为什么样本方差里面要除以(n-1)而不是n
为什么样本标准差使用被称为自由度的n-1

为什么样本标准差使用被称为自由度的n-1
自由度的定义:
“自由度(degrees of freedom)”指的是,在一定的约束条件下,样本所能提供的独立的信息的个数。
考虑样本量为n的样本(n个数),如果我们知道样本均值,那么我们只需要知道前n-1个数,就可以得知全部信息,因为最后一个数可以借助均值计算得出。
所以,在给定样本均值(约束条件)的情况下,我们相当于在原本n个数的基础上消减了一个自由度,样本提供的信息只有n-1个独立的部分。
当样本数据的个数为n时,若样本平均数x拔确定后,则附加给n个观测值的约束个数就是1个,一次只有n-1个数据可以自由取值,其中必有一个数据不能自由取值。
按照这一逻辑,如果对n个观测值附加的约束个数为k个,自由度则为n-k。
例如假设样本有3个值,即x1=2,x2=4,x3=9,则当x拔=5确定后,x1、x2、x3只有两个数据可以自由取值,另一个则不能自由取值,比如x1=6,x2=7,那么x3必然取2,而不能取其他值。
样本方差自由度为什么为n-1呢,因为在计算离差平方和∑(xi -x)2 时,必须先求出样本平均数 x拔,而 x拔则是附加给∑(xi -x)2 的一个约束,因此,计算离差平方和时只有n-1个独立的观测值,而不是n个。
方差估计常用公式推导

方差估计常用公式推导
嘿,咱今天就来好好聊聊方差估计常用公式推导!先来说说总体方差的估计公式吧,就像射击打靶一样,要衡量一群数据的离散程度。
比如咱有一组数 1,3,5,7,9,这中间的波动有多大呢,就得用公式啦!
总体方差的估计公式就是:样本方差 = 各数据与样本均值的差的平方和除以样本个数。
哎呀,是不是听起来有点晕乎?举个例子哈,这组数 1,3,5,7,9,先算出均值是 5,然后算每个数和 5 的差值的平方,再把这些平方和加起来,最后除以 5,这不就得出方差啦!
还有个样本方差公式呢,就好像是给总体方差打了个折扣!公式是:样本方差 = 各数据与样本均值的差的平方和除以(样本个数 - 1)。
咦,为啥要除以(样本个数 - 1)呢?这就像给计算加了点调料,让结果更靠谱呀!比如说另一组数 2,4,6,8,它的样本方差就得按照这个公式好好算一算啦!
咋样,是不是感觉方差估计也不是那么难理解啦?加油哦,你肯定能掌握的!。
证明样本方差的时候除以n是一个一致的估计量

证明样本方差的时候除以n是一个一致的估计量
样本方差是统计分析中常常使用的量,它是用来描述一组数据的离散程度,并且可以用来衡量数据之间的差异。
在统计学中,方差是一种重要的度量,但是由于其计算复杂性,通常会有所出入。
《证明样本方差的时候除以n是一个一致的估计量》这个问题,研究人员普遍认为,当样本方差除以n时,这一估计量是一致的。
这就是说,当数据组大小越大,样本方差的估计值越接近真实方差。
要解释这一结论,我们可以从理论上和实证上来考虑这个问题。
实证上,我们可以利用不同大小的样本,对样本方差的估计量进行检验,假设真实方差为θ。
实验结果表明,当样本大小增加时,样本方差的估计值的确是一致的,即:
估计量S / n趋于θ
从这个实证上,我们很容易得出结论:当样本方差除以n时,这一估计量是一致的。
理论上,这一结论也可以由大数定律和中心极限定理给出证明,即大数定律指出,任何统计量的样本平均都会收敛到总体平均,而中心极限定理则指出,总体平均的样本方差会收敛到总体方差。
因此,由此可以推出,当样本方差除以n时,这一估计量是一致的。
由以上理论和实证的论述可知,当样本方差除以n时,这一估计量是一致的,这也是大多数研究人员普遍认可的,由此可见,这一结论是可信的。
总结一下,本文的主要内容是:证明样本方差的时候除以n是一
个一致的估计量。
从理论和实证上来看,当样本方差除以n时,这一估计量是一致的,这也是大多数研究人员普遍认可的,由此可见,这一结论是可信的。
样本方差公式中N-1的思考

