曲线拟合和回归方程
标准曲线的回归方程

标准曲线的回归方程标准曲线的回归方程是统计学中常用的一种分析方法,它可以帮助我们找到一条最符合数据分布规律的曲线,从而进行数据预测和分析。
在实际应用中,标准曲线的回归方程被广泛应用于工程、经济、生物学等领域,具有重要的理论和实践价值。
首先,我们来了解一下标准曲线的回归方程的基本概念。
标准曲线是指一种特定形式的曲线,它通常是由一组数据点所构成的,而回归方程则是用来描述这条曲线的数学模型。
回归方程通常采用最小二乘法进行拟合,通过最小化实际观测值与回归方程预测值之间的误差来找到最佳拟合曲线。
在实际应用中,标准曲线的回归方程可以用来进行数据的拟合和预测。
通过对已有数据进行回归分析,我们可以得到回归方程,从而可以利用这个方程对未来的数据进行预测。
这对于工程和经济领域的决策和规划具有重要的意义,可以帮助我们更好地理解和预测数据的变化趋势。
此外,标准曲线的回归方程还可以用来进行数据的分析和解释。
通过回归方程,我们可以得到各个变量之间的相关性和影响程度,从而可以深入分析数据的内在规律。
这对于生物学和医学领域的研究具有重要的意义,可以帮助我们更好地理解生物和医学数据之间的关系。
在实际操作中,我们通常通过统计软件来进行标准曲线的回归分析。
统计软件可以帮助我们快速、准确地得到回归方程,并进行相关性检验和显著性检验,从而得出结论。
同时,统计软件还可以帮助我们对回归方程进行可视化展示,直观地呈现数据的拟合效果和预测结果。
总的来说,标准曲线的回归方程是一种重要的统计分析方法,它可以帮助我们更好地理解和预测数据的变化趋势,对于工程、经济、生物学等领域具有重要的应用价值。
通过对回归方程的分析和解释,我们可以更深入地理解数据之间的关系,为决策和规划提供科学依据。
因此,掌握标准曲线的回归方程分析方法对于提高数据分析能力和科研水平具有重要意义。
spss曲线拟合与回归分析
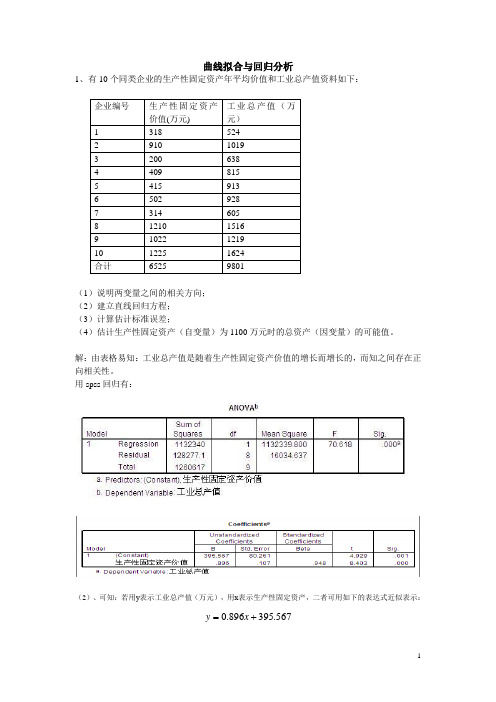
曲线拟合与回归分析1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:(1)说明两变量之间的相关方向;(2)建立直线回归方程;(3)计算估计标准误差;(4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能值。
解:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。
用spss回归有:(2)、可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示:=x.0+y.567395896(3)、用spss回归知标准误差为80.216(万元)。
(4)、当固定资产为1100时,总产值可能是(0.896*1100+395.567-80.216~0.896*1100+395.567+80.216)即(1301.0~146.4)这个范围内的某个值。
另外,用MATLAP也可以得到相同的结果:程序如下所示:function [b,bint,r,rint,stats] = regression1x = [318 910 200 409 415 502 314 1210 1022 1225];y = [524 1019 638 815 913 928 605 1516 1219 1624];X = [ones(size(x))', x'];[b,bint,r,rint,stats] = regress(y',X,0.05);display(b);display(stats);x1 = [300:10:1250];y1 = b(1) + b(2)*x1;figure;plot(x,y,'ro',x1,y1,'g-');industry = ones(6,1);construction = ones(6,1);industry(1) =1022;construction(1) = 