定性数据分析第三章课后答案
数据挖掘第三版第三章课后习题答案

2.1再给三个用于数据散布的常用特征度量(即未在本章讨论的),并讨论如何在大型数据库中有效的计算它们答:异众比率:又称离异比率或变差比。
是非众数组的频数占总频数的比率应用:用于衡量众数的代表性。
主要用于测度定类数据的离散程度,定序数据及数值型数据也可以计算。
还可以对不同总体或样本的离散程度进行比较计算:标准分数:标准分数(standard score)也叫z分数(z-score),是一个分数与平均数的差再除以标准差的过程。
用公式表示为:z=(x-μ)/σ。
其中x为某一具体分数,μ为平均数,σ为标准差。
Z值的量代表着原始分数和母体平均值之间的距离,是以标准差为单位计算。
在原始分数低于平均值时Z则为负数,反之则为正数。
计算:Z=(x-μ)/σ其中μ= E( X) 为平均值、σ² = Var( X) X的概率分布之方差若随机变量无法确定时,则为算术平均数离散系数:离散系数,又称“变异系数”,是概率分布离散程度的一个归一化量度,其定义为标准差与平均值之比。
计算:CV=σ/μ极差(全距)系数:Vr=R/X’;平均差系数:Va,d=A.D/X’;方差系数:V方差=方差/X’;标准差系数:V标准差=标准差/X’;其中,X’表示X的平均数。
平均差:平均差是总体所有单位的平均值与其算术平均数的离差绝对值的算术平均数。
平均差是一种平均离差。
离差是总体各单位的标志值与算术平均数之差。
因离差和为零,离差的平均数不能将离差和除以离差的个数求得,而必须讲离差取绝对数来消除正负号。
平均差是反应各标志值与算术平均数之间的平均差异。
平均差异大,表明各标志值与算术平均数的差异程度越大,该算术平均数的代表性就越小;平均差越小,表明各标志值与算术平均数的差异程度越小,该算术平均数的代表性就越大。
计算:平均差=(∑|x-x'|)÷n,其中∑为总计的符号,x为变量,x'为算术平均数,n为变量值的个数。
统计学第五版课后习题答案(完整版)

统计学(第五版)课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
医学统计学第七版课后答案及解析

医学统计学第七版课后答案第一章绪论一、单项选择题答案 1. D 2. E 3. D 4. B 5. A 6. D 7. A8. C 9. E 10. D二、简答题1答由样本数据获得的结果,需要对其进行统计描述和统计推断,统计描述可以使数据更容易理解,统计推断则可以使用概率的方式给出结论,两者的重要作用在于能够透过偶然现象来探测具有变异性的医学规律,使研究结论具有科学性。
2答医学统计学的基本内容包括统计设计、数据整理、统计描述和统计推断。
统计设计能够提高研究效率,并使结果更加准确和可靠,数据整理主要是对数据进行归类,检查数据质量,以及是否符合特定的统计分析方法要求等。
统计描述用来描述及总结数据的重要特征,统计推断指由样本数据的特征推断总体特征的方法,包括参数估计和假设检验。
3答统计描述结果的表达方式主要是通过统计指标、统计表和统计图,统计推断主要是计算参数估计的可信区间、假设检验的P 值得出相互比较是否有差别的结论。
4答统计量是描述样本特征的指标,由样本数据计算得到,参数是描述总体分布特征的指标可由“全体”数据算出。
5答系统误差、随机测量误差、抽样误差。
系统误差由一些固定因素产生,随机测量误差是生物体的自然变异和各种不可预知因素产生的误差,抽样误差是由于抽样而引起的样本统计量与总体参数间的差异。
6答三个总体一是“心肌梗死患者”所属的总体二是接受尿激酶原治疗患者所属的总体三是接受瑞替普酶治疗患者所在的总体。
第二章定量数据的统计描述一、单项选择题答案 1. A 2. B 3. E 4. B 5. A 6. E 7. E8. D 9. B 10. E二、计算与分析2第三章正态分布与医学参考值范围一、单项选择题答案 1. A 2. B 3. B 4. C 5. D 6. D 7. C8. E 9. B 10. A二、计算与分析12[参考答案] 题中所给资料属于正偏态分布资料,所以宜用百分位数法计算其参考值范围。
第三章 定性数据的 检验

3
? ? 假 如设果三H0类成的立观,察我次们数希分望别在为样本n1中, n喜2和欢n每3 一,品i?1 牌ni 的? n顾。
从而
c
?
