关联性分析
薪酬绩效关联性分析

薪酬绩效关联性分析薪酬绩效关联性分析是企业进行绩效管理和薪酬制度设计的重要工具。
通过对薪酬与绩效之间的关系进行深入剖析,可以帮助企业更好地激励员工,提高工作效率,增加组织竞争力。
本文将介绍薪酬绩效关联性分析的概念、方法以及对组织和员工的影响。
一、概念薪酬绩效关联性分析是一种评估薪酬制度与绩效管理效果的方法。
它通过对薪酬和绩效数据进行整合和分析,来确定薪酬与绩效之间的关系。
薪酬绩效关联性分析可以帮助企业了解薪酬制度是否能够合理激励员工,是否能够提高员工的工作绩效。
二、方法1. 数据收集和整理:首先,企业需要收集和整理薪酬和绩效数据。
薪酬数据可以包括员工的工资、奖金、股权等薪酬福利;绩效数据可以包括员工的工作成果、工作进度、工作质量等。
2. 数据关联分析:在数据收集和整理完成后,企业可以通过一些统计方法,如相关性分析、回归分析等,来分析薪酬和绩效之间的相关性。
相关性分析可以帮助企业确定薪酬和绩效之间的关系强度和方向,而回归分析可以帮助企业建立薪酬和绩效之间的数学模型。
3. 结果解读:根据数据分析的结果,企业可以了解薪酬制度是否对绩效产生了积极的影响。
如果薪酬和绩效之间存在显著的正向关系,说明薪酬制度能够有效激励员工,提高工作绩效;如果薪酬和绩效之间存在负向关系或者无关系,说明薪酬制度可能存在问题,需要进行调整和改进。
三、对组织的影响1. 激励员工:薪酬绩效关联性分析可以帮助企业确定薪酬制度是否能够激励员工努力工作。
当薪酬与绩效存在正向关系时,员工将更加积极地为了薪酬目标而努力工作,增加工作动力和投入度。
2. 提高工作效率:薪酬绩效关联性分析可以帮助企业发现工作绩效低下的员工,及时给予奖励或其他激励措施,以提高员工的工作效率和绩效水平。
同时,也能够优化薪酬分配,给予高绩效员工更多的奖励,进一步激发员工的工作动力。
3. 建立公平公正的薪酬制度:薪酬绩效关联性分析可以帮助企业确立一个公平公正的薪酬制度。
通过对不同员工的绩效进行量化评估,合理分配薪酬福利,避免薪酬不公平现象的发生。
报告中的实证研究与关联性分析

报告中的实证研究与关联性分析引言在不同领域的研究中,报告起到了整合和总结研究成果的重要作用。
实证研究和关联性分析是报告中常见的研究方法和数据分析技术。
本文将探讨报告中的实证研究和关联性分析的应用和意义,并提供了六个具体的标题,分别从不同角度对这一主题进行展开论述。
标题一:实证研究的基本框架实证研究是以实证主义的哲学观点为基础的一种研究方法,强调通过收集和分析实证数据来验证假设或推论。
该部分将介绍实证研究的基本步骤,包括问题的提出、数据的收集和整理、数据分析以及对研究结果的解释和讨论。
通过实例介绍如何运用实证研究方法进行报告撰写。
标题二:关联性分析的原理和技术关联性分析是一种数据挖掘技术,用于发现数据中的相关模式和关联规则。
该部分将介绍关联性分析的原理和常用技术,如Apriori算法和FP-growth算法。
通过对关联性分析的引入和实例运用,论述在报告中如何利用关联性分析揭示数据之间的关联关系。
标题三:实证研究和关联性分析的联系与区别实证研究和关联性分析都是通过数据分析来得出结论的方法,但二者有着不同的侧重点和应用范围。
该部分将比较实证研究和关联性分析的异同之处,并解释它们在报告中的角色和价值。
指引读者在合适的场景中选择适当的方法。
标题四:实证研究与关联性分析的应用领域实证研究和关联性分析在各个领域都有广泛的应用。
该部分将逐一介绍实证研究和关联性分析在市场营销、金融、医疗等领域的应用案例,深入探讨其在这些领域中如何发挥作用,并举例说明数据分析和结论推断的重要性。