1219;for i = 1:5industry(i+1) =industry(i) * 1.045;construction(i+1) = b(1) + b(2)* construction(i+1);enddisplay(industry);display( construction);end运行结果如下所示:b =395.56700.8958stats =1.0e+004 *0.0001 0.0071 0.0000 1.6035industry =1.0e+003 *1.02201.06801.11601.16631.21881.2736construction =1.0e+003 *1.2190 0.3965 0.3965 0.3965 0.3965 0.3965200400600800100012001400生产性固定资产价值(万元)工业总价值(万元)2、设某公司下属10个门市部有关资料如下:(1)、确定适宜的 回归模型; (2)、计算有关指标,判断这三种经济现象之间的紧密程度。
数学建模线性拟合求回归方程

摘要冬青是一种寄生在大树上部树枝的药科植物。
本文主要研究每株大树上冬青的数量与大树年龄之间的关系。
本文主要是运用两种方法,一是线性化模型求解,二是非线性模型求解。
1.线性化求解,由于题目中的数据对参数是非线性的,因此要通过两边取对数的方法转化为线性模型,即εln ln ln ++=bx a y模型中的因变量y ln 对新的参数A 、B 是线性的。
运用MATLAB 进行线性拟合因而得到A 、B 的值,从而得到a 、b 的值从而得到回归方程x b e a yˆˆˆ= 2.非线性模型求解,题目中的数据对参数是非线性的,因此可以用非线性回归的方法直接估计模型中的参数。
模型的求解可以用MATLAB 统计工具箱中的命令进行,使用格式为:[beta,R,J]=nlinfit(x,Y,'f1',beta0)Nlinfit 函数可以对给出的数据进行非线性回归,确定出参数的值,从而得到回归方程x b e a yˆˆˆ= 关键词: 线性回归 非线性回归 nlinfit一.问题重述冬青是一种寄生在大树上部树枝的药科植物,它喜欢寄生在年轻的大树上,以模型Y=εbx ae ,ln ε~N(0,2σ)拟合数据,试求曲线回归方程()x b a yˆex p ˆˆ=。
二.基本假设1.每株大树的生长环境是一样;2.影响大树上冬青寄生的株数的环境因素也是一样。
三.符号说明四.问题分析由数据绘制出散点图如下:以大树的年龄x 为自变量、以每株大树上冬青寄生的株数y 为因变量,利用MATLAB 统计工具箱的plot 命令画出散点图如图1,使用程序见附录程序1图1 散点图下面可以用εbx ae y =拟合数据。
其中ε为随机误差。
这个模型是非线性的,因此要通过两边取对数将其变成线性的,即bx a y ++=εln ln ln 。
可以将其看成是一元线性方程:εln ln ++=Bx A y 。
则y ln 对x 是线性的。
输出b 为a ln 和b 的估计值,bint 为b 的置信区间,stats 为回归模型的检验统计量,分别为回归方程的决定系数2R ,统计量值F ,概率值p 。
总氮检测标准曲线

总氮检测标准曲线总氮检测标准曲线是一种常用的分析方法,用于测量样品中总氮的含量。
标准曲线是通过一系列已知浓度的标准溶液进行测定,然后绘制出浓度与检测信号之间的关系曲线。
在实际测量中,通过样品的检测信号可以确定其总氮的浓度。
在绘制总氮检测标准曲线时,首先需要准备一系列已知浓度的标准溶液。
这些标准溶液的浓度应该覆盖待测样品的浓度范围。
一般情况下,标准溶液的浓度应该从较低浓度开始,逐渐增加到较高浓度。
标准曲线的制备过程中,一种常用的方法是通过原子吸收光谱仪等仪器测量标准溶液在特定条件下的吸光度或发射光强。
标准溶液的吸光度或发射光强与其浓度之间存在一定的关系,通过确定吸光度或发射光强与浓度之间的线性关系,就可以获得总氮检测的标准曲线。
