SPSS案例分析
SPSS上机实验案例分析剖析

SPSS上机实验案例分析练习一:下表为10个人对两个不同的问题作出的回答(回答为“Yes”或“No”)后得到的数据,利用SPSS为该数据创建频数分布表。
练习二: 某百货公司连续40天的商品销售额(单位:万元)如下:根据上面的数据进行适当分组,编制频数分布表。
练习三:某行业管理局所属40个企业1999年的产品销售收入数据(单位:万元)如下:(1)根据上面的数据进行适当分组,编制频数分布表,并计算出累计频数和累计频率;(2)按规定,销售收入在125万元以上为先进企业,115万元-125万元为良好企业,105万元-115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
(1)请按下面注明的两个条件计算出该班每位同学的总评成绩。
条件1:总评成绩的构成:总评成绩=0.2*平时成绩+0.8*期末成绩(即总评成绩中,平时成绩占20%,期末成绩占80%)条件2:总评成绩请保留为整数(2)请按100-90分,89-80分,79-70分,69-60分,59分及以下,将该班全体同学按照期末成绩进行分组得出各组人数。
练习五:如下表中所示的是20个股票经纪商对于两种不同交易收取佣金数据的一个样本。
这两种交易分别为: 买(1)计算两种交易佣金的全距和四分位数间距。
(2)计算两种交易佣金的方差和标准差。
(3)计算两种交易佣金的变异系数。
(4)比较两种交易的成本变异程度。
练习六:某生产部门利用一种抽样程序来检验新生产出来的产品的质量,该部门使用下面的法则来决定检验结果:如果一个样本中的14个数据项的方差大于0.005,则生产线必须关闭整修。
假设搜集的数据如下:问此时的生产线是否必须关闭?为什么?练习七:将50个数据输入到SPSS工作表中。
并使用SPSS计算这些数据描述统计量(如最大值、平均值、方差、标准差求晚8:30分时段电视节目中广告所占时间均值的点估计的95%置信区间。
练习九:某年度我国部分工业品产量如下表所示请据表中数据对如下六个问题进行统计图形描述(1)请选择一个适当图形描述各地区所含省市数目(2)请选择一个适当图形描述各地区水泥的平均产量(3)请选择一个适当图形描述每个地区水泥产量低于800万吨的省市数目(4)请选择一个适当图形描述该年度全国生铁、钢、水泥、塑料的平均产量(5)请选择一个适当图形描述该年度华北五省市工业品产量(6)请选择一个适当图形描述各地区塑料总产量占全国总量的比例(1)用平均房价作自变量,画出这些数据的散点图;(2)求客房使用率关于平均房价估计的回归方程;(3)对于平均房价为80美元的一家旅馆,估计它的客房使用率练习十一:某公司采集了美国市场上办公用房的空闲率和租金率的数据。
SPSS数据分析实例
t检验的假设如下: H0:两总体均数相同,μ1 =μ2
Байду номын сангаас
H1:两总体不均数相同,μ1 ≠μ2
两样本t检验对数据的要求: 1.小样本时要求分布不太偏 2.小样本时要求方差齐
第18页/共19页
感谢您的欣赏
第19页/共19页
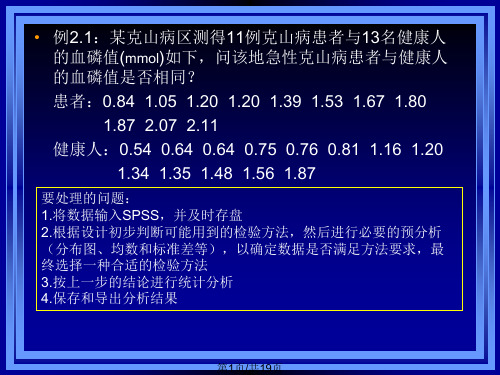
• 例2.1:某克山病区测得11例克山病患者与13名健康人 的血磷值(mmol)如下,问该地急性克山病患者与健康人 的血磷值是否相同? 患者:0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人:0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87
应该观察分组描述情况 选择菜单项 数据 拆分文件 ,系统弹出对话框
选择 比较组 ,将变量group选入分组方式框,点击确定
第11页/共19页
再做一次数据描述,输出结果
根据描述结果,可判断检验结果多半会拒绝H0。
取消文件拆分,不然会影响以后的统计分析
选择菜单项 数据 拆分文件 ,选择 分析所有个案,不创建组
∴应该先判断该数据是否符合t检验要求,即对数据进行简单描述
第8页/共19页
2.2.1 数据的简单描述
选择菜单项 分析
描述统计
描述
,
系统弹出对话框
选择描述变量
第9页/共19页
选择所需描述变量x,点击ok
系统弹出新界面
结果浏览窗口
导航栏
具体输出结果
spss案例分析报告(精选)

spss案例分析报告(精选)本文通过分析一份 SPSS 数据,展示 SPSS 在统计分析中的应用。
数据概述本数据为一家咖啡馆的销售数据,共有 200 条记录,包括 7 个变量:日期、时间、收银员、商品名、销售价格、数量和总价。
SPSS 分析1. 描述性统计使用 SPSS 的描述性统计功能,可以获取数据的基本信息,如均值、标准偏差、最大值、最小值等。
其中,销售价格的均值为 44.71 元,标准偏差为 13.29 元,最小值为 23 元,最大值为 78 元。
数量的均值为 1.62 个,标准偏差为 0.51 个,最小值为 1 个,最大值为3 个。
总价的均值为 73.25 元,标准偏差为 21.89 元,最小值为 23 元,最大值为 156 元。
2. 单样本 t 检验假设一杯咖啡的平均售价为 50 元,我们可以使用单样本 t 检验对这个假设进行检验。
首先,我们需要用 SPSS 的数据透视表功能,计算出每杯咖啡的平均售价。
