基于storm的实时计算架构
dstorm原理

dstorm原理
DSTORM(Distributed Storm System)是一种分布式实时计算系统,
它允许用户在多个计算节点上运行多个并行任务,并且能够有效地处
理大量数据流。
DSTORM 的原理主要包括以下几个方面:
1. 分布式架构:DSTORM 是一个分布式系统,它可以将计算任务分布
在多个计算节点上,从而提高计算能力和可扩展性。
DSTORM 使用Apache Zookeeper 或类似工具来协调和管理各个节点的状态和任务分配。
2. 流处理:DSTORM 是一种流处理平台,它能够实时处理大量数据流。
与传统的批量处理系统不同,DSTORM 允许数据在进入系统时直接被处理,而不需要将数据存储在本地或远程存储系统中的批量数据集。
3. 容错和恢复:DSTORM 提供了强大的容错和恢复功能,以确保系统
的高可用性和可靠性。
当一个节点出现故障时,DSTORM 可以自动重新
分配任务到其他健康的节点,从而保持系统的正常运行。
此外,DSTORM 还提供了快照恢复功能,以便在系统发生故障时能够快速恢复
到之前的状态。
4. 模块化设计:DSTORM 采用模块化设计,将不同的功能划分为不同
的模块,并允许用户根据需要选择和组合不同的模块。
这种设计使得DSTORM 更加灵活和可定制,能够适应不同的应用场景和需求。
总之,DSTORM 的原理是基于分布式架构、流处理、容错和恢复以及模
块化设计,旨在提供一种高效、可靠、可扩展的实时计算平台,适用
于各种大规模数据流处理应用场景。
storm的用法

storm的用法一、了解Storm大数据处理框架Storm是一个用于实时流数据处理的分布式计算框架。
它由Twitter公司开发,并于2011年发布。
作为一个开源项目,Storm主要用于处理实时数据,比如实时分析、实时计算、流式ETL等任务。
二、Storm的基本概念及特点1. 拓扑(Topology):拓扑是Storm中最重要的概念之一。
它代表了整个计算任务的结构和流程。
拓扑由一系列组件组成,包括数据源(Spout)、数据处理节点(Bolt)以及它们之间的连接关系。
2. 数据源(Spout):Spout负责从外部数据源获取数据,并将其发送给Bolt进行处理。
在拓扑中,通常会有一个或多个Spout进行数据输入。
3. 数据处理节点(Bolt):Bolt是对数据进行实际处理的模块。
在Bolt中可以进行各种自定义的操作,如过滤、转换、聚合等,根据业务需求不同而定。
4. 流组(Stream Grouping):Stream Grouping决定了从一个Bolt到下一个Bolt 之间的任务调度方式。
Storm提供了多种Stream Grouping策略,包括随机分组、字段分组、全局分组等。
5. 可靠性与容错性:Storm具有高可靠性和容错性的特点。
它通过对任务状态进行追踪、失败重试机制和数据备份等方式,确保了整个计算过程的稳定性。
6. 水平扩展:Storm可以很方便地进行水平扩展。
通过增加计算节点和调整拓扑结构,可以实现对处理能力的无缝提升。
