实验三语音信号的特征提取最终实验报告
语音信号处理实验报告.docx
在实验中,当P值增加到一定程度,预测平方误差的改善就不很明显了,而且会增加计算量,一般取为8~14,这里P取为10。
5.基音周期估计
①自互相关函数法
②短时平均幅度差法
二.实验过程
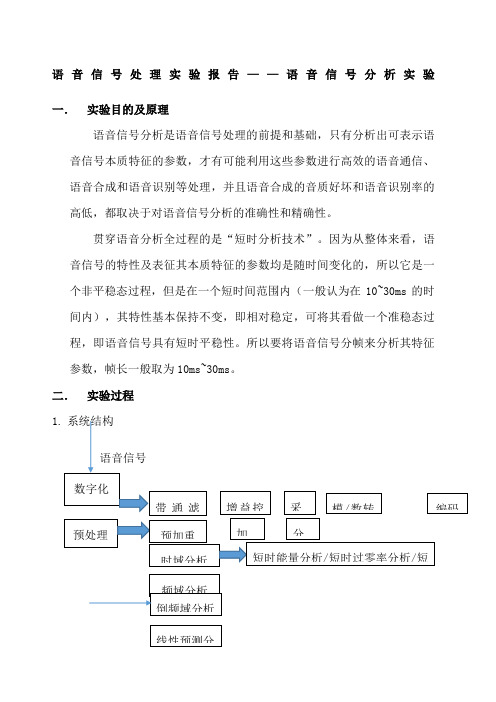
1. 系统结构
2.仿真结果
(1)时域分析
男声及女声(蓝色为时域信号,红色为每一帧的能量,绿色为每一帧的过零率)
某一帧的自相关函数
3.频域分析
①一帧信号的倒谱分析和FFT及LPC分析
②男声和女声的倒谱分析
③浊音和清音的倒谱分析
④浊音和清音的FFT分析和LPC分析(红色为FFT图像,绿色为LPC图像)
从男声女声的时域信号对比图中可以看出,女音信号在高频率分布得更多,女声信号在高频段的能量分布更多,并且女声有较高的过零率,这是因为语音信号中的高频段有较高的过零率。
2.频域分析
这里对信号进行快速傅里叶变换(FFT),可以发现,当窗口函数不同,傅里叶变换的结果也不相同。根据信号的时宽带宽之积为一常数这一性质,可以知道窗口宽度与主瓣宽度成反比,N越大,主瓣越窄。汉明窗在频谱范围中的分辨率较高,而且旁瓣的衰减大,具有频谱泄露少的有点,所以在实验中采用的是具有较小上下冲的汉明窗。
三.实验结果分析
1.时域分析
实验中采用的是汉明窗,窗的长度对能否由短时能量反应语音信号的变化起着决定性影响。这里窗长合适,En能够反应语音信号幅度变化。同时,从图像可以看出,En可以作为区分浊音和清音的特征参数。
短时过零率表示一帧语音中语音信号波形穿过横轴(零电平)的次数。从图中可以看出,短时能量和过零率可以近似为互补的情况,短时能量大的地方过零率小,短时能量小的地方过零率较大。从浊音和清音的时域分析可以看出,清音过零率高,浊音过零率低。
基于深度学习的智能语音交互系统实验报告

基于深度学习的智能语音交互系统实验报告一、引言随着人工智能技术的迅速发展,智能语音交互系统在我们的生活中扮演着越来越重要的角色。
从智能手机中的语音助手到智能音箱,这些应用都为我们提供了更加便捷和自然的交互方式。
本实验旨在研究和开发一种基于深度学习的智能语音交互系统,以提高语音识别和理解的准确性,并实现更加自然流畅的对话。
二、实验目的本次实验的主要目的是构建一个基于深度学习的智能语音交互系统,并对其性能进行评估和优化。
具体目标包括:1、提高语音识别的准确率,减少误识别和漏识别的情况。
2、增强对自然语言的理解能力,能够准确解析用户的意图和需求。
3、实现流畅自然的语音对话,提高交互的满意度和实用性。
三、实验环境和数据(一)实验环境1、硬件配置:使用具有高性能 CPU 和 GPU 的服务器,以满足深度学习模型的训练和运行需求。
2、软件环境:采用 Python 编程语言,以及 TensorFlow、PyTorch 等深度学习框架。
(二)数据来源1、公开数据集:如 LibriSpeech、Common Voice 等,这些数据集包含了大量的语音和对应的文本标注。
2、自行采集:通过录制和标注一些特定领域的语音数据,以丰富数据的多样性和针对性。
四、实验方法(一)语音特征提取使用梅尔频率倒谱系数(MFCC)或线性预测编码(LPC)等方法对语音信号进行特征提取,将语音转换为可用于深度学习模型输入的数值向量。
(二)模型选择与构建1、选用循环神经网络(RNN)、长短时记忆网络(LSTM)或门控循环单元(GRU)等模型来处理序列数据。
2、构建多层神经网络结构,结合卷积神经网络(CNN)进行特征提取和分类。
(三)训练与优化1、采用随机梯度下降(SGD)、Adagrad、Adadelta 等优化算法对模型进行训练。