标题五:实证研究和关联性分析在决策支持中的作用实证研究和关联性分析常常用于提供决策支持,在决策过程中发挥重要的作用。
该部分将通过案例分析实证研究和关联性分析在决策支持中的应用,讨论如何基于实证研究和关联性分析的结果做出合理的决策,并提升决策的科学性和准确性。
标题六:实证研究和关联性分析的挑战和展望实证研究和关联性分析领域还存在一些挑战和亟待解决的问题,如数据质量问题、算法的改进和结果的解释等。
知识点关联性分析

知识点关联性分析知识点关联性分析可以帮助我们理清各个知识点之间的关系,从而更好地学习和应用知识。
通过深入研究不同领域的知识点之间的联系,我们可以更好地掌握知识的本质,并更加高效地运用于实践中。
本文将介绍知识点关联性分析的概念、方法和应用,并以具体案例进行说明。
一、知识点关联性分析的概述知识点关联性分析是一种方法,用于研究和理解知识点之间的相互关系。
它可以通过对知识点的属性、结构和语义进行分析,揭示不同知识点之间的联系和依赖关系。
通过知识点关联性分析,我们可以建立知识点之间的网络图,从而更好地理解知识的结构和组织方式。
二、知识点关联性分析的方法1. 数据收集和整理:首先,我们需要收集和整理各个领域相关的知识点。
这可以通过查阅文献、专业书籍和互联网资源等途径进行。
在收集过程中,我们可以结合自己的学习需求和目标进行筛选和归类。
2. 知识点属性分析:针对不同的知识点,我们可以进行属性分析,包括知识点的定义、特征、作用等方面。
通过比较不同知识点的属性,我们可以初步了解它们之间的关联性。
3. 知识点结构分析:知识点的结构是指它们之间的层次结构和组织方式。
我们可以对不同知识点进行层次划分,将它们按照从基础到高级的顺序排列。
通过对结构的分析,我们可以更好地理解知识点之间的逻辑关系和依赖关系。
4. 知识点语义分析:知识点的语义是指它们的含义和关联的概念。
我们可以通过分析不同知识点之间的语义相似性和差异性,了解它们之间的联系和区别。
这可以通过利用自然语言处理和机器学习等技术来实现。
5. 知识点关联度计算:在进行知识点关联性分析时,我们可以通过计算不同知识点之间的关联度来评估它们之间的关系。
这可以使用图论、数据挖掘和机器学习等方法来实现。
关联度的计算可以考虑知识点之间的直接关系,也可以考虑它们之间的间接关系。
三、知识点关联性分析的应用知识点关联性分析可以应用于多个领域,包括教育、信息检索和知识图谱等。
下面以信息检索领域为例,介绍知识点关联性分析的具体应用。
在报告中使用关联性分析进行数据解读

在报告中使用关联性分析进行数据解读一、什么是关联性分析关联性分析是一种统计方法,用于确定两个或多个变量之间的关系。
它可以帮助我们了解变量之间的相互作用,并揭示出可能存在的因果关系。
在数据分析中,关联性分析常用于探索变量之间的相关性,并帮助我们解读数据。
二、为什么要使用关联性分析1. 发现潜在关系:通过关联性分析,我们可以发现数据中可能存在的潜在关系。
例如,在营销分析中,我们可以通过分析顾客购买记录和推广活动之间的关联性,了解哪些推广活动对销售业绩有积极影响,从而优化营销策略。
2. 预测未来趋势:通过观察变量之间的关联性,我们可以预测未来的趋势。
例如,通过分析天气数据和销售数据之间的关联性,我们可以预测某种商品在不同天气条件下的销售情况,为供应链管理提供参考。
3. 解释数据:关联性分析可以帮助我们解释数据背后的原因和机制。
通过分析变量之间的关联性,我们可以了解各个因素对结果的影响程度,从而找出影响因素并提出改进措施。
