第二章:数据预处理
第二章 数据采集与预处理 (教案与习题)
2 of 42
2.1大数据采集架构
第二章 数据采集与预处理
2.1.2 常用大数据采集工具
数据采集最传统的方式是企业自己的生产系统产生的数据,除上述生产系统中的数据外, 企业的信息系统还充斥着大量的用户行为数据、日志式的活动数据、事件信息等,越来越 多的企业通过架设日志采集系统来保存这些数据,希望通过这些数据获取其商业或社会价 值。
$sudo apt-get update
Apache Kafka需要Java运行环境,这里使用apt-get命令安装default-jre包,然后安装Java运行环境:
$sudo apt-get install default-jre
通过下面的命令测试一下Java运行环境是否安装成功,并查看Java的版本信息:
第2章 数据预处理
(3)计算变量
• 改变原始数据的分布形态 • 产生新的变量、信息
练习1
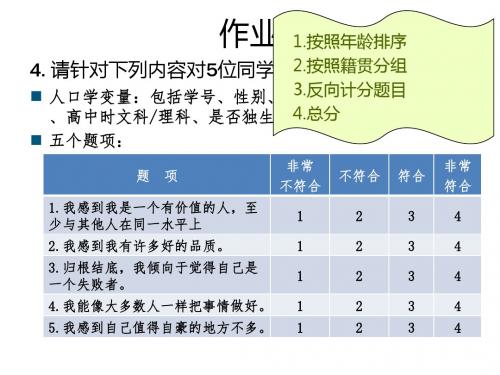
1.按照年龄排序 2.按照籍贯分组:省内/省外 4. 请针对下列内容对5位同学进行调查: 3.反向计分题目 人口学变量:包括学号、性别、年龄、籍贯(来自哪个省份) 4.总分 、高中时文科/理科、是否独生子女。
五个题项:
作业
2.基于表2-8(26页)完成2456题,简要写出完成 该操作的操作步骤。 3.简述变量重新编码的适用情况和保存方法。
2.1 数据菜单的预处理
• 选择个案
2.2 转换菜单的预处理
• 计算变量 • 变量重新编码 • 替换缺失值
(1)变量重新编码
• 反向计分题目 →具体数值的转换 • 分组次数分布 →数值范围的转换
(1)变量重新编码
• 重新编码为相同变量 • 重新编码为不同变量
(2)替换缺失值
• 替换缺失值是根据数据的分布类型和研究目的, 利用不同的方法将缺失的数据补充完整,使得原 始数据得到最大程度的利用。 • 默认“序列均值”
1
1 1 1 122 2 2233 3 3 3
4
4 4 4 4
第二章 SPSS的数据预处理
2.1 数据菜单的预处理 2.2 转换菜单的预处理
2.1 数据菜单的预处理
• 合并文件 • 排序个案 • 分类汇总 • 加权个案
2.1 数据菜单的预处理
• 排序个案
▫ 将已经录好的数据文件按照某个或某几个变量进行 排序。 ▫ 排序是对整个数据文件进行排序,排序完成保存后, 原有数据顺序被打乱,如果没有标识时间或顺序的 变量,很难恢复到原始数据状态。
题 项 非常 不符合 不符合 符合 非常 符合
1.我感到我是一个有价值的人,至 少与其他人在同一水平上 2.我感到我有许多好的品质。 3.归根结底,我倾向于觉得自己是 一个失败者。 4.我能像大多数人一样把事情做好。 5.我感到自己值得自豪的地方不多。
2第二章 数据预处理

数据变换(Data transformation)
规范化和聚集
数据归约(Data reduction)
减少数据的字段数目,但是仍然产生相同或者近似的分
析结果
数据离散化(Data discretization)
数据归约的一部分,但是对于数值性数据而言特别重要
数据预处理的形式
6
ECUST--Jing Zhang
Outlier(离群值): 通常为高于/低于 1.5 x IQR的值。
13
度量数据的离散程度
14
方差(Variance)和标准差(
Variance:
2
standard deviation)
(algebraic, scalable computation)
1 N
2
1 n 1 n 2 1 n 2 2 s xi ( xi ) ] ( xi x ) n 1[ n 1 i 1 n i 1 i 1