然后,使用单样本 t 检验功能,输入样本均值、假设的总体均值(50 元)、样本标准差、样本大小以及置信度水平。
在这个数据集中,单样本 t 检验得出的 t 值为 -2.36,P 值为 0.019,显著性水平为 0.05,因此我们可以拒绝原假设,认为该咖啡馆的咖啡售价不是 50 元。
4. 相关分析假设我们想要了解商品数量和销售额之间的关系,我们可以使用 SPSS 的相关分析功能来进行分析。
首先,我们需要使用数据透视表功能,计算出每个订单的总价和数量。
然后,使用相关分析功能,输入这两个变量的值,得出相关系数和显著性水平。
在这个数据集中,商品数量和销售额之间的相关系数为 0.749,P 值为 0,显著性水平非常显著。
因此,我们可以认为商品数量和销售额之间存在极强的正相关关系。
结论本文通过 SPSS 对一份咖啡馆销售数据进行分析,展示了 SPSS 在统计分析中的应用。
通过描述性统计、单样本 t 检验、双样本 t 检验和相关分析等功能,我们可以获得数据的基本信息,检验假设,分析变量之间的关系,从而帮助企业更好地决策和管理。
2024版SPSS案例分析

SPSS案例分析目的和背景案例介绍案例来源数据类型数据分析目的问卷调查实验数据公开数据库网络爬虫数据来源数据筛选与清洗去除重复数据检查并删除重复的记录或观测值。
处理缺失值根据数据的性质和缺失情况,采用插补、删除等方法处理缺失值。
异常值处理识别并处理数据中的异常值,如离群点、极端值等。
数据转换根据分析需求,对数据进行必要的转换,如对数转换、标准化等。
数据分类根据研究目的和变量性质,对数据进行分类整理。
变量编码对分类变量进行编码,以便于后续的统计分析。
数据排序按照特定变量或条件对数据进行排序,以便更好地观察数据分布和规律。
数据分组将连续变量按照一定规则进行分组,以便进行组间比较和统计分析。
数据整理与编码频数分布表与直方图频数分布表直方图集中趋势度量算术平均数01中位数02众数03离散程度度量极差方差与标准差变异系数点估计使用样本数据计算总体参数的点估计值,如样本均值、样本比例等。
区间估计根据样本数据构造总体参数的置信区间,以评估参数的真实值可能落入的范围。
假设检验中的参数估计在假设检验中,参数估计可用于计算检验统计量的值,以及确定拒绝或接受原假设的依据。
参数估计030201假设检验检验统计量原假设与备择假设决策与结论显著性水平与P值设定显著性水平(α),并根据检验值,以判断是否拒绝原假设。
方差分析方差分析的基本思想单因素方差分析多因素方差分析方差分析的结果解读数据可视化方法图表展示利用SPSS的图表功能,可以绘制各种类型的图表,如柱状图、折线图、散点图等,直观地展示数据的分布和关系。
数据透视表通过数据透视表功能,可以按照不同的维度对数据进行汇总和展示,方便用户快速了解数据的整体情况。
交互式可视化SPSS还提供了交互式可视化工具,允许用户通过拖拽、选择等方式与数据进行互动,更加灵活地探索数据。
1 2 3描述性统计推论性统计数据挖掘数据解读与讨论将分析结果进行整理和归纳,提取出主要结论和观点。
结果整理结果解释结果可视化报告撰写对分析结果进行解释和说明,阐述其意义和影响。
SPSS统计分析分析案例

SPSS统计分析案例一、我国城镇居民现状近年来;我国宏观经济形势发生了重大变化;经济发展速度加快;居民收入稳定增加;在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下;全国居民的消费支出也强劲增长;消费结构发生了显著变化;消费结构不合理现象得到了一定程度的改善..本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点..二、我国居民消费结构的横向分析第一;食品消费支出比重随收入增加呈现出明显的下降趋势;这与恩格尔定律的表述一致..但最低收入户与最高收入恩格尔系数相差太过悬殊;城镇最低收入户刚刚解决了温饱问题;而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型;甚至接近最富裕型..第二;衣着消费支出比重随收入增加缓慢上升;到高收入户又有所下降;但各收入组支出比重相差不大..衣着支出比重没有更多的递增且最高收入户的支出比重有所下降;这些都符合恩格尔定律关于衣着消费的引申..随着收入的增加;衣着支出比重呈现先上升后下降的走势..事实上;在当前的价格水平和服装业的发展水平下;城镇居民的穿着是有一定限度的;而且居民对衣着的需求也不是无限膨胀的;即使收入水平继续提高;也不需要将更大的比例用于购买服饰用品了..第三;家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势;说明居民的生活水平随收入的增加而不断提高和改善..第四;医疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势..这是因为医疗保健支出作为生活必须支出;不论居民生活水平高低;都要将一定比例的收入用于维持自身健康;而且由于医疗制度改革;加重了个人负担的同时;也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别;因而不同收入等级的居民在医疗保健支出比重上差别不大..