python读取xml文件
Python中的XML和JSON处理

Python中的XML和JSON处理随着网络技术的不断发展,数据交换在各行各业中变得越来越重要。
XML和JSON是两种非常常见的数据交换格式,它们能够以一种结构化的方式表示复杂的数据集合。
在Python中,我们可以很容易地利用XML和JSON库来处理这些不同的数据格式。
在本文中,我们将介绍Python中的XML和JSON处理的一些基本知识和应用。
一、XMLXML(可扩展标记语言)是一种通用的标记语言,用于表示结构化的数据,并允许针对这些数据进行操作。
它的设计目的是传输和存储数据,而不是展示数据。
XML由多个标签组成,每个标签都有一个开始标记和一个结束标记,并且可能包含其他嵌套标签和数据。
Python中的“xml”库提供了许多方法来创建、解析和操作XML文档。
在Python中创建XML文档非常容易,使用“xml.dom.minidom”库中的“Document”类能够轻松地创建。
例如,以下代码段就创建了一个简单的XML文档:```from xml.dom.minidom import Documentdoc = Document()root = doc.createElement('root')doc.appendChild(root)child = doc.createElement('child')root.appendChild(child)child.appendChild(doc.createTextNode('This is a child node.'))```这个示例代码首先创建了一个Document对象,然后创建了一个名为“root”的元素,并将其添加到文档中。
接着,它创建了一个名为“child”的元素,并将其添加为“root”的子级。
最后,它在“child”元素中添加了文本内容。
在Python中读取和解析现有的XML文档也非常容易。
python请求并解析xml的几种方法

一、介绍在网络开发中,经常会遇到需要请求并解析xml格式的数据的情况,而Python作为一种十分流行的编程语言,提供了多种方法来实现这一功能。
本文将介绍Python中请求并解析xml的几种方法,以帮助读者更好地应对实际开发中的需求。
二、使用urllib和xml.etree.ElementTree1. 使用urllib库发送HTTP请求获取xml数据``` pythonimport urllib.requesturl = "xxx"response = urllib.request.urlopen(url)xml_data = response.read()```2. 使用xml.etree.ElementTree库解析xml数据``` pythonimport xml.etree.ElementTree as ETroot = ET.fromstring(xml_data)3. 示例代码``` pythonimport urllib.requestimport xml.etree.ElementTree as ETurl = "xxx"response = urllib.request.urlopen(url)xml_data = response.read()root = ET.fromstring(xml_data)```三、使用requests和xmltodict1. 使用requests库发送HTTP请求获取xml数据``` pythonimport requestsurl = "xxx"response = requests.get(url)xml_data = response.text2. 使用xmltodict库解析xml数据``` pythonimport xmltodictxml_dict = xmltodict.parse(xml_data) ```3. 示例代码``` pythonimport requestsimport xmltodicturl = "xxx"response = requests.get(url)xml_data = response.textxml_dict = xmltodict.parse(xml_data) ```四、使用lxml库1. 使用requests库发送HTTP请求获取xml数据``` pythonimport requestsurl = "xxx"response = requests.get(url)xml_data = response.text```2. 使用lxml库解析xml数据``` pythonfrom lxml import etreexml_tree = etree.fromstring(xml_data)```3. 示例代码``` pythonimport requestsfrom lxml import etreeurl = "xxx"response = requests.get(url)xml_data = response.textxml_tree = etree.fromstring(xml_data)```五、总结本文介绍了Python中请求并解析xml的几种方法,包括使用urllib和xml.etree.ElementTree、requests和xmltodict、以及lxml库。
python xmltodict用法

pythonxmltodict用法Python是一种强大的编程语言,它具有广泛的库和工具,可用于处理各种数据格式。
XML是一种常用的数据格式,它被广泛应用于网络通信和数据交换。
在Python中,可以使用第三方库将XML转换为易于处理的格式,如字典。
这种库称为XML库,其中之一是xmltodict。
一、XML到Python字典的转换xmltodict库可以将XML文档转换为Python字典。
