华理计量经济学第二次实验报告
计量经济学实验报告二

学生实验报告学院:经济学院课程名称:计量经济学专业班级:11经济学1班姓名:魏丹丹学号:0112102学生实验报告(经管类专业用)一、实验目的及要求:1、目的利用Eviews软件,使学生在实验过程中全面了解和熟悉计量经济学。
2、内容及要求熟悉Eviews软件的操作与应用二、仪器用具:三、实验方法与步骤:1 经研究发现,家庭书刊消费受家庭收入几户主受教育年数的影响,表中为对某地区部分家庭抽样调查得到样本数据:(2)利用样本数据估计模型的参数;(3)检验户主受教育年数对家庭书刊消费是否有显着影响;(4)分析所估计模型的经济意义和作用答:(1)家庭书刊消费的计量经济学模型是:Dependent Variable: YMethod: Least SquaresDate: 11/27/12 Time: 14:36Sample: 1 18Included observations: 18Variable Coefficient Std. Error t-Statistic Prob.??C -50.01638 49.46026 -1.011244 0.3279X 0.086450 0.029363 2.944186 0.0101T 52.3703 5.202167 10.06702 0.00001R-squared 0.951235 ????Mean dependentvar755.1222Adjusted R-squared 0.944732 ????S.D. dependentvar258.7206S.E. of regression 60.82273 ????Akaike infocriterion11.20482Sum squared resid 55491.07 ????Schwarz criterion11.35321Log likelihood -97.84334 ????F-statistic146.2974Durbin-Watson stat2.605783 ????Prob(F-statistic)0.00000=^Y -50.0163+0.0865X+52.3703T 标准误 49.4603 0.0294 5.2022 t 值 -1.0112 2.9442 10.0670 p 值 0.3279 0.0101 0.0000 R 2=0.9512 =2R 0.9447总体显着性的F 统计值为146.2974,F 统计量的p 值:0.0000 (2)样本数据估计的模型参数为β1=0.0865,β2=52.3703(3)由回归结果得:户主受教育年限的p 值为0.0000,小于0.05,则拒绝原假设。
(完整word版)计量经济学实践报告 2

课程名称:课程名称:计量经济学学生姓名:阳诗琪学号:201174250203班级: 1102班专业:金融学2013 年 5 月 5日计量经济学实验报告多元回归模型实验【实验目标】:通过上机实验,使学生能够使用 Eviews 软件【实验内容】:1.用Eviews完成多元线性回归模型的统计检验2.对Eviews结果对应的相关统计检验进行解释【实验步骤及分析】:1、经济理论理论上认为影响成品钢材的需求量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。
产量、原煤产量1980——1998年的有关数据如下表。
年份成品钢材(万吨)y 原油(万吨)x1生铁(万吨)x2原煤(亿吨)x3发电量(亿千瓦)x4铁路货运量(万吨)x5固定资产投资额(亿元)x6居民消费(亿元)x71980 2716.2105953802.4 6.23006.2111279 910.92317.1 1981 2670.1101223416.6 6.23092.107673 9612604.12、模型估计多元线性回归模型的基本形式:设随机变量y 与一般变量x 1,x 2,...x p 的理论线性回归模型为:y=εββββ+++++p p x x x (22110)其中β1,β2,。
,βp 是p+1个未知参数,β0称为回归常数,β1,β2,。
,βp 称为回归系数。
y 称为被解释变量(因变量),而x 1,x 2,...x p 是p 个可以精确测量并可控制的一般变量,称为解释变量(自变量)。
