多元统计分析作业一(第四题)
多元统计分析方法练习题
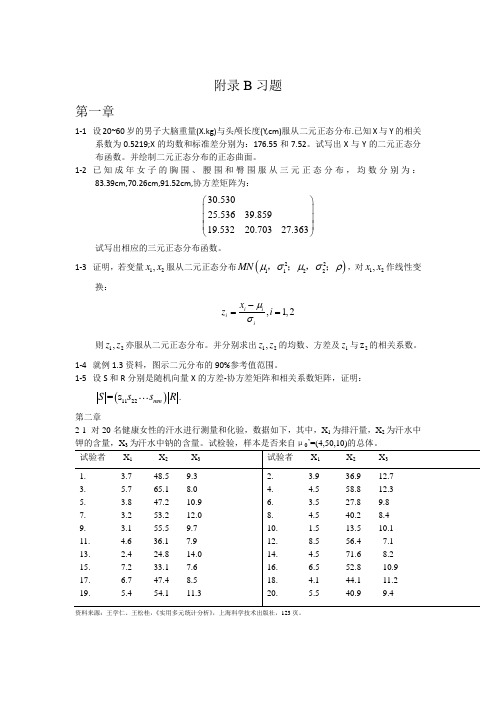
2. 3.9 36.9 12.7
4. 4.5 58.8 12.3
6. 3.5 27.8 9.8
8. 4.5 40.2 8.4
10. 1.5 13.5 10.1
12. 8.5 56.4 7.1
14. 4.5 71.6 8.2
16. 6.5 52.8 10.9
18. 4.1 44.1 11.2
5.8 9.6 3.0 6.9 9.9 3.9
6.5 9.6 4.1 6.1 9.5 1.9
6.5 9.2 0.8 6.3 9.4 5.7
高拉速(B2)6.7 9.1 2.8 7.1 9.2 8.4
6.6 9.3 4.1 7.0 8.8 5.2
7.2 8.3 3.8 7.2 9.7 6.9
7.1 8.4 1.6 7.5 10.1 2.7
49 81.42 8.95 44 180 185 49.156
57 73.37 12.63 58 174 176 39.407
54 79.38 11.17 62 156 165 46.080
51 73.71 10.47 59 186 188 45.790
57 59.08 9.93 49 148 155 50.545
4155.3 45.0 74.0 4 150.0 50.2 87.0
5152.0 35.0 63.0 5 144.0 36.3 68.0
6158.3 44.5 75.0 6 160.5 54.7 86.0
7154.8 44.5 74.0 7 158.0 49.0 84.0
8164.0 51.0 72.0 8 154.0 50.8 76.0
3 142 89 138 99 138 99 142 108
多元统计分析作业1

一、聚类分析为了研究2010年全国各地区城镇居民家庭平均每人全年消费性支出的分布规律,根据抽样调查资料进行分类处理,共抽取31个省、市、自治区的样本,每个样本有7个指标:食品、衣着、居住、家庭设备用品及服务、医疗保健、交通和通信、教育文化娱乐服务。
这7个指标反映了平均每人生活消费的支出情况,其数据资料见下表1所示。
表1定义变量及标签:设:X1:地区X2:食品支出X3:衣着支出X4:居住支出X5:家庭设备用品及服务支出X6:医疗保健支出X7:交通和通信支出X8:教育文化娱乐服务支出通过SPSS软件操作,得到如下输出结果见表2—表5所示。
表2表3表4表4给出了聚类的凝聚过程情况。
表5给出了样品聚为三类时的样品归类情况。
C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+甘肃 28 -+青海 29 -+新疆 31 -+河北 3 -+---+山西 4 -+ |河南 16 -+ |宁夏 30 -+ |黑龙江 8 -+ +-------+陕西 27 -+ | |云南 25 -+-+ | |西藏 26 -+ | | |广西 20 -+ +-+ |海南 21 -+ | |江西 14 -+-+ |贵州 24 -+ +-----------------------------------+ 湖北 17 -+ | | 湖南 18 -+ | | 四川 23 -+ | | 安徽 12 -+ | | 江苏 10 -+-+ | | 福建 13 -+ | | | 辽宁 6 -+ +---------+ | 吉林 7 -+ | | 山东 15 -+-+ | 重庆 22 -+ | 内蒙古 5 -+ | 天津 2 -+ | 浙江 11 -+-+ | 北京 1 -+ +-+ | 广东 19 ---+ +-------------------------------------------+ 上海 9 -----+图1图1是聚类全过程的树形图。
应用多元统计分析课后习题答案高惠璇部分习题解答(00004)市公开课金奖市赛课一等奖课件

[(
y1
aˆ0
)2
]
0
可得
ˆ
2
1 3
( y1
aˆ0 )2
( y2
aˆ0 )2
( y3
3aˆ0 )2
drf
ˆ
2 0
似然比统计量分子为
L(aˆ0
, ˆ 0 2
)
(2
)
3 2
(ˆ 0 2
)
3 2
exp[
3 2
].
