数据挖掘与知识发现(第二章)
数据挖掘第一与第二章PPT课件

预测建模可以用来确定顾客对产品促销活 动的反应,预测地球生态系统的扰动,或根据 检查结果判断病人是否患有某种疾病。
14
数据挖掘任务
• 关联分析 用来描述数据中强关联特征的模式。 关联分析的应用包括找出具有相关功
能的基因组、识别用户一起访问的Web页面、 理解地球气候系统不同元素之间的联系等。
12
数据挖掘任务
• 预测vs.描述 • 预测(Prediction)
– 根据其他属性的值,预测特定属性的值 • 描述(Description)
– 导出概括数据中潜在联系的模式
2020年9月29日星期二
13
数据挖掘任务
• 预测建模 涉及以说明自变量函数的方式为目标变量
建立模型。 有两类预测建模任务:分类,用于预测离
– 使用抽样技术或开发并行和分布算法也可以提高可 伸缩程度
2020年9月29日星期二
7
挑战2
• 高维性
– 具有数以百计或数以千计属性的数据集
• 生物信息学:涉及数千特征的基因表达数据 • 不同地区温度测量:如果在一个相当长的时间周期内进
行测量,维度(特征数)的增长正比于测量的次数
– 为低维数据开发的数据分析技术不能很好地处理高 维数据
异常检测的应用包括检测欺诈、网络攻 击、疾病的不寻常模式、生态系统扰动等。
– Jiawei Han的定义
• 从大型数据集中提取有趣的 (非平凡的, 蕴涵的, 先前未知的并且是潜在有用的) 信息或模式
4
数据挖掘技术的定义
• 定义:数据挖掘就是从大量的、不完全的、有 噪声的、模糊的、随机的实际应用数据中,提 取隐含在其中的,人们事先不知道的、但又是 潜在有用的信息和知识的过程.
第二章 知识发现

『
知 识 发 现 的 任 务 一
数 据 总 结 三 』
数据泛化目前主要有两种技术:
多维数据分析方法:是一种数据 仓库技术,也称作联机分析处理 (On-Line Analytical Processing,OLAP)。
数据仓库是面向决策支持的、集成 的、稳定的、不同时间的历史数据 集合。决策的前提是数据分析。
知 识 发 现 的 任 务 一
数 据 总 结 二 』
数据泛化:(数据挖掘主要关 心从数据泛化的角度来讨论数 据总结)一种把数据库中的有 关数据从低层次抽象到高层次 上的过程。
为什么要泛化:为了不遗漏任何 可能有用的数据信息,数据库内 的数据或对象所包含的信息总是 最原始、最基本的信息。而人们 有时又希望从高层次的视图上处 理或浏览数据,因此需要对数据 进行不同层次上的泛化以适应各 种查询要求
知 识 发 现 的 任 务 二
『概 念 描 述 四
』
例子:一个数据挖掘系统需要从我校职工 数据库中,针对我校副教授情况(对比数据 集),对我校讲师情况(目标数据集)进行对 比概要总结,并给出我校讲师对比概念描述。 数据挖掘首先利用SQL查询语句从我校职工 数据库中,选择其中副教授和讲师信息数据; 之后利用对比数据概要总结挖掘算法,获取我 校(对比副教授)讲师情况的一个对比概要描 述总结并对比概念描述规则加以表示出来。其 中一条对比概念描述规则可以是:“讲师:78% (papers<3)and(teaching course<2)”,而“副教 授:66%(papers>=3)and(teaching course>=2)”; 该对比规则表示我校讲师中约有四分之三的人 发表论文少于三篇且主讲课程不超过一门;而 对比之下我校副教授中约有三分之二的人发表 论文不少于三篇且主讲课程不少于一门。
Microsoft Word - 第二章 数据预处理

