数据结构实验五
数据结构实验五矩阵的压缩存储与运算学习资料

数据结构实验五矩阵的压缩存储与运算第五章矩阵的压缩存储与运算【实验目的】1. 熟练掌握稀疏矩阵的两种存储结构(三元组表和十字链表)的实现;2. 掌握稀疏矩阵的加法、转置、乘法等基本运算;3. 加深对线性表的顺序存储和链式结构的理解。
第一节知识准备矩阵是由两个关系(行关系和列关系)组成的二维数组,因此对每一个关系上都可以用线性表进行处理;考虑到两个关系的先后,在存储上就有按行优先和按列优先两种存储方式,所谓按行优先,是指将矩阵的每一行看成一个元素进行存储;所谓按列优先,是指将矩阵的每一列看成一个元素进行存储;这是矩阵在计算机中用一个连续存储区域存放的一般情形,对特殊矩阵还有特殊的存储方式。
一、特殊矩阵的压缩存储1. 对称矩阵和上、下三角阵若n阶矩阵A中的元素满足= (0≤i,j≤n-1 )则称为n阶对称矩阵。
对n阶对称矩阵,我们只需要存储下三角元素就可以了。
事实上对上三角矩阵(下三角部分为零)和下三角矩阵(上三角部分为零),都可以用一维数组ma[0.. ]来存储A的下三角元素(对上三角矩阵做转置存储),称ma为矩阵A的压缩存储结构,现在我们来分析以下,A和ma之间的元素对应放置关系。
问题已经转化为:已知二维矩阵A[i,j],如图5-1,我们将A用一个一维数组ma[k]来存储,它们之间存在着如图5-2所示的一一对应关系。
任意一组下标(i,j)都可在ma中的位置k中找到元素m[k]= ;这里:k=i(i+1)/2+j (i≥j)图5-1 下三角矩阵a00 a10 a11 a20 … an-1,0 … an-1,n-1k= 0 1 2 3 …n(n-1)/2 …n(n+1)/2-1图5-2下三角矩阵的压缩存储反之,对所有的k=0,1,2,…,n(n+1)/2-1,都能确定ma[k]中的元素在矩阵A中的位置(i,j)。
这里,i=d-1,(d是使sum= > k的最小整数),j= 。
2. 三对角矩阵在三对角矩阵中,所有的非零元素集中在以主对角线为中心的带内状区域中,除了主对角线上和直接在对角线上、下方对角线上的元素之外,所有其它的元素皆为零,见图5-3。
《数据结构》实验报告

苏州科技学院数据结构(C语言版)实验报告专业班级测绘1011学号10201151姓名XX实习地点C1 机房指导教师史守正目录封面 (1)目录 (2)实验一线性表 (3)一、程序设计的基本思想,原理和算法描述 (3)二、源程序及注释(打包上传) (3)三、运行输出结果 (4)四、调试和运行程序过程中产生的问题及采取的措施 (6)五、对算法的程序的讨论、分析,改进设想,其它经验教训 (6)实验二栈和队列 (7)一、程序设计的基本思想,原理和算法描述 (8)二、源程序及注释(打包上传) (8)三、运行输出结果 (8)四、调试和运行程序过程中产生的问题及采取的措施 (10)五、对算法的程序的讨论、分析,改进设想,其它经验教训 (10)实验三树和二叉树 (11)一、程序设计的基本思想,原理和算法描述 (11)二、源程序及注释(打包上传) (12)三、运行输出结果 (12)四、调试和运行程序过程中产生的问题及采取的措施 (12)五、对算法的程序的讨论、分析,改进设想,其它经验教训 (12)实验四图 (13)一、程序设计的基本思想,原理和算法描述 (13)二、源程序及注释(打包上传) (14)三、运行输出结果 (14)四、调试和运行程序过程中产生的问题及采取的措施 (15)五、对算法的程序的讨论、分析,改进设想,其它经验教训 (16)实验五查找 (17)一、程序设计的基本思想,原理和算法描述 (17)二、源程序及注释(打包上传) (18)三、运行输出结果 (18)四、调试和运行程序过程中产生的问题及采取的措施 (19)五、对算法的程序的讨论、分析,改进设想,其它经验教训 (19)实验六排序 (20)一、程序设计的基本思想,原理和算法描述 (20)二、源程序及注释(打包上传) (21)三、运行输出结果 (21)四、调试和运行程序过程中产生的问题及采取的措施 (24)五、对算法的程序的讨论、分析,改进设想,其它经验教训 (24)实验一线性表一、程序设计的基本思想,原理和算法描述:程序的主要分为自定义函数、主函数。
数据结构实验五(二叉树的建立及遍历)题目和源程序

实验5:二叉树的建立及遍历(第十三周星期三7、8节)一、实验目的1.学会实现二叉树结点结构和对二叉树的基本操作。
2.掌握对二叉树每种操作的具体实现,学会利用递归方法编写对二叉树这种递归数据结构进行处理的算法。
二、实验要求1.认真阅读和掌握和本实验相关的教材内容。
2.编写完整程序完成下面的实验内容并上机运行。
3.整理并上交实验报告。
三、实验内容1.编写程序任意输入二叉树的结点个数和结点值,构造一棵二叉树,采用三种递归遍历算法(前序、中序、后序)对这棵二叉树进行遍历并计算出二叉树的高度。
2 .编写程序生成下面所示的二叉树,并采用中序遍历的非递归算法对此二叉树进行遍历。
四、思考与提高1.如何计算二叉链表存储的二叉树中度数为1的结点数?2.已知有—棵以二叉链表存储的二叉树,root指向根结点,p指向二叉树中任一结点,如何求从根结点到p所指结点之间的路径?/*----------------------------------------* 05-1_递归遍历二叉树.cpp -- 递归遍历二叉树的相关操作* 对递归遍历二叉树的每个基本操作都用单独的函数来实现* 水上飘2009年写----------------------------------------*/// ds05.cpp : Defines the entry point for the console application.