标准曲线的绘制一般采用线性回归方法,常用的回归方程形式为:y = mx + b,其中y表示检测信号,x表示浓度,m表示曲线的斜率,b表示曲线的截距。
可以使用各种统计软件或工具进行曲线拟合和回归方程的求解。
标准曲线制备完成之后,就可以使用得到的回归方程来确定待测样品的总氮浓度。
测量待测样品的检测信号后,将信号代入回归方程即可计算出总氮的浓度。
绘制总氮检测标准曲线时,需要注意以下几点:1. 标准曲线的制备应该在相同的实验条件下进行,包括仪器的设置、样品的处理等。
2. 标准曲线的制备应该重复多次,以提高实验数据的可靠性和准确性。
3. 选择不同浓度的标准溶液时,应该根据待测样品的浓度范围进行选择,既要保证浓度的覆盖范围,又要避免过高或过低的浓度导致信号失真。
4. 在绘制标准曲线时,应该注意选择的浓度点应为线性范围内的点,以减少非线性对曲线的影响。
5. 标准曲线的斜率和截距需要进行统计分析,以评估曲线拟合的好坏程度,并确定曲线的相关性。
6. 绘制标准曲线时,要注意标记单位和坐标轴的刻度,以便于后续计算和数据处理。
总之,总氮检测标准曲线是一种重要的分析方法,在实际样品测量中具有广泛的应用。
Stata的曲线拟合

level ( # ) :指定假设检验的水准和可信区间的可信度
( obs = 7)
init ( …) :指定参数的初值 Inlsq ( # ) :指定按对数最小二乘法估计参数
Iteration 0 :residual S S = 24710226 …………
eps( # ) :指定收敛界限 ,缺省值为 le - 05 (0100001) 。
浓度增加时 ,细胞的增殖逐渐减弱 ,直至停止增殖 。结
合散点的趋势 , 本例选择过定点 (0 , 1) 的 logistic 回归
模型 :
y
=
1 +α 1 +αebx
该模型在 x = 0 时 , y = 1 ;当 x →∞时 , y →0 , 满足
资料提出的要求 。拐点为 ln
1 a
。
Stata 用于拟合任意曲线的程序基本结构是 :
曲线拟合是反映两变量间量变关系的重要手段 。 Stata 统计软件提供了 3 种曲线的拟合 , 另外给用户提 供了一个开发的空间 , 用户可根据自己的需要进行程 序设计 ,结合 Stata 提供的绘图功能 , 用户可得到精美 的拟合图 (本文图形即是用 Stata 完成的) 。
Stata 提供的曲线拟合
Iteration 8 :residual S S = 14150299
nolog :指定不打印迭代过程 。 trace :指定打印每次迭代的部分结果
Source Model
SS
df
1302165697
2
iterate ( # ) :指定最大迭代次数
Residual
1415029864
4
resid :在 nl pred 中指定计算残差而不是预测值
二次多项式回归方程

二次多项式回归方程二次多项式回归方程是一种常用的数学模型,用于拟合二次曲线形状的数据。
它是基于多项式回归的扩展,通过引入平方项的系数来更好地适应具有非线性关系的数据。
二次多项式回归方程的一般形式如下:y = ax^2 + bx + c其中,y表示因变量(依赖变量),x表示自变量(独立变量),a、b、c表示二次多项式回归方程的系数。
在二次多项式回归中,我们通常使用最小二乘法来估计系数的值。
该方法旨在使模型的预测值与实际观测值之间的平方差尽量小。
通过求解最小二乘问题,可以得到最佳拟合的二次多项式回归方程。
为了求解系数a、b、c,可以利用已知的数据点进行拟合。
首先,我们需要收集足够数量的自变量x和对应的因变量y的数据对。
然后,我们可以使用数值计算方法或者统计软件来估计系数的值。
一种常见的方法是使用最小二乘法拟合二次多项式回归方程。
这种方法的基本思想是,通过选择合适的系数值,使得二次多项式回归方程的预测值与已知数据点的观测值之间的残差平方和最小化。
残差表示了预测值与观测值之间的差异。
