采用邻接表存储结构-编写一个求无向图的连通分量个数的算法
323.无向图中连通分量的数目

323.⽆向图中连通分量的数⽬题⽬:给定编号从 0 到 n-1 的 n 个节点和⼀个⽆向边列表(每条边都是⼀对节点),请编写⼀个函数来计算⽆向图中连通分量的数⽬。
⽰例 1:输⼊: n = 5 和 edges = [[0, 1], [1, 2], [3, 4]]0 3| |1 ---2 4输出: 2⽰例 2:输⼊: n = 5 和 edges = [[0, 1], [1, 2], [2, 3], [3, 4]]0 4| |1 ---2 --- 3输出: 1注意:你可以假设在 edges 中不会出现重复的边。
⽽且由于所以的边都是⽆向边,[0, 1] 与 [1, 0] 相同,所以它们不会同时在 edges 中出现。
解答:DFS:维持⼀个未遍历过的节点,每次取⼀个为遍历过的节点,然后从它开始dfs,遍历所有可达的节点,也就是找到了⼀个连通分量。
class Solution {public:int countComponents(int n, vector<vector<int>>& edges) {if(n<=0){return0;}unordered_map<int,unordered_set<int> > edge_map;for(auto& edge:edges){edge_map[edge[0]].insert(edge[1]);edge_map[edge[1]].insert(edge[0]);}unordered_set<int> unvisited;for(int i=0;i<n;++i){unvisited.insert(i);}int res=0;while(unvisited.size()>0){// for(int x:unvisited){// cout<<x<<" ";// }cout<<endl;auto cur=unvisited.begin();dfs(*cur,unvisited,edge_map);++res;}return res;}void dfs(int cur,unordered_set<int>& unvisited,unordered_map<int,unordered_set<int> >& edge_map){unvisited.erase(cur);for(const int& neighbour:edge_map[cur]){if(unvisited.count(neighbour)){dfs(neighbour,unvisited,edge_map);}}}};并差集:(开始没想到,确实是个好⽅法)class Solution {public:vector<int> father;int Father(int i){if(father[i]!=i){return father[i]=Father(father[i]);}return i;}void merge(int x,int y){int px=Father(x),py=Father(y);father[px]=py;}int countComponents(int n, vector<vector<int>>& edges) {father.resize(n);for(int i=0;i<n;++i){father[i]=i;}for(auto& edge:edges){merge(edge[0],edge[1]);}unordered_set<int> tmp;for(int i=0;i<n;++i){if(tmp.count(Father(i))==0){//注意这⾥要调⽤Father(i)函数,因为可能i的⽗亲还没有更新为最靠上的祖先。
计算机学科专业基础综合数据结构-图(二)_真题-无答案

计算机学科专业基础综合数据结构-图(二)(总分100,考试时间90分钟)一、单项选择题(下列每题给出的4个选项中,只有一个最符合试题要求)1. 具有6个顶点的无向图至少应有______条边才能确保是一个连通图。
