计量经济学-李子奈-计算题集合
计量经济学李子奈计算题整理集合

第一题 下表给出了一含有3个实解释变量的模型的回归结果:方差来源 平方和(SS ) 自由度(d.f.)来自回归65965 —来自残差— —总离差(TSS) 66056 43(1)求样本容量n 、RSS 、ESS 的自由度、RSS 的自由度(2)求可决系数2R 和调整的可决系数2R(3)在5%的显著性水平下检验1X 、2X 和3X 总体上对Y 的影响的显著性(已知0.05(3,40) 2.84F =)(4)根据以上信息能否确定1X 、2X 和3X 各自对Y 的贡献?为什么? 答案:(1)样本容量n=43+1=44 (1分)RSS=TSS-ESS=66056-65965=91 (1分)ESS 的自由度为: 3 (1分)RSS 的自由度为: d.f.=44-3-1=40 (1分)(2)R 2=ESS/TSS=65965/66056=0.9986 (1分)2R =1-(1- R 2)(n-1)/(n-k-1)=1-0.001443/40=0.9985 (2分)(3)H 0:1230βββ=== (1分)F=/65965/39665.2/(1)91/40ESS k RSS n k ==-- (2分) F >0.05(3,40) 2.84F = 拒绝原假设 (2分)所以,1X 、2X 和3X 总体上对Y 的影响显著 (1分)(4)不能。
(1分)因为仅通过上述信息,可初步判断X 1,X 2,X 3联合起来对Y 有线性影响,三者的变化解释了Y 变化的约99.9%。
但由于无法知道回归X 1,X 2,X 3前参数的具体估计值,因此还无法判断它们各自对Y 的影响有多大。
(1分)第二题以某地区22年的年度数据估计了如下工业就业模型i i i i i X X X Y μββββ++++=3322110ln ln ln回归方程如下:ii i i X X X Y 321ln 62.0ln 25.0ln 51.089.3ˆ+-+-= (-0.56)(2.3) (-1.7) (5.8)20.996R = 147.3=DW 式中,Y 为总就业量;X 1为总收入;X 2为平均月工资率;X 3为地方政府的总支出。
李子奈《计量经济学》考试试卷(48)

某财经学院李子奈《计量经济学》课程试卷(含答案)__________学年第___学期考试类型:(闭卷)考试考试时间:90 分钟年级专业_____________学号_____________ 姓名_____________1、判断题(3分,每题1分)1. 消除序列相关的一阶差分变换假定自相关系数ρ必须等于1。
()正确错误答案:正确解析:消除序列相关的一阶差分变换假定自相关系数ρ=1,即假设随机干扰项之间是完全正序列相关的,这样广义差分方程就转化为一阶差分方程。
2. 随机干扰项μi和残差项ei是一回事。
()正确错误答案:错误解析:随机干扰项是针对总体回归模型而言的,它是模型中其他没有包含的因素的综合体;而残差项是针对样本回归模型而言的,它是实际观测值与样本回归线上值的离差。
两者的含义不同,后者只能说成是对前者的一个估计。
3. 在C-D生产函数Y=AKαLβ中,α和β分别是劳动与资本的产出弹性。
()正确错误答案:错误解析:在C-D生产函数Y=AKαLβ中,α和β分别是资本与劳动的产出弹性。
2、名词题(5分,每题5分)1. 总体回归函数答案:总体回归函数是指在给定量下Y,分布的总体均值与X所形成的函数关系(或者说将总体被解释变量的条件期望表示为解释变量的某种函数)。
由于变量间关系的随机性,回归分析关心的是根据解释变量的已知或给定值,考察被解释变量的总体均值,即当解释变量取某个确定值时,与之统计相关的被解释变量所有可能出现的对应值的平均值。
解析:空3、简答题(25分,每题5分)1. 表3-1列出了某地区家庭人均鸡肉年消费量Y,与家庭月平均收入X,鸡肉价格P1,猪肉价格P2与牛肉价格P3的相关数据。