样本方差公式中N-1的思考蒲智勇摘要:样本方差是来判断数据的稳定性的,在生活中应用样本方差来做出选择,直接关系着事件的成功与否。
本文通过文件检索等方法,分析了的意义与来源,得出样本方差公式中N-1是对标准方差的修正的结果。
关键词:样本样本方差统计量无偏性Sample variance formula for N - 1Abstract:the stability of the sample variance is to judge the data, application sample variance in life to make a choice, directly related with the success of the event. In these paper, through methods of document retrieval, analyzes the meaning and origin, draw a sample variance formula for N - 1 is the result of a modification to the standard variance.Keywords:sample sample variance statistics magnitude unbiasedness前言:目前许多教材上,对样本方差是如何来的都未做出解释,即使有也一笔带过,大学上课的老师提都未提。
大学是来做学问的地方,怎么不去探讨它?当接触这样本方差公式时,就在想是不是,样本的平均值与观察值相等的原因引起的。
就随便列举了一组观察值,恰好观察值与样本均值相等,就草率的认为明白了这公式。
但心里还是对这个公式感觉怪怪的,怎么跟以前的方差公式不一样,以前是N,怎么现在变成了N-1?一直想从其他角度推出这个公式,因为个人因素,未能如愿。
那就只有从侧面去解释这个原因一、样本方差中的基本概念为无偏估计。
贝塞尔公式 n-1

贝塞尔公式 n-1
什么是贝塞尔公式 n-1?
在统计学中,贝塞尔公式 n-1 常常被用来对样本统计量的方差进行校正。
而对于需要进行参数估计的问题,常常需要使用样本较小的情况下,
通过样本均值来估计总体均值。
然而,当我们使用样本平均数来进行参数估计时,可能会出现估计偏
差的问题。
这是因为我们所计算的样本均值只是样本中所有数据相加
后所得到的平均数,并未考虑到样本数据集在相加的过程中出现了随
机误差。
为了避免这样的估计偏差,我们需要对样本统计量的方差进
行校正。
在这种情况下,我们将采用贝塞尔公式,这个公式在统计学中是非常
重要的。
事实上,许多人都认为贝塞尔公式是统计学的艺术之一。
不
过初学者也不要害怕,它对于我们的数据分析提供了一种重要的手段,帮助我们更加准确地估计出样本数据的总体参数。
就像之前所说的,贝塞尔公式用于校正样本统计量的方差。
具体地说,贝塞尔公式是将样本方差乘以一个校正因子来得到修正后的样本方差,这个校正因子通常是 (n-1)/n,其中 n 代表样本数据点的总数。
使用贝塞尔公式校正样本统计量的方差的好处是显然的,它可以帮助
我们更加准确地估计总体参数。
然而,也需要注意到贝塞尔公式使用
的范围是有限的。
当样本数据点数量趋近于总体数据点数量时,贝塞尔公式的偏差会变得非常小,因此它的效果也会减弱。
总之,贝塞尔公式对于样本数据的方差校正是非常有用的,这样我们就可以得到更加准确的总体参数估计。
它是统计学中的一道精妙的工具,在实际数据分析过程中也经常被使用。
为什么样本方差里面要除以(n-1)而不是n?