三、Storm的应用场景1. 实时分析与计算:Storm适用于需要对大规模实时数据进行即时分析和计算的场景。
比如金融领域中的实时交易监控、电商平台中用户行为分析等。
2. 流式ETL:Storm可以实现流式ETL(Extract-Transform-Load)操作,将源数据进行抽取、转换和加载到目标系统中,并实时更新数据。
3. 实时推荐系统:通过结合Storm和机器学习算法,可以构建快速响应的实时推荐系统。
JStorm—实时流式计算框架入门介绍
JStorm—实时流式计算框架⼊门介绍JStorm介绍 JStorm是参考storm基于Java语⾔重写的实时流式计算系统框架,做了很多改进。
如解决了之前的Storm nimbus节点的单点问题。
JStorm类似于Hadoop MapReduce系统,⽤户按照指定的接⼝去实现⼀个任务,任务提交给JStorm进⾏运⾏,且这种运⾏是不间断的,因为如果期间有worker发⽣故障,调度器会分配⼀个新的worker去替换这个故障worker。
从应⽤的⾓度来看,JStorm是⼀种分布式应⽤;从系统框架层⾯来看,JStorm⼜是⼀种类似于Hadoop MapReduce的调度系统;从数据层⾯来看,JStorm⼜是⼀种流式的实时计算⽅案。
JStorm优势1. 易开发性: JStomr接⼝简易,只需按照Spout、Bolt及Topology编程规范进⾏应⽤开发即可;2. 扩展性:可以线性的扩展性能,配置并发数即可;3. 容错性:出现故障worker时,调度器会分配⼀个新的worker去代替;4. 数据精准性:JStorm内置ACK机制,确保数据不丢失。
还可以采⽤事务机制确保进⼀步的精准度;5. 实时性:JStorm不间断运⾏任务,且实时计算。
JStorm应⽤场景1. 实时计算:可实时数据统计,实时监控;2. 消息转移:流处理完消息后,可以定向的将结果存储到其他消息中间件中;3. rpc请求:提交任务就是⼀次rpc请求过程;典型的场景:⽤于⽇志分析,rpc请求提交任务,从收集的⽇志中,统计出特定的数据结果,并将统计后的结果持久化到外部存储中,这是⼀种信息流处理⽅式,可聚合,可分析。
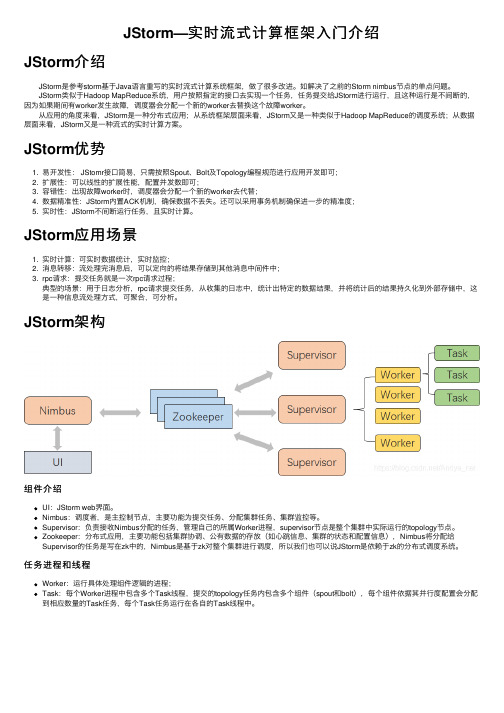
JStorm架构组件介绍UI:JStorm web界⾯。
Nimbus:调度者,是主控制节点,主要功能为提交任务、分配集群任务、集群监控等。
Supervisor:负责接收Nimbus分配的任务,管理⾃⼰的所属Worker进程,supervisor节点是整个集群中实际运⾏的topology节点。
《Storm框架分享》课件

对Storm框架的未来展望
我们预计Storm框架将与大数据生态系统更深入 地整合,在支持更多编程语言和数据源目标的 同时,提供更强大的实时计算能力。
《Storm框架分享》PPT 课件
欢迎大家参加今天的分享会!在本次课程中,我们将深入探讨Storm框架的各 个方面,包括其特点、基本概念、核心原理、具体应用、优缺点以及未来发 展趋势。
Storm框架简介
什么是Storm框架?