?
2
?
(k
? 1)
对例3.1来说,k ? 3 ,当? ? 0.05 时,??2(k ?1)? ?02.05(2)? 5.991
? 2 ? (61 ? 50)2 ? (53 ? 50)2 ? (36 ? 50)2 ? 6.52
50
50
50
? 由于? 2 ? 6.52 ? 5.991,因此拒绝零假设。
由假设检验的一般原理知, c的值可由给定的显
著性水平 ? 确定,即c满足 P(? 2 ? c) ? ?
关于统计量 ? 2的分布,英国统计学家 Karl Pearson
给出下面的定理:
设总体中的每一个个体属于且只属 A1, A2 , , Ak
,k个类之一。总体中属于 k个类的比例为 p1, p 2 , , pk
即认为顾客对这三种品牌矿泉水的喜好确实存 在差异。
利用统计分析软件SPSS13.0可以大大简 化计算过程,下面用统计软件对例3.1进行分析。
?1.按要求录入数据; ?2.选择 Data ? weightCase 对数据进行加权; ?3.选择 Analyze ? Non ? parametricTest ? Chi ? square 进行非参数检验
3.1 多项分布与? 2 分布
?收集分类数据的目的是分析在每个类中 数据的分布。例如,我们为了估计消费 者中喜欢三种牙膏中每一种的比例,则 统计购买者三种牙膏的顾客购买每一种 的人数。在这里仅仅是根据牙膏的种类 来分类,我们称之为一维分类或一向分 类。下面通过例子来介绍一向分类数据 的分析。
定性数据分析第三章课后答案
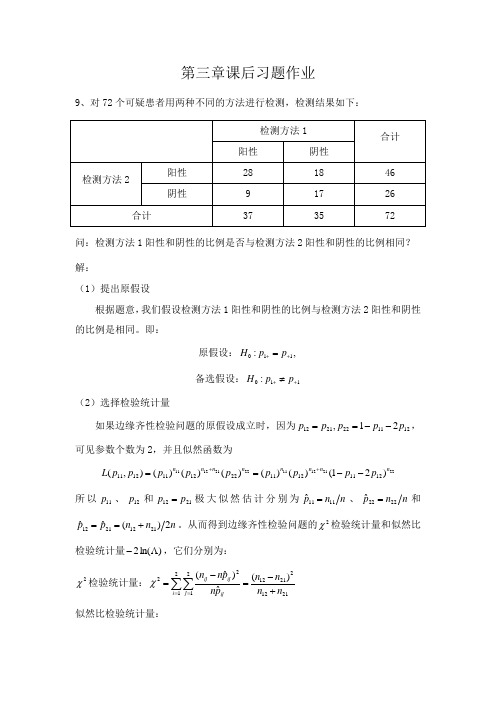
第三章课后习题作业9、对72个可疑患者用两种不同的方法进行检测,检测结果如下:问:检测方法1阳性和阴性的比例是否与检测方法2阳性和阴性的比例相同? 解:(1)提出原假设根据题意,我们假设检测方法1阳性和阴性的比例与检测方法2阳性和阴性的比例是相同。
即:原假设:011:,H p p ++= 备选假设:011:H p p ++≠(2)选择检验统计量如果边缘齐性检验问题的原假设成立时,因为121122211221,p p p p p --==,可见参数个数为2,并且似然函数为2221121122211211)21()()()()()(),(121112112212111211n n n n n n n n p p p p p p p p p L --==++所以11p 、12p 和2112p p =极大似然估计分别为n n p1111ˆ=、n n p 2222ˆ=和n n n p p2)(ˆˆ21122112+==。
从而得到边缘齐性检验问题的2χ检验统计量和似然比检验统计量)ln(2Λ-,它们分别为:2χ检验统计量:211222112212122)(ˆ)ˆ(n n n n p n p n n i j ij ij ij +-=-=∑∑==χ似然比检验统计量:⎪⎪⎭⎫⎝⎛+++-=⎪⎪⎭⎫⎝⎛-=Λ-∑∑==212112211221121221212ln 2ln 2ˆln 2)ln(2n n n n n n n n n p n n i j ijijij它们都有渐近2χ分布,其自由度都是4-2-1=1。
(3)计算检验统计量和p 值,并作出决策则McNemar 2χ检验统计量和似然检验统计量)ln(2Λ-的值分别为:3918)918(22=+-=χ 05818.392918ln 9182918ln 182)ln(2=⎪⎭⎫ ⎝⎛⋅++⋅+-=Λ-我们在Excel 中分别输入“)1,3(chidist =”和“)1,05818.3(chidist =”,可得到2χ检验统计量和似然检验统计量)ln(2Λ-的p 值分别为:083264517.0)3)1((2=≥=χP p 080331601.0)05818.3)1((2=≥=χP p由于p 值都不小,我们不能拒绝原假设,从而认为检测方法1阳性和阴性的比例与检测方法2阳性和阴性的比例是相同。