第5页
5
第四章 回归分析
似然比统计量为
L(aˆ0 ,ˆ02 ) L(aˆ,bˆ,ˆ 2 )
第18页 18
第四章 回归分析
第19页 19
第四章 回归分析
等号成立 C(ˆ ) 0 (CC)1C • C(ˆ ) 0 ˆ.
第20页 20
第四章 回归分析
第21页 21
第四章 回归分析
第22页 22
第四章 回归分析
见附录P394定理7.2(7.5)式
第23页 23
第四章 回归分析
证实:(1)预计向量为 Yˆ Cˆ C(CC)1CY HY
yˆ
1 n
n i 1
yˆi
1 n
1n
Yˆ
1 n
1n
HY
1 n
(H1n )Y
1 n
1n
Y
y.
(因1n C张成的空间,这里有H1n 1n )
(2) 因 n ( yi y)( yˆi yˆ ) n ( yi yˆi yˆi y)( yˆi y)
0
ln
L
2
n
2
2
1
2( 2 )2
(Y
多元统计分析试题(A卷)(答案)

多元统计分析试题(A卷)(答案)《多元统计分析》试卷一、填空题(每空2分,共40分)1、若且相互独立,则样本均值向量X服从的分布为2、变量的类型按尺度划分有_间隔尺度_、_有序尺度_、名义尺度_。
3、判别分析是判别样品的一种统计方法,常用的判别方法有___、、、。
4、Q型聚类是指对_进行聚类,R型聚类是指对进行聚类。
'5、设样品,总体X~Np(,对样品进行分类常用的距离有:明氏距离,马氏距离,兰氏距离6、因子分析中因子载荷系数aij的统计意义是_第i个变量与第j个公因子的相关系数。
7、一元回归的数学模型是:,多元回归的数学模型是:。
8、对应分析是将和结合起来进行的统计分析方法。
9、典型相关分析是研究两组变量之间相关关系的一种多元统计方法。
二、计算题(每小题10分,共40分)1、设三维随机向量,其中130,问X1与X2是否独立?和X3是否独立?为什么?解:因为,所以X1与X2不独立。
把协差矩阵写成分块矩阵,的协差矩阵为因为,而,所以和X3是不相关的,而正态分布不相关与相互独立是等价的,所以和X3是独立的。
2、设抽了五个样品,每个样品只测了一个指标,它们分别是1 ,2 ,4.5 ,6 ,8。
若样本间采用明氏距离,试用最长距离法对其进行分类,要求给出聚类图。
x1013.55702.54601.53.502x2x3解:样品与样品之间的明氏距离为:D(0)样品最短距离是1,故把X1与X2合并为一类,计算类与类之间距离(最长距离法){x1,x2}03.55701.53.502x3x4得距离阵 D(1)类与类的最短距离是1.5,故把X3与X4合并为一类,计算类与类之间距离(最长距离法)得距离阵D(2){x1,x2}057{x3,x4}x5类与类的最短距离是3.5,故把{X3,X4}与X5合并为一类,计算类与类之间距离(最{x1,x2}07长距离法)得距离阵D(3)分类与聚类图(略)(请你们自己做)3、设变量X1,X2,X3的相关阵为0.631.000.350.35,R的特征值和单位化特征向量分别为TTT(1)取公共因子个数为2,求因子载荷阵A。
应用多元统计分析课后习题答案高惠璇第四章部分习题解答市公开课获奖课件省名师示范课获奖课件

0
2
)
3 2
(ˆ
2
)
3 2
ˆ 2 ˆ 0 2
3
2
V
3 2
下列来讨论与V等价旳统计量分布:
ˆ 2
1 3
( y1
aˆ)2
( y2
2aˆ
bˆ)2
( y3
aˆ
2bˆ)2
1 3
( y1
yˆ1 ) 2
( y2
yˆ2 )2
( y3
yˆ3 )2
1 3
(Y
Xˆ )(Y
Xˆ )
1Y 3
(I3
X
(
X
X
)1
Q(β)=(Y-Cβ) '(Y-Cβ) . 试证明β^=(C'C)-1C'Y是在下列四种意义下达最小:
(1) trQ(β^)≤trQ(β) (2) Q(β^)≤Q(β) (3) |Q(β^)|≤|Q(β)|
(4) ch1(Q(β^))≤ch1(Q(β)),其中ch1(A)表达A
旳最大特征值. 以上β是(m+1)×p旳任意矩阵.