第五;居住支出比重基本上呈先上升后下降的趋势;这与我国居民消费能级不断提升;住宅商品正在越来越成为城镇居民关注的热点是相吻合的;同时与恩格尔定律的引申也是一致的..可以看出;城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响;但归根结底仍取决于居民的收入水平;要提高城镇居民的消费支出;必须增加居民收入..因此;采取切实有效的措施增加城镇居民的可支配收入;不仅可以提高全国城镇居民的总体消费水平;促进消费结构向着更加健康、合理的方向发展;而且在启动内需;促进我国的经济发展方面有着重大的现实意义..三、我国居民消费结构的纵向分析进入21世纪以来;随着经济体制改革的深入;国民经济的迅速发展;我国城乡居民的消费水平显著提高;居民的各项支出显著增加..随着消费水平的提高;我国城乡居民消费从注重量的满足到追求质的提高;从以衣食消费为主的生存型到追求生活质量的享受型、发展型;消费质量和消费结构都发生了明显的变化..城镇居民在食品、衣着、家庭设备用品三项支出在消费支出中的比重呈现明显的下降趋势;其中食品类支出比重降幅最大;衣着类有所下降;家庭设备用品类下降幅度不是很大..与此同时;医疗保健、交通通讯、文化娱乐教育服务、居住及杂项商品支出在消费支出中的比例均有上升;富裕阶段的消费特征开始显现..四、我国城镇居民消费结构及趋势的统计分析下图是出自中国统计年鉴—2009这一资料性年刊;它系统收录了全国和各省、自治区、直辖市2008年经济、社会各方面的统计数据;以及近三十年和其他重要历史年份的全国主要统计数据..此年鉴正文内容分为24个篇章;本文选取其中的第九篇章-人民生活;用以探究我国城镇居民消费结构及其趋势..表1 中国统计年鉴—2009统计表9-5 城镇居民家庭基本情况可支配收入1510.16 4282.95 6279.98 13785.81 15780.76平均每人消费性支出元1278.89 3537.57 4998.00 9997.47 11242.85 食品693.77 1771.99 1971.32 3628.03 4259.81衣着170.90 479.20 500.46 1042.00 1165.91居住60.86 283.76 565.29 982.28 1145.41 家庭设备用品及服务108.45 263.36 374.49 601.80 691.83 医疗保健25.67 110.11 318.07 699.09 786.20交通通信40.51 183.22 426.95 1357.41 1417.12 教育文化娱乐服务112.26 331.01 669.58 1329.16 1358.26 杂项商品与服务66.57 114.92 171.83 357.70 418.31 平均每人消费性支出构成人均消费性支出=100食品54.25 50.09 39.44 36.29 37.89衣着13.36 13.55 10.01 10.42 10.37居住 6.98 8.02 11.31 9.83 10.19 家庭设备用品及服务10.14 7.44 7.49 6.02 6.15 医疗保健 2.01 3.11 6.36 6.99 6.99交通通信 1.20 5.18 8.54 13.58 12.60 教育文化娱乐服务11.12 9.36 13.40 13.29 12.08 杂项商品与服务0.94 3.25 3.44 3.58 3.72注:1.本表至9-17表为城镇住户抽样调查资料..2.从2002年起;城镇住户调查对象由原来的非农业人口改为城市市区和县城关镇住户;本篇章相关资料均按新口径计算;历史数据作了相应调整..五、SPSS统计分析图一给出了基本的描述性统计图;图中显示各个变量的全部观测量的Mean均值、Std.Dev iation标准差和观测值总数N..图2给出了相关系数矩阵表;其中显示3个自变量两两间的Pearson相关系数;以及关于相关关系等于零的假设的单尾显著性检验概率..图1 描述性统计表图2 相关系数矩阵从表中看到因变量家庭设备用品及服务与自变量食品、衣着之间相关关系数依次为0.869、0.684;反映家庭设备用品及服务与食品、衣着之间存在显著的相关关系..说明食品与衣着对于家庭设备用品及服务条件的好转有显著的作用..自变量居住于因变量家庭设备用品及服务之间的相关系数为-0.894;它于其他几个自变量之间的相关系数也都为负;说明它们之间的线性关系不显著..此外;食品与衣着之间的相关系数为0.950;这也说明它们之间存在较为显著的相关关系..按照常识;它们之间的线性相关关系也是符合事实的..图3给出了进入模型和被剔除的变量的信息;从表中我们可以看出;所有3个自变量都进入模型;说明我们的解释变量都是显著并且是有解释力的..图3 变量进入/剔除信息表图4给出了模型整体拟合效果的概述;模型的拟合优度系数为0.982;反映了因变量于自变量之间具有高度显著的线性关系..表里还显示了R平方以及经调整的R值估计标准误差;另外表中还给出了杜宾-瓦特森检验值DW=2.632;杜宾-瓦特森检验统计量DW是一个用于检验一阶变量自回归形式的序列相关问题的统计量;DW在数值2到4之间的附近说明模型变量无序列相关..图4 模型概述表图4给出了方差分析表;我们可以看到模型的设定检验F统计量的值为9.229;显著性水平的P值为0.236..