使用该库,您可以轻松地将XML数据加载到Python程序中,以便进行进一步的处理和分析。
要使用xmltodict库,请确保已安装该库。
您可以使用pip命令在终端中安装它:```shellpipinstallxmltodict```安装完成后,您可以使用以下代码将XML文档转换为Python字典:```pythonimportxmltodict#读取XML文件withopen('example.xml','r')asf:xml_data=f.read()#将XML数据转换为Python字典python_dict=xmltodict.parse(xml_data)#打印字典内容print(python_dict)```上述代码中,我们使用`xmltodict.parse()`函数将XML数据转换为Python 字典。
该函数接受一个字符串参数(表示XML数据),并返回一个Python字典对象。
您可以将该字典对象存储在变量中,以便进一步处理和操作。
二、使用Python字典处理XML数据转换后的Python字典可用于各种操作和查询XML数据。
例如,您可以使用字典中的键来访问特定的元素和属性。
以下是一个示例代码片段,演示如何使用Python字典处理XML数据:```pythonimportxmltodict#假设XML数据包含以下内容:xml_data='''<root><itemid="1">Item1</item><itemid="2">Item2</item><itemid="3">Item3</item></root>'''#将XML数据转换为Python字典python_dict=xmltodict.parse(xml_data)#访问特定的元素和属性item_1=python_dict['root']['item'][0]['@id']#获取id为1的item的id属性值print(item_1)#输出:1```在上述示例中,我们使用Python字典访问了名为“item”的元素列表中的第一个元素(id为1),并获取了其id属性值。
Python读取XML文件内容

Python读取XML⽂件内容XML 指的是可扩展标记语⾔(eXtensible Markup Language),和json类似也是⽤于存储和传输数据,还可以⽤作配置⽂件。
类似于HTML超⽂本标记语⾔,但是HTML所有的标签都是预定义的,⽽xml的标签可以随便定义。
XML元素指从开始标签到结束标签的部分(均包括开始和结束)⼀个元素可以包括:其它元素<aa><bb></bb></aa>属性<a id=’132’></a>⽂本<a >abc</a>混合以上所有XML语法规则所有的元素都必须有开始标签和结束标签,省略结束标签是⾮法的。
如:<root>根元素</root>⼤⼩写敏感,以下是两个不同的标签<Note>this is a test1</Note><note>this is a test2</note>xml⽂档必须有根元素<note><b>this is a test2</b><name>joy</name></note>XML必须正确嵌套,⽗元素必须完全包住⼦元素。
如:<note><b>this is a test2</b></note>XML属性值必须加引号,元素的属性值都是⼀个键值对形式。
如:<book category=" Python"></book>注意:元素book的category属性值python必须⽤引号括起来,单引号双引号都可以。
如果属性值中包含单引号那么⽤双引号括起来,如果属性值包含单引号那么外⾯⽤双引号括起来。
XML命名规则名称可以包含字母、数字以及其他字符名称不能以数字或标点符号开头名称不能以字母xml或XML开始名称不能包含空格可以使⽤任何名称,没有保留字名称应该具有描述性,简短和简单,可以同时使⽤下划线。
python3解析XML

python3解析XML在XML解析⽅⾯,Python贯彻了⾃⼰“开箱即⽤”(batteries included)的原则。
在⾃带的标准库中,Python提供了⼤量可以⽤于处理XML语⾔的包和⼯具,数量之多,甚⾄让Python编程新⼿⽆从选择。
本⽂将介绍深⼊解读利⽤Python语⾔解析XML⽂件的⼏种⽅式,并以笔者推荐使⽤的ElementTree模块为例,演⽰具体使⽤⽅法和场景。
⽂中所使⽤的Python版本为2.7。
⼀、什么是XML?XML是可扩展标记语⾔(Extensible Markup Language)的缩写,其中的标记(markup)是关键部分。
您可以创建内容,然后使⽤限定标记标记它,从⽽使每个单词、短语或块成为可识别、可分类的信息。
标记语⾔从早期的私有公司和政府制定形式逐渐演变成标准通⽤标记语⾔(Standard Generalized Markup Language,SGML)、超⽂本标记语⾔(Hypertext Markup Language,HTML),并且最终演变成 XML。
XML有以下⼏个特点。
XML的设计宗旨是传输数据,⽽⾮显⽰数据。
XML标签没有被预定义。
您需要⾃⾏定义标签。
XML被设计为具有⾃我描述性。
XML是W3C的推荐标准。
⽬前,XML在Web中起到的作⽤不会亚于⼀直作为Web基⽯的HTML。
XML⽆所不在。
XML是各种应⽤程序之间进⾏数据传输的最常⽤的⼯具,并且在信息存储和描述领域变得越来越流⾏。
因此,学会如何解析XML⽂件,对于Web开发来说是⼗分重要的。
⼆、有哪些可以解析XML的Python包?Python的标准库中,提供了6种可以⽤于处理XML的包。
xml.domxml.dom实现的是W3C制定的DOM API。
如果你习惯于使⽤DOM API或者有⼈要求这这样做,可以使⽤这个包。
不过要注意,在这个包中,还提供了⼏个不同的模块,各⾃的性能有所区别。