由于数据库系统所获数据量的迅速膨胀(已达 或 数量级),从而导致了现实世界数据库中常常包含许多含有噪声、不完整( )、甚至是不一致( )的数据。
显然对数据挖掘所涉及的数据对象必须进行预处理。
那么如何对数据进行预处理以改善数据质量,并最终达到完善最终的数据挖掘结果之目的呢?数据预处理主要包括:数据清洗( )、数据集成( )、数据转换( )和数据消减( )。
本章将介绍这四种数据预处理的基本处理方法。
数据预处理是数据挖掘(知识发现)过程中的一个重要步骤,尤其是在对包含有噪声、不完整,甚至是不一致数据进行数据挖掘时,更需要进行数据的预处理,以提高数据挖掘对象的质量,并最终达到提高数据挖掘所获模式知识质量的目的。
例如:对于一个负责进行公司销售数据分析的商场主管,他会仔细检查公司数据库或数据仓库内容,精心挑选与挖掘任务相关数据对象的描述特征或数据仓库的维度( ),这包括:商品类型、价格、销售量等,但这时他或许会发现有数据库中有几条记录的一些特征值没有被记录下来;甚至数据库中的数据记录还存在着一些错误、不寻常( )、甚至是不一致情况,对于这样的数据对象进行数据挖掘,显然就首先必须进行数据的预处理,然后才能进行正式的数据挖掘工作。
所谓噪声数据是指数据中存在着错误、或异常(偏离期望值)的数据;不完整( )数据是指感兴趣的属性没有值;而不一致数据则是指数据内涵出现不一致情况(如:作为关键字的同一部门编码出现不同值)。
而数据清洗是指消除数据中所存在的噪声以及纠正其不一致的错误;数据集成则是指将来自多个数据源的数据合并到一起构成一个完整的数据集;数据转换是指将一种格式的数据转换为另一种格式的数据;最后数据消减是指通过删除冗余特征或聚类消除多余数据。
不完整、有噪声和不一致对大规模现实世界的数据库来讲是非常普遍的情况。
不完整数据的产生有以下几个原因:( )有些属性的内容有时没有,如:参与销售事务数据中的顾客信息;( )有些数据当时被认为是不必要的;( )由于误解或检测设备失灵导致相关数据没有记录下来;( )与其它记录内容不一致而被删除;( )历史记录或对数据的修改被忽略了。
数据挖掘第三版第二章课后习题答案

1.1什么是数据挖掘?(a)它是一种广告宣传吗?(d)它是一种从数据库、统计学、机器学和模式识别发展而来的技术的简单转换或应用吗?(c)我们提出一种观点,说数据挖掘是数据库进化的结果,你认为数据挖掘也是机器学习研究进化的结果吗?你能结合该学科的发展历史提出这一观点吗?针对统计学和模式知识领域做相同的事(d)当把数据挖掘看做知识点发现过程时,描述数据挖掘所涉及的步骤答:数据挖掘比较简单的定义是:数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际数据中,提取隐含在其中的、人们所不知道的、但又是潜在有用信息和知识的过程。
数据挖掘不是一种广告宣传,而是由于大量数据的可用性以及把这些数据变为有用的信息的迫切需要,使得数据挖掘变得更加有必要。
因此,数据挖掘可以被看作是信息技术的自然演变的结果。
数据挖掘不是一种从数据库、统计学和机器学习发展的技术的简单转换,而是来自多学科,例如数据库技术、统计学,机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成。
数据库技术开始于数据收集和数据库创建机制的发展,导致了用于数据管理的有效机制,包括数据存储和检索,查询和事务处理的发展。
提供查询和事务处理的大量的数据库系统最终自然地导致了对数据分析和理解的需要。
因此,出于这种必要性,数据挖掘开始了其发展。