ε是随机误差。
3、画散点图1982 2902 10212 3551 6.66 3277 11349 1230.4 2867.9 1983 3072 10607 3738 7.15 3514 118784 1430.1 3182.5 1984 3372 11461.3 4001 7.89 3770 124074 1832.9 3674.5 1985 3693 12489.5 4384 8.72 4107 130709 2543.2 4589 1986 4058 13068.8 5064 8.94 4495 135635 3120.6 5175 1987 4356 13414 5503 9.28 4973 140653 3791.7 5961.2 1988 4689 13704.6 5704 9.8 5452 144948 4753.8 7633.1 1989 4859 13764.1 5820 10.54 5848 151489 4410.4 8523.5 1990 5153 13830.6 6238 10.8 6212 150681 4517 9113.2 1991 5638 14009.2 6765 10.87 6775 152893 5594.5 10315.9 1992 6697 14209.7 7589 11.16 7539 157627 8080.1 12459.8 1993 7716 14523.7 8739 11.51 8395 162663 13072.3 15682.4 1994 8482 14608.2974112.49281 163093 17042.1 20809.8 1995 8979.8 15004.94 10529.27 13.61 10070.3 165885 20019.3 26944.5 1996 9338.02 15733.39 10722.513.9710813.116880322974 32152.3 1997 9978.9316074.14 11511.41 13.73 11355.53 16973422913.534854.64、建立模型将原始数据导入到Eviews6.0(破解版)的数据框中,然后用Eviews软件做线性回归分析如下:在Eviews主窗口菜单单击Quick/Estimate Equation,弹出方程估计窗口,再在弹出的窗口清单内填入以下回归方程的书写形式。
《计量经济学》课程实验报告
《计量经济学》课程实验报告年级专业:2012级金融学姓名:*** 学号:2012******一、实验目的1.学会Eviews工作文件的建立、数据输入、数据的编辑和描述;2.掌握用Eviews软件通过阿尔蒙多项式变换法估计分布滞后模型。
二、实验内容根据某地区1980-2001年固定资产投资Y与销售额X的资料,取阿尔蒙多项式的次数M=2,阿尔蒙多项式变换法估计分布滞后模型:错误!未找到引用源。
,将系数错误!未找到引用源。
(i=0,1,2,3,4)用二次多项式近似,则原模型可变为:错误!未找到引用源。
,由此用Eviews软件得出分布滞后模型的最终估计式。
三、实验数据教材第186页,表7.5:某地区1980-2001年固定资产投资Y与销售额X的资料四、实验步骤1.分析固定资产投资Y与销售额X的关系;2.模型设定:错误!未找到引用源。
;将系数错误!未找到引用源。
(i=0,1,2,3,4)用二次多项式近似,则原模型可变为:错误!未找到引用源。
;3.用Eviews计算错误!未找到引用源。
(i=0,1,2,3,4)。
步骤如下:(1)建立工作文件:双击Eviews图标,进入Eviews主页。
在菜单选项中依次点击New—Workfile,出现“Workfile Range”。
在““Workfile Frequency”中选择数据频率“Annual”,并在“Start Date”菜单中输入“1980”,在“End”菜单中输入“2001”,点击“OK”,出现未命名文件的“Workfile UNTITLED”工作框。
已有对象“c”为截距项,“resid”为剩余项。
(2)输入数据:在“Quick”菜单中点击“Empty Group”,出现数据编辑窗口。