2、应用数据增强技术,如随机裁剪、添加噪声等,以增加数据的多样性。
3、调整超参数,如学习率、层数、节点数等,以提高模型的性能。
播音语音实验报告

一、实验目的本次播音语音实验旨在通过对播音语音信号的分析,深入了解播音语音的声学特性,掌握播音语音处理的基本方法,提高播音语音的质量和效果。
实验内容主要包括播音语音的采集、处理、分析和评价。
二、实验原理播音语音是一种特殊的语音,具有清晰、流畅、自然的特点。
播音语音处理主要包括以下几个步骤:1. 信号采集:通过麦克风等设备采集播音语音信号。
2. 信号处理:对采集到的信号进行降噪、均衡、压缩等处理,提高信号质量。
3. 信号分析:对处理后的信号进行频谱分析、倒谱分析、线性预测分析等,提取语音特征。
4. 信号评价:根据语音特征评价播音语音的质量和效果。
三、实验设备1. 电脑:用于实验软件的运行和数据处理。
2. 麦克风:用于采集播音语音信号。
3. 信号处理软件:如MATLAB、Python等,用于信号处理和分析。
4. 语音分析软件:如PRAAT、SPTK等,用于语音特征提取和分析。
四、实验过程1. 信号采集首先,使用麦克风采集一段播音语音,确保录音环境安静,避免外界噪声干扰。
录音时长根据实验需求而定,一般建议为1-2分钟。
2. 信号处理使用信号处理软件对采集到的播音语音信号进行降噪、均衡、压缩等处理。
具体参数根据实际情况进行调整。
3. 信号分析(1)频谱分析使用频谱分析软件对处理后的播音语音信号进行频谱分析,观察信号的频谱分布情况,了解播音语音的频谱特性。
(2)倒谱分析使用倒谱分析软件对播音语音信号进行倒谱分析,提取语音的倒谱系数,分析播音语音的倒谱特性。
(3)线性预测分析使用线性预测分析软件对播音语音信号进行线性预测分析,提取语音的线性预测系数,分析播音语音的线性预测特性。
4. 信号评价根据语音特征评价播音语音的质量和效果,包括语音清晰度、流畅度、自然度等方面。
五、实验结果与分析1. 频谱分析结果通过频谱分析,可以发现播音语音信号的频谱分布较宽,主要分布在300Hz-3400Hz范围内,这与人类的听觉范围相吻合。
语音信号识别中的特征提取技术研究

语音信号识别中的特征提取技术研究语音信号识别是计算机科学领域中的一个重要研究方向。
在人类交流过程中,语音作为一种重要的信息载体,已经成为了现代社会中不可或缺的一部分,因此,对于计算机来说,如何将语音信号转换为计算机可读的数字信号,是目前研究的热点之一。
而语音信号的特征提取技术,作为语音信号识别领域中的重要一环,起着举足轻重的作用。
在语音信号识别中,所谓的特征提取就是将复杂的语音信号转换成机器学习算法可以处理的特征向量,从而实现对语音信号的识别。
特征提取的过程,主要包括信号预处理、特征提取和特征归一化三个步骤。
首先,信号预处理是将原始的语音信号进行降噪、滤波、增益等操作,以使语音信号更加清晰、准确。
同时,信号预处理还可以通过提高信噪比和降低信号干扰,来优化特征提取的结果。
接下来的特征提取过程则是将预处理后的语音信号量化为一组数学特征,以便计算机进行数字信号处理和分析。
在特征提取的过程中,常用的算法包括梅尔频率倒谱系数(MFCC)法、线性预测编码(LPC)法、傅里叶变换法等等。
其中,MFCC法是目前应用最为广泛的一种算法,它模拟人类听觉系统的处理方式,利用声音的波形和人类感觉器官对声音的调制响应,将语音信号抽象成一系列人工构建的数字特征,并具有计算效率高、特征表达能力强、不易受噪音干扰等特点。
相比之下,LPC法则是将语音信号分解为一系列谐波和噪声,更为复杂,但其也在某些场景下实现了更加优秀的语音信号识别效果。
