论Storm分布式实时计算工具
dstorm原理

dstorm原理
DSTORM(Distributed Storm System)是一种分布式实时计算系统,
它允许用户在多个计算节点上运行多个并行任务,并且能够有效地处
理大量数据流。
DSTORM 的原理主要包括以下几个方面:
1. 分布式架构:DSTORM 是一个分布式系统,它可以将计算任务分布
在多个计算节点上,从而提高计算能力和可扩展性。
DSTORM 使用Apache Zookeeper 或类似工具来协调和管理各个节点的状态和任务分配。
2. 流处理:DSTORM 是一种流处理平台,它能够实时处理大量数据流。
与传统的批量处理系统不同,DSTORM 允许数据在进入系统时直接被处理,而不需要将数据存储在本地或远程存储系统中的批量数据集。
3. 容错和恢复:DSTORM 提供了强大的容错和恢复功能,以确保系统
的高可用性和可靠性。
当一个节点出现故障时,DSTORM 可以自动重新
分配任务到其他健康的节点,从而保持系统的正常运行。
此外,DSTORM 还提供了快照恢复功能,以便在系统发生故障时能够快速恢复
到之前的状态。
4. 模块化设计:DSTORM 采用模块化设计,将不同的功能划分为不同
的模块,并允许用户根据需要选择和组合不同的模块。
这种设计使得DSTORM 更加灵活和可定制,能够适应不同的应用场景和需求。
总之,DSTORM 的原理是基于分布式架构、流处理、容错和恢复以及模
块化设计,旨在提供一种高效、可靠、可扩展的实时计算平台,适用
于各种大规模数据流处理应用场景。
stormproxies的使用方法

stormproxies的使用方法(实用版3篇)目录(篇1)1.引言2.StormProxies 的概念和背景3.StormProxies 的使用方法3.1 创建 StormProxies 实例3.2 配置 StormProxies3.3 启动 StormProxies3.4 关闭 StormProxies4.StormProxies 的应用场景5.总结正文(篇1)一、引言随着互联网的发展,数据挖掘和分析的需求越来越大。
在大数据时代,分布式计算框架应运而生,其中 Storm 是一种实时的大数据处理系统。
为了使 Storm 处理速度更快,StormProxies 应运而生。
本文将介绍StormProxies 的使用方法。
二、StormProxies 的概念和背景StormProxies 是 Netflix 开发的一个用于加速 Storm 计算的代理应用。
它可以在 Storm 集群中代替 Nimbus 和 Supervisor,从而提高整个集群的性能。
StormProxies 通过代理 Nimbus 和 Supervisor 的通信,减少了集群中的网络延迟和负载,使得 Storm 处理速度更快。
三、StormProxies 的使用方法1.创建 StormProxies 实例要使用 StormProxies,首先需要创建一个 StormProxies 实例。
可以通过以下命令创建一个 StormProxies 实例:```java -jar stormproxies.jar```2.配置 StormProxies在创建 StormProxies 实例后,需要对其进行配置。
可以通过修改stormproxies.jar 中的 resources 文件夹下的配置文件进行配置。
配置文件名为 stormproxies.conf。
以下是一个配置示例:```imbus.host="localhost"imbus.port=6627supervisor.host="localhost"supervisor.port=10808```其中,nimbus.host 和 nimbus.port 分别表示 Nimbus 的 IP 地址和端口,supervisor.host 和 supervisor.port 分别表示 Supervisor 的 IP 地址和端口。
storm的用法

storm的用法一、了解Storm大数据处理框架Storm是一个用于实时流数据处理的分布式计算框架。
它由Twitter公司开发,并于2011年发布。
作为一个开源项目,Storm主要用于处理实时数据,比如实时分析、实时计算、流式ETL等任务。
二、Storm的基本概念及特点1. 拓扑(Topology):拓扑是Storm中最重要的概念之一。
它代表了整个计算任务的结构和流程。
拓扑由一系列组件组成,包括数据源(Spout)、数据处理节点(Bolt)以及它们之间的连接关系。
2. 数据源(Spout):Spout负责从外部数据源获取数据,并将其发送给Bolt进行处理。
在拓扑中,通常会有一个或多个Spout进行数据输入。