将第一列命名为“Y”:方法是按上行键“↑”,对应“obs”格自动上跳,在对应的第二行有边框的“obs”空格中输入变量名为“Y”,再按下行键“↓”,变量名一下各格出现“NA”,依次输入Y的对应数据。
计量经济学实验报告_学习总结_总结汇报_实用文档

目录(一) 研究背景 (2)(二) 理论来源 (2)(三) 模型设定 (2)(四) 数据处理 (2)1. 数据来源 (2)2. 解释变量的设置 (3)(五) 先验预期 (3)1.经验预期 (3)2.散点图分析 (3)(六) 参数估计 (4)(七) 显著性检验 (5)(八) 正态性检验 (5)(九) MWD检验 (5)(十) 相关系数 (7)(十一)虚拟变量 (7)(十二)异方差检验、修正 (8)1. 图形检验 (8)2.格莱泽检验 (9)3.帕克检验 (10)4.异方差的修正加权最小二乘法 (10)5.异方差修正后的检验 (11)(十三)自相关检验 (11)1. 图形法 (11)2.德宾-沃森d检验 (12)(十四)最终结果 (12)(一)研究背景中国是一个大国,幅员辽阔,历史上自然地形成了一个极端不平衡发展的格局。
而1978年开始的改革,政府采取了由东向西梯度推进的非均衡发展战略,使已经存在的地区间的差距进一步扩大,不利于整个社会的稳定和发展。
地区发展不平衡问题包括社会发展不平衡,尤其是教育发展的不平衡。
因此关注中国教育发展的地区不平衡性非常迫切。
不仅是因为教育的重要性,还因为当前我国需要进一步推进教育改革的进程,使其朝着更健康的方向发展。
(二)理论来源刘红梅.中国各地区教育发展水平差异的实证分析[J]数理统计与管理.2013.7(三)模型设定⏹Y i=B1+B2X2i+B3X3i+B4X4i+B5X2i 2+B6X4i2+ui⏹Y——地区教育水平,用平均受教育年限表示,(年)⏹X2——学生平均预算内教育经费,(万元/人)⏹X3——人均GDP,(万元/人)⏹X4——平均生师比(四)数据处理1.数据来源:国家统计局官网,选取2014年的数据:1)各省GDP2)各地区总人口3)各地区每十万人拥有的各种受教育程度人口比较数据4)地区在校总学生数5)各地区教育财政投入6)地区每十万总专任教师数2.解释变量的设置:⏹X2=地区预算内教育经费/地区在校总学生数=学生平均预算内教育经费(万元/人)⏹X3=地区总GDP/地区总人口=人均GDP(万元/人)⏹X4=地区每十万人口各级学校平均在校生数的和/地区每十万人口总专任教师数=平均生师比其中:P为各地区每十万人拥有的各种受教育程度人口比较数T为教育年限1,6,9,12,16(五)先验预期1.经验预期:平均受教育年限分别跟学生平均预算内教育经费、人均GDP呈正相关关系,跟平均生师比呈负相关关系。
《计量经济学》实训报告内容

进一步检查是否存在异方差,倘若存在,更改权重 (例如,残差项平方的倒数作为权重)
2019/2/14 4
第二次实训内容:对时间序列数据 进行线性回归
• 基本步骤
建立数据文件 Quick-Equation Estimation-输入计量模型
2019/2/14
5
• 如何防止多重共线性?
相关性分析(View-Covariance Analysis) 解决方法:排除变量法、差分法(在时间序列 数据、面板数据中使用)
2019/2/14
6
• 如何防止序列相关性?
在回归方程中加入ar(1)、ar(2)……,检验D.W. 值是否接近于2
2019/2/14
7
第三次实训内容:对面板数据进行 线性回归
• 基本步骤
建立数据文件
如何防止多重共线性?略。
一般不考虑异方差性和序列相关性。
2019/2/14
8
Estimate,在Specification中输入被解释变量 (加一个问号),在cross-section中选择 random;在Common coefficents中各自变 量(每个自变量后面加一个问号,并且用空格 隔开),点击确定。 固定效应和随机效应的选择:ViewFixed/Random Effect Testing-Correlated Random Effects-Hausman Test,倘若 Cross-section random的伴随概率小于0.1, 那么运用固定效应,否则运用随机效应。
计量经济学实验报告
多重共线性模型的检验和处理实验目的:掌握多重共线性模型的检验和处理方法。
实验要求:了解辅助回归检验,解释变量相关系数检验等。