negatively skewed
Data Mining: Concepts and Techniques
September 14, 2011
度量数据的离散程度
极差(range),四分位数(Quartiles),
离群点
(outliers)和盒图( boxplots)
Range(极差): max()-min() Quartiles(四分位数): Q1 (25th percentile), Q3 (75th percentile)
其中 n 是 元组个数,p 和 q 分别是p 和 q 的平均值, σp 是 σq 分别是 p 和 q的标准差, Σ(pq) 是pq 叉积的和(即,对于每个元组,A的值 乘以该元组B的值)。
Microsoft Word - 第二章 数据预处理

由于数据库系统所获数据量的迅速膨胀(已达 或 数量级),从而导致了现实世界数据库中常常包含许多含有噪声、不完整( )、甚至是不一致( )的数据。
显然对数据挖掘所涉及的数据对象必须进行预处理。
那么如何对数据进行预处理以改善数据质量,并最终达到完善最终的数据挖掘结果之目的呢?数据预处理主要包括:数据清洗( )、数据集成( )、数据转换( )和数据消减( )。
本章将介绍这四种数据预处理的基本处理方法。
数据预处理是数据挖掘(知识发现)过程中的一个重要步骤,尤其是在对包含有噪声、不完整,甚至是不一致数据进行数据挖掘时,更需要进行数据的预处理,以提高数据挖掘对象的质量,并最终达到提高数据挖掘所获模式知识质量的目的。
例如:对于一个负责进行公司销售数据分析的商场主管,他会仔细检查公司数据库或数据仓库内容,精心挑选与挖掘任务相关数据对象的描述特征或数据仓库的维度( ),这包括:商品类型、价格、销售量等,但这时他或许会发现有数据库中有几条记录的一些特征值没有被记录下来;甚至数据库中的数据记录还存在着一些错误、不寻常( )、甚至是不一致情况,对于这样的数据对象进行数据挖掘,显然就首先必须进行数据的预处理,然后才能进行正式的数据挖掘工作。
所谓噪声数据是指数据中存在着错误、或异常(偏离期望值)的数据;不完整( )数据是指感兴趣的属性没有值;而不一致数据则是指数据内涵出现不一致情况(如:作为关键字的同一部门编码出现不同值)。
而数据清洗是指消除数据中所存在的噪声以及纠正其不一致的错误;数据集成则是指将来自多个数据源的数据合并到一起构成一个完整的数据集;数据转换是指将一种格式的数据转换为另一种格式的数据;最后数据消减是指通过删除冗余特征或聚类消除多余数据。
不完整、有噪声和不一致对大规模现实世界的数据库来讲是非常普遍的情况。
不完整数据的产生有以下几个原因:( )有些属性的内容有时没有,如:参与销售事务数据中的顾客信息;( )有些数据当时被认为是不必要的;( )由于误解或检测设备失灵导致相关数据没有记录下来;( )与其它记录内容不一致而被删除;( )历史记录或对数据的修改被忽略了。
数量生态学(第二版)第2章 数据处理

第二章数据的处理数据是数量生态学的基础,我们对数据的类型和特点应该有所了解。
在数量分析之前,根据需要对数据进行一些预处理,也是必要的。
本章将对数据的性质、特点、数据转化和标准化等做简要介绍。
第一节数据的类型根据不同的标准,数据可以分成不同的类型。
下面我们将介绍数据的基本类型,它是从数学的角度,根据数据的性质来划分的;然后叙述生态学数据,它是根据生态意义而定义的,不同的数据含有不同的生态信息。
一、数据的基本类型1、名称属性数据有的属性虽然也可以用数值表示,但是数值只代表属性的不同状态,并不代表其量值,这种数据称为名称属性数据,比如5个土壤类型可以用1、2、3、4、5表示。
