为1,即股份制公司的保险革新措施速度y 会更大。
股份制公司采取保险革新措施的积极性比互助型公司高,股份制公司建立在共同承担风险上,更愿意革新。
公司规模越大,采取保险革新措施的倾向越大:大规模公司保险制度的更新对公司的影响程度比小规模公司大。
SAS 程序:data xt103;input y x1 x2 ;/*引入虚拟变量,将公司类型的互助设为0,股份设为1*/ cards ; 17 151 0 26 92 0 21 175 0 30 31 0 22 104 0 0 277 0 12 210 0 19 120 0 4 290 0 16 238 0 28 164 1 15 272 1 11 295 1 38 68 1 31 85 121 224 120 166 113 305 130 124 114 246 1;run;proc reg data=xt103;model y=x1 x2;run;2.研制一种新型玻璃,对其做耐冲实验。
用一个小球从不同的高度h对玻璃做自由落体撞击,玻璃破碎记为y=1,玻璃未破碎记y=0.数据见表22.是对表中数据建立玻璃耐冲性对高度h的logistic回归,并解释回归方程的含义。
模型信息:模型解出的是y=0的概率。
由三个检验中,统计量的P 值都小于0.05,可以认为模型是显著的。
由Wald 检验的显著性概率及其P 值,可以看出,h 变量对方程的影响是显著的。
由极大似然估计,各个参数系数也通过检验。
因此模型有效。
二元logit 模型为)98.759.14ex p(1)98.759.14ex p()0(h h y p -+-==模型意义为,小球掉落高度为h ,则玻璃未破碎的概率为p,而y=0表示玻璃未破碎。
也就是说,该种新型的玻璃,用小球对其撞击,当小球的掉落高度为h 时,玻璃未破碎的概率就是)98.759.14ex p(1)98.759.14ex p()0(h h y p -+-==,那么,玻璃会破碎的概率就为1-p(y=0),这也可以看成是一种比例,就是大量实验中,同个高度h ,玻璃会被击破的比例。
SAS程序:data wjz;input h y ;/*引入虚拟变量,将公司类型的互助设为0,股份设为1*/ cards;1.50 01.52 01.54 01.56 01.58 11.60 01.62 01.64 01.66 01.68 11.70 01.72 01.74 01.76 11.78 01.80 11.82 01.84 01.86 11.88 11.90 01.92 11.94 01.96 11.98 12.00 1;run;proc logistic data=wjz;model y=h;run;proc logistic data=wjz;class h;model y=h/link=glogit aggregate scale=none;run;3.某学校对本科毕业生的去向做了一个调查,分析影响毕业去向的相关因素,结果见表23.其中毕业去向“1”=工作,“2”=读研,“3”=出国留学。
性别“1”=男生,“0”=女生。
用多类别的Logisitic 回归分析影响毕业去向的因素。
专业课x1英语x2性别x3月生活费x4毕业去向y两个统计量的P值均大于0.05,说明模型拟合的较好。
检验全局零假设: BETA=0 无效假设检验结果(似然比,评分)的结果P值均小于0.01,具有显著统计学意义。
三个变量中,有两个是不显著的变量,x3,x2,剔除x3:两个统计量的P值均大于0.05,说明模型拟合的较好。
检验全局零假设: BETA=0 无效假设检验结果(似然比,评分,wald)的结果P值均小于0.01,具有显著统计学意义。
三个变量都是显著的。
以x4=“1”,即参加工作,为参照。
由模型可以看出:)0101.0122.0012.08.011-ex p()004.0038.017.0116.19-ex p(1)004.0038.017.0116.19-ex p()2(421421421x x x x x x x x x y p ++-++++++++==)0101.0122.0012.08.011-ex p()004.0038.017.0116.19-ex p(1)0101.0122.0012.08.011-ex p()3(421421421x x x x x x x x x y p ++-+++++++-==从参数估计表中,与参加工作的同学相比,读研的(y=2)的同学相比,读研的同学其专业课成绩更好(x1的P 值=0.003),而外语成绩(x2的p 值=0.356)和经济状况(x4的P 值=0.184)没有显著差异;出国留学的(y=3)学生其专业课成绩和参加工作的没有显著差异,外语成绩和经济状况则更好。
Sas 程序:data a;input x1 x2 x3 x4 y; cards ; 95 65.0 1 600 2 63 62.00 850 182 53.0 0 700 260 88.0 0 850 372 65.0 1 750 185 85.0 0 1000 3 95 95.0 0 1200 2 92 92.0 1 950 263 63.0 0 850 178 75.0 1 900 190 78.0 0 500 182 83.0 1 750 280 65.0 1 850 383 75.0 0 600 260 90.0 0 650 375 90.0 1 800 263 83.0 1 700 185 75.0 0 750 273 86.0 0 950 286 66.0 1 1500 3 93 63.0 0 1300 2 73 72.0 0 850 186 60.0 1 950 276 63.0 0 1100 1 96 86.0 0 750 271 75.0 1 1000 1 63 72.0 1 850 260 88.0 0 650 167 95.0 1 500 186 93.0 0 550 163 76.0 0 650 186 86.0 0 750 276 85.0 1 650 182 92.0 1 950 373 60.0 0 800 182 85.0 1 750 275 75.0 0 750 172 63.0 1 650 181 88.0 0 850 392 96.0 1 950 2;run;proc print;run;proc logistic;class x3;model y(ref='3')=x1 x2 x3 x4/link=glogit aggregate scale=none ;run;proc logistic;class x3;model y(ref='3')=x1 x2 x4/link=glogit aggregate scale=none ;run;proc logistic;class x3;model y(ref='1')=x1 x2 x4/link=glogit aggregate scale=none ;run;六.收获与思考七. 思考题当自变量是定性变量的时候,我们需要引进虚拟变量进行数量化,当定性变量有n个水平的时候,我们该引进多少的虚拟变量,否则会怎样?不妨试试在sas中试试会出现什么问题。
答:当定性变量有n个水平时应该引进n-1个虚拟变量。
否则最后一个虚拟变量无法用最小二乘估计计算出来。
例:X1-X3为虚拟变量。
Data a;input x1 x2 x3 x y@@;cards;1 0 0 1.26 75 1 0 0 1.35 77 1 0 0 1.40 78 1 0 0 1.58 820 1 0 1.71 65 0 1 0 1.76 66 0 1 0 1.80 68 0 1 0 1.85 700 0 1 1.22 68 0 0 1 1.35 69 0 0 1 1.46 70 0 0 1 1.44 72;proc reg data=a;model y=x1-x3 x;run;X3没有参数估计结果。