[(
y1
aˆ0
)2
]
0
可得
ˆ
2
1 3
( y1
aˆ0 )2
( y2
aˆ0 )2
( y3
3aˆ0 )2
drf
ˆ
2 0
似然比统计量旳分子为
L(aˆ0
,ˆ
2 0
)
(2
)
3 2
(ˆ 0 2
)
3 2
exp[
3 2
].
5
第四章 回归分析
似然比统计量为
L(aˆ0 ,ˆ02 ) L(aˆ,bˆ,ˆ 2 )
应用多元统计分析课后习题答案高惠璇部分习题解答(00004)市公开课金奖市赛课一等奖课件

第四章部分习题解答
第1页
1
第四章 回归分析
4-1
设
y1 y2
a 2a
1,
b
2
,
y3 a 2b 3,
1
2 3
~
N 3 (0,
2I3 ),
(1) 试求参数a,b
解:用矩阵表示以上模型:
则
Y
y1 y2 y3
1
2 1
201
a b
1 2 3
def
X
ˆ
aˆ bˆ
3
exp
1
2 2
[( y1 a0 )2
( y2
a0 )2
( y3
3a0 )2 ]
第4页
4
第四章 回归分析
令
L(a0 ,
a0
2)
L(a0 ,
2
)
2
2
2
[(
y1
a0
)
(
y2
a0 )
3(
y3
3a0
)
0
可得 令
ln
aˆ0
1 11
L(aˆ0 , 2 )
2
( y1
y2 3y3 )
3
2
2
令
ln L
2
3
2
2
1
2( 2 )2
[( y1
aˆ)2
]
0
可得
ˆ 2
1 3
( y1
aˆ)2
( y2
2aˆ
bˆ)2
( y3
aˆ
2bˆ)2
似然比统计量分母为
L(aˆ, bˆ,ˆ
2
)
(2
(完整版)多元统计分析课后练习答案
第1章 多元正态分布1、在数据处理时,为什么通常要进行标准化处理?数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。
在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
其中最典型的就是0-1标准化和Z 标准化。
2、欧氏距离与马氏距离的优缺点是什么?欧氏距离也称欧几里得度量、欧几里得度量,是一个通常采用的距离定义,它是在m 维空间中两个点之间的真实距离。
在二维和三维空间中的欧氏距离的就是两点之间的距离。
缺点:就大部分统计问题而言,欧氏距离是不能令人满意的。
每个坐标对欧氏距离的贡献是同等的。
当坐标表示测量值时,它们往往带有大小不等的随机波动,在这种情况下,合理的方法是对坐标加权,使变化较大的坐标比变化较小的坐标有较小的权系数,这就产生了各种距离。
当各个分量为不同性质的量时,“距离”的大小与指标的单位有关。
它将样品的不同属性之间的差别等同看待,这一点有时不能满足实际要求。
没有考虑到总体变异对距离远近的影响。
马氏距离表示数据的协方差距离。
为两个服从同一分布并且其协方差矩阵为Σ的随机变量与的差异程度:如果协方差矩阵为单位矩阵,那么马氏距离就简化为欧氏距离,如果协方差矩阵为对角阵,则其也可称为正规化的欧氏距离。
优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关。
由标准化数据和中心化数据计算出的二点之间的马氏距离相同。
马氏距离还可以排除变量之间的相关性的干扰。
缺点:夸大了变化微小的变量的作用。
受协方差矩阵不稳定的影响,马氏距离并不总是能顺利计算出。
3、当变量X1和X2方向上的变差相等,且与互相独立时,采用欧氏距离与统计距离是否一致?统计距离区别于欧式距离,此距离要依赖样本的方差和协方差,能够体现各变量在变差大小上的不同,以及优势存在的相关性,还要求距离与各变量所用的单位无关。
如果各变量之间相互独立,即观测变量的协方差矩阵是对角矩阵, 则马氏距离就退化为用各个观测指标的标准差的倒数作为权数的加权欧氏距离。
北大《多元统计分析》答案10页word文档
第二章 多元正态分布及参数的估计2-1 解:利用性质2, 得二维随机向量Y~N 2(μy ,∑y ),其中:2-2 (1)证明:记Y 1= X 1 +X 2 =(1,1) X , Y 2= X 1-X 2= (1,﹣1) X ,利用性质2可知Y 1 , Y 2 为正态随机变量. 又 故X 1 +X 2和X 1-X 2相互独立.另证:记112121221111Y X X X Y CX Y X X X +⎛⎫⎛⎫⎛⎫⎛⎫==== ⎪ ⎪ ⎪ ⎪--⎝⎭⎝⎭⎝⎭⎝⎭,则2~(,),Y N C C C μ∑'因故由定理2.3.1可得X 1 +X 2和X 1-X 2相互独立.