提取文件夹中所有TXT中所需信息并导入数据库
把数据从txt文件导入到Oracle数据库的实现方法

把数据从txt文件导入到Oracle数据库的实现方法
1、环境配置准备
在导入txt文件到Oracle数据库之前,我们需要配置环境,方可方
便后续的操作:
(1)安装Oracle数据库,并配置好数据库用户及其权限;
(2)安装Oracle的工具sqlldr,这是一个数据导入工具;
(3)在操作系统中,创建一个目录,用于存放sqlldr需要使用的控
制文件,以及要导入数据库的txt文件;
(4)编写好sqlldr需要的控制文件,控制文件可以定义数据的格式,以及要插入到数据库的表结构等;
(5)将要被导入的txt文件存放到上面定义的目录中;
2、编写sqlldr控制文件
sqlldr提供了一种类SQL语句的控制文件,这些控制文件用于描述
如何将txt文件中的数据导入到Oracle数据库中,主要包括以下几方面
的内容:
(1)数据的编码;
(2)要被导入的表名;
(3)每个要被导入的字段的定义,包括其类型、长度等;
(4)数据的分隔符,比如以空格分隔或者以tab分隔等;
(5)进行数据校验,比如检查给定字段的数据是否是满足要求的类型等;
(6)如果数据中有时间字段,可以定义时间的格式;
(7)数据导入失败的记录日志路径;
(8)定义要被导入的字段的映射关系,比如txt文件中的列名与表中的字段没有一一对应;。
Txt文件导入oracle数据库方法

Txt文件导入oracle数据库方法在Oracle数据库中,可以使用SQL*Loader工具或者外部表的方式将文本文件(.txt文件)导入到数据库。
下面我将为你详细介绍这两种方法。
方法一:使用SQL*Loader工具导入txt文件1.创建控制文件控制文件是SQL*Loader用来定义数据导入规则的文件。
它描述了数据文件的格式、目标表的结构,以及导入时的数据转换和验证规则。
例如,假设我们要将一个txt文件中的数据导入到名为EMP的表中,EMP表的结构如下:CREATETABLEEMPEMPNONUMBER(4),ENAMEVARCHAR2(10),JOBVARCHAR2(9),MGRNUMBER(4),HIREDATEDATE,SALNUMBER(7,2),COMMNUMBER(7,2),DEPTNONUMBER(2)我们可以创建一个名为emp.ctl的控制文件,内容如下:LOADDATAINFILE 'emp.txt'APPENDINTOTABLEEMPFIELDS TERMINATED BY ',' optionally enclosed by '"'EMPNO,ENAME,JOB,MGR,HIREDATECHAR"YYYY-MM-DD",SAL,COMM,DEPTNO2.准备数据文件在导入数据之前,需要将数据准备好并保存为一个txt文件(如emp.txt)。
确保数据文件的每一行与控制文件中的字段一一对应,并且字段之间以逗号分隔,如下所示:7902,SMITH,CLERK,7901,1980-12-17,800,,207369,ADAMS,CLERK,7876,1983-01-12,1100,,20...3. 使用SQL*Loader导入数据打开命令行窗口(或终端),输入以下命令导入数据:其中,username是数据库用户名,password是数据库密码,database是数据库实例名。
教你用python提取txt文件中的特定信息并写入Excel

教你⽤python提取txt⽂件中的特定信息并写⼊Excel⽬录问题描述:⼯具:操作:源代码:Reference:总结问题描述:我有⼀个这样的数据集叫test_result_test.txt,⼤概⼏百上千⾏,两⾏数据之间隔⼀个空⾏。
N:505904X:0.969wsecY:0.694wsecN:506038X:4.246wsecY:0.884wsecN:450997X:8.472wsecY:0.615wsec...现在我希望能提取每⼀⾏X:和Y:后⾯的数字,然后保存进Excel做进⼀步的数据处理和分析就拿第⼀⾏来说,我只需要0.969 和0.694。
每⼀⾏三个数字的具体位置是不确定的,因此不能⽤固定的列数去处理,刚好发现split函数能对⽂本进⾏切⽚,所以这⾥我们⽤这个函数来提取需要的数字信息。
split函数语法如下:1、split()函数语法:str.split(str="",num=string.count(str))[n]参数说明:str:表⽰为分隔符,默认为空格,但是不能为空('')。
若字符串中没有分隔符,则把整个字符串作为列表的⼀个元素num:表⽰分割次数。