//#include "stdafx.h"#include <iostream>typedef char ElemType;using namespace std;typedef struct BiTNode {ElemType data;//左右孩子指针BiTNode *lchild, *rchild;}BiTNode, *BiTree;//动态输入字符按先序创建二叉树void CreateBiTree(BiTree &T) {char ch;ch = cin.get();if(ch == ' ') {T = NULL;}else {if(ch == '\n') {cout << "输入未结束前不要输入回车,""要结束分支请输入空格!" << endl;}else {//生成根结点T = (BiTNode * )malloc(sizeof(BiTNode));if(!T)cout << "内存分配失败!" << endl;T->data = ch;//构造左子树CreateBiTree(T->lchild);//构造右子树CreateBiTree(T->rchild);}}}//输出e的值ElemType PrintElement(ElemType e) { cout << e << " ";return e;}//先序遍历void PreOrderTraverse(BiTree T) { if (T != NULL) {//打印结点的值PrintElement(T->data);//遍历左孩子PreOrderTraverse(T->lchild);//遍历右孩子PreOrderTraverse(T->rchild);}}//中序遍历void InOrderTraverse(BiTree T) {if (T != NULL) {//遍历左孩子InOrderTraverse(T->lchild);//打印结点的值PrintElement(T->data);//遍历右孩子InOrderTraverse(T->rchild);}}//后序遍历void PostOrderTraverse(BiTree T) { if (T != NULL) {//遍历左孩子PostOrderTraverse(T->lchild);//遍历右孩子PostOrderTraverse(T->rchild);//打印结点的值PrintElement(T->data);}}//按任一种遍历次序输出二叉树中的所有结点void TraverseBiTree(BiTree T, int mark) {if(mark == 1) {//先序遍历PreOrderTraverse(T);cout << endl;}else if(mark == 2) {//中序遍历InOrderTraverse(T);cout << endl;}else if(mark == 3) {//后序遍历PostOrderTraverse(T);cout << endl;}else cout << "选择遍历结束!" << endl;}//输入值并执行选择遍历函数void ChoiceMark(BiTree T) {int mark = 1;cout << "请输入,先序遍历为1,中序为2,后序为3,跳过此操作为0:";cin >> mark;if(mark > 0 && mark < 4) {TraverseBiTree(T, mark);ChoiceMark(T);}else cout << "此操作已跳过!" << endl;}//求二叉树的深度int BiTreeDepth(BiTNode *T) {if (T == NULL) {//对于空树,返回0并结束递归return 0;}else {//计算左子树的深度int dep1 = BiTreeDepth(T->lchild);//计算右子树的深度int dep2 = BiTreeDepth(T->rchild);//返回树的深度if(dep1 > dep2)return dep1 + 1;elsereturn dep2 + 1;}}int _tmain(int argc, _TCHAR* argv[]){BiTNode *bt;bt = NULL; //将树根指针置空cout << "输入规则:" << endl<< "要生成新结点,输入一个字符,""不要生成新结点的左孩子,输入一个空格,""左右孩子都不要,输入两个空格,""要结束,输入多个空格(越多越好),再回车!"<< endl << "按先序输入:";CreateBiTree(bt);cout << "树的深度为:" << BiTreeDepth(bt) << endl;ChoiceMark(bt);return 0;}/*----------------------------------------* 05-2_构造二叉树.cpp -- 构造二叉树的相关操作* 对构造二叉树的每个基本操作都用单独的函数来实现* 水上飘2009年写----------------------------------------*/// ds05-2.cpp : Defines the entry point for the console application.//#include "stdafx.h"#include <iostream>#define STACK_INIT_SIZE 100 //栈的存储空间初始分配量#define STACKINCREMENT 10 //存储空间分配增量typedef char ElemType; //元素类型using namespace std;typedef struct BiTNode {ElemType data; //结点值BiTNode *lchild, *rchild; //左右孩子指针}BiTNode, *BiTree;typedef struct {BiTree *base; //在栈构造之前和销毁之后,base的值为空BiTree *top; //栈顶指针int stacksize; //当前已分配的存储空间,以元素为单位}SqStack;//构造一个空栈void InitStack(SqStack &s) {s.base = (BiTree *)malloc(STACK_INIT_SIZE * sizeof(BiTree));if(!s.base)cout << "存储分配失败!" << endl;s.top = s.base;s.stacksize = STACK_INIT_SIZE;}//插入元素e为新的栈顶元素void Push(SqStack &s, BiTree e) {//栈满,追加存储空间if ((s.top - s.base) >= s.stacksize) {s.base = (BiTree *)malloc((STACK_INIT_SIZE+STACKINCREMENT) * sizeof(BiTree));if(!s.base)cout << "存储分配失败!" << endl;s.top = s.base + s.stacksize;s.stacksize += STACK_INIT_SIZE;}*s.top++ = e;}//若栈不空,则删除s的栈顶元素,并返回其值BiTree Pop(SqStack &s) {if(s.top == s.base)cout << "栈为空,无法删除栈顶元素!" << endl;s.top--;return *s.top;}//按先序输入字符创建二叉树void CreateBiTree(BiTree &T) {char ch;//接受输入的字符ch = cin.get();if(ch == ' ') {//分支结束T = NULL;} //if' 'endelse if(ch == '\n') {cout << "输入未结束前不要输入回车,""要结束分支请输入空格!