三、关联性分析的常用方法1. 相关系数分析:相关系数是衡量两个变量之间线性相关程度的指标。
通过计算相关系数,我们可以了解两个变量之间的相关性强弱及正负方向。
例如,在销售分析中,我们可以通过计算销售额与广告投放费用之间的相关系数,来判断广告对销售的影响。
2. 散点图分析:散点图是一种显示两个变量之间关系的可视化工具。
通过绘制散点图,我们可以直观地看出两个变量之间的趋势以及散布的程度。
例如,在人口统计学中,我们可以通过绘制散点图来观察年龄和收入之间的关联性。
3. 回归分析:回归分析是一种用于建立变量之间关系模型的方法。
通过回归分析,我们可以确定一个或多个自变量与因变量之间的数学关系,并用于预测和解释数据。
例如,在金融领域,我们可以通过回归分析建立股价与宏观经济指标之间的关系模型。
四、案例分析:关联性分析在市场营销中的应用以某互联网公司为例,研究不同广告渠道对用户购买意愿的影响。
首先,通过相关系数分析,计算不同广告渠道与用户购买意愿之间的相关系数。
关联性分析方法

关联性分析方法(一)比较分析法比较分析法,是通过对比两期或连续数期财务报告中的相同指标,确定其增减变动的方向、数额和幅度,来说明企业财务状况或经营成果变动趋势的一种方法。
比较分析法的具体内容运用主要存有关键财务指标的比较、会计报表的比较和会计报表项目形成的比较三种方式。
1、不同时期财务指标的比较主要有以下两种方法:(1)的定基动态比率,就是以某一时期的数额为紧固的基期数额而计算出来的动态比率。
(2)环比动态比率,是以每一分析期的数据与上期数据相比较计算出来的动态比率。
2、会计报表的比较;3、会计报表项目构成的比较就是以会计报表中的某个总体指标做为%,再排序出来各共同组成项目中约总体指标的百分比,从而比较各个项目百分比的多寡变动,以此去推论有关财务活动的变化趋势。
采用比较分析法时,应当注意以下问题:(1)用作对照的各个时期的指标,其排序口径必须保持一致;(2)应剔除偶发性项目的影响,使分析所利用的数据能反映正常的生产经营状况;(3)应当运用完全相同原则对某项存有明显变动的指标搞重点分析。
(二)比率分析法比率分析法就是通过排序各种比率指标去确认财务活动变动程度的方法。
比率指标的类型主要存有形成比率、效率比率和有关比率三类。
1、构成比率形成比率又称结构比率,就是某项财务指标的各组成部分数值占到总体数值的百分比,充分反映部分与总体的关系。
2、效率比率效率比率,就是某项财务活动中所费与税金的比率,充分反映资金投入与生产量的关系。
3、相关比率有关比率,就是以某个项目和与其有关但又相同的项目予以对照税金的比率,充分反映有关经济活动的相互关系。
比如,将流动资产与流动负债进行对比,计算出流动比率,可以判断企业的短期偿债能力。
使用比率分析法时,应特别注意以下几点:(1)对比项目的相关性;(2)对照口径的一致性;(3)衡量标准的科学性。
(三)因素分析法因素分析法是依据分析指标与其影响因素的关系,从数量上确定各因素对分析指标影响方向和影响程度的一种方法。
超大规模数据中的关联性分析及其应用研究

超大规模数据中的关联性分析及其应用研究引言超大规模数据在当前的信息时代中已经成为了一种常见的资源形态。
通过对这些数据的处理和分析,我们能够挖掘出其中包含的价值信息,从而对各类行业和领域做出更加准确、科学的决策和规划。
然而,超大规模数据的处理和分析也面临诸多挑战,其中最重要的就是如何在海量数据中识别和挖掘出相互关联的信息。
因此,关联性分析在超大规模数据的处理和分析过程中具有非常重要的地位。