表3-1(1)求出该地区关于家庭鸡肉消费需求的如下模型:lnY=β0+β1lnX+β2lnP1+β2lnP2+β3lnP3+μ(2)请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响?答案:(1)Eviews软件的回归结果如图3-1所示。
计量经济学 李子奈 第七版 复习题汇总

计量经济学 复习题一、单选题1、怀特检验法可用于检验( )。
A.异方差性B.多重共线性C.序列相关D.模型设定误差2、计量经济学分析问题的工作程序是( )。
A.设定模型,检验模型,估计模型,改进模型B.设定模型,估计参数,检验模型,应用模型C.估计模型,应用模型,检验模型,改进模型D.搜集资料,设定模型,估计参数,应用模型3、对下列模型进行经济意义检验,哪一个模型是没有实际意义的( )。
A.i C (消费)i I 8.0500+=(收入)B.di Q (商品需求)i I 8.010+=(收入)i P 9.0+(价格)C.si Q (商品供给)i P 75.020+=(价格)D.i Y (产出量)6.065.0i K =(资本)4.0i L (劳动)4、戈德菲尔德—匡特检验法可用于检验模型的( )。
A.异方差性B.多重共线性C.序列相关D.设定误差5、在满足基本假定的情况下,对单方程计量经济学模型而言,下列有关解释变量和被解释变量的说法中正确的有( )。
A.被解释变量和解释变量均为随机变量B.被解释变量和解释变量均为非随机变量C.被解释变量为随机变量,解释变量为非随机变量D.被解释变量为非随机变量,解释变量为随机变量6、根据样本资料估计得到人均消费支出Y 对人均收入X 的回归方程为X Y ln 75.000.2ln += ,这表明人均收入每增加1%,人均消费支出将增加( )。
A.2%B.0.75C.0.75%D.7.5%7、设k 为回归模型中的解释变量个数,n 为样本容量,则对总体回归模型进行显著性检验(F 检验)时构造的F 统计量为( )。
A.)1/()/(--=k n RSS k ESS F B. )k n /(RSS )1k /(ESS 1F ---=C. RSS ESS F =D. ESSRSS F = 8.下列属于有限分布滞后模型的是( )。
A.u y b y b x b y t t t t t a +++++=-- 22110B.u y b y b y b x b y t k t k t t t t a ++++++=--- 22110C.u x b x b y t t t ta ++++=- 110 D.u xb x b x b y tk t k t t t a +++++=-- 110 9、已知DW 统计量的值接近于0,则样本回归模型残差的一阶自相关系数ρˆ近似等于( )。
计量经济学李子奈(第3版)例题+习题数据
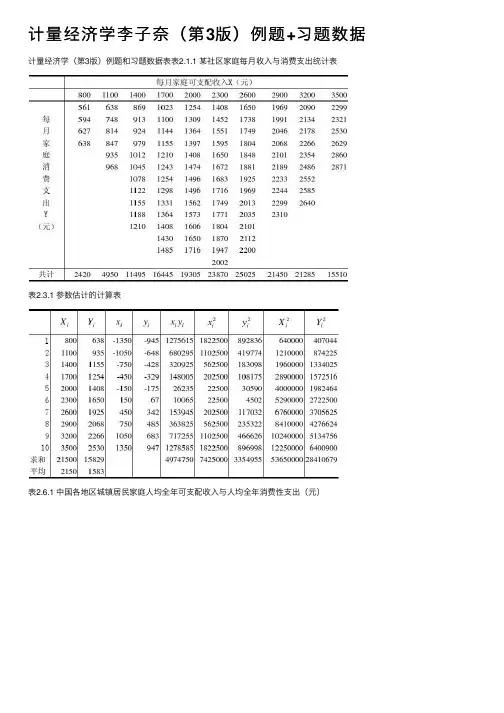
计量经济学李⼦奈(第3版)例题+习题数据计量经济学(第3版)例题和习题数据表表2.1.1 某社区家庭每⽉收⼊与消费⽀出统计表表2.3.1 参数估计的计算表表2.6.1 中国各地区城镇居民家庭⼈均全年可⽀配收⼊与⼈均全年消费性⽀出(元)资料来源:《中国统计年鉴》(2007)。
表2.6.3 中国居民总量消费⽀出与收⼊资料单位:亿元年份GDP CONS CPI TAX GDPC X Y 19783605.6 1759.1 46.21519.28 7802.5 6678.83806.7 19794092.6 2011.5 47.07537.828694.2 7551.64273.2 19804592.9 2331.2 50.62571.70 9073.7 7944.24605.5 19815008.8 2627.951.90629.899651.8 8438.05063.9 19825590.0 2902.9 52.95700.02 10557.3 9235.25482.4 19836216.2 3231.154.00775.5911510.8 10074.65983.2 19847362.7 3742.0 55.47947.35 13272.8 11565.06745.7 19859076.7 4687.460.652040.79 