DOM解析器在任何处理开始之前,必须把基于XML⽂件⽣成的树状数据放在内存,所以DOM解析器的内存使⽤量完全根据输⼊资料的⼤⼩。
使用python处理大型xml文件的方法

使用python处理大型xml文件的方法==============在许多情况下,XML文件可能非常大,这可能会对处理过程产生重大影响。
大型XML文件可能会占用大量的内存,导致程序运行缓慢,甚至崩溃。
在这种情况下,使用Python处理大型XML文件需要一些特殊的方法和技术。
本文将介绍如何使用Python处理大型XML文件。
一、准备工作------在开始处理大型XML文件之前,我们需要做一些准备工作。
首先,我们需要确保我们的Python环境已经安装了所有必要的库。
这些库包括`xml.etree.ElementTree`(用于解析XML文件)和`multiprocessing`(用于并行处理)。
二、使用多进程处理---------对于大型XML文件,使用多进程处理是一种非常有效的方法。
Python的`multiprocessing`库提供了一种简单的方法来创建并管理多个进程。
我们可以使用这个库来将大型XML文件分解成多个较小的部分,并在不同的进程中处理这些部分。
以下是一个简单的示例代码,展示了如何使用多进程处理大型XML文件:```pythonfrommultiprocessingimportPoolfromxml.etreeimportElementTreedefprocess_file(file_path):#解析XML文件并处理内容#...if__name__=='__main__':#指定要处理的XML文件的路径列表file_paths=['large_file.xml','large_file2.xml']#创建进程池withPool(processes=4)aspool:#使用map方法将文件路径列表传递给process_file函数,并在多个进程中并行处理pool.map(process_file,file_paths)```在这个示例中,我们创建了一个包含要处理的XML文件路径的列表,并使用`Pool`类创建了一个包含4个进程的进程池。
python解析XML文件
python解析XML⽂件对于xml的解析,与json原理是相同的。
都是摆脱了只是纯⽂件解析成str的⿇烦。
⽆论是json解析还是xml解析,对于python来说都获取了对象,可以拿来直接⽤。
具体⽅法,看数据⽂件的格式。
但⽆疑,json更好⽤,可以直接对应上python的列表或者字典。
⽽xml,需要⼀些对象、属性处理。
⾄于xml相对JSON的好处,似乎没有什么优势,只因为XML⽐JSON 产⽣的时间早,那么在这个⽐较长的时间⾥⾯,形成了⼀种习惯⽤法。
在表述数据⽅⾯因为有<>等的帮助,可能会更清晰⼀些。
但也是仁者见仁罢了。
利⽤python解析XML的模块,需要遍历根(root)节点及⼦节点。
⽽节点的属性有4个:tag、attrib、text、tail,在python中⽤for循环遍历即可。
本⽂主要⽤xml.etree.ElementTree模块,最清晰明确。
python还有其他两个模块:SAX (simple API for XML )、DOM(Document Object Model)可以解析XML⽂件。
但感觉⽤法⽐较繁复,另做探讨。
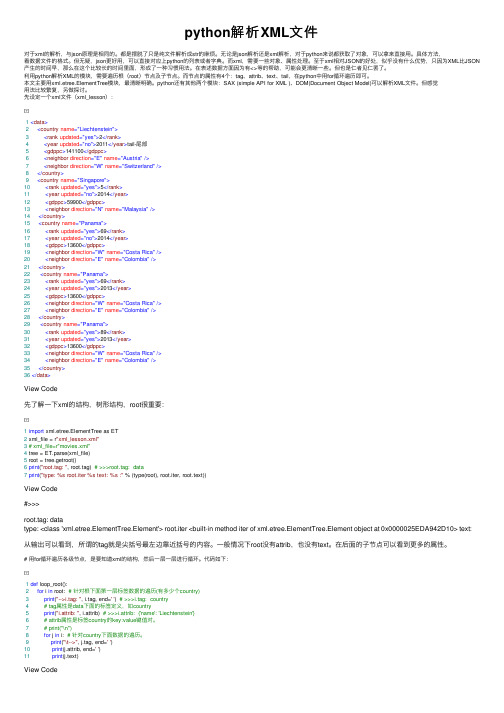
先设定⼀个xml⽂件(xml_lesson):1<data>2<country name="Liechtenstein">3<rank updated="yes">2</rank>4<year updated="no">2011</year>tail-尾部5<gdppc>141100</gdppc>6<neighbor direction="E" name="Austria"/>7<neighbor direction="W" name="Switzerland"/>8</country>9<country name="Singapore">10<rank updated="yes">5</rank>11<year updated="no">2014</year>12<gdppc>59900</gdppc>13<neighbor direction="N" name="Malaysia"/>14</country>15<country name="Panama">16<rank updated="yes">69</rank>17<year updated="no">2014</year>18<gdppc>13600</gdppc>19<neighbor direction="W" name="Costa Rica"/>20<neighbor direction="E" name="Colombia"/>21</country>22<country name="Panama">23<rank updated="yes">69</rank>24<year updated="yes">2013</year>25<gdppc>13600</gdppc>26<neighbor direction="W" name="Costa Rica"/>27<neighbor direction="E" name="Colombia"/>28</country>29<country name="Panama">30<rank updated="yes">89</rank>31<year updated="yes">2013</year>32<gdppc>13600</gdppc>33<neighbor direction="W" name="Costa Rica"/>34<neighbor