(接着输入)" << endl;} //if'\n'endelse {//生成根结点T = (BiTNode * )malloc(sizeof(BiTree));if(!T)cout << "内存分配失败!" << endl;T->data = ch;//构造左子树CreateBiTree(T->lchild);//构造右子树CreateBiTree(T->rchild);} //Create end}//输出e的值,并返回ElemType PrintElement(ElemType e) {cout << e << " ";return e;}//中序遍历二叉树的非递归函数void InOrderTraverse(BiTree p, SqStack &S) {cout << "中序遍历结果:";while(S.top != S.base || p != NULL) {if(p != NULL) {Push(S,p);p = p->lchild;} //if NULL endelse {BiTree bi = Pop(S);if(!PrintElement(bi->data))cout << "输出其值未成功!" << endl;p = bi->rchild;} //else end} //while endcout << endl;}int _tmain(int argc, _TCHAR* argv[]){BiTNode *bt;SqStack S;InitStack(S);bt = NULL; //将树根指针置空cout << "老师要求的二叉树序列(‘空’表示空格):""12空空346空空空5空空,再回车!"<< endl << "请按先序输入一个二叉树序列(可另输入,但要为先序),""无左右孩子则分别输入空格。
数据结构实验指导书(新版)
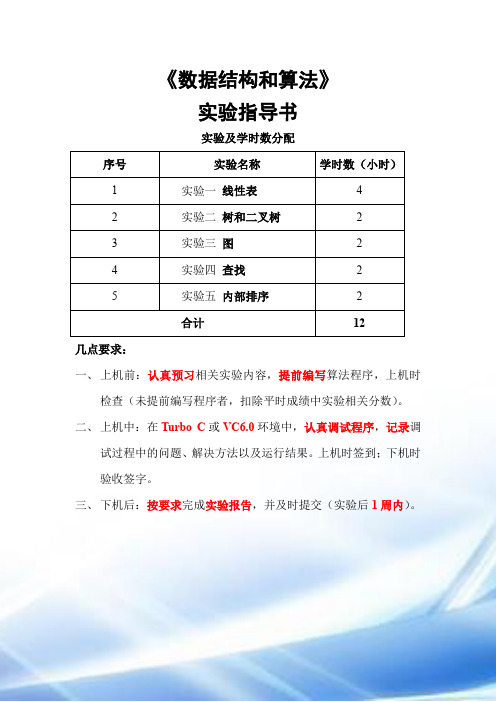
《数据结构和算法》实验指导书实验及学时数分配序号实验名称学时数(小时)1 实验一线性表 42 实验二树和二叉树 23 实验三图 24 实验四查找 25 实验五内部排序 2合计12几点要求:一、上机前:认真预习相关实验内容,提前编写算法程序,上机时检查(未提前编写程序者,扣除平时成绩中实验相关分数)。
二、上机中:在Turbo C或VC6.0环境中,认真调试程序,记录调试过程中的问题、解决方法以及运行结果。
上机时签到;下机时验收签字。
三、下机后:按要求完成实验报告,并及时提交(实验后1周内)。
实验一线性表【实验目的】1、掌握用Turbo c上机调试线性表的基本方法;2、掌握线性表的基本操作,插入、删除、查找以及线性表合并等运算在顺序存储结构和链式存储结构上的运算;3、运用线性表解决线性结构问题。
【实验学时】4 学时【实验类型】设计型【实验内容】1、顺序表的插入、删除操作的实现;2、单链表的插入、删除操作的实现;3、两个线性表合并算法的实现。
(选做)【实验原理】1、当我们在线性表的顺序存储结构上的第i个位置上插入一个元素时,必须先将线性表中第i个元素之后的所有元素依次后移一个位置,以便腾出一个位置,再把新元素插入到该位置。
若是欲删除第i个元素时,也必须把第i个元素之后的所有元素前移一个位置;2、当我们在线性表的链式存储结构上的第i个位置上插入一个元素时,只需先确定第i个元素前一个元素位置,然后修改相应指针将新元素插入即可。
若是欲删除第i个元素时,也必须先确定第i个元素前一个元素位置,然后修改相应指针将该元素删除即可;3、详细原理请参考教材。
【实验步骤】一、用C语言编程实现建立一个顺序表,并在此表中插入一个元素和删除一个元素。
1、通过键盘读取元素建立线性表;(从键盘接受元素个数n以及n个整形数;按一定格式显示所建立的线性表)2、指定一个元素,在此元素之前插入一个新元素;(从键盘接受插入位置i,和要插入的元素值;实现插入;显示插入后的线性表)3、指定一个元素,删除此元素。
数据结构试验报告-图的基本操作

中原工学院《数据结构》实验报告学院:计算机学院专业:计算机科学与技术班级:计科112姓名:康岩岩学号:201100814220 指导老师:高艳霞2012-11-22实验五图的基本操作一、实验目的1、使学生可以巩固所学的有关图的基本知识。
2、熟练掌握图的存储结构。
3、熟练掌握图的两种遍历算法。
二、实验内容[问题描述]对给定图,实现图的深度优先遍历和广度优先遍历。
[基本要求]以邻接表为存储结构,实现连通无向图的深度优先和广度优先遍历。
以用户指定的结点为起点,分别输出每种遍历下的结点访问序列。
【测试数据】由学生依据软件工程的测试技术自己确定。
三、实验前的准备工作1、掌握图的相关概念。
2、掌握图的逻辑结构和存储结构。
3、掌握图的两种遍历算法的实现。
四、实验报告要求1、实验报告要按照实验报告格式规范书写。
2、实验上要写出多批测试数据的运行结果。
3、结合运行结果,对程序进行分析。