试验用软件:Eviews实验原理:解释变量相关系数检验和辅助回归检验等。
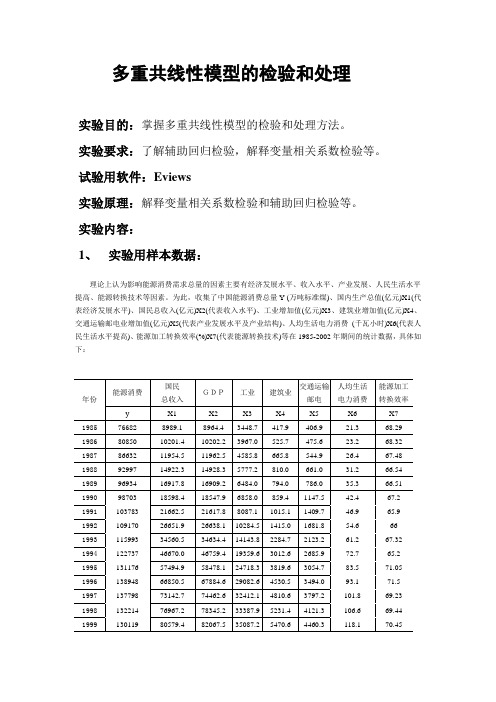
实验内容:1、实验用样本数据:理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。
为此,收集了中国能源消费总量Y (万吨标准煤)、国内生产总值(亿元)X1(代表经济发展水平)、国民总收入(亿元)X2(代表收入水平)、工业增加值(亿元)X3、建筑业增加值(亿元)X4、交通运输邮电业增加值(亿元)X5(代表产业发展水平及产业结构)、人均生活电力消费(千瓦小时)X6(代表人民生活水平提高)、能源加工转换效率(%)X7(代表能源转换技术)等在1985-2002年期间的统计数据,具体如下:资料来源:《中国统计年鉴》2004、2000年版,中国统计出版社。
实验要求:(1)建立对数线性多元回归模型(2)如果决定用表中全部变量作为解释变量,你预料会遇到多重共线性的问题吗?为什么?(3)如果有多重共线性,你准备怎样解决这个问题?明确你的假设并说明全部计算。
2、实验步骤:建立对数线性多元回归模型设模型的函数形式为:Y=β+β1X1+β2X2+β3X3+β4X4+β5X5+β6X6+β7X7+u运用OLS估计方法对上式中的参数进行估计,EViews过程如下1、参数估计:(1)点击“File/New/Workfile”,屏幕上出现Workfile Range对话框,在Start date里键入1985,在End date里键入2002,点击OK后屏幕出现“Workfile对话框(子窗口)”。
(2)方法一:在Objects菜单中点击New objects,在New objects选择Group,并在Name for Objects定义文件名,点击OK出现数据编辑窗口,,按顺序键入数据。
计量经济学实验报告

计量经济学实验报告计量经济学实验基于EViews的中国能源消费影响因素分析学院:班级:学号:姓名:基于EViews的中国能源消费影响因素分析⼀、背景资料能⽤消费是引是指⽣产和⽣活所消耗的能源。
能源消费按⼈平均的占有量是衡量⼀个国家经济发展和⼈民⽣活⽔平的重要标志。
能源是⽀持经济增长的重要物质基础和⽣产要素。
能源消费量的不断增长,是现代化建设的重要条件。
我国能源⼯业的迅速发展和改⾰开放政策的实施,促使能源产品特别是⽯油作为⼀种国际性的特殊商品进⼊世界能源市场。
随着国民经济的发展和⼈⼝的增长,我国能源的供需⽭盾⽇益紧张。
同时,煤炭、⽯油等常规能源的⼤量使⽤和核能的发展,⼜会造成环境的污染和⽣态平衡的破坏。
可以看出,它不仅是⼀个重⼤的技术、经济问题,⽽且以成为⼀个严重的政治问题。
在20世纪的最后⼆⼗年⾥,中国国内⽣产总值(GDP)翻了两番,但是能源消费仅翻了⼀番,平均的能源消费弹性仅为0.5左右。
然⽽⾃2002年进⼊新⼀轮的⾼速增长周期后,中国能源强度却不断上升,经济发展开始频频受到能源瓶颈问题的困扰。
鉴于此,研究能源问题不仅具有必要性和紧迫性,更具有很⼤的现实意义。
由于我国⽬前⾯临的所谓“能源危机”,主要是由于需求过⼤引起的,⽽我国作为世界上最⼤的发展中国家,⼈⼝众多,所需能源不可能完全依赖进⼝,所以,研究能源的需求显得更加重要。
⼆、影响因素设定根据西⽅经济学消费需求理论可知,影响消费需求的因素有:商品的价格、消费者收⼊⽔平、相关商品的价格、商品供给、消费者偏好以及消费者对商品价格的预期等。
对于相关商品价格的替代效应,我们认为其只存在能源品种内部之间,⽽消费者偏好及消费者对商品价格的预期数据差别较⼤,不容易进⾏搜集整理在此暂不涉及。
另外,发展经济学认为,来⾃知识、⼈⼒资本的积累⽔平所体现的技术进步不仅可以带动劳动产出的增长,⽽且会通过外部效应可以提⾼劳动⼒、⾃然资源、物质资本与⽣产要素的⽣产效率,消除其中收益递减的内在联系,带来递增的规模收益。
2021年计量经济学实验报告2

1.背景经济增加是指一个国家生产商品和劳务能力扩大。
在实际核实中, 常以一国生产商品和劳务总量增加来表示, 即以国民生产总值(GDP )和中国生产总值增加来计算。
古典经济增加理论以社会财富增加为中心, 指出生产劳动是财富增加源泉。
现代经济增加理论认为知识、 人力资本、 技术进步是经济增加关键原因。