direction="E" name="Colombia"/>35</country>36</data>View Code先了解⼀下xml的结构,树形结构,root很重要:1import xml.etree.ElementTree as ET2 xml_file = r"xml_lesson.xml"3# xml_file=r"movies.xml"4 tree = ET.parse(xml_file)5 root = tree.getroot()6print("root.tag: ", root.tag) # >>>root.tag: data7print("type: %s root.iter %s text: %s :" % (type(root), root.iter, root.text))View Code#>>>root.tag: datatype: <class 'xml.etree.ElementTree.Element'> root.iter <built-in method iter of xml.etree.ElementTree.Element object at 0x0000025EDA942D10> text:从输出可以看到,所谓的tag就是尖括号最左边靠近括号的内容。
Python读写XML后保持节点属性顺序不变

python环境:2.7
库:import xml.dom.minidom
修改minidom源码,引入相应的库
from collections import OrderedDict
根据下面代码 注释掉相应的源码 新增 self._attrs = OrderedDict()
__init__(...) self._attrs = OrderedDict() #self._attrs = {}
博客园 用户登录 代码改变世界 密码登录 短信登录 忘记登录用户名 忘记密码 记住我 登录 第三方登录/注册 没有账户, 立即注册
Python读写 XML后保持节点属性顺序不变
Python读 写 XML后 保 持 节 点 属 性 顺 序 不 变
试过xml.etree.ElementTree和xml.dom.minidom两个python的库,发现读取后输出都会改变xml里面节点属性的顺序. 虽然这个顺序其实没什么 意义但是有些时候时候会比较纠结,找了好多资料最后在stackoverflow中找到一些有用的资料.最后亲测可用.
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
python读取xml文件还可以参见网址/uid-22183602-id-3036442.html/uid-22183602-id-3036442.html2014-03-04 23:43 by 虫师, 13913 阅读, 1 评论, 收藏, 编辑关于python读取xml文章很多,但大多文章都是贴一个xml文件,然后再贴个处理文件的代码。
这样并不利于初学者的学习,希望这篇文章可以更通俗易懂的教如何使用python 来读取xml 文件。
什么是xml?xml即可扩展标记语言,它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。
abc.xml<?xml version="1.0" encoding="utf-8"?><catalog><maxid>4</maxid><login username="pytest" passwd='123456'><caption>Python</caption><item id="4"><caption>测试</caption></item></login><item id="2"><caption>Zope</caption></item></catalog>Ok ,从结构上,它很像我们常见的HTML超文本标记语言。
但他们被设计的目的是不同的,超文本标记语言被设计用来显示数据,其焦点是数据的外观。
它被设计用来传输和存储数据,其焦点是数据的内容。
那么它有如下特征:首先,它是有标签对组成,<aa></aa>标签可以有属性:<aa id=’123’></aa>标签对可以嵌入数据:<aa>abc</aa>标签可以嵌入子标签(具有层级关系):<aa><bb></bb></aa>获得标签属性那么,下面来介绍如何用python来读取这种类型的文件。
#coding=utf-8import xml.dom.minidom#打开xml文档dom = xml.dom.minidom.parse('abc.xml')#得到文档元素对象root = dom.documentElement print root.nodeName print root.nodeValue print root.nodeType print root.ELEMENT_NODEmxl.dom.minidom 模块被用来处理xml文件,所以要先引入。
xml.dom.minidom.parse() 用于打开一个xml文件,并将这个文件对象dom变量。
documentElement 用于得到dom对象的文档元素,并把获得的对象给root每一个结点都有它的nodeName,nodeValue,nodeType属性。
nodeName为结点名字。
nodeValue是结点的值,只对文本结点有效。
nodeType是结点的类型。