【设计思路】【代码整理】#include "stdafx.h"#include <iostream>#include <malloc.h>using namespace std;typedef int Status;#define OK 1#define ERROR 0#define OVERFLOW -1#define MAX_SIZE 20typedef enum{DG,DN,UDG,UDN}Kind;typedef struct ArcNode{int adjvex; //顶点位置struct ArcNode *nextarc; //下一条弧int *info; //弧信息};typedef struct{char info[10]; //顶点信息ArcNode *fistarc; //指向第一条弧}VNode,AdjList[MAX_SIZE];typedef struct{AdjList vertices;int vexnum,arcnum; //顶点数,弧数int kind; //图的种类,此为无向图}ALGraph;//这是队列的节点,仅用于广度优先搜索typedef struct Node{int num;struct Node* next;};//队列的头和尾typedef struct{Node * front;Node *rear;}PreBit;int LocateV ex(ALGraph G,char info[]);//定位顶点的位置Status addArcNode(ALGraph &G,int adjvex); //图中加入弧Status CreatGraph(ALGraph&G);//创建图的邻接表Status DFSTraverse(ALGraph G);//深度优先搜索Status BFSTraverse(ALGraph G);//广度优先搜索Status DFS(ALGraph G,int v);//深度优先搜索中的数据读取函数,用于递归bool visited[MAX_SIZE]; // 访问标志数组//初始化队列Status init_q(PreBit&P_B){P_B.front=P_B.rear=(Node*)malloc(sizeof(Node));if(!P_B.front){exit(OVERFLOW);}P_B.front->next=NULL;}//将数据入队Status en_q(PreBit & P_B,int num){Node *p=(Node*)malloc(sizeof(Node));if(!p){exit(OVERFLOW);}p->num=num;p->next=NULL;P_B.rear->next=p;P_B.rear=p;return OK;}//出队Status de_q(PreBit & P_B){if(P_B.front==P_B.rear){return ERROR;}Node* p=P_B.front->next;P_B.front->next=p->next;if(P_B.rear==p){P_B.rear=P_B.front;}free(p);return OK;}Status CreatGraph(ALGraph&G){cout<<"请输入顶点数目和弧数目"<<endl;cin>>G.vexnum>>G.arcnum;//依次输入顶点信息for(int i=0;i<G.vexnum;i++){cout<<"请输入顶点名称"<<endl;cin>>G.vertices[i].info;G.vertices[i].fistarc=NULL;}//依次输入弧信息for(int k=1;k<=G.arcnum;k++){char v1[10],v2[10]; //用于表示顶点名称的字符数组int i,j; //表示两个顶点的位置BACK: //返回点cout<<"请输入第"<<k<<"条弧的两个顶点"<<endl;cin>>v1>>v2;i=LocateV ex(G,v1); //得到顶点v1的位置j=LocateV ex(G,v2); //得到顶点v2的位置if(i==-1||j==-1){ //头信息不存在则返回重输cout<<"不存在该节点!"<<endl;goto BACK; //跳到BACK 返回点}addArcNode(G,i); //将弧的顶点信息插入表中addArcNode(G,j);}return OK;}//倒序插入弧的顶点信息Status addArcNode(ALGraph &G,int adjvex){ArcNode *p; //弧节点指针p=(ArcNode*)malloc(sizeof(ArcNode));p->adjvex=adjvex;p->nextarc=G.vertices[adjvex].fistarc;//指向头结点的第一条弧G.vertices[adjvex].fistarc=p; //头结点的第一条弧指向p,即将p作为头结点的第一条弧return OK;}//定位顶点的位置int LocateV ex(ALGraph G,char info[]){for(int i=0;i<G.vexnum;i++){if(strcmp(G.vertices[i].info,info)==0){ //头结点名称与传入的信息相等,证明该头节点存在return i; //此时返回位置}}return -1;}//深度优先搜索Status DFSTraverse(ALGraph G){for(int v=0;v<G.vexnum;v++){visited[v]=false;}char v1[10];int i;BACK:cout<<"请输入首先访问的顶点"<<endl;cin>>v1;i=LocateV ex(G,v1);if(i==-1){cout<<"不存在该节点!"<<endl;goto BACK;}DFS(G,i);return OK;}//深度优先搜索递归访问图Status DFS(ALGraph G,int v){visited[v]=true;cout<<G.vertices[v].info<<" ";//输出信息ArcNode *p;p=G.vertices[v].fistarc; //向头节点第一条while(p) //当弧存在{if(!visited[p->adjvex]){DFS(G,p->adjvex); //递归读取}p=p->nextarc;}return OK;}//广度优先搜索Status BFSTraverse(ALGraph G){for(int v=0;v<G.vexnum;v++){visited[v]=false;}char v1[10];int v;BACK:cout<<"请输入首先访问的顶点"<<endl;cin>>v1;v=LocateV ex(G,v1);if(v==-1){cout<<"不存在该节点!"<<endl;goto BACK;}PreBit P_B;init_q(P_B);ArcNode *p;visited[v]=true;cout<<G.vertices[v].info<<" ";//输出信息en_q(P_B,v); //将头位置v入队while(P_B.front!=P_B.rear){//当队列不为空时,对其进行访问int w=P_B.front->next->num;//读出顶点位置de_q(P_B);//顶点已经访问过,将其出队列p=G.vertices[w].fistarc;//得到与顶点相关的第一条弧while(p){if(!visited[p->adjvex]){en_q(P_B,p->adjvex);//将弧入队,但不读取,只是将其放在队尾}p=p->nextarc;}}return OK;}int _tmain(int argc, _TCHAR* argv[]){ALGraph G;CreatGraph(G);cout<<"深度优先搜索图:"<<endl;DFSTraverse(G);cout<<endl;cout<<"广度优先搜索图:"<<endl;BFSTraverse(G);cout<<endl;system("pause");return 0;}。