从古典增加理论到新增加理论, 都重视物质资本和劳动贡献。
物质资本是指经济系统运行中实际投入资本数量.然而, 因为资本服务流量难以测度, 在这里我们用全社会固定资产投资总额(亿元)来衡量物质资本。
中国拥有十三亿人口, 为经济增加提供了丰富劳动力资源。
所以本文用总就业人数(万人)来衡量劳动力。
居民消费需求也是经济增加关键原因。
经济增加问题既受各国政府和居民关注,也是经济学理论研究一个关键方面。
在1978—31年中,中国经济年均增加率高达9.6%,综合国力大大增强,居民收入水平与生活水平不停提升,居民消费需求数量和质量有了很大提升。
不过,中国现在仍然面临消费需求不足问题。
本文将以中国经济增加作为研究对象, 选择时间序列数据计量经济学模型方法, 将中国中国生产总值与和其相关经济变量联络起来, 建立多元线性回归模型, 研究中国中国经济增加变动趋势, 以及关键影响原因, 并依据所得结论提出相关提议与意见。
用计量经济学方法进行数据分析将得到愈加含有说服力和愈加具体指标, 能够愈加好帮助我们进行估计与决议。
所以, 对中国经济增加计量经济学研究是有意义同时也是很必需。
2.模型建立 2.1 假设模型为了具体分析各要素对中国经济增加影响大小, 我们能够用中国生产总值(Y )这个经济指标作为研究对象; 用总就业人员数(1X )衡量劳动力; 用固定资产投资总额(2X )衡量资本投入: 用价格指数(3X )去代表消费需求。
利用这些数据进行回归分析。
这里被解释变量是, Y: 中国生产总值,与Y-中国生产总值亲密相关经济原因作为模型可能解释变量, 累计3个, 它们分别为:1X 代表社会就业人数, 2X 代表固定资产投资,3X 代表消费价格指数,μ代表干扰项。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
华东理工大学2016–2017学年第二学期《多元线性回归模型》实验报告实验名称计量经济学第二次实验专业经济152姓名王恺颖学号10151346组名/组号实验时间2017/4/7实验地点机房319指导教师吴玉鸣教师批阅:实验成绩:教师签名:日期:实验报告正文:(包括实验步骤、实验结果、实验过程中出现的问题及解决方法等。
要求做到内容精炼、层次清楚、格式规范。
)3.1(1)建立百户拥有家用汽车量计量经济模型,估计参数并对模型加以检验,检验的结论的依据是什么?实验步骤:先在命令框输入data y x2 x3 x4,并把所需数据粘贴到group中,再输入sort y,把y按升序排列,然后点击view —graph—line。
得到一个百户拥有家用汽车量以及其影响因素的数据图形,如下:可以看出每个影响因素与y的差异明显,变动方向基本相同,有一定相关性,建立模型如下:Y t=β1+β2X2t+β3X3t+β4X4t+μt再点击quick—estimate equation 出现的对话框的equation specification键入ls y c x2 x3 x4 出现回归结果如下图。
1、根据该表数据,模型的估计的结果为:Ŷt=246.8540+5.996865X2−0.524027X3−2.265680X4(51.97500) (1.406058) (0.179280) (0.518837)t=(4.749476)(4.205020)(-2.922950)(-4.366842)R2=0.666062 R̅2=0.628957 F=17.95108 n=31模型检验:1)拟合优度R2=0.666062 R̅2=0.628957,这说明模型对样本的拟合程度较好。
2)F检验:针对H0=β2=β3=β4=0,给定显著性水平α=0.05,在F分布表中查出自由度为k-1=3和n-k=27的临界值Fα(3,27)=2.97由于F=17.95108>Fα(3,27)=2.97 ,所以拒绝原假设,说明回归方程整体显著,即“人均GDP”、“城镇人口比重”、“交通工具消费”联合对“百户人家汽车拥有量”有影响。
3)t检验:分别针对H0:βj=(j=2、3、4),给定显著性水平α=0.05,查t分布表得自由度n-k=27 t0.052(n−k)=2.052而βĵ对应t估计值的绝对值均> t0.052(n−k)=2.052,拒绝原假设,说明“人均GDP”、“城镇人口比重”、“交通工具消费”对“百户人家汽车拥有量”均有显著影响。