3. 数据处理节点(Bolt):Bolt是对数据进行实际处理的模块。
在Bolt中可以进行各种自定义的操作,如过滤、转换、聚合等,根据业务需求不同而定。
4. 流组(Stream Grouping):Stream Grouping决定了从一个Bolt到下一个Bolt 之间的任务调度方式。
Storm提供了多种Stream Grouping策略,包括随机分组、字段分组、全局分组等。
5. 可靠性与容错性:Storm具有高可靠性和容错性的特点。
它通过对任务状态进行追踪、失败重试机制和数据备份等方式,确保了整个计算过程的稳定性。
6. 水平扩展:Storm可以很方便地进行水平扩展。
通过增加计算节点和调整拓扑结构,可以实现对处理能力的无缝提升。
三、Storm的应用场景1. 实时分析与计算:Storm适用于需要对大规模实时数据进行即时分析和计算的场景。
比如金融领域中的实时交易监控、电商平台中用户行为分析等。
2. 流式ETL:Storm可以实现流式ETL(Extract-Transform-Load)操作,将源数据进行抽取、转换和加载到目标系统中,并实时更新数据。
3. 实时推荐系统:通过结合Storm和机器学习算法,可以构建快速响应的实时推荐系统。
JStorm—实时流式计算框架入门介绍
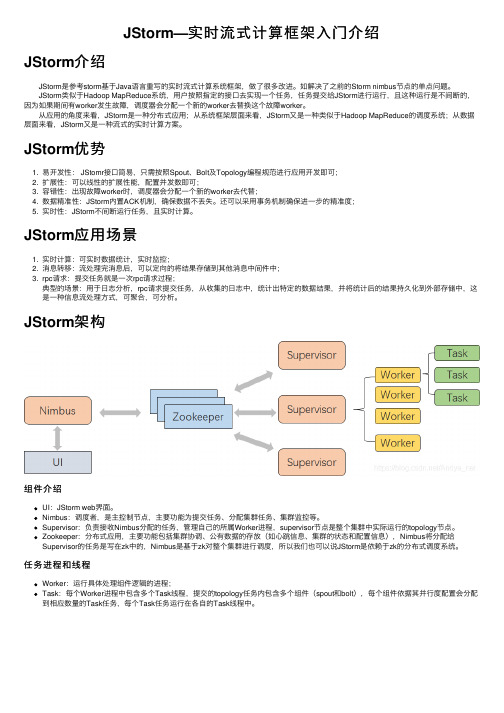
JStorm—实时流式计算框架⼊门介绍JStorm介绍 JStorm是参考storm基于Java语⾔重写的实时流式计算系统框架,做了很多改进。
如解决了之前的Storm nimbus节点的单点问题。
JStorm类似于Hadoop MapReduce系统,⽤户按照指定的接⼝去实现⼀个任务,任务提交给JStorm进⾏运⾏,且这种运⾏是不间断的,因为如果期间有worker发⽣故障,调度器会分配⼀个新的worker去替换这个故障worker。
从应⽤的⾓度来看,JStorm是⼀种分布式应⽤;从系统框架层⾯来看,JStorm⼜是⼀种类似于Hadoop MapReduce的调度系统;从数据层⾯来看,JStorm⼜是⼀种流式的实时计算⽅案。
JStorm优势1. 易开发性: JStomr接⼝简易,只需按照Spout、Bolt及Topology编程规范进⾏应⽤开发即可;2. 扩展性:可以线性的扩展性能,配置并发数即可;3. 容错性:出现故障worker时,调度器会分配⼀个新的worker去代替;4. 数据精准性:JStorm内置ACK机制,确保数据不丢失。
还可以采⽤事务机制确保进⼀步的精准度;5. 实时性:JStorm不间断运⾏任务,且实时计算。
JStorm应⽤场景1. 实时计算:可实时数据统计,实时监控;2. 消息转移:流处理完消息后,可以定向的将结果存储到其他消息中间件中;3. rpc请求:提交任务就是⼀次rpc请求过程;典型的场景:⽤于⽇志分析,rpc请求提交任务,从收集的⽇志中,统计出特定的数据结果,并将统计后的结果持久化到外部存储中,这是⼀种信息流处理⽅式,可聚合,可分析。
JStorm架构组件介绍UI:JStorm web界⾯。
Nimbus:调度者,是主控制节点,主要功能为提交任务、分配集群任务、集群监控等。
Supervisor:负责接收Nimbus分配的任务,管理⾃⼰的所属Worker进程,supervisor节点是整个集群中实际运⾏的topology节点。
storm 面试题

storm 面试题Storm面试题1. Introduction to StormStorm是一个开源的分布式实时计算系统,用于处理大规模实时数据流。
它是一个可靠和高效的系统,可以将海量数据在分布式集群上进行并行处理,实现实时分析和计算。
本文将介绍Storm的工作原理、应用场景以及面试常见问题。
2. Storm的工作原理Storm使用了一种称为"Topology"的数据处理模型,其中包含多个组件,包括Spout、Bolt和Stream。
Spout负责数据源的读取和发送,Bolt负责数据转换和处理,Stream用于在Spout和Bolt之间传递数据。
Storm的工作流程如下:(1) 数据流入系统,由Spout接收数据并发送给Bolt。
(2) Bolt对接收到的数据进行处理和计算。
(3) 处理完成后,Bolt可以发送数据到其他Bolt,形成数据流的连续处理。
(4) 最后,数据可以被存储到数据库、文件系统或其他外部系统中。
Storm的分布式架构使得它能够处理大规模数据流,并实现高可用性和容错性。
它将工作负载分散到集群中的多台计算机上,并通过消息传递机制实现组件间的通信。
3. Storm的应用场景Storm在实时数据分析和处理方面具有广泛的应用场景,包括但不限于以下几个方面:(1) 金融领域:Storm可以用于实时风险管理、交易监控和欺诈检测。