Storm是一个开源的实时计算系统,可用于处理大规模的流数据,提供高并发性和可靠性。
数据的可靠性保障
Storm框架通过在拓扑结构中引入消息可靠性机制,确保数据的传输和处理过程具有高可靠 性。
Storm框架的具体应用
1 实时数据处理
Storm框架适用于对实时流数据进行实时计算和分析,如实时推荐系统、广告投放分析等。
2 流量控制
通过Storm框架,可以对大规模的数据流进行控制和调度,确保数据的顺畅传输和负载均 衡。
Topology
消息处理的拓扑结构,由 多个Spout和Bolt组成,形 成一条处理流水线。
Storm框架的核心原理
数据的流式处理
Storm框架以流的方式进行数据处理,能够实时地对输入数据进行计算和分析。
数据的并行处理
通过将拓扑结构分解为多个任务,Storm框架能够并行处理大规模数据,提高处理效率。
传统数据处理 vs Storm框架
相比传统的批量处理方式,Storm框架能够实现实时流式处理,处理速度更快,反应更及时。
Storm框架的基本概念
Spout
消息的来源,负责从数据 源获取输入数据并发送给 下游的Bolt。
Bolt
消息的处理者,接收Spout 发送的数据并进行计算、 过滤等操作,然后将结果 发送给下一个Bolt。
storm的5个主要术语

Storm的5个主要术语Storm是一个开源分布式实时计算系统,它被广泛应用于大规模数据处理和实时分析。
在Storm中,有一些主要的术语被用来描述其核心概念和工作原理。
本文将详细介绍Storm的5个主要术语,包括拓扑(Topology)、流(Stream)、Spout、Bolt和任务(Task)。
1. 拓扑(Topology)拓扑是Storm中最基本的概念之一。
它表示了一个实时计算任务的结构和流程。
拓扑由多个组件(Component)组成,每个组件负责特定的数据处理任务。
组件之间通过流进行连接,形成了一个有向无环图。
拓扑可以看作是一个数据处理的蓝图,它定义了数据从输入到输出的整个计算过程。
在拓扑中,每个组件都可以并行执行,并且可以在不同节点上进行分布式部署。
通过合理设计拓扑结构,可以实现高效的数据处理和并行计算。
2. 流(Stream)流是Storm中用来传递数据的基本单位。
它代表了一系列具有相同类型的数据项,在拓扑中从一个组件流向另一个组件。
流可以包含多个字段,每个字段都有特定的类型和含义。
在拓扑中,流可以被分为多个分支,每个分支可以由不同的组件处理。
这种方式使得数据可以以不同的路径进行处理,从而实现更灵活和高效的计算。
同时,流还支持多种操作,如过滤、聚合、转换等,可以对数据进行各种形式的处理和加工。
3. SpoutSpout是Storm中用于数据输入的组件。
它负责从外部数据源读取数据,并将其发送到拓扑中的下一个组件。
Spout可以读取各种不同类型的数据源,如消息队列、文件系统、数据库等。
在拓扑中,Spout通常是数据流的起点。
它以一定的速率产生数据,并通过流发送给下一个组件进行处理。
Spout还可以实现可靠性保证机制,确保数据不会丢失或重复发送。
通过合理配置Spout的并行度和任务数,可以实现高吞吐量和低延迟的数据输入。
4. BoltBolt是Storm中用于数据处理和计算的组件。
它接收来自上游组件(如Spout或其他Bolt)传递过来的数据流,并对其进行加工、过滤、聚合等操作。
论Storm分布式实时计算工具

论Storm分布式实时计算工具作者:沈超邓彩凤来源:《中国科技纵横》2014年第03期【摘要】互联网的应用催生了一大批新的数据处理技术,storm分布式实时处理工具以其强大的数据处理能力、可靠性高、扩展性好等特点,在近几年得到越来越广泛的关注和应用。
【关键词】分布式实时计算流处理1 背景及特点互联网的应用正在越来越深入的改变人们的生活,互联网技术也在不断发展,尤其是大数据处理技术,过去的十年是大数据处理技术变革的十年,MapReduce,Hadoop以及一些相关的技术使得我们能处理的数据量比以前要大得多得多。
但是这些数据处理技术都不是实时的系统,或者说,它们设计的目的也不是为了实时计算。
没有什么办法可以简单地把hadoop变成一个实时计算系统。
实时数据处理系统和批量数据处理系统在需求上有着本质的差别。
然而大规模的实时数据处理已经越来越成为一种业务需求了,而缺少一个“实时版本的hadoop”已经成为数据处理整个生态系统的一个巨大缺失。
而storm的出现填补了这个缺失。