图5 方差分析表图6给出了回归系数表和变量显著性检验的T值;我们发现;变量居住的T值太小;没有达到显著性水平;因此我们要将这个变量剔除;从这里我们也可以看出;模型虽然通过了设定检验;但很有可能不能通过变量的显著性检验..图6 回归系数表图7给出了残差分析表;表中显示了预测值、残差、标准化预测值、标准化残差的最小值、最大值、均值、标准差及样本容量等;根据概率的3西格玛原则;标准化残差的绝对值最大为1.618;小于3;说明样本数据中没有奇异值..图7 残差统计表图8给出了模型的直方图;由于我们在模型中始终假设残差服从正态分布;因此我们可以从这张图中直观地看出回归后的实际残差是否符合我们的假设;从回归残差的直方图于附于图上的正态分布曲线相比较;可以认为残差的分布不是明显地服从正态分布..尽管这样也不能盲目的否定残差服从正态分布的假设;因为我们用了进行分析的样本太小;样本容量仅为5..图8 残差分布直方图从上面图4的分析结果看;我们的模型需要剔除居住这个变量;用本次实验中的方法和步骤重新令家庭设备用品及服务对食品和衣着回归;得到的主要结果如图9、图10和图11所示;跟上面的分析类似;从中可以看出;剔除居住这个变量后;模型拟合优度为0.964;比原来有所降低;而方差分析的F检验为27.071;新模型与原来的模型相比;各个系数都通过了显著性T检验;因此更加合理;从而我们可以得出结论:剔除居住这个变量后的模型更加合理;因此在做预测过程中要使用剔除不显著变量后的模型..图9 模型概述图10 方差分析表图11 回归系数表六、我国居民消费变化的趋势特点1食品消费质量提高;衣着消费支出比重下降..食品消费水平由过去简单的吃饱吃好;转变为品种更加丰富;营养更加全面..一方面由于食品供应的日益充足..另一方面由于在外饮食的增加;粮食消费比重减小;购买量大幅度下降..衣着是两项基本生存资料之一;衣着消费向时装化、名牌化、个性化发展的倾向更加明显;成衣化倾向成为主流..从衣着和食品消费比重的下降可以看出城镇居民满足基本生活的支出并没有随着收入水平的提高而提高;这表明我国城镇居民满足吃、穿为主的生存型消费需求阶段已经结束;逐步向以发展型和享受型消费的阶段过渡..2 居民收入迅速增长;消费水平大幅度提高;消费结构呈现明显的富裕型特征消费是收入的函数;收入的增加是消费水平提高和消费结构变化的前提..随着我国经济的发展;我国居民的收入水平不断提高;特别是21世纪以来;我国居民的收入水平迅速提高..伴随着收入水平的提高;城乡居民各项支出全面增加;消费性支出大幅度增长..今后5—10年以至更长时间;我国经济保持一个较高的增长速度是完全可能的;城乡居民的消费水平将大幅度提高..3消费能级不断提高;消费内容日益丰富;住房与轿车消费同时升温;可望提前成为消费热点在消费水平提高和消费结构改善的同时;城乡居民的消费能级不断提高....4以教育为龙头的娱乐教育文化服务类消费继续攀升随着人们对知识认知程度的提高和自我完善意识的增强;对教育的投入仍会保持增长..目前从子女教育在人们储蓄目的位居前列的情况看;对教育及教育产品的投入仍是今后一个时期的消费热点..大力发展教育事业;特别是高等教育、成人教育、职业教育应是政府长期坚持和倡导的提高城镇居民收入水平;缩小收入差距;应做到:1.进一步强化收入分配的宏观调控力度采取切实措施努力提高低收入群体的收入水平..2.加快西部大开发步伐;做好扶贫开发工作..3.进一步完善社会保障制度;改善居民整体尤其是社会弱势群体的生存环境..4.通过完善税收制度来缩小部分不合理的高低收入阶层差距..5.对不动产、金融资产收益以及财产的继承与赠与;要通过合理设置税种税率;征收房产税、利息税以及遗产与赠与税等税种来进行调节..参考文献1 吕振通张凌云spss统计分析与应用机械工程出版社;2009年2 Nancy L.Leech Karen C.Barrett Ceorge A.Morgan SPSS for Intermediate Statistics Use and InterpretationThird Edition PUBLISHING HOUSE OF ELECTRONICS INDUSTRY;2009年。
2024年SPSS培训案例分析1-(含多场合)

SPSS培训案例分析1-(含多场合)SPSS培训案例分析1一、案例背景SPSS(StatisticalPackagefortheSocialSciences)是一款广泛应用于社会科学、医学、商业等多个领域的统计分析软件。
为了提高员工的数据分析能力,某企业决定对员工进行SPSS培训。
本次培训的主要目的是帮助员工掌握SPSS的基本操作,提高数据分析的效率,从而为企业决策提供有力支持。
二、培训需求分析1.员工背景:参与培训的员工来自不同的部门,包括市场部、人力资源部、研发部等,他们的专业背景、工作经验和数据技能各不相同。
2.培训目标:根据员工背景和实际需求,确定培训目标如下:(1)掌握SPSS的基本操作和界面布局;(2)学会数据录入、整理和管理;(3)掌握描述性统计分析和推断性统计分析的基本方法;(4)能够运用SPSS进行实际项目数据分析。