它能够对流式数据进行复杂计算和规则验证,以实现实时预警和决策支持。
(2) 电信领域:Storm可以用于网络监控和故障诊断,实时分析和处理大量网络数据。
它可以帮助运营商及时发现并解决网络问题,提高网络运行的稳定性和可靠性。
(3) 电商领域:Storm可以用于实时推荐系统、广告投放和用户行为分析。
它能够根据用户的实时行为和偏好生成个性化推荐,提高用户购物体验和销售转化率。
(4) 物联网领域:Storm可以用于实时监测和分析传感器数据,实现设备状态监控和异常检测。
storm的5个主要术语

Storm的5个主要术语Storm是一个开源分布式实时计算系统,它被广泛应用于大规模数据处理和实时分析。
在Storm中,有一些主要的术语被用来描述其核心概念和工作原理。
本文将详细介绍Storm的5个主要术语,包括拓扑(Topology)、流(Stream)、Spout、Bolt和任务(Task)。
1. 拓扑(Topology)拓扑是Storm中最基本的概念之一。
它表示了一个实时计算任务的结构和流程。
拓扑由多个组件(Component)组成,每个组件负责特定的数据处理任务。
组件之间通过流进行连接,形成了一个有向无环图。
拓扑可以看作是一个数据处理的蓝图,它定义了数据从输入到输出的整个计算过程。
在拓扑中,每个组件都可以并行执行,并且可以在不同节点上进行分布式部署。
通过合理设计拓扑结构,可以实现高效的数据处理和并行计算。
2. 流(Stream)流是Storm中用来传递数据的基本单位。
它代表了一系列具有相同类型的数据项,在拓扑中从一个组件流向另一个组件。
流可以包含多个字段,每个字段都有特定的类型和含义。
在拓扑中,流可以被分为多个分支,每个分支可以由不同的组件处理。
这种方式使得数据可以以不同的路径进行处理,从而实现更灵活和高效的计算。
同时,流还支持多种操作,如过滤、聚合、转换等,可以对数据进行各种形式的处理和加工。
3. SpoutSpout是Storm中用于数据输入的组件。
它负责从外部数据源读取数据,并将其发送到拓扑中的下一个组件。
Spout可以读取各种不同类型的数据源,如消息队列、文件系统、数据库等。
在拓扑中,Spout通常是数据流的起点。
它以一定的速率产生数据,并通过流发送给下一个组件进行处理。
Spout还可以实现可靠性保证机制,确保数据不会丢失或重复发送。
通过合理配置Spout的并行度和任务数,可以实现高吞吐量和低延迟的数据输入。
4. BoltBolt是Storm中用于数据处理和计算的组件。
它接收来自上游组件(如Spout或其他Bolt)传递过来的数据流,并对其进行加工、过滤、聚合等操作。
基于STORM分布式计算的海量数据统计系统设计方法研究

基于STORM分布式计算的海量数据统计系统设计方法研究陈 波(携程旅游信息技术(上海)有限公司,上海 200050)摘 要:笔者运用STORM分布式系统的强大计算能力以及高性能的KAFKA分布式消息系统来实现海量数据实时统计系统。
该系统通过KAFKA发送、存储、接收接口将计算的原始数据实时传递给STORM。
STORM通过Spout作为KAFKA的Consumer接收数据,将数据转发给内部组件Bolt,通过Bolt分布在多台机器进行数据计算,最后又将计算后的数据返回给KAFKA供第三方应用。
STORM支持数据重发,通过ACK机制保证数据计算的可靠性。
最后通过电商订单统计系统实例,给出海量数据实时统计系统详细的设计方法。
关键词:STORM;KAFKA;分布式系统;大数据;实时计算中图分类号:TP311.52 文献标识码:A 文章编号:1003-9767(2017)04-122-04Research on Design Method of Massive Data Statistic System based onSTORM Distributed ComputingChen Bo(Ctrip Tourism Information Technology (Shanghai) Co., Ltd., Shanghai 200050, China) Abstract: The author uses the powerful computing power of STORM distributed system and the high performance KAFKA distributed message system to realize the real-time statistical system of massive data. The system transmits the stored raw data to STORM in real time by sending, storing and