中文词性标注集
浅谈《现代汉语词典》(第五版)词性标注的几个问题

浅谈《现代汉语词典》(第五版)词性标注的几个问题摘要:本文主要从功能的角度对《现代汉语词典》(第五版)的词性标注进行了初步的探索,主要涉及词性标注及其与释义和配例相一致、兼类词的释义等几个方面的问题,对《现汉》(五)的成功和不足之处作了一定说明。
关键词:《现代汉语词典》(第五版)词性标注释义《现代汉语词典》是目前国内最有影响的语文辞书之一。
对现代汉语词典质量产生影响的根本性因素,是词典的释义问题。
一、《现代汉语词典》(第五版)词性标注现代汉语词典标注词性,给汉语教学、用户的学习和使用和中文信息处理等带来了很大的方便。
标注词性必须要对词类系统和词与非词进行界定。
科学的给词归类,主要根据词的语法功能。
陆俭明提出的词类划分标准是:1、词充当句法成分的功能,2、词跟词结合的功能,3、词表示类别的功能,即语法意义。
《现代汉语词典》(第5版)依据的词类是中学语文课本的教学词类系统,是比较科学的。
如:集成:【动】同类著作汇集在一起(多用做书名):《丛书~》|《中国古典戏曲论著~》。
(《现汉》(五)p592)集锦:【名】编辑在一起的精彩的图画、诗文等(多用做标题):图片~|邮票~。
(《现汉》(五)p593)《现代汉语词典》(第5版)中的“集成”与“集锦”根据配例来看,“丛书集成”、“图片集锦”、“邮票集锦”,二者看似相同,但是语法意义不同。
根据“语料库在线”的检索结果,“集成”66条例句中,17个做谓语例句,13个做定语例句,且能带宾语;“集锦”6条例句中5个做中心语。
前者语法意义表示事物的动作、行为或变化、存在,后者的语法意义表示事物名称。
所以二者词性标注不同。
另外,在根据功能判断词性的基础上,也不能完全脱离意义。
“集成”与“集锦”词汇意义也不同,“集:1.集合;聚集”(《现汉》(五)p639),“成:3.【动】成为;变为”(《现汉》(五)p171),“集成”有“汇集成为”的意思,释义行文体现为动词性。
“锦:有彩色花纹的丝织品”(《古汉语常用字字》p150),这里应为比喻义,指美好的东西,所以“集锦”释义行文应体现为名词性。
中文词性标注与viterbi算法

中⽂词性标注与viterbi算法⼀、viterbi算法原理及适⽤情况当事件之间具有关联性时,可以通过统计两个以上相关事件同时出现的概率,来确定事件的可能状态。
以中⽂的词性标注为例。
中⽂中,每个词会有多种词性(⽐如"希望"即是名字⼜是动词),给出⼀个句⼦后,我们需要给这个句⼦的每个词确定⼀个唯⼀的词性,实际上也就是在若⼲词性组合中选择⼀个合适的组合。
动词、名词等词类的搭配是具有规律性的,⽐如动词+名词的形式是⼤量存在的,当我们看到句⼦"存在希望",如果确定了"存在"是动词,那么由于动名词组合的概率较⼤,我们就会认定"希望"是名词。
viterbi算法的原理就是基于此。
我们需要计算所有的名词+动词,名词+名词,动词+形容词。
等各种种词性搭配的出现概率,然后从中选出最⼤概率的组合。
⼆、操作步骤1、需要准备⼀个语料库,包含已经正确标注了词性的⼤量语句。
2、对语料库的内容进⾏统计。
需要得到以下数据。
(1)所有可能的词性。
(2)所有出现的词语。
(3)每个词语以不同词性出现的次数。
(4)记录句⾸词为不同词性的次数。
(5)记录句⼦中任⼀两种词性相邻的次数(如遇到:"看电影"这个句⼦,则有[动词][名词]的值加⼀。
3、针对前⾯统计的结果,进⾏分析计算。
需计算以下数据。
(1)计算每类词性作为句⾸出现的⽐例(⽐如:动词为句⾸,占所有不同词性为句⾸中的⽐例),记录到fstart[TYPE_NUM]。