求解最小二乘问题可以使用线性代数的方法,例如矩阵运算或者求解线性方程组。
具体步骤如下:1. 将数据点表示为矩阵形式:X = [x^2, x, 1]Y = [y]2. 使用最小二乘法的公式计算系数向量:θ = (X^T X)^-1 X^T Y其中,X^T表示X的转置,(X^T X)^-1表示X^T X的逆矩阵。
3. 得到系数向量后,可以得到二次多项式回归方程:y = θ[0]x^2 + θ[1]x + θ[2]这样,我们就得到了二次多项式回归方程,并可以使用该方程进行预测或拟合。
需要注意的是,二次多项式回归方程在某些情况下可能会产生过拟合的问题。
过拟合指的是模型过度拟合训练数据,导致在新数据上的表现不如预期。
为了解决过拟合问题,可以考虑使用正则化技术,如岭回归或Lasso回归,来减小高次项的系数。
另外,二次多项式回归方程也可以进一步扩展为更高阶的多项式回归方程,以适应更复杂的数据模式。
求回归方程

求回归方程
回归方程是统计学中一个重要的概念,它描述了两个或多个变量之间的关系。
在实际应用中,我们经常需要使用回归方程来预测未来的趋势或者解释数据之间的关系。
因此,求回归方程是非常重要的。
求回归方程的方法有很多种,其中最常用的是最小二乘法。
这种方法就是通过寻找一条最能够拟合数据的直线或曲线来确定回归方程。
具体来说,我们需要找到一条直线或曲线,使得它与数据点的距离的平方和最小。
在实际应用中,我们经常需要使用回归方程来预测未来的趋势或者解释数据之间的关系。
例如,我们可以使用回归方程来预测股票价格的走势,或者分析销售额与广告投入之间的关系。
除了最小二乘法,还有其他的方法可以求回归方程,例如岭回归和lasso回归等。
这些方法都有各自的优缺点,适用于不同的情况。
在实际应用中,我们还需要注意回归方程的可靠性和精度。
如果回归方程的可靠性较低,那么它的预测能力也会受到影响。
因此,我们需要对数据进行充分的分析和处理,以确保回归方程的可靠性和精度。
总之,求回归方程是统计学中非常重要的一环,它可以帮助我们预测未来的趋势或者解释数据之间的关系。
我们需要选择合适的方法,对数据进行充分的分析和处理,以确保回归方程的可靠性和精度。
- 1 -。
s型曲线回归方程

S型曲线回归方程:从概念到实践1.S型曲线回归方程的概念与特点S型曲线回归方程,或称为Sigmoid回归方程,是一种广泛使用的数学模型,特别是在生物学、医学和社会科学领域。
S型曲线描述了在饱和之前,随着自变量(通常是输入)的增加,因变量(通常是输出)的增长速率如何变化。
其特点是因变量最终会达到一个最大值或饱和点。
2.常见S型曲线及其对应的数学模型几种常见的S型曲线包括:⏹Logistic 函数:(y = \frac{1}{1 + e^{-x}})⏹Hyperbolic tangent:(y = \tanh(x))⏹Growth model:(y = \frac{a}{1 + e^{-x}})1.求解S型曲线回归方程的方法与步骤步骤如下:⏹收集数据:获取描述自变量和因变量之间关系的观察数据。
⏹数据清洗:处理缺失值、异常值和离群点。
⏹选择合适的S型曲线模型:根据数据特性选择合适的数学模型。
⏹参数估计:使用最小二乘法、梯度下降法等优化算法估计模型的参数。
⏹模型拟合:将选择的模型应用于数据,并观察其拟合效果。
⏹评估模型:使用R-squared、MSE等指标评估模型的性能。
1.应用场景举例及其实际意义举例来说,在生物学中,S型生长曲线可以描述生物种群随时间的变化,帮助理解种群的增长和生态学特性。
在社会学中,可以用S型曲线描述某种社会现象的普及程度,如新技术或新观念的采纳和传播。
2.曲线拟合优化技巧和参数选择为了提高模型的拟合效果,可以使用以下优化技巧:⏹选择正确的损失函数:损失函数决定了模型试图最小化的目标,比如均方误差(MSE)或者交叉熵等。
⏹正则化:这是一种防止模型过拟合的技术,通过对模型参数施加惩罚项来避免参数过大。
常用的正则化项包括L1正则化和L2正则化。