数据结构实训实验报告

一、实验背景数据结构是计算机科学中一个重要的基础学科,它研究如何有效地组织和存储数据,并实现对数据的检索、插入、删除等操作。
为了更好地理解数据结构的概念和原理,我们进行了一次数据结构实训实验,通过实际操作来加深对数据结构的认识。
二、实验目的1. 掌握常见数据结构(如线性表、栈、队列、树、图等)的定义、特点及操作方法。
2. 熟练运用数据结构解决实际问题,提高算法设计能力。
3. 培养团队合作精神,提高实验报告撰写能力。
三、实验内容本次实验主要包括以下内容:1. 线性表(1)实现线性表的顺序存储和链式存储。
(2)实现线性表的插入、删除、查找等操作。
2. 栈与队列(1)实现栈的顺序存储和链式存储。
(2)实现栈的入栈、出栈、判断栈空等操作。
(3)实现队列的顺序存储和链式存储。
(4)实现队列的入队、出队、判断队空等操作。
3. 树与图(1)实现二叉树的顺序存储和链式存储。
(2)实现二叉树的遍历、查找、插入、删除等操作。
(3)实现图的邻接矩阵和邻接表存储。
(4)实现图的深度优先遍历和广度优先遍历。
4. 算法设计与应用(1)实现冒泡排序、选择排序、插入排序等基本排序算法。
(2)实现二分查找算法。
(3)设计并实现一个简单的学生成绩管理系统。
四、实验步骤1. 熟悉实验要求,明确实验目的和内容。
2. 编写代码实现实验内容,对每个数据结构进行测试。
3. 对实验结果进行分析,总结实验过程中的问题和经验。
4. 撰写实验报告,包括实验目的、内容、步骤、结果分析等。
五、实验结果与分析1. 线性表(1)顺序存储的线性表实现简单,但插入和删除操作效率较低。
(2)链式存储的线性表插入和删除操作效率较高,但存储空间占用较大。
2. 栈与队列(1)栈和队列的顺序存储和链式存储实现简单,但顺序存储空间利用率较低。
(2)栈和队列的入栈、出队、判断空等操作实现简单,但需要考虑数据结构的边界条件。
3. 树与图(1)二叉树和图的存储结构实现复杂,但能够有效地表示和处理数据。
数据结构实验报告
数据结构实验报告一、实验目的数据结构是计算机科学中重要的基础课程,通过本次实验,旨在深入理解和掌握常见数据结构的基本概念、操作方法以及在实际问题中的应用。
具体目的包括:1、熟练掌握线性表(如顺序表、链表)的基本操作,如插入、删除、查找等。
2、理解栈和队列的特性,并能够实现其基本操作。
3、掌握树(二叉树、二叉搜索树)的遍历算法和基本操作。
4、学会使用图的数据结构,并实现图的遍历和相关算法。
二、实验环境本次实验使用的编程环境为具体编程环境名称,编程语言为具体编程语言名称。
三、实验内容及步骤(一)线性表的实现与操作1、顺序表的实现定义顺序表的数据结构,包括数组和表的长度等。
实现顺序表的初始化、插入、删除和查找操作。
2、链表的实现定义链表的节点结构,包含数据域和指针域。
实现链表的创建、插入、删除和查找操作。
(二)栈和队列的实现1、栈的实现使用数组或链表实现栈的数据结构。
实现栈的入栈、出栈和栈顶元素获取操作。
2、队列的实现采用循环队列的方式实现队列的数据结构。
完成队列的入队、出队和队头队尾元素获取操作。
(三)树的实现与遍历1、二叉树的创建以递归或迭代的方式创建二叉树。
2、二叉树的遍历实现前序遍历、中序遍历和后序遍历算法。
3、二叉搜索树的操作实现二叉搜索树的插入、删除和查找操作。
(四)图的实现与遍历1、图的表示使用邻接矩阵或邻接表来表示图的数据结构。
2、图的遍历实现深度优先遍历和广度优先遍历算法。
四、实验结果与分析(一)线性表1、顺序表插入操作在表尾进行时效率较高,在表头或中间位置插入时需要移动大量元素,时间复杂度较高。
删除操作同理,在表尾删除效率高,在表头或中间删除需要移动元素。
2、链表插入和删除操作只需修改指针,时间复杂度较低,但查找操作需要遍历链表,效率相对较低。
(二)栈和队列1、栈栈的特点是先进后出,适用于函数调用、表达式求值等场景。
入栈和出栈操作的时间复杂度均为 O(1)。
2、队列队列的特点是先进先出,常用于排队、任务调度等场景。
数据结构实验五---查找的实现
实验五查找得实现一、实验内容1、建立一个线性表,对表中数据元素存放得先后次序没有任何要求.输入待查数据元素得关键字进行查找。
为了简化算法,数据元素只含一个整型关键字字段,数据元素得其余数据部分忽略不考虑.建议采用前哨得作用,以提高查找效率。
2、查找表得存储结构为有序表,输入待查数据元素得关键字利用折半查找方法进行查找.此程序中要求对整型量关键字数据得输入按从小到大排序输入。