Storm出现之前,互联网技术人员可能需要自己手动维护一个由消息队列和消息处理者所组成的实时处理网络,消息处理者从消息队列取出一个消息进行处理,更新数据库,发送消息给其它队列等等。
不幸的是,这种方式有以下几个缺陷:单调乏味:技术人员花费了绝大部分开发时间去配置把消息发送到哪里,部署消息处理者,部署中间消息节点—设计者的大部分时间花在设计,配置这个数据处理框架上,而真正关心的消息处理逻辑在代码里面占的比例很少。
脆弱:不够健壮,设计者要自己写代码保证所有的消息处理者和消息队列正常运行。
伸缩性差:当一个消息处理者的消息量达到阀值,需要对这些数据进行分流,配置这些新的处理者以让他们处理分流的消息。
Storm定义了一批实时计算的原语。
如同hadoop大大简化了并行批量数据处理,storm的这些原语大大简化了并行实时数据处理。
storm的一些关键特性如下:适用场景广泛:storm可以用来处理消息和更新数据库(消息流处理),对一个数据量进行持续的查询并返回客户端(持续计算),对一个耗资源的查询作实时并行化的处理(分布式方法调用),storm的这些基础原语可以满足大量的场景。
分布式实时(流)计算框架

MZ案例介02—GN平台采集
从2个GN平台采集Gn原始数据, 将原始数据的文档合并,上限 为50个文档。每个文档的大小 约为200MB,合并后的文档上 限为10GB。合并后的文档上传 至HDFS平台。 上传的HDFS目录分别是 /tmp/gn/1和 /tmp/gn/2, 再 根据上传的时间点建立新的目 录.
RDMS
整个数据处理流程包括四部分: 第一部分是数据接入层,该部分从前端业务系统获取数据; 第二部分是最重要的storm实时处理部分,数据从接入层接入,经过实时处理后传入 数据落地层; 第三部分为数据落地层,该部分指定了数据的落地方式; 第四部分元数据管理器。
7
Storm实时计算业务接口
8
Storm实时计算具体业务需求
(1) 条件过滤
这是Storm最基本的处理方式,对符合条件的数据进行实时过滤,将符合条件的数据保存下来,
这种实时查询的业务需求在实际应用中是很常见的。
(2) 中间计算
我们需要改变数据中某一个字段(例如是数值),我们需要利用一个中间值经过计算(值比 较、求和、求平均等等)后改变该值,然后将数据重新输出。
(3) 求TopN
相信大家对TopN类的业务需求也是比较熟悉的,在规定时间窗口内,统计数据出现的TopN, 该类处理在购物及电商业务需求中,比较常见。
(4) 推荐系统
正如我架构图中画的那样,有时候在实时处理时会从mysql及hadoop中获取数据库中的信息, 例如在电影推荐系统中,传入数据为用户当前点播电影信息,从数据库中获取的是该用户之前的 一些点播电影信息统计,例如点播最多的电影类型、最近点播的电影类型,及其社交关系中点播
13
MediationZone--集中控制,分布执行
storm原理

storm原理Storm是一个分布式实时计算系统,它可以处理海量的实时数据流,并且能够在毫秒级别内对数据进行处理和分析。
Storm的原理是基于流处理模型,它将数据流分成一系列的小批次,然后对每个小批次进行处理和分析,最终将结果输出到目标系统中。
Storm的核心组件是Nimbus和Supervisor。
Nimbus是Storm的主节点,它负责管理整个集群的拓扑结构和任务分配。
Supervisor是Storm的工作节点,它负责接收Nimbus分配的任务,并且在本地执行任务。
Storm的数据流模型是基于DAG(有向无环图)的,每个节点代表一个数据处理单元,节点之间的边代表数据流。
Storm的拓扑结构是由Spout和Bolt组成的。
Spout是数据源,它从外部数据源中读取数据,并将数据发送到Bolt中进行处理。
Bolt是数据处理单元,它接收Spout发送的数据,并且对数据进行处理和分析,最终将结果输出到目标系统中。
Storm的数据流模型是基于流处理模型的,它可以实现实时数据处理和分析。
Storm的数据流模型是基于DAG的,它可以实现高效的数据处理和分析。
Storm的拓扑结构是由Spout和Bolt组成的,它可以实现灵活的数据处理和分析。
Storm的优点是可以实现实时数据处理和分析,它可以处理海量的实时数据流,并且能够在毫秒级别内对数据进行处理和分析。
Storm的缺点是需要一定的技术水平才能使用,而且需要一定的硬件资源才能支持。
总之,Storm是一个非常强大的分布式实时计算系统,它可以处理海量的实时数据流,并且能够在毫秒级别内对数据进行处理和分析。