14966.8 11601.77729.2 198610508.5 5302.1 64.572090.37 16273.7 13036.58210.9 198712277.4 6126.1 69.302140.36 17716.3 14627.78840.0 198815388.6 7868.1 82.302390.47 18698.7 15794.09560.5 198917311.3 8812.6 97.002727.40 17847.4 15035.59085.5 199019347.8 9450.9 100.002821.86 19347.8 16525.99450.9 199122577.4 10730.6 103.422990.17 21830.9 18939.610375.8 199227565.2 13000.1 110.033296.91 25053.0 22056.511815.3 199336938.1 16412.1 126.204255.30 29269.1 25897.313004.7 199450217.4 21844.2 156.655126.88 32056.2 28783.413944.2 199563216.9 28369.7 183.416038.04 34467.5 31175.415467.9 199674163.6 33955.9 198.666909.82 37331.933853.717092.5 199781658.5 36921.5 204.218234.04 39988.5 35956.218080.6 199886531.6 39229.3 202.599262.80 42713.1 38140.919364.1 199991125.0 41920.4 199.7210682.58 45625.8 40277.020989.3 200098749.0 45854.6200.5512581.51 49238.0 42964.622863.9 2001108972.4 49213.2 201.9415301.38 53962.5 46385.424370.1 2002120350.3 52571.3 200.3217636.45 60078.0 51274.026243.2 2003136398.8 56834.4 202.7320017.31 67282.2 57408.128035.0 2004160280.4 63833.5 210.6324165.68 76096.3 64623.130306.2 2005188692.1 71217.5 214.4228778.54 88002.1 74580.433214.4 2006221170.5 80120.5 217.6534809.72 101616.3 85623.136811.2资料来源:根据《中国统计年鉴》(2001,2007)整理。
计量经济学李子奈第三版STATA答案

(5)
ˆ xt (6) y ˆ xt ˆ ˆ yt ˆt
(5)不正确。作为已经完成参数估计的模型,Yt应有“”标记。 故(6)正确。
在95%置信度下,均值E(Y0)的预测区间(或区间估计)为:
. adjust gdp=8500,ci se Dependent variable: y Command: regress Covariate set to value: gdp = 8500
All
xb 593.267
stdp (55.4871)
ˆ xt ˆ (3) yt t
不正确。作为计量经济学理论模型,待估计的参数不能用表示估计 量的符号“”标记,这样标记表示它们是已经估计出来。作为已 经完成参数估计的经济计量模型也是不正确的,残差项没有用“ 3 ” 标记。
ˆ xt ˆ (4) y ˆt t
14
或者在95%置信度下,均值E(Y0)的预测区间(或区间估计)为:
. adjust x1=35 x2=20000,ci se Dependent variable: y Command: regress Covariates set to value: x1 = 35, x2 = 20000