二、源代码与执行结果1、#include〈iostream>using namespace std;#define MAX 100#define KeyType inttypedef struct{KeyType key ;}DataType;typedef struct{ﻩDataType elem[MAX] ;intlength ;}SeqTable ,*PSeqTable ;PSeqTable Init_SeqTable(){ﻩPSeqTable p =(PSeqTable)malloc(sizeof(SeqTable)) ;ﻩif(p !=NULL){p->length = 0 ;ﻩreturnp;}ﻩelse{ﻩcout〈<"Outof space!”〈〈endl ;ﻩreturn NULL;ﻩ}}int insert_SeqTable(PSeqTable p,KeyType x){if(p->length〉= MAX)ﻩ{ﻩcout〈<”overflow!"<<endl ;ﻩreturn 0 ;ﻩ}p—>elem[p—>length]、key= x ;p-〉length++;return 1 ;}int SeqSearch(SeqTable s ,KeyTypek){ﻩint n , i = 0;ﻩn = s、length ;s、elem[n]、key =k ;ﻩwhile(s、elem[i]、key != k)ﻩﻩi ++ ;ﻩif(i == n)return —1 ;elseﻩﻩreturn i ;}voidmain(){PSeqTable p ;inti , n;ﻩKeyType a ;p =Init_SeqTable();ﻩcout<〈"请输入数据个数:" ;cin>>n ;cout〈<"请输入数据:”<〈endl ;for(i = 0 ; i< n ;i++)ﻩ{ﻩcin〉>a ;ﻩinsert_SeqTable(p , a);}ﻩcout<<"请输入要查找得数据,输入32767结束:” ;cin〉〉a ;ﻩwhile(a != 32767)ﻩ{i =SeqSearch(*p, a) ;if(i == -1){ﻩﻩﻩcout<<”无此数据!请重新输入:"<〈endl ;ﻩﻩcin>>a ;ﻩ}ﻩﻩelseﻩﻩ{ﻩcout<〈"该数据得位置就是:"〈<i+1<<endl;ﻩcout〈<"请输入要查找得数据:" ;ﻩﻩcin〉〉a;ﻩ}ﻩ}}2、#include<iostream>using namespace std;#define MAX 100#define KeyType inttypedef struct{KeyType key ;}DataType;typedef struct{ﻩDataType elem[MAX] ;ﻩint length ;}BinTable ,*PBinTable ;PBinTable Init_BinTable(){ﻩPBinTable p = (PBinTable)malloc(sizeof(BinTable)) ;if(p != NULL){p->length= 0;ﻩﻩreturn p ;ﻩ}elseﻩ{ﻩcout〈<"Out of space!"〈<endl ;return NULL ;ﻩ}}int insert_BinTable(PBinTable p ,KeyType x){if(p—〉length >= MAX){ﻩcout<<"overflow!”<〈endl ;ﻩreturn 0 ;ﻩ}ﻩp-〉elem[p—>length]、key =x ;p->length ++ ;ﻩreturn 1;}int BinSearch(BinTable s ,KeyType k){ﻩint low,mid , high;ﻩlow = 0 ;high = s、length-1 ;while(low <= high){ﻩﻩmid=(low+high)/2 ;ﻩif(s、elem[mid]、key== k)ﻩﻩﻩreturnmid;ﻩelse if(s、elem[mid]、key >k)ﻩﻩhigh= mid- 1 ;ﻩﻩelseﻩlow = mid +1 ;ﻩ}ﻩreturn —1;}void main(){PBinTable p ;ﻩinti ,n ;ﻩKeyType a;p =Init_BinTable();cout<<”请输入数据个数:”;cin〉>n;ﻩcout<〈"请按从小到大得顺序输入数据:”〈<endl;for(i = 0 ;i〈 n; i ++)ﻩ{cin>〉a;ﻩinsert_BinTable(p,a);}ﻩcout<<"请输入要查找得数据,输入32767结束:” ;ﻩcin〉>a ;while(a!= 32767){ﻩi =BinSearch(*p , a);if(i ==-1)ﻩ{ﻩﻩcout〈〈"无此数据!请重新输入:"〈〈endl ;cin>>a;ﻩ}ﻩelse{ﻩcout<<"该数据得位置就是:”〈<i+1〈<endl ;ﻩﻩﻩcout<〈”请输入要查找得数据:" ;cin>〉a ;}ﻩ}}。
数据结构 实验报告
数据结构实验报告一、实验目的数据结构是计算机科学中非常重要的一门课程,通过本次实验,旨在加深对常见数据结构(如链表、栈、队列、树、图等)的理解和应用,提高编程能力和解决实际问题的能力。
二、实验环境本次实验使用的编程语言为C++,开发工具为Visual Studio 2019。
操作系统为 Windows 10。
三、实验内容1、链表的实现与操作创建一个单向链表,并实现插入、删除和遍历节点的功能。
对链表进行排序,如冒泡排序或插入排序。
2、栈和队列的应用用栈实现表达式求值,能够处理加、减、乘、除和括号。
利用队列实现银行排队系统的模拟,包括顾客的到达、服务和离开。
3、二叉树的遍历与操作构建一棵二叉树,并实现前序、中序和后序遍历。
进行二叉树的插入、删除节点操作。
4、图的表示与遍历用邻接矩阵和邻接表两种方式表示图。
实现图的深度优先遍历和广度优先遍历。
四、实验步骤及结果1、链表的实现与操作首先,定义了链表节点的结构体:```cppstruct ListNode {int data;ListNode next;ListNode(int x) : data(x), next(NULL) {}};```插入节点的函数:```cppvoid insertNode(ListNode& head, int val) {ListNode newNode = new ListNode(val);head = newNode;} else {ListNode curr = head;while (curr>next!= NULL) {curr = curr>next;}curr>next = newNode;}}```删除节点的函数:```cppvoid deleteNode(ListNode& head, int val) {if (head == NULL) {return;}ListNode temp = head;head = head>next;delete temp;return;}ListNode curr = head;while (curr>next!= NULL && curr>next>data!= val) {curr = curr>next;}if (curr>next!