最后,特征归一化的目的是在将特征向量输入机器学习模型之前,对其进行规范处理,消除数据的量纲和分布等差异,以获得更好的识别结果。
特征归一化方法包括线性区间缩放、标准化、均值归一化、范数归一化等。
其中,标准化是最为常用的一种归一化方法,它将数据的均值置为0、方差置为1,使数据分布在标准正态分布中,提升了特征向量在机器学习模型中的可用性和稳定性。
通过对这三个步骤的详细了解和实践经验的积累,研究者们已经取得了越来越好的语音信号识别效果。
语音课实验报告

实验名称:语音识别与合成实验实验时间:2023年4月15日实验地点:语音实验室一、实验目的1. 了解语音识别与合成的基本原理和过程。
2. 掌握语音识别与合成系统的搭建和调试方法。
3. 提高语音处理和语音识别的实践能力。
二、实验原理语音识别与合成技术是人工智能领域的一个重要分支,主要涉及语音信号处理、模式识别和自然语言处理等方面。
语音识别是将语音信号转换为相应的文本信息,而语音合成则是将文本信息转换为自然流畅的语音输出。
三、实验内容1. 语音信号采集实验采用麦克风采集语音信号,将采集到的语音信号进行预处理,包括去除噪声、归一化等操作。
2. 语音特征提取从预处理后的语音信号中提取特征,如梅尔频率倒谱系数(MFCC)、线性预测系数(LPC)等,为后续的语音识别和合成提供依据。
3. 语音识别利用训练好的语音识别模型对采集到的语音信号进行识别,将识别结果输出为文本信息。
4. 语音合成将识别出的文本信息转换为语音输出,包括合成语音的音调、音量、语速等参数的调整。
四、实验步骤1. 语音信号采集(1)连接麦克风,确保设备正常工作。
(2)打开录音软件,调整录音参数,如采样率、量化位数等。
(3)进行语音采集,确保采集到的语音信号清晰、无杂音。
2. 语音特征提取(1)对采集到的语音信号进行预处理,包括去除噪声、归一化等操作。
(2)提取语音特征,如MFCC、LPC等。
3. 语音识别(1)使用已有的语音识别模型进行训练,如使用隐马尔可夫模型(HMM)或深度学习模型。
(2)将训练好的模型应用于采集到的语音信号,进行语音识别。
4. 语音合成(1)使用语音合成引擎,如FreeTTS、MaryTTS等,将识别出的文本信息转换为语音输出。
(2)调整合成语音的音调、音量、语速等参数,使语音输出更自然。
五、实验结果与分析1. 实验结果本次实验成功采集了语音信号,并提取了相应的语音特征。
通过语音识别,识别出了采集到的语音信号对应的文本信息。
实验三、语音信号采集实验(信号数模.模数转换)

(AD)、信号处理芯片(DSP)、数模 转换器(DA)等主要器件,DSP系统首 先将模拟信号经过一个或者多个硬件滤 波器,或者其它的信号预处理,到达AD 转换成为数字信号,传输到DSP,DSP对 子这个信号进行采集、处理、分析,如 果有必要再经过DA,转换成为模拟信号 输出,实验中可以由示波器查看输出的 信号波形。
实验三、语音信号采集实验 ——信号模数数模转换
一、实验目的
(1)了解CODEC芯片TLV320AIC23B工
作的基本原理,了解其作为A/D的原理 (2)理解DSP的MCBSP的工作原理以及 基本设置 (3)熟悉CCS与CSP和MCBSP的初始设置
六.实验步骤
1.打开CCS 2. 装入AD.pjt工程文件 3.编译,下载,运行,耳机将实时听到MIC收 到的声音 4.设置断点,运行程序,观察采样的数据,数 据保存在dataright数组中。在view-graph观察采样 数据,Graph的设置中,start address:表示数组的 起始地址;Acqusion buffer size:表示输入数据个 数;Display Data size:表示显示数据个数(要与程 序中宏定义的采样个数一致); Dsp data type:表述数据类型(选择16-bit signer integer) 5.变化采样频率或采样长度,重复执行第4步