3.培训内容:根据培训目标,设计培训内容如下:(1)SPSS软件概述:介绍SPSS的发展历程、功能特点和应用领域;(2)SPSS基本操作:讲解SPSS的界面布局、菜单功能、数据视图和变量视图的操作;(3)数据管理:介绍数据录入、导入、整理和管理的方法;(4)描述性统计分析:讲解均值、标准差、频数、交叉表等描述性统计量的计算和应用;(5)推断性统计分析:介绍t检验、方差分析、相关分析、回归分析等推断性统计方法;(6)案例分析:通过实际案例,演示SPSS在数据分析中的应用。
三、培训实施1.培训方式:采用线下集中授课的方式进行,共计10个课时,每个课时2小时。
2.培训师资:邀请具有丰富SPSS教学经验的统计学专业教师进行授课。
3.培训教材:选用《SPSS统计分析与应用》一书作为教材,结合实际案例进行讲解。
4.培训过程:(1)第一课时:SPSS软件概述,介绍SPSS的发展历程、功能特点和应用领域;(2)第二课时:SPSS基本操作,讲解SPSS的界面布局、菜单功能、数据视图和变量视图的操作;(3)第三课时:数据管理,介绍数据录入、导入、整理和管理的方法;(4)第四课时:描述性统计分析,讲解均值、标准差、频数、交叉表等描述性统计量的计算和应用;(5)第五课时:推断性统计分析(一),介绍t检验、方差分析的基本原理和应用;(6)第六课时:推断性统计分析(二),介绍相关分析、回归分析的基本原理和应用;(7)第七课时:案例分析(一),通过实际案例,演示SPSS 在描述性统计分析中的应用;(8)第八课时:案例分析(二),通过实际案例,演示SPSS 在推断性统计分析中的应用;(9)第九课时:实操练习,学员根据所学内容,进行SPSS实操练习;(10)第十课时:总结与答疑,对培训内容进行总结,解答学员疑问。
spss数据分析报告案例
SPSS数据分析报告案例1. 研究背景本研究旨在调查大学生是否存在晚睡现象,并探究晚睡与健康问题之间的关系。
通过采集大学生的睡眠时间、就寝时间以及健康状况等数据,利用SPSS软件进行数据分析,进一步了解大学生的睡眠状况与健康问题的关联。
2. 数据概况本研究共收集了200名大学生的数据,其中包括性别、年级、每晚睡眠时间、平均就寝时间、是否存在健康问题等变量。
下面是对数据的描述统计分析结果:•性别分布:男性占50%,女性占50%。
•年级分布:大一占25%,大二占30%,大三占25%,大四占20%。
•每晚睡眠时间:平均睡眠时间为7.8小时,标准差为1.2小时。
最小值为5小时,最大值为10小时。
•平均就寝时间:平均就寝时间为23:30,标准差为0.5小时。
最早就寝时间为22:00,最晚就寝时间为01:00。
•健康问题:共有45%的大学生存在健康问题。
3. 数据分析结果3.1 性别与睡眠时间的关系首先,我们探究性别与睡眠时间之间的关系。
利用独立样本T检验,得出以下的结果:•假设检验:男性和女性的睡眠时间是否存在显著差异?•结果:独立样本T检验显示,男性平均睡眠时间为7.6小时,女性平均睡眠时间为8.0小时。
T值为-2.14,P值为0.034,意味着男性和女性的睡眠时间存在显著差异。
3.2 年级与睡眠时间的关系我们进一步探究年级与睡眠时间的关系。
使用单因素方差分析(ANOVA),得出以下结果:•假设检验:各年级的睡眠时间是否存在显著差异?•结果:单因素方差分析显示,大一、大二、大三和大四的平均睡眠时间分别为7.7小时、7.9小时、8.1小时和7.6小时。
F值为2.75,P值为0.043,说明各年级之间的睡眠时间存在显著差异。
3.3 睡眠时间与健康问题的关系最后,我们分析睡眠时间与健康问题之间的关系。
利用相关分析,得出以下结果:•假设检验:睡眠时间与健康问题之间是否存在相关性?•结果:相关分析结果显示,睡眠时间和健康问题之间存在显著负相关(r = -0.25,P值 = 0.001),即睡眠时间越少,存在健康问题的可能性越大。
spss案例分析
1、某班共有28个学生,其中女生14人,男生14人,下表为某次语文测验的成绩,请用描述统计方法分析女生成绩好,还是男生成绩好。
方法一:频率分析(1) 步骤:分析→描述统计→频率→女生成绩、男生成绩右移→统计量设置→图表(直方图)→确定 (2) 结果:统计量女生成绩男生成绩N有效 1515 缺失73 73 均值 69.9333 67.0000 中值 71.0000 72.0000 众数 76.00a48.00a标准差 8.91601 14.53567 方差 79.495 211.286 全距 30.00 46.00 极小值 54.00 43.00 极大值 84.00 89.00 和1049.001005.00a. 存在多个众数。
显示最小值(3)分析:由统计量表中的均值、标准差及直方图可知,女生成绩比男生成绩好。
方法二:描述统计(1)步骤:分析→描述统计→描述→女生成绩、男生成绩右移→选项设置→确定(2)结果:(3)分析:由描述统计量表中的均值、标准差、方差可知,女生成绩比男生成绩好。
2、某公司经理宣称他的雇员英语水平很高,现从雇员中随机随出11人参加考试,得分如下:80、81、72、60、78、65、56、79、77、87、76,请问该经理的宣称是否可信?(1)方法:单样本T检验H 0:u=u,该经理的宣称可信H 1:u≠u,该经理的宣称不可信(2)步骤:①输入数据:(80,81,…76)②分析→比较均值→单样本T检验→VAR00001右移→检验值(75)→确定(3)结果:单个样本统计量N 均值标准差均值的标准误VAR00001 11 73.73 9.551 2.880(4)分析:由单个样本检验表中数据知t=0.668>0.05,所以接受H,即该经理的宣称是可信的。