(2)计算后词固定为词性[n]时,前词为词性[x]占总情况的⽐例(如:后词固定为[动词]时,前词[名词]出现的次数占所有[x][动词]的⽐例),记录到fshift[TYPE_NUM][TYPE_NUM];(3)计算每⼀个词作为不同类词性出现的次数,占所有该类词出现总数的⽐例(如:"中国"作为名词出现的次数占所有名词的⽐例),记录到ffashe[TYPE_NUM][60000]4、输⼊句⼦进⾏词性标注输⼊的句⼦中每个词有多个词性。
5_语料库的构建

汉语语料库(续1)
宾州(Pennsylvania)大学语料库(UPenn Tree Bank)
/~treebank/home.html )
美国宾州大学计算机系M.Marcus 教授主持 2000年完成第一版中文树库,约10万词次,4185个句 子 例子: 原始句子:他还提出一系列具体措施的政策要点。 词性标注:他/ PN 还/ AD 提出/ VV 一/ CD 系列/ M 具体/ JJ 措施/ NN 和/ CC 政策/ NN 要点/ NN 。/PU
语料库分类
按来源分类
口语语料库/书面语语料库
按语言分类
单语语料库/双语语料库
按加工方式分
– 单语
原始语料库/切分标注语料库/句法树库/语义标注 语料库/…
– 双语
篇章对齐语料库/句子对齐语料库/词语对齐语料/ 库/结构对齐语料库
中文文本信息处理的原理与应用
语料库收集、整理和应用
中文文本信息处理的原理与应用
C/C++ Java
PerlBiblioteka /Python在该语言中用正则表达 式没有在Perl里面用起 来容易
Prolog
内置的数据库功能和能够方便地处理 缺少Perl的方便处理正 复杂的数据结构的特点,使得Prolog 则表达式的功能 在某些方面表现得相当优秀 中文文本信息处理的原理与应用
语料库语言学中常用技术(续2)
宾州大学树 库
美国 Pennsylvania大 学1980年代末 开始发起
中文文本信息处理的原理与应用
关于语料库
语料库基本概念 国外语料库概况 汉语语料库建设情况
中文文本信息处理的原理与应用
汉语语料库
基于条件随机场CRFs的中文词性标注方法_洪铭材

行文本标注时 , 先对文本进行初始标注 , 然后按照规则获取的 次序应用规则进行标注 。 该方法在英文词性标注上取得了很 好的效果 。 其主要问题是学习规则的时间过长 。 针对这一问 题 , 周明等提出一个快速学习算法 , 使训练速度大大提高[ 2] 。
③基于统计的方法 。 基于统计的方法是目前应用最广泛 的词性标注方法 。 白栓虎提出基于统计的汉语词性自动标注 方法 , 使用二元语法模型 和动态 规划的 方法进 行汉语 的词性 标注 。当前 大部分汉语词性系统采用基于二元语法模型或三 元语法模型的隐马尔可夫模型 , 通过 EM 训练的方法 , 给每个 词和词性标签对分配一个 联合概率 , 通 过维特 比解码 的动态 规划方法来获取一个句子对应的最佳的词性标注序列 。 隐马 尔可夫模型的缺点是假设词的词性只与 词本身和它 前面的 n 个词有关 , 而与该词后 面的词 没有关 系 。 这个假 设与实 际情 况并不吻合 。 基于最大熵模 型的词 性标注 方法 , 有效地 利用 了上下文信息 , 在一定的 约束条 件下可 以得到 与训练 数据一 致的概率分布 , 得到了 很好标 注效果 。 但 是最大 熵模型 存在 一种称为“ label bias” 问题 的弱点[ 1] , 在 某些 训练 集上得 到的 模型可能会得到很差的标注效果 。 常见的基于统计的方法还 有神经元网络 、决策树 、线性分离网络标注模型等 。
词性标注是自然语言处 理的重 要内容 之一 , 是其他 信息 的标注正确率 , 其封 闭测 试和开 放测 试的 准确率 分别 为 98.