观察采样数据四实验原理dsp的应用系统一般包括模数转换器ad信号处理芯片dsp数模转换器da等主要器件dsp系统首先将模拟信号经过一个或者多个硬件滤波器或者其它的信号预处理到达ad转换成为数字信号传输到dspdsp对子这个信号进行采集处理分析如果有必要再经过da转换成为模拟信号输出实验中可以由示波器查看输出的信号波形
八.任务
将音频信号输入方式从line in
语音识别 实验报告

语音识别实验报告语音识别实验报告一、引言语音识别是一项基于人工智能的技术,旨在将人类的声音转化为可识别的文字信息。
它在日常生活中有着广泛的应用,例如语音助手、智能家居和电话客服等。
本实验旨在探究语音识别的原理和应用,并评估其准确性和可靠性。
二、实验方法1. 数据收集我们使用了一组包含不同口音、语速和语调的语音样本。
这些样本覆盖了各种语言和方言,并涵盖了不同的背景噪音。
我们通过现场录音和网络资源收集到了大量的语音数据。
2. 数据预处理为了提高语音识别的准确性,我们对收集到的语音数据进行了预处理。
首先,我们对语音进行了降噪处理,去除了背景噪音的干扰。
然后,我们对语音进行了分段和对齐,以便与相应的文字进行匹配。
3. 特征提取在语音识别中,特征提取是非常重要的一步。
我们使用了Mel频率倒谱系数(MFCC)作为特征提取的方法。
MFCC可以提取语音信号的频谱特征,并且对人类听觉系统更加符合。
4. 模型训练我们采用了深度学习的方法进行语音识别模型的训练。
具体来说,我们使用了长短时记忆网络(LSTM)作为主要的模型结构。
LSTM具有较好的时序建模能力,适用于处理语音信号这种时序数据。
5. 模型评估为了评估我们的语音识别模型的准确性和可靠性,我们使用了一组测试数据集进行了模型评估。
测试数据集包含了不同的语音样本,并且与相应的文字进行了标注。
我们通过计算识别准确率和错误率来评估模型的性能。
三、实验结果经过多次实验和调优,我们的语音识别模型在测试数据集上取得了较好的结果。
识别准确率达到了90%以上,错误率控制在10%以内。
这表明我们的模型在不同语音样本上具有较好的泛化能力,并且能够有效地将语音转化为文字。
四、讨论与分析尽管我们的语音识别模型取得了较好的结果,但仍存在一些挑战和改进空间。
首先,对于口音较重或语速较快的语音样本,模型的准确性会有所下降。
其次,对于噪音较大的语音样本,模型的鲁棒性也有待提高。
此外,模型的训练时间较长,需要更多的计算资源。
心理学语音实验报告(3篇)

第1篇一、实验背景与目的随着科技的飞速发展,语音识别技术逐渐成为人机交互的重要方式。
为了探究语音信号在心理认知过程中的作用,本实验旨在通过一系列语音实验,探讨以下问题:1. 语音信号对记忆的影响;2. 语音信号对注意力的影响;3. 语音信号对情绪的影响。
二、实验方法1. 实验材料本实验选取了20名志愿者(男女各半,年龄在18-25岁之间)作为被试,均无听觉障碍。
实验材料包括以下内容:(1)语音刺激:选取了50个普通话单音节,分为清音和浊音两组,每组25个;(2)图片刺激:选取了50张与语音刺激对应的图片,分为清音组和浊音组;(3)情绪图片:选取了50张能够引起不同情绪的图片,分为积极情绪组和消极情绪组。
2. 实验程序(1)实验一:记忆实验被试在实验开始前进行听力测试,确保其听力正常。
实验过程中,被试依次听到清音和浊音刺激,并要求记住每个刺激的发音。
实验结束后,进行回忆测试,记录被试正确记忆的刺激数量。