一、关联性分析的基本概念1.1 关联性分析的定义关联性分析是指通过计算数据中属性之间的相关程度,进而得到属性间相互关联关系的方法。
进一步来说,关联性分析可以用来帮助我们发现一组数据中的因素、和某个目标值之间的关系,以及两个或者多个变量之间的相关关系等。
1.2 关联性分析的分类基于不同的研究目标和数据形式,关联性分析可以分为多种类型。
其中,最常见的包括:- 二元关联性分析:研究两个二元变量之间是否存在相关关系;- 多元关联性分析:研究多个变量之间的关系;- 有序关联性分析:研究变量之间的有序的相关关系;- 时间序列关联性分析:研究某变量在时间上的演变规律,并进行相关性分析。
以上所有的关联性分析方法都旨在帮助我们更好地理解数据,挖掘数据中的信息,进而做出更加准确、科学的预测和决策。
二、关联性分析的应用领域关联性分析在超大规模数据分析中涉及到的领域非常广泛,其中包括了各类行业和领域。
以下是一些典型的应用领域:2.1 零售业随着消费者对于商品选择意愿的变化,零售业近年来也逐步开始探索关联性分析的方式。
通过研究消费者的购买历史,分析顾客购买商品之间的关联关系,零售商可以根据这些信息制定更加合理的促销策略,从而更好地吸引消费者。
2.2 健康领域健康领域也是关联性分析的重要应用领域。
例如,在疾病诊断和治疗方面,通过关联性分析可以发现疾病之间的关联关系以及病因的可能性,并进一步根据这些信息来预测病情的发展趋势,辅助医生做出更加准确的诊断和治疗建议。
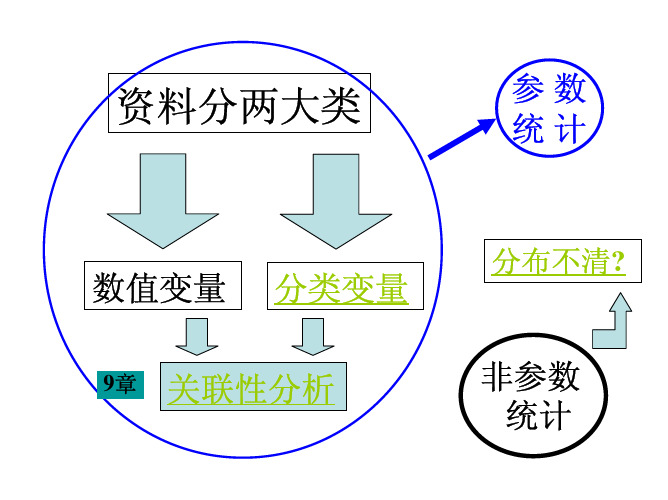
医学统计学-第9章 关联性分析
线性?程度如何?是正相关还是负相关? ⑵统计推断:两者的关系是否有统计学意
义?根据专业知识下结论。
9.2.2 相关系数的统计推断
r是样本相关系数,是总体相关系数ρ的估计
值,要想判断X、Y间是否有相关关系,就要检
验r是否来自总体相关系数ρ为零的总体。方法
本例 ν=n对-2=15-2=13,r0.05,13=0.514, 得到: p<0.05,即相关系数有统计学意义。
tr =
− 0.926 = −8.874,
1 − (0.926)2
ν = 15 − 2 = 13
15 − 2
可按公式(9-2) 计算
查附表C2(教材560),t 0.05,13=2.160;t> t 0.05,13,按α=0.05水准,拒绝H0,接受H1,故 可以认为凝血酶浓度与凝血时间呈负相关关系。
9.2.3 Spearman 秩相关
一、秩相关的概念及其统计描述 前面指出:Pearson积矩相关的假设检验要求
X和Y均服从正态分布。对那些不服从正态 分布或等级资料、总体分布未知的资料,因 难以进行分析,所以就不宜用积矩相关系数 来描述相关性。
此时,可采用等级相关(rank correlation), 或称秩相关来描述两个变量间相关的程度与方 向。该法是利用两变量的秩次大小作线性相关 分析,对原变量的分布不作要求,属非参数统 计方法。
例 某地研究2-7岁急性白血病患儿的血小
板数与出血症状程度之间的相关性,结果见下 表:试用秩相关进行分析。
首先先将实测原始数据由小到大排序 编秩,以pi表示Xi秩次;qi表示Yi的
次,见上表所示。
观察值相同的取平均秩次;将pi、qi直接 替换(9-1)中的X和Y的均数,直接得 到如下算式:
关联性分析课件

1. 它们在客观上是有一定联系的; 特点: 2. 在观察时是独立地去测量的;
3.这两个随机变量都服从正态分布; 例如:父子的身高(X)、儿子的身高(Y)
X1 Y1 、X2 Y2 、 X3 Y3 、 … 、 Xn Yn
相关分析和回归分析
是否有联系,联系的方 向、程度如何?