A.5 B.6 C.7 D.82. 设G是一个非连通无向图,有15条边,则该图至少有______个顶点。
A.5 B.6 C.7 D.83. 下列关于无向连通图特性的叙述中,正确的是______。
①所有顶点的度之和为偶数②边数大于顶点个数减1③至少有一个顶点的度为1A.只有① B.只有② C.①和② D.①和③4. 对于具有n(n>1)个顶点的强连通图,其有向边的条数至少是______。
A.n+1B.nC.n-1D.n-25. 下列有关图的说法中正确的是______。
A.在图结构中,顶点不可以没有任何前驱和后继 B.具有n个顶点的无向图最多有n(n-1)条边,最少有n-1条边 C.在无向图中,边的条数是结点度数之和 D.在有向图中,各顶点的入度之和等于各顶点的出度之和6. 对于一个具有n个顶点和e条边的无向图,若采用邻接矩阵表示,则该矩阵大小是______,矩阵中非零元素的个数是2e。
A.n B.(n-1)2 C.n-1 D.n27. 无向图的邻接矩阵是一个______。
A.对称矩阵 B.零矩阵 C.上三角矩阵 D.对角矩阵8. 从邻接矩阵可知,该图共有______个顶点。
如果是有向图,该图共有4条有向边;如果是无向图,则共有2条边。
A.9 B.3 C.6 D.1 E.5 F.4 G.2 H.09. 下列说法中正确的是______。
A.一个图的邻接矩阵表示是唯一的,邻接表表示也唯一 B.一个图的邻接矩阵表示是唯一的,邻接表表示不唯一 C.一个图的邻接矩阵表示不唯一,邻接表表示唯一 D.一个图的邻接矩阵表示不唯一,邻接表表示也不唯一10. 用邻接表存储图所用的空间大小______。
A.与图的顶点数和边数都有关 B.只与图的边数有关 C.只与图的顶点数有关 D.与边数的二次方有关11. 采用邻接表存储的图的深度优先搜索算法类似于二叉树的______,广度优先搜索算法类似于二叉树的层次序遍历。
数据结构作业答案第章图作业答案

第7章 图 自测卷解答 姓名 班级一、单选题(每题1分,共16分) 前两大题全部来自于全国自考参考书!( C )1. 在一个图中,所有顶点的度数之和等于图的边数的 倍。
A .1/2 B. 1 C. 2 D. 4 (B )2. 在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的 倍。
A .1/2 B. 1 C. 2 D. 4 ( B )3. 有8个结点的无向图最多有 条边。
A .14 B. 28 C. 56 D. 112 ( C )4. 有8个结点的无向连通图最少有 条边。
A .5 B. 6 C. 7 D. 8 ( C )5. 有8个结点的有向完全图有 条边。
A .14 B. 28 C. 56 D. 112 (B )6. 用邻接表表示图进行广度优先遍历时,通常是采用 来实现算法的。
A .栈 B. 队列C. 树D. 图 ( A )7. 用邻接表表示图进行深度优先遍历时,通常是采用 来实现算法的。
A .栈 B. 队列C. 树D. 图 ( )8. 已知图的邻接矩阵,根据算法思想,则从顶点0出发按深度优先遍历的结点序列是( D )9. 已知图的邻接矩阵同上题8,根据算法,则从顶点0出发,按深度优先遍历的结点序列是A . 0 2 4 3 1 5 6 B. 0 1 3 5 6 4 2 C. 0 4 2 3 1 6 5 D. 0 1 3 4 2 5 6 ( )10. 已知图的邻接矩阵同上题8,根据算法,则从顶点0出发,按广度优先遍历的结点序列是A . 0 2 4 3 6 5 1 B. 0 1 3 6 4 2 5 C. 0 4 2 3 1 5 6 D. 0 1 3 4 2 5 6 (建议:0 1 2 3 4 5 6) ( C )11. 已知图的邻接矩阵同上题8,根据算法,则从顶点0出发,按广度优先遍历的结点序列是A . 