当把数据挖掘看作知识发现过程时,涉及步骤如下:数据清理,一个删除或消除噪声和不一致的数据的过程;数据集成,多种数据源可以组合在一起;数据选择,从数据库中提取与分析任务相关的数据;数据变换,数据变换或同意成适合挖掘的形式,如通过汇总或聚集操作;数据挖掘,基本步骤,使用智能方法提取数据模式;模式评估,根据某种兴趣度度量,识别表示知识的真正有趣的模式;知识表示,使用可视化和知识表示技术,向用户提供挖掘的知识1.3定义下列数据挖掘功能:特征化、区分、关联和相关性分析、分类、回归、聚类、离群点分析。
研究生《知识发现与数据挖掘》教学大纲
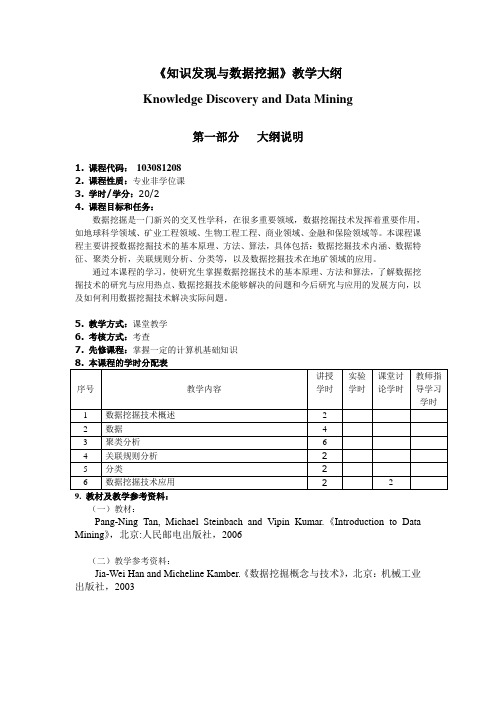
《知识发现与数据挖掘》教学大纲Knowledge Discovery and Data Mining第一部分大纲说明1. 课程代码:1030812082. 课程性质:专业非学位课3. 学时/学分:20/24. 课程目标和任务:数据挖掘是一门新兴的交叉性学科,在很多重要领域,数据挖掘技术发挥着重要作用,如地球科学领域、矿业工程领域、生物工程工程、商业领域、金融和保险领域等。
本课程课程主要讲授数据挖掘技术的基本原理、方法、算法,具体包括:数据挖掘技术内涵、数据特征、聚类分析,关联规则分析、分类等,以及数据挖掘技术在地矿领域的应用。
通过本课程的学习,使研究生掌握数据挖掘技术的基本原理、方法和算法,了解数据挖掘技术的研究与应用热点、数据挖掘技术能够解决的问题和今后研究与应用的发展方向,以及如何利用数据挖掘技术解决实际问题。
5. 教学方式:课堂教学6. 考核方式:考查7. 先修课程:掌握一定的计算机基础知识9. 教材及教学参考资料:(一)教材:Pang-Ning Tan, Michael Steinbach and Vipin Kumar.《Introduction to Data Mining》,北京:人民邮电出版社,2006(二)教学参考资料:Jia-Wei Han and Micheline Kamber.《数据挖掘概念与技术》,北京:机械工业出版社,2003第二部分教学内容和教学要求第一章数据挖掘概述1.1 教学目的与要求重点讲解数据挖掘的起源、数据挖掘过程与功能,以及面临的主要问题。
1.2 教学内容理解和掌握数据挖掘的基本概念、数据挖掘过程以及数据挖掘功能;了解数据挖掘的应用和面临的问题;重点是对数据挖掘能够解决的问题和解决问题思路有清晰的认识。
1.2.1 什么是数据挖掘数据挖掘(Data Mining)就是从大量的、不完全的、模糊的、随机的实际应用数据中,提取隐含在其中的、事先不知道的但又是潜在有用的信息和知识的过程。
第2章 数据挖掘过程与知识发现

第二章数据挖掘过程与知识发现第一节 CRISP_DM介绍跨行业数据挖掘标准流程被行业成员广泛应用,这一模型包括以下六个阶段:一、业务理解:业务理解包括确定商业对象、了解现状、建立数据挖掘目标和制定计划书。
应该是对数据挖掘的目标有一个清晰的认识,知道利润所在,其中包括数据收集、数据分析和数据报告等步骤。
二、数据理解:一旦商业对象和计划书确定完备,数据理解就考虑将所需要的数据。
这一过程包括原始数据收集、数据描述、数据探索和数据质量核查等。
由于数据挖掘是目标导向的,不同的商业目的需要不同的数据系列。
数据挖掘的第一步是从许多可供使用的数据库中筛选相关数据,来正确描述研究问题;即对问题进行简单描述;识别问题的相关数据;所选择的变量要相互独立,变量独立意味着不涵盖重复信息。
三、数据准备:确定可用的数据资源以后,需要对此进行筛选、清理、调整为所需要的形式。