这类数据在数量分析中各状态的地位是等同的,而且状态之间没有顺序性,根据状态的数目,名称属性数据可分成两类:二元数据和无序多状态数据。
(1)二元数据:是具有两个状态的名称属性数据。
如植物种在样方中存在与否,雌、雄同株的植物是雌还是雄,植物具刺与否等等,这种数据往往决定于某种性质的有无,因此也叫定性数据(qualitative data)。
对二元数据一般用1和0两个数码表示,1表示某性质的存在,而0表示不存在。
(2)无序多状态数据:是指含有两个以上状态的名称属性数据。
比如4个土壤母质的类型,它可以用数字表示为2、1、4、3,同时这种数据不能反映状态之间在量上的差异,只能表明状态不同,或者说类型不同。
比如不能说1与4之差在量上是1与2之差的3倍,这种数据在数量分析中用得很少,在分析结果表示上有时使用。
2.顺序性数据这类数据也是包含多个状态,不同的是各状态有大小顺序,也就是它一定程度上反映量的大小,比如将植物种覆盖度划为5级,1=0~20%,2=21%~40%,3=41%~60%,4=61%~80%,5=81%~100%。
这里1~5个状态有顺序性,而且表示盖度的大小关系。
比如5级的盖度就是明显大于1级的盖度,但是各级之间的差异又是不等的,比如盖度值分别为80%和81%的两个种,盖度仅差1%,但属于两个等级4和5;而另外两个盖度值分别为41%和60%,相差19%,但属于同一等级。
数据导入与预处理技术复习

数据导⼊与预处理技术复习数据导⼊与预处理技术复习笔记本⽂由本⼈学习过程中总结,难免有纰漏,欢迎交流学习第1章为什么需要数据处理本章内容将涵盖以下⼏个⽅⾯:为什么需要数据处理关于数据科学的六个简单处理步骤,包括数据清洗;与数据预处理相关的参考建议对数据清洗有帮助的⼯具⼀个关于如何将数据清洗融⼊整个数据科学过程的⼊门实例在数据分析、挖掘、机器学习或者是可视化之前,做好相关的数据预处理⼯作意义重⼤。
这个数据预处理的过程不是⼀成不变的,是⼀个迭代的过程,在实际的⼯作中,需要不⽌⼀次的执⾏数据预处理。
所采⽤的数据挖掘或分析⽅法会影响清洗⽅式的选取。
数据预处理包含了分析所需要的各种处理数据的任务:如交换⽂件的格式、字符编码的修改、数据提取的细节等。
数据导⼊、数据存储和数据清洗是数据预处理中密切相关的技术。
搜集原始数据->存储->数据清洗->存储->增量搜集数据->合并存储数据->数据挖掘(⼤数据、⼈⼯智能)->数据可视化;有三种处理⽅案可以选择:什么都不处理:忽略这些错误数据,直接开始构建线形图。
如果直接数据可视化,这样的结果是,有⽤的数据被掩盖了。
修正数据:算出错误消息的正确数据,采⽤修订后的数据集来可视化。
扔掉错误数据:放弃错误数据。
为了在选项⼆和三之间做个选择,计算错误数据实际上这些只占到了数据量的百分之⼀。
因此,选择选项三,扔掉这些数据。
利⽤Google的Spreadsheets能在初始数据中缺少⽇期的情况下,在x轴⾃动进⾏零值数据补齐,创建线性图或者条状图。
在以上的数据集中,需要补齐的零值就是所缺失的数据。
1.6 ⼩结从以上的实例看出,数据预处理占了整个过程的80%的⼯作量;数据预处理是数据科学过程的关键部分,不仅涉及对技术问题的理解,还需要做出相应的价值判断;第⼆章数据预处理为什么对数据进⾏预处理描述性数据汇总数据清理数据集成和变换数据归约离散化和概念分层⽣成脏数据不完整缺少数据值;缺乏某些重要属性;仅包含汇总数据;e.g., occupation=""有噪声包含错误或者孤⽴点e.g. Salary = -10数据不⼀致e.g., 在编码或者命名上存在差异e.g., 过去的等级: “1,2,3”, 现在的等级: “A, B, C”e.g., 重复记录间的不⼀致性e.g., Age=“42” Birthday=“03/07/1997”不完整数据的成因数据收集的时候就缺乏合适的值数据收集时和数据分析时的不同考虑因素⼈为/硬件/软件问题噪声数据(不正确的值)的成因数据收集⼯具的问题数据输⼊时的⼈为/计算机错误数据传输中产⽣的错误数据不⼀致性的成因不同的数据源违反了函数依赖性数据预处理为什么是重要的?