0 2 4 3 1 6 5 B. 0 1 3 5 6 4 2 C. 0 1 2 3 4 6 5 D. 0 1 2 3 4 5 6A .0 2 4 3 1 5 6B. 0 1 3 6 5 4 2C. 0 4 2 3 1 6 5D. 0 3 6 1 5 4 2建议:先画出图,再深度遍历⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡0100011101100001011010110011001000110010011011110( A )12. 已知图的邻接表如下所示,根据算法,则从顶点0出发不是深度优先遍历的结点序列是A.0 1 3 2 B. 0 2 3 1C. 0 3 2 1D. 0 1 2 3(A)14. 深度优先遍历类似于二叉树的A.先序遍历 B. 中序遍历 C. 后序遍历 D. 层次遍历(D)15. 广度优先遍历类似于二叉树的A.先序遍历 B. 中序遍历 C. 后序遍历 D. 层次遍历(A)16. 任何一个无向连通图的最小生成树A.只有一棵 B. 一棵或多棵 C. 一定有多棵 D. 可能不存在(注,生成树不唯一,但最小生成树唯一,即边权之和或树权最小的情况唯一)二、填空题(每空1分,共20分)1. 图有邻接矩阵、邻接表等存储结构,遍历图有深度优先遍历、广度优先遍历等方法。
第7章自测题与答案

第7章图自测卷解答姓名班级题号一二三四五总分题分1620241030100得分一、单选题(每题1分,共16分)(C)1.在一个图中,所有顶点的度数之和等于图的边数的倍。
A.1/2B.1C.2D.4(B)2.在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的倍。
A.1/2B.1C.2D.4(B)3.有8个结点的无向图最多有条边。
A.14B.28C.56D.112(C)4.有8个结点的无向连通图最少有条边。
A.5B.6C.7D.8(C)5.有8个结点的有向完全图有条边。
A.14B.28C.56D.112(B)6.用邻接表表示图进行广度优先遍历时,通常是采用来实现算法的。
A.栈B.队列C.树D.图(A)7.用邻接表表示图进行深度优先遍历时,通常是采用来实现算法的。
A.栈B.队列C.树D.图(C)8.已知图的邻接矩阵,根据算法思想,则从顶点0出发按深度优先遍历的结点序列是01111011001001A.02431561000100B.0136542C.042316511001101011010D.03615420001101建议:01342561100010(D)9.已知图的邻接矩阵同上题8,根据算法,则从顶点0出发,按深度优先遍历的结点序列是A.0243156B.0135642C.0423165D.0134256(B)10.已知图的邻接矩阵同上题8,根据算法,则从顶点0出发,按广度优先遍历的结点序列是A.0243651B.0136425C.0423156D.0134256(建议:0123456)(C)11.已知图的邻接矩阵同上题8,根据算法,则从顶点0出发,按广度优先遍历的结点序列是A.0243165B.0135642C.0123465D.01234561(D)12.已知图的邻接表如下所示,根据算法,则从顶点0出发按深度优先遍历的结点序列是A.0132B.0231C.0321D.0123(A)13.已知图的邻接表如下所示,根据算法,则从顶点0出发按广度优先遍历的结点序列是A.0321B.0123C.0132D.0312(A)14.深度优先遍历类似于二叉树的A.先序遍历B.中序遍历C.后序遍历D.层次遍历(D)15.广度优先遍历类似于二叉树的A.先序遍历B.中序遍历C.后序遍历D.层次遍历(A)16.任何一个无向连通图的最小生成树A.只有一棵B.一棵或多棵C.一定有多棵D.可能不存在(注,生成树不唯一,但最小生成树唯一,即边权之和或树权最小的情况唯一)二、填空题(每空1分,共20分)1.图有邻接矩阵、邻接表等存储结构,遍历图有深度优先遍历、广度优先遍历等方法。
图练习与答案
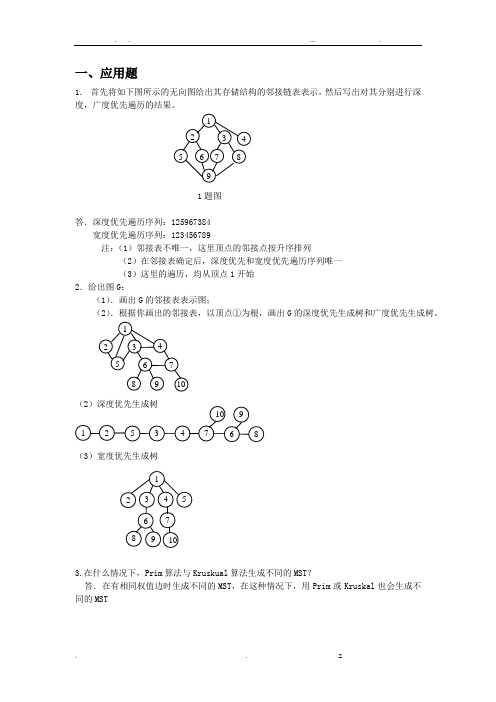
一、应用题1.首先将如下图所示的无向图给出其存储结构的邻接链表表示,然后写出对其分别进行深度,广度优先遍历的结果。