= NULL) {ListNode temp = curr>next;curr>next = curr>next>next;delete temp;}}```遍历链表的函数:```cppvoid traverseList(ListNode head) {ListNode curr = head;while (curr!= NULL) {std::cout << curr>data <<"";curr = curr>next;}std::cout << std::endl;}```对链表进行冒泡排序的函数:```cppvoid bubbleSortList(ListNode& head) {if (head == NULL || head>next == NULL) {return;}bool swapped;ListNode ptr1;ListNode lptr = NULL;do {swapped = false;ptr1 = head;while (ptr1->next!= lptr) {if (ptr1->data > ptr1->next>data) {int temp = ptr1->data;ptr1->data = ptr1->next>data;ptr1->next>data = temp;swapped = true;}ptr1 = ptr1->next;}lptr = ptr1;} while (swapped);}```测试结果:创建了一个包含 5、3、8、1、4 的链表,经过排序后,输出为 1 3 4 5 8 。
实验五__线性表的链式表示和实现
浙江大学城市学院实验报告课程名称数据结构基础实验项目名称实验五线性表的链式表示和实现学生姓名专业班级学号实验成绩指导老师(签名)日期一.实验目的和要求1、了解线性表的链式存储结构,学会定义线性表的链式存储结构。
2、掌握单链表、循环单链表的一些基本操作实现函数。
二.实验内容1、设线性表采用带表头附加结点的单链表存储结构,请编写线性表抽象数据类型各基本操作的实现函数,并存放在头文件LinkList.h中(注:教材上为不带表头附加结点)。
同时建立一个验证操作实现的主函数文件test5.cpp,编译并调试程序,直到正确运行。
提示:⑴单向链表的存储结构可定义如下:struct LNode { // 定义单链表节点类型ElemType data; // 存放结点中的数据信息LNode *next; // 指示下一个结点地址的指针}⑵线性表基本操作可包括如下一些:①void InitList (LNode *&H) //初始化单链表②void ClearList(LNode *&H) //清除单链表③int LengthList (LNode *H) //求单链表长度④bool EmptyList (LNode *H) //判断单链表是否为空表⑤ElemType GetList (LNode *H, int pos)//取单链表第pos 位置上的元素⑥void TraverseList(LNode *H) //遍历单链表⑦bool InsertList ( LNode *&H, ElemType item, int pos)//向单链表插入一个元素⑧bool DeleteList ( LNode *&H, ElemType &item, int pos)//从单链表中删除一个元素⑶带表头附加结点的单链表初始化操作的实现可参考如下:void InitList(LNode *&H){ //构造一个空的线性链表H,即为链表设置一个头结点,//头结点的data数据域不赋任何值,头结点的指针域next则为空H=(LNode *)malloc(sizeof(LNode)); // 产生头结点Hif (!H) exit(0); // 存储分配失败,退出系统H->next=NULL; // 指针域为空}2、选做部分:编写一个函数void MergeList(LNode *&La, LNode *&Lb, LNode *&Lc),实现将两个有序单链表La和Lb合并成一个新的有序单链表Lc,同时销毁原有单链表La和Lb。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
} else if(key==T->data) { p=T; return (OK); } else if(key<T->data) SearchBST(T->lchild,key,T,p); else SearchBST(T->rchild,key,T,p); }
H.r[1] ←→ H.r[i];
//交换,要借用temp
HeapAdjust( H, 1,i-1 ); //从头重建最大堆, i-1=m
}
}
HeapAdjust(r, i, m ){
current=i; temp=r[i]; child=2*i;
while(child<=m){
//检查是否到达当前堆尾,未到尾则整理
/*二叉排序树中删除算法*/ int Delete(BiTree &p) { BiTree q,s;
if(!p->data) { q=p;
p=p->lchild;
//Delete() sub-function
free(q);
}
else if(!p->lchild)
{ q=p;
p=p->rchild;
/*一趟快速排序算法(针对一个子表的操作) */ int Partition(SqList &L,int low,int high){ //一趟快排 //交换子表 r[low…high]的记录,使支点(枢轴)记录到位,并返回其位置。返回时,在支点之前的记录均不 大于它,支点之后的记录均不小于它。 r[0]=r[low]; //以子表的首记录作为支点记录,放入r[0]单元 (续下页) pivotkey=r[low].key; //取支点的关键码存入pivotkey变量 while(low < high) //从表的两端交替地向中间扫描{ while(low<high && r[high].key>=pivotkey ) -high;
} //for } //SelectSort /*建堆算法 (即堆排序算法中的第一步) */ void HeapSort (HeapType &H ) {
//H是顺序表,含有H.r[ ]和H.length两个分量