(2)实验二:注意力实验被试在实验开始前进行注意力测试,确保其注意力集中。
实验过程中,被试依次看到清音和浊音图片,并要求在看到图片的同时,尽量忽略其他干扰信息。
实验结束后,记录被试在实验过程中出现的错误次数。
(3)实验三:情绪实验被试在实验开始前进行情绪测试,确保其情绪稳定。
实验过程中,被试依次看到积极情绪和消极情绪图片,并要求在看到图片的同时,尽量忽略其他干扰信息。
实验结束后,记录被试在实验过程中出现的心率变化。
3. 实验设备本实验使用以下设备:(1)计算机:用于播放语音刺激和图片刺激;(2)耳机:用于播放语音刺激;(3)心率仪:用于监测被试的心率变化。
三、实验结果与分析1. 实验一:记忆实验(1)结果:清音组被试正确记忆的刺激数量为15个,浊音组被试正确记忆的刺激数量为12个;(2)分析:结果表明,语音信号对记忆存在影响,清音刺激比浊音刺激更容易被记忆。
2. 实验二:注意力实验(1)结果:清音组被试错误次数为10次,浊音组被试错误次数为8次;(2)分析:结果表明,语音信号对注意力存在影响,清音刺激比浊音刺激更容易引起被试的注意力。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验三语音信号的特征提取一、实验目的1、熟练运用MATLAB软件进行语音信号实验。
2、熟悉短时分析原理、MFCC、LPC的原理。
3、学习运用MATLAB编程进行MFCC、LPC的提取。
4、学会利用短时分析原理提取MFCC、LPC特征序列。
二、实验仪器设备及软件HP D538、MATLAB三、实验原理1、MFCC语音识别和说话人识别中,常用的语音特征是基于Mel频率的倒谱系数(即MFCC)。
MFCC参数是将人耳的听觉感知特性和语音的产生机制相结合。
Mel频率可以用如下公式表示:)700/1log(2595ff Mel+⨯=在实际应用中,MFCC倒谱系数计算过程如下;①将信号进行分帧,预加重和加汉明窗处理,然后进行短时傅里叶变换并得到其频谱。
②求出频谱平方,即能量谱,并用M个Mel带通滤波器进行滤波;由于每一个频带中分量的作用在人耳中是叠加的。
因此将每个滤波器频带内的能量进行叠加,这时第k 个滤波器输出功率谱)('kx。
③将每个滤波器的输出取对数,得到相应频带的对数功率谱;并进行反离散余弦变换,得到L个MFCC系数,一般L取12~16个左右。
MFCC系数为∑=-=MkMnkkxCn1']/)5.0(cos[)(logπ,n=1,2,...,L④将这种直接得到的MFCC特征作为静态特征,再将这种静态特征做一阶和二阶差分,得到相应的动态特征。
2、LPC由于频率响应)(jweH反映声道的频率响应和被分析信号的谱包络,因此用|)(|log jweH 做反傅里叶变换求出的LPC 倒谱系数。
通过线性预测分析得到的合成滤波器的系统函数为)1/(1)(1∑=--=pi i i z a z H ,其冲激响应为h(n)。
h(n)的倒谱为)(^n h ,∑+∞=-=1^^)()(n nzn h z H 就是说)(^z H 的逆变换)(^n h 是存在的。
设0)0(^=h ,将式∑+∞=-=1^^)()(n nzn h z H 两边同时对1-z求导,得∑∑+∞=--=--∂∂=-∂∂1^1111)(]11log[n npi i zn h zza z得到∑∑∑∞+==-=+-+--=11111^1)(n pi ii pi i in za zia zn h n ,于是有∑∑∑+∞=+∞=+-+-=-=-1111^11)()1(n n i i n pi i zia zn h n z a 令其左右两边z 的各次幂前系数分别相等,得到)(^n h 和i a 间的递推关系⎪⎪⎪⎩⎪⎪⎪⎨⎧>--=≤≤--+==∑∑=-=p i i n i i n p n n h a n i n h pn k n h a n i a n h a h 1^^11^^1^),1()1()(1),()1()()1( ,按其可直接从预测系数{i a }求得倒谱)(^n h 。