All
2 2
13
X0 (1, X10 , X 20 ) 1,35,20000 X0 ( X X )1 X 0
3)预测区间: 线性模型为 y=626.5093-9.790572x1+0.0286182x2 x1=35, x2=20000时, y0=626.5093-9.790572*35+0.0286182*20000=856.20328
李子奈---计量经济学--第三版--考点整理

题型1、名词解释(5题10分)2、选择题(10题20分)3、判断题(8题8分)4、问答题(2题20分)5、计算题(3题42分)一.名词解释1.计量经济学:计量经济学是一门从数量上研究物质资料的生产、交换、分配、消费等经济关系和经济活动规律及其应用的科学。
2.数据质量:数据满足明确或隐含需求程度的指标。
3。
相关分析:主要研究变量之间的相互关联程度,用相关系数表示。
包括简单相关和多重相关(复相关)。
4。
回归分析:研究一个变量(因变量)对于一个或多个其他变量(解释变量)的数量依存关系。
其目的在于根据已知的解释变量的数值来估计或预测因变量的总体平均值。
5。
面板数据:时间序列数据和截面数据的混合.时间序列数据:一批按先后顺序排列的统计数据。
截面数据:是一批发生在同一时间截面上的调查数据.6。
拟合优度(修正的拟合优度):指检验模型对样本观测值的拟合程度,用R²表示,该值越接近1拟合程度越好.7。
异方差:对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,则认为出现了异方差性。
8.自相关:自相关是在时间序列资料中按时间顺序排列的观测值之间的相关或在横截面资料中按空间顺序排列的观测值之间的相关.9。
多重共线性:解释变量之间存在完全的或近似的线性关系。
解释变量存在完全的线性关系叫完全多重共线;解释变量之间存在近似的线性关系叫不完全(近似)多重共线.10。
工具变量:在模型估计过程中被作为工具使用,以替代模型中与随机误差项相关的随机解释变量。
11.虚拟变量:根据这些因素的属性类型,构造只取“0”或“1”的人工变量,通常称为虚拟变量,记为D。
12。
滞后变量:滞后变量是指在回归模型中,因变量与解释变量的时间滞后量。
13.分布滞后模型:若滞后变量模型中没有滞后被解释变量,仅有解释变量X的当期值,称为分布滞后模型。
(自回归模型:如果滞后变量模型中的解释变量仅包含X的当期值与被解释变量Y的一个或多个滞后值,则称为自回归模型.)14.联立方程模型:需要多个单一方程和在一起的联立方程组来描述。
李子奈《计量经济学》(第4版)配套题库-经典单方程计量经济学模型:多元线性回归模型章节题库(圣才出品
第3章经典单方程计量经济学模型:多元线性回归模型一、选择题1.一元回归方程∧Y i=32.03+0.22X i,其斜率系数对应的t统计量为2.00,样本容量为20,则在5%显著性水平下,对应的临界值及显著性为()。
A.临界值为1.734,系数显著不为零B.临界值为2.101,系数显著不为零C.临界值为1.734,系数显著为零D.临界值为2.101,系数显著为零【答案】B【解析】在变量显著性检验中,针对变量βj设计的原假设与备择假设为H0:βj=0,H1:βj≠0。
给定一个显著性水平α,得到临界值tα/2(n-k-1),于是可根据|t|>tα/2(n-k-1)(或|t|≤tα/2(n-k-1))来决定拒绝(或接受)原假设H0,从而判定对应的解释变量是否显著为零。
由已知条件可知tα/2(n-k-1)=t0.025(18)=2.101>2.00,故拒绝原假设,系数显著不为零。
2.接上题,该方程对应的方程显著性检验的F统计量为()。
A.1.85B.4.00C.11.83D.61.92【答案】B【解析】在一元线性回归中,方程总体线性显著性检验的F 统计量与用于斜率参数β1的显著性检验的t 统计量的关系是:F=t 2,故F=2.002=4.00。
二、判断题1.回归平方和是指被解释变量的总体平方和与残差平方和之差。