如果存在参数num,则仅分隔成 num+1 个⼦字符串,并且每⼀个⼦字符串可以赋给新的变量[n]:表⽰选取第n个分⽚注意:当使⽤空格作为分隔符时,对于中间为空的项会⾃动忽略于是对于我们这⾥的⽂本,我们可以先⽤“:”切⽚,把⽂本分成三份,⽐如对于第⼀⾏以“:”进⾏切⽚得到取第三个分⽚进⾏“w”切⽚,得到这⾥的第⼀分⽚就是我们要的X坐标最后我们分析⼀下思路:⾸先定位⽂件位置读取txt⽂件内容,去掉空⾏保存Excel准备⼯作,新建Excel表格,并编辑好标题为写⼊数据就位对于每⼀⾏数据,⾸先⽤‘:'进⾏切⽚,再⽤‘w'切⽚得到想要的数字,然后写⼊Excel保存⼯具:安装好python模块的visual studio 2017包:os,xlwt操作:先import我们所需要的包import osimport xlwt1.找到我们想要处理的⽂件,因此去到指定的位置,定位好⽂件a = os.getcwd() #获取当前⽬录print (a) #打印当前⽬录os.chdir('D:/') #定位到新的⽬录,请根据你⾃⼰⽂件的位置做相应的修改a = os.getcwd() #获取定位之后的⽬录print(a) #打印定位之后的⽬录2.打开我们的txt⽂件查看下⾥⾯的内容(这⼀步可有可⽆)#读取⽬标txt⽂件⾥的内容,并且打印出来显⽰with open('test_result1.txt','r') as raw:for line in raw:print (line)3.去除空⽩⾏并保存#去掉txt⾥⾯的空⽩⾏,并保存到新的⽂件中with open('test_result1.txt','r',encoding = 'utf-8') as fr, open('output.txt','w',encoding= 'utf-8') as fd:for text in fr.readlines():if text.split():fd.write(text)print('success')执⾏完毕同个位置下多了⼀个txt⽂件4. 创建⼀个Excel⽂件#创建⼀个workbook对象,相当于创建⼀个Excel⽂件book = xlwt.Workbook(encoding='utf-8',style_compression=0)'''Workbook类初始化时有encoding和style_compression参数encoding:设置字符编码,⼀般要这样设置:w = Workbook(encoding='utf-8'),就可以在excel中输出中⽂了。
把数据从txt文件导入到数据库的实现方法

把数据从txt文件导入到数据库的实现方法将数据从txt文件导入到数据库可以通过以下步骤实现:1. 创建数据库表结构:首先需要创建一个与txt文件数据相对应的数据库表结构。
表的列应该与txt文件中的数据字段对应。
可以使用数据库管理工具(如MySQL Workbench)或编程语言中的数据库操作库(如Python的MySQLdb)来创建表结构。
2. 打开txt文件:使用编程语言中的文件操作函数(如Python的open(函数)打开txt文件,并读取其中的数据。
根据txt文件的格式,可以使用逐行读取或一次性读取整个文件的方式来获取数据。
3. 解析数据:对于每一行数据,需要将其解析成各个字段的值。
可以使用字符串操作函数(如split(函数)将一行数据拆分成多个字段值。
如果txt文件中的数据是有结构的,可以使用正则表达式来匹配和提取字段值。
4. 建立数据库连接:使用编程语言中的数据库操作库连接到目标数据库。
根据数据库类型,可以使用不同的库(如Python的MySQLdb库、psycopg2库用于PostgreSQL等)来建立连接。
5.插入数据:将解析得到的数据插入到数据库表中。
使用数据库操作库提供的插入语句(如SQL语句)将数据插入到数据库表中。
可以使用批量插入的方式来提高插入性能,即将多个数据记录一次性插入到数据库中。
6. 关闭文件和数据库连接:在数据导入完成后,关闭txt文件和数据库连接,释放资源。
7. 错误处理:在数据导入的过程中,可能会出现一些错误,如文件不存在、数据格式错误等。
需要进行错误处理,确保数据导入的完整性和正确性。
可以使用异常处理机制(如Python的try-except语句)来捕获和处理错误。
8. 日志记录:为了追踪数据导入的过程和结果,可以添加日志记录功能。
可以使用编程语言中的日志库(如Python的logging库)来记录日志,包括导入开始时间、结束时间、导入的记录数等信息。
总结:将数据从txt文件导入到数据库需要完成文件读取、数据解析、数据库连接、数据插入等步骤。
文本文件导入到数据库中的几种方法

INFILE '/ora9i/fengjie/agent/data/ipaagent200410.txt'
TRUNCATE
INTO TABLE fj_ipa_agent
( DEVNO POSITION(1:20) CHAR,
date_cache -- size (in entries) of date conversion cache(默认1000)
PLEASE NOTE: 命令行参数可以由位置或关键字指定。前者的例子是 'sqlloadscott/tiger foo'; 后一种情况的一个示例是 'sqlldr
其基本工作原理是:首先要针对数据源文件制作一个控制文件,控制文件是用来解释如何对源文件进行解析,其中需要包含源文件的数据格式、目标数据库的字段等信息,一个典型的控制文件为如下形式:
LOAD DATA
INFILE '/ora9i/fengjie/agent/data/ipaagentdetail200410.txt'
readsize -- Size of Read buffer (默认1048576)