1题图答.深度优先遍历序列:125967384宽度优先遍历序列:123456789注:(1)邻接表不唯一,这里顶点的邻接点按升序排列(2)在邻接表确定后,深度优先和宽度优先遍历序列唯一(3)这里的遍历,均从顶点1开始2.给出图G:(1).画出G的邻接表表示图;(2).根据你画出的邻接表,以顶点①为根,画出G的深度优先生成树和广度优先生成树。
(3)宽度优先生成树3.在什么情况下,Prim算法与Kruskual算法生成不同的MST?答.在有相同权值边时生成不同的MST,在这种情况下,用Prim或Kruskal也会生成不同的MST4.已知一个无向图如下图所示,要求分别用Prim 和Kruskal 算法生成最小树(假设以①为起点,试画出构造过程)。
答.Prim 算法构造最小生成树的步骤如24题所示,为节省篇幅,这里仅用Kruskal 算法,构造最小生成树过程如下:(下图也可选(2,4)代替(3,4),(5,6)代替(1,5))5.G=(V,E)是一个带有权的连通图,则:(1).请回答什么是G 的最小生成树; (2).G 为下图所示,请找出G 的所有最小生成树。
28题图答.(1)最小生成树的定义见上面26题 (2)最小生成树有两棵。
(限于篇幅,下面的生成树只给出顶点集合和边集合,边以三元组(Vi,Vj,W )形式),其中W 代表权值。
V (G )={1,2,3,4,5} E1(G)={(4,5,2),(2,5,4),(2,3,5),(1,2,7)};E2(G)={(4,5,2),(2,4,4),(2,3,5),(1,2,7)}6.请看下边的无向加权图。
(1).写出它的邻接矩阵。
(2).按Prim 算法求其最小生成树,并给出构造最小生成树过程中辅助数组的各分量值。
辅助数组各分量值:7.已知世界六大城市为:(Pe)、纽约(N)、巴黎(Pa)、伦敦(L) 、东京(T) 、墨西哥(M),下表给定了这六大城市之间的交通里程:世界六大城市交通里程表(单位:百公里)(1).画出这六大城市的交通网络图;(2).画出该图的邻接表表示法;(3).画出该图按权值递增的顺序来构造的最小(代价)生成树.8.已知顶点1-6和输入边与权值的序列(如右图所示):每行三个数表示一条边的两个端点和其权值,共11行。
Python编程实例:计算图的连通分量

06
总结与展望
总结连通分量计算的重要性和应用场景
连通分量计算是图论中的基本问题,对于理解图的结构和性质至关重 要。
连通分量计算在社交网络分析、网页排名、图像分割等领域有着广泛 的应用。
连通分量计算可以帮助我们更好地理解数据的分布和关联,从而为实 际问题提供有效的解决方案。
未来,随着图数据的不断增加,连通分量计算的重要性和应用场景将 会更加广泛。
计算连通分量:使用 networkx库的
connected_compon ents函数
输出结果:将计算 结果打印或保存到 文件中
05
连通分量计算的应用
在社交网络分析中的应用
社交网络中的连通分量:表 示社交网络中相互连接的用 户群体
连通分量的应用:分析社交 网络的结构和特性,例如找 出核心用户群、检测社交网 络中的社区结构等
添加标题
顶点表:存储图中所有顶点的信息,如顶点编号 、顶点名称等
添加标题
边表:存储图中所有边的信息,如起始顶点、终 止顶点、边的权重等
添加标题
邻接表表示法的优点:易于实现图的基本操作, 如添加顶点、删除顶点、添加边、删除边等
添加标题
邻接表表示法的缺点:占用空间较大,不适合表 示稀疏图
添加标题
Python实现图的连通分量计算时,可以使用邻接 表表示法来存储图结构,方便地进行图的遍历和 操作。
在交通运输网络中的应用
计算图的连通分量可以帮助我们理解交通运输网络的结构
通过计算连通分量,可以找出交通网络的关键节点和关键路径
在交通网络优化中,连通分量的计算可以帮助我们找到最优的交通路 线
连通分量的计算还可以帮助我们预测交通网络的拥堵情况,并采取相 应的措施进行缓解
算法与数据结构重考复习题(0910)

i列1的元素之和 )。对于含n个顶点和e条边的图,采用邻接矩阵表示的空间复杂度为( O(n2) )。连通图