前段日子重新整理了一下这个问题的解答,跟大家分享一下,如果有什么错误的话希望大家能够提出来,我会及时改正的,话不多说进入正题:首先,我们来看一下样本方差的计算公式:刚开始接触这个公式的话可能会有一个疑问就是:为什么样本方差要除以(n-1)而不是除以n?为了解决这个疑惑,我们需要具备一点统计学的知识基础,关于总体、样本、期望(均值)、方差的定义以及统计估计量的评选标准。
有了这些知识基础之后,我们会知道样本方差之所以要除以(n-1)是因为这样的方差估计量才是关于总体方差的无偏估计量。
这个公式是通过修正下面的方差计算公式而来的:修正过程为:我们看到的其实是修正后的结果:对于这种修正的话是有相关的公式推导的。
下面都会一一给出。
为了方便叙述,在这里说明好数学符号:前面说过样本方差之所以要除以(n-1)是因为这样的方差估计量才是关于总体方差的无偏估计量。
在公式上来讲的话就是样本方差的估计量的期望要等于总体方差。
如下:但是没有修正的方差公式,它的期望是不等于总体方差的也就是说,样本方差估计量如果是用没有修正的方差公式来估计总计方差的话是有偏差的下面给出比较好理解的公式推导过程:也就是说,除非否则一定会有需要注意的是不等式右边的才是的对方差的“正确”估计,但是我们是不知道真正的总体均值是多少的,只能通过样本的均值来代替总体的均值。
所以样本方差估计量如果是用没有修正的方差公式来估计总计方差的话是会有偏差,是会低估了总体的样本方差的。
为了能无偏差的估计总体方差,所以要对方差计算公式进行修正,修正公式如下:这种修正后的估计量将是总体方差的无偏估计量,下面将会给出这种修正的一个来源;为了能搞懂这种修正是怎么来的,首先我们得有下面几个等式:1.方差计算公式:2.均值的均值、方差计算公式:对于没有修正的方差计算公式我们有:因为:所以有:在这里如果想修正的方差公式,让修正后的方差公式求出的方差的期望为总体方差的话就需要在没有修正的方差公式前面加上来进行修正,即:所以就会有这样的修正公式:而我们看到的都是修正后的最终结果:这就解释了为什么要对方差计算公式进行修正,且为什么要这样修正。
多元统计
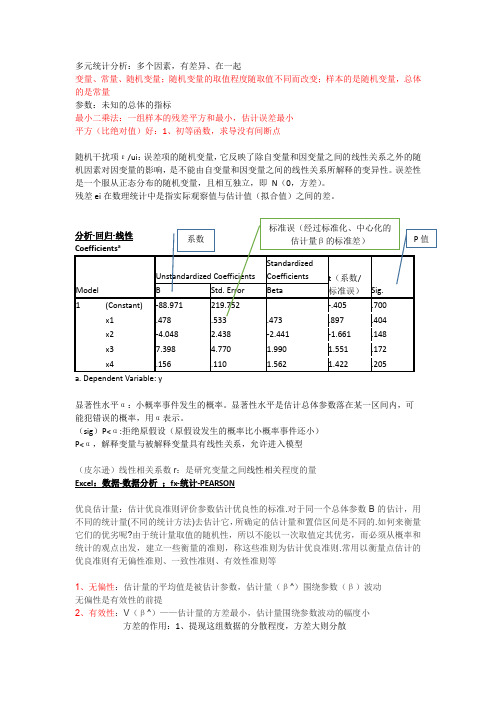
多元统计分析:多个因素,有差异、在一起变量、常量、随机变量;随机变量的取值程度随取值不同而改变;样本的是随机变量,总体的是常量参数:未知的总体的指标最小二乘法:一组样本的残差平方和最小,估计误差最小平方(比绝对值)好:1、初等函数,求导没有间断点随机干扰项ε/ui:误差项的随机变量,它反映了除自变量和因变量之间的线性关系之外的随机因素对因变量的影响,是不能由自变量和因变量之间的线性关系所解释的变异性。
误差性是一个服从正态分布的随机变量,且相互独立,即N(0,方差)。
残差ei在数理统计中是指实际观察值与估计值(拟合值)之间的差。
优良估计量:估计优良准则评价参数估计优良性的标准.对于同一个总体参数B的估计,用不同的统计量(不同的统计方法)去估计它,所确定的估计量和置信区间是不同的.如何来衡量它们的优劣呢?由于统计量取值的随机性,所以不能以一次取值定其优劣,而必须从概率和统计的观点出发,建立一些衡量的准则,称这些准则为估计优良准则.常用以衡量点估计的优良准则有无偏性准则、一致性准则、有效性准则等1、无偏性:估计量的平均值是被估计参数,估计量(β^)围绕参数(β)波动无偏性是有效性的前提2、有效性:V(β^)——估计量的方差最小,估计量围绕参数波动的幅度小方差的作用:1、提现这组数据的分散程度,方差大则分散3、样本容量越大越好为什么样本方差是除以n-1:自由度df:相互独立的变量个数标准化的好处:1、同一量纲2、不再有水平和分散程度的不同(均值0方差1)分析-描述统计-描述-将标准化得分另存为变量z标准化回归:线性回归中-选项-把在等式中包含常量的√去掉(随机)向量(x,y):把独立(随机)变量x、y放在一起形成一个整体行向量*列向量=一个数列向量*行向量=一个矩阵假设检验:假设的是总体,假设是具体的总检验:F统计量线性回归结果-方差分析表ANOVA有n个样本,i个解释变量,最小二乘法有n-(i+1)个方程,i+1是因为除了参数还有截距项。
样本方差与方差的关系