(2)经济意义:人均GDP增加一万元,百户拥有家用汽车增加5.996865辆,城镇人口比重增加百分之一,百户拥有家用汽车减少0.524027辆,交通工具消费价格指数上升1,百户拥有家用汽车减少2.265680辆。
(3)改进模型:实验步骤:可以尝试对解释变量或被解释变量取对,比较可决系数,取可决系数最大者。
以下为其中一部分模型结果,比较可得建立以下模型可决系数较大,优于原来的模型。
Y t=β1+β2X2t+β3lnX3t+β4X4t其可决系数为0.689969>0.666,拟合程度比原来好。
3.2.(1)以下是出口货物总额与工业增加值和人民汇率的相关数据和线性图:建立模型:Y t=β1+β2X2t+β3X3t+μt回归分析结果如下:根据该表数据,模型的估计的结果为:Ŷt=−18231.58+0.135474X2+18.85348X3(8638.216) (0.012799) (9.776181)t= (-2.110573)(10.58454)(1.928512)R2=0.985838 R̅2=0.983950 F=522.0976 n=18模型检验:1)拟合优度R2=0.985838 R̅2=0.983950,这说明模型对样本的拟合程度很好。
2)F检验:针对H0=β2=β3=β4=0,给定显著性水平α=0.05,在F分布表中查出自由度为k-1=2和n-k=15的临界值Fα(2,15)=3.68由于F=522.0976>Fα(2,15)=3.68 ,所以拒绝原假设,说明回归方程整体显著,即“工业增加值X2”、“人民币汇率X3”联合对“出口货物总额”有影响。
3)t检验:分别针对H0:βj=(j=2、3),给定显著性水平α=0.05,查t分布表得自由度n-k=15 t0.052(n−k)=2.131而βĵ对应t估计值的绝对值均> t0.052(n−k)=2.052,拒绝原假设,说明“工业增加值X2”、“人民币汇率X3”对“出口货物总额”均有显著影响。
(2)lnY t=α1+α2lnX2t+α3X3t+μt回归结果如下:根据该表数据,模型的估计的结果为:lnŶt=−10.81090+1.573784lnX2+0.002438X3(1.698653) (0.091547) (0.000936)t= (-6.364397)(17.19106)(2.605321)R2=0.986373 R̅2=0.984556 F=542.8930 n=18模型检验:1)拟合优度R2=0.986373 R̅2=0.984556,这说明模型对样本的拟合程度很好。
2)F检验:针对H0=β2=β3=0,给定显著性水平α=0.05,在F分布表中查出自由度为k-1=2和n-k=15的临界值Fα(2,15)=3.68由于F=542.8930 >Fα(2,15)=3.68 ,所以拒绝原假设,说明回归方程整体显著,即“工业增加值X2”、“人民币汇率X3”联合对“出口货物总额”有影响。
3)t检验:分别针对H0:βj=(j=2、3),给定显著性水平α=0.05,查t分布表得自由度n-k=15 t0.052(n−k)=2.131而βĵ对应t估计值的绝对值均> t0.052(n−k)=2.052,拒绝原假设,说明“工业增加值X2”、“人民币汇率X3”对“出口货物总额”均有显著影响。
(3)(1)式中的经济意义:工业增加1亿元,出口货物总额增加0.135474亿元,人民币汇率增加1,出口货物总额增加18.85348。
(2)式中的经济意义:工业增加百分之一,出口货物增加1.573784%,人民币汇率增加1,出口货物总额增加0.002438%。
3.3(1)整理数据以及家庭书刊消费和影响因素图形如下图:建立模型Y t=β1+β2X t+β3T t+μt根据该表数据,模型的估计的结果为:Ŷt=−50.01638+0.086450X2+52.37031T3(49.46026) (0.029363) (5.202167)t= (-1.011244)(2.944186)(10.06702)R2=0.951235 R̅2=0.944732 F=146.2974 n=18模型检验:1)拟合优度R2=0.951235 R̅2=0.944732,这说明模型对样本的拟合程度很好。