receiving the interface through KAFKA. STORM through Spout as KAFKA the Consumer receive data, the data forwarded to the internal component Bolt, through the Bolt distribution in multiple machines for data calculation, and finally return the calculated data to KAFKA for third-party applications. STORM supports data retransmission, through the ACK mechanism to ensure the reliability of data calculation. Finally, the author gives the detailed design method of the real-time statistical system of massive data through the example of electricity quotient system.Key words: STORM; KAFKA; distributed system; big data; real-time calculation随着互联网技术的应用不断深入,各类应用系统产生的业务数据越来越多,基于业务数据的计算应用越来越重要。
分布式实时(流)计算框架

MZ案例介02—GN平台采集
从2个GN平台采集Gn原始数据, 将原始数据的文档合并,上限 为50个文档。每个文档的大小 约为200MB,合并后的文档上 限为10GB。合并后的文档上传 至HDFS平台。 上传的HDFS目录分别是 /tmp/gn/1和 /tmp/gn/2, 再 根据上传的时间点建立新的目 录.
RDMS
整个数据处理流程包括四部分: 第一部分是数据接入层,该部分从前端业务系统获取数据; 第二部分是最重要的storm实时处理部分,数据从接入层接入,经过实时处理后传入 数据落地层; 第三部分为数据落地层,该部分指定了数据的落地方式; 第四部分元数据管理器。
7
Storm实时计算业务接口
8
Storm实时计算具体业务需求
(1) 条件过滤
这是Storm最基本的处理方式,对符合条件的数据进行实时过滤,将符合条件的数据保存下来,
这种实时查询的业务需求在实际应用中是很常见的。
(2) 中间计算
我们需要改变数据中某一个字段(例如是数值),我们需要利用一个中间值经过计算(值比 较、求和、求平均等等)后改变该值,然后将数据重新输出。
(3) 求TopN
相信大家对TopN类的业务需求也是比较熟悉的,在规定时间窗口内,统计数据出现的TopN, 该类处理在购物及电商业务需求中,比较常见。
(4) 推荐系统
正如我架构图中画的那样,有时候在实时处理时会从mysql及hadoop中获取数据库中的信息, 例如在电影推荐系统中,传入数据为用户当前点播电影信息,从数据库中获取的是该用户之前的 一些点播电影信息统计,例如点播最多的电影类型、最近点播的电影类型,及其社交关系中点播
13
MediationZone--集中控制,分布执行
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
论Storm分布式实时计算工具
作者:沈超邓彩凤
来源:《中国科技纵横》2014年第03期
【摘要】互联网的应用催生了一大批新的数据处理技术,storm分布式实时处理工具以其强大的数据处理能力、可靠性高、扩展性好等特点,在近几年得到越来越广泛的关注和应用。
【关键词】分布式实时计算流处理
1 背景及特点
互联网的应用正在越来越深入的改变人们的生活,互联网技术也在不断发展,尤其是大数据处理技术,过去的十年是大数据处理技术变革的十年,MapReduce,Hadoop以及一些相关的技术使得我们能处理的数据量比以前要大得多得多。
但是这些数据处理技术都不是实时的系统,或者说,它们设计的目的也不是为了实时计算。
没有什么办法可以简单地把hadoop变成一个实时计算系统。
实时数据处理系统和批量数据处理系统在需求上有着本质的差别。
然而大规模的实时数据处理已经越来越成为一种业务需求了,而缺少一个“实时版本的hadoop”已经成为数据处理整个生态系统的一个巨大缺失。
而storm的出现填补了这个缺失。
Storm出现之前,互联网技术人员可能需要自己手动维护一个由消息队列和消息处理者所组成的实时处理网络,消息处理者从消息队列取出一个消息进行处理,更新数据库,发送消息给其它队列等等。