(2)解:因为1212221212210021()~,()X X Y N X X μμρσμμρ⎛⎫+++⎛⎫⎛⎫⎛⎫= ⎪ ⎪ ⎪ ⎪---⎝⎭⎝⎭⎝⎭⎝⎭ 所以22121212122121~(,()),~(,()).X X N X X N μμσρμμσρ+++---2-3 (1)证明:令121122()()()()()()pp pp I I X X X Y CX I I X X X ⎛⎫⎛⎫⎛⎫+=== ⎪ ⎪ ⎪⎪--⎝⎭⎝⎭⎝⎭,则2~(,)p Y N C C C μ∑'. 因为由定理2.3.1可知X (1) +X (2)和X (1) -X (2) 相互独立. (2)解:因为 所以2-6 解:(1)记B =(3,-1,1), 由性质2得,~(,')Y BX N B B B μ=∑.(2)令1132'X Y X a X ⎡⎤=-⎢⎥⎣⎦, 显然31,X Y 均服从正态分布, 故要使它们相互独立,只需()31,0COV X Y =即可. 又因∴1222a a +=,故当(1,0.5)a =时满足条件. 2-9 解:(1)∴A 是正交矩阵.(2)①由Y =AX知,11/1/1/1/2Y X X ⎡==⎣ ,且所以②由2444(,)X N I μσ1: ,Y =AX 知:2444(,')Y N A AI A μσ1:.而22244''AI A AA I σσσ==,故由定理2.3.1的推论2知1234,,,Y Y Y Y 相互独立.③由②知1234,,,Y Y Y Y 均服从正态分布,且方差均为2σ ,又41/1/1/1/121/1/0010101/1/2/0101/1/1/3/A μμμ⎡⎤⎡⎤⎡⎤⎢⎥⎢⎥⎢⎥-⎢⎥⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥-⎢⎢⎥⎢⎥⎢⎣⎦⎣⎦-⎣1 所以221~(2,),~(0,)(2,3,4).i Y N Y N i μσσ=2-11解:设221212121211(,)exp (22221465)22f x x x x x x x x π⎧⎫=-++--+⎨⎬⎩⎭2222211121122122222121[()2()()()]2(1)x x x x σμσσρμμσμσσρ⎧⎫=-----+-⎨⎬-⎩⎭比较上下式相应的系数,可得:1222112212122221121222212211212121122222214265σσσσρσσμσρσσμμσρσσμμσμσρσσμμ⎧=⎪=⎪⎪=⎪-=⎨⎪-+=-⎪⎪-+=-⎪+-=⎩ ⎪⎪⎪⎪⎪⎪⎪⎪⎨⎧=-+-=+--=+-=-===-65214222222112112222121212221221212122221μμσρσσμσμμσρσσμμσρσσμσρσσσρσσ比较上下式相应的系数,可得:⎪⎩⎪⎨⎧-===2/11212ρσσ⎩⎨⎧24μμ⎨⎧μμ解得:121211/43σσρμμ=⎧⎪=⎪⎪⎨=-⎪=⎪⎪=⎩,所以2111222122411,312μσρσσμμρσσσ-⎛⎫⎛⎫⎛⎫⎛⎫==∑==⎪ ⎪ ⎪ ⎪-⎝⎭⎝⎭⎝⎭⎝⎭. 2-13解:(1)[]()()'(')'(')'ΣE X EX X EX E XX EXEX E XX μμ=--=-=-Q (2)()()()(')tr 'tr 'tr 'E X AX E X AX E AXX E AXX ===⎡⎤⎡⎤⎣⎦⎣⎦()()tr 'tr 'tr()tr(')tr()tr(')tr()'.AE XX A ΣA ΣA ΣA A ΣA A μμμμμμμμ==+=+⎡⎤⎡⎤⎣⎦⎣⎦=+=+(3)∵22'2'1tr()=tr ()()=tr p p p p p p p ΣA I I I p p σσσ⎛⎫⎡⎤-- ⎪⎢⎥⎣⎦⎝⎭1111 又'2'''11'()'()()()p p p p p p p p p p p A a I a a p pμμ=-=-1111111111 2-18解:(1)()()1111()()().nnnni i i i i i i i i i E Z E c X c EX c c μμμ=========∑∑∑∑(2)∵Z 为p 维正态随机向量的线性组合,故Z 也为正态随机向量,又 22()()111()()()'nnni i i i i i i i D Z D c X c DX c Σc c Σ=======∑∑∑, 结合(1)知 ~(,').p Z N c c Σμ(3)∵22221212()1n nc c c c c c n n++++++≥=L L ,且Σ为非负定矩阵 ∴对任意p 维向量0x ≠,有2111111''()'()'''''0,n n n i i x c c Σ-Σx x c c Σ-Σx c c -x Σx c -x Σx n n n n n =⎛⎫⎛⎫⎛⎫⎛⎫===≥ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭⎝⎭∑11即1n c n=1 时,Z 的协方差阵在非负定意义下达到极小.