是指图中任意两个顶点之间(都连通的无向图 )。一个有n个顶点的无向连通图,它所包含的连通分量个数最
保持青春的秘诀,是有一颗不安分的心。
算法与数据结构重考复习题(0910)
一、单选题(斜体为答案)
1.数据结构被形式地定义为(D,R),其中D 是
A. 算法 B. 操作的集合 C. 数据元素的集合 D. 数据关系的集合
2.顺序表是线性表的
A. 顺序存储结构 B. 链式存储结构 C. 索引存储结构 D. 散列存储结构
5.已知栈的输入序列为1,2,3....,n,输出序列为a1,a2,...,an,a2=n的输出序列共有(n-1)种输出序列。
队列的特性是先入先出,栈的特性是(后入先出)。如果以链栈为存储结构,则出栈操作时必须判别(栈空 )。与顺序栈相比,链栈有一个明显的优势是( 不易出现栈满 )。
6.循环队列采用数组data[1..n]来存储元素的值,并用front和rear分别作为其头尾指针。为区分队列的满和空,约定:队中能够存放的元素个数最大为(n-l),也即至少有一个元素空间不用,则在任意时刻,至少可以知道一个空的元素的下标是(front) ;入队时,可用语句(rear=rear+1%n)求出新元素在数组data中的下标。
(3)双向链表:q=p->prior; temp=q->data; q->data=p->data;p->data=temp;
2.内存中一片连续空间(不妨设地址从1到m),提供给两个栈S1和S2使用,怎样分配这部分存储空间,使得对任意一个栈,仅当这部分全满时才发生上溢。(为了尽量利用空间,减少溢出的可能,可采用栈顶相向,栈底分设两端的存储方式,这样,对任何一个栈,仅当整个空间全满时才会发生上溢。)
数据结构(第二版)习题

第一章绪论一、问答题1.什么是数据结构?2.叙述四类基本数据结构的名称与含义。
3.叙述算法的定义与特性。
4.叙述算法的时间复杂度。
5.叙述数据类型的概念。
6. 叙述线性结构与非线性结构的差别。
7.叙述面向对象程序设计语言的特点。
8.在面向对象程序设计中,类的作用是什么?9.叙述参数传递的主要方式及特点。
10.叙述抽象数据类型的概念。
二、判断题(在各题后填写“√”或“×”)1.线性结构只能用顺序结构来存放,非线性结构只能用非顺序结构来存放。
()2.算法就是程序。
()3. 在高级语言(如C或PASCAL)中,指针类型是原子类型。
()三、计算下列程序段中X=X+1的语句频度for(i=1;i<=n;i++)for(j=1;j<=i;j++)for(k=1;k<=j;k++)x=x+1;四、试编写算法,求一元多项式Pn(x)=a0+a1x+a2x2+a3x3+…anxn的值Pn(x0),并确定算法中的每一语句的执行次数和整个算法的时间复杂度,要求时间复杂度尽可能小,规定算法中不能使用求幂函数。
注意:本题中的输入ai(i=0,1,…,n),x和n,输出为Pn(x0)。
通常算法的输入和输出可采用下列两种方式之一:(1)通过参数表中的参数显式传递。
(2)通过全局变量隐式传递。
试讨论这两种方法的优缺点,并在本题算法中以你认为较好的一种方式实现输入和输出。
第二章线性表2.1描述以下三个概念的区别:头指针,头结点,首元素结点。
2.2填空:(1)在顺序表中插入或删除一个元素,需要平均移动____元素,具体移动的元素个数与__插入或删除的位置__有关。
(2)在顺序表中,逻辑上相邻的元素,其物理位置______相邻。
在单链表中,逻辑上相邻的元素,其物理位置______相邻。
(3)在带头结点的非空单链表中,头结点的存储位置由______指示,首元素结点的存储位置由______指示,除首元素结点外,其它任一元素结点的存储位置由____指示。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
w->mark=1;
L=w->first;
while(L!=NULL){
if((v+(L->position))->mark==0){
DFS(v,(v+L->position)); //递归调用