数据整理和数据转换等数据建模的准备工作需要在这一阶段完成。
更深层次的数据探索也可以在这一阶段进行,新增模型的应用再次提供了在业务理解基础上看清楚数据模式的机会。
数据预先处理:1、噪声问题和缺失问题a)数据重复b)数值错误c)数据缺失2、数据的变换a)数据类型的变换b)数据的平滑c)数据的概化d)数据的规范化十进制缩放:将某个数据全部除以10的相同的幂通过极值来转化:新数据=(原数据-最小数值)/(最大数值-最小数值)通过均值和标准差来转化:新数据=(原数据-均值)/标准差通过对数来转化:对每个数据经过自然对数进行数据转换,例如下面的转换可以把数据转换到0-1之间: O=1/(1+exp(-x))四、建立模型:数据模型建立是应用数据挖掘软件不不同的情景下获得结果的过程。
首先往往是聚类分析和数据视觉探究。
依据数据挖掘类型的不同,应用各种不同的模型,如果任务是对数据分组,则运用判别分析;如果任务是估计,在连续数据类型的情况下,回归分析就可以运用,对于不连续的数据则可以运用逻辑回归分析,神经网络技术对两者都是可以的。
数据挖掘与知识发现-课程PPT课件

当数据挖掘工具运行于高性能的并行处理系统上的时 候,它能在数分钟内分析一个超大型的数据库。这种 更快的处理速度意味着用户有更多的机会来分析数据, 让分析的结果更加准确可靠,并且易于理解。
-
27
数据挖掘的进化历程
-
52
数据挖掘的分类
根据挖掘的数据库类型分类 根据挖掘的知识类型分类 根据应用分类 根据所用的方法和技术分类
-
50
数据挖掘的分类
根据挖掘的数据库类型分类 根据挖掘的知识类型分类 根据应用分类 根据所用的方法和技术分类
-
51
根据挖掘的数据库类型分类
与数据库匹配的数据挖掘技术分类
➢ 关系数据挖掘 ➢ 非关系型数据挖掘
处理的数据的特定类型分类
➢ 空间的数据挖掘 ➢ 时间序列的数据挖掘 ➢ 文本的数据挖掘 ➢ 多媒体的数据挖掘
-
47
知识发现与数据挖掘的 基本概念
数据挖掘的进化历程 数据挖掘的任务 数据挖掘的分类 数据挖掘的对象 数据挖掘与专家系统的区别
-
48
数据挖掘的分类
数据库技术 信息科学
可视化
数据挖掘
统计学 机器学习 其他学科
-
49
数据挖掘的分类
根据挖掘的数据库类型分类 根据挖掘的知识类型分类 根据应用分类 根据所用的方法和技术分类
知识发现系统的结构
知识发 现管理
器
知识 库
数
数据
数据 库
据 选
仓库 接口
择
知识发 现描述
知识发现 评价
数据仓库的数据库接口
商业分析 知识发现系统的数据库接口
第2章知识发现的基本概念
思维科学将知识定义
思维科学将知识定义为: 思维科学将知识定义为:“人类认知的成 果来自于实践活动。 果来自于实践活动。处理人际社交关系活 动和科学试验等实践活动。 动和科学试验等实践活动。从实践中得到 的感性认识经过去粗取精, 的感性认识经过去粗取精,去伪存真由此 及彼, 及彼,由表及里的加工制作上升为抽象的 理论认知, 理论认知,成为以概念为元素的系统的科 学理论, 学理论,这是知识的比较完备的形 态。”[1] [1] 田运,思维辞典,浙江教育出版社, 田运,思维辞典,浙江教育出版社, 1996年P338。 年 。
We often see data as a string of bits, or numbers and symbols, or “objects” which we collect daily. Information is data reduced to the minimum necessary to characterize the data.