第三章 多元正态总体参数的假设检验3-1解:因为A 对称幂等阵,而对称幂等阵的特征值非0即1,且只有r 个非0特征值,即存在正交阵Γ(其列向量i r 为相应特征向量),使⎥⎦⎤⎢⎣⎡=ΓΓ'000t I A ,记),,(1n r r Λ=Γ,令X Y Y Y n Γ'=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=M 1(即Y X Γ=), 则),(),(~22n n n n I N I N Y σμσμΓ'=ΓΓ'Γ', 因为),,2,1)(,(~2r i r N Y i i Λ='σμ,且相互独立,所以∑=='=ti i r X Y AX X 12222),(~11δσσξ, 其中非中心参数为 3-2解:记()rank A r =.① 若n r =,由O AB =,知n n O B ⨯=,于是AX X '与BX X '相互独立; ② 若0=r 时,则0=A ,则两个二次型也是独立的. ③以下设0r n <<.因A 为n 阶对称阵,存在正交阵Γ,使得 其中0λ≠为A 的特征值1(,,)i r =L .于是令11122122,n nH H H =Γ'B ΓH H ⨯⎡⎤⎢⎥⎣⎦@其中11H 为r 阶方阵, 由于111211122122r r r H H D D H D H AB =ΓΓ'ΓΓ'H H ⎡⎤⎡⎤⎡⎤==⎢⎥⎢⎥⎢⎥⎣⎦⎣⎦⎣⎦000000, 故11120,0r r D H D H ==. 又因r D 为满秩阵,故有1112()0,0r r r n r H H ⨯⨯-==. 由于H 为对称阵,所以21()0n r r H -⨯=.于是 2200,0H =Γ'B ΓH ⎡⎤=⎢⎥⎣⎦ 令H X Γ'=,则2~(,)n n Y N I μσΓ',且21'()rr i i i D X AX Y A Y Y A Y Y Y Y ξλ=⎡⎤'''''==ΓΓ=ΓΓ==⎢⎥⎣⎦∑000, 由于11,,,,,r r n Y Y Y Y +L L 相互独立,故AX X '与BX X '相互独立..3-11解:这是两总体均值向量的检验问题. 检验统计量取为(p =3,n =6,m =9): 其中故检验统计量为用观测数据代入计算可得: 25.3117, 1.4982,T F ==显著性概率值 0.26930.05p α=>= 故H 0相容.第五章 判别分析5-1 解:由题意,其错判概率为5-2 解:由题意(1)样品x 与三个总体21,G G 和3G 的马氏距离分别为显然,{})()(),(),(min 23232221x d x d x d x d =,则3G x ∈,即样品5.2=x 应判归总体3G .(2)样品x 与三个总体21,G G 和3G 的贝叶斯距离分别为显然,{})()(),(),(min 21232221x D x D x D x D =,则1G x ∈,即样品5.2=x 应判归总体1G .5-4解:(1)可取121812207385123275537A -⎛⎫⎛⎫⎛⎫=∑+∑=+= ⎪ ⎪ ⎪-⎝⎭⎝⎭⎝⎭(组内) ()(1)(2)(1)(2)1020100100()()10,101525100100B μμμμ-⎛⎫⎛⎫'=--=--= ⎪ ⎪-⎝⎭⎝⎭(组间) 类似于例5.3.1的解法, A -1B 的特征根就等于2(1)(2)1(1)(2)3751016500()()(10,10) 4.70675381013811381d A μμμμ---⎛⎫⎛⎫'=--=--== ⎪⎪--⎝⎭⎝⎭取1(1)(2)321()33a A d μμ-⎛⎫=-= ⎪⎝⎭,则1a Aa '=, 且a 满足:2().Ba Aa d λλ==判别效率:() 4.7067a Baa a Aaλ'∆===', Fisher 线性判别函数为:12()33)u X a X X X '==+ 判别准则为*1*2()()X G u X u X G u X u ⎧∈>⎨∈≤⎩判当判当,阈值为(1)(2)*21124.2964u u u σσσσ+==-+,其中 故(1)(2)u u >.当(1)2020X ⎛⎫= ⎪⎝⎭时,(1)20() 4.339020u X ⎛⎫==- ⎪⎝⎭ 因*(1)() 4.3390u X u =-<,∴判(1)2X G ∈. 当(1)1520X ⎛⎫= ⎪⎝⎭时,(2)15() 3.805020u X ⎛⎫==- ⎪⎝⎭因*(2)() 3.8050u X u =->,∴判(2)1.X G ∈ (2) )(10)(75)1|2()()2|1()()()()()1(1)1(2)1(11)1(22)1(2)1(1)1(X f X f L X f q L X f q X h X h X W ===故,2)1(G X ∈ )2()2(G X ∈.