3、某医院分别用 A 、B 两种血红蛋白测定仪器检测了16名健康男青年的血红蛋白含量(g/L ),检测结果如下。
问:两种血红蛋白测定仪器的检测结果是否有差别?仪器A :113,125,126,130,150,145,135,105,128,135,100,130,110,115,120 ,155仪器B :140,150,138,120,140,145,135,115,135,130,120,133,147,125,114,165(1)方法:配对样本t 检验H 0:u 1=u 2,两种血红蛋白测定仪器的检测结果无差别 H 1:u 1≠u 2,两种血红蛋白测定仪器的检测结果有差别(2)步骤:①输入两列数据:A 列(113,125,…155);B 列(140,125,…165);②分析→比较均值→配对样本t 检验→仪器A 、仪器B 右移→确定(3)结果:成对样本统计量均值 N标准差 均值的标准误对 1仪器A 126.38 16 15.650 3.912 仪器B134.501613.7703.442(4)分析:由成对样本检验表的Sig 可见t =0.032小于0.05,所以拒绝H 0,即两种血红蛋白测定仪器的检测结果有差别。
spss案例大数据分析报告
spss案例大数据分析报告SPSS 案例大数据分析报告在当今数字化时代,数据已成为企业和组织决策的重要依据。
通过对大量数据的分析,可以揭示隐藏在其中的规律和趋势,为决策提供有力支持。
本报告将以一个具体的案例为例,展示如何使用 SPSS 进行大数据分析。
一、案例背景本次分析的对象是一家电商企业的销售数据。
该企业在过去一年中积累了大量的销售记录,包括商品信息、客户信息、订单金额、购买时间等。
企业希望通过对这些数据的分析,了解客户的购买行为和偏好,优化商品推荐和营销策略,提高销售业绩。
二、数据收集与整理首先,从企业的数据库中提取了相关数据,并进行了初步的清理和整理。
删除了重复记录和缺失值较多的字段,对数据进行了标准化处理,使其具有统一的格式和单位。
在整理数据的过程中,发现了一些问题。
例如,部分客户的地址信息不完整,部分商品的分类存在错误。
通过与相关部门沟通和核实,对这些问题进行了修正和补充。
三、数据分析方法本次分析主要采用了以下几种方法:1、描述性统计分析计算了数据的均值、中位数、标准差、最大值、最小值等统计指标,以了解数据的集中趋势和离散程度。
2、相关性分析分析了不同变量之间的相关性,例如商品价格与销量之间的关系,客户年龄与购买金额之间的关系。
3、聚类分析将客户按照购买行为和偏好进行聚类,以便更好地了解客户群体的特征。
4、因子分析提取了影响客户购买行为的主要因素,为进一步的分析和建模提供基础。
四、数据分析结果1、描述性统计分析结果商品的平均价格为_____元,中位数为_____元,标准差为_____元。
销量的最大值为_____件,最小值为_____件,均值为_____件。
客户的平均年龄为_____岁,中位数为_____岁,标准差为_____岁。
购买金额的最大值为_____元,最小值为_____元,均值为_____元。
2、相关性分析结果商品价格与销量之间呈现负相关关系,相关系数为_____。
这表明价格越高,销量越低。
spss案例分析报告精选文档
s p s s案例分析报告精选文档TTMS system office room 【TTMS16H-TTMS2A-TTMS8Q8-S p s s分析身高与体重的相互影响一、案例介绍:这是某幼儿园学生的身高体重数据,数据中主要包括编号,学生姓名,性别,学生年龄,每个学生的体重以及身高数值。
主要是看下幼儿园学生体重与身高的相互关系。
二、研究案例的目的:分析幼儿园学生身高体重的相互关系和影响。
三、下面是数据来源:四、研究的方法:主要是使用spss中的描述统计分析和线性回归分析;在描述统计分析中主要是分析出身高体重的最大值和最小值、均值,在图表中可以看出身高的最大值;在线性回归分析中主要是采用身高为自变量,体重为因变量来进行分析的。
五、研究的结果:1)描述分析:打开文件“某班23名同学的身高、体重、年龄数据”,通过菜单兰中的分析选项,进行描述性分析,选择体重和身高,求最大值最小值和均值,得到如下结果:从结果看出,该班学生样本数为23,体重最小值为13.7kg,最大值为23kg,平均体重为17.7167kg。
身高最小值为105cm,最大值为116cm,平均身高为108.85cm。
以身高为例子,选择描述中的频率选项可以得出分布,在频率对话框的图形选项中,选择条形图,即可用图形直观看到结果。
从图形中可以很直观的看出不同身高段的人数分布情况,其中108cm左右的人数最多。
从表格中则可以清楚地看到具体数目。
2)线性回归分析:选择分析——回归——线性,在弹出的对话框中,以身高作为自变量,体重作为因变量,结果如下:从表中可以得出。
R=0.223,即两者具有弱相关性。
从图表中,可以看出它们之间的线性关系大概可以表示为y=-0.139x+2.617 六、研究结论:从描述分析和回归分析可以身高和体重的相关性是相对比较弱的,也就是弱相关性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