external_table -- use external table for load; NOT_USED, GENERATE_ONLY, EXECUTE(默认NOT_USED)
(默认: 常规路径 64, 所有直接路径)
bindsize -- Size of conventional path bind array in bytes(默认256000)
silent -- Suppress messages during run (header,feedback,errors,discards,partitions)
Txt文件导入oracle数据库方法
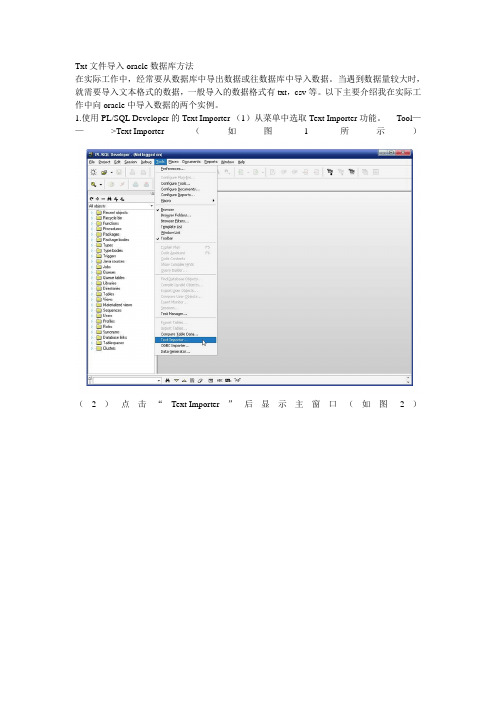
Txt文件导入oracle数据库方法
在实际工作中,经常要从数据库中导出数据或往数据库中导入数据。
当遇到数据量较大时,就需要导入文本格式的数据,一般导入的数据格式有txt,csv等。
以下主要介绍我在实际工作中向oracle中导入数据的两个实例。
1.使用PL/SQL Developer的Text Importer (1)从菜单中选取Text Importer功能。
Tool——>Text Importer(如图1所示)
(2)点击“Text Importer”后显示主窗口(如图2)
3)设置将数据文件导入到哪个数据库中的哪个表中,如图3所示。
(4)设置完成后,点击“Import”按钮,数据开始导入直到数据全部导入到数据库中。
2.使用Power Builder 将txt文件导入到数据库中。
(1)先建表结构
例如:Create Table Temp (subsid varchar(20) not null primary key,subsname(50));如图4所示。
在这里需要说明的是:在建立表的过程中,必须设置主键,否着不允许导入数据。
(2)检索刚建的临时表temp select * from temp
(3)点击“Rows”下的“Import”选项,弹出文件对话框,选择你要加载的数据文件,点击“确定”。
如图5所示。
批量提取指定内容的步骤

批量提取指定内容的步骤
要批量提取指定内容,可以按照以下步骤进行操作:
1. 收集待处理的文档或数据集:收集包含要提取内容的文档或数据集,并保存在一个文件夹或数据库中。
2. 确定要提取的内容:确定要提取的具体内容,例如日期、姓名、地址等。
这个步骤非常重要,因为它会影响后续的提取过程。
3. 选择合适的工具或技术:根据要提取的内容类型,选择适合的工具或技术进行批量提取。
例如,如果要提取的是文本中的关键词,可以使用自然语言处理技术;如果要提取的是结构化数据,可以使用数据挖掘工具。
4. 编写代码或使用现有工具:根据选择的工具或技术,编写代码或使用现有的提取工具进行批量提取。
如果没有编程经验,可以考虑寻找现有的软件或工具来完成任务。
5. 测试和验证:对提取结果进行测试和验证,确保提取的内容准确无误。
可以随机选择几个样本进行人工验证,以确保提取的准确性和完整性。
6. 批量提取并保存结果:将编写的代码应用于整个文档或数据集,并批量提取需要的内容。
将提取的结果保存在适当的格式中,例如CSV文件或数据库。
7. 数据清洗和整理:根据需要,对提取的结果进行数据清洗和整理,例如删除重复项、规范化格式等。
8. 分析和应用结果:根据实际需要,对提取的结果进行进一步的分析和应用。
可以使用各种统计、机器学习或数据可视化技术进行分析,从中提取有用的信息。
以上是一般的批量提取指定内容的步骤,具体的实施过程可能会因不同的情况而有所变化。
将TXT文件导入sqlserver数据库

将TXT⽂件导⼊sqlserver数据库数据库已存在旧表名 old_table,列名old_column_name。
将TXT⽂件导⼊数据库已存在旧表old_table中,导⼊过程中需注意数据源中列名可全部不修改或全部修改列名为old_column_name(与old_table中列名⼀致)。
情景⼆:将源TXT⽂件导⼊数据库,默认时以源TXT⽂件名建新表sourceFile_table;导⼊过程中需修改数据源中列名为 custom_column_name(⾃定义列名)数据库右键》任务》导⼊数据(I)...》 --或者-- 开始》程序》Microsoft Visual Studio2008》导⼊和导出数据(**位)》SQLServer导⼊和导出向导》下⼀步》选择数据源数据源:平⾯⽂件源常规⽂件名(i): 浏览选择TXT⽂件区域设置(L): 中⽂代码页(C): 65001(UTF-8) : 源TXT⽂件编码⽅式为UTF-8936(ANSI/OEM-简体中⽂ GBK): 源TXT⽂件编码⽅式为ANSI 格式(M): 带分隔符⽂本限定符(Q): <⽆>标题⾏分隔符(R): {CR}{LF}要跳过的标题⾏数(S): 可⾃定义列⾏分隔符(O): {CR}{LF}列分隔符(C): 制表符{t}⾼级列名Name列名(可修改) ColumnDelimiter制表符{t}DataType据⽬标表的字段类型定义OutputColumnWidth可⾃定义TextQualified