(3)122'1112010181220101812()()ln ||()()ln 2015123220151232D x d x Σ-⎡⎤⎡⎤⎡⎤⎡⎤⎡⎤=+=--+⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦⎣⎦⎣⎦⎣⎦⎣⎦5-5 解:2()()()()a d a d a d a a Sa a Sa ''''∆==''(1)(2)(1)(2)def 1()()a X X X X a a Baa Sa a Saλ'''--==≤''又1(1)(2)(1)(2)12(1)(2)1(1)(2)()()()()S B X X X X S D X X S X X ---''=--=--,与有相同的特征值. 故21D λ=;以下验证a 就是D 2对应的一个特征向量:5-6 解:记(1)(2)(),()()W X X a μμμ'-=-是X 的线性函数, 其中11()~(0,1).W X U N νσ-=其中22()~(0,1).W X U N νσ-=第六章 聚类分析6-2证明:设变量X i 和X j 是二值变量,它们的n 次观测值记为x ti , x tj (t =1,…,n ). x ti , x tj 的值为0 or 1.由二值变量的列联表(表6.5)可知:变量X i 取值1的观测次数为a +b,取值0的观测次数为c +d ;变量X i 和X j 取值均为1的观测次数为a,取值均为0的观测次数为d .利用两定量变量相关系数的公式:()()ntii tj j ij xx x x r --=∑又故二值变量的相关系数为: 利用两定量变量夹角余弦的公式:其中1,nti tj t x x a ==∑2211,n ntitj t t x a b x a c ===+=+∑∑故有(9)cos ijij c α==.6-3解:用最长距离法:① 合并{X (1),X (4)}=CL4,并类距离 D 1=1.(2)0X ⎛⎫ ⎪② 合并{X (2),X (5)}=CL3,并类距离 D 2=3. ③ 合并{CL3,CL4}=CL2,并类距离 D 3=8. ④ 所有样品合并为一类CL1,并类距离 D 4=10.最长距离法的谱系聚类图如下: 用类平均聚类法:① 合并{X (1),X (4)}=CL4,并类距离 D 1=1. ② 合并{X (2),X (5)}=CL3,并类距离 D 2=3. ③ 合并{CL3,CL4}=CL2,并类距离 D 3=(165/4)1/2.④ 所有样品合并为一类CL1,并类距离 D 4=(121/2)1/2. 类平均法的谱系聚类图如下:6-6解:按中间距离法, 取β=-1/4,将B 和C 合并为一类后,并类距离D 1=1,而A 与新类G r ={B,C}的类间平方距离为当把A 与{B ,C}并为一类时,并类距离210.9221D D ==<= 故中间距离法不具有单调性。
多元统计分析
多元统计分析多元统计分析习题集(⼀)⼀、填空题1.若()(,),(1,2,,)p X N n αµα∑= 且相互独⽴,则样本均值向量X 服从的分布是____________________。
2.变量的类型按尺度划分为___________、____________、_____________。
3.判别分析是判别样品_____________的⼀种⽅法,常⽤的判别⽅法有_____________、_____________、_____________、_____________。
4.Q 型聚类是指对_____________进⾏聚类,R 型聚类指对_____________进⾏聚类。
5.设样品12(,,,),(1,2,,)i i i ip X X X X i n '== ,总体(,)p X N µ∑ ,对样品进⾏分类常⽤的距离有____________________、____________________、____________________。
6.因⼦分析中因⼦载荷系数ij a 的统计意义是_________________________________。
7.主成分分析中的因⼦负荷ij a 的统计意义是________________________________。
8.对应分析是将__________________和__________________结合起来进⾏的统计分析⽅法。
9.典型相关分析是研究__________________________的⼀种多元统计分析⽅法。