相关或关联
定量指示相关或关联的 指标:如相关系数
定量描述其 依存关系
回归分析
依存性 (relationship)
数学模型:如Y=f (x)
如何保证一份作关联性研究的样本合格?
抽样研究
保证样本的合格性
随机抽样 保证样本间相互独立
关联性分析
9.1 概述 9.2 两个连续型随机变量的相关分析 9.3 两个分类变量间的关联分析
(b)
(d)
(f)
(h)
散点图能直观地看出两变量是否存在相关关系。故研 究两变量关系应先绘散点图,再量化两者的关系。
Positive Correlation
Negative Correlation
Zero Correlation
Curvilinear relationship
(a)
(c)
Linear Relationship
相关系数反应线性相关性:
Y
Y
5.0
Y
7.5
Y
6
2.2
4.5
Y
7.0
2.0
5
4.0
1.8
6.5
4
3.5
1.6 3.0
6.0
3
1.4
2.5
5.5
1.2
2
2.0
1.0
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
讨论3:
有研究者欲研究某药口服量与血药浓度关 系,把口服药物设定为1, 2.5, 5, 7.5, 10, 15, 20, 30等档次,每档各取3只动物(共24只)进行 试验,于服药后1 h抽血检验血药浓度(教材 表99)。在SPSS中作散点图(教材图94), 计算得口服药物量与血药浓度的Pearson相关 系数r=0.979,经假设检验P<0.001,认为口服 药物量与血药浓度呈线性正相关。
Data95.xls
作业:
v
P172 第1、2、3题
图2 删除异常点后的散点图
20
RANK of 患病率
r =0.939 s P< 0.001
10
0 0 10 20
RANK of 碘含量
图3 分别取秩次后的散点图
v 患病率一般不服从正态分布,son积矩相 关系数,应用spearman等级相关系数。
请问: 本例的两个变量各有何特征?可以计 算Pearson相关系数吗?若可以,则计算的 方法与步骤有何不妥吗?计算结果正确 吗?可以推出本例的结论吗?
存在问题:
v
线性相关的条件不满足
即口服剂量是人为取定的,属于非随机变量,不宜作 相关分析。
v
利用Pearson相关系数
分析本例的散点图,可发现散点呈曲线形,而非直线 型,因此即使口服剂量是随机变量也不宜直接作线性相关 分析。
表1 某省不同地区水质碘含量与甲状腺肿患病率
碘含量 患病率 地区 (%) (μg/L) 1 1.0 40.5 2 2.0 37.7 3 2.5 39.0 4 3.5 20.0 5 3.5 22.0 6 4.0 37.4 7 4.4 31.5 8 4.5 15.6 9 4.6 21.0 碘含量 患病率 (μg/L) (%) 7.7 6.3 8.0 7.1 8.0 9.0 8.3 4.0 8.5 4.0 8.5 5.4 8.8 4.7 24.5 0.0
v 样本量少,抽样误差大,不能说是关系密
切。
讨论2:
有研究者欲评价两种量表对某疾病的严重 程度得分的一致性,评分者A用量表1,评分者 B用量表2,对同一批患者(5人)进行了评 分,计算了两次评分的相关系数,结果两者相 关系数非常之高(r=0.866 3),因此认为,两 种量表得分是一致的。
请问: 该研究的目的与设计方法吻合吗? 就本例的设计而言,存在任何不妥吗? 本例可否采用Pearson相关系数进行计 算?计算的结果正确吗?推论正确吗?