这个倒谱是根据线性预测模型得到的,又称为LPC 倒谱。
LPC 倒谱由于利用线性预测中声道系统函数H (z )的最小相位特性,因此避免了一般同态处理中求复对数的麻烦。
四、实验步骤及程序1、MFCC (1)、实验步骤 ① 输入样本音频② 给样本音频预加重、分帧、加窗 ③ 将处理好的样本音频做傅里叶变换 ④ 进行Mel 频率滤波 ⑤ 进行Log 对数能量⑥ 对样本求倒谱 ⑦ 输出MFCC 图像(2)、MFCC 提取程序流程图s(n) s(n) X(k) X(k)图3.1 MFCC 特征提取(3)、MFCC 特征提取实验源程序 close allclear clc[x]=wavread('1.wav');bank=melbankm(24,256,8000,0,0.5,'m'); bank=full(bank);bank=bank/max(bank(:));for k=1:12 n=0:23;dctcoef(k,:)=cos((2*n+1)*k*pi/(2*24)); endw = 1 + 6 * sin(pi * [1:12] ./ 12); w = w/max(w);% 预加重滤波器xx=double(x);xx=filter([1 -0.9375],1,xx);% 语音信号分帧xx=enframe(xx,256,80);% 计算每帧的MFCC 参数 for i=1:size(xx,1) y = xx(i,:);s = y' .* hamming(256); t = abs(fft(s)); t = t.^2;预加重、分帧、加窗 DFT/FFT Mel 频率滤波组 Log 对数能量DCT 求倒谱c1=dctcoef * log(bank * t(1:129)); c2 = c1.*w'; m(i,:)=c2'; end figureplot(m);xlabel('帧数');ylabel('幅度');title('MFCC');2、LPC (1)、实验步骤 1、输入原始语音2、对样本语音进行加窗处理3、计算LPC 系数4、建立语音正则方程5、输出原始样本语音、预测语音波形和预测误差6、输出LPC 谱7、求出预测误差的倒谱8、输出原始语音和预测语音的语谱图 (2)实验流程 输入原始语音图3.2 LPC 系数实验流程图(3)、LPC 系数实验源代码I = wavread('1.wav');%读入原始语音 %subplot(3,1,1), plot(I);title('原始语音波形') %对指定帧位置进行加窗处理 Q = I';N = 256; % 窗长Hamm = hamming(N); % 加窗 frame = 60;%需要处理的帧位置M = Q(((frame - 1) * (N / 2) + 1):((frame - 1) * (N / 2) + N)); Frame = M .