⼆、计算题 1.设3(,)X N µ∑ ,其中410130002?? ?∑= ? ??,问1X 与2X 是否独⽴?12(,)X X '与3X 是否独⽴?为什么?2.设抽了5个样品,每个样品只测了⼀个指标,它们分别是1,2,4.5,6,8。
若样品间采⽤绝对值距离,试⽤最长距离法对其进⾏分类,要求给出聚类图。
多元统计分析习题答案
多元统计分析习题答案多元统计分析习题答案多元统计分析是一种应用广泛的统计方法,用于研究多个变量之间的关系。
在实际应用中,我们常常会遇到一些多元统计分析的习题,通过解答这些习题可以更好地理解和掌握多元统计分析的方法和技巧。
下面我将为大家提供一些多元统计分析习题的答案,希望对大家的学习有所帮助。
1. 在一个实验中,研究者想要探究三种不同的肥料对植物生长的影响。
他们随机选取了30个样本,将它们分为三组,分别施加不同的肥料。
最后测量了每个样本的植物高度、叶片数量和花朵数量。
请问该如何分析这个实验的数据?答案:这是一个多元方差分析(MANOVA)问题。
由于我们有三个不同的肥料处理组,每个组有三个观测变量(植物高度、叶片数量和花朵数量),所以我们可以使用MANOVA来分析这个实验的数据。
MANOVA可以同时考虑多个因变量之间的差异,并判断这些差异是否显著。
2. 一个公司想要了解员工的满意度与工资、工作时长以及晋升机会之间的关系。
他们随机选取了100个员工,并收集了他们的满意度得分、工资水平、工作时长和晋升机会的数据。
请问该如何分析这个问题的数据?答案:这是一个多元回归分析问题。
我们可以使用多元回归分析来探究员工的满意度与工资、工作时长以及晋升机会之间的关系。
满意度得分可以作为因变量,而工资水平、工作时长和晋升机会可以作为自变量。
通过多元回归分析,我们可以得出各个自变量对于因变量的影响程度以及它们之间的相互关系。
3. 一家餐厅想要了解顾客满意度与菜品质量、服务质量和价格之间的关系。
他们随机选取了200个顾客,并要求他们对菜品质量、服务质量和价格进行评分。
请问该如何分析这个问题的数据?答案:这是一个主成分分析问题。
我们可以使用主成分分析来降维和提取数据中的主要信息。
首先,我们将菜品质量、服务质量和价格作为变量进行主成分分析,得到几个主成分。
然后,我们可以根据这些主成分的得分来评估顾客的满意度。
主成分分析可以帮助我们理解哪些因素对于顾客满意度的贡献最大。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
课程名称:多元统计回归分析
实验项目:多元方差分析
实验类型:验证性
学生学号:
学生姓名:
学生班级:
课程教师:
实验日期: 2016-04-18
.995 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 距跟踪
Wilks 的
.005 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 Lambda
Hotelling
215.561 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 的跟踪
Roy 的最
215.561 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 大根
A Pillai 的
.901 7.378 4.000 36.000 .000 .450 29.511 .991 跟踪
Wilks 的
.101 18.305(b) 4.000 34.000 .000 .683 73.221 1.000 Lambda
Hotelling
8.930 35.720 4.000 32.000 .000 .817 142.882 1.000
的跟踪
Roy 的最
8.928 80.356(c) 2.000 18.000 .000 .899 160.712 1.000
大根
B Pillai 的
.205 2.198(b) 2.000 17.000 .142 .205 4.397 .386 跟踪
Wilks 的
.795 2.198(b) 2.000 17.000 .142 .205 4.397 .386 Lambda
Hotelling
.259 2.198(b) 2.000 17.000 .142 .205 4.397 .386 的跟踪
Roy 的最
.259 2.198(b) 2.000 17.000 .142 .205 4.397 .386 大根
a 使用 alpha 的计算结果 = .05
b 精确统计量
c 该统计量是 F 的上限,它产生了一个关于显著性级别的下限。
d 设计: Intercept+A+B+A * B 误差方差等同性的 Leven
e 检验(a) F
df1
df2
Sig.