2)F检验:针对H0=β2=β3=0,给定显著性水平α=0.05,在F分布表中查出自由度为k-1=2和n-k=15的临界值Fα(2,15)=3.68由于F=146.2974>Fα(2,15)=3.68 ,所以拒绝原假设,说明回归方程整体显著,即“家庭收入”以及“户主受教育年数的影响”联合对“家庭书刊消费”有影响。
3)t检验:分别针对H0:βj=(j=2、3),给定显著性水平α=0.05,查t分布表得自由度n-k=15 t0.052(n−k)=2.131而βĵ对应t估计值的绝对值均> t0.052(n−k)=2.052,拒绝原假设,说明“家庭收入”以及“户主受教育年数的影响”对“家庭书刊消费”均有显著影响。
(2)作家庭书刊消费(Y)对户主受教育年数(T)的一元回归,获得残差E1;再作家庭月平均收入(X)对户主受教育年数(T)的一元回归,并获得残差E2。
以下为家庭书刊消费(Y)对户主受教育年数(T)的一元回归(左)和家庭月平均收入(X)对户主受教育年数(T)的一元回归(右)。
得到残差E1 E2如下残差结果如上图所示,整理为右表。
并且对右表建立无截距项模型E1=α2E2+υi 得到回归结果如下:得到的参数估计式为E1=0.08645E2+2.27E −06α̂2=0.08645(4)α̂2=0.08645 = β̂2=0.08645 它们的变化规律一致。
3.4回归结果要填的空(用红色表示)Dependent Variable: LOG(Y) Method: Least Squares Date: 04/08/17 Time: 15:15 Sample (adjusted): 1978 2007 Included observations:30Variable Coefficient Std. Error t -Statistic Prob. C -2.755637 0.64080 -4.300307 0.002 LOG(X2) 0.451234 0.142129 3.174831 0.0038 LOG(X3) 0.627133 0.161566 3.881590 0.006 X4 0.010137 0.005645 1.795667 0.0842 R -squared 0.987591 Mean dependent var 8.314376 Adjusted R -squared 0.972490 S.D. dependent var 1.357225 S.E. of regression 0.025496 Akaike info criterion -0.707778Sum squared resid 0.662904 Schwarz criterion -0.520952 Log likelihood 14.61680 F -statistic 347.030822 Prob(F -statistic) 0.000000 Durbin -Watson stat 0.616136以下为解题依据:R ̅2(Adjusted R −squared )=1−(1−R 2)n−1n−k =1-(1-0.975336)*(29/26)=0.92490 σ̂2(S.E. of regression )=RSSn−k =0.662904/26=0.025496 F(F -statistic) =n−k k−1·R 21−R 2=(26/3)*(0.987591/1-0.975336)=347.030822t (t -Statistic )=β̂j SE ̂(β̂j ) (Coefficient /Std. Error)同理 SÊ(β̂j )=t/β̂j β̂j =t ∗ SE ̂(β̂j )3.5 方差分析表 由题知k=3 TSS=ESS+RSS=847962.19变差来源 平方和 (SS ) 自由度 (df ) 平方和的均值(MSS ) 来自回归(ESS ) 377067.19 2(k -1) 188533.595 ESS/(k -1) 来自残差(RSS ) 470895.00 17(n -k ) 27699.70588 RSS/(n -k) 总变差 (TSS ) 847962.19 19(n -1) 44629.58895 TSS/(n -1) (1) 见图中红颜色部分,解题思路标注在旁。