处理技术的基础 , 被广 泛地应 用于机 器翻译 、文字 识别 、语音 56%和 96.60 %, 兼类 词和未 登录 词的 标注 也取 得了 很好 的
词性标注对照表
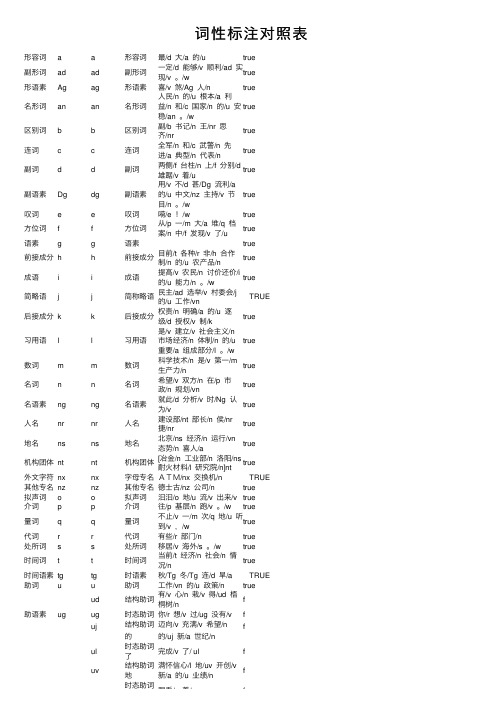
词性标注对照表形容词a a形容词最/d ⼤/a 的/u true副形词ad ad副形词⼀定/d 能够/v 顺利/ad 实现/v 。
/wtrue形语素Ag ag形语素喜/v 煞/Ag ⼈/n true名形词an an名形词⼈民/n 的/u 根本/a 利益/n 和/c 国家/n 的/u 安稳/an 。
/wtrue区别词b b区别词副/b 书记/n 王/nr 思齐/nrtrue连词c c连词全军/n 和/c 武警/n 先进/a 典型/n 代表/ntrue副词d d副词两侧/f 台柱/n 上/f 分别/d雄踞/v 着/utrue副语素Dg dg副语素⽤/v 不/d 甚/Dg 流利/a的/u 中⽂/nz 主持/v 节⽬/n 。
/wtrue叹词e e叹词嗬/e !/w true⽅位词f f⽅位词从/p ⼀/m ⼤/a 堆/q 档案/n 中/f 发现/v 了/utrue语素g g语素 true前接成分h h前接成分⽬前/t 各种/r ⾮/h 合作制/n 的/u 农产品/ntrue成语i i成语提⾼/v 农民/n 讨价还价/i的/u 能⼒/n 。
/wtrue简略语j j简称略语民主/ad 选举/v 村委会/j的/u ⼯作/vnTRUE后接成分k k后接成分权责/n 明确/a 的/u 逐级/d 授权/v 制/ktrue习⽤语l l习⽤语是/v 建⽴/v 社会主义/n市场经济/n 体制/n 的/u重要/a 组成部分/l 。
/wtrue数词m m数词科学技术/n 是/v 第⼀/m⽣产⼒/ntrue名词n n名词希望/v 双⽅/n 在/p 市政/n 规划/vntrue名语素ng ng名语素就此/d 分析/v 时/Ng 认为/vtrue⼈名nr nr⼈名建设部/nt 部长/n 侯/nr捷/nrtrue地名ns ns地名北京/ns 经济/n 运⾏/vn态势/n 喜⼈/atrue机构团体nt nt机构团体[冶⾦/n ⼯业部/n 洛阳/ns耐⽕材料/l 研究院/n]nttrue外⽂字符nx nx字母专名ATM/nx 交换机/n TRUE 其他专名nz nz其他专名德⼠古/nz 公司/n true拟声词o o拟声词汩汩/o 地/u 流/v 出来/v true介词p p介词往/p 基层/n 跑/v 。
汉语文本词性标注标记集的规范

汉语文本词性标注标记集的规范汉语文本词性标注标记集的规范代码名称帮助记忆的诠释 Ag 形语素形容词性语素。
形容词代码为a,语素代码g前面置以A。
a 形容词取英语形容词adjective的第1个字母。
ad 副形词直接作状语的形容词。
形容词代码a和副词代码d并在一起。
an 名形词具有名词功能的形容词。
形容词代码a和名词代码n并在一起。
b 区别词取汉字“别”的声母。
c 连词取英语连词conjunction的第1个字母。
Dg 副语素副词性语素。
副词代码为d,语素代码g前面置以D。
d 副词取adverb的第2个字母,因其第1个字母已用于形容词。
e 叹词取英语叹词exclamation的第1个字母。