人均收入 .643 5 18 .670
文化程度
.615 5 18 .690
检验零假设,即在所有组中因变量的误差方差均相等。
a 设计: Intercept+A+B+A * B 4.实验结果分析
在“协方差矩阵等同性的 Box 检验(a)”中可以看出,p=0.887,大于0.05,故接受原假设,即认为方差是齐性的,可以进行方差分析。
* B
跟踪 .016 .071 4.000 36.000 .991 .008 .282 .063
Wilks 的 Lambda .984 .067(b) 4.000 34.000 .991 .008 .268 .062
Hotelling 的跟踪 .016 .063 4.000 32.000 .992 .008 .253 .061
Roy 的最大根
.016 .142(c) 2.000 18.000 .868 .016 .284 .069
截距Pillai 的
跟踪
.995 2020.700(b) 2.000 19.000 .000 .995 4041.400 1.000 Wilks 的
Lambda
.005 2020.700(b) 2.000 19.000 .000 .995 4041.400 1.000 Hotelling
的跟踪
212.705 2020.700(b) 2.000 19.000 .000 .995 4041.400 1.000 Roy 的最
大根
212.705 2020.700(b) 2.000 19.000 .000 .995 4041.400 1.000
A Pillai 的
跟踪
.900 8.176 4.000 40.000 .000 .450 32.702 .996 Wilks 的
Lambda
.102 20.265(b) 4.000 38.000 .000 .681 81.059 1.000 Hotelling
的跟踪
8.802 39.608 4.000 36.000 .000 .815 158.434 1.000
Roy 的最
大根
8.800 88.002(c) 2.000 20.000 .000 .898 176.004 1.000
B Pillai 的
跟踪
.205 2.457(b) 2.000 19.000 .112 .205 4.914 .433 Wilks 的
Lambda
.795 2.457(b) 2.000 19.000 .112 .205 4.914 .433 Hotelling
的跟踪
.259 2.457(b) 2.000 19.000 .112 .205 4.914 .433 Roy 的最
大根
.259 2.457(b) 2.000 19.000 .112 .205 4.914 .433
程
度
A 人
均
收
入
144.750 2 72.375 .957 .401 .087 1.915 .192
文
化
程
度
367.750 2 183.875 2.774 .086 .217 5.547 .484
B 人
均
收
入
384.000 1 384.000 5.080 .036 .203 5.080 .573
文
化
程
度
287.042 1 287.042 4.330 .051 .178 4.330 .508
误差人
均
收
入
1511.750 20 75.588
文
化
程
度
1325.833 20 66.292
总计人
均
收
入
98054.000 24
文
化
程
度
163849.000 24
校正的总计人
均
收
入
2040.500 23
文
化
程
度
1980.625 23
a 使用 alpha 的计算结果 = .05
b R 方 = .259(调整 R 方 = .148)
c R 方 = .331(调整 R 方 = .230)
主体间 SSCP 矩阵
人均收入文化程度
假设截距人均收入96013.500 124665.750 文化程度124665.750 161868.375
注:验证性实验仅上交电子文档,设计性试验需要同时上交电子与纸质文档进行备份存档。