数据挖掘与知识发现 复杂数据对象的数据挖掘与知识发现) (复杂数据对象的数据挖掘与知识发现)
2 知识发现 基本概念
2 知识发现的基本概念
2.1 数据、信息、知识 2.2 KDD定义 2.3 KDD对象 2.4 KDD功能 2.5 KDD技术方法
数据、信息、 数据、信息、知识
事实(facts):人类思想和社会活动的客观映射。 事实(facts):人类思想和社会活动的客观映射。 事实的数字化、编码化和序列化。 数据(data):事实的数字化、编码化和序列化。
信息资源的控制成为全球性难题
Internet已经成为最大的信息源, Internet已经成为最大的信息源,但缺乏集中统一 已经成为最大的信息源 的管理机制, 信息发布具有自由性和任意性, 的管理机制 , 信息发布具有自由性和任意性 , 难于 控制和管理 分散、无序、无政府、变动、数量、 分散、无序、无政府、变动、数量、包罗万象 真伪并存, 真伪并存, 资源信息和非资源信息难于驾御 非规范、 非规范、非结构 检索查全和查准提出新的挑战 多媒体、多语种、 多媒体、多语种、多类型信息的整合提出新的挑战 跨国界数据传递和流动, 带来政治、 跨国界数据传递和流动, 带来政治、文化新问题 集成多种(正式和非正式等) 集成多种(正式和非正式等)交流方式
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
15
属性的类型也可以用不改变属性意义的变换来描述:
例: 如果长度分别用米和英尺度量,其属性意义是否有变化。计算平均长 度时,有什么变化? 例:温度 我们说“温度2度是1度的两倍”,用下列哪种测量有意义? 绝对标度?摄氏度?华氏度?
16
三、非对称的属性
对于非对称的属性,只有非零值才是重要的
例1:对象是学生,属性是学生是否选修某门大学课程。对某个学生,如果他选 择了对应某属性的课程,则该属性取1,否则取0。
22
稀疏数据矩阵
数据矩阵的特殊形式 属性类型相同 非对称
23
三、基于图形的数据
带有对象之间联系的数据
数据对象映射到图中的结点 对象之间的联系用对象之间和链、方向、权值表示
2 5 2 5 1
24
具有图形对象的数据
若对象具有结构(包含具有联系的子对象),则对象常用图形表示
25
34
一、测量误差和数据收集错误
测量误差:
测量过程中导致的问题,在某种程度上,记录的值与实际值不符 例: 一个人连续两次测量体重,得到的值不一样
数据收集错误:
遗漏数据对象或属性值,或不当的包含了其他数据对象 例: 一类特定种类动物研究可能包含了其他相关种类的动物,他们只是表面上与要 研究的种类相似。
12
二、属性类型
属性的性质不必与用来度量他的值的性质相同 属性类型告诉我们,属性的哪些性质反映在用于测量他的 值中。 例1:雇员年龄与ID号 这两个属性都可以用整数表示 雇员的平均年龄有意义,而平均ID却无意义 年龄有最大最小值,而整数却无此限制 但用整数来表示时,并未暗示有限制
13
例2:线段长度
TID
Items
1 2 3 4 5
Bread, Coke, Milk Beer, Bread Beer, Coke, Diaper, Milk Beer, Bread, Diaper, Milk Coke, Diaper, Milk
21
数据矩阵
数据集族中的所有数据对象都具有相同的数值属性集 数据对象可看作是多维空间中的向量 可以使用标准的矩阵操作对数据进行变换和处理
38
五、遗漏值
一个数据对象遗漏一个或多个属性值 信息收集不全 属性不能用于所有对象
处理策略 ① 删除数据对象或属性,如遗漏数据对象很少 ② 估计遗漏值,如插值或最近邻法 ③ 在分析时忽略遗漏值,如忽略属性计算相似度
39
六、不一致的值
如地址字段包含城市和邮编,但是有的邮编区域不包含在城市中 如人的身高出现了负值
9
下表显示包含学生信息的数据集 每行对应于一个学生,而每列则是一个属性,描述学生的 某一方面,如平均成绩(GPA)或标示号(ID)
学生ID
1034262 1052663 1082246
年
级
平均GPA
3.24 3.51 3.62
…
… … …
四年级 二年级 一年级
这种数据集最常见,但还有其他类型的数据集
41
从商业或科学的角度看
只有当数据适合预期应用时,他才是高质量的!