True预览要跳过的数据⾏数(A): 可⾃定义下⼀步》选择⽬标⽬标(D): SQL Server Native Client 10.0服务器名称(S): 需⼿动输⼊“⽬标服务器名称”使⽤SQL Server ⾝份验证(Q)⽤户名(U):需⼿动输⼊密码(P): 需⼿动输⼊数据库(T): 选择已建的数据库下⼀步》选择源表和源视图表和视图(T):源⽬标双击》列映射(可编辑)》当主键id⾃增时,选中启⽤标识插⼊单击》下拉框》可选择⽬标表为(已存在表old_table 或者默认时以源TXT⽂件名sourceFile_table建⽴新表)》下⼀步》下⼀步》完成-------------------------------------------问题⼀:将源TXT⽂件sourceFile_table.txt,导⼊数据库已存在表old_table原因:源TXT⽂件sourceFile_table.txt中数据类型为varchar(50),数据库已存在表old_table中数据类型为nvarchar(50)解决⽅法:修改表old_table中,对应字段数据类型为varchar(50)-------------------------------------------问题⼆:将TXT⽂件导⼊ sqlserver数据库后,字段值中⽂乱码原因:源TXT⽂件编码⽅式,和数据库编码⽅式不⼀致解决⽅法:⽂件转码⽅法1.源TXT⽂件》右键打开》⽂件另存为》编码(E):**》保存⽅法2.源TXT⽂件sourceFile_table.txt、备份⽂件backupFile_table.txt》将源⽂件使⽤转码⼯具转换》将备份⽂件中数据复制到源⽂件中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
<%@LANGUAGE="VBSCRIPT" CODEPAGE="65001"%><!--#include file="Connections/conn.asp" --><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="/1999/xhtml"><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>提取数据</title></head><body><%Set fso = Server.CreateObject("Scripting.FileSystemObject")on error resume nextSet objFolder=fso.GetFolder("C:\Jerry\ASP\WEB\wwwroot\getdata") Set objFiles=objFolder.Files'循环输出文件夹path下的文件的文件名For each objFile in objFiles '取相关值txtname=""name1=""school=""sex=""qq=""msn=""telephone=""if objFile.Type="Text Document" thenResponse.Write "<br>"+ & "<br>"txtname='判断是否有相同的文件名Set rs2 = Server.CreateObject("ADODB.Recordset")sql="select * from dbo.data1 where txtname="&txtnamers2.Open sql,objConn,1,3if rs2.eof=true then'读取文档dim fsodim pathset fso=server.createobject("scripting.filesystemobject")path = objFile.Pathset file = fso.opentextfile(path,1,true)if not file.atendofstream thenline=file.ReadAllend if'提取姓名response.write ("姓名:")n=instr(line,"帐号 <#>")m=instr(line,"装扮主页</store/view/home?wc=10000>修改资料")if m=0 then'提取物修改资料这块的账户姓名line=right(line,len(line)-n-13)i=instr(line,"\x{")if i<5 and i<>0 thenname1=mid(line,1,i-1) elsename1=mid(line,1,3)end ifresponse.write name1+"<br>" elseline=right(line,len(line)-m-127)i=instr(line,"\x{")if i<5 thenname1=mid(line,1,i-1) elsename1=mid(line,1,3)end ifresponse.write name1+"<br>" end if'提取所在学校str2="所在学校:"str3="生日:"str4="<"str5=">"n=Instr(line,str2)m=Instr(line,str3)if