某道路弯道处 53 车辆减速前观测到的车辆运行速度,试检验车辆运行速度是否服从正态分布。
这道题目的解答可以先通过绘制样本数据的直方图、P-P 图和Q-Q 图坐车粗略判断,然后利用非参数检验的方法中的单样本K-S 检验精确实现。
一、初步判断1.1绘制直方图(1)操作步骤在SPSS 软件中的操作步骤如图所示。
2)输出结果通过观察速度的直方图及其与正态曲线的对比,直观上可以看到速度的直方图与正太去线除了最大值外,整体趋势与正态曲线较吻合,说明弯道处车辆减速前的运行速度有可能符合正态分布。
1.2绘制P-P 图1)操作步骤在SPSS 软件中的操作步骤如图所示。
2)结果输出根据输出的速度的正态P-P 图,发现速度均匀分布在正态直线的附近,较多部分与正态直线重合,与直方图的结果一致,说明弯道处车辆减速前的运行速度可能服从正态分布。
二、单样本K-S 检验2.1单样本K-S 检验的基本思想K-S 检验能够利用样本数据推断样本来自的总体是否服从某一理论分布,是一种拟合优的检验方法,适用于探索连续型随机变量的分布。
单样本K-S 检验的原假设是:样本来自的总体与指定的理论分布无显著差异,即样本来自的总体服从指定的理论分布。
SPSS 的理论分布主要包括正态分布、均匀分布、指数分布和泊松分布等。
单样本K-S 检验的基本思路是:首先,在原假设成立的前提下,计算各样本观测值在理论分布中出现的累计概率值F(x),;其次,计算各样本观测值的实际累计概率值S(x);再次,计算实际累计概率值与理论累计概率值的差D(x);最后,计算差值序列中的最大绝对值差值,即D = maxS(x)- F(x i)i通常,由于实际累计概率为离散值,因此D 修正为:D = maxS(x)- F(x)D 统计量也称为K-S 统计量。
在小样本下,原假设成立时,D 统计量服从Kolmogorov 分布。
在大样本下,原假设成立时,nD近似服从K(x)分布:当D 小于0时,K(x)为0;当D大于0时,K(x)= ( - 1)exp( - 2j2x2)j= -容易理解,如果样本总体的分布与理论分粗的差异不明显,那么D 不应较大。
如果 D 统计量的概率P 值小于显著性水平α,则应拒绝原假设,认为样本来自的总体与指定的分布有显著差异如果D 统计量的P 值大于显著性水平α,则不能拒绝原假设,认为,样本来自的总体与指定的分布无显著差异。
在SPSS 中,无论是大样本还是小样本,仅给出大样本下的和nD 对应的概率P 值。
2.2 软件操作步骤单样本 K-S 检验的操作步骤如图所示2.3 输出结果并分析SPSS 的输出结果如表所示.单样本速度N98 正态参数a,b均值 47.988 标准差 11.6310绝对值.090 最极端差别正.050负-.090 Kolmogorov-Smirnov Z .888 渐近显著性(双侧).409a. b. 根据数据计算得到。
该表表明,速度的均值为47.988,标准差为11.6310。
最大绝对差值为0.090,最大正差 值为0.050,最大负差值为-0.090。
本例应采用大样本下D 统计量的精确概率值,输出了根 号nD值0.888和概率P值0.409,如果显著性水平为0.05,由于概率P值大于显著性水平,因此不能拒绝原假设,可以认为弯道处车辆减速前的运行速度服从正态分布。
第13题表中数据为某条公路上观测到的交通流速度与密度数据,试用一元线性回归模型分析两者的 101关系。
一、一元线性回归的基本原理1.1一元线性回归模型:Y =0 +1+~ N(0,2)上述模型可分为两部分:(1) +是非随机部分;(2)是随机部分。
β0和β1为回归常熟和回归系数该式被称为估计的一元线性回归方程。
1.2模型参数估计用最小二乘法估计参数,是在关于随机误差的正态性、无偏性、同方差性、独立性这四个假设的基础上进行的。
f ( x i ) = y i - y i = ( y i -b0-b1x i)2=min为了求回归系数,0 ,1,令一阶导数为0 ,得:nb0 + b1x i = y ib0 x i +b1x i2=x i y i从中解出:(x i-x)(y i-y)(x i - x)b0=y -b1x二、一元线性回归分析的假设检验:n_n ^_n ^SST =(y i - y)2=(y i- y)2+(y i - y)2= SSR + SSEi=1 i =1 i=1其中:SST称为总体离差平方和,代表原始数据所反映的总偏差的大小。
SSR 称为回归离差平方和,它是由变量 x 引起的偏差,反应 x 的重要程度SSE 称为剩余离差平方和,它是由实验误差以及其它未加控制因素引起的偏差,反映了试验误差及其它随机因素对试验结果的影响。
2.1 回归方程优度检验的2 SSR SSER =SST =1-SST相关系数反映了由于使用Y与X之间的线性回归模型来估计y的均值,而导致总离差平方和减少的程度。
它与SSR成正比,R2的取值在0-1之间,其值越接近1,说明方程对样本数据点的拟合度越高;反之,其越接近0说明,明模型的拟合度越低。
2.2回归方程的显著性检验假设H0: 1= 0, H1:10。