()【答案】√2.在满足基本假定的条件下,利用最小二乘法对多元线性回归模型的估计量不具有无偏性。
()【答案】×【解析】当多元线性回归模型满足基本假设的情况时,其参数的普通最小二乘估计、最大似然估计及矩估计具有线性性、无偏性和有效性。
同时,随着样本容量增加,即当n→∞时,参数估计量具有渐进无偏性、一致性及渐进有效性。
三、证明题1.在经典假定成立条件下,以解释变量样本值为条件,对所有的j=1,2,…,k,都有:Var(∧βj )=σ2/[TSS j (1-R j 2)]式中,()21nj ij j i TSS X X ==-∑为X j 的总样本变异(总离差平方和);R j 2将X j 对所有其他自变量(并包括一个截距项)进行回归所得到的样本可决系数R 2。
计量经济学李子奈第五版课后习题
计量经济学试题精选一、单项选择题1.回归分析中定义的()A、解释变量为非随机变量被解释变量为随机变量B、解释变量和被解释变量都是随机变量C、解释变量为随机变量被解释变量为非随机变量D、解释变量和被解释变量都为非随机变量2.经济计量学与数理经济学的区别在于是否考虑经济行为发生变化的A、确定性因素B、内生因素C、外生因素D、随机因素3.对联立方程模型进行参数估计的方法可以分两类,即:()A、单方程估计法和系统估计法B、间接最小二乘法和系统估计法C、工具变量法和间接最小二乘法D、单方程估计法和二阶段最小二乘法4.线性估计量是指与下述哪个变量的关系是线性的?A、被解释变量YB、解释变量XC、残差项eD、误差项u5.假设回归模型为其中Xi为随机变量,Xi与Ui相关则的普通最小二乘估计量()A、无偏但不一致B、无偏且一致C、有偏且不一致D、有偏但一致6.A、时间序列数据B、横截面数据C、平行数据D、修匀数据7.当模型中第i个方程是不可识别的,则该模型是()A、不可识别的B、可识别的C、恰好识别D、过度识别8.选择模型的数学形式的主要依据是A、数理统计理论B、经济统计理论C、经济行为理论D、宏观经济理论9.已知样本回归模型残差的一阶自相关系数接近于-1,则DW统计量近似等于()A、1B、0C、4D、210.A、行为方程模型B、随机方程模型C、非随机方程模型D、联立方程模型11.经济计量模型是指()A、数学规划模型B、投入产出模型C、模糊数学模型D、包含随机方程的经济数学模型12.8A、经济理论准则B、经济计量准则C、统计准则和经济理论准则D、统计准则13.样本数据的质量问题A、一致性B、时效性C、系统性D、广泛性14.7A、准确性B、一致性C、完整性D、可比性15.在同一时点或时期上,不同统计单位的相同统计指标组成的数据是A、时点数据B、时期数据C、截面数据D、时序数据16.结构式模型中的每一个方程都称为结构式方程,在结构方程中,解释变量可以是前定变量,也可以是()A、滞后变量B、外生变量C、外生变量和内生变量D、内生变量。
李子奈---计量经济学--第三版--考点整理汇编
题型1、名词解释(5题10分)2、选择题(10题20分)3、判断题(8题8分)4、问答题(2题20分)5、计算题(3题42分)一.名词解释1.计量经济学:计量经济学是一门从数量上研究物质资料的生产、交换、分配、消费等经济关系和经济活动规律及其应用的科学。
2.数据质量:数据满足明确或隐含需求程度的指标。
3.相关分析:主要研究变量之间的相互关联程度,用相关系数表示。
包括简单相关和多重相关(复相关)。
4.回归分析:研究一个变量(因变量)对于一个或多个其他变量(解释变量)的数量依存关系。
其目的在于根据已知的解释变量的数值来估计或预测因变量的总体平均值。
5.面板数据:时间序列数据和截面数据的混合。
时间序列数据:一批按先后顺序排列的统计数据。
截面数据:是一批发生在同一时间截面上的调查数据。
6.拟合优度(修正的拟合优度):指检验模型对样本观测值的拟合程度,用R²表示,该值越接近1拟合程度越好。
7.异方差:对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,则认为出现了异方差性。
8.自相关:自相关是在时间序列资料中按时间顺序排列的观测值之间的相关或在横截面资料中按空间顺序排列的观测值之间的相关。