没有⾼质量的数据,就没有⾼质量的挖掘结果⾼质量的决策必须依赖⾼质量的数据e.g. 重复值或者空缺值将会产⽣不正确的或者令⼈误导的统计数据仓库需要对⾼质量的数据进⾏⼀致地集成数据预处理将是构建数据仓库或者进⾏数据挖掘的⼯作中占⼯作量最⼤的⼀个步骤数据质量的多维度量⼀个⼴为认可的多维度量观点:精确度完整度⼀致性合乎时机可信度附加价值可解释性跟数据本⾝的含义相关的内在的、上下⽂的、表象的以及可访问性数据预处理的主要任务数据清理填写空缺的值,平滑噪声数据,识别、删除孤⽴点,解决不⼀致性数据集成集成多个数据库、数据⽴⽅体或⽂件数据变换规范化和聚集数据归约得到数据集的压缩表⽰,它⼩得多,但可以得到相同或相近的结果数据离散化数据归约的⼀部分,通过概念分层和数据的离散化来规约数据,对数字型数据特别重要基本统计类描述的图形显⽰常⽤的显⽰数据汇总和分布的⽅法:直⽅图、分位数图、q-q图、散布图和局部回归曲线直⽅图:⼀种单变量图形表⽰⽅法将数据分布划分成不相交的⼦集或桶,通常每个桶宽度⼀致并⽤⼀个矩形表⽰,其⾼度表⽰桶中数据在给定数据中出现的计数或频率数据清理任务填写空缺的值识别离群点和平滑噪声数据纠正不⼀致的数据解决数据集成造成的冗余空缺值数据并不总是完整的例如:数据库表中,很多条记录的对应字段没有相应值,⽐如销售表中的顾客收⼊引起空缺值的原因设备异常与其他已有数据不⼀致⽽被删除因为误解⽽没有被输⼊的数据在输⼊时,有些数据应为得不到重视⽽没有被输⼊对数据的改变没有进⾏⽇志记载空缺值要经过推断⽽补上如何处理空缺值忽略元组:当类标号缺少时通常这么做(假定挖掘任务设计分类或描述),当每个属性缺少值的百分⽐变化很⼤时,它的效果⾮常差。
Excel数据清洗与数据预处理教程

Excel数据清洗与数据预处理教程第一章:介绍Excel作为一款强大的数据处理工具,在数据分析和统计方面有着广泛的应用。
然而,原始数据通常存在各种问题,如重复数据、缺失值、错误数据等,这就需要对数据进行清洗和预处理,以保证数据的准确性和完整性。
本教程将介绍Excel数据清洗和数据预处理的基本技巧和方法,帮助读者更好地利用Excel进行数据处理。
第二章:去除重复值在数据清洗过程中,去除重复值是首要任务之一。
Excel提供了多种去除重复值的方式。
首先,可以使用“数据”菜单中的“删除重复项”功能来去除重复值。
其次,利用“排序”功能将数据按照一列或多列进行排序,并通过筛选功能选择非重复项。
此外,还可以使用Excel的公式函数和宏来实现自动去重,提高处理效率。
第三章:处理缺失值缺失值是数据中常见的问题之一。
Excel提供了多种方式来处理缺失值。
可以使用“查找与替换”功能,将缺失值替换为指定的数值或者删除包含缺失值的行或列。
此外,可以使用公式函数来识别和替换缺失值。
另外,利用数据透视表功能可以快速统计并填补缺失值,提高数据分析的准确性。
第四章:处理错误值错误值是数据清洗中需要处理的另一个问题。
Excel提供了多种处理错误值的方法。
首先,可以使用公式函数进行错误值的识别和替换。
例如,使用IF函数结合条件判断语句来判断错误值并替换或删除。
其次,可以使用数据透视表功能进行错误值的统计和处理,快速找出错误值所在的行或列。
此外,还可以使用条件格式设置对错误值进行标记,便于后续的处理和分析。
第五章:数据格式转换数据格式转换是数据预处理中一个重要环节。
Excel提供了丰富的数据格式转换功能。