Storm的原理是基于流处理模型,它将数据流分成一系列的小批次,然后对每个小批次进行处理和分析,最终将结果输出到目标系统中。
Storm的优点是可以实现实时数据处理和分析,它可以处理海量的实时数据流,并且能够在毫秒级别内对数据进行处理和分析。
Storm的缺点是需要一定的技术水平才能使用,而且需要一定的硬件资源才能支持。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
应用场景@阿里巴巴
业务监控
效果监控中心
实时GMV 效果监控 实时流量 效果监控
推荐
网站实时推荐
首页实时推荐
店铺实时推荐
卖家360
买家实时活动
404页面实时推荐
Top likes/trends
实时访问动态 实时搜索动态
实时活动 效果监控
实时营销 效果监控
实时反馈动态 实时订阅动态
异常监控中心
日志异常实时报警 恶意点击 实时报警
配置服务 • 任务管理中心,直观反应当前任 务执行状态,能够中止、暂时、 重设任务 • 监控:系统(内存,cpu,网络, io等),功能(redis,meta, storm等),任务,数据质量 • storm集群管理
5.1 storm topology开发效率
简单统计场景(中文站UV,PV统计):
1.1 业务背景 • • • • • Big data数据量膨胀 业务快速变化,商业模式的创新 SNS,移动互联网 用户体验个性化,实时化 …
1.2 离线计算 vs. 流计算
From <IBM InfoSphere Streams: Harnessing Data in Motion>
1.3 数据分析演进趋势
message connector message adaptor
meta
MSC manager
supervisor bolt spout
nimbus
Data output service
file …
zookeper
DB
Engine state storage
Local buffer cache
Persistence storage
Байду номын сангаас
应用开发
Processing operator interface Stream processing engine
Engine state storage Log Job control center
Message extract service
Message store center
Data output service
• 统一消息存储方式
– 基于Metamorphosis:淘宝一款类似Kafka 强大的 通用消息中间件
–
– –
Pull模式的MQ
高吞吐量 Meta spout
–
支持消息顺序
• •
•
Message read interface Message write interface
MSC manager
4.6 Engine state storage
相同key 的消息
Stream Grouping
Bolt A
Spout
hash分区
Bolt B
消息分区
Task
6.3 实践经验(Cont.)
• 时效与准确性间平衡
– 纯流计算(时序不严格,注重时效性,准确性可 通过批量计算补偿) – 精确计算(牺牲一定时效,接近准确)
• • • • • 消息保序 transactional topolgoy (transaction id) 消息重发 应用去重 幂等
Countagg Operation: Grouby country Schema(country ,count)
5.6 squrriel QL&Hive QL
Hive QL Squrriel QL
数据存储
数据格式
HDFS
用户自定义
HBASE
用户自定义
数据更新
索引
不支持
有(0.8版之后增加)
不支持
3.4天罡-核心概念
处理流程
数据采集 数据接入 流式计算 数据输出
Message topic 信息 Message source
Message topic
Message
Message Message
Data
Job
Extract job
由message extract service 提供 功能凼数
无
执行
可扩展性
MapReduce
高(UDF,UDAF,UDTF)
Topology
高
6.1 实践经验
• 中间状态读写策略
– 缓存,超时6秒 – LRU – 命中率
6.2实践经验(Cont.)