定性数据分析第三章课后答案
第三章课后习题作业9、对72个可疑患者用两种不同的方法进行检测,检测结果如下:问:检测方法1阳性和阴性的比例是否与检测方法2阳性和阴性的比例相同? 解:(1)提出原假设根据题意,我们假设检测方法1阳性和阴性的比例与检测方法2阳性和阴性的比例是相同。
即:原假设:011:,H p p ++= 备选假设:011:H p p ++≠(2)选择检验统计量如果边缘齐性检验问题的原假设成立时,因为121122211221,p p p p p --==,可见参数个数为2,并且似然函数为2221121122211211)21()()()()()(),(121112112212111211n n n n n n n n p p p p p p p p p L --==++所以11p 、12p 和2112p p =极大似然估计分别为n n p1111ˆ=、n n p 2222ˆ=和n n n p p2)(ˆˆ21122112+==。
从而得到边缘齐性检验问题的2χ检验统计量和似然比检验统计量)ln(2Λ-,它们分别为:2χ检验统计量:211222112212122)(ˆ)ˆ(n n n n p n p n n i j ij ij ij +-=-=∑∑==χ似然比检验统计量:⎪⎪⎭⎫⎝⎛+++-=⎪⎪⎭⎫⎝⎛-=Λ-∑∑==212112211221121221212ln 2ln 2ˆln 2)ln(2n n n n n n n n n p n n i j ijijij它们都有渐近2χ分布,其自由度都是4-2-1=1。
(3)计算检验统计量和p 值,并作出决策则McNemar 2χ检验统计量和似然检验统计量)ln(2Λ-的值分别为:3918)918(22=+-=χ 05818.392918ln 9182918ln 182)ln(2=⎪⎭⎫ ⎝⎛⋅++⋅+-=Λ-我们在Excel 中分别输入“)1,3(chidist =”和“)1,05818.3(chidist =”,可得到2χ检验统计量和似然检验统计量)ln(2Λ-的p 值分别为:083264517.0)3)1((2=≥=χP p 080331601.0)05818.3)1((2=≥=χP p由于p 值都不小,我们不能拒绝原假设,从而认为检测方法1阳性和阴性的比例与检测方法2阳性和阴性的比例是相同。
统计学第三版课后答案

统计学第三版课后答案第一章1.什么是统计学?统计学是一门研究如何收集、分析和解释数据的学科。
它涉及到收集数据的方法、数据的描述和分析、以及通过数据来进行推断和预测。
2.数据可以分为哪两种类型?数据可以分为定量数据和定性数据。
定量数据是可以用数字表示的,例如身高、体重等;定性数据是描述性的,例如颜色、性别等。
3.描述性统计与推论统计有什么区别?描述性统计是对收集到的数据进行总结、整理和展示的过程,主要通过统计指标如平均数、中位数等来描述数据的特征。
推论统计则是通过对样本数据进行推断,从而对整个总体进行推断和预测。
4.什么是样本?样本是从总体中选取出来的一部分个体。
通过对样本进行统计分析,我们可以对整个总体进行推断和预测。
5.什么是抽样误差?抽样误差是指由于样本选择的随机性所导致的样本统计量与总体参数之间的差异。
第二章1.总体和样本的区别是什么?总体是指研究对象的全体个体,而样本是从总体中选取出来的一部分个体。
2.简单随机抽样和分层抽样的区别是什么?简单随机抽样是指每个个体被抽中的概率相等且相互独立的抽样方法,适用于总体中各个个体之间没有明显分层的情况。