通过选择单元格或选定一列,然后在“数据”菜单中选择“文本转列”功能,可以将数值格式转换为文本格式或者将文本格式转换为数值格式。
此外,还可以使用文本函数来进行数据格式转换,如将日期字符串转换为日期格式,将百分数字符串转换为数值格式等。
第六章:数据排序和筛选数据排序和筛选是数据清洗和预处理中常用的功能之一。
如何进行数据挖掘与分析

如何进行数据挖掘与分析数据挖掘与分析是指通过挖掘大量数据,发现其中的模式、关联、规律,并进行相应的分析和解释的过程。
这是一项涉及统计学、机器学习、数据库技术、数据可视化等多个领域的综合性工作。
本文将从数据获取、数据预处理、特征工程、模型选择和评估等方面介绍如何进行数据挖掘与分析。
## 第一章:数据获取数据获取是数据挖掘与分析的第一步,其质量和完整性直接影响后续分析的结果。
数据可以通过行业数据库、公共数据集、自主采集等方式获得。
在选择数据源时,需要考虑数据的可靠性、时效性和适用性。
同时,在获取数据之前,应详细了解数据的结构、格式和字段含义,为后续的预处理做好准备。
## 第二章:数据预处理数据预处理是对原始数据进行清洗、转换、集成和规约等操作,以减少数据的噪声、不一致性和冗余,提高后续分析的准确性和效率。
常用的数据预处理方法包括数据清洗、缺失值处理、异常值处理、数据变换等。
通过数据预处理,可以提高数据质量,并为数据挖掘和分析的进行打下基础。
## 第三章:特征工程特征工程是指通过对原始数据进行特征提取、降维和创造新特征等操作,以提取数据的有价值信息。
特征工程是数据挖掘与分析中的关键环节,直接影响模型的性能和结果的准确性。
常用的特征工程方法包括主成分分析(PCA)、线性判别分析(LDA)、特征选择、特征创造等。
通过特征工程,可以更好地表达数据,提高模型的泛化能力。
## 第四章:模型选择模型选择是在数据挖掘与分析中选择最合适的模型或算法。
常用的数据挖掘算法包括聚类算法、分类算法、回归算法等。
在模型选择过程中,需要根据具体的问题需求和数据特征来选择合适的模型。
同时,还需要考虑模型的复杂度、训练时间、解释性等因素。
通常可以通过交叉验证和评估指标来评估模型的性能和泛化能力。
## 第五章:模型评估模型评估是对数据挖掘与分析模型的性能进行评估和验证的过程。
常用的模型评估指标包括准确率、召回率、F1值、ROC曲线等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据可视化
2.0 认识数据 –
数据对象与属性类型
数据对象:数据集由数据对象组成,一个数据对象 代表一个实体
顾客、商品、患者 又称样本、实例、数据点、元组等
属性:表示数据对象的一个特征
维、特征、变量 一个给定对象的一组属性称作属性向量(特征向量) 属性的类型由该属性可能具有的值的集合决定
40 35 30 25 20 15 10 5 0
10000 20000 30000 40000 50000 60000 70000 80000 90000 100000
2.0 认识数据 –
数据基本统计描述
直方图能够比盒图展现更多的信息
这两个直方图具有相同的min, Q1, median, Q3, max
• 缺少数据值;缺乏某些重要属性;仅包含汇总数据
有噪声(noisy)
• • • 包含错误或者孤立点(outliers) e.g., 在编码或者命名上存在差异 e.g., Age=“42” Birthday=“03/07/1997”
数据不一致(inconsistent)
GIGO (Garbage in, garbage out)原理:No quality data, no
数类型
可用众数与中位数表示中心趋势
2.0 认识数据 –
可用整数或实数度量