• 消息顺序如何保证?
– 全序,偏序 – 设置保序key – 消息中间件meta存储顺 序 – 保证在同一个task( fields grouping,自定义 hash grouping) MetaQ
COUNTAGG
Ds: Projection(uid,order)
Opt: Goup by uid Schema(uid,count)
5.5 squirrel QL JOIN
Ds: Projection:uid,country CUSTOMER Ds: Projection:uid ,order ORDER
3.3天罡Features
•简单统计计算(包括时间窗口) •多流join计算(动态) •容错,事务 •中间状态持久化 •统一消息接入 •支持类SQL •支持数据类型:int/long/string/double… Engine state storage •支持schema •支持join,distinct,group by,count, top N •支持常规函数 -to_char ,substr…
实时流计算应用开发框架-天罡
关于
□ 孔令西
• 阿里巴巴数据平台部 • 游泳,海鲜,金花,儿子 • 专注数据平台基础平台产品化及流计算 • lingxi.konglx@ • :/kennyccp
提纲
•1 . 背 景 •2 . 业 界 •3 . 产 品 介 绍 •4 . 架 构 设 计 •5 . s q u i r r e l Q L •6 . 实 践 经 验
• SELECT c.country, COUNT(o.order) FROM custormer c join order o on c.uid= o.uid GROUP BY c.country
CUSTOMER_ORDER
Join Opt: Schema(co untry,order)
COUNTAGG
HBASE
4.2天罡-功能模块划分
Data subscriber service
Global Control System
Data output service
Job Configure Assistant
Command Line Client
Metadata Center
Monitor & Alarm
4.1天罡-技术方案
Squrriel QL
SQL解析组件 SQL执行计划组件 元数据管理
算子组件 table
join
distinct
arg
…
消息处理流向
erosa 精卫 实时log
Message extract service Message storage center
Stream processing engine(storm) HBASE
Processing job
processing
由类SQL组件实现业务逻辑
天罡系统里的相关概念说明:
1. 2.
一个message source(相当亍database)包括1个以上的message topic(相当亍table),一个message topic由1条以上的 message(相当亍record)组成。 天罡系统有二类Job,分别称为extract job和processing job。一个extract job负责一个message topic的消息接入,一个 processing job由1个以上的message topic参不计算。一个message topic可以被多个processing job引用。Processing job的输 入内容称为message,计算的结果输出,称为data。
Job Control Center
squirrel QL
Engine state storage
Log
Stream processing engine
Message store center
Message extract service
4.3天罡-功能模块关系
Job Configure Assistant
2.1 业界流计算引擎
Engine state storage
2.2 storm介绍
•最新版本storm 0.74 •主要特性:
-适用场景广泛 -可伸缩性高 -保证无数据丢失 -异常健壮 -容错性好
•一些问题: Engine state storage -编程门槛对普通用户较高
-框架无持久化存储 -框架不提供消息接入模块 -storm ui功能简单 -跨topology的bolt复用 -nimbus单点 -topology不支持动态部署
实时推荐
分钟级延迟;丌能漏算;丌能错算;统计 时长为当天; 秒级延迟;允许漏算;丌能错算;计算过 程复杂(规则多); 秒级延迟;允许漏算;丌能错算;不推荐 系统交互频繁;
秒级延迟;丌允许漏算;丌能错算;计算 过程复杂(指标定义复杂,指标个数多); 部分指标统计时长跨天;
实时数据信息服务
3.2天罡-产品定位
系统模块
Metadata
运维管控
Monitor(system,service,job,data)
Alarm
报警
4.4 Message extract service