时效性:有些数据收集后就开始老化 例如:顾客的购买行为,WEB浏览模式
相关性:可用的数据必须包含应用所需要的信息 例如:预测交通事故发生率,忽略驾驶员的年龄和性别 例如:调查数据只反应对调查做出响应的人的意见(抽样偏倚) 关于数据的知识:数据解释文档的好坏决定了他是否干扰分析 例如:文档说明属性是强相关的,则说明属性可能提供高度冗余 的信息,我们可以只选择一个属性。 若文档没有告诉我们某特定字段遗漏值用-9999表示,则 数据分析就会出错。
此时,不要在进行数据挖掘任务时假设属性之间在统计上是相互独立的!
31
2、数据质量
32
数据挖掘使用的数据通常是为其他用途收集的,或 收集时无明确目的 因此,数据质量问题往往无法避免
对数据挖掘任务来说,需要着眼于 (1)数据质量问题的检测和纠正
(2)使用容忍低质量数据的算法
33
2.1、测量和数据收集问题
课程1 课程2 课程3 课程4 课程5 课程6 课程7 课程8 课程9 学生1
学生2 学生3
0
1 0
0
0 1
0
0 000 011 00
0 0
0
0 0
0
0 1
1
0 0
只有非0值才重要的二元属性称为非对称二元属性 只有非0值才重要的离散属性称为非对称二元属性(学分) 只有非0值才重要的连续属性称为非对称二元属性(成绩)
10
1.1、属性与度量
11
一、先来看看什么是属性
属性是对象的性质或特质,因对象而异,或随时间而变化
例如:眼球的颜色因人而异,物体的温度随时间而变
属性本身并非数字或符号!
测量标度是将数值或符号值与对象的属性相关联的规则或函 数
例如:踏上浴室的磅秤称体重;将人分为男女;清点会议室的椅子数, 确定是否能为与会者提供足够的座位
6
1、数据类型
7
数据集的不同表现在很多方面
用来描述数据对象的数据可以具有不同的类型-定量或定 性的 数据集可能具有特定的性质,如数据集包含时间序列或彼 此之间具有明显联系的对象 数据的类型决定我们应使用何种技术和工具来分析数据!