数据对象与属性类型
数值属性(numeric attribute)
区间标度(interval-scaled)属性:用相同的单位尺度 度量。
• 可用众数、中位数、均值表示
比例标度(ratio-scaled)属性:可用倍数表示。
单峰的(unimodal,也叫单模态)、双峰的
(bimodal)、三峰的(trimodal);多峰的 (multimodal)
对于适度倾斜(非对称的)的单峰频率曲线,可以使 用以下经验公式计算众数
mean mode 3 (mean median)
2.0 认识数据 –
对称与正倾斜、负倾斜数 据的中位数、均值和众数
数据基本统计描述
分位数-分位数图(Q-Q 图):对着另一个单变 量的分位数,绘制一个单变量分布的分位数 允许用户观察是不是有从一个分布到另外一个分 布的迁移
Example shows unit price of items sold at Branch 1 vs. Branch 2 for each quantile. Unit prices of items sold at Branch 1 tend to be lower than those at Branch 2.
x
5 i 1
i
x
2
s
30.8 31.26
51
2
31.7 31.26 30.1 31.26 31.6 31.26 32.1 31.2 4
2 2 2
2.572 0.643 4 s2 0.643 0.8019
2.0 认识数据 –
标准差s是方差s2的平方根
标准差s是关于平均值的离散的度量,因此仅当选平均值做 中心度量时使用 所有观测值相同则 s=0,否则 s>0 方差和标准差都是均值:31.26
s
2
数据基本统计描述
例子:5个数据 30.8, 31.7, 30.1, 31.6, 32.1
e.g. 计算平均工资时,可以截掉上下各2%的值后计算 均值,以抵消少数极端值的影响
中位数:有序集的中间值或者中间两个值平均
整体度量;但是可以通过插值法计算近似值 当观测数据数量很大,中位数计算开销很大
2.0 认识数据 –
数据基本统计描述
众数(Mode,模):集合中出现频率最高的值
2.2 数据清洗
业界对数据清理的认识
“数据清理是数据仓库构建中最重要的问题”— DCI survey
数据清理任务
填写空缺值 识别离群点和平滑噪声数据 纠正不一致的数据 解决数据集成造成的冗余
2.2 数据清洗
空缺值
数据并不总是完整的
• 例如:数据库表中,很多条记录的对应字段没有相应值,比 如销售表中的顾客收入
2.0 认识数据 –
数据基本统计描述
左半部分是正相关 右半部分是负相关
2.0 认识数据 –
数据基本统计描述
不相关数据
本章内容
2.0 认识数据
2.1
2.2
为什么要预处理数据
数据清理
2.3
2.4
数据集成和变换
数据归约
2.1 为什么要预处理数据
现实世界的数据是“脏的”
不完整(incomplete)
数据挖掘
第二章:数据预处理
本章内容
2.0 认识数据
2.1
2.2
为什么要预处理数据
数据清理
2.3
2.4
数据集成和变换
数据归约
基本要求:了解数据质量问题及其对挖掘的影
响,掌握数据清理、集成和变换、归约等方法
2.0 认识数据
洞察数据有助于数据预处理与挖掘
数据由什么类型的属性或字段组成 属性具有何种类型的属性值 属性是离散的还是连续的 数据分布特性
2.0 认识数据 –
数据对象与属性类型
枚举类型(nominal attribute):分类类型
属性值域是一个由符号、事物构成的有限集合 头发颜色、婚姻状态、职业 不具备有意义的序、不是定量的
可用众数(mode)度量中心趋势
二元属性(binary attribute):布尔属性