在H0成立的条件下,有:SSR/nF=SSE /n(n1+n2= n-1)上式中,n1 =1,n2=n-2,F服从自由度为(1,n-2)的F分布。
给定显著水平,若F F(n1,n2),拒绝原假设,表明回归效果显著。
2.3回归系数的显著性检验在H0成立的条件下,有:^t =^L xx : t(n-2)当t t(n - 2)时,拒绝原假设,回归显著。
2 注意:注意回归方程的显著性检验与回归系数的显著性检验的的区别:回归系数的显著性检验是用于检验回归方程各个参数是否显著为0的单一检验,回归方程的显著性检验是检验所有解释变量的系数是否同时为0的联合检验,分别为t检验FF检验。
对于一元线性回归模型,F检验与t检验是等价的,而对于二元以上的多元回归模型,解释变量的整体对被解释变量的影响是显著的,并不表明每一个解释变量对它的影响都显著,因此在做完F检验后还须进行t检验。
2.4残差均值为零的正态性分析,进行一元线性回归建模的前提是残差ε~N(0,δ2)。
而结实变量x 去某个特定的值是,对应的残差必然有证有负,但总体上应服从已领为君值得正态分布。
可以通过绘制残插图对该问题进行分析。
残插图是一种散点图,途中横坐标是结实变量,纵坐标为残差。
如果残差的均值为零,则残插图中的点应在纵坐标为零的横线上、下随机散落。
三、软件操作一元线性回归的软件操作步骤如图所示。
四、输出结果SPSS 的输出结果如表所示。
ba. 预测变量:b. 因变量: 速度该表中格列数据的含义(从第二列开始)依次是:被解释变量和解释变量的负相关系数、判定系数R2 、调整的系数R2 、回归方程的估计标准误差。
依据该表可以进行拟合优度检验。
由于判定系数R2 较接近1,因此认为拟合优度较高,被解释变量可以被模型解释的部分较多,不能被模型解释的部分较少。
ba.b. 因变量: 速度该表各项数据的含义(从第一列开始)依次为:被解释变量的表差来源,离差平方和。
自由度、方程、回归方程显著性检验中 F 检验统计量的观测值和概率P 值。
由表可知,F 检验统计量的观测值为,369.56,对应的概率P值为0.000。
如果显著性水平取0.05,由于概率P 值小于显著性水平,所以应该拒绝原假设,认为,被解释变量与及时变量的线形关系是显著的,可以建立线性模型。
aa. 因变量该表中各列数据的含义(第二列开始)依次为:偏回归系数,偏回归系数的标准误差,标准化偏回归系数、回归系数显著性检验中t检验统计量的观测值、对应的概率P值。
从表中可以看出,产量和密度对应的概率P值均为0.000。
若取显著性水平为0.05,则应拒绝原假设,认为密度与速度的线性关系显著。
aa. 因变量该表中可以看出,残差和标准残差的均值均为0,符合残差均值为零的正态性分析。
综上,该公路上速度与密度的一元线性回归模型为:V = -8.393K + 153.344,其中,V表示速度,K表示密度。
第17题为了分析双车道公路上驾驶人超车行为及其影响因素,应用超车试验研究了超车过程中同向的车流间隙对驾驶人换车道的影响。
此次试验共采集到有效样本数据 342 条,表中给出了部分试验数据整理结果。
请用logistic 回归模型标定出换道行为模型。
本题可采用二元logistic 回归分析对换道行为进行标定。
一、二元Logistic 回归基本原理当被解释变量为0/1 二分类变量时,虽然无法直接采用一般线性回归模型建模,但可充分借鉴其理论模型和分析思路。
利用一般线性回归模型对被解释变量取值为1的概率进行建模,此时回归方程被解释变量的实际取值范围在0~1 之间。
回归方程的一般形式为:P y=1 = 0 + 1x现将P 转换为=1-p p对对两边取对数,并建立被解释变量与解释变量之间的多元分析模型,即kpp )= 0 + i x iln(1-pi=1于是有P =k1 + exp ( -(0+ i x i)) i=1该式即被解释变量预测为1 类的模型。
二、软件操作二元logistic 回归模型的SPSS 操作如图所示。
操作中,对换道行为进行了分类设置:超车成功=1,超车失败=2。
、结果输出a. 模型中包括常量。
b. 切割值为 .5该表显示了logistic 分析初级阶段(第0 步,方程中只有常数项,其他回归系数约束为0),的混淆矩阵。
可以看待,有 4 人超车失败但模型预测错误,正确率为0%,有8 人超车成功模型预测正确,正确率为100%。
模型总的预测正确率为66.7%。
该表为方层中只有常数项时回归系数方面的指标,由于此时模型中未包含任何解释变量,该表并没有实际意义。
该表显示了待进入方程的各解释变量的情况。
可以看到,下一波速度。
车头间距和车头时距进入方程,则Score 检验统计量的鬼厕纸和概率P 值分别依次是10.170、0.001,0.568、0.451,3.210,0.073。
如果显著性水平为0.05,则由于车头间距和车头时距的概率P 值大于显著性水平,所以不能进入方程。
aa. 切割值为 .5002) 因此将车头间距和车头时距移除,再看该分类表,模型的预测率为 100%。
从而车辆 环岛行为模型的标定仅与行车速度有关。
从而得到换到行为的logistic 回归模型标定结果ln(1 -p p )= 4.729 - 145.071V (1)11 + exp ( -(4.729 - 145.071V ))则式(2)为超车成功的标定模型,其中,V 为行车速度。
P =。