8
1、数据集全称是什么? 数据对象的集合 2、数据对象是什么? 记录、点、向量、模式、事件、案例、样本、观测、实体 3、数据对象用什么来描述? 属性、变量、特性、字段、特征、维
偏倚=均值-标准重量=1.001-1.000=0.001 精度=标准差=0.013
准确率:被测量的测量值与实际值之间的接近度
准确率依赖于精度和偏倚,他是一个一般化的概念
37
四、离群点
某种意义上具有不同于数据集中其他大部分数据对象的特征的数据对象 离群点可以是合法的数据对象或值 与噪声不同,有时是人们感兴趣的对象
35
二、噪声和伪象
噪声:测量误差的随机部分
例: 在老旧电话上说话时的声音的干扰 电视屏幕上的雪花
伪象:确定性现象造成的测量误差
例: 一组照片在同一地方出现条纹
36
正弦波+ 噪声
两个正弦波
三、精度、偏倚、准确率
精度:(同一个量)重复测量值之间的接近程度 偏倚:测量值与被测量值之间的系统变差
例: 某样品的标准重量为1克,为了评估实验室新天平的精度和偏倚,我们称重5次 {1.015, 0.990, 1.013, 1.001, 0.986}
Yes No No Yes No No Yes No No No
Single Married Single Married
Divorced 95K Married 60K
Divorced 220K Single Married Single 85K 75K 90K
20
事务数据或购物篮数据
特殊类型的记录数据 每个记录中的项是购物篮中的商品 可以将它转换为标准记录数据, 记录的字段是非对称属性 属性可以是离散或连续的,例如商品数量或费用
29
四、处理非记录数据
记录数据 非记录数据
子结构1 化合物1 化合物2 化合物3
子结构2
子结构3
子结构4
1 1 …
0 1 …
0 0 …
1 0 …
30
注意:尽管容易用记录形式表示非记录数据,但不能捕获所有信息
时间相关性
Jan
位点1 位点2 位点3
Feb
Mar
Apr
空 间 相 关 性
27.2 28.7 29.2 31.1 30.1 33.5 35.9 37.3 … … … …
数据挖掘者 统计人员
。。。有意思,还有其他问题吗? 啊?我没听到任何问题 没有。。。。。。。。 哦,你得到了所有病人的数据? 是的。字段 2和字段 3 也有不少问题。我猜 是的,我还没有足够的时间分 真棒,病人数据集的数据问题 哦,首先是字段 5 ,这是我们要预测的 那你一定听说过字段 4的问题了吧?他的测量范围应当是 哼哼。我的结果那是相当的好。字 什么?字段 1只是一个标识号。 是的。但是这些这些字段只是字段 5 无论如何,尽管有这些问题,你还能够完 无论如何,我的结果在那。 。。。。。。。。。。。。。。。 啊!不!我才想起来,按字段 5排序之后, 想你可能已经注意到了。 太多,我没什么进展。。 析,但是我的确有了一些有趣 1 到 10 ,而 0 表示有遗漏的值。但是,由于数据输入错 变量。地球人都知道,如果使用这些值 段 1 是字段 5 的很强的预测子。你们 的弱预测子。 成一些分析。真厉害啊! 。。。。。。。。。。。。。。。 我们加上了一个ID号。他们之间存在很 的结果。 误,所有的10的日志,结果会更好,但是我们后来才 都变成了0。可是,由于有些病人这个字 这些人竟然没注意到。 。。。。。。。。。。。。。。。 强的联系,但是毫无意义,抱歉。。。 发现这一点。他们告诉你了吗? 段的值有遗漏,所以不能确定该字段上的 0实际是0还是 。。。。。。。。。。。。。。。 10。不少记录都存在这个问题。
数据挖掘与知识发现
第二章 数据
这是不是数据?
2.3 1.2 1.7 5.0 2.3 2.2 1.3 2.2 3.7 2.1 3.3 2.2 3.3 1.3 2.1 2.2 3.1 5.2 1.2 2.2 3.5 2.9 5.1 3.1
2
• • • •
数据类型 数据质量 数据预处理 相似性和相异性度量
3
考虑你收到了某个医学研究者发来的邮件,内容如下:
你好, 我已附上先前邮件提及的数据文件。每行包含一个病人的信息,由5个字 段组成。我们想使用前面4个字段预测最后一个字段。因为我要出去几天,所 以没有时间为你提供关于这些数据的更多信息,但希望不会耽误你太多时间。 如果你不介意的话,我回来之后是否可以开会讨论你的初步结果?我可能会 邀请我们小组的其他成员参加。 谢谢!几天之后见!