9.多重共线性:解释变量之间存在完全的或近似的线性关系。
解释变量存在完全的线性关系叫完全多重共线;解释变量之间存在近似的线性关系叫不完全(近似)多重共线。
10.工具变量:在模型估计过程中被作为工具使用,以替代模型中与随机误差项相关的随机解释变量。
11.虚拟变量:根据这些因素的属性类型,构造只取“0”或“1”的人工变量,通常称为虚拟变量,记为D。
12.滞后变量:滞后变量是指在回归模型中,因变量与解释变量的时间滞后量。
13.分布滞后模型:若滞后变量模型中没有滞后被解释变量,仅有解释变量X的当期值,称为分布滞后模型。
(自回归模型:如果滞后变量模型中的解释变量仅包含X的当期值与被解释变量Y的一个或多个滞后值,则称为自回归模型。
李子奈(第二版)_计量经济学考试与答案
李子奈(第二版)_计量经济学考试与答案计量经济学习题及答案一、单项选择题(本大题共25小题,每小题1分,共25分)在每小题列出的四个选项中只有一个选项是符合题目要求的,请将正确选项前的字母填在题后的括号内。
1.对联立方程模型进行参数估计的方法可以分两类,即:( )A.间接最小二乘法和系统估计法B.单方程估计法和系统估计法C.单方程估计法和二阶段最小二乘法D.工具变量法和间接最小二乘法 2.当模型中第i个方程是不可识别的,则该模型是( )A.可识别的B.不可识别的C.过度识别D.恰好识别 3.结构式模型中的每一个方程都称为结构式方程,在结构方程中,解释变量可以是前定变量,也可以是( )A.外生变量B.滞后变量C.内生变量D.外生变量和内生变量 4.已知样本回归模型残差的一阶自相关系数接近于-1,则DW统计量近似等于( )A.0B.1C.2D.4其中Xi为随机变量,Xi与Ui相关则的普通最小二乘估计量( ) 5.假设回归模型为A.无偏且一致B.无偏但不一致C.有偏但一致D.有偏且不一致 6.对于误差变量模型,模型参数的普通最小二乘法估计量是( )A.无偏且一致的B.无偏但不一致C.有偏但一致D.有偏且不一致 7.戈德菲尔德-匡特检验法可用于检验( )A.异方差性B.多重共线性C.序列相关D.设定误差 8.对于误差变量模型,估计模型参数应采用( )A.普通最小二乘法B.加权最小二乘法C.广义差分法D.工具变量法 9.系统变参数模型分为( )A.截距变动模型和斜率变动模型B.季节变动模型和斜率变动模型C.季节变动模型和截距变动模型D.截距变动模型和截距、斜率同时变动模型10.虚拟变量( )A.主要来代表质的因素,但在有些情况下可以用来代表数量因素B.只能代表质的因素C.只能代表数量因素D.只能代表季节影响因素11.单方程经济计量模型必然是( )A.行为方程B.政策方程C.制度方程D.定义方程 12.用于检验序列相关的DW 统计量的取值范围是( )A.0?DW?1B.,1?DW?1C. ,2?DW?2D.0?DW?4 13.根据判定系数R2与F统计量的关系可知,当R2=1时有( )A.F=1B.F=,1C.F=?D.F=014.在给定的显著性水平之下,若DW统计量的下和上临界值分别为dL和du,则当dL<DW<du时,可认为随机误差项( )A.存在一阶正自相关B.存在一阶负相关C.不存在序列相关D.存在序列相关与否不能断定15.经济计量分析的工作程序( )A.设定模型,检验模型,估计模型,改进模型B.设定模型,估计参数,检验模型,应用模型C.估计模型,应用模型,检验模型,改进模型D.搜集资料,设定模型,估计参数,应用模型16.前定变量是( )的合称。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计量经济学-李子奈-计算题整理集合
作者: 日期:
第一题
F表给出了一含有3个实解释变量的模型的回归结果:
(1)求样本容量n、RSS、ESS的自由度、RSS的自由度
2
(2)求可决系数R2和调整的可决系数R
(3)在5%的显著性水平下检验人、X2和X3总体上对丫的影响的显著性(已知F O.05(3,4O) 2.84)
(4)根据以上信息能否确定X” X2和X3各自对丫的贡献?为什么?