for ( i = length / 2; i >0; - - i ) //把r[1…length]建成大根堆 HeapAdjust(r, i, length ); //使r[i…length]成为大根堆
实验五 查找与排序
实验课程名:数据结构(c 语言版)
专业班级: 学 号:
姓 名:
实验时间:
实验地点: 指导教师:
一、实验目的 1、进一步掌握指针变量、动态变量的含义。 2、掌握二叉树的结构特性,以及各种存储结构的特点和适用范围。 3、掌握用指针类型描述、访问和处理二叉树的运算
二、实验的内容和步骤
下面是查找与排序的部分基本操作实现的算法,请同学们自己设计主函数和部分算法,调用这些算法,完成下 面的实验任务。
if(s) return s%11;
/*输入数据的关键字函数*/ ElemType Inputkey() { ElemType x;
cout<<"请输入数据"<<endl;
cin>>x; return x;
}
/*输入一组关键字,建立Hash表,表长为m,用链地址法处理冲突*/
…… } // HeapSort
/*堆排序的算法实现 */
void HeapSort (HeapType &H )
{
//对顺序表H进行堆排序
for ( i = H.length / 2; i >0; - - i )
HeapAdjust(H,i, H.length ); //for,建立初始堆
for ( i = H.length; i > 1; - -i) {
{
ShellInsert(L,dlta[k]);
}
} // ShellSort
/* 希尔排序算法(其中某一趟的排序操作) */ void ShellInsert(SqList &L,int dk) { //对顺序表L进行一趟增量为dk的Shell排序,dk为步长因子 for(i=dk+1;i<=L.length; ++ i)
typedef struct LNode { ElemType key;
struct LNode *next; }LNode,*LinkList;
typedef LNode * CHashTable [MAXSIZE] ; //链地址Hash表类型
/*求Hash函数*/ int H(int s)// {
/*二叉排序树中插入算法*/ int SearchBST(BiTree T,KeyType key,BiTree f,BiTree &p) //SearchBST() { if(!T)
{ p=f; return (ERROR);
} else if(key==T->data) { p=T; return (OK); } else if(key<T->data) SearchBST(T->lchild,key,T,p); else SearchBST(T->rchild,key,T,p); } //SearchBST() end
int Build_Hash (CHashTable & T, int m)
{ ElemType key;
LNode* q;
int n;
if(m<1) return ERROR;
for(int i=0; i<m; i++)
T[i]=NULL; //哈希表初始化
while( (key=Inputkey())!=0 ) //输入元素有效
/*整个快速排序的递归算法: */
void QSort ( SqList &L, int low, int high )
{
//对顺序表L中的子序列r[ low…high] 作快速排序
if ( low < high)
{ pivot = Partition ( L, low, high );
QSort ( L, low, pivot-1);
# define MAX_LENGTH 100 typedef int KeyType;
/* 顺序查找表的存储类型 */
typedef struct
//define structure SSTable
{ KeyType *elem;
int length;
}SSTable;
/* 在查找表中顺序查找其关键字等于 key 的数据元素。 */
//定义顺序表L的结构
RecordType r [ MAXSIZE +1 ]; //存储顺序表的向量
//r[0]一般作哨兵或缓冲区
int length ;
//顺序表的长度
}SqList ,L;
//例如L.r或L.length表示其中一个分量
//若r数组是表L中的一个分量且为node类型,则r中某元素的key分量表示为:r[i].key
/*直接插入排序算法的实现: */
void InsertSort ( SqList &L ) { //对顺序表L作直接插入排序
for ( i = 2; i <=L.length; ++ i ) //直接在原始无序表L中排序
if (L.r[i].key < L.r[i-1].key) //若L.r[i]较小则插入有序子表内
int Print_Hash (CHashTable & T)
{
LNode* q;
int n;
for(int i=0; i<11; i++)
{
q=T[i]; //哈希表初始化
while(q ) //输入元素有效
{
cout<<q->data<<"
";
q=q->next;
}
cout<<endl;
}
return OK;
{ q=(LNode*)malloc(sizeof(LNode));
q->data=key;
q->next=NULL;
n=H(key); //查HASH表得到指针数组的地址
q->next=T[n]; //原来的头指针后移
T[n]=q;
//新元素插入头部
} //while
return OK;
}
/*输出用链地址法处理冲突的Hash表*/
if(r[i].key < r[i-dk].key) { r[0]=r[i]; for(j=i-dk; j>0&&(r[0].key<r[j].key); j-=dk)
r[j+dk]=r[j];
r[j+dk]=r[0]; }//if } //ShellInsert //理解难点:不提前处理i子集后部元素,每次只考虑子集的前部(j=j-dk), //第二轮也只考虑i+1那个子集的前部。
}
/*定义每个记录(数据元素)的结构*/
Typedef struct {
//定义每个记录(数据元素)的结构
KeyType
key ;
//关键字
InfoType
otherinfo; //其它数据项
}RecordType,node ;
//例如node.key表示其中一个分量