数据基本统计描述
2.0 认识数据 –
数据基本统计描述
评估数值数据散布或发散的度量:极差、五数 概括(基于四分位数)、中间四分位数极差和 标准差
极差(range):数据集的最大值和最小值之差 百分位数(percentile):第k个百分位数是具有如下 性质的值x:k%的数据项位于或低于x • 中位数就是第50个百分位数 四分位数:Q1 (25th percentile), Q3 (75th percentile)
引起空缺值的原因
• • • • • 设备异常 与其他已有数据不一致而被删除 因为误解而没有被输入的数据 在输入时,有些数据应为得不到重视而没有被输入 对数据的改变没有进行日志记载
空缺值要经过推断而补上
2.2 数据清洗
如何处理空缺值
忽略元组:当类标号缺少时通常这么做(假定挖掘任务设 计分类或描述),当每个属性缺少值的百分比变化很大时, 它的效果非常差。 人工填写空缺值:工作量大,可行性低
Q3: $100
2.0 认识数据 –
数据基本统计描述
2.0 认识数据 –
数据基本统计描述
常用的显示数据汇总和分布的方法
直方图、分位数图、q-q图、散布图和局部回归曲线
直方图:一种单变量图形表示方法
将数据分布划分成不相交的子集或桶,通常每个桶宽度一致 并用一个矩形表示,其高度表示桶中数据在给定数据中出现 的计数或频率
只有两个类别与状态:0与1, true与false 对称的:两个状态分布或重要性相同。性别 非对称的:两个状态分布或重要性不是相同的。HIV 检验。
2.0 认识数据 –
数据对象与属性类型
序数类型(ordinal attribute)
属性值之间存在有意义的序,相继值之间差是定性的 大中小、职位、军衔 可通过把数值量的值域划分为有限个有序列性得到序
2.0 认识数据 –
数据基本统计描述
散布图:确定两个量化的变量之间看上去是否有联系、 模式或者趋势的最有效的图形方法之一 散布图中的每个值都被视作代数坐标对,作为一个点 画在平面上 易于观察双变量数据在平面上的分布
2.0 认识数据 –
数据基本统计描述
loess曲线为散布图添加一条平滑的曲线,以便更好 的观察两个变量间的依赖模式 Loess (local regression)意指“局部回归”,为了拟合 loess曲线,需要两个参数:平滑参数α ,被回归拟合 的多项式的阶λ
quality mining results!
2.1 为什么要预处理数据
广为认可的数据质量多维度量
精确度 可信度 可增值性 可解释性
完整度
一致性 时效性
可访问性
2.1 为什么要预处理数据
数据处理的主要任务
数据清理
• 填写空缺的值,平滑噪声数据,识别、删除孤立点,解决 不一致性 集成多个数据库、数据立方体或文件
但是它们具有不同数据分布
2.0 认识数据 –
数据基本统计描述
分位数图:一种利用分位数信息观察单变量数据 分布的简单有效方法 显示所有的数据,允许用户评估总的情况和不寻 常情况的出现
设xi是递增排序的数据,则每个xi都有相对应的fi,指 出大约有100 fi %的数据小于等于xi
2.0 认识数据 –
数据集成
•
数据变换
•
• •
规范化和聚集
得到数据集的压缩表示,但可得到相同或相近的结果 通过概念分层和数据离散化来规约数据,对数值型数据特 别重要
数据归约 数据离散化
2.1 为什么要预处理数据
本章内容
2.0 认识数据
2.1
2.2
为什么要预处理数据
数据清理
2.3
2.4
数据集成和变换
数据归约
2.0 认识数据 –
数据基本统计描述
五数概括: min, Q1, Median, Q3, max
盒图:数据分布的一种直观表示
方差和标准差
方差s2:n个观测之x1,x2...xn的方差是