catalog是ELEMENT_NODE类型现在有以下几种:'ATTRIBUTE_NODE''CDATA_SECTION_NODE''COMMENT_NODE''DOCUMENT_FRAGMENT_NODE''DOCUMENT_NODE''DOCUMENT_TYPE_NODE''ELEMENT_NODE''ENTITY_NODE''ENTITY_REFERENCE_NODE''NOTATION_NODE''PROCESSING_INSTRUCTION_NODE''TEXT_NODE'NodeTypes - 有名常数/xmldom/dom_nodetype.asp获得子标签现在要获得catalog的子标签以的标签name<?xml version="1.0" encoding="utf-8"?><catalog> <maxid>4</maxid><login username="pytest" passwd='123456'><caption>Python</caption><item id="4"><caption>测试</caption></item></login><item id="2"><caption>Zope</caption></item></catalog>对于知道元素名字的子元素,可以使用getElementsByTagName方法获取:#coding=utf-8import xml.dom.minidom#打开xml文档dom = xml.dom.minidom.parse('abc.xml')#得到文档元素对象root = dom.documentElementbb = root.getElementsByTagName('maxid')b= bb[0]print b.nodeNamebb = root.getElementsByTagName('login')b= bb[0]print b.nodeName如何区分相同标签名字的标签:<?xml version="1.0" encoding="utf-8"?><catalog><maxid>4</maxid><login username="pytest" passwd='123456'><caption>Python</caption><item id="4"><caption>测试</caption></item></login><item id="2"><caption>Zope</caption></item></catalog><caption>和<item>标签不止一个如何区分?#coding=utf-8import xml.dom.minidom#打开xml文档dom = xml.dom.minidom.parse('abc.xml')#得到文档元素对象root = dom.documentElementbb = root.getElementsByTagName('caption')b= bb[2]print b.nodeNamebb = root.getElementsByTagName('item')b= bb[1]print b.nodeNameroot.getElementsByTagName('caption') 获得的是标签为caption 一组标签,b[0]表示一组标签中的第一个;b[2] ,表示这一组标签中的第三个。
获得标签属性值<?xml version="1.0" encoding="utf-8"?><catalog><maxid>4</maxid><login username="pytest" passwd='123456'><caption>Python</caption><item id="4"><caption>测试</caption></item></login><item id="2"><caption>Zope</caption></item></catalog><login>和<item>标签是有属性的,如何获得他们的属性?#coding=utf-8import xml.dom.minidom#打开xml文档dom = xml.dom.minidom.parse('abc.xml')#得到文档元素对象root = dom.documentElementitemlist = root.getElementsByTagName('login')item = itemlist[0]un=item.getAttribute("username")print unpd=item.getAttribute("passwd")print pdii = root.getElementsByTagName('item')i1 = ii[0]i=i1.getAttribute("id")print ii2 = ii[1]i=i2.getAttribute("id")print igetAttribute方法可以获得元素的属性所对应的值。
获得标签对之间的数据<?xml version="1.0" encoding="utf-8"?><catalog> <maxid>4</maxid><login username="pytest" passwd='123456'><caption>Python</caption><item id="4"><caption>测试</caption></item></login><item id="2"><caption>Zope</caption></item></catalog><caption>标签对之间是有数据的,如何获得这些数据?获得标签对之间的数据有多种方法,方法一#coding=utf-8import xml.dom.minidom#打开xml文档dom = xml.dom.minidom.parse('abc.xml')#得到文档元素对象root = dom.documentElementcc=dom.getElementsByTagName('caption')c1=cc[0]print c1.firstChild.datac2=cc[1]print c2.firstChild.datac3=cc[2]print c3.firstChild.datafirstChild 属性返回被选节点的第一个子节点,.data表示获取该节点人数据。