⏹参数选择:参数的选择应该根据具体情况进行,有时候需要做一些试验来找到最优的参数。
常见的参数选择方法有网格搜索和随机搜索。
1.异常值处理与敏感性分析方法在应用S型曲线回归时,需要对异常值进行处理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
曲线拟合和回归分析
学院:信息学院专业:电子信息科学与技术
姓名:文欢学号:20131060218
1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:
(1)说明两变量之间的相关方向;
答:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。
回归方程:y=395.567+0.896x
(2)建立直线回归方程;
答:若用y表示工业总产值(万元),用x2示生产性固定资产,二者可用如下的表达式近似表示:y=0.896x+395.567
(3)计算估计标准误差;
答:标准误差为80.216(万元)。
(4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能
值。
答:
当固定资产为1100时,
总产值:.(0.896*1100+395.567-80.216~0.896*1100+395.567+80.216)即
(1301.0~146.4)这个范围内的某个值。
function [b,bint,r,rint,stats] = regression1
x = [318 910 200 409 415 502 314 1210 1022 1225];
y = [524 1019 638 815 913 928 605 1516 1219 1624];
X = [ones(size(x))', x'];
[b,bint,r,rint,stats] = regress(y',X,0.05);%一元
线性回归
display(b); %以矩阵方式显示b
display(stats); %阵显示stats,用于检测回归模型的统计
量
x1 = [300:10:1250];
y1 = b(1) + b(2)*x1;
figure;
plot(x,y,'ro',x1,y1,'g-');
industry = ones(6,1);
construction = ones(6,1);
industry(1) =1022;
construction(1) = 1219;
for i = 1:5
industry(i+1) =industry(i) * 1.045;
construction(i+1) = b(1) + b(2)* construction(i+1);
end
display(industry);
display( construction);
end
运行结果如下所示:
>> regression1
b = %回归系数估计值
395.5670
0.8958
stats =
1.0e+04 *
0.0001 0.0071 0.0000 1.6035 industry =
1.0e+03 *
1.0220
1.0680
1.1160
1.1663
1.2188
1.2736 construction =
1.0e+03 *
1.2190
0.3965
0.3965
0.3965
0.3965
0.3965 ans =
395.5670
0.8958
2、设某公司下属10个门市部有关资料如下:
(1)、确定适宜的回归模型;
(2)、计算有关指标,判断这三种经济现象之间的紧密程度。
解:用spss进行回归分析:
;若用y,x1,x2分别表示销售利润率、职工平均销售额和流通费用水平,则通过以上的分析结果可知: y=-6.769+2.909x1+0.985x2;
并且由显著性水平可知:流通费用水平对销售利润率影响不大(0.131大于0.05),而职工平均销售额的显著性水平为0,说明它对销售利润率的影响很大。