而分层抽样是将总体分为若干层次,然后从每个层次中分别抽取样本,适用于总体中各个层次之间存在明显差异的情况。
3.什么是系统抽样?系统抽样是指根据某种规则,从总体中以一定间隔选取样本的抽样方法。
例如,每隔k个个体选取一个个体作为样本。
4.方便抽样和判断抽样的特点是什么?方便抽样是指通过方便快捷的方法选取样本,例如通过问卷调查、网络调研等。
方便抽样的特点是样本选择的随机性不足,很容易导致样本与总体之间存在偏差。
判断抽样则是基于研究者的判断来选取样本,因此也可能存在主观性和偏见。
5.什么是多阶段抽样?多阶段抽样是指将总体分为若干个阶段,先从每个阶段中按一定方法抽取较小的样本,然后再从这些小样本中抽取最终的样本。
第三章1.什么是频率?频率是指某个数值或范围在样本或总体中出现的次数。
王静龙定性数据分析 习题五

王静龙定性数据分析习题五1. 问题描述在定性数据分析中,王静龙遇到了一个问题,他想要了解一份调查问卷中的开放性问题的回答情况。
具体而言,他想要回答以下几个问题:1.开放性问题的回答内容的总体情况如何?2.开放性问题的回答内容中是否存在一些常见的关键词或主题?3.开放性问题的回答内容中是否存在一些特定的意见或情感?为了解决这个问题,王静龙希望能够进行数据分析,并得出一些有用的结论。
2. 数据准备首先,王静龙需要准备调查问卷中开放性问题的回答数据。
这些数据可以以文本文件的形式存储,每一行代表一个回答。
例如,以下是一些示例数据:1. 我觉得工作环境很好,同事们相互合作,给了我很多帮助。
2. 公司的培训计划很好,能够提高员工的技能和知识。
3. 我对公司的管理方式有一些不满意,希望能够改进。
4. 薪资待遇不够优厚,希望能够有所提升。
5. 我觉得公司的发展前景很不错,希望能够有更好的发展空间。
3. 数据分析3.1 总体情况分析为了了解开放性问题的回答内容的总体情况,王静龙可以进行以下分析:•回答的总数•回答的平均长度•回答的最长长度•回答的最短长度为了实现这些分析,可以使用Python编程语言中的文本处理库进行操作。
下面是一个示例代码,可以帮助完成上述分析:```python # 导入所需的库 import pandas as pd 读取文本文件data = pd.read_csv(’responses.txt’, header=None)计算回答的总数total_responses = len(data)计算回答的平均长度average_length = data[0].apply(len).mean()计算回答的最长长度max_length = data[0].apply(len).max()计算回答的最短长度min_length = data[0].apply(len).min()输出结果print(。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第三章课后习题作业
9、对72个可疑患者用两种不同的方法进行检测,检测结果如下:
问:检测方法1阳性和阴性的比例是否与检测方法2阳性和阴性的比例相同? 解:
(1)提出原假设
根据题意,我们假设检测方法1阳性和阴性的比例与检测方法2阳性和阴性的比例是相同。
即:
原假设:011:,H p p ++= 备选假设:011:H p p ++≠
(2)选择检验统计量
如果边缘齐性检验问题的原假设成立时,因为121122211221,p p p p p --==,可见参数个数为2,并且似然函数为
2221121122211211)21()()()()()(),(121112112212111211n n n n n n n n p p p p p p p p p L --==++