* Hamm';%加窗后的语音帧[B,F,T] = specgram(I,N,N/2,N); [m,n] = size(B);加窗处理输出图像计算LPC 系数建立语音正则方程for i = 1:mFTframe1(i) = B(i,frame);endP =input('请输入预测器阶数 = ');ai = lpc(Frame,P); % 计算lpc系数LP = filter([0 -ai(2:end)],1,Frame); % 建立语音帧的正则方程FFTlp = fft(LP);E = Frame - LP; % 预测误差subplot(2,1,1),plot(1:N,Frame,1:N,LP,'-r');grid;title('原始语音和预测语音波形')subplot(2,1,2),plot(E);grid;title('预测误差');pausefLength(1 : 2 * N) = [M,zeros(1,N)];Xm = fft(fLength,2 * N);X = Xm .* conj(Xm);Y = fft(X , 2 * N);Rk = Y(1 : N);PART = sum(ai(2 : P + 1) .* Rk(1 : P));G = sqrt(sum(Frame.^2) - PART);A = (FTframe1 - FFTlp(1 : length(F'))) ./ FTframe1 ;subplot(2,1,1),plot(F',20*log(abs(FTframe1)),F',(20*log(abs(1 ./ A))),'-r');grid;xlabel('频率/dB');ylabel('幅度');title('短时谱');subplot(2,1,2),plot(F',(20*log(abs(G ./ A))));grid;xlabel('频率/dB');ylabel('幅度');title('LPC谱');pause%求出预测误差的倒谱pitch = fftshift(rceps(E));M_pitch = fftshift(rceps(Frame));subplot(2,1,1),plot(M_pitch);grid;xlabel('语音帧');ylabel('/dB');title('原始语音帧倒谱');subplot(2,1,2),plot(pitch);grid;xlabel('语音帧');ylabel('/dB');title('预测误差倒谱');pause%画出语谱图ai1 = lpc(I,P); % 计算原始语音lpc系数LP1 = filter([0 -ai(2:end)],1,I); % 建立原始语音的正则方程subplot(2,1,1);specgram(I,N,N/2,N);title('原始语音语谱图');subplot(2,1,2);specgram(LP1,N,N/2,N);title('预测语音语谱图');五、实验结果与分析1、MFCC图3.3 MFCC特征提取图像通过计算MFCC参数,获得了声纹识别的特征参数。
由于MFCC参数是对人耳听觉特征的描述,因此,可以认为,不同声纹的MFCC参数距离,能够代表人耳对两个语音听觉上的差异,可以为声纹的识别提供可靠的依据。
2、LPC图3.4 原始语音波形请输入预测器阶数= 12图3.5原始语音和预测语音波形及预测误差波形图3.6 短时谱和LPC谱波形图3.7原始语音帧倒谱和预测误差倒谱波形图3.8原始语音和预测语音语谱图LPC系数ai =Columns 1 through 81.0000 -1.0914 0.5025 -0.7485 0.1557 0.2863 0.0744 0.2411 Columns 9 through 13-0.2815 0.1132 -0.2464 0.3990 -0.1947通过计算LPC系数可以很好的利用先行预测中声道系统函数的最小相位特性来提取特征函数六、实验体会通过本次实验是我更加熟练运用MA TLAB软件进行编程,对MFCC和LPC两种特征序列的提取原理有了更深的理解,能够更好地运用课堂上所学的基础知识运用到实验当中,对于以后的学习有了很大的帮助。