你同意上述推理和计算吗?应当如何研 究疗效和剂量的关联性? 独立样本,不能考察关联性和计算关联系数。
电脑实验:
v v v
Pearson积矩相关系数计算 p.155
Data91.sav
Spearman等级相关系数计算 p.159
Data92.sav
多分类资料的关联性分析p163 Data93.sav v 散点图的分层与合并 Data94.sav v 两组率比较的资料作关联性检验的实验
地区 10 11 12 13 14 15 16 17
率病患
50
40
r=0.712 P=0.001
30
20
10
0
-10 0 10 20 30
碘含量
图1 甲状腺肿患病率与碘含量的散点图
率病患
50
40
r=0.927 P< 0.001
30
20
10
0 0 10 20 30
碘含量
r =
c2 c + n
2
=
7 584 . = 0 3538 . 7 584 + 53 .
经c2检验,得P<0.025,按0.05水准,可 以认为三种剂量镇痛有效的总体概率有差别。 研究者认为,既然不同剂量组有不同的阵痛效 果,阵痛效果与剂量必定有关联;其关联的程 度可用列联系数来描述:
实习八:
关联性分析
20071114
目的要求
v 了解相关的种类以及相关分析的基本步骤 v 掌握两连续变量间的相关分析方法 v 掌握分类资料的关联分析方法 v 注意相关分析的解释
讨论1:
对某省不同地区水质的碘含量及其甲状 腺肿的患病率作了调查后得到下表的数据, 计算出Pearson相关系数,得r=0.712,经检 验P =0.001,据此认为甲状腺肿的患病率与水 质的碘含量之间有负相关关系,且关系较密 切。这是否正确?为什么?
对r进行假设检验,P值只能说明两变量有 无直线关系,不表示相关的密切程度。
注意分层资料盲目合并易出假象!当且 仅当分层情形下两变量的关系不会因为合并 而被歪曲时才可考虑合并。
b:无相关
® 相关 d:相关 ® 不相关
c:正相关
®负相关
讨论5:
为研究某镇痛药的镇痛效果与剂量的关 系,研究人员在自愿的原则下,将条件相似 的53名产妇随机分成三组, 分别按三种不同剂 量服用该药,镇痛效果如表119所示。
存在问题:
v
样本量太小(5人), 难以得出有统计学意义的结 论。
查表得知,当样本量只有5时,自由度为3,此时在的 水平要得到有统计学意义的相关系数值的最低界限是 0.878,本例相关系数为0.86,尚未达到有统计学意义的临 界值,原研究者必定是对相关系数未作假设检验而妄下断 论。
v
以“相关”推断“一致”
v
未限定浓度范围
研究者取的剂量范围为1~30,而结论认为口服药物量与 血药浓度呈线性正相关,未限定浓度范围,也是不妥的。 相关分析很重要的一条就是在多大范围作的研究就在多大 范围下结论,因为超过范围很可能结论就不再成立。
讨论4:
为研究糖尿病人血糖水平(mmol/L)与胰岛素水 平(mU/L)之间关系,某研究者在太原市某医院收集 了20名糖尿病人的有关数据,得到r =0.523(双侧 s 0.01<P<0.02);同时又在广州市几家医院收集60例 同 类 型 糖 尿 病 人 数 据 , 得 到 r =0.456 ( 双 侧 s P<0.001)。根据P值的大小,该研究者认为广州市 病人总体的相关更密切。 试对此结论发表你的看法。 若对上题的两个样 本作合并分析,讨论合并时的注意事项。