所以11p 、12p 和2112p p =极大似然估计分别为n n p
1111ˆ=、n n p 2222ˆ=和n n n p p
2)(ˆˆ21122112+==。
从而得到边缘齐性检验问题的2χ检验统计量和似然比检验统计量)ln(2Λ-,它们分别为:
2
χ检验统计量:211222112212
1
22
)(ˆ)ˆ(n n n n p n p n n i j ij ij ij +-=-=∑∑==χ
似然比检验统计量:
⎪⎪⎭⎫
⎝⎛+++-=⎪⎪⎭
⎫
⎝⎛-=Λ-∑∑==21211221122112122
1212ln 2ln 2ˆln 2)ln(2n n n n n n n n n p n n i j ij
ij
ij
它们都有渐近2χ分布,其自由度都是4-2-1=1。
(3)计算检验统计量和p 值,并作出决策
则McNemar 2χ检验统计量和似然检验统计量)ln(2Λ-的值分别为:
39
18)918(2
2
=+-=
χ 05818.392918ln 9182918ln 182)ln(2=⎪⎭⎫ ⎝
⎛
⋅++⋅+-=Λ-
我们在Excel 中分别输入“)1,3(chidist =”和“)1,05818.3(chidist =”,可得到2χ检验统计量和似然检验统计量)ln(2Λ-的p 值分别为:
083264517.0)3)1((2=≥=χP p 080331601.0)05818.3)1((2=≥=χP p
由于p 值都不小,我们不能拒绝原假设,从而认为检测方法1阳性和阴性的比例与检测方法2阳性和阴性的比例是相同。
13、某肿瘤学专家在11年里对4万多个中年人的生活方式进行了观察。
发现在喜爱腌制食品的男性中,每500人中就有1人患胃癌。
这是很少吃腌制食品男性的两倍。
令A 表示患胃癌,B 表示喜爱腌制食品。
B 作为A 的风险因素,试求其相对危险度和优比。
解:由题意知,A 表示患胃癌,B 表示喜爱腌制食品,则相应的概率四格表为:
(1)相关概念
①相对危险度是指有风险因素的危险程度与无风险的危险程度之比,在本题则是指喜爱腌制食品的男性中患胃癌的概率与很少吃腌制食品男性中患胃癌的概率之比;
②优比是指两个优势的比,本题中优比是指在喜爱腌制食品的男性中患胃癌与不患胃癌的概率比比上很少吃腌制食品男性中患胃癌与不患胃癌的概率所得的结果。
(2)根据题意列出相应关系式 ①用C 表示相对危险度,则有
)|()|(B A P B A P C =
②用θ表示优比,则有
)
|()|()
|()|(B A P B A P B A P B A P =
θ
(3)计算结果
由题喜爱腌制食品的男性中,每500人中就有1人患胃癌,他是很少吃腌制食品男性的两倍,我们可以知道
001
.021
5001)|(002.0500
1
)|(=⨯===
B A P B A P
①则相对危险度为
2001.0002.0)|()|(===B A P B A P C
②由四格表知
2
12111)|()|(++==p p B A P p p B A P
且有2221212111,++=+=+p p p p p p 所以优比为
002004008
.2001.0999
.0998.0002.0001
.01001.0002.01002
.011)()()|()|()|()|(2
122121
1111121222121111111222212
121
111
=⨯=--=--=--===++++++++++++++θθp p p p p p p p p p p p p p p p p p p p p p p p p p B A P B A P B A P B A P
由此可知优比与相对危险度相差很小。