答案:
(1 )样本容量n=43+仁44 (1分)RSS=TSS-ESS=66056-65965=91 (1 分)
ESS的自由度为:3 (1分)
RSS 的自由度为:d.f.=44-3-1=40 (1 分)
(2)R2=ESS/TSS=65965/66056=0.9986 (1 分)R2=1-(1- R2)(n-1)/(n-k-1)=1-0.0014 43/40=0.9985 (2 分)(3)H o: 1 2 30 (1 分)ESS/k 65965/3
F= 9665.2 (2 分)RSS/( n k 1)91/40
F F O.O5(3,4O) 2.84 拒绝原假设(2 分)
所以,X!、X2和X3总体上对丫的影响显著(1分)
(4)不能。
(1分)因为仅通过上述信息,可初步判断X1,X2,X3联合起来
对Y有线性影响,三者的变化解释了Y变化的约99.9%。
但由于
无法知道回归X1, X2,X3前参数的具体估计值,因此还无法
判断它们各自对Y的影响有多大。
(1分)
第二题
以某地区22年的年度数据估计了如下工业就业模型
丫0 1 ln X 1i 2 ln X 2i 3 ln X 3i i
回归方程如下:
Y? 3.89 0.511nX ,j 0.251 n X 2i 0.621 nX 3i
(-0.56) (2.3) (-1.7)
(5.8)
2
R 0.996
DW 3.147
式中,丫为总就业量;X i 为总收入;X 2为平均月工资率;X 3为地方政府 的总支出。
已知t °.025(18) 2.101,且已知n 22,k 3,
0.05时,
d L 1.05,d u 1.66。
在5%的显著性水平下
(1) 检验变量ln X 2i 对Y 的影响的显著性 (2) 求1的置信区间
(3) 判断模型是否存在一阶自相关,若存在,说明类型
(4)将模型中不显著的变量剔除,其他变量的参数的估计值会不会改
变?
答案:
1.在对某国“实际通货膨胀率(Y )”与“失业率(X 1)” 、“预期通货膨胀率(X 2) ”的关系的研
究中,建立模型
丫 0
1
X 1i 2X 2i i ,利用软件进行参数估计,得到了如下估计结果:
(1)H 。
:
t 2
1.7
t 2
分) 1.7 t °.°25(18)
2.101
所以,ln X 2i 对Y 的影响不显著
(1分)
(1分)
所以,接受原假设 (2 (1
(2) S ?1
分)
? 1 ?
'1
/t 1 0.51/2.3 0.2217
t 0.025 (18)
S ?)