}
L=L->next;
}
}
int main(){
int i,j,k;
int num=0;
学院名称
专业班级
实验成绩
学生姓名
学号
实验日期
课程名称
数据结构
实验题目
3 图
一、实验目的与要求
熟悉图的存储结构,掌握有关算法的实现,了解图在计算机科学及其他工程技术中的应用。
二、主要仪器设备
Cfree
三、实验内容和原理
[问题描述]
采用邻接表存储结构,编写一个求无向图的连通分量个数的算法。
[输入]
图顶点的个数,和以各个顶点为弧尾的所有弧,并以-1结束输入。
[输出]
连通分量的个数。
[存储结构]
图采用邻接矩阵的方式存储。
[算法的基本思想]
用到深度优先搜索,先从任意一个顶点开始进行深度优先搜索,搜索完后,连通分量个数增1。然后再从没有遍历过的顶点找一个出来进行深度优先搜索,搜索完后,连通分量个数增1。一直到所有的顶点都被遍历过。
[参考源程序]
#include<stdio.h>
struct ArcNode* p;
struct VNode* temp;
struct VNode* flag;
printf("\n请输入顶点个数 n:");
scanf("%d",&n);
while(n<1){
printf("你输入的值不合理,请重新输入:\n");
scanf("%d",&n);
}
p=(struct ArcNode*)malloc(n*sizeof(struct ArcNode));
p[i].mark=0;
flag=temp;
scanf("%d"&k);while(k!=-1){
temp=(struct VNode*)malloc(sizeof(struct VNode));
temp->position=k;
temp->next=NULL;
flag->next=temp;
flag=temp;
/*说明:1.Vi表示第i个顶点,它在表中的位置为i-1,如V3在表中的位置为2;
2.如果输入以V1为弧尾的所有弧(假设存在弧<V1,V3>和<V1,V2>)
则输入:2 1 -1(只需输入弧头的位置,并用-1表示结束)*/
for(i=0;i<n;i++){ //创建无向图
printf("\n请输入以V%d为弧尾的所有弧,并以-1结束输入\n",i+1);
scanf("%d",&k);
}
}
}
i=0;
while(p[i].mark==0){ //计算连通分量的个数
DFS(p,(p+i));
num++;
i=0;
while(p[i].mark!=0&&i<n){
i++;
}
}
printf("此图的连通分量个数为:%d\n",num);
system("pause");
return 0;
}
五、实验结果与分析
习题1:这题主要还是用到深度优先搜索,先从任意一个顶点开始进行深度优先搜索,搜索完后,连通分量个数增1。然后再从没有遍历过的顶点找一个出来进行深度优先搜索,搜索完后,连通分量个数增1。一直到所有的顶点都被遍历过。
实验结果如图:
六、实验心得及体会
通过本次实验,我更好的掌握了图的相关操作,能够熟练的进行图的建立、遍历。
在编写程序时,有很多不明白的地方,在得到同学的鼎立相助后,基本解决了这些问题。
scanf("%d",&k);
if(k==-1){
p[i].mark=0;
p[i].first=NULL;
}
else{
temp=(struct VNode*)malloc(sizeof(struct VNode));
temp->position=k;
temp->next=NULL;
p[i].first=temp;
#include<malloc.h>
int n;
struct VNode{ //顶点
int position;
struct VNode* next;
};
struct ArcNode{ //弧
int mark;
struct VNode* first;
};
void DFS(struct ArcNode* v,struct ArcNode* w){ //深度优先搜索