n<>0 thenschool=mid(line,n+11,m-n-11)response.write "所在学校:"+school+"<br>"'提取了所在大学end if'提取生日line=right(line,len(line)-m+1)n=Instr(line,str4)year1=mid(line,1+9,n-10)'提取了年份line=right(line,len(line)-n)n=Instr(line,str5)m=instr(line,str4)month1=mid(line,n+1,m-n-1)'提取了月份line=right(line,len(line)-m)n=Instr(line,str5)m=instr(line,str4)day1=mid(line,n+1,m-n-1)'提取了日birthdate=replace(year1&month1&day1," ","")response.Write ("生日:"+birthdate+"<br>")'显示生日'提取了性别n=instr(line,"性别 :")m=instr(line,"生日 :")sex=mid(line,n+10,1)response.Write "性别:"+sex+"<br>"'提取联系方式n=instr(line,"QQ :")m=instr(line,"MSN :")k=instr(line,"手机号 :")j=instr(line,"个人网站 :")if n<>0and m<>0 and k=0 then'只有QQ 和MSN的情况qq=mid(line,n+10,m-n-10)response.Write "QQ:"+qq+"<br>"'提取了QQmsn=mid(line,m+10,j-m-10)response.Write "MSN:"+msn+"<br>"'提取了msnelseif n<>0 and m=0 and k<>0 then'只有QQ和手机号码的情况qq=mid(line,n+10,k-n-10)response.Write "QQ:"+qq+"<br>"'提取了QQtelephone=mid(line,k+10,j-k-10)response.Write "手机号:"+telephone+"<br>"'提取了手机号elseif n<>0 and m=0 and k=0then'只有QQ的情况qq=mid(line,n+10,j-n-10)response.Write "QQ:"+qq+"<br>"'提取了QQelseif n<>0 and m<>0 and k<>0 then'QQ MSN 手机号码都有的情况qq=mid(line,n+10,m-n-10)response.Write "QQ:"+qq+"<br>"'提取了QQmsn=mid(line,m+10,k-m-10)response.Write "MSN:"+msn+"<br>"'提取了MSNtelephone=mid(line,k+10,j-k-10)response.Write "手机号:"+telephone+"<br>"'提取了手机号码elseif n=0 and m<>0 and k=0 then'只有MSN的情况msn=mid(line,m+10,j-m-10)response.Write "MSN:"+msn+"<br>"'提取了MSNelseif n=0 and m<>0 and k<>0 then'只有MSN 手机号的情况msn=mid(line,m+10,k-m-10)response.Write "MSN:"+msn+"<br>"'提取了MSNtelephone=mid(line,k+10,j-k-10)response.Write "手机号:"+telephone+"<br>"'提取了手机号elseif n=0 and m=0 and k<>0 then'只有手机号的情况telephone=mid(line,k+10,j-k-10)response.Write "手机号:"+telephone+"<br>"'提取了手机号end if'去除空格qq=replace(qq," ","")msn=replace(msn," ","")telephone=replace(telephone," ","")'将记录插入数据库中set cmd=Server.CreateObject("mand")query="insert into data1(txtname,name,school,birthdate,sex,qq,msn,telephone)values('"&txtname&"','"&name1&"','"&school&"','"&birthdate&"','"&sex&"','"&qq&"','"&msn&" ','"&telephone&"')"objConn.execute(query)elseresponse.Write("数据库中已经存在该文档名称的数据,请不要重复添加!")end ifrs2.closeend ifNextSet objFolder=nothingSet fso=nothing '释放对象%></body></html>。