不幸的是,这种方式有以下几个缺陷:
单调乏味:技术人员花费了绝大部分开发时间去配置把消息发送到哪里,部署消息处理者,部署中间消息节点—设计者的大部分时间花在设计,配置这个数据处理框架上,而真正关心的消息处理逻辑在代码里面占的比例很少。
脆弱:不够健壮,设计者要自己写代码保证所有的消息处理者和消息队列正常运行。
伸缩性差:当一个消息处理者的消息量达到阀值,需要对这些数据进行分流,配置这些新的处理者以让他们处理分流的消息。
Storm定义了一批实时计算的原语。
如同hadoop大大简化了并行批量数据处理,storm的这些原语大大简化了并行实时数据处理。
storm的一些关键特性如下:
适用场景广泛:storm可以用来处理消息和更新数据库(消息流处理),对一个数据量进行持续的查询并返回客户端(持续计算),对一个耗资源的查询作实时并行化的处理(分布式方法调用),storm的这些基础原语可以满足大量的场景。
可伸缩性高:Storm的可伸缩性可以让storm每秒可以处理的消息量达到很高。
Storm使用ZooKeeper来协调集群内的各种配置使得Storm的集群可以很容易的扩展很大。
保证无数据丢失:实时系统必须保证所有的数据被成功的处理。
那些会丢失数据的系统的适用场景非常窄,而storm保证每一条消息都会被处理,这一点和S4相比有巨大的反差。
异常健壮:不像Hadoop—出了名的难管理,storm集群非常容易管理。
容易管理是storm 的设计目标之一。
语言无关性:健壮性和可伸缩性不应该局限于一个平台。
Storm的topology和消息处理组件可以用任何语言来定义,这一点使得任何人都可以使用storm。
2 storm的关键概念
计算拓补:Topologies
一个实时计算应用程序的逻辑在storm里面被封装到topology对象里面,我把它叫做计算拓补。
Storm里面的topology相当于Hadoop里面的一个MapReduce Job,它们的关键区别是:一个MapReduce Job最终总是会结束的,然而一个storm的topoloy会一直运行—除非你显式的杀死它。
一个Topology是Spouts和Bolts组成的图状结构,而链接Spouts和Bolts的则是Streamgroupings。
消息流:Streams
消息流是storm里面的最关键的抽象。
一个消息流是一个没有边界的tuple序列,而这些tuples会被以一种分布式的方式并行地创建和处理。
对消息流的定义主要是对消息流里面的tuple的定义,我们会给tuple里的每个字段一个名字。
并且不同tuple的对应字段的类型必须一样。
也就是说:两个tuple的第一个字段的类型必须一样,第二个字段的类型必须一样,但是第一个字段和第二个字段可以有不同的类型。
在默认的情况下,tuple的字段类型可以是:integer,long,short,byte,string,double,float,boolean和bytearray。
你还可以自定义类型—只要你实现对应的序列化器。
3 storm应用及前景
根据storm的特点,大致有两个应用模式:(1)实时流处理;(2)drpc调用;前者就是通过消息队列等方式将数据源源不断的发送给storm集群来处理,而后者,类似于开启一个服务,客户端方面可以远程的发送数据给storm并同步或异步的接收到处理结果。
storm的应用场景非常广泛,具体如下:
监控系统:监控整个集群的状态,当出现异常log的时候进行分析,对异常进行分类并实时发出报警,提示运维人员来维护。
并且可以进一步考虑。
这样可以对整个系统的做一个很好的监控和反应。
安全系统:在信息安全领域中,做实时的流量分析,异常过滤、恶意攻击检测等。
实时计算:根据之前数据分析人员分析计算的数学模型,如点击量预估模型、用户付费预期计算模型、好友推荐算法,放到storm的拓扑中,通过topology来计算,可以帮助实时为用户提供服务、及时发现问题、极大的提高工作效率,而不必受制于老的计算模式,如一天计算一次、一小时计算一次等。
Storm0.7系列的版本已经在各大公司得到了广泛使用,最近发布的0.8版本中引入了State,使得其从一个纯计算框架演变成了一个包含存储和计算的实时计算新利器,还有刚才提到的Trident,提供更加友好的接口,同时可定制scheduler的特性也为其针对不同的应用场景做优化提供了更便利的手段,也有人已经在基于storm的实时ql(query language)上迈出了脚本。
在服务化方面,storm一直在朝着融入mesos框架的方向努力。
同时,storm也在实现细节上不断地优化,使用很多优秀的开源产品,包括kryo,Disruptor,curator等等。
可以想象,当storm发展到1.0版本时,一定是一款无比杰出的产品。