f 方位词取汉字“方” g 语素绝大多数语素都能作为合成词的“词根”,取汉字“根”的声母。
h 前接成分取英语head的第1个字母。
i 成语取英语成语idiom的第1个字母。
j 简称略语取汉字“简”的声母。
k 后接成分 l 习用语习用语尚未成为成语,有点“临时性”,取“临”的声母。
m 数词取英语numeral的第3个字母,n,u已有他用。
Ng 名语素名词性语素。
名词代码为n,语素代码g前面置以N。
n 名词取英语名词noun的第1个字母。
nr 人名名词代码n和“人(ren)”的声母并在一起。
ns 地名名词代码n和处所词代码s 并在一起。
nt 机构团体“团”的声母为t,名词代码n和t并在一起。
nz 其他专名“专”的声母的第1个字母为z,名词代码n和z并在一起。
o 拟声词取英语拟声词onomatopoeia的第1个字母。
p 介词取英语介词prepositional的第1个字母。
q 量词取英语quantity的.第1个字母。
r 代词取英语代词pronoun的第2个字母,因p已用于介词。
s 处所词取英语space的第1个字母。
Tg 时语素时间词性语素。
时间词代码为t,在语素的代码g前面置以T。
CTB 词性标注中文版翻译

CTB词性标注指南第一章引言中文几乎没有屈折语素。
譬如,词语不随时态、格、人称和数量而曲折变化。
因此,对特定文本中的词进行词性标注往往都很困难。
这个文件是专为宾州中文树库项目[XPS+00]所设计的。
这个项目的目标是构建一个十万词的有语法托架的中文官话文本语料库。
标注包括两个步骤:第一阶段是中文分词和词性标注,第二阶段是句法托架。
每个步骤包括至少两个经过,即数据库由一个标注者标注,结果文件由另一个标注者检查。
词性标注指南,就如分词指南和托架指南,在项目进行过程中已经修订了多次。
到目前为止,我们已经在我们的网站上发行了三个版本:第一部草作完成于1998年12月,在第一个中文分词和词性标注文件发行后;第二部草作完成于1999年3月,在第二个中文分词和词性标注文件发行后;这个文件,是第三部草作,修订于第二个托架文件发行后。
在这个第三部草作中,与前两部草作相比,主要改变在于:(1)我们增加了一章引言来解释指南中存在的一些基本原理;(2)我们增加了对中文词语的注释;(3)我们把这个指南写成了一个技术性报告,报告被发表于宾夕法尼亚大学认知科学研究机构(IRCS)。
1.1 标注标准词性标注(POS)的核心问题是词性标注是否应该基于意义或者句法分布来标注。
这个问题自1950年以来就被热烈争论到现在,并且始终存在两种不同的观点。
譬如,中文词“毁灭”可以被翻译为英文中的destroy或destroys或destroyed或destroying或destruction,并且如它英文所对应的词一样使用。
根据第一种观点,词性标注应该只基于意义。
因为词的意义在它所有的用法中基本都是一样的,它就应该总是被标注为一个动词。
第二种观点是词性标注应该由词的句法分布来决定。
当“毁灭”是一个名词短语的首词,它在那个文本中就应该被标注为一个名词;当“毁灭”是一个动词短语的首词,它就应该被标注为一个动词。
我们选择了句法分布作为我们词性标注的主要标准,因为这与当代语言学理论所采纳的原则一致,譬如X-bar理论和GB理论中的首字投射概念。
国家语委语料库.