样本方差与方差的关系样本方差和方差是统计学中常用的两个概念。
它们都是用来衡量数据的离散程度的指标。
本文将介绍样本方差和方差的概念、计算方法以及它们之间的关系。
我们来了解一下样本方差和方差的定义。
样本方差是指在统计学中,用来衡量一组样本数据的离散程度的统计量。
它表示数据与其均值之间的偏离程度。
用公式表示为:样本方差=∑(xi-x̄)²/n-1,其中xi表示样本中的每个数据点,x̄表示样本的均值,n表示样本的个数。
方差是指在统计学中,用来衡量一组数据的离散程度的统计量。
它表示数据与其均值之间的偏离程度。
用公式表示为:方差=∑(xi-μ)²/n,其中xi表示每个数据点,μ表示总体的均值,n表示数据的个数。
从定义可以看出,样本方差和方差的计算公式非常相似,只是分母上的n-1和n有所不同。
这是因为样本方差是用来估计总体方差的,而总体方差是用来描述整个总体数据的离散程度的。
而在计算样本方差时,为了使样本方差更接近总体方差,需要用n-1来代替n,这样可以更好地估计总体的离散程度。
样本方差和方差的关系可以从两个方面来进行解释。
首先,从计算公式上看,样本方差和方差的计算方法非常相似,只是分母上的n-1和n有所不同。
其次,从概念上看,样本方差和方差都是用来衡量数据的离散程度的指标,都表示数据与其均值之间的偏离程度。
因此,可以说样本方差是方差的一种估计。
在实际应用中,样本方差和方差都有着重要的作用。
它们可以帮助我们了解数据的离散程度,进而进行数据分析和决策。
比如,在财务领域,可以用方差来衡量投资组合的风险;在生产领域,可以用样本方差来衡量产品的质量稳定性;在医学领域,可以用方差来衡量药物的疗效稳定性。
样本方差和方差是用来衡量数据的离散程度的统计量。
它们在计算公式和概念上都非常相似,只是分母上的n-1和n有所不同。
样本方差是用来估计总体方差的,而方差是用来描述整个总体数据的离散程度的。
它们在实际应用中有着重要的作用,可以帮助我们了解数据的离散程度,进行数据分析和决策。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
为什么样本方差里面要除以(n-1)而不是n?(---by小马哥整理)
首先,我们来看一下样本方差的计算公式:
(1) 刚开始接触这个公式的话可能会有一个疑问就是:为什么样本方差要除以(n-1)而不是除以n?为了解决这个疑惑,我们需要具备一点统计学的知识基础,关于总体、样本、期望(均值)、方差的定义以及统计估计量的评选标准。
有了这些知识基础之后,我们会知道样本方差之所以要除以(n-1)是因为这样的方差估计量才是关于总体方差的无偏估计量。
这个公式是通过修正下面的方差计算公式而来的。
公式(2)是我们按照正常的思维, 思考的应该有的方差的计算公式,也就是除以n的情况:
(2)
公式(3)是我们经过修正得到的式子, 修正过程为:
(3)
我们在课本上看到的其实是修正后的结果:
(4) 下面详细(推导)讲, 为啥会要乘以前面那个(1/n-1), 来对公式(2)进行修正.
为了方便叙述,在这里说明好数学符号:
(5) 前面说过样本方差之所以要除以(n-1)是因为这样的方差估计量才是关于总体方差的无偏估计量。
在公式上来讲的话就是样本方差的估计量的期望要等于总体方差。
如下:
(6) 但是没有修正的方差公式,它的期望是不等于总体方差的(下面会讲解详细原因, 就是下面那个公式推导!)
(7) 也就是说,样本方差估计量如果是用没有修正的方差公式来估计总计方差的话是有偏差的
下面给出比较好理解的公式推导过程:
(8) 也就是说,除非否则一定会有
(9) 需要注意的是不等式右边的才是的对方差的“正确”估计,但是我们是不知道真正的总体均值是多少的,只能通过样本的均值来代替总体的均值。
所以样本方差估计量如果是用没有修正的方差公式来估计总计方差的话是会有偏差,是会低估了总体的样本方差的。
为了能无偏差的估计总体方差,所以要对方差计算公式进行修正,修正公式如下:
(10) 这种修正后的估计量将是总体方差的无偏估计量,下面将会给出这种修正的一个来源;
为了能搞懂这种修正是怎么来的,首先我们得有下面几个等式:
1.方差计算公式:
(11) 2. 均值的均值、方差计算公式:
(12) 对于没有修正的方差计算公式我们有:
(13)
因为:
(14) 所以有:
(15) 在这里如果想修正的方差公式,让修正后的方差公式求出的方差的期望为总体方差的话就需要在没有修正的方差公式前面加上来进行修正,即:
(16) 所以就会有这样的修正公式:
(17) 而我们看到的都是修正后的最终结果:
(18)。