1
(0.51 2.101 0.2217)
(3) 4-d L
1
(0.0442,0.9758) 4 1.05
2.95
DW 3.147
DW 4- d L
为一阶负自相关 所以,存在一阶自相关
(4 )会
第二题
(2分) (2分)
(1 分)
(1分)
(2分)
(1分) (1分)
要求回答下列问题:(1)①、②处所缺数据各是多少? 8.586 0.8283
(2)“失业率”、“预期通货膨胀率”各自对“实际通货膨胀率”的影响是否显著?为什么?(显著性水平取1%)
(3)“实际通货膨胀率”与“失业
率”、“预期通货膨胀率”之间的线
性关系是否显著成立?为什么?(显著性水平取1%)(4)随机误差项的方差的普通最小二乘估计值是多少?
(5)可否判断模型是否存在一阶自相关?为什么?
(显著性水平取5%,已知=5%、n=16、k=2 时,d L =0.98, d u =1.54)答案:
(1) ①处所缺数据为
? 1.378710
t2 28.586295(1分)
0.160571
s?
2
②处所缺数据为
—22n 1
R 21(1 R )
n k 1
16 1
=1-(1-0.851170)
16 2 1
15 =1-0.148830 13
=0.828273
(2 分)
(2) “失业率” 、“预期通货膨胀率”各自对“实际通货膨胀率”的影响显著。
(2分)
因为对应的t 统计量的P 值分别为0.0003、0.0000,都小于1%。
(1分)
(3) “实际通货膨胀率”与“失业率”
、“预期通货膨胀率”之间的线性关系显著成
因为F 统计量的 P 值为0.000004,小于1%。
(4 )随机误差项的方差的普通最小二乘估计值为
(5 )不能判断模型是否存在一阶自相关。
因为
DW=1.353544
d L <DW< d u
第四题
根据美国1961年第一季度至1977年第二季度的季度数据,得咖啡需求函数回归 方程:
InQ 1.2789 0.16471nR 0.5115lnl t 0.1483lnR 0.0089T 0.0961D 1t
(2.14)
(1.23) (0.55) ( 3.36)
(3.74)
2
0.1570D 2t 0.0097D 3t R 2
0.80
(6.03)
( 0.37)
其中:Q ――人均咖啡消费量(单位:磅)
R ——咖啡的价格
I ――人均收入
R ――茶的价格
T ――时间趋势变量(1961年一季度为1,……1977年二季度 为
66)
D = 1 第一季度; D = 1
第二季度; D = 1 第三季度
1
= 0 其它 '
2
= 0 其它 '
3
= 0 其它
要求回答下列问题:
立。
(2分)
(1分)
17.33513
13
1.33347
(3分)
(1分)
(2分)
(1) 模型中P 、I 和p 的系数的经济含义是什么? (2)
咖啡的价格需求是否很有弹性? ( 3)
咖啡和茶是互补品还是替代品?
(4)如何解释时间变量T 的系数?( 5)如何解释模型中虚拟变量的作用? (6) 哪些虚拟变量在统计上是显著的?
( 7)咖啡的需求是否存在季节效应?
酌情给分。
答案:
(1)从咖啡需求函数的回归方程看, P 的系数-0.1647表示咖啡需求的自价格弹性;
I 的系
数0.5115示咖啡需求的收入弹性 ;P'的系数 0.1483表示咖啡需求的交叉价格弹性。
(3分)
(2)
咖啡需求的自价格弹性的绝对值较小,表明咖啡是缺乏弹性。
(2分)
(3)
P'的系数大于0,表明咖啡与茶属于替代品。
(2分)
(4) 从时间变量T 的系数为-0.01看,咖啡的需求量应是逐年减少 (2分)
(5)
虚拟变量在本模型中表示咖啡需求可能受季节因素的影响。
(2分)
(6) 从各参数的 t 检验看,第一季度和第二季度的虚拟变量在统计上是显著的。
(2分)
(7) 咖啡的需求存在季节效应,回归方程显示第一季度和第二季度的需求比其他季节 (2分)
,但减少的速度很慢。
少。