设计样本分布
科 目
表一:人文与社会科学类
比 例 字 数 1919-1925 1926-1949 1950-1965 1966-1976 19775% 15% 37.5 37.5 37.5 37.5 37.5 225 37.5 25% 62.5 62.5 62.5 62.5 62.5 375 62.5 5% 12.5 12.5 12.5 12.5 12.5 75 12.5 50% 125 125 125 125 125 750 125
• 时间层次。 • 文化层次。以具有高中文化程度的人能够阅读的语料为主,其他文化程 度为辅。 • 社会使用面层次。以社会使用面较为广泛的语料为主,其他语料为辅进 行补充;以人文与社会科学为主,自然科学为辅;以门类为主,以语体 为辅,对门类进行补充。
语料的描述性原则
从现代汉语语料库建设的主要用途出发, 语料应在必要的人工干预的前提下,做 描述性选取,以便为语言文字的规范与 科研提供客观的科学依据。 为了保证现代汉语的字、词、句、义在 语料中具有合理的出现频率,语料的选 择应在控制比例的前提下,尽量做到采 样广泛。
现代汉语语料库的主要用途及选材规模
主要用途
语言文字的信息处理 语言文字规范和标准的制定 语言文字的学术研究 语文教育 语言文字的社会应用 规模较大的通用语料库,其选材字数拟定在 5000万字左右,包括抽样材料和整篇材料。 教材字数另计。
选材规模
ቤተ መጻሕፍቲ ባይዱ材的分类
依据材料内容,选材大体作如下分类:
语言材料的完整性
语言材料的遍历性
语料抽样
抽样的数量与方式
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
'c': ('连词', 'conjunction', {
'cc': ('并列连词', 'coordinating conjunction'),
}),
'u': ('助词', 'particle', {
'uzhe': ('着', 'particle 着'),
'ule': ('了/喽', 'particle 了/喽'),
'wyy': ('右引号', 'right quotation mark'),
'wj': ('句号', 'period'),
'ww': ('问号', 'question mark'),
'wt': ('叹号', 'exclamation mark'),
'wd': ('逗号', 'comma'),
'wf': ('分号', 'semicolon'),
'ryt': ('时间疑问代词', 'temporal interrogative pronoun'),
'rys': ('处所疑问代词', 'locative interrogative pronoun'),
'ryv': ('谓词性疑问代词', 'predicate interrogative pronoun'),
'uguo': ('过', 'particle 过'),
'ude1': ('的/底', 'particle 的/底'),
'ude2': ('地', 'particle 地'),
'ude3': ('得', 'particle 得'),
'suo': ('所', 'particle 所'),
'udeng': ('等/等等/云云', 'particle 等/等等/云云'),
'r': ('代词', 'pronoun', {
'rr': ('人称代词', 'personal pronoun'),
'rz': ('指示代词', 'demonstrative pronoun', {
'rzt': ('时间指示代词', 'temporal demonstrative pronoun'),
}),
's': ('处所词', 'locative word'),
'f': ('方位词', 'noun of locality'),
'v': ('动词', 'verb', {
'vd': ('副动词', 'auxiliary verb'),
'vn': ('名动词', 'noun-verb'),
'vshi': ('动词"是"', 'verb 是'),
}),
'w': ('标点符号', 'punctuation mark', {
'wkz': ('左括号', 'left parenthesis/bracket'),
'wky': ('右括号', 'right parenthesis/bracket'),
'wyz': ('左引号', 'left quotation mark'),
'vg': ('动词性语素', 'verb morpheme'),
}),
'a': ('形容词', 'adjective', {
'ad': ('副形词', 'auxiliary adjective'),
'an': ('名形词', 'noun-adjective'),
'ag': ('形容词性语素', 'adjective morpheme'),
'wn': ('顿号', 'enumeration comma'),
'wm': ('冒号', 'colon'),
'ws': ('省略号', 'ellipsis'),
'wp': ('破折号', 'dash'),
'wb': ('百分号千分号', 'percent/per mille sign'),
'wh': ('单位符号', 'unit of measure sign'),
'uyy': ('一样/一般/似的/般', 'particle 一样/一般/似的/般'),
'udh': ('的话', 'particle 的话'),
'uls': ('来讲/来说/而言/说来', 'particle 来讲/来说/而言/说来'),
'uzhi': ('之', 'particle 之'),
'ulian': ('连', 'particle 连'),
}),
}
}),
'e': ('叹词', 'interjection'),
'y': ('语气词', 'modal particle'),
'o': ('拟声词', 'onomatopoeia'),
'h': ('前缀', 'prefix'),
'k': ('后缀', 'suffix'),
'x': ('字符串', 'string', {
}),
'rg': ('代词性语素', 'pronoun morpheme'),
}),
'm': ('数词', 'numeral', {
'mq': ('数量词', 'numeral-plus-classifier compound'),
}),
'q': ('量词', 'classifier', {
'qv': ('动量词', 'verbal classifier'),
'rzs': ('处所指示代词', 'locative demonstrative pronoun'),
'rzv': ('谓词性指示代词', 'predicate demonstrative pronoun'),
}),
'ry': ('疑问代词', 'interrogative pronoun', {
'nz': ('其它专名', 'other proper noun'),
'nl': ('名词性惯用语', 'noun phrase'),
'ng': ('名词性语素', 'noun morpheme'),
}),
't': ('时间词', 'time word', {
'tg': ('时间词性语素', 